
端到端维吾尔语语音识别研究
2020-01-08 01:37丁枫林
小型微型计算机系统 2020年1期
丁枫林,郭 武,孙 健
(中国科学技术大学 语音及语言信息处理国家工程实验室,合肥 230027)
1 引 言
随着深度神经网络(Deep Neural Network,DNN)在自动语音识别领域的广泛应用,语音识别性能得到了显著的改善[1].目前,基于深度神经网络-隐马尔科夫模型[2](Hidden Markov Model,DNN-HMM)的语音识别系统仍是主流识别模型.DNN-HMM系统一般由声学模型,语言模型,发音词典等多个部分组成.这种模型通常以隐马尔科夫模型HMM为基础对状态进行建模,训练前需要通过混合高斯-隐马尔科夫模型(Gaussian Mixture Model,GMM-HMM)获得每一帧的语音标注,其间更是涉及决策树聚类,状态绑定等过程,模型训练过程相对复杂.
近年来,基于端到端(End-to-End)的语音识别系统由于对语言学知识要求较少,训练流程简单,越来越受到人们的关注.目前,最主流的端到端识别模型有两种,一种是基于链接时序分类[3](Connectionist Temporal Classification,CTC)的端到端模型[4],另一种是基于注意力机制的编码器-解码器(encoder-decoder)端到端模型[5,6]:其中CTC取得了与主流相近的识别性能.然而CTC模型通常采用长短时记忆网络[7]Long Short-Term Memory,LSTM)作为网络的主体结构来为语音的时序建模,虽然建模能力比较好,但是并行化程度较低,模型训练速度十分缓慢[8].针对这种循环神经网络(Recurrent Neural Networks,RNN)结构存在的问题,谷歌的Vaswani等人提出一种名为Transformer[9]的编码器-解码器端到端模型.该模型摈弃了RNN的结构,完全采用自注意力(self-attention,SA)机制来建立输入到输出的依赖关系.[10]将Transformer用于英语的语音识别任务上,取得了较好的效果.但是由于该模型没有有效利用语言学知识,总体性能仍存在可观的提升空间.鉴于此,本文在Transformer的基础上,将其部分结构与CTC准则相结合,提出结合自注意力机制和CTC的SA-CTC模型,并将其用于维吾尔语的语音识别任务上,实现两者的有机结合.
在CTC输出建模单元的选择上,太多或者太少的建模单元都会影响识别的性能,本文针对维吾尔语的识别单元选择进行研究.维吾尔语是中国境内维吾尔族的官方语言,属阿尔泰语系—突厥语族—葛逻禄语支.维吾尔语是一种拼音式文字,共有32个字母,其中有8个元音字母,24个辅音字母,书面语和口语之间的区别不大[11].虽然维吾尔语的发音单元并不多,但由于维吾尔语是一种典型的黏着语种,其构词和构形附加成分很丰富,词汇中除有维吾尔语的共同词外,还有一定数量的阿拉伯语和波斯语的借词.这些导致了维吾尔语的词汇量非常庞大,增加了语音识别的难度,如何寻找合适的声学建模单元来兼顾庞大的词汇量成为一个影响识别性能的重要问题.为了在声学建模单元和丰富的词汇量之间找到一个平衡,本文引入字节对编码[12](Byte Pair Encoding,BPE)算法对维吾尔语词汇进行学习,以该算法产生的子词单元作为CTC建模单元.
在识别时,为了利用维吾尔语的语言学知识,进一步提升识别性能,我们在解码时结合传统的语言模型,将词典、语言模型和声学模型统一解码,系统识别性能获得明显的提升.在King-ASR450维吾尔语数据集上,采用本文推荐的算法,识别性能明显优于当前主流的基于隐马尔可夫模型的混合系统和基于双向长短时记忆网络的端到端模型.
