
基于改进花粉算法的极限学习机分类模型
2020-01-06 02:15邵良杉李臣浩
计算机工程与应用 2020年1期
邵良杉,李臣浩
辽宁工程技术大学 软件学院,辽宁 葫芦岛125105
1 引言
极限学习机(Extreme Learning Machine,ELM)[1~2]是南洋理工大学黄广斌副教授在2004 年根据Moore-Penrose pseudoinverse广义逆矩阵提出的一种单隐层前馈神经网络(SLFNs)学习算法,相比于其他需要初始化大量参数的神经网络,ELM 只需预设网络中间层节点个数,并且不需要通过迭代来优化权值和阈值[3],具有计算速度快,泛化性能好的特点[4]。MELM(Multi-output Extreme Learning Machine)[5]在继承ELM优势的同时,增加了网络输出数目,使其能够更好地适用于多分类问题。
但ELM和MELM的初始输入权值和阈值随机选取的问题在一定程度上限制了模型的分类精度,导致分类结果产生一定的随机性和波动性[6]。近年来,有部分学者对极限学习机的初始输入权值和阈值进行优化,2006年Huang等人[7]首次采用人工蜂群算法优化MELM的初始输入权值和阈值,并得到了较好效果;2018年,贾伟等人[8]采用粒子群优化算法对ELM 的初始输入权值和输入层阈值进行优化,得到了最优的ELM模型;但是粒子群和人工蜂群算法都存在参数过多,执行过程复杂且易陷入局部最优解的问题。
花粉算法(Flower Pollination Algorithm,FPA)[9]作为一种新型元启发式优化算法具有参数少、易实现的特点,相比粒子群和遗传算法有着更好的寻优能力[9],2013年,贺兴时等人[10]将花粉算法应用到多目标优化问题上并取得了较好的效果。鉴于此,本文采用花粉算法优化极限学习机分类模型初始输入权值和阈值,但是和其他种群优化算法一样,花粉算法同样存在易陷入局部最优、收敛速度过慢的问题。肖辉辉等人[11]采用Levy飞行和配子间万有引力的方法实现配子位置的更新;段艳明等人[12]通过引入量子系统的态叠加特性,用波函数描述种群个体的位置,提高算法的全局寻优能力;Jiang 等人[13]通过入侵杂草的繁殖、空间扩散和竞争策略,动态生成种群,增加种群的多样性和有效性。以上改进虽然一定程度上提高了花粉算法的寻有能力,但仍然存在易陷入局部最优,寻优速度较慢的问题。为进一步提高FPA 的寻优能力和寻优效率,本文提出改进的花粉算法(self-Adaptive and Tent Chaos based Flower Pollination Algorithm,ACFPA),利用基于反向学习的Tent 映射优化花粉算法配子的初始位置,并在FPA算法的全局搜索上引入Tent混沌搜索策略,在局部搜索策略和切换概率p 中分别引入自适应算子,以此提高FPA算法的搜索效率。然后使用改进的花粉算法优化MELM的输入权值和阈值,并结合代价敏感(Cost-Sensitive,CS)[14]的思想,引入基于CS 的适应度函数,使花粉算法能够更加精确地刻画模型的分类性能,从而进一步提高ACFPAMELM模型的分类精度和收敛速度。
2 基本理论
2.1 MELM分类模型
极限学习机(ELM)是一种单隐层神经网络,根据输出数目的不同,可分为单输出极限学习机(ELM)和多输出极限学习机(MELM)。鉴于MELM模型在多分类问题上有着更好的适用性,因此本文采用MELM 解决多分类问题。
对于一个有k 个输入变量{(xi,ti)}ki=1l 个隐含层节点,z 个输出变量的极限学习机的输出可以表示为:
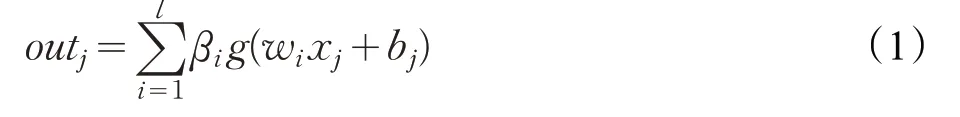
式中,j 为迭代次数,g()为激活函数,βi、wi、bi分别为第i 个隐含层节点的输出权值矩阵、输入权值矩阵和偏置。
将上式转换成矩阵Hβ=T 后的具体形式为:

