
面向排名预测的上市公司股价收益研究
2020-01-08 01:37孙伯维姚念民孙玉轩
小型微型计算机系统 2020年1期
孙伯维,姚念民,孙玉轩
(大连理工大学 计算机科学与技术学院,辽宁 大连 116024)
1 引 言
在大数据时代,数据信息不论是对个人还是对企业都显得尤为重要,企业本身可以利用企业现有的经营数据,分析企业经营状态和未来走势,及时进行战略规划和调整,对于热衷于投资事业的个人或者团队来说,可以合理利用这些数据,进行预测和分析,从而确保在选择股票或者基金等理财产品的时候实现利益最大化.
在公司披露出的众多数据中,股价无疑是最受关注的数据,因为它代表了企业资产的价值,也和股民的收益直接挂钩,在东方财富网,新浪财经,巨潮网等金融网站上,为我们提供了丰富的数据信息以及企业年报,在深证信数据服务平台上我们可以根据季度获取上市公司的部分数据和信息.在这些数据中更为重要的便是股价收益,往往收益排名靠前的更容易被选择,但由于多种因素,造成股价收益排名并不稳定,如果合理的对排名做出预测,便会提高投资者的收益.
股价预测排名归根结底还是一个排序问题,分析问题的背景和使用场景,排序学习[1]为我们的研究提供了丰富的理论依据.本文首次将排序学习方法与股价收益排名预测任务相结合,其主要创新在于:1)利用多种排序学习方法进行实验,构建了面向股价排名预测的排序学习模型,并且和神经网络等方法进行了对比实验.2)在特征提取方面加入了公司评价信息等文本特征,并且在特征重要程度分析时证明有效,从而提高了股价排名预测任务的性能[2].
2 相关研究
面对大量的上市公司的经济数据,公司新闻,员工对公司评价等信息,如何从海量数据信息中快速挖掘和提取对我们有用的信息,从而对股价进行预测一直是研究的热点.Mi-ngtao[3]等通过数据转换,网络建模等方式提出了基于BP神经网络的股票价格预测模型,初步实现了神经网络在非线性系统中的预测任务.Zuo[4]等提出了一种概率图形模型,它通过有向无环图表示一组随机变量及其条件依赖性,实现了使用贝叶斯网络对股价的预测.Wang[5]等通过将支持向量回归并(SVR)与主成分分析(PCA)相结合,利用PCA从20个技术指标中选择V-SVR的输入变量,用于股票价格指数预测.Selvin等[6],使用深度学习架构来识别数据中存在的潜在动态.并利用LSTM,RNN,CNN-sliding window三个模型进行了股价预测任务.
3 面向股价排名预测的排序学习模型
本文对于股价排名预测任务,提出了面向股价排名预测的排序学习模型(Stock Price Ranking Prediction,SPRP),该模型可分为三个模块,分别是数据提取,数据处理,数据模型,具体流程如图1所示.
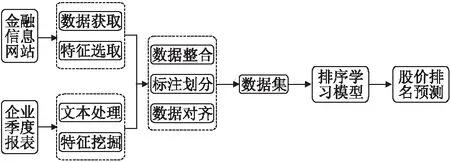
图1 面向股价排名预测的排序学习模型Fig.1 Ranking learning model for stock price ranking prediction
3.1 数据提取以及模型构建
3.1.1 数据提取
本文所使用的数据主要来自深证信数据服务平台(Sh-enzhen Securities Information CO.Ltd),该网站是在深圳交易所开放的互动数据交易平台,上线一周年访问量便过亿,是可靠的数据提取平台.在该平台上可以根据时间,公司股票代码查询到在深圳交易所上市的公司在本季度的每股收益排名情况,以及营业利润率,每股收益率等相关数据,根据排序学习模型,可以将平台提供的部分数据以及从公司季度报表中提出来的部分数据,经过处理后作为特征,此外在本模型中,还加入了本季度内公司正负面新闻,员工对公司的评价等文本数据作为公司的特征,实验的标注结果来自于网站的官方排名,由此,实现了股价收益排名模型数据集的构建.但由于排名是包含全部公司的,为了更好训练模型,在接下来的实验中,模型将公司分为18类,针对每个类别我们利用相同的特征,进行某个类别内股价收益的排名预测.本文利用网络爬虫爬取了2015年1季度到2018年3季度深交所上市公司所披露的数据,并根据公司名称爬取了该公司指定季度内在看准网的员工评价,用正负面评价作为特征,以及用公司名字作为关键字爬取百度网页上的某季度内对该公司的新闻报导,以正负面报道作为特征.将所获得的数据按照季度和公司存储起来,以便对数据进行预处理.
