
基于协处理器的HBase内存索引机制的研究
2020-01-06 02:11:14朱松杰娄渊胜
计算机工程与应用 2020年1期
朱松杰,娄渊胜,叶 枫,,李 凌,陈 勇
1.河海大学 计算机与信息学院,南京211100
2.南京龙渊微电子科技有限公司 博后工作站,南京211106
1 引言
随着大数据时代的到来,传统的关系型数据库难以处理无规范模式的数据集,并且随着数据集规模的增大,不能提供高效的存储和查询服务,也不能满足系统的新需求。互联网先驱不得不重新设计数据库,大数据系统和NoSQL(Not-Only-SQL即非关系型数据库)越来越多地被开发出来,例如Facebook的Cassandra、Amazon的Dynamo 以及支持高效数据查询的内存数据存储系统Redis等[1]。这些数据库的数据存储都采用了key-value数据模型,HBase 便是key-value 数据库中使用最为广泛的[2]。
在Google 的BigTable 论文的发表后,Cafarella 在Hadoop 上面实现了BigTable 的一个开源版本,被称为HBase[3]。HBase由多个软件子系统组成,主要包括客户端、HMaster、HRegionServer、Zookeeper 等,这些子系统共同组成一个分布式应用系统,它具有开源、分布式、可扩展及面向列存储的特点,能够为大数据提供随机、实时的读写访问功能。如何从海量数据中快速获得所需数据是使用HBase 等NoSQL 数据库的一个重要原因,HBase在其主键上建立了B+树索引,在使用主键进行查询时效率很高[4]。但是,在进行非主键的条件查询时,由于缺少主键的支撑,HBase 必须进行全表扫描,导致查询效率低下,无法满足上述要求。对此,本文在借鉴关系型数据库解决方案的基础上,提出了一种基于二级索引的查询机制,并将索引数据存储在内存数据库中,通过内存进行二级索引检索,进一步提高了对大数据的实时查询响应。
2 相关工作
HBase 是一个构建在HDFS 之上,用于海量数据存储分布式列存储系统[5]。HBase 表的每行都是按照RowKey 的字典序排序存储,每行数据是按照RowKey区间进行分割存储成多个Region。HBase 只针对行健的索引,在原生产品中访问HBase表中的行只能通过行健访问,行健区间访问和全表扫描三种。
当前,国内许多使用HBase的企业或者个人都会对其建立索引来提高性能,比较常见的有基于Coprocessor方案,如华为的HIndex方案和Apache Phoenix方案[6]。其支持自定义数据处理逻辑,采用数据“双写”(dual-write)策略,在有数据写入时同时同步到二级索引表。相比于华为的HIndex,Apache Phoenix 的版本迭代情况较好,支持和兼容多个HBase版本,二级索引只是其中一块功能[6]。同时,二级索引的创建和管理直接有SQL语法的支持,使用简单。王文贤等人[7]实现了一种基于Solr 的HBase海量数据二级索引方案,该方案主要对华为Hindex进行改进,其基于数据存储和索引分离的思想,将Solr 检索与HBase 的大数据存储结合起来,具有一定的通用性。丁飞等人[4]实现了基于协处理器的HBase区域级服务端区域级第二索引扩展功能,索引存储格式选HBase自身的数据组织方式,即HFile文件格式。利用HFile高效的IO性能保证索引查询的效率。周伟等人[8]对HBase分布式二级索引通用方案进行研究,引入分布式索引机制,在SolrCloud中完成对索引的管理,借助协处理器提供的索引功能为HBase记录创建、存储索引,其中HBase负责存储数据,Solr负责索引数据和检索。
许多研究者已经使用Coprocessor 来构建HBase 二级索引,具体有两种解决方案:一种是直接存储到数据库或文件中实现索引持久化,但这种方法的索引检索效率较低,另一种是通过构建内存索引,并存储到特定环境中实现持久化。从开发设计的角度看,把很多对二级索引管理的细节都封装在的Coprocessor具体实现类里面,这些细节对外面读写的人是无感知的,简化了数据访问者的使用。虽然具有一定的入侵性,会对Region-Server性能产生一定影响。
对于非Coprocessor方案,不基于Coprocessor开发,而是自行在外部构建和维护索引关系。常见的是采用底层基于Apache Lucene 的Elasticsearch[9],来构建强大的索引能力、搜索能力,例如支持模糊查询、全文检索、组合查询、排序等。LilyHBase Indexer(也简称HBase Indexer)是国外的NGDATA公司开源的基于solr的索引构建工具,特色是其基于HBase 的备份机制,开发了一个叫SEP工具,通过监控HBase的WAL日志(Put/Delete操作),来触发对solr 集群索引的异步更新,基本对HBase无侵入性[10]。葛微等人[3]提出了名为HiBase的二级索引,它是一种基于分层式索引的设计方案,其将热点索引进行缓存,并建立高效的缓存替换策略来提高二级索引的查询速度。Zou 等提出了互补聚簇式索引(Complemental Clustering Index,CCIndex),该方案把数据的详细信息也存放在索引表中,不需要通过获取的行键再到原表中去查找数据。使用非Coprocessor方案时,如存储开销比较大,尤其是当索引列比较多的时候,空间开销会更大。索引更新代价比较高,会影响系统的吞吐量,索引创建以后,不能够动态增加或修改。
综上,本文使用基于观察者模式的Coprocessor 方法实现二级索引功能,并通过分布式存储保证二级索引的高可用和高容错性。提出了基于Coprocessor的索引构建方案,并且针对协处理器索引检索速度问题,构建了内存索引,意图是提高索引检索速度。
3 所提出的索引机制
所提机制的总体结构如图1所示。其中,索引管理模块是框架核心,在用户对数据表进行更新操作时,协处理器Coprocessor 会对这些请求进行拦截,并对索引表进行相应操作,包括插入、删除和更新索引的元数据(记录用户表对应的索引表名称、索引列等信息)。执行查询操作时,系统会在缓存中寻找对应索引位置,提高了索引检索速度,当缓存中的索引更新时,索引管理模块也会对索引进行更新。索引持久化管理模块主要对缓存索引进行持久化操作,提供索引表和值表的持久化存储,HBase为持久化存储数据提供可扩展性和容错性。

