
基于LSTM的设备故障在线检测方法
2020-01-06 02:18周剑飞
计算机工程与应用 2020年1期
周剑飞,刘 晨
1.北方工业大学 大规模流数据集成与分析技术北京市重点实验室,北京100144
2.北方工业大学 计算机科学与技术学院,北京100144
1 引言
设备故障检测旨在帮助检测设备故障,以便安排设备检修与维护,减少设备过度维修的现象。在工业4.0时代,故障检测在现代工业降低生产成本中扮演者重要的角色。故障检测主要是用于评估设备的健康状态[1]。由于物联网的迅速发展,工业设备上部署了大量的传感器用于检测设备的健康状态。因此,可以基于收集到的传感器数据建立故障检测模型,用于分析设备的潜在故障。随着近些年来深度学习的深入发展,基于深度学习的故障检测方法已经成为主流[2-4],而在这种方法中特征提取扮演着重要的角色。这是因为在大量传感器中手工选择有效的传感器数据作为输入特征是十分困难的。除此之外,大量的数据导致模型学习成本高昂,因此不能直接输入到模型中。
在近些年来,许多研究人员已经使用特征提取技术用于在原始传感数据中获取有效特征[5-8]。特征提取技术可以在高维度数据中获取非冗余变量[9]。它可以通过计算原始输入的协方差矩阵的特征向量,将一组存在相关性的数据集转化成为一组相互独立的特征。之前的工作[10]提出了一种面向延迟相关的特征提取方法,能够有效地提取带有延迟相关性的高维数据的特征。
然而,在实际的工业生产环境中,设备受到多种因素(外部环境、自身劣化等)的影响,其产生的传感数据也具有时变性,设备的预测性模型无法一次性学习所有的数据,也就是说,使用历史传感器数据所学习的模型已经无法准确预测当前设备的状态信息。例如,火电厂中大型机组处于长期运行的高负荷状态,设备发生劣化使得设备性能降低,继续使用历史数据训练的模型会使得误报率升高,发出错误的预警信息让专业人员对电厂设备进行检修,增加了电厂设备维护的成本。
针对电厂设备运行状态变化,模型也需要随着时间的推移适应设备状态的变化。因此本文提出了一种基于长短时记忆神经网络的设备故障在线检测方法。其主要贡献有:(1)在数据预处理阶段,采用延迟相关的特征提取算法,进一步降低了模型训练的成本;(2)借助滑动窗口技术实现设备故障检测和模型的在线更新,使其适应设备的状态变化,提高模型的准确性,降低模型的误报率。
2 相关工作
2.1 设备故障诊断
机器学习方法是故障检测中最流行的方法,从简单的线性判别到更为复杂的逻辑回归和神经网络都已经应用于设备故障检测[9]。文献[11]对采集到风力发电机的传感器数据使用振动分析方法获取有效的输入特征,再使用支持向量机构建分类模型用于检测设备故障。文献[12]提出了一种基于高斯潜在因子模型的迁移因子分析算法(TCA)用于特征提取,并在此基础上训练线性分类器用于故障检测。文献[13]提出了一种混合机器学习模型的方法,即同时构建两个机器学习模型,其中一个模型的正确输出用于训练另外一个机器学习模型,从而训练出更高精度的分类器以达到故障检测的目的。文献[14]通过专业知识分析风叶涡轮机的传感器数据,进行特征提取之后,借助超参数搜索方法训练支持向量机模型来诊断故障。文献[15]通过收集设备的正常数据来训练单分类支持向量机模型以学习到正常数据空间的边界,并应用于设备的故障检测。
上述文献在一定程度上解决了故障检测问题,但是他们的方法并不能直接应用于大型工业的预测性维护。主要是因为:(1)电厂数据体量庞大且不同传感器数据之间具有延迟相关性;(2)电厂设备运行状态会随着时间的推移而变化,上述方法不能对设备状态的变化及时反应从而更新模型。随着时间的推移,模型性能会越来越差。
2.2 设备故障在线检测
近几年,越来越多研究者关注于小训练样本或者故障缺失样本情况下,无法学习到设备生命周期内的所有故障模式的问题,提出了一些解决方案。Dong 等人[16]针对故障样本缺失以及由于训练阶段和测试阶段独立导致的无法识别新的故障问题,提出了一种在小训练样本情况下,基于在线自适应学习的异常检测以及故障诊断方法.该方法集成了分类与聚类功能,打破了传统故障诊断方法中未知数据和故障类型之间的映射。已知类型的样本被分类,未知类型的样本在AHr-detector 的测试阶段聚集在一起。Yang 等人[17]针对当前训练集中的数据无法代表设备声明周期中可能遇到的所有的情况,基于信号重建,提出应用在线序列极限学习机(OS-ELM)来进行故障检测。OS-ELM具有强大的学习能力,快速的训练能力和在线学习的优点。通过一个真实案例的应用验证基于OS-ELM 的检测模型可以连续地学习不断发展的环境,实现良好的检测性能。但是其仍缺少一组决策规则来确定何时触发OS-ELM 的更新功能来适应不断变化的操作条件。Yan 等人[18]针对不可用的故障训练数据,提出了一种新颖的混合方法来检测冷却器子系统的故障仅通过训练正常数据。混合特征选择算法选择最重要的特征变量,并通过组合扩展卡尔曼滤波器(EKF)模型和递归一类支持向量机(ROSVM)引入在线分类框架。然而,上述的方法没有考虑到具有延迟相关性的传感数据集,且需要一定的经验知识。
3 问题分析
首先对历史数据进行数据预处理,通过延迟相关的特征提取算法获取有效特征离线训练模型,之后借助滑动窗口实现故障设备的在线检测和模型的在线更新。
故障检测模型是将特征提取之后的传感器数据作为模型的有效输入获取预测值。故障检测的目的通过分析设备的相关信息,从而准确判断设备的运行状态。首先给出本文中关于故障检测的定义:

图1 风烟系统传感器流数据示例

其中M 表示网络模型,Func 表示网络模型所学习到的x 到y 的映射关系,给定一组数据xi,根据模型M 输出预测值ŷi,计算出预测值和真实值之间的差值d:

设定一个阈值ε 用于判断设备状态,如果d ≤ε 则认为设备处于正常运行状态,反之亦然。
但是当设备运转一段时间之后,设备的运行状态可能会随着时间而不断变化,使得模型:

使用历史数据所训练的模型已经无法精确描述当前设备的运行状态,此时需要检测设备运行状态的同时考虑使用新产生的传感器数据训练模型来更新模型参数,以适应当前设备的运行状态。
用一个真实的案例来解释设备状态变化现象。在火电厂中有数百台发电设备持续运转,每个发电机组上部署有超过7 000 个传感器实时产传感数据,来反映设备的运行状态。
图1展示了发电厂中风烟系统的运行原理,图中展示了一次风机电动机电流的实际值和模型预测值。在设备运行初期,基于使用历史传感器数据已经训练出性能较好的模型。然而随着发电设备的长时间运转工作,其会发生劣化,其产生的传感数据趋势也会发生改变。前期的模型的输出难以表示当前的设备的状态,如图1所示,系统会根据模型的输出和当前的数据趋势不断发出预警信息,使得模型的误报率升高。此时,需要对模型本身更新。
因此,在模型对设备状态进行预测的时候,如果没有考虑设备的状态变化而及时的对模型进行重新学习更新参数,则会对设备状态进行误判,导致模型的准确率下降,误报率升高。因此,构建故障检测模型的时候考虑设备运行状态的改变是至关重要的。
4 在线故障检测方法
图2 展示了本文所提出的在线故障检测模型的总体框架图。主要分为三个部分:(1)面向延迟相关性的特征提取部分:主要是针对发电设备之间的延迟相关性,来进行传感数据的特征提取,实现高维数据向低维数据的转换[10];(2)故障检测模型:主要是基于长短时记忆神经网络,构建设备的故障检测模型;(3)在线故障检测方法:主要是借助滑动窗口,实现对设备的在线故障监测,以及实现模型的更新。

图2 本文方法框架图
4.1 滑动窗口
滑动窗口是一种对采集到的数据进行实时更新的算法。将相邻的数据界定为一个窗口,当得到新数据的时候,将新数据添加进滑动窗口内,并剔除较老的数据,随着时间的推移,窗口不断纳入新数据而舍弃旧数据,从而实现故障的在线检测。
在本文中,滑动窗口由固定大小的滑动窗口FSW(Fixation Sliding Window)和动态滑动窗口DSW(Dynamic Sliding Window)两部分组成,如图3所示。

