
不平衡训练数据下的基于深度学习的文本分类
2020-01-08 01:37陈志,郭武
小型微型计算机系统 2020年1期
陈 志,郭 武
(中国科学技术大学 语音及语言信息处理国家工程实验室,合肥 230027)
1 引 言
随着互联网技术的不断发展,各种各样的文本数据在日益增加,文本分类技术能够有效地组织和管理这些文本数据,极大地节省了物力和人力.
在文本分类中,首先需要用表示模型将文本表示为固定维数的向量,然后用分类器对固定维数的文本向量进行分类.TF-IDF模型是常用的文本表示模型,其通过计算文本中词频和逆向文档频率来将文本表示成一个固定维的向量[1].这种表示方法虽然简单有效,但是面临众多问题,比如数据稀疏、忽略语义信息等.
为了克服TF-IDF的缺点,研究者们发展了一系列文本降维方法,主要分为无监督方法和监督方法.典型的无监督方法有LSA[2]、PLSA[3]和LDA[4].LSA主要通过对大量的文本集进行统计分析来挖掘文本间关系,进而将文本表示为一个低维的向量.PLSA,LDA等主题模型主要利用文本词语之间的关联性来挖掘词语中蕴含的潜在语义信息,进而将该文本的潜在语义信息映射为一个低维的向量.上述方法均可以有效解决TF-IDF数据稀疏性问题.
与无监督方法相比,有监督方法产生的潜在主题特征通常更具主题区分性,因为其直接将文本的标签信息作为神经网络的训练目标.近年来,基于深度学习的词向量方法可以完美地实现词汇的低维、稠密的连续向量表示[5,6],为基于深度学习的文本表示学习提供了基础.近来如何利用神经网络模型去学习文档的分布式表示是一个研究重点.例如递归神经网络(Recursive Neural Network,RNN)、循环神经网络(Recurrent Neural Network,RNN)和卷积神经网络(Convolutional Neural Network,CNN)在文本建模任务上均获得了很好地效果[7-13].文献[11]中,作者通过利用三组大小不同的卷积核去提取文本中不同的n-gram特征,然后通过全局最大池化操作提取文中最重要的信息.实验结果表明作者提出的模型在文本分类任务上效果显著,已成为目前主流文本分类模型之一.
上述模型在训练数据各类样本平衡时能够取得很好的分类效果,但是当训练数据不平衡时,模型参数会偏移,导致分类效果并不理想[14-17].不平衡数据集指的是在同一个数据集中,某些类别的记录数远远大于或小于其他类别的记录数量,在实际文本分类任务中,例如垃圾邮件检测,电话诈骗检测等应用中都存在数据不平衡问题.如何解决这个难题成为了研究的热点.针对不平衡数据集分类改进方法一般可以分为两类:面向训练数据和面向模型参数.面向数据的方法主要是采样技术.采样是对训练数据进行处理,改变原有的数据分布,降低不平衡程度.采样主要包括下采样(random oversampling,RAMO)和上采样(random undersampling,RAMU)[18]:下采样主要通过删除训练集中的多数类样本数目来重新平衡数据集,但是下采样在删除多数类样本的时候,可能会删除重要的样本信息.上采样主要通过随机增加训练集中的少数类的数目,即重复利用少数类,来重新平衡数据集.
面向训练模型参数常用的方法有三种:
1)代价敏感学习方法,让网络结构对少数类更加敏感.例如Adaboosting算法[19],其主要通过在每一轮迭代中学习一个新的分类器方式得到多个分类器.在每一轮迭代学习中,当前分类器会根据每个样本的表现来给每个样本赋予不同的权重.这种赋值策略是为了减小正确分类样本的权重,而加大错误分类样本权重.最后通过对多次迭代模型线性加权得到最终的模型,那些分类准确率高的分类器会获得更大的权重;
2)集成学习方法,即把样本数量多的类切割成几个小部分,用不同的网络训练,每个网络训练多数类样本的一个小部分,同时训练全部少数类样本,通过投票原则确定最终分类结果.例如Bagging算法[20-22],多次在原始数据集上选出若干个样本来训练分类器,然后用训练得到的分类器集合来对测试样本进行分类得到多个分类结果.最后用多数投票或者对输出求均值的方法来得到这些分类器的最终分类结果,即最终的标签.
