
语义增强的在线学习行为预测研究
2020-01-08 01:37叶俊民罗达雄廖志鑫
小型微型计算机系统 2020年1期
叶俊民,罗达雄,陈 曙,廖志鑫
(华中师范大学 计算机学院,武汉 430079)
1 引 言
在线开放课程不仅为学习者提供了学习著名大学先进课程内容的机会,而且还为教师、教学管理者提供了各类数据以进行分析的可能.针对学习者的学习行为(如预测学习者期中考试成绩和预测学习者毕业与否等问题)进行预测就是这些分析活动中的典型[1,2].针对在线学习行为预测的早期的研究主要是利用学习者的统计信息和学习行为信息预测在线学习行为,如A.Anderson等人制定了学习者参与类型的分类方法,并讨论学习者的参与度和其成绩之间的关系[3];J.Wilkowski等人发现先验技能与课程完成率之间无相关性[4];C.G.Brinton等人调查了与论坛活动下降有关的因素,发现与因素相关的线程分类和排序策略[5].随着在线论坛等板块的出现和短文本数据的积累,近年来越来越多的工作通过结合在线学习者的短文本语义信息来预测学习者的行为,如ESen-Can A等人提出一个针对论坛同步辅导对话的无监督理解模型,从语义的角度分析学习者的短文本信息,从而理解学习者的行为[6].
从技术角度上做分类,可将在线学习者成绩预测的研究可归纳为基于概率的预测方法、基于深度学习的预测方法和基于矩阵因子化的预测方法3类.第一,基于概率的预测方法主要包含知识追踪(Knowledge Tracing)和认知诊断(Cognitive Diagnosis).目前主流的知识追踪方法有贝叶斯知识追踪[7](BKT)和深度知识追踪[8](DKT),后者在实验中被证明有更优的效果;在此研究领中,最新提出的一种基于动态键值对记忆网络的方法,可以学习知识概念之间的关系和个体学习者对具体概念的掌握情况,并以此未来学习情况的预测[9].传统的认知诊断模型(CDM)可以分为连续型和离散型,其中潜在特质理论(IRT)是连续模型的典型例子,Deterministic Inputs,Noisy-And gate model (DINA)是离散模型的典型例子[10].在这一领域中,最新提出的一种模糊的认知诊断框架技术,可以用于学习者主观题和客观题的认知建模,增强了对学习者测验表现预测的精度[11].第二,深度知识追踪(DKT)技术是第一次尝试利用递归神经网络来模拟学习者练习过程以预测其未来表现的工作[8];Yu Su等人结合测验的文本信息提出了一种测验增强的循环神经网络框架来预测学习者的测验表现[12];Wenzheng Feng等人提出了一种上下文感知的特征交互网络来预测学习者的退出率[13].第三,矩阵因子化(Matrix Factorization)近年来也常被应用于教育领域的成绩预测和课堂内评估预测[14],Sweeney等人将SVD、SVD-kNN和因子分解机(FM)等几种推荐系统中常见方法用于预测下学期的成绩[15];Zhiyun Ren等人提出了一种时序课程影响的分解算法,课程因素和时间因素结合到学习者成绩预测方法中[16].
虽然利用短文本语义能够增强在线学习行为的预测效果,但是,该研究工作还面临许多问题,具体表现在:
1)当前研究没有将短文本语义信息与学习者的其他信息(如行为信息)有效结合,导致对学习者的刻画不够全面;
2)当前研究大部分只能预测特定种类的学习行为(如学习者的成绩),没有形成统一的预测框架.
针对以上的问题,本文提出了一种短文本语义增强的在线学习行为预测方法.具体思想是,首先,利用双向长短时记忆网络(BiLSTM)[19]得到短文本的语义向量表示;其次,基于深度知识追踪模型(DKT),将短文本语义向量、人口统计特征向量和学习行为特征向量相融合作为长短时记忆网络(LSTM)每个时间步的输入,以此建模学习者在不同时刻的学习状态;最后,基于学习者的学习状态设计相应的预测策略来预测在线学习者不同类型学习行为.
2 问题形式化定义
设N为在线学习者的个数,V是在线学习者的集合,|V|=N.T是课程所包含的知识点总数,一门在线课程包含若干知识点,这些知识点可以按照在线教学的时间顺序要求加以安排,学习者的学习状态与其在知识点对应时间歩上的各类信息相关.