3.1.2 特征提取
为了确保提取的特征的高效性和充分性,模型主要从数值和文本两个方面进行了特征抽取,其中数值特征分为营运能力特征,发展能力特征.营运能力指的是企业经营运作管理的能力,简单来讲就是企业利用各项资产来实现利润最大化的过程,因此抽取“营业收入增长率”,“毛利率”,“营业利润”,“营业利润率”作为营运能力特征.
对于企业的来说,营运和发展密切相关,相辅相成,企业的发展能力,是企业自身通过生产经营活动,不断发展积累壮大资本的发展潜能.由此进一步将“每股收益”,“每股净资产”,“毛利率”等作为发展能力特征.
除去以上因素,考虑到公司的运营状况也受到非系统性因素的影响,譬如说企业的新闻报导就会极大程度的影响公司的运营,负面新闻过多势必会给企业带来消极影响,从而影响公司的股票价格.企业员工对公司的评价也是一项影响公司股价的重要指标,风评较好的企业势必拥有着良好的企业文化和经营方向,这样的企业便拥有良好的发展前景.所以实验中便又提取了员工评价和企业新闻作为文本特征,其中员工评价主要来自于看准网的公司评价,我们对实验中公司评价进行爬取,对评级为1到2星的公司标签置为-1,3星置为0,4到5星置为1.企业新闻主要是对指定时间内的公司的新闻进行爬取,并利用词语极性字典对新闻中的词频进行统计,其中消极词频大于积极词频我们将标签置为-1,消极词频小于积极词频我们将标签置为1,否则为0.实验特征具体如图2所示.
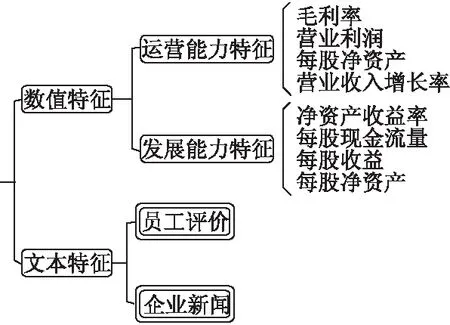
图2 公司特征信息Fig.2 Company′s characteristic information
3.1.3 数据预处理
在提取公司特征数据的时候,存在某些缺失值的情况,因此利用求均值的办法对缺失的特征值进行处理.例如某个季度的某个公司的每股收益数据值缺失,利用它上个季度和下个季度的均值来作为缺失的特征值.利用这种方式便可极大程度的减少由于特征值缺失而对实验精度的影响.
由于所提取的特征数值范围大小不一,通过数据标准化,可以将特征值缩放到相同的范围,以提高排序学习模型的训练速度和准确度.标准化公式为:
(1)
其中feature表示处理前某特征值,μ表示某个特征所有数值的均值,δ表示某个特征所有数值的方差,result表示处理后的特征值.
3.1.4 数据标注
深证信数据服务平台提供的官方股价收益排名可以作为数据标注的标签,具体的标记方式为:将下个季度的某个公司的排名作为当前季度的数据标注.依据每个季度的股价收益排名将公司划分为了四个标注等级.
排名在1~3名的公司划分为第一档,标注为4.这一档的公司在行业内表现突出,受到整个行业的关注,一般也是股民的首选.排名在4~9名的公司划分为第二档,标注为3.这一档的公司一般都有很大的潜力,也会经常挤进第一档,股价大都呈现平缓上升的趋势,一般会受到有一定资历的股民的青睐.排名在10~16的公司划分为第三档标注为2.这一档的公司一般排名波动较大,容易受到季节等因素的影响,但仍然是有潜力的公司,选择股票时候也是参考的重要依据.排名在17~25的公司划分为第四档,标注为1.这一档的公司一般比较小众,也会有一些比较年轻的公司,虽然竞争优势不明显,但股价都是呈现上涨的趋势.排名在25名之后的公司划分为第五档,标注为0.这一档的公司一般关注的人较少,股价会呈现亏损的状态.一般类别的公司数目大多会在50个以上,半数以上的公司股价都是盈利的,这些公司也是股民或者投资人比较关注的公司,所以这样的划分是合理的并且具有现实意义的[7].个别行业内公司数目较少的公司,根据具体情况,对每一档内的数据会做一些适当的调整,但是标注为非0的类别都会占到半数左右.