图1 系统总体结构图
3.1 Coprocessor基本概念
由于HBase无法定制服务端逻辑,使得用户无法在服务端实现自己需求的二级索引方案,HBase在0.92版本中引入了协处理器Coprocessor 机制,它受启发于Google 的Bigtable 的协处理器,为实现建立二次索引、复杂过滤器(谓词下推)以及访问控制等提供了一种很好的解决方案[11]。协处理器是一种服务端组件,类似于轻量级的MapReduce,它的主要思想是通过将集群内的数据移动取代为计算移动来减少计算代价,提高效率。其可理解为服务端的拦截器,可根据需求确定拦截点,再重写这些拦截点对应的方法。协处理器允许在Region服务器上运行自己的代码,更准确地说是允许用户执行Region级的操作,并且可以使用与RDBMS中触发器(trigger)类似的功能。
Coprocessor可以分为两大类:Observer Coprocessors(观察者)和EndPoint Coprocessor(终端)。Observer Coprocessor在一个特定的事件发生前或发生后触发,其工作过程如图2所示。

图2 协处理器工作过程
Observer Coprocessor使用场景如下。
(1)安全性:在执行Get 或Put 操作前,通过preGet或prePut方法检查是否允许该操作。
(2)引用完整性约束:HBase 并不直接支持关系型数据库中的引用完整性约束概念,即通常所说的外键。但是,可以使用Coprocessor增强这种约束。
(3)二级索引:可以使用Coprocessor 来维持一个二级索引。
Endpoint协处理器类似传统数据库中的存储过程,客户端可以调用这些Endpoint协处理器执行一段Server端代码,并将Server 端代码的结果返回给客户端进一步处理[12]。利用Coprocessor,用户可以将代码部署到HBase Server 端,HBase 将利用底层cluster 的多个节点并发执行。Endpoint 不仅能与客户端通信,而且能与Observer 进行通信。Observer 可以在回调方法里通知Endpoint,执行一定的事件响应逻辑。两种处理器的共同协作可以定制功能强大的HBase应用,既可以实现对集群中每个Region数据变更的监控,又可以通过Endpoint将处理结果返回给客户端。
3.2 Coprocessor二级索引实现
协处理器机制支持用户根据业务要求,重写Endpoint和Observer代码,本文使用Observer协处理器来进行索引的构建。Observer 协处理器类似于关系型数据库中的触发器,当对数据库进行增删改查操作时,Observer会对这些请求进行拦截,并根据这些请求,实时更新索引表。二级索引的整体架构图如图3所示。