对于基于梯度的神经网络算法(如BP),需要在迭代过程中优化所有参数,但在ELM算法中,如果激活函数无限可微,只需要随机给出输入权值和偏置,算法同时根据公式自动生成输出矩阵β1,此过程只执行一次,在保证精度的同时,降低了时间和空间的复杂度。输出矩阵β1可以表示为:

式中,H+是矩阵H 的Moore-Penrose广义逆矩阵。
2.2 Tent混沌策略
混沌变量能够运用其特有的非线性规律在目标空间中遍历所有可行解,拥有随机性、非线性、规律性和对初始值敏感性的特点[15]。当前解决混沌问题常用的映射方程有虫口模型方程和切比雪夫方程等[16-17]。由文献[18]可知,虫口模型方程在解空间两端取得的概率较高,在解空间中心区域取得的概率较低且分布均匀,而切比雪夫方程虽然在(0,1)区间上分布均匀,但迭代速度较慢。单梁等人[19]指出,Tent 映射在(0,1)区间上分布均匀并且速度较快,此外,反向学习策略能够增加解向量的多样性[20],因此,基于对上述分析,为使FPA在整个可行域内快速、均匀地搜索MELM 模型输入权值和阈值,本文采用基于反向学习的Tent混沌映射和Tent搜索优化FPA算法。
2.2.1 基于反向学习的Tent混沌映射
由于Tent 混沌映射在点0.2、0.4、0.6、0.8 上产生混沌吸引子,出现小周期现象,为避免迭代落入小周期循环,当xi={0,0.25,0.5,0.75}时采用xi=zj+1=zj+e(e为0~1 的随机变量)公式改变迭代初值,增加了混沌的内随机性,从而增加了混沌强度,同时通过反向学习公式增加了Tent混沌的遍历性,有助于提高解的质量和求解效率[20]。
Tent映射公式为:
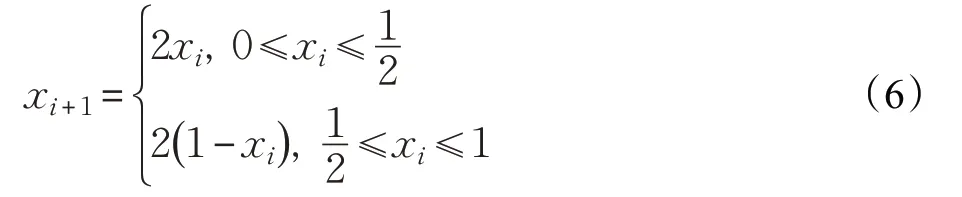
Tent映射的移位变换公式为:

反向解求解公式为:

基于反向学习的混沌序列生成:
步骤1 随机产生(0,1)的初值x0,z1=x0。
步骤2 根据式(7)生成一个x 序列。
步骤3 若xi={0,0.25,0.5,0.75},或xi=xi-s,s={0,1,2,3,4}则带入xi=zj+1=zj+e(e 为0~1 的随机变量);否则执行步骤(2)。
步骤4 若满足迭代次数,则停止迭代返回x 序列;否则转向步骤2。
步骤5 根据式(8)生成x 序列的反向解,并计算全部解向量的适应度值,返回前N 个最优的解向量。
2.2.2 Tent混沌搜索
本文采用混沌搜索对花粉算法的全局搜索进行优化,其中混沌搜索的步骤如下:
步骤1 利用公式(4)将xi投影到(0,1)区间
步骤3 利用式(10)将zi(k)载波到解空间
步骤4 计算当前解的是适应度,并与历史最优适应度进行比较,保留最优解。
步骤5 若达到最大迭代次数,则返回最优解,否则执行步骤2。

3 基于Tent混沌和自适应的花粉算法
3.1 花粉算法及改进可行性
花粉算法于2012 年由学者杨新社首次提出,在解决多目标和单目标优化方面效果理想。相比于粒子群等种群优化算法,FPA利用概率p(0 <p <1)按一定比例进行异花授粉和自花授粉,体现了Levy飞行策略,在一定程度上解决了输出结果容易陷入局部最优解的问题。因此,相比于其他优化算法,利用花粉算法优化MELM模型能在保证分类精度的同时,大大加快模型的收敛速度。
设花粉配子个数为N ,目标函数维度为d,配子的当前位置为Xi=[xi1,xi2,…,xid](i=1,2,…,N)配子局部搜索(自花授粉)公式为:


式中,L 为服从Levy 分布的随机变量,g*为全局最优解。其中L 近似表示为:

式中,s ≪s0≪0,gam(γ)为gamma函数,γ 取1.5。
通过分析FPA的授粉策略不难发现,配子在全局搜索中以全局最优解为目标,在追赶全局最优粒子的过程中,随着粒子逐步接近全局最优解,大部分粒子仍表现出明显的“趋同性”,使算法陷入局部最优,出现早熟。在局部搜索过程中,配子不参考全局最优解,仅将花粉群内两个任意个体的差分作为追赶目标,表现出明显的随机性、盲目性和不确定性,从而降低了全局最优解的更新速度。同时,切换概率p 在整个寻优过程中保持恒定,导致全局搜索在算法初期比例过小且后期比例过大,从而降低了算法的搜索效率。此外,由于FPA初始花粉配子位置随机选取,从而导致配子很难相对均匀的分布在解空间上,因此降低了FPA 搜索的效率。上述缺陷在一定程度上限制了FPA 的寻优精度和收敛速度。
混沌变量能够运用其特有的非线性规律在目标空间中遍历所有可行解。同时反向学习策略能够增加花粉配子的多样性,采用基于反向学习混沌映射对FPA算法的配子进行初始化,能使配子较为均匀的分布在解空间上并保持其配子的多样性,提高初始配子的分布质量。在FPA算法的全局搜索中,混沌搜索能够帮助FPA算法在整个解空间内搜索,避免全局搜索陷入局部最优。在局部搜索方面,通过定义α 算子,将搜索范围和算法迭代次数相联系,可使局部搜索范围随着迭代次数的增加而缩小,使算法更具针对性,同时,将切换概率p和算法迭代次数相联系,使算法在不同阶段能够动态的调整局部搜索和全局搜索的比例。进而提高FPA 算法的寻优精度和收敛速度。
3.2 花粉算法改进
3.2.1 改进的配子初始化
在FPA的配子初始化阶段,文本利用基于反向学习的Tent 混沌映射对配子群进行初始化。首先随机产生初始向量,并根据式(1)和式(2)生成混沌解序列。然后根据式(3)生成对应的反向解。最后计算全部解序列的适应度值,并将前N 个最优的解序列作为N 个花粉配子的初始位置。
3.2.2 改进的切换概率p
为使算法能够在不同阶段动态调整全局搜索和局部搜索的比例,本文将切换概率p 转化成迭代次数t 的函数,使局部搜索的比例随迭代次数的增加而指数增长,在算法初期,大规模使用全局搜索使算法在较为大的范围内寻优,帮助局部搜索确定最优所在区域;后期算法逐步接近全局最优解,因此逐渐增加局部搜索的比例,使算法在更为细化的区域内寻优,使算法更加具有针对性。同时定义系数ε(ε ∈[ ]0,1),ε 的大小决定了局部搜索比例的增长速度和上限,防止搜索后期全局搜索消失。相比于原始的搜索策略,改进后的搜索策略更好的平衡了全局搜索和局部搜索的关系,在整个算法运行过程中,两种不同方式的寻优策略相互促进,增加算法的寻优速度和精度。改进的切换概率p 为:

其中,t 为算法当前迭代次数,tmax为算法最大迭代次数。
3.2.3 改进的全局搜索策略
在FPA的全局搜索策略上,为避免大量配子过分聚集,增强FPA 算法跳出局部最优的能力,本文在原有全局搜索的基础上,通过变异策略将混沌搜索引入FPA的全局搜索策略,当前引入变异的方法有全局引入,概率引入和到达指定条件引入等。全局引入混沌策略是在每次迭代中将所有配子的有向搜索策略替换成无向混沌搜索,这虽然能使全局搜索在整个运行期间以较大范围寻优,但所有配子无目标的盲目更新会导致配子位置彼此重叠,并且对所有配子采用混沌搜索会消耗较长时间,这必然会降低FPA 全局搜索寻优效率和寻优精度,从而丧失FPA 原有全局搜索的优势。而小概率引入是在每次迭代中选取一小部分配子进行混沌搜索,使其在极大保留原有全局搜索优势的基础上增加了跳出局部最优的能力,相比于全局引入具有更高的效率和精度,能够更快、更准地确定最优解所在的局部区域,保障了算法后期大规模局部搜索(根据改进的切换概率p 可知算法后期局部搜索比例逐渐增大)精度和效率。因此,本文通过小概率变异形式在全局搜索策略中引入混沌搜索,改进的全局搜索流程图为。
3.2.4 改进的局部搜索策略
在FPA 的局部搜索策略上,文献[21]在原有局部搜索公式的基础上参考了全局最优解,但局部搜索范围不能够动态调整。本文在此基础上,引入自适应算子,使局部搜索的范围随迭代次数的增加而减小,增加局部搜索效率。改进的局部搜索策略为:
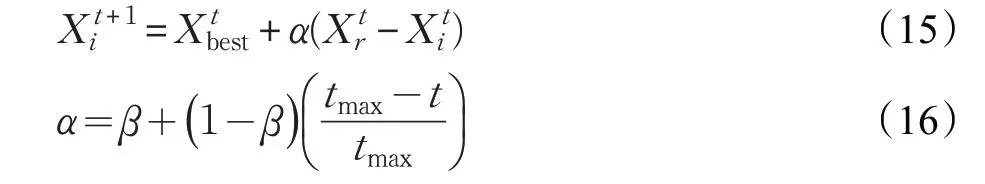
4 CS-ACFPA-MELM模型构建
鉴于FPA 算法相比于粒子群和遗传算法拥有更好的寻有能力,并且ACFPA 算法改善了FPA 易陷入局部最优解和收敛速度过慢的问题,因此,本文采用ACFPA算法优化MELM 的输入权值和阈值,并在ACFPA 算法的适应度函数引入代价敏感的思想。
4.1 基于CS的适应度函数
传统的MELM多分类算法采用0-1适用度函数,将模型输出的连续值转换成二进制离散值,虽然能在一定程度上评价模型的分类性能,但此过程会损失大量信息。针对上述问题并结合MELM 输出结构,本文提出一种基于代价敏感的适应度函数,在原有0-1 适应度函数的基础上,进一步参考每个输出节点的数值大小,提高ACFPA 算法对MELM 分类性能的评价能力,进而提高ACFPA-MELM的收敛速度。
MELM处理多分类问题时,将输出节点中最大值所对应的节点序号作为模型的预测结果,因此优化MELM的目标就是要尽可能的增大正确类别节点对应的输出值。传统的0-1适应度函数仅将所有样本中被正确分类的比例作为评价标准。为增强适应度函数对MELM模型的评价能力,本文根据每个样本下正确节点对应输出值占总输出值的比例计算样本被分到正确类别的概率,并使适应度函数和此概率成正相关。因此对于相同的分类结果,改进的适应度函能根据每个样本被正确分类的概率给予每个分类结果不同的分类代价,这将大大加快PSO、FPA 等优化算法对神经网络参数的优化速度,并且在一定程度上降低分类模型的误差。改进的适应度函数为:

式中,N 表示样本个数,k 表示样本类别数,p 表示迭代次数。outright表示每个样本分类结果中正确类别所对应输出的输出值,outj表示模型第j 个输出的输出值,rightj表示j 节点对应的真实值。
4.2 CS-ACFPA-MELM算法流程
步骤1 初始化FPA 相关参数,并随机生成一个d维的花粉配子,然后利用基于反向学习的混沌映射对花粉配子进行初始化。
步骤2 计算切换概率p,对于每一个配子而言,产生一个随机数e ∈(0,1)。如果e >p,则利用式(15)对该配子进行局部搜索;否则根据图1 进行全局搜索,更新配子位置信息。