2 基于SA-CTC的声学建模
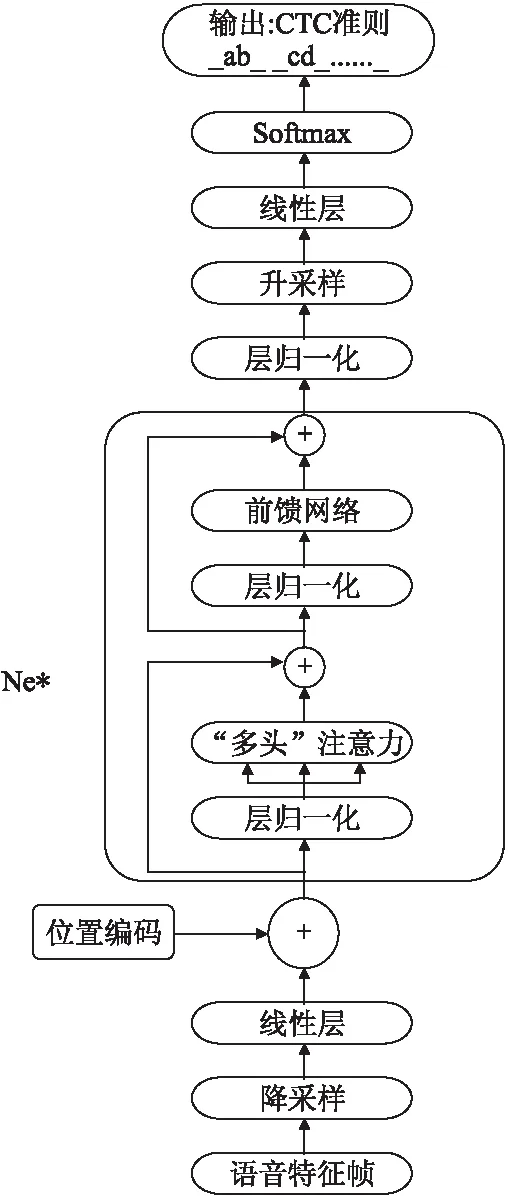
图1 模型结构Fig.1 Model architecture
编码器-解码器结构集成的语言模型仅体现在解码时利用上一时刻的预测得到当前时刻的预测,存在一定的局限性,无法充分利用语言学信息.因此为了在解码过程中显式的引入语言模型,进一步提升语音识别的性能,本文在Transformer结构的基础上,去除其中的解码器部分,将编码器与链接时序分类(CTC)相结合,作为本文所采用的端到端模型,模型结构如图1所示.整个模型的主体由若干个相同的编码层堆叠而成,每个编码层分为两大部分:“多头”注意力(Multi-head attention)和前馈网络(Feed-Forward Network).每一部分后面都添加一个残差(residual)连接,然后进行层归一化(layer nomalization)操作.另外模型还包括降采样与升采样模块,位置编码模块以及输出层.输出采用链接时序分类(CTC)准则,对每一帧语音预测一个标签,最小化CTC损失函数.
2.1 编码层
2.1.1 “多头”注意力
“多头”注意力(Multi-head attention)模块由若干个相同的层堆叠而成,每层是一个自注意力(self-attention)机制,通过缩放的点乘注意力(Scaled Dot-Product Attention)来实现.自注意力是一种利用输入序列的不同位置间的联系来计算输入表示的机制.具体来说,它有三个输入,查询(queries),键(keys)和值(values),可以理解为编码后的语音特征.Query的输出由value加权求和得到,而每个value的权值通过query及与之相关的key的设计函数计算得到.如图2(a)所示,设Q表示query,维度为tq×dq;K表示key,维度为tk×dk;V表示value,维度为tv×dv.通常情况下,tk=tv,dq=dk,则自注意力的输出由公式(1)计算:
(1)
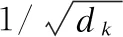
“多头”机制用来联合多个层不同的自注意力表示,即计算h次自注意力,h表示“头”的数目.如图2(b)所示,query,key和value分别经过三个线性投影层以增加彼此之间的区分性,然后利用它们分别计算h次点乘自注意力,将输出拼接起来后再经过一个线性投影层作为最终的注意力表示:
MultiHead(Q,K,V)=Concat(head1,…,headh)WO
(2)
(3)
其中W为对应线性投影层的权重.

图2 点乘注意力与“多头”注意力Fig.2 Dot-product attention and multi-head attention
2.1.2 位置前馈网络
位置前馈网络(Position-wise feed-forward network)包含两个线性变换层,两层之间有一个ReLU激活,见公式(4):
FFN(X)=max(0,XW1+b1)W2+b2
(4)
其中W为对应的线性层的权重,b为偏置量.