3)单分类器方法,即仅对少数类进行训练,例如运用支持向量机 (Support Vector Machine,SVM)只对少数类进行训练分类.
上述方法均在传统算法上进行改进的,随着深度学习的发展,基于神经网络的文本分类方法逐渐成为主流的文本分类模型,然而数据的不平衡给神经网络训练带来了巨大的挑战,如何减小数据不平衡给神经网络带来的影响成为了研究的热点.本文在神经网络模型参数训练中,提出了一种带类别权重的误差函数,实验结果表明本文提出的方法能显著地提升文本分类的F1值,提高了神经网络对不平衡数据的分类能力.
本文的后续内容安排如下:第二部分简要介绍了系统框架,第三部分介绍了改进方法,第四部分是实验结果及分析,最后一部分是总结.
2 系统框架
本文研究中文的文本分类任务,整个系统主要包括文本预处理、词向量训练、带类别权重的卷积神经网络分类器三个部分.
2.1 文本预处理
在训练或测试之前,需要对文本进行预处理,主要包括分词和去词.本文采用哈工大的LTP分词工具进行分词.分词后一般要引入停用词表和高频词表剔除对分类没多大影响的词语.
2.2 词向量训练
机器学习算法需要将输入表示为固定长度的特征向量,如何将词表示为一个固定长度的特征向量是将机器学习引入文本分类的核心.本文词向量是用谷歌公司开源的word2vec[5]训练得到的,实验中采用300维词向量.
2.3 卷积神经网络
近年来,CNN逐渐被应用于NLP任务中,在语义解析、搜索查询检索、句子建模、文本分类等任务上均取得了不错的效果,已经成为一种主流的文本分类模型.
卷积神经网络的输入是词向量矩阵,然后通过卷积和最大池化操作来筛选和组合信息,从而获得文档最终的分布式表示.本文采用的卷积神经网络如图1所示,其主要由输入层、卷积层、池化层和全连接层4部分组成.

图1 卷积神经网络Fig.1 Convolution neural network
1)输入层
在卷积神经网络输入层,其要求输入的是固定长度的向量,所以输入的句子会被映射成词向量矩阵x1:n=[x1,x2,…,xn]∈h×k.其中xi代表句子中第i个词对应的词向量,n表示输入句子长度,k表示词向量的维度.
2)卷积层
在卷积层,三组不同的滤波器同时在一个高度为h的窗口内进行卷积操作,从而就能同时提取出了三组不同的n-gram信息.
例如,用其中的一组卷积核w在xi:i+h-1上进行卷积操作,提取出n-gram特征ci:
ci=f(w·xi:i+h-1+b)
(1)
其中,f表示激活函数,b表示偏置.w在{x1:h,x2:h+1,…,xn-h+1:n} 这n-h+1个窗口进行一轮完整的卷积运算,得到相应的特征图c=[c1,c2,…,cn-h+1].
图1显示了两组不同卷积核,即两个阴影矩阵即分别表示大小为2和4的滤波器.
3)池化层

4)全连接层
最后我们会对计算得到的特征向量z进行softmax操作,进而得到每个文本在每一类别上的分布概率.softmax输出结果y∈M为:
y=softmax(w·z+b)
(2)
为了防止卷积神经网络对训练数据过拟合,我们在全连接层之前加入dropout,并且dropout仅在神经网络训练过程中使用.
3 带类别权重的卷积神经网络
卷积网络的训练过程中根据算法对其进行更新,先正向计算得到网络输出误差,然后反向更新网络权重,使网络的输出误差最小,本文采用批量梯度下降的方法更新网络参数.