图1 改进的FPA全局搜索流程图
步骤3 若Xid>Upper_Boundd(d 维上边界),则Xid=Upper_Boundd;若Xid<Low_Boundd(d 维下边界),则Xid=Low_Boundd。
步骤4 将当前配子位置的适应度函数值和此配子的历史最优位置的适应度函数值进行比较,若优于历史最优值,则将历史最优值更新为当前位置;否则直接进行下一步。
步骤5 将当前配子位置的适应度函数值和全局最优位置的适应度函数值进行比较,若优于全局最优值,则将全局最优值的位置更新为当前配子位置;否则直接进行下一步。
步骤6 对所有配子执行以上步骤。
步骤7 迭代以上步骤指定次数,输出全局最优位置。
5 仿真实验与结果分析
为验证ACFPA-MELM 模型在分类性能和运行效率上的优势,本文分别设计3组实验:(1)确定切换概率p 中参数ε 的最优值;(2)纵向对比MELM、FPA-MELM、CAFPA-MELM、CS-ACFPA-ELM模型在分类精度、迭代次数和运行时间上的差距;(3)横向对比CS-ACFPAELM、LS-SVM、CART模型在分类精度和结果一致性上的差距。
借鉴文献[22]的实验方案和数据集使用,采用10组UCI公共数据集进行实验,其中diabetes、credit-g、kr-vs-kp样本数量规模较大,10 个数据集的样本个数和特征个数如表1 所示。实验中操作系统为Windows7,CPU 为Intel Core i5-3230 主频2.60 GHz,内存为8 GB,编程语言为Python3.6。采用5×10重交叉验证和分层抽样的方法将数据集划分成5份,每次选取1份作为测试集,其余作为训练集,循环10次,计算10次精度均值作为模型最终精度结果。算法的运行时间为算法达到最优精度所消耗的时间。
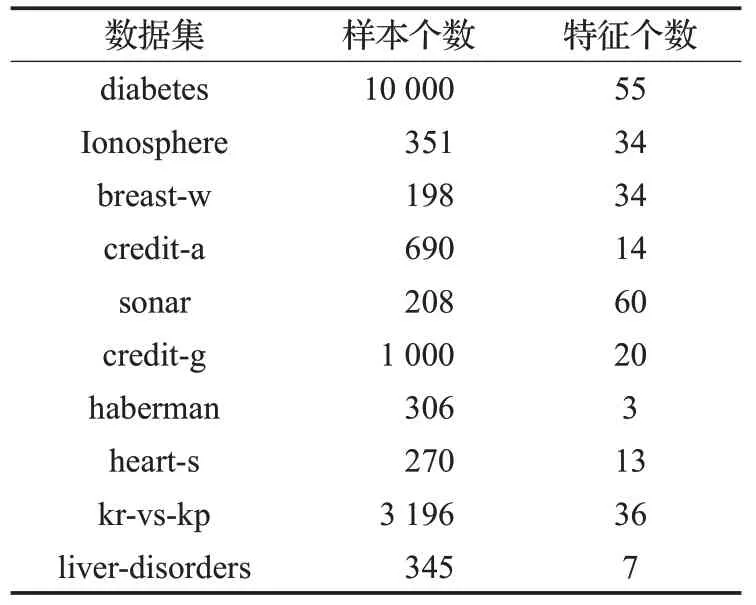
表1 所选用数据集的样本数和特征数
5.1 算法参数确定
5.1.1 参数ε 确定
采用穷举法,对比切换概率p 中参数ε 的不同取值时,CS-ACFPA-MELM模型的分类精度和运行时间。选取区间0.1~0.9,步长为0.1的9个值作为参数ε 的测试值带入到CS-ACFPA-MELM分类模型中,对每个样本分别进行9 次独立实验,每次实验迭代200 次。CS-ACFPAMELM在10个样本上精度随ε 值的变化如图2所示,运行时间随ε 值的变化如图3所示。