2.2 降采样与升采样
自注意力需要计算每帧声学参数的注意力权重,对训练语音较长的语句,会导致内存需求过大.为了减少模型训练时所占用的内存,加快训练速度,首先对原始语音特征帧进行降采样,然后再经过线性层进行编码.同时由于输出采用 CTC准则,需要对每一帧语音预测一个标签,所以在输出层之前再对语音特征进行一步升采样操作,将语音帧长度恢复成原始长度.这样,在加快运算速度、减小内存需求的同时也保证了模型精确度,提高了识别性能.
2.3 位置编码
由于模型中没有使用任何循环网络的结构,所以模型无法对输入语音帧的时序进行建模,而时序建模对于语音识别来说是必不可少的.因此需要在输入特征序列中加入位置编码信息以使模型获得输入语音的时序信息.位置编码由公式(5)计算:
(5)
其中p表示序列中的位置,即将序号为p的位置映射为一个维度为dpos的向量,这个向量的第i维由PEi(p)计算得到.由三角函数的和角公式可知,p+k的位置编码可表示为p位置编码的线性变换,提供了表达相对位置信息的途径.
2.4 链接时序分类
输出层采用链接时序分类(Connectionist Temporal Classification,CTC)准则.CTC是一种典型的端到端技术,用来处理输入序列和输出标签序列对应关系未知情况下的序列分类问题.
在语音识别中,输入序列为x={x1,x2,...,xT},对应的输出标签序列为y={y1,y2,...,ym},通常m< (6) 其中y′ 是对输出标签序列y经过插入blank以及重复单元等操作而得到的映射序列.例如y=(a,a,b),y′=(-,aa,-,a,-,b) .最终输出是对中间序列合并连续重复单元及去除blank得到. 在CTC准则中,假设输出单元之间是相互独立的,则概率P(π|x) 可表示为公式(7): (7) CTC损失函数定义为真实标签序列L对应的后验概率P(L|x)的负对数似然,如公式(8)所示: LCTC=-lnP(L|x) (8) 后验概率分布P(y|x)可通过前向-后向(forward-backward)算法求解,如公式(9)所示: (9) 正如前述,维吾尔语属阿尔泰语系—突厥语族—葛逻禄语支,是一种典型的黏着语种,存在着音素比较少(8个元音+24个辅音)和构词特别丰富(百万量级)的两个极端情况,都不适合用来作为CTC建模的输出单元.从工程的角度,CTC建模单元在几千到上万之间是比较适合的.我们采用字节对编码(Byte Pair Encoding,BPE)算法来生成CTC输出建模单元. BPE算法利用贪心算法思想,是一种高效的数据压缩算法.在数据压缩的过程中,BPE算法每次搜索在目标内存(RAM)页面上的程序代码中出现次数最多的字节对;然后,用未在特定代码中出现过的单字节令牌替换该字节对.反复迭代这两步操作,直到所有字节对都被替换或是没有频次大于1的字节对出现,最终输出压缩后的数据和包含所有被替换字节对的词典,词典用来恢复数据. 基于BPE的思想,可以将其用于子词切分以从单词中获得子词单元,并用这些子词单元实现对单词序列的一种编码.我们采用[13]中的BPE操作,具体步骤如下: 1)准备过程.对训练语料进行统计,生成“词语—词频”词典.然后将每个词语以字符为单位用空格切分开,并在词尾添加一个词尾标识符,以区别在其他位置相同的字符. 2)学习BPE单元.将单词中的字符以空格为分隔符两两前后组合形成字符对,结合词频,统计所有的字符对及其出现的频次.选择出现频次最高的一对字符,去除中间的空格进行合并,合并后产生的字符序列作为一个新的符号代替原来的字符对.然后重复统计字符对频次及合并最高频次字符对这两步操作,直到合并的次数达到指定的次数为止.按照统计频次从高到低输出合并的字符对. 3)应用BPE单元.用上一部产生的字符对列表对需要处理的语料进行切分.