
基于深度学习的点云分割方法综述
2020-01-06 02:07刘延华
计算机工程与应用 2020年1期
俞 斌,董 晨,3,刘延华,程 烨
1.福州大学 数学与计算机科学学院,福州350116
2.福州大学 福建省网络计算与智能信息处理重点实验室,福州350116
3.福州大学 网络系统信息安全福建省高校重点实验室,福州350116
1 引言
点云分割,即对点云中的每个点赋予有意义的标注,标注代表可以是任何具有特定意义的信息。在实际应用中,通常是一组代表几种特定类别标签的一个。如果标签具有特定含义,如是一个场景的物体类别,那么这个过程就是一个场景的分割或称语义理解。机器学习技术的进步也使得三维数据理解受益匪浅,尤其是对密集点云这样的大量数据。一些基于人工提取特征的经典机器学习方法,如支持向量机(SVM)和随机森林(RF),也在一系列三维模型检测与分割任务中取得了较为成功的结果[1-2]。近年来,从机器人导航到国家级遥感技术,对算法实时性和鲁棒性的要求也越来越高。以自动驾驶为例,若汽车采集的图像以及点云数据需要等待漫长的手工提取特征,再进行场景分析,显然是不可行的。于是,越来越多的研究开始转向深度学习[3]。深度学习相比其他机器学习算法有着独特的优势。
(1)特征学习(Representation Learning):原本需要人工提取的特征可作为训练过程的一部分进行学习。
(2)端到端(End-to-End):设备采集的原始输入数据可以直接输入到学习算法中,而后算法自动导出检测或分类所需的输出形式。
深度学习在二维图像分类分割上取得了许多成功,并且已经有许多相当成熟的算法。基于深度学习的点云分割算法起源于二维图像算法,但在发展过程中也表现出其独有的特点和趋势。本文首先对该领域传统方法作简要评述,然后为了方便对比和梳理,对该技术近四年来在点云分割问题上的最新工作,按基本思想分为基于二维图像处理、基于体素和三维卷积的方法、无序点云的方法、空间卷积的方法、点云组织的方法以及无监督学习的方法。分析了这些算法的优劣及应用并简要评述,最后展望了未来研究趋势。
2 基于人工特征和机器学习的方法
在机器学习中,为了实现每个预测数据的自动标注,通常会选择监督学习方法进行模型训练。传统的基于机器学习的点云分割方法,通常采用典型的监督学习算法包括支持向量机(SVM)、随机森林(RF)和朴素贝叶斯。由于仅考虑点云中的单个点是不能获得有意义的信息,因此这些方法还依赖于一系列称为特征描述符(Signature)或描述子的人工特征。常见的点云的描述子可以大致分为统计特征和几何特征。
(1)统计特征通常会选取固定邻域内点云的数量、密度、体积、标准差等,其中比较具有代表性的有:快速点特征直方图(Fast Point Feature Histograms,FPFH)[4]、方向直方图(Signature of Histograms of OrienTations,SHOT)[5]等。