3.2 排序学习方法
为了更加充分和系统地对股价收益排名任务进行研究,本文首次将排序学习方法和股价收益排名任务相结合,并构建了SPRP模型.排序学习在信息检索领域[8]已经有着非常成熟的研究,并延伸到多个热门领域,凭借着机器学习手段不断地提高排序结果.为了使SPRP模型与股价收益预测任务充分契合,我们构建了两个领域的概映射关系,如图3所示.
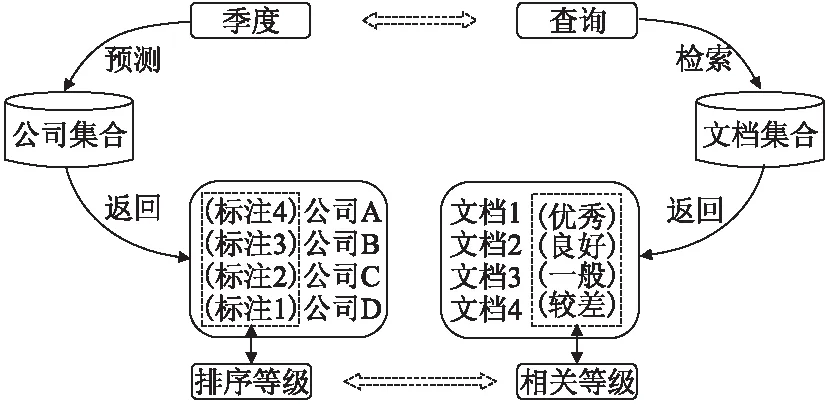
图3 信息检索与股价收益排名关系映射Fig.3 Relationship mapping between information retrieval and stock price ranking
实验中以季度作为时间点,并以行业类别对公司进行了划分,用每个季度对应信息检索领域的查询(query),某个行业的某个季度的公司股价收益排行与查询结果的相关文档集合(document set)相对应,某季度内特定行业的公司股价收益排名与文档相关等级(relevant level)相对应.通过映射预测公司股价收益排名便转化为成功检索出来的相关文档在文档集合中的排序问题.
通过以上对SPRP模型在股价收益排名预测任务中的可行性分析,本文安排了如下实验:使用Random Forests,Rank Net,Random Forests,MART等排序学习方法并利用Xgboost,和神经网络进行对比实验以便更好的观察实验结果.
4 实 验
4.1 结果分析
经过前面对数据的分析和预处理,实验最终形成的结构化数据有超过12000条,在这些数据中所属于的公司门类一共有18个,在保证公司类别间数据均衡的情况下,将实验数据划分为训练集和测试集,其中训练集有公司门类15个(电力,房产等),格式化数据10000多条;训练集有公司门类3个,格式化数据2000多条(家电,民航等).
通过Yu[9]等人的工作,我们知道在经过相关特征处理之后Xgboost可以对股价进行预测,并且有着不错的结果,可以作为排序学习方法用于股价收益预测实验的对比实验,通过Quah[10]等人的工作,我们了解到利用前馈神经网络可以对股价做出基本预测,并且也是股价预测任务中的一个基本模型.在本文的实验中,将不同的排序学习方法运用到股价收益预测模型中,对模型进行训练,通过与Xgboost和神经网络方法进行对比,可以进一步对实验结果进行分析和评价.将排序学习方法运用到SPRP模型中,并且利用MAP、NDC-G@n作为评价指标.在信息检索领域,NDCG[11]常用来衡量和评价搜索结果算法.将NDCG的思想迁移到股价收益排名任务中,实验中对股价排名划分的不同等级,正好与信息检索中的相关性相呼应,所以NDCG指标可以帮助我们评价股价排名预测任务结果的质量.得到的实验结果和对比实验的结果如表1所示.

表1 NDCG@n和MAP评价结果(%)Table 1 Evaluation results of NDCG@n and MAP
针对本文的实验,对于股价收益排名而言TOP-K的结果可能更具有意义,所以我们利用评价指标ERR@n[12]以及P@n进一步对实验结果进行评估.其中ERR代表预期的倒数排名,表示用户的需求被满足时停止的位置的倒数的期望,这一指标可以更好的衡量用户所关心的企业有多少排在指定名次内,其具体实验结果见表2.