图3 滑动窗口
由于传感器之间的延迟相关性,设定FSW 的时间跨度为Δt,Δt 是在数据预处理时曲线排齐算法中所计算得出的时间偏差,其可以保证在实时检测阶段,窗口内数据可以进行排齐并在特征提取之后获取有效特征作为模型的输入。DSW 的时间跨度为σ ,σ 为一个可变值,其主要目的是额外保存历史数据。当模型运转良好则增大σ 值,这时滑动窗口可以包含更多的系统状态区域,使得模型预测更加精确;当模型误报率高于基线值,则减小σ 值抛弃时间相对久远的历史数据,使滑动窗口只包含近期数据用于模型的在线更新以适应当前设备的运行状态。
4.2 基于滑动窗口的在线检测方法
在检测过程中,当数据流填满滑动窗口之后便开始数据处理:(1)窗口内数据经过曲线排齐特征提取计算得出有效特征;(2)将提取之后的特征作为故障检测模型的输入,获取模型预测值;(3)将预测值和传感器实测值做差求取绝对值,判断故障是否发生故障;(4)计算当前滑动窗口内数据的误报率;(5)当前误报率与基线误报率作为比对,如果升高则减少滑动窗口大小重新获取数据用于模型的在线更新,否则增大滑动窗口,使得滑动窗口能够包含更多的设备状态。算法1 实现了在线故障检测算法的过程。
算法1 在线故障检测算法OnlineDetection
输入:滑动窗口数据SlidingWindowData,故障预测模型M,实际采集值RealValue,阈值ε
输出:设备状态Status
1. Var EffctiveFeature=AlinementAndPca(SlidingWindow-Data);//对滑动窗口内数据进行曲线排齐特征提取,获取有效特征
2. Var PredictValue=ModelPredict(M,EffctiveFeature);//根据有效特征模型输出对应预测值
3. Var Difference=Abs(PredictValue-RealValue);//计 算预测值和有效值的差值
4. Var Status=Difference>ε?1:0;//判断设备运行状态
5. Var CurrentFPR=calcFRP();//计算当前滑动窗口数据的误报率
6. If(CurrnetFPR>BaselineFPR){
7. Var NewSensorData=ReduceSlidingWindowAndGet-Data(SlidingWindowData);//减少滑动窗口大小并获取新滑动窗口内的传感器数据
8. RetrainModel(M,NewSensorData)//重新练模型
9. }
10.Else {
11.ExtraSildingWindow();//增加滑动窗口大小
12.}
13.Returen Status;
5 实验与评价
5.1 实验环境与实验数据
实验环境为含有8个节点的集群,每个节点的机器采用8-核Intel Xeon(E312xx)CPU,32 GB 内存,使用1 GB 的带宽和以太网连接。每个节点都运行在虚拟机中,使用CentOS6.4操作系统和Java 1.8。借助Spark平台可以使用SparkMlib 库分布式运行PCA 特征提取算法。