(2)几何特征通常将局部领域内的点云描述为线、面或者几何形状,其中比较典型的有自旋图像(Spin Image)[6]、局部表面切片(Local Surface Patches)[7]、固有形态(Intrinsic Shape)[8]等。
为了从大量点云中找到这些领域特征,通常需要一定的加速算法。此外,这些特征对点云密度具有一定的耦合性。虽然最近的一些研究工作[9-12],在一定程度上解决了这些问题,并可以实现90%左右的分类精度。但是,这些方法都是在一定小范围内进行测试和验证,缺乏泛化和扩展能力,并且,这些方法对大范围场景下出现物体被遮挡或者重叠通常表现不佳。最重要的,手工提取特征耗费的时间是实时性应用所不能接受的。
3 基于深度学习的方法
深度学习自诞生以来,在许多领域产生了突破性的进展,在点云分割上也不例外,其发展的总体趋势是从二维到三维,从转换数据到直接处理。由于思路来源的不同,出现了几种发展方向,本文按照基本思想的分为了五类。
3.1 基于投影和视图的方法
为了能利用基于CNN 的网络架构,通过变换将点云光栅化为2.5D结构化图像阵列,或者按照球面、柱面将三维坐标投影到二维平面上。这样不仅可以避免复杂的3D 处理,还能利用成熟的图像处理技术和海量的二维图像数据集进行模型预训练。
早期在地理信息科学中,就有将ALS 点云数据光栅化为二维图像的做法[13-14]。而Su 等人提出了多视图CNN[15]后,视图投影方法就开始广泛应用。最近,Qin等人提出了一种多视图的对ALS 点云进行地形分类的方法[16]。所提出的网络架构TLFnet,是第一个将多视图CNN应用于大规模ALS点云分割的一种通用架构。
近年来,随着诸如Microsoft Kinect R 这样的低成本RGB-D 传感器的广泛应用,越来越多研究倾向于针对RGB-D图像的设计网络架构[17]。虽然RGB-D图像与点云是不同类型的三维数据,但Boulch 等人提出的SnapNet网络架构[18]打破了两者之间的鸿沟。该方法生成的快照除了常规的RGB 图像外,还有包含点云提供的几何特征的融合图像。实验测试了不同的组合,包括SegNet[19]/random、U-Net[20]/multiscale,以寻找有利的融合。该方法经多场景的实验证明有着十分广泛的应用范围。
基于CNN 的网络架构的能力不仅限于处理图像,任何具备局部特征性的二维张量矩阵都可以。最近,Wu 等人提出了SqueezeSeg[21]以及SqueezeSegV2[22]用于自动驾驶MLS点云数据的道路对象分割。该方法通过二维球面投影,将点云坐标、强度和范围转换为一个64×512×5 的张量,并用条件随机场(CRF)产生每点的分类标签。针对合成数据缺少噪声和强度信息的问题,加入域适应训练管线(Domain Adaptation Training Pipeline)来自主学习强度信息并进行相关的校准,将合成数据训练的模型的测试精度提高了28.4%。改进后的网络架构还采用了新的损失函数Focal Loss[23]和批归一化(Batch Normalization)[24]。