定义1.学习者特征表征.设F∈RN×T×d表示了在不同知识点下的所有学习者特征.其中,Ft(i)=[Fi,t,0,Fi,t,1,…Fi,t,d-1]T∈Rd表示示学习者i在知识点t上的特征.Ft(i)由学习者的人口统计特征向量Fgt(i)、学习行为特征向量Fbt(i)和短文本语义特征向量DocSTt(i)拼接形成.
定义2.学习状态表征.设St(i)=[Si,t,0,Si,t,1,…Si,t,m-1]T∈Rm表示学习者i在知识点t上的学习状态,其中,Si,t,,j∈[0,1].所有学习者的学习状态被存储在S∈[0,1]N×T×m中,可通过学习者状态S预测其行为.
问题定义.语义增强的在线学习行为预测.本文要解决的预测问题描述如下.
输入:通过统计、学习行为和短文本信息得到的所有学习者的特征张量F
输出:利用F获取学习者的学习状态S,并通过S预测学习者的在线学习行为B.
针对上述问题,本文基于深度学习理论设计了一种短文本语义增强的在线学习行为预测方法,具体方法的流程如图1所示.此框架为三层结构,第一层针对学习者特征建模,在线学习社区的短文本STt(i)通过BiLSTM模型[19]加工得到其语义向量DocSTt(i),并将DocSTt(i)、Fgt(i)和Fbt(i)拼接成学习者特征向量Ft(i).第二层针对学习状态建模,即结合前一时间步的学习状态St-1(i)和当前时间步的特征Ft(i)得到当前时间步的学习状态St(i).第三层实现在线学习行为预测,即基于学习状态St(i),使用不同的预测策略,以预测出该学习者的在线学习行为Bt(i).
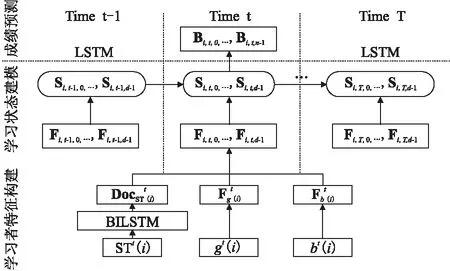
图1 语义增强的在线学习行为预测方法框架Fig.1 Semantic enhanced behavior prediction method for online learners framwork
3 在线学习社区学习者行为预测
3.1 短文本语义编码
设每个学习者i在知识点t上发表的短文本为STt(i)={s1,…,sp},其中,sj={wj1,…,wjLj}表示短文本中的一个句子,wj*表示句子j中单词的词,Lj表示句子j的长度.首先,利用Word2Vec[17]方法将短文本中的每一个单词转换成预训练好的词向量,即STt(i)={w11,…,w1L1,…wp1,…,wpLp}.其次,将STt(i)中的所有词向量作为输入,基于一种名为Long-Short Term Memery(LSTM)[18]的循环神经网络建模短文本的语义,具体计算过程如公式(1)所示:
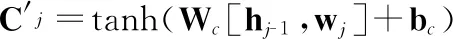
(1)
传统的LSTM模型只从一个方向建模文本的语义,没有充分利用短文本整体的上下文信息.为了解决此问题,本文使用BiLSTM来建模文本语义,具体过程如图2所示.
如图2所示,BiLSTM每个时间步的隐藏语义向量由两个方向的LSTM隐藏语义向量构成,具体计算采用公式(2).其中,hj是第j个时间步两个方向的LSTM隐藏语义向量的拼接.
(2)
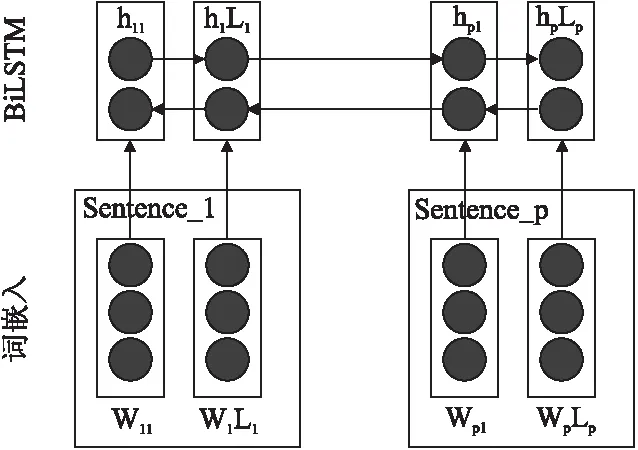
图2 BiLSTM示意图Fig.2 BiLSTM schematic diagram
对每个时间步的BiLSTM的隐藏语义向量取均值,并施加一个线性和非线性变换作为短文本的最终语义表示,具体过程如公式(3)所示.
docstt(i)=δ(W0mean(h1,…,hL1+…+Lp)+b0)
(3)
其中,W0是权值矩阵,b0是偏置向量,σ为激活函数,具体选择为sigmod函数.BiLSTM在语义建模的时候没有使用任何的专家信息,自动化地获取到短文本的语义特征和不同的学习者发言的特点.