图3 二级索引架构图
建立的索引结构如图3 所示,采用了倒排的方法,将数据表的值与主键进行交换,原本的值充当主键,原本的主键放在值的位置,一个最基本的索引表即构建完毕。在未建立索引前,HBase的数据模型可形式化表示为:
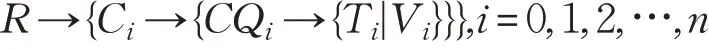
其中行健为R,列族为C ,列限定符为CQ,时间戳为T ,值为V 。则二级索引的形式化表示为:Vi→{Ci→{CQi→{Ti|R}}},i=0,1,2,…,n。
框架保证了索引文件和主表在同一个Regionserver上,这样可以保证在需要使用索引文件时只需与Region-Server建立一次连接就可以完成,提高了速度。在此架构中,用户首先在配置文件(hbase-site.xml)中设定索引的细节,主服务器从配置文件中获取需要建立的索引信息,然后在对应的RegionServer中的IndexingCoprocessor中建立索引同时管理二级索引数据。每个节点上都部署了协处理器Coprocessor,部署之后RegionServer端中的每个区域Region 上都会自动创建一个区域协处理RegionCoprocessorHost实例,它的主要功能是用来维护系统级或表级的区域观察者协处理RegionObserver。每当RegionObserver启动时会将RegionCoprocessorHost初始化,初始化的过程中,RegionCoprocessorHost 会加载当前服务端所有的RegionObserver。索引管理由扩展的RegionObserver 实例(IndexRegionObserver)完成。IndexRegionObserver主要的扩展接口如表1所示。

表1 IndexRegionObserver主要扩展接口
下面以Put拦截器举例说明索引表的更新过程:
如图4所示,在数据表进行Put操作时,数据表会监测插入数据的Rowkey,并由此定位到RegionServer 上的Region,该事件在Put 操作之前被CoprocessorHost拦截,并自动调用此Region 上进行监听的Observer 的prePut 方法。用户可以根据自己的需求对这个方法重写,更新索引。在索引更新完成后,即Put方法执行完成后,Put之后的事件会再次被CoprocessorHost拦截,并调用监听器Observer 的postPut 方法,同样,该方法支持用户的重写,以实现在Put 操作完成后的索引逻辑。由此可以看出,在Put操作未完成时,监听器将监听到这一事件,从而不会调用postPut 方法,索引逻辑将无法完成,保证了索引与原数据表的一致性与事件性,不会出现索引与原数据表无法匹配的情况。