基于投影和视图的方法虽然会损失维度信息,在准确度上也并非先驱者,但有赖于二维深度学习算法的成熟,可用于许多小型和特定的场景,具有实用性强的优势。为直观展现近年来该类方法的发展态势和应用情况,表1列举了近年来的一些方法以供研究者参考[25-34]。

表1 几种基于投影和视图的方法
3.2 基于体素的方法
最早的深度体素网络是Maturana和Scherer提出了VoxNet 网络架构[35]。通过将点云按0.1 m2的分辨率采样后,形成大小为32×32×32的体积网格,再将输入数据在[-1,1]之间归一化。数据输入一个简单的包含两个卷积层,一个池化层和两个完全连接的层的Volumetric CNN网络,最后输出简单的分类标签,实验仅在简单分类任务进行了测试,但提出三维卷积是开创性的突破,将此概念由二维空间推向三维空间。
基于二维全卷积网络(FCN)思路,Tchapmi 等人提出了一种三维的全卷积网络架构SEGCloud[36]。该方法首先对3D 点云进行体素化并通过3D 全卷积神经网络进行馈送,以生成粗略的降采样标签。然后通过三线性插值层将这种粗略输出从体素解析为原始3D 点表示。过程中得到的3D 点分数可用于3D 全连接CRF 中的推断,以产生最终结果。该方法提出了一种3D-FCN 架构,并在公开的两个室内数据集和两个室外数据集上取得了不错的结果,证明了三维空间也是可以构造全卷积网络的。
环顾最近的计算机视觉的国际会议,该类方法已逐渐减少,综合分析有以下原因:
(1)三维卷积的运算过程较复杂,需较大算力,因此对研究者的设备要求较高。
(2)算法的空间复杂度高,运算和存储中间过程均需较大开销,因此实用性相对较低。
(3)体素大小不易确定,需要根据实际实验情况调整,不合适的体素大小会产生许多冗余体素网格,优化问题较难解决。
但实际上,体素方法在点云处理的历史上具有相当久的历史,所以该类方法还是具有一定潜在发展空间的。三维卷积处理三维空间信息,对每个维度信息特征都能很好的保留,流程上也更加自然。为直观展示深度体素方法的发展历史,表2中列举了近几年国内外研究者提出几种典型方法[37-41]。其中,由国内学者提出的MSNet,在遥感领域取得不错的成绩,所以,该类方法的研究和改进还是有可能随着计算性能和存储方法的变革,以某种新的形式再度流行起来的。
3.3 无序点云的方法
无序点云的方法,在很多文献中也称为点方法。其特点是直接输入原始数据,输入网络之前不对点云数据做任何变换。这也符合基于深度学习的端到端架构的思想,同时基于点的方法也是现在点云分割的主流发展方向。