卷积网络输出结果为y=[y1,y2,…,yN],y∈N×M,其中N是batch size包含的样本个数,M是输入数据集类别总数.
卷积神经网络的误差函数E为:
(3)
其中,tij表示样本i属于类别j的概率,当且仅当tij是1时,样本i属于类别j;yij表示第i个样本经过softmax回归后第j个节点的输出值,即样本i属于类别j的概率.
本文提出改进后的误差函数E为:
(4)
其中,cij是第i个样本真实类别j对应的标签权重.与之前卷积神经网络误差函数不同的是,本文所用的误差函数引入了类别标签权重c:c=[c1,c2,…,cM],其中cj为第j类标签对应的标签权重,具体计算方式为:
(5)
其中,T是超参数,dj为第j类标签在训练集中的文本总数,可以看出标签权重与标签所有的文本总数成反比.在不平衡数据集上,多数类与少数类样本数相差较大,如果类标签权重与标签所有的文本总数成反比,这样可以强化少数类对模型参数的影响,让神经网络对少数类更加敏感,从而获得更好的分类效果.
4 实验结果及分析
4.1 实验数据集
本实验采用的数据集为复旦大学发布的文本分类数据集,该数据库共包含19637篇文档,覆盖了20个主题,主要包括Art、Literature、Education等.训练语料和测试语料基本按照1:1的比例来划分.主题的具体分布如图2所示.
由图可以看出主题之间差异较大,例如主题15有1600个文本,而主题9只有25个文本,训练数据集各类别不平衡.
4.2 评价指标
文本分类任务需要同时衡量准确率P和召回率R.为了兼顾两者,本文采用F1作为文本分类的评价指标,具体计算方式如下:
(6)
在多类别分类任务中,F1可分为宏平均F1和微平均F1.微平均F1主要从整体上计算分类结果的F1值,其反应了系统的整体性能;宏平均F1先分别计算每个类别的F1,然后对所有类别的F1求平均,其反应了各个类别性能的均衡状况.本次实验主要在不平衡的复旦数据集进行,所以我们同时采用微平均F1和宏平均F1作为系统的性能评价指标.
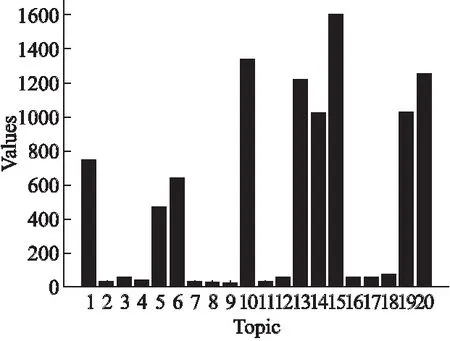
图2 主题分布Fig.2 Distribution of topic
4.3 实验结果与分析
本文建立了基于VSM(Vector Space Model)、PLSA、LDA和CNN四个对比系统,其中:
1)基于TF-IDF的VSM:用TF-IDF表示文本,特征的维度为52315,并用SVM对文本进行分类;
2)PLSA:用概率主题模型PLSA对文本建模,其中主题个数为190个时性能最优,主题模型提取出文本的主题向量之后用SVM进行分类;
3)LDA:用概率主题模型LDA对文本建模,其中主题个数为130个时性能最优,主题模型提取出文本的主题向量之后用SVM进行分类;
4)CNN:用训练集训练一个CNN模型,输入维度是3000;卷积核尺度为3、4、5;每组不同尺度的卷积核有128个波器;输出节点数为20,即主题个数;dropout的参数p设为0.5;激活函数采用ReLU.