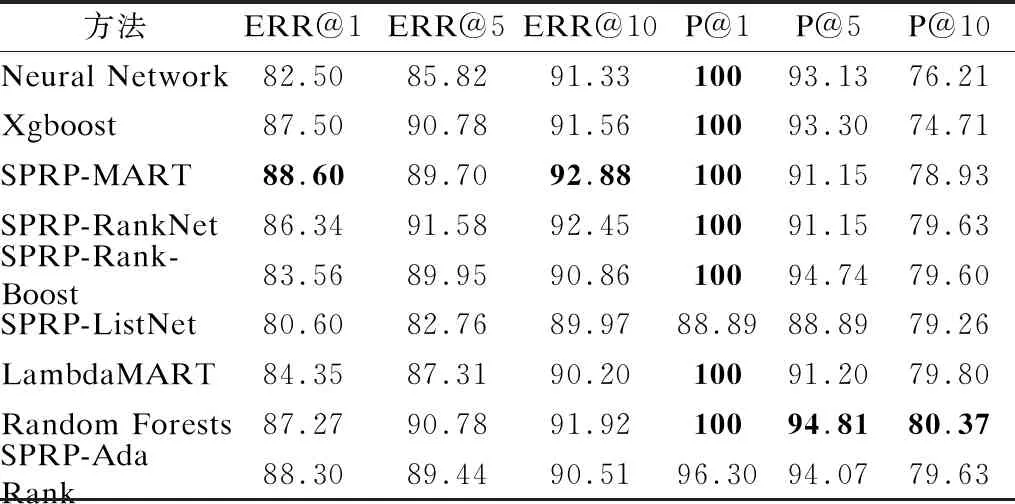
表2 ERR@n和P@n评价结果(%)Table 2 Evaluation results of ERR@n and P@n
根据实验结果可以得出,SPRP-MART,SPRP -Lambda MART[13]和SPRP-Random Forests 模型对股价收益排名预测的效果整体上要优于SPRP-RankNet,SPRP-ListNet,Xgboo-st以及神经网络模型,可以看到SPRP-Random Forests模型整体效果是最好的,尤其是在预测排名靠前的公司,由于Rank Net[14]利用交叉熵作为损失函数,巧妙的规避了评价指标的间断点,故而造成在参数优化的过程中,模型更加关注的是造成损失的文档.相反,当对模型进行评价时,主要关注的是排在前面的文档的相关程度,所以Rank Net的预测结果稍差一些.
4.2 趋势分析
如图4所示为Xgboost,SPRPP-MART,SPRP-Random For-ests等模型在测试集上对股价收益排名预测的NDCG@n 曲线图,通过观察可以得到,SPRP-Random Forests模型的预测结果几乎在每个点都是最高值,这说明了该模型对股价收益排名预测的最好,SPRP-MART的预测结果相对较差,只有在n>13时,才超过Xgboost和神经网络模型,纵观结果总体,每条曲线都是呈现曲折上升的,但都会有震荡点的存在,这与前面对数据的标注以及NDCG的计算规则有关,由于在标注的分界点预测误差会使NDCG指标下降更为明显,所以在标注的分界点指标值都会有比较大的变动,从图中还可以得到,Xgboost和神经网络的NDCG@n曲线的指标值整体上偏低,并且数据波动比较大,稳定性比较差,这表明SPRP模型对股价预测排名更为稳定,能够对真实排名靠前的公司进行较为稳定的预测.

图4 NDCG@n曲线变化图Fig.4 Curve change chart of NDCG@n
评价指标P@n表示在检索结果的文档集合中,相关性文档所占的比例,根据上文提到的对数据的处理以及对股价排名等级的划分,排名位于某个行业内的前50%的公司,被认定为是相关的,所以P@n在股价排名预测任务中,可表示为:在预测结果中排在前n名的公司,它们的真实排名排在前50%的比例有多少.由于排名靠前的公司股价变化大多在公司数目的前50%中变化,所以n的值越小,P@n的值越高,比如表3中多种方法的P@1都达到了100%,分析实验结果,可以得出:SPRP-Rank Boost,SPRP-Random Forests,SPRP--Ada Rank这三种方法的P@n指标总体上要高于Neural Net-work和Xgboost方法,但SPRP-ListNet方法表现的较差.