最早直接输入点云数据进行特征学习的网络是在CVPR2017 上提出的PointNet[42]。与其他架构不同,PointNet 不使用卷积提取特征仅由全连接层组成。网络解决了点云无序性、几何旋转的问题,实验结果也表明其性能相当可观。虽然是是突破性的进展,但尚有许多问题,比如对局部空间特征的感知较差。由2D-CNN获取灵感,Qi等人又提出了PointNet++[43],网络由PointNet 构成的特征提取块组成,并采用了MSG、MRG 以及特征传播改进网络架构,输入沿着多分辨率层次以逐渐变大的比例捕获特征。虽然在一些数据集上的结果提高不是很多,但是也提高了架构对于稀疏点的鲁棒性。
自PointNet++提出之后,针对直接输入点的研究大量涌现。由于PointNet对点云的顺序不予考虑,所以需要适配点云的变换一致性,空间复杂度较高。针对此问题,许多研究采用基于聚类和传统特征提取相关的算法改进PointNet 的层次结构或者其T-Net 结构,来降低近邻点搜索和组织的空间复杂度。直接输入无序点云的方法虽然省去了组织和排序所带来的时间成本,但仍需要消除顺序的影响后,并且不考虑顺序可能造成潜在特征信息的丢失,因此也产生了对点云组织的点方法的研究。

表2 几种典型的基于体素的方法
3.4 有序点云的方法
最早对点云进行有序化处理的一个最突出的例子是OctNet[44]。该方法将点云数据存储在浅八叉树中并加以索引,卷积运算符是直接在树的结构上定义的,能够处理非定长数据。类似的,通过使用KD树结构索引点云,Klokov等人提出了一种直接在KD树上构造的称为KD-Network 的深度网络[45]。与CNN 一样,网络是前馈但可学习与KD 树中节点的权重相关联的参数。网络还展示了训练和推理的效率以及可扩展性。
虽然高效组织点云被证明有效,但需要额外的数据处理步骤,所以在端到端处理上是存在劣势的。Su 等人提出的一种网络架构SplatNet[46]很好地解决了这个问题。其灵感来自permutohedral 网格[47],通过Bilateral Convolution Layer(BCL)卷积层结构堆叠构造起整个网络,把对点云的组织放到了每一次卷积操作中,实现了端到端的处理。
而针对分割任务并不受点云顺序影响的观点,Landrieu和Simonovsky提出了一种基于图的方法很好地反驳了这点,网络采用了一种称为超点图(Superpoint Graphs,SPG)[48]的新型数据结构中。该结构包含一组称为超级点(Superpoint)的形状单元,其灵感来源于超像素点(Super Pixel)[49]。文章认为,通过将数据组织为SPG,并使用边缘条件卷积[50]有助于分类和分割。网络不仅在小型模型分割上表现良好,在大规模场景分割上也毫不逊色。最近,CVPR2019 的一篇匿名论文[51]提出了一种采用图注意力卷积(Graph Attention Convolution,GAC)的方法。其引入注意力机制组织搜索点云,使网络具有强大的结构化特征学习能力,对室外场景中易遮挡和残缺的对象(例如汽车、硬景观、低/高植被)的特征的区分度有较大提升。但是对于点数量较多、较密集并容易混淆的人工和自然地形,权重分配不能很好发挥作用,因此场景总体识别能力提升不大。