表1 不同系统在复旦数据集上的实验结果
Table 1 Experimental results of different systems on fudan corpus
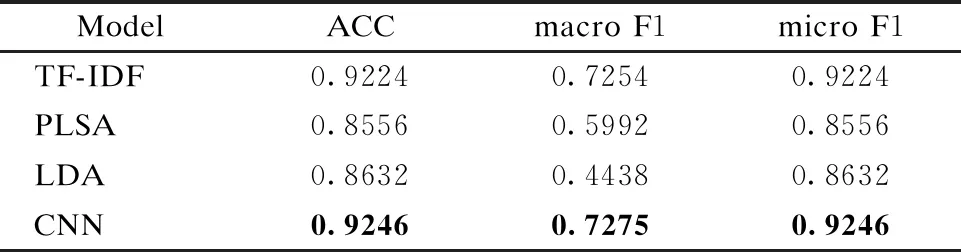
ModelACCmacroF1microF1TF-IDF0.92240.72540.9224PLSA0.85560.59920.8556LDA0.86320.44380.8632CNN0.92460.72750.9246
表1显示了基于TF-IDF、LDA、PLSA和CNN四个系统在复旦文本分类据集上的实验结果.由表可以看出在这四个系统中,不管是宏平均F1值还是微平均F1值,都是CNN最高.概率主题模型PLSA和LDA分类效果较差,这也是由于数据不均匀导致概率主题模型有偏差所致.由四组实验结果可以观察到宏平均F1值均明显小于微平均F1值,这是由数据类别不平衡造成的.为了提高分类宏平均F1值,我们选择分类效果最好的算法CNN,在其训练的过程中引入类别标签权重,强化少数类对模型参数的影响,类别标签权重如公式(5)所示.在公式(5)中,T是超参数,图3显示不同T对宏平均F1值和微平均F1值的影响.
图3显示了不同T值对F1的影响.曲线micro F1表示不同T值对微平均F1值的影响,由图可以看出当T值变化时,微平均F1值整体变化不大.曲线macro F1表示不同T值对宏平均F1值的影响,当T值在变化时,宏平均F1值变化较大,并在T等于100时取得最大值(0.7724),当T大于100时随着T的增大而呈现出下降趋势,所以带类别权重的卷积神经网络在T等于100时性能较好.

图3 不同T对F1的影响Fig.3 Influence of different T on F1 performance
为了证明卷积神经网络训练的过程中引入类别标签权重分类效果好于先进的文本分类的算法、数据采样和集成学习算法,本文加入四组对比试验.
1)RAMO:对训练集随机上采样[18];
2)RAMU:对训练集随机下采样[18];
3)Bagging:子分类器是决策树[22];
4)Adaboosting:子分类器是决策树[19].
表2 不同改进方法在复旦数据集上的实验结果
Table 2 Experimental results of different improvement methods on fudan corpus
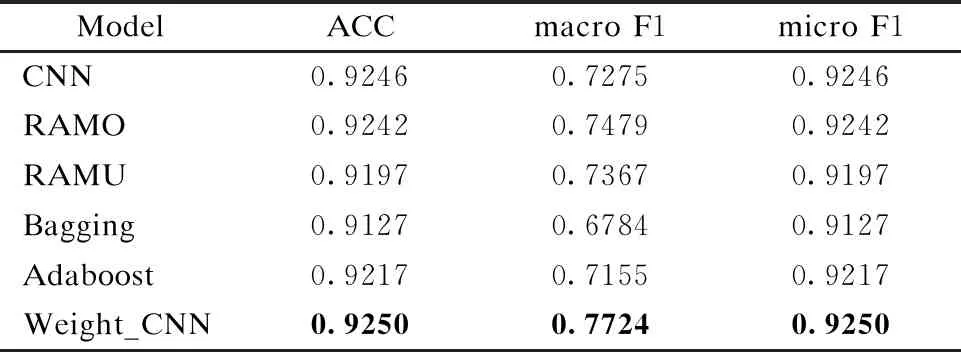
ModelACCmacroF1microF1CNN0.92460.72750.9246RAMO0.92420.74790.9242RAMU0.91970.73670.9197Bagging0.91270.67840.9127Adaboost0.92170.71550.9217Weight_CNN0.92500.77240.9250
表2显示了CNN、RAMO、RAMU、Adaboosting、Bagging和本文CNN六种不同算法在复旦文本分类据集上的实验结果.对比本文CNN (Weight_CNN)与其他算法,改进后的CNN算法宏平均F1值和微平均F1值均最高,分类效果最好.随机上采样(RAMO)可以同时提高宏平均F1值和微平均F1值,随机上采样(RAMU)提高宏平均F1值,却降低了微平均F1值,这很可能由于丢失信息造成的.本文CNN (Weight_CNN)分类效果明显好于上采样和下采样,而且也好于集成算法Adaboost和Bagging.Adaboost的宏平均F1值和微平均F1值均高于Bagging,因为Adaboost会关注被分错的训练样本,而Bagging是随机选择训练样本.相比于原来的CNN,改进后的Weight_CNN算法的宏平均F1值有了4.49%的提升.本文推荐Weight_CNN算法虽然对微平均提升不是很多,这主要是由于类别不均匀所致,但是毕竟也有提升.