实验中使用的数据来自火发电厂的真实传感器数据。选择了烟风系统中5 个重要设备,上面共部署290个传感器,并对传感器产生的数据进行每3 分钟1 条的采样,数据采集时间从2014-07-01 的00:00:00 到2016-01-31 的23:59:59。表1 展示了实验中的部分数据集。故障日志文件来自于DCS 日志文件,用于验证故障检测结果的准确性。
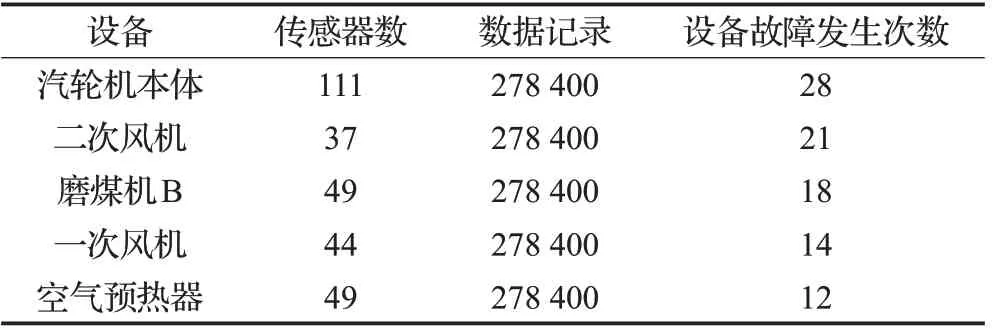
表1 实验数据表
5.2 实验指标
本文使用深度学习技术为故障检测训练了一个预测模型,通过预测值与真实值的差值和阈值ε 对比,将其转化为一个二分类问题。因此故障检测有四种可能的结果。真正例(TP)和真负例(TN)结果表示正确的分类,同时假正例(FP)和假负例(FN)结果表示错误的分类。
对于实验结果的评估,采用精确率(Precision)、召回率(Recall)、误报率(False Positive Rate,FPR)、F1 分数(F1-Score)以及ROC曲线作为本文的评价指标。
5.3 实验设置
故障检测模型旨在发现设备异常,并且在实际生产环境中进行部署,将本文方法与以下检测发电厂异常情况的方法进行比较。
R-模型(Rule-Model):传统的基于规则的异常检测方法是基于经验积累的。实现了基于规则的统计控制图。一旦传感器数据超过了上限值或者下限值,就会得出发现故障。
P-模型(PCA-Model):将经过PCA算法特征提取之后的传感器数据输入到LSTM中去检测设备故障。
SWCP-模型(Sliding Window Curve registration PCA-Model):使用滑动窗口记录最近一段时间的数据,对窗口内数据使用曲线排齐之后使用PCA进行特征提取,输入模型中用于故障诊断,当误报率高于基线值时,更新模型以适应当前设备状态。
P-模型、SWCP-模型均是基于LSTM的神经网络模型。本文所用的LSTM网络模型是一个全连接的LSTM神经网络模型,包含了4 个隐藏层,每个隐藏层有50 个神经元,其结构如图4 所示。 HLi:50 表示第i 个隐藏层,且其有50个神经元节点。
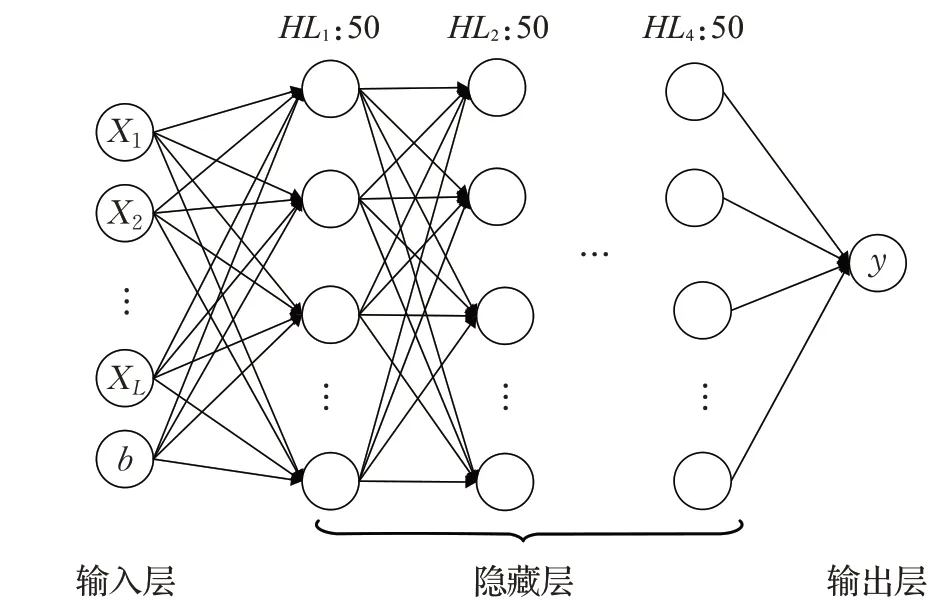
图4 LSTM神经网络模型结构图
基于图4中的网络结构,在[-0.08,0.08]的范围内均匀初始化所有权重参数,使得模型在训练初始阶段可以记住所有记忆,设置LSTM遗忘门的初始偏置值为1.0,输入门和输出门的初始值为[0,1]区间上的随机浮点数职。然后使用微批次随机梯度下降训练网络,学习率为0.001,衰减因子为0.95。采用均方误差作为损失函数。训练模型50 轮,并在10 轮之后每一轮学习率都乘以衰减因子0.95。选择80%作为训练集,剩下的数据作为测试集。
表2给出了不同设备输入特征向量的维度。表中L值表示特征提取之后的数据维度,也是神经网络输入向量的维度。基于表2中的输入向量的训练数据和5.1节所设置的实验环境,训练初始化的LSTM 网络,得到最终的模型参数,在测试集上验证本文所提出方法的有效性。
5.4 实验结果与分析
本文每个实验进行10 次,取10 次结果的平均值作为最终的实验结果。