图4 索引表更新过程
索引的使用:在构建完索引表后,当进行索引查询时,客户端需要进行Scan操作,此操作将会被协处理器拦截,将检索条件截取,并从索引表中找出符合条件的索引项,返回原数据表的Rowkey,数据表根据Rowkey查询即可。
3.3 内存索引构建
Coprocessor 构建的索引只是在逻辑上实现了索引结构,为了提高检索Coprocessor 索引速度,需要对Coprocessor 构建的索引进行特定结构设计,内存索引设计即可完成上述目标。内存的索引相较于传统位于磁盘的索引在设计和架构上都大不相同,基于内存的索引在查询效率上得到了极大提升。广泛采用的内存索引有T 树、基于缓存敏感的CSS/CSB+树和改进的Hash 索引等[13]。使用了HT 树构建内存索引,其结构如图5所示。
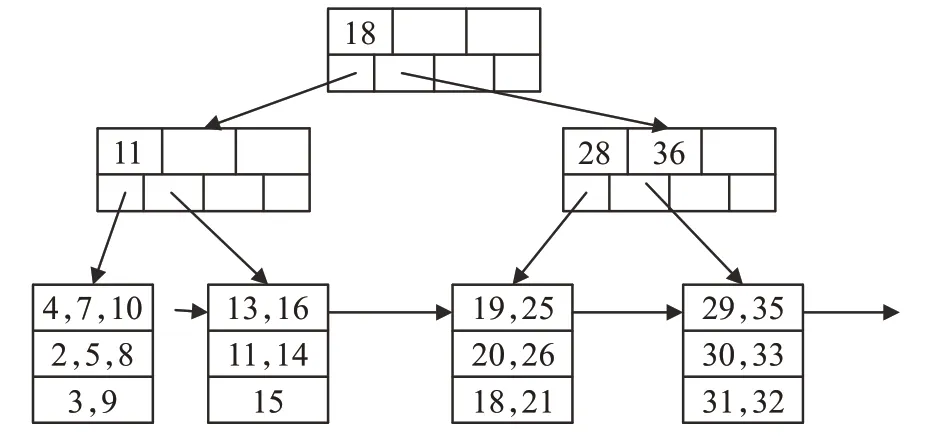
图5 HT树的结构
如图5所示,每个叶子节点有4个哈希表,每个哈希表中有3个哈希桶,在使用HT构建内存索引时,需要通过查找算法查找到关键字可以插入的哈希表,然后通过计算,找到关键字可插入的哈希桶,判断哈希桶是否已满,若已满则分裂该节点,将该关键字插入,若未满则直接插入哈希桶。
内存索引工作流程与一般索引的使用过程有所不同,具体流程如下:
(1)内存索引初始化
当向数据表的构建过程中,需要同步进行内存索引的建立,对外提供检索服务。在第一次请求索引检索时,系统会检查内存索引是否为空,如果为空,则进行索引的初始化操作,建立内存索引。
(2)Put操作过程
Put 操作在HBase 中相当于插入操作,当HBase 执行这个操作时,当前操作发生的Region上的Observer会拦截这个事件,向内存索引中插入一条对应的索引项。
(3)Delete操作过程
和Put 操作相似,当客户端执行Delete 操作时,HBase将从表中删除一条记录,当前操作发生的Region上的Observer会拦截这个事件,在内存索引中删除一条对应的索引项。
(4)查询操作过程
该机制中,为了提高查询效率,尽量将数据处理过程本地化。在协处理器拦截到查询请求后,将会构建检索条件,根据条件在内存索引中进行多线程检索。得到满足检索条件的Rowkey 后,返回数据表中查询原始数据,将结果返回客户端。在内存中检索的过程如下:
在进行内存索引查询时,首先在哈希表中进行查找,定位关键字所在桶,继续在桶中查找,若找到,则指针指向所需记录。当关键字处于内部节点,且它的键为K1,K2,…,Kn。如果key <K1,则为第一个子节点;如果K1≤key <K2,则为第二个子节点。依此类推,在该子节点上递归运用查找过程。对于范围查询,在实际情况下使用频率较高,下面给出算法进行说明。
算法1 内存索引查找算法
输入 查询范围[ks,ke]的关键字ks,ke。输出 行键集合RQ。
RQ ←[∅]// 结果集合设为空
Hs←T .Get Hash(ks)//通过树形索引查找ks所在的哈希表
He←T .Get Hash(ke)
H ←Hs
while next[H]≠Hsdo
H ←next[H]
RQ ∪all Value[H] //将哈希表中所有值并入结果集合中
end while
for each map M in Hsdo //遍历哈希表
if key [M]>ksthen //当遍历映射的键大于范围开始的关键字时
RQ ∪value[M] //将映射的值并入结果集合中
end if
end for
for each map M in Hedo if key [M]<kethen //当遍历映射的键小于范围结束的关键字时
RQ ∪value[M]
end if
end for
end for
(5)Region分片过程
Region分片主要为了解决在数据表数据增加时,数据行超出预设分片大小的情况。当数据表发生分片过程即Split操作时,对应的内存索引对象也会随之发生变化[14]。分片时,Region 将会从一个变为两个,数据表的也会一分为二,分别存于两个Region 中,此时Observer会监测到Split事件,通知Endpoint重新构建索引表。如图6所示。

图6 分片时表变化
数据表从第三项分裂成两张表,协处理器在原索引表第一行构建索引游标,以此标记向后检索并在Region的数据表中寻找是否有此条记录,若存在则保留数据记录,否则删除,索引表由此更新完成。内存索引构建在索引表主键之上,由于索引主键结构的改变,原索引结构需要初始化操作,即步骤一操作。新分片的内存索引对象存储在新的Region协处理器中。
3.4 内存索引持久化
由于内存索引的维护都由协处理器完成,因此,内存持久化的操作主要为了保证内外存数据的一致性,保证主机断电时不用重新构建索引,不涉及对索引创建操作。提出了内存索引持久化方法,将建立的内存索引从内存中映射到外存中,用于持久化内存索引的外存区域索引文件由存储索引信息的索引头和索引结构组成,索引文件与内存空间采用内存映射技术mmap 保持一致性[15],映射时会使用地址转换表,将索引文件中的地址转换为内存中地址,并一一对应。在对内存索引结构进行修改时,外存索引文件也会自动更新。具体的内存持久化流程如图7所示。