图2 ε取值不同时CS-ACFPA-MELM模型的分类精度对比

图3 在前3个数据集上ε 取值和运行时间的对比
由图2可知,10个分类样本中,在ε=0.8时,ACFPAMELM 分类模型均达到最高精度。由图3 可知,在ε=0.8 时,模型在前3个样本上达到最高精度所用的时间最短。因此结合上述数据可知,对于不同样本数量和不同特征数量的数据集,在ε=0.8 时均能达到模型的时间最优和精度最优,故在实验时将改进切换概率p 中的参数ε 定为0.8。
5.1.2 变异阈值确定
采用同5.1.1 小节相同的测试方法,选取0.1 到0.9的9个测试值代入CS-ACFPA-MELM模型中进行实验,在10 个数据集上的模型变异阈值与分类精度、模型运行时间的关系,如表2所示。
由表2 可知,当变异阈值取0.2 时,CS-ACFPAMELM 模型在10 个分类数据集均达到了最高分类精度,以此可知,对于不同规模样本数量、不同特征维度的分类数据集,变异阈值为0.2时CS-ACFPA-MELM模型达到最优,具有普遍适用性,因此在实验中将变异阈值定义为0.2。
5.2 CS-ACFPA-MELM模型纵向对比实验
对于FPA 算法,根据前文分析,将FPA 局部搜索中的参数β 定为0.1;根据5.1 节中的实验,将切换概率中的参数ε 定0.8,将全局搜索中的变异阈值定为0.2;根据文献[10]中的建议,将FPA 的γ 的值设定为0.1;将花粉配子个数定为20;为和MELM模型形成对照,在MELM模型外嵌套迭代机制,重复实验输出历史最优结果。
如图4是MELM、FPA-MELM、ACFPA-MELM、CSACFPA-MELM分类模型在10个数据集上的收敛曲线;如表3是MELM、FPA-MELM、ACFPA-ELM、CS-ACFPAMELM分类模型在10个数据集上的卡帕系数和运行时间。结合图表可知,嵌套迭代机制的MELM 模型由于自身的随机性,分类精度提升缓慢,并且都存在很高的迭代次数和运行时间。利用FPA算法优化MELM的初始输入权值和阈值,使MELM的迭代增加了方向性,大大加快了MELM 模型的分类精度、卡帕系数以及收敛速度。ACFPA算法在FPA算法的基础上进一步优化了FPA 的寻优策略,从而将FPA-MELM 模型的的分类精度和运行效率分别提高了1.3%和9.9%;此外,基于代价敏感的适应度函数更加细致地刻画了MELM模型的质量,从而将ACFPA-MELM模型的分类精度和效率提升了0.8%和8.7%;从卡帕系数的对比可知,FPA-MELM、ACFPA-ELM、CS-ACFPA-MELM 模型,分别将MELM模型的分类一致性逐步提高了1.63%、1.97%和2.30%,达到了模型预测值和真实值的高度一致性。以上数据验证了基于CS 适应度函数和ACFPA 算法对MELM 模型优化的有效性。
5.3 CS-ACFPA-MELM模型横向多尺度对比
为证明CS-ACFPA-MELM 分类模型的优势,实验对比LS-SVM、CART、CS-ACFPA-MELM 分类模型在10 个测试数据集上的分类精度和卡帕系数。如表4 是LS-SVM、CART、CS-ACFPA-MELM分类模型在10个数据集上卡帕系数和分类精度的对比。不同于LS-SVM模型和CART 模型从全局角度出发逐渐逼近全局最优解,CS-ACFPA-MELM模型能够从全局和局部两个角度入手逼近全局最优解,使算法具有跳出局部最优的能力,进而提高分类精度和收敛速度。
由表4 可知,CS-ACFPA-MELM 模型在diabetes、Ionosphere、breast-w、credit-a、credit-g、heart-s、kr-vs-kp这7数据集上的准确率和卡帕系数明显高于LS-SVM和CART两种经典分类模型。结合表1可知,上述7个数据集的样本数均值为2 244,而kr-vs-kp、credit-g、diabetes这3个数据集的样本数均值为286,远远低于前者,这表明CS-ACFPA-MELM分类模型在规模较大的样本上分类性能明显优于LS-SVM和CART;在sonar和liver-disorders数据集上,CS-ACFPA-MELM模型的分类精度和卡帕系数相比于比LS-SVM、CART模型优势较小,这表明随着样本数量的增加,CS-ACFPA-MELM模型训练效果更全面,CS-ACFPA-MELM模型的优势更加明显。上述结论验证了CS-ACFPA-MELM模型在大规模样本上的优势以及小样本上的适用性。
6 结束语
为提高MELM 模型的分类性能,本文采用花粉算法优化MELM 的输入权值和阈值,并通过分析FPA 算法的不足,在配子初始化和全局搜索中引入Tent混沌策略,在局部搜索和切换概率p 中引入自适应算子,并且将代价敏感的思想引入适应度函数之中。对比实验表明,改进的花粉算法对MELM 模型分类精度和的收敛速度均有较大提升。

表2 变异阈值取不同值时CS-ACFPA-MELM模型在10个数据集上的分类精度

图4 MELM、FPA-MELM、ACFPA-ELM、CS-ACFPA-MELM在不同数据集下的收敛曲线

表3 4种模型在不同数据集的卡帕系数和运行时间对比

表4 LS-SVM,CART,CS-ACFPA-ELM在不同数据集的卡帕系数和分类精度对比
在今后的工作中,将会增加测试数据集的种类和数量,进而对CS-ACFPA-MELM 模型的适用样本类型进行更深入的研究。
猜你喜欢
计算机仿真(2022年8期)2022-09-28
数学物理学报(2022年4期)2022-08-22
数学物理学报(2022年2期)2022-04-26
生物学通报(2021年11期)2021-09-28
金桥(2018年4期)2018-09-26
郑州大学学报(工学版)(2018年2期)2018-04-13
中国塑料(2016年11期)2016-04-16
中国组织化学与细胞化学杂志(2016年3期)2016-02-27
中国医药导报(2015年26期)2015-02-28
中国卫生(2014年5期)2014-11-10