点方法在近两年来发展迅速,并不断将原有深度学习算法扩展泛化以适应点云运算。为直观展现点方法的发展情况,表3列举了近年来一些其他的点方法的优缺点以供研究者参考[52-63]。
3.5 无监督学习的方法
无监督学习是目前深度学习发展的一个新趋势。一方面,无监督学习利用了自编码器的特性,能实现一种类型到另一种类型的跨越式生成;另一方面,无监督学习不需要利用数据的标注,可以利用大量无标注数据。
目前无监督方法还较少,适应范围也较小,但也初具雏形,如Achlioptas 等人提出的一种可以用于模型重建的方法[64]。该方法直接将PointNet重构为一个带有解码器网络的自编码器。其实验表明,对于模型重建有着非常好的结果。Li等人提出了SO-Net网络[65],使用自组织映射输入并组织点云,并在各个自组织图节点上执行分层特征提取。网络采用可调节的视野域,可根据局部几何形状进行调整,以实现更有效的局部特征聚合。Zamorski等人将变分自编码器(Variational Auto-Encoder,VAE)泛化为对抗自编码器(Adversarial Auto-Encoder,AAE),提出了一种3DAAE网络架构[66]。这是一个完全端到端的结构,学习点云空间表示的同时并依据学习到的特征生成3D模型。该方法也展现了无监督自动生成CAD等三维模型的可行性和广阔的前景。
4 数据集与评估方法
基准数据集对于深度学习领域的作用不言而喻,经过多年研究,也产生了许多优秀的室内和室外场景数据集。表4 选取了几个在最近研究中较为常用数据集以展示算法在室内场景分割,模型分割以及室外场景分割的性能,选取的数据集有:斯坦福大学的S3DIS[67]、普林斯顿大学的ShapeNet[37]以及苏黎世联邦理工学院的Semantic 3D[38]。因为有些算法的实验和评估过程有其侧重性,并非所有算法这些数据集的指标上给出数据,或只给出部分数据。选取的评估指标为在大多数文献中都采取的几个指标:S3DIS和Semantic3D的语义分割的总体准确度(OA)和平均交并比(mIOU),以及在ShapeNet 模型分类(Class.)和语义分割(Seg.)上的平均准确度(mAcc,相当于mIoU)。部分文献仅给出mIoU或者仅给出OA的情况下,本文尽可能通过给出的数据计算补全数据,但如未给出每类准确度的情况下,mIoU是无法计算的。表中分类1~5分别对应文章第3章中的5个小节的方法类别,数据旨在展示算法的性能,供相关研究者参考分析。

表3 几种点方法的优缺点比较
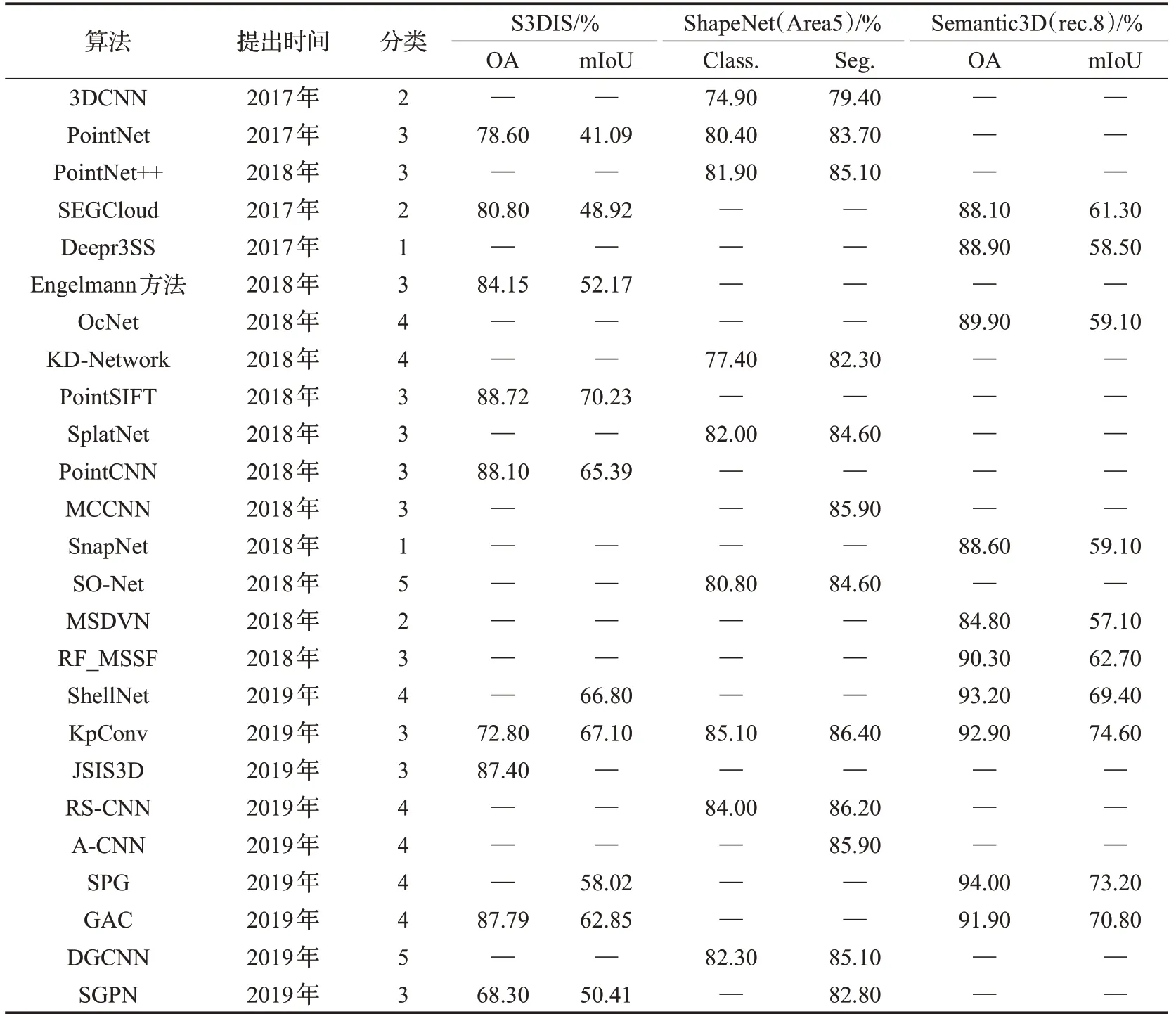
表4 一些算法在选取的数据集的表现
5 结束语
本文对基于深度学习点云分割方法进行了整理、分类和简要分析。3D深度学习虽然是一个相对较新的领域,也不像2D深度学习那么成熟,但就目前研究现状来说,差距正在逐渐缩小。通过对相关技术和算法的总结分析,提出以下几个观点:
(1)深度学习端到端的架构能将原始数据直接输入到学习算法中,并将特征作为训练过程的一部分进行学习后自动导出检测或分类所需的输出,能很好地满足实时性和鲁棒性的要求。基于深度学习的点云分割算法,免去了繁琐的手工提取特征的过程,强化了传统算法泛化和扩展能力,为自动驾驶、机器人和无人机导航等一系列新兴应用的自动化提供了可能。
(2)无论是投影和视图的方法还是最新的无监督方法,都有着最先进的结果,表5 简要分析并总结了目前各类方法的优劣。虽然三维卷积在计算和存储开销上较大,但是最新进展仍显示有能力超越同时期的点方法;投影和视图的方法在一些简单场景具有极其强的实用性,丢失空间信息的影响也就显得不那么重要。总的来说,各类方法都有自身的优劣,孰优孰劣不能简单一刀切。
(3)虽然无序点方法是近年来的主流,但最近的一些工作显示,该类方法正在融合有序点方法和一些数学方法。点云虽然是无序的,但是点云表示的场景或者物体却是有几何上下文关系的,所以不能忽视拓扑学的重要性。并且在最近的工作中,有序点法也显示了极其强大的分割能力和最先进的成绩。而对于深度学习技术的发展,几何学、拓扑学以及数学方法也是相当重要的,最近有研究开始对深度网络和微分方程的联系进行探究,并得出了一些有意义的结论。这也表明通过数学的规范公理化语言描述,能增强深度学习的方法的理论性、确定性和可复现性。
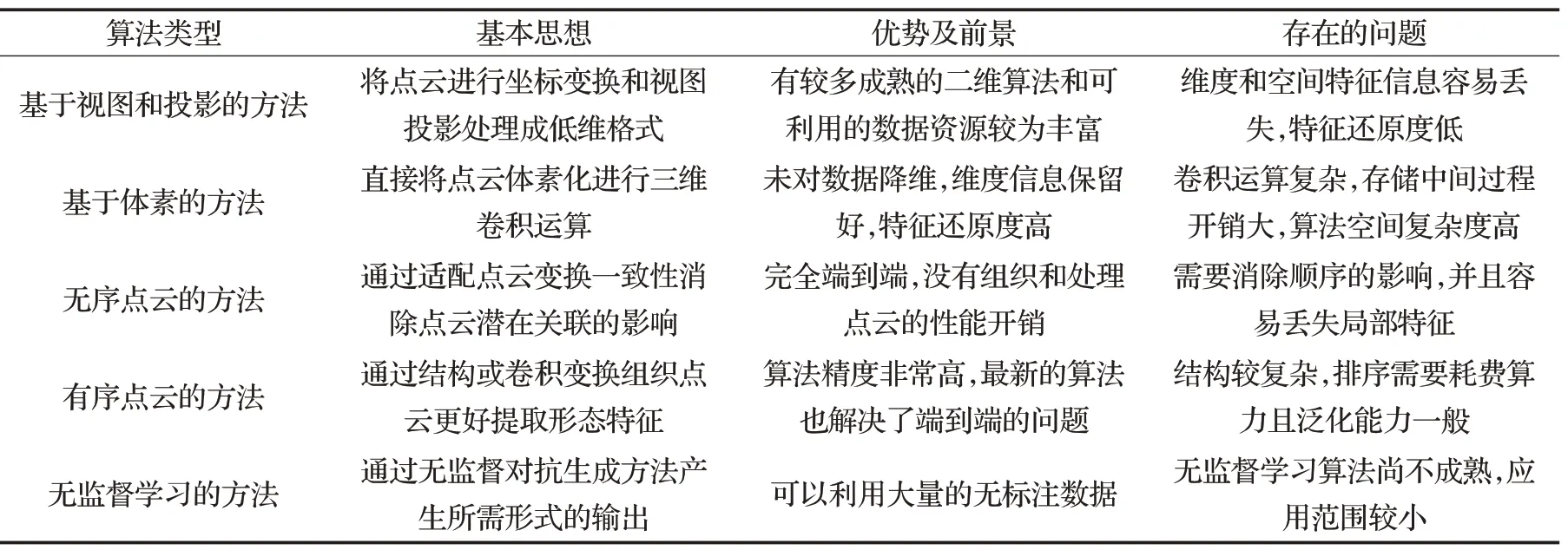
表5 各类算法优缺点分析
(4)无监督学习是深度学习技术甚至是机器学习领域的一个发展趋势,虽然现有的技术不那么成熟,但在当前大数据的背景下,利用无标注数据所带来的效益是极大的。因为三维数据的标注相比二维数据,其不仅是时间成本上的升维,还对操作人员的技能素质有极大的要求。此外,即便是专业人员,为正确标注数据,所要付出的耐心和细心也更大。
(5)虽然目前已经有S3DIS、KITTI甚至Semantic3D这样的规模较大的数据集,但与ImageNet 的规模相比仍是沧海一粟。无论是在监督学习还是主流的今天,还是无监督学习可能主导的未来,标注数据仍然是非常重要的。最近的SqueezeSeg、SythCity[68]提供了人工合成数据以及在虚拟环境采集数据的思路。这或许不失为补充预训练数据集的方法,但仍需考虑解决域迁移的问题,更进一步,研究如何合成逼真的仿真数据。
猜你喜欢
成都信息工程大学学报(2022年4期)2022-11-18
家庭医学(2022年3期)2022-04-07
汽车工程(2021年12期)2021-03-08
计算机集成制造系统(2020年4期)2020-05-08
时代人物(2019年27期)2019-10-23
中国惯性技术学报(2019年1期)2019-05-21
中学生数理化·中考版(2017年6期)2017-11-09
非公有制企业党建(2017年10期)2017-11-03
计算机测量与控制(2017年6期)2017-07-01
现代兵器(2017年4期)2017-06-02