图7 内存持久化流程
在上述流程图中,一个重要的步骤即如何将索引文件映射入内存,索引文件映射入内存后返回的是虚拟地址,索引结构数据没有进入内存中。为了保证索引结构完全处于内存中,要使用相应的方法将索引结构逐步导入内存,采用了层次遍历的方法,将索引树完全遍历,所有索引结构便处于内存中。
4 实验与结果分析
4.1 实验环境与数据
为评估本文提出的基于协处理器的内存索引方案,验证在构建二级索引时对数据库写入性能的影响和在构建了二级索引时对查询性能有怎样的提升。同时,实验同样基于协处理器但使用内存构建索引(本文方案)与使用solr构建索引在查询性能上的表现,测试了数据扩展性与集群扩展性。本文在主机上搭建了Hadoop集群、Zookeeper集群和HBase集群,为了与同样基于协处理器的solr 方案和HiBase 方案进行比较,还搭建了solr集群。实验环境如表2所示。

表2 实验环境
实验所用数据为某河流近3 年各站点水位观测记录,属性包括ID、站点(STCD)、水位(RZ)、地区(RFROM)和时间(TM),共3 000万条数据。
4.2 插入性能对比
实验在分布式环境下进行,通过3台客户端同时向HBase 表中插入数据,并在3 台客户端上统计每500 万数据的Put 时间,为了保证实验的准确性,进行30 次重复测试,并将结果累加求得均值。实验分别测试了无索引、基于solr 的索引、HiBase 和本文提出的基于协处理器与内存的索引方案在相同条件下的Put 时间,结果如图8所示。

图8 插入实验结果
从实验结果可以看出,Put 效率执行最高的是无索引方案,这是因为在进行Put操作时,无索引方案无需分配资源进行索引的构建,而其他需构建二级索引的方案在将数据放入数据表的同时,会触发协处理器对Put 操作进行拦截,并调用用户自定义的方法开始构建二级索引。同时也可得出,在前对500 万条数据进行Put 操作时,各方案的性能差距较小,但在到达1 000 万数量级时,无索引的方案明显优于其他有索引方案。这是因为随着数据量的增加,索引数据也越来越多,在进行索引插入时也会相较500 万条记录时更加困难。HiBase 和本方案都是基于内存索引,在构建内存索引时,需要在协处理器中构建适合内存存储的索引结构,会消耗额外的计算资源。而基于solr的方案只需要在solr中构建二级索引,不需要在程序中进行额外计算。因此,HiBase和本方案相较基于solr的方案稍有劣势,但在一个可接受的范围之内。
4.3 查询性能对比
实验在一台客户端上进行,数据源仍然是3 000 万条数据,本次实验设置了4 个测试用例。详情如下:查询河流站点水位值(STCD)在一定范围内的记录条数,对水位值范围更改后即可得到不同的数据量。在水位值属性上以建立HT 树内存索引,对水位值进行范围查询,图9 所示横坐标数据是4 次测试用例所查询到的所有结果数据量。进行30 次测试,求得各数据库查询时间的平均值,结果如图9所示。

图9 查询实验结果
如图9所示,无索引的方案与其他有索引的方案性能相比有很大差距,原因是,在原生的数据库中搜寻一个特定值时,只能通过Scan的方式进行全表的扫描,效率极低,在数据量大时,这种查询方式可达几十个小时,无法进行实际使用。同时,可以发现,无论查询出的结果为多少,无索引的查询速度都在110 min 左右。排除误差影响,这是因为,无论结果如何,无索引的方案都要全表扫描,在每次扫描的数据量相同时,查询时间变化不大。而本方案相比于同样构建了二级索引的基于solr的方案,性能有较明显的提升,数据量大时,查询速度为其3.5 倍左右,与未构建索引的查询效率相比速度是其50 倍左右,与同样基于内存索引的HiBase 方案提升了10%左右。本方案不仅在性能上优势巨大,随着查询结果的增大时,查询所需的时间变化也较小,因为通过内存进行计算,计算速度快,并且都在索引上建立了索引树结构,在关键字搜索时根据树结构搜索可以快速定位,数据量增大时,对速度影响也较小。
4.4 扩展性实验
测试了基于协处理器的内存索引在不同规模数据下均匀与非均匀分布数据集查询性能。均匀分布数据集使用3 000 万条水文数据,单值查询河流站点水位值(STCD)为62.20和范围查询水位值在60到65之间的记录条数,结果如图10所示。