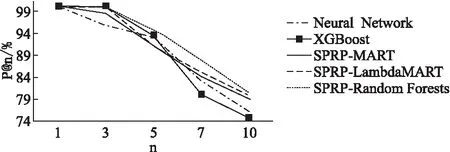
图5 P@n曲线变化图Fig.5 Curve change chart of P@n
如图5所示为Xgboost以及神经网络和SPRP-MART,SP-RP-Random Forests等方法关于P@n指标在测试集上的预测结果折线对比图.由图可知,当n<3时,除了神经网络方法之外,其余的方法结果都接近100%,此时的模型预测出的前3名左右的公司,真实排名也是排在前面的,当n=5时,所有模型都呈明显下滑的趋势,原因在于,在n=5附近是第一档和第二档的临界区域,边界附近的公司排名波动比较大,模型在边界处的预测能力稍显薄弱,可以观察到在每个档次变化的临界区域,都有呈现指标值下滑的趋势,但嵌入在SPRP中的排序学习方法下滑的速度明显较缓慢,并且最后结果趋于平缓时,Xgboost和神经网络的指标值也都比SPRP-Random Lambda MART等方法低.
4.3 实例分析
如表3所示是深证数据平台公布的2018年第一季度民航机场行业的股价收益排名以及各排序学习模型的预测结果,通过与官方排名对比,可以发现,Xgboost模型在股价收益预测排名中表现得不够理想,只将前三名预测正确,4~12名都出现了偏差.SPRP-Random Forests模型的预测结果和官方排名最为贴切,整体效果最好,只将中国国航和白云机场的排名顺序颠倒,对排名靠前的公司预测也颇为准确.在SPRP-Lambda MART[15]模型的预测结果中,第6~7名,10~11名的预测结果刚好与真实值相反.在SPRP -MART模型的预测结果中,5~8名的排序与真实结果相差较大,总体上来讲,这两个模型要稍差于SPRP-Random Forests,但远强于Xgboost.
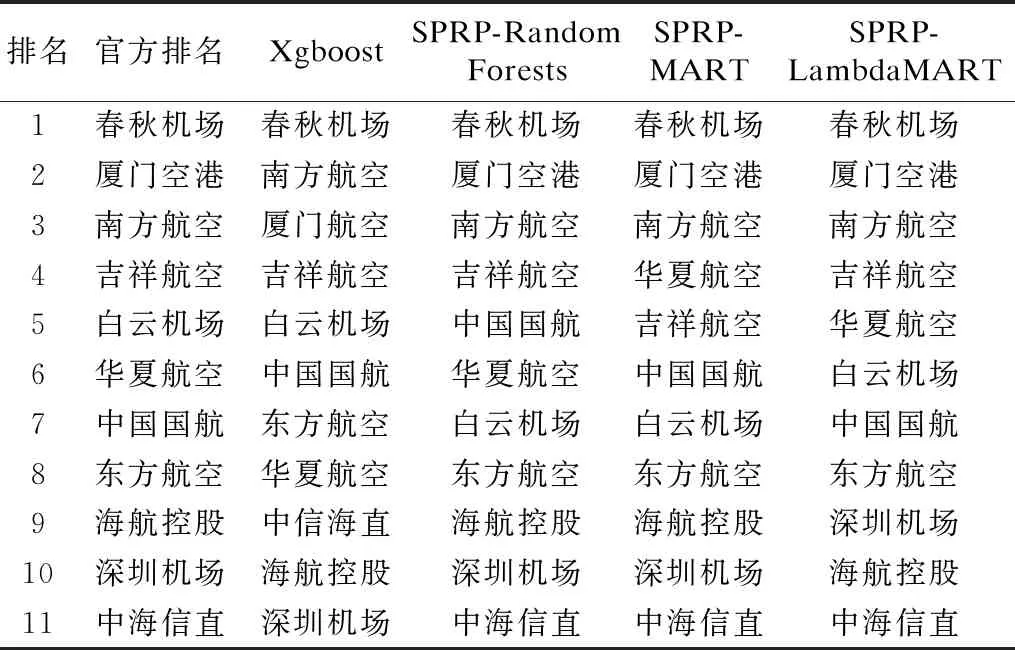
表3 部分模型对排名的预测结果Table 3 Prediction results using baseline and proposed models
4.4 特征重要性分析
如图6所示是Xgboost模型中各个特征的重要程度,从图中可以看出,在Xgboost模型中“净资产收益”,“每股收益”,“营业利润率”,“净资产收益”,“企业新闻”这个5个特征对公司排名贡献最大,其中净资产收益最为突出,是最重要的特征.这是因为净资产收益是由企业净利润和企业的净资产做商得到,它直接反应了企业利用资产来赚取利润的能力.“企业新闻”关系到公司的声誉,发展前景等,评价越正向,未来股价收益的可能性越大.“净资产收益”关系到公司经营水平和基础实力,收益越高,对股价上涨越有帮助.这些指标都直接或者间接影响了公司排名.