3.2 学习者特征构建与学习状态建模
为了准确预测学习者的学习行为,本文将3.1节中得到的短文本向量表示与学习者的统计信息和行为信息进行融合.此过程中本文选取了文献[21]中使用的8个统计特征(如:年龄、性别和教育水平等)构建人口统计特征向量Fgt(i).同时,选取文献[20]中使用的16个学习行为特征(如:花费在看视频上的时间、在论坛中的发言次数和回复次数等)构建学习行为特征向量Fbt(i).
通过对多源数据特征信息的融合,具体为将Fgt(i)、Fbt(i)和DocSTt(i)进行拼接即可得到学习者在某个知识点的完整特征表示Ft(i).但由于学习是一个连续的过程,其在某一时刻的学习状态是受之前的学习状态与表现的影响.所以,如何有效地建模学习者在不同时刻的学习状态并刻画这些状态之间的影响是本文要解决的另一个问题.
文献[12]提出了一种基于深度学习方法以得到学习者当前的学习状态,并预测其在下次测验中的得分.基于此,本文提出采用可有效处理时间序列问题的LSTM模型来建模学习状态,具体的建模过程如图1所示,每个知识点对应时间步的学习者学习状态St(i)计算采用公式(4)进行计算.
C′j(i)=tanh(Wc[Sj-1(i),Fj(i)]+bc)fj(i)=σ(Wf[Sj-1(i),Fj(i)]+bf)ij(i)=σ(Wi[Sj-1(i),Fj(i)]+bi)oj(i)=σ(Wo[Sj-1(i),Fj(i)]+bo)Cj(i)=fj(i)∘Cj-1(i)+ij(i)∘C′j(i)Sj(i)=oj(i)*tanh(Cj(i))
(4)
其中,W*是权值矩阵;b*是偏置向量;C′j(i)是当前知识点对应时间步的LSTM临时状态;tanh是激活函数;Sj-1(i)是前一知识点对应时间步学习者的学习状态;Fj(i)是当前知识点对应时间步的学习者特征向量;fj(i)是当前知识点对应时间步遗忘门的计算结果;σ是激活函数;ij(i)是当前知识点对应时间步输入门的计算结果;Cj(i)是当前知识点对应时间步的LSTM状态;Cj-1(i)是前一知识点对应时间步的LSTM状态;oj-1(i)是当前知识点对应时间步的输出门的计算结果;Sj(i)是当前知识点对应时间步的学习者学习状态,即是学习者状态建模所需要得到的最终结果,接下来就可以研究学习行为预测问题.
3.3 在线学习行为预测
3.3.1 预测学习者期中考试成绩
基于期中考试时刻对应时间步的学习状态向量ST/2(i),利用一个线性变换和sigmod函数可预测其成绩,具体预测方法如公式(5)所示:
score(i)=sigmod(W1ST/2(i)+b1)
(5)
其中,score(i)表示所预测得到的第i个学习者的期中测验成绩,W1是线性变换的权重向量,b1是偏置;损失函数如公式(6)所示:
(6)
其中,scorer(i)是学习者真实的期中成绩.
3.3.2 预测学习者毕业与否
学习者毕业与否这个问题可视为一个二分类的问题.由于在不同知识点上的学习状态与表现对于毕业与否有着不同的影响,所以本文采用注意力机制[21]来得到不同时刻学习状态的重要性.并利用重要性加权学习者状态向量得到学习者在课程上的最终学习状态向量.具体过程如公式(7)所示:
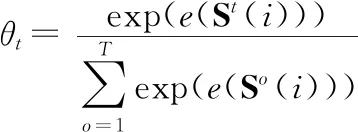
(7)
其中,e(*)为得分函数;v是计算t时刻学习状态重要性得分的向量;W2权值矩阵;b2是偏置向量;θt是不同时刻学习状态对于学习者i的重要性,F(i)是最终表示学习者i的学习状态向量.