图10 均匀数据集查询性能
可以看到,当数据的规模从0 持续变化到3 000 万级别时,查询的时间保持了线性增长,这也验证了基于内存方案在数据的可扩展性方面有着良好的表现,查询响应时间和结果集大小成正比。因为在查询响应时间中,主要开销是对查询结果集的访问,在数据集中,数据是符合均匀分布的,随着数据行总数的增长,查询结果集也随之增加,因此,查询响应时间会与数据行总数大小成正比。
同时,本文选用了UCI数据集Abalone数据集,该数据集符合非均匀分布,数据集可分为6类,并满足22.69%、27.53%、25.33%、19.46%、2.31%和2.68%的数据分布规律,同时长度数据也满足非均匀分布性。为了满足大数据测试要求,将数据量以同等倍数增加,保证数据分布的不变性,查询数据集中Length 为130 和Length 大于110小于130的数据,两种查询结果如图11所示。

图11 非均匀数据集查询性能
由图11 可以看出,当数据量从0 增加到600 万时,由于数据的非均匀分布性,并未出现像均匀分布数据集中的线性增长趋势。这是由于单值查询和范围查询查询的目标数值普遍分布于数据表的前半段,在查询开始时查询所得结果集较多,因此,查询时间增加较快。查询数据量增多时,满足查询条件的记录条数减少,查询增加时间也随之变少,这也验证了内存索引方案良好的可扩展性。
同时,在3 000万条数据的基础上,通过增加节点的数量进行集群扩展性实验,由于节点的变化对单值查询的性能影响可以忽略。因此,实验只对范围查询进行,实验结果如图12所示。

图12 节点数量变化对查询时间影响
可以看出,随着节点数量的增加,查询响应时间逐渐减少。在进行范围查询时,会向所有节点发送查询请求,因此,当节点数量增加时,相应的查询时间就会变短。
5 结束语
为了提高HBase的查询性能,本文提出了基于协处理器Coprocessor的方案,实现了内存索引的构建,并将构建的内存索引持久化存储在外存中,通过实验达到了预期目标。其核心的思想为:通过协处理器构建内存索引,具体的内存索引结构为HT树索引,它可以极大提高索引的检索速度。同时,使数据表与索引文件协同分布,托管于同一台Region Server,保证了数据表和索引文件同时分布于集群中的同一台服务器上,在需要用到索引文件时,直接将索引文件映射入内存,节约了时间。
但本文还有一些不足,为了查询的简易性,对每一个列值都创建了索引,这导致了构建的索引文件较为庞大,降低了索引效率。同时,在内存中构建索引对象需要付出巨大的内存开销,当数量过大或索引内容过多时,集群中各服务器的内存会急剧消耗,有可能出现系统瘫痪。
综上所述,本文提出的索引方案实现了HBase检索速度的提高,性能和稳定性也得到了充分的保证,但面对大数据环境下各种各样的挑战,仍需要更多的努力去完善HBase的大数据处理方案。
猜你喜欢
科学与财富(2021年4期)2021-03-08 10:14:32
党员生活(2020年2期)2020-04-17 09:56:30
科学与财富(2020年34期)2020-03-11 18:58:06
当代陕西(2019年13期)2019-08-20 03:54:22
铁道通信信号(2018年10期)2018-12-06 09:34:56
软件导刊(2018年3期)2018-03-26 02:14:46
中国石油企业(2014年4期)2014-11-30 06:13:06
河南科技(2014年24期)2014-02-27 14:19:25
测绘科学与工程(2014年5期)2014-02-27 07:06:14
电脑爱好者(2009年13期)2009-07-07 09:52:52