在进行切分时,同样以词语为单位,先分割成字符.然后依次按照在字符对列表中出现频次从高到低的顺序合并字符对.最后保留没有出现在字符对列表中的单元以及没有参与合并的单个字符. 可以看到,在学习BPE单元的步骤中,随着合并次数的增多,高频词语会被合并成一个单独的符号输出.因此,被切分后的语料最终包含了高频词、子词及单个字符. 用BPE对单词进行编码与其他编码方式最大的不同在于,BPE产生的单元仍是可解释的,即作为原单词的子词单元.且单元数目是算法的唯一超参数,因此可以针对具体语言选择合适数目的子词单元. 在本文的实验中,我们结合了维吾尔语自身的特点,对[13]中的BPE操作做出以下几点改动: 1)我们不在训练集语音对应的转录文本上用BPE学习子词单元,而是直接在维吾尔语词典上学习子词单元,并且不再考虑词频.因为观察维语词典可以发现,多数低频维语词是一些长词,这些长词都是在短词基础上连接一些词缀形成的,这也正是黏着语的特点.短词中已包含长词中的大多数单元,如果过分考虑高频词中的单元,则会导致低频词中的附加单元无法被BPE学习到. 2)在BPE学习子词单元之前不在词尾加入词尾标识符,即不再区分相同的字符在不在词尾.因为维吾尔语是一种拼音式文字,且书面语(写法)和口语(读法)之间的区别不大.所以如果强制把两个相同的字母因位置的不同而区分开,会导致学习到的子词单元比较混乱. 3)为了考虑实际发音中单词与单词之间的相互影响,我们在被BPE子词单元划分后的单词中加入位置(position)信息.在实验中比较了词首位置与词尾位置后,我们选择在词首加入位置信息,即将词首的子词单元与其他位置的子词单元区分开来. 表1 BPE算法产生子词单元Table 1 BPE algorithm generates subword units 表1展示了我们在维吾尔语单词上用BPE算法产生子词单元及加入位置信息的例子. 本文在King-ASR-450维语数据集上进行实验.该数据库收集了安静环境下79149条语音数据,长达121.3小时,转录文本所形成的词典共包含66027个维吾尔语单词.所有语音数据均为8KHz采样率、16bit、单通道的格式.在实验中挑选了~76.6k条语音数据(~117.45h)作为训练集,~0.5k条语音数据(~0.77h)作为开发集,~2.0k条语音数据(~3.07h)作为测试集.本文以Pytorch,Kaldi[14]和Eesen[15]作为实验平台,比较了不同模型下的实验效果,探究了改进的BPE单元对识别性能的影响. 在实验中,我们构建了三套系统进行比较,首先是主流的基于BiLSTM-HMM的基线系统,第二套系统是基于BiLSTM的CTC端到端识别系统,第三套系统是本文提出的SA-CTC端到端识别系统. 4.1.1 基于BiLSTM-HMM的系统 实验中将39维梅尔频率倒谱系数(MFCC特征)作为GMM-HMM混合系统的输入信号,在GMM-HMM系统中,通过高斯分裂和决策树聚类最终绑定状态数目为3334,用得到的模型对训练数据做强制对齐得到帧级标签,作为后续神经网络的训练数据. 在BiLSTM-HMM训练中,采用108维filterbank特征进行训练.在当前帧的前后各使用40帧语音数据获得前后信息.网络共有3层隐藏层,隐层节点为1024,建模单元为绑定的3334个状态.解码时结合3-gram语言模型. 4.1.2 基于BiLSTM的CTC语音识别系统 在基于BiLSTM的端到端语音识别系统中,我们采用双向长短时记忆网络为语音特征的时序建模,输出采用链接时序分类(CTC)准则,直接预测标签序列.本实验中采取3层隐藏层,每层1024个隐藏节点的BiLSTM网络,和108维filterbank特征进行声学模型的训练.建模单元采用BPE子词单元.解码时结合3-gram语言模型. 