接下来,基于深度学习理论,利用一个线性层和softmax函数可得到学习者毕业与否的概率,具体如公式(8)所示:
P(i)=softmax(W3F(i)+b3)
(8)
其中,P(i)∈[0,1]2是表示学习者毕业与否的概率分布的向量;W3是线性层的权重矩阵;b3是线性层的偏置向量.此任务的损失函数如公式(9)所示:
(9)
其中,Pr(i)是学习者i毕业与否的真实情况类别向量,只有在其所属类别对应出现时该位置的值才为1,其余情况该位置之值为0.
至此,利用以上的策略训练得到的模型可以有效完成相应的学习者行为预测任务.
4 实 验
本文在真实的MOOC学习数据集上进行了实验,论证了本文方法的有效性.
4.1 数据集
本文收集了来自国内某知名大学MOOC平台上的学习行为数据集.数据集由2013秋季学期和2014春季学期的11门完整在线课程组成.将这些课程归为3大类:工科(计算机科学与电子工程)、理科(经济学)和文科及其他(历史和体育).每门课程都设有论坛,学习者可针对不同知识点的教学内容发布问题或回复他人提出的问题,这一过程为本文方法提供了所需的短文本数据.除此之外,数据集还包含学习者的人口统计学信息和多种类型的学习者活动数据,如观看视频、完成作业、下载资源等数据,总计56800000个时间戳记的活动日志数据.表1介绍了数据集的相关统计数据.

表1 数据集介绍Table 1 Dataset introduction
4.2 实验设置
在超参数设置上,利用Glove[20]训练得到200维度的词向量.将BiLSTM模型的隐藏节点个数设置为100,即BiLSTM每个时间步的输出为200维向量.设短文本语义向量的维度设置为20;每个短文本最多含有20个句子,且每个句子的长度不大于50个单词.再采用Adam[22]方法优化整体模型的参数.将学习状态的维度m设置为24.
4.3 在线学习行为预测实验结果
本节说明短文本语义增强的学习行为预测方法实验结果.首先从每门课程中选取发表短文本次数处于前80%的学习者数据作为实验数据集.
4.3.1 预测学习者毕业与否
本文在11门课程上进行了预测学习者毕业与否的实验.每门课程将80%的学习者数据作为训练数据,将其余20%的数据作为测试测试.实验中的测评指标采用Precision、Recall和F1.由于本文数据集不满足基于概率的预测方法的需求,所以选择两种传统的机器学习方法Logistic Regression(LR)、Support Vector Machine(SVM)代替基于概率的方法作为本文方法的对比方法.选择方法Factorization Machine(FM)[16]作为代表基于矩阵因子化预测方法的对比方法.由于Latent Dynamic Factor Graph(LadFG)[20]被证明优于大部分深度学习方法,所以选择其作为代表基于深度学习预测方法的对比方法.LR和SVM利用除短文本语义信息外的统计信息和学习行为信息特征训练logistic回归模型和SVM模型,并利用训练好的摸型进行预测.FM方法先构造学习者-课程矩阵,将学习者对应课程的成绩作为矩阵元素,利用矩阵因子化的方法可得到学习者和课程的特征向量,再基于特征向量去判断学习者毕业与否.LadFG利用学习者的人口统计数据、学习行为数据和论坛行为数据构建动态图模型,再基于学习者的整个过程的学习状态去预测学习者毕业与否.具体结果如表2所示.

表2 预测学习者毕业与否效果对比Table 2 Result compare of predicting learners′ graduation or not
如表2所示,由于LRC和SVM方法仅考虑基本不变的统计学特征和学习行为的平均数值,所以无法学习到学习者学习状态的变化,因此这两种方法的预测效果较差.FM方法仅利用学习者的成绩数据,无法刻画学习者整体的学习行为,所以此方法的预测效果也不理想.相比之下,本文方法与LadFG方法均在时序上考虑学习者的多种特征,因此可学习到不同时刻的学习状态变化信息,所以实验效果较好.同时,本文方法还使用了短文本语义增强机制和注意力机制,这不仅使得本文方法可学习到学习者主观因素,而且还可以捕捉到不同时刻学习状态对学习者毕业与否的不同的重要性,这又进一步提升了本文方法的预测准确性.