为了证明在损失函数中引入类别标签权重来解决不平衡问题方法的有效性,本文还在较先进的文本分类算法RCNN上进行了实验[23].
表3 RCNN和Weight_RCNN在复旦数据集上的实验结果
Table 3 Experimental results of RCNN and Weight_RCNN on fudan corpus

ModelACCmacroF1microF1RCNN0.93930.75010.9393Weight_RC-NN0.94020.78900.9391
表3显示了RCNN和带权重RCNN(Weight_RCNN)算法在复旦文本分类据集上的实验结果.对比带权重RCNN(Weight_RCNN)和RCNN,可以看到改进后的RCNN算法宏平均F1值有了3.89%的提升.由此可以看出,即使对于较先进的文本分类算法,在训练中引入类别权重来解决不平衡问题也是可行的.

图4 CNN和Weight_CNN在每个主题上的实验结果Fig.4 Experimental results of CNN and Weight_CNN on each topic
图4显示了CNN和Weight_CNN在每个主题上的F1值.由图可以看出,Weight_CNN在多数类分类准确度保持基本不变的情况下,可以较好地提高少数类的分类正确度,从而提高数据集整体的分类正确度.由实验结果可以看出,改进后的误差函数可能会降低某些多数类的分类性能,但是下降幅度很小.改进后的误差函数旨在让神经网络能够较好地检测出少数类,避免少数类样本被多数类覆盖(因为少数类样本数量太少).同时多数类训练样本充足,而且样本不同类别属性差异性较大,所以神经网络能在保持多数类性能基本不变情况下提高少数类的分类性能.
通过上面所有实验结果可看出,在神经网络模型参数训练中引入了一种带类别权重的误差函数后,不仅提高了少数类的分类正确度,而且也提高了数据集整体的分类正确度.总之,本文提出的算法可以较好地解决不平衡数据上神经网络分类问题.这在实际的工作中比如诈骗检测具有重要得价值,可以把海量数据中的少数类准确检测出来.
5 总 结
本文在神经网络模型参数训练中引入了一种带类别权重的误差函数,以复旦文本分类数据集为例,探讨了该方法对不平衡数据集分类的可行性.通过实验验证,卷积神经网络训练中引入类别权重与文献[11]中的CNN相比在不平衡数据集上分类准确度有了较大的提高.实验证明,在神经网络模型参数训练中引入带类别权重的误差函数可以极大地提升系统性能,可以较好地解决不平衡数据集分类问题.
猜你喜欢
农业工程学报(2022年12期)2022-09-09
心理学报(2022年5期)2022-05-16
北京航空航天大学学报(2021年9期)2021-11-02
北京航空航天大学学报(2021年9期)2021-11-02
计算机系统应用(2021年9期)2021-10-11
当代陕西(2020年17期)2020-10-28
少儿画王(3-6岁)(2020年4期)2020-09-13
东方教育(2018年20期)2018-08-22
人大建设(2018年5期)2018-08-16
证券市场红周刊(2018年3期)2018-05-14