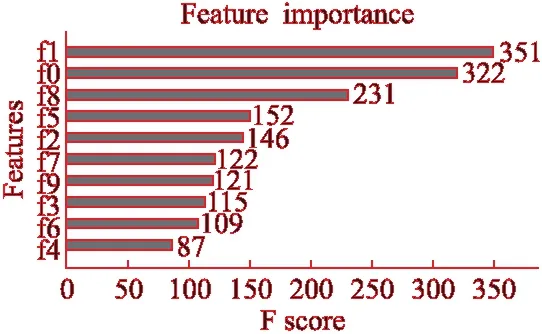
图6 Xgboost模型各特征重要程度Fig.6 Importance of Xgboost model features
如图7所示是SPRP-Random Forests模型各特征的重要程度,通过分析可以看到“每股收益”在模型中是十分重要的特征,对排名预测等级预测具有很大的贡献.这是因为股价是投资者最关心的指标,每股收益直接决定了单只股票的盈利性.“员工评价”在Xgboost模型中重要性排在第7位,而在SPRP-Random Forests中却排在第3位,通过对比可以发现,相同的特征在两个不同的模型中,贡献程度有很大差别.但综合来看,本文归纳的发展能力特征和文本特征对公司排名预测拥有更好的实验效果.
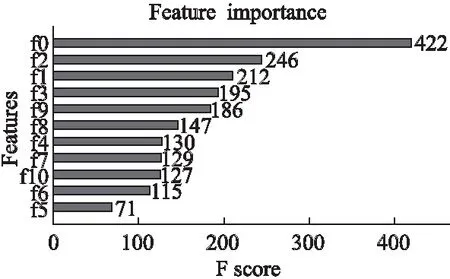
图7 Random Forests模型的特征重要程度Fig.7 Importance of Random Forests model features
5 结束语
本文提出了一种面向上市公司股价排名预测的排序学习模型,对股价收益排名进行合理的预测,利用深证信数据平台上的大量经济数据,以及爬取的文本数据,通过特征提取,数据重构等处理,构建了实验所需要的标准化数据集,利用模型中嵌入多种排序学习方法对数据进行训练和测试,并利用神经网络和Xgboost方法进行对比实验,实验结果发现:SPRP-Random Forests模型对公司排名预测的结果最为稳定,有比较好的效果,并且本文加入的公司新闻和员工评价的文本特征能够有效地提高模型的性能,综合来看本文提出的股价收益排名预测模型能够有效地提高股价收益排名预测任务的性能.预测排名可以在股民选股,投资者选择行业,行业内结果优化等方面有较大帮助.但本文的模型是对已经在深交所上市的公司进行排名预测,对于刚上市的公司由于数据缺失无法进行排名预测,又由于这些公司所在的领域比较新兴,国家或者地区政策等因素影响,短期内发展也是较为势头强劲的.未来的研究方向,会对公司年报中的呈现的文本进行分析和提取,以及通过分析行业市盈率,对比行业整体发展情况,对特征以及排序模型进一步完善.
猜你喜欢
名家名作(2021年4期)2021-05-12
科普童话·学霸日记(2020年1期)2020-05-08
股市动态分析(2019年42期)2019-11-13
股市动态分析(2019年49期)2019-01-13
小天使·一年级语数英综合(2019年2期)2019-01-10
股市动态分析(2016年2期)2016-09-27
商业会计(2015年15期)2015-09-21
中国经济信息(2015年8期)2015-05-05
时代英语·高三(2014年5期)2014-08-26