4.3.2 期中成绩预测
首先本文将百分制的分数换算到[0,1]区间,并在11门课程上进行了期中成绩预测任务的实验.每门课程选择80%的学习者数据作为训练数据,选择其余的20%的数据作为测试数据.由于成绩预测任务的输出是数值类型,所以此处采用以下两个测评指标,具体形式如公式(10)和公式(11)所示.
(10)
其中,T[-0.03,+0.03]表示预测分数和学习者真实期中成绩的差距在此区间范围之内的学习者人数,N为测试集中的所有学习者人数.
(11)

在实验对比方法上,除了上一节提到的方法FM和方法LadFG之外,同时再引入多变量回归(MR)作为本文方法的对比算法.具体为利用除短文本信息外的统计信息和学习行为信息特征训练多变量回归模型,并利用此模型进行预测.实验结果如表3所示.
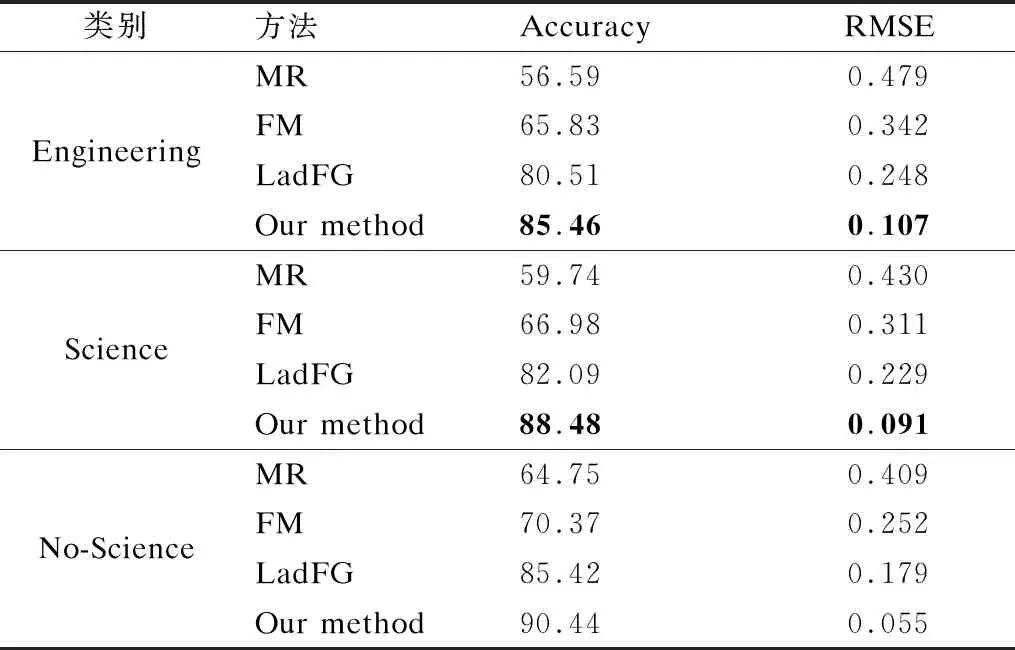
表3 期中成绩预测效果对比Table 3 Result compare of predicting learners′ grade
4.3.3 收敛性实验
为了证明本文方法在实际使用时候的有效性,本文针对这11门课程数据进行了收敛性分析.首先选取每门课程80%的学习者数据作为训练数据,并设置学习状态向量的维度m为24.

图3 收敛性分析Fig.3 Convergence analysis
图3为收敛性分析的结果,每次迭代利用了50个学习者的数据作为输入,结果显示:在大约15000次迭代(大约300次epoch)之后模型就会逐渐收敛.
5 总 结
本文提出了一种语义增强的在线学习行为预测方法.首先,利用BiLSTM得到短文本的语义向量.其次,将短文信息、学习行为信息和统计信息相融合,并利用LSTM对学习状态进行建模.最后,针对不同的学习行为应用不同的策略进行预测.通过在真实数据集上的实验证明了利用短文本语义信息能有效地提升在线学习行为预测的精度,并且此方法原则上能够用于所有学习行为的预测,具有很强的通用性.
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
新高考·高一数学(2022年3期)2022-04-28
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
时代英语·高二(2018年7期)2018-12-03
时代英语·高二(2018年3期)2018-06-06
高中生学习·高三版(2016年9期)2016-05-14
长江学术(2016年4期)2016-03-11
新高考·高二数学(2015年11期)2015-12-23
长江学术(2015年1期)2015-02-27
阅读与作文(英语高中版)(2013年12期)2013-12-11