4.1.3 基于SA-CTC的端到端语音识别系统 对于本文所描述的基于SA-CTC的端到端模型,在实验中,我们采用6层编码层,“多头”注意力部分采用8个“头”,原始语音特征为108维filterbank特征,经1/4降采样,编码后维度采用512维,再加入位置编码信息作为网络的输入.前馈网络维度采用1024维.建模单元采用BPE子词单元,解码时结合3-gram语言模型. 三套不同系统的识别结果如表2所示,这里我们都是参数调节到最好的系统的比较. 表2 不同模型下的识别结果Table 2 Results of different models 可以看出,基于端到端模型的识别系统的识别性能要明显优于基于隐马尔可夫模型的混合系统,识别准确率均在90%以上.同时基于SA-CTC的端到端模型的识别效果又要优于基于BiLSTM-CTC的端到端模型,准确率达到91.35%.同时基于SA-CTC的端到端模型由于没有采用任何的RNN结构,模型训练速度远远快于基于BiLSTM-CTC的端到端模型.我们的实验在一块NVIDIA GTX 1080 Ti GPU上进行,对于基于BiLSTM-CTC的端到端模型,训练花费在24-30小时,而对于基于SA-CTC的端到端模型,训练时间仅为前者的1/3-1/4.由此可以体现出基于SA-CTC的端到端模型的优越性能. 另外为了探究本文在BPE子词单元上加入位置信息对识别性能的影响,在基于SA-CTC的端到端模型上,将不加位置信息的BPE子词单元和加入位置信息的BPE子词单元分别用于实验,实验结果如表3所示. 表3 不同BPE子词单元下的识别结果Table 3 Results of different BPE subword units 可以看出,在相同规模数量的情况下,加入位置信息后对识别性能有一定的改善,使得识别准确率达到了91.35%. 综合实验结果,本文用BPE算法产生的子词单元作为维语识别单元及在此基础上加入位置信息的改进,对于维吾尔语或类似语言的语音识别在建模单元的选取上具有一定的参考意义. 本文研究了基于自注意力机制和链接时序分类的端到端技术,在维吾尔语数据集上,搭建了完整的语音识别系统.同时针对维吾尔语大词汇量的特点,引入BPE算法,以BPE子词单元作为维语识别的建模单元.最终基于SA-CTC的端到端模型的识别性能超越基于HMM的混合模型和基于BiLSTM的端到端模型,识别准确率达到91.35%.证明了基于SA-CTC的端到端技术在维语识别上的有效性,也验证了BPE子词单元有效地解决了维语识别建模单元的选取问题.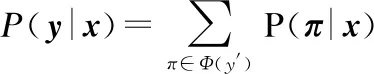

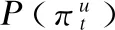
3 采用字节对编码的维吾尔语建模单元生成
3.1 字节对编码算法简介
3.2 维吾尔语识别单元生成

4 实验结果及分析
4.1 识别系统搭建
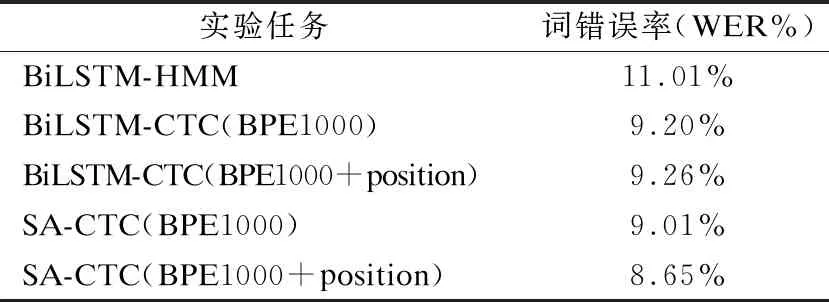
4.2 不同模型的实验分析
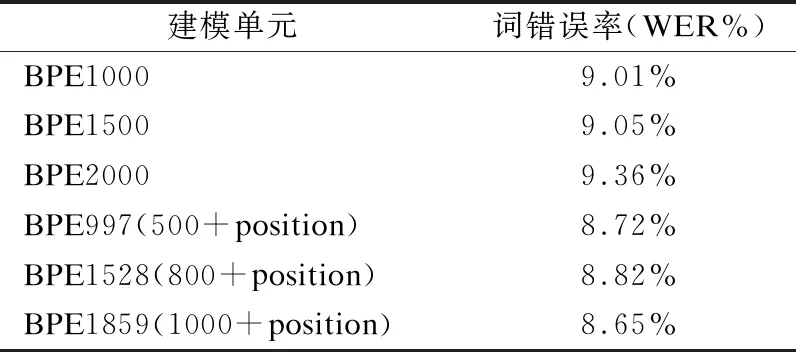
4.3 不同BPE单元的实验分析
5 总 结
猜你喜欢
小学生学习指导(中年级)(2021年12期)2021-12-30
昆明医科大学学报(2021年4期)2021-07-23
电脑知识与技术(2019年29期)2019-12-16
小学生学习指导(低年级)(2019年12期)2019-12-04
中国民族博览(2019年10期)2019-11-29
电脑爱好者(2019年8期)2019-10-30
疯狂英语·新读写(2018年3期)2018-11-29
知识文库(2018年16期)2018-05-14
电脑知识与技术(2018年3期)2018-03-21
北方文学(2018年2期)2018-01-27