表2 输入特征向量L 值
图5 所示的是不同方法应用在不同设备上的精确率。基于规则的方法的平均精确率是0.554,最高精确率为0.66。P-模型的平均精确率是0.736,最大精确率为0.79,SWCP-模型的平均精确率是0.79,最大准确率为0.82。

图5 不同方法的精确率
图6 所示的是不同方法应用在不同设备上的召回率。基于规则的方法平均召回率为0.488,最大值为0.52。P-模型的平均召回率为0.807,最大值为0.82;SWCP-模型的平均召回率是0.862,最大值为0.88。

图6 不同方法的召回率
此外,针对本文所提出的方法,在搭建网络模型时,本文尝试减少神经网络模型隐藏层的个数(3层隐藏层,每层45 个神经元),经过训练后的模型,输出的预测结果的平均准确率为0.65,平均召回率为0.74。当增加隐藏层的个数(6 层隐藏层,每层60 个神经元),经过训练后的模型,输出的预测结果的平均准确率为0.791 45,平均召回率为0.856 98,不会提升预测的准确率和召回率,但是其平均训练时间为3.4 h。
图7 表示不同方法应用在不同设备上的误报率。基于规则的方法平均误报率为0.44,最小值为0.416。P-模型方法的平均误报率为0.157,最小值为0.13。SWCP-模型的平均误报率为0.136,最小值为0.118。

图7 不同方法的误报率
图8 所示的是不同方法应用在不同设备上的F1 分数。P-模型方法的平均F1分数为0.77,最大值为0.805;SWCP-模型的平均F1分数为0.82,最大值为0.84。
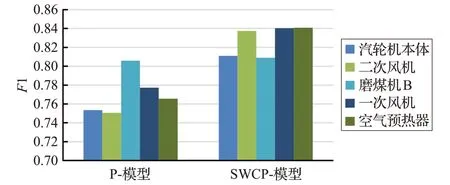
图8 不同方法的F1分数
由于本文的LSTM模型实际上是一个二分类模型,因此利用ROC 曲线来验证分类效果的好坏。图9 展示了不同设备下的ROC 曲线,SWCP-模型的曲线面积大于P-模型和R-模型,其分类效果越好,故障诊断的效果也就越好。

图9 不同方法的ROC曲线
图5 到图9 的实验结果,客观地证明了基于深度学习的预测维护比传统的基于规则的方法更有效。图7所示SWCP-模型有效地减少了误报率,同时图8 和图9所展现的是模型的综合性能,可以看出SWCP-的得分更高。因此得出结论:本文方法有助于提高特征提取和模型的应用性能。
此外,本文通过训练时间来计算不同方法的训练效率。如图10 所示,使用相同的训练数据在5.1 节所设置的集群上进行模型的训练,计算不同模型的训练时间。
如图10 所示,P-模型的平均训练时间是2.412 h,SWCP-模型的平均训练时间是2.1 h。本文方法的训练时间低于P-模型。这表明了本文方法所采用的特征提取方法可以从高维数据中有效的提取特征,使得训练数据量大大减少,有助于降低LSTM 神经网络的训练成本。因此,本文方法有助于建立一个基于LSTM神经网络的轻量级故障检测模型。
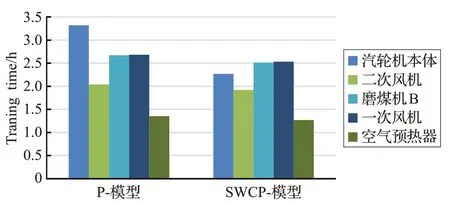
图10 训练时间
6 总结
本文提出的基于长短时记忆神经网络的设备故障在线检测方法,考虑了在线检测阶段设备运行状态的变化,使得模型随着时间推移可以不断适应设备的运行状态。
本文方法在数据预处理部分采用了延迟相关的特征提取方法,减少了数据的维度,降低了模型训练成本;借助滑动窗口技术对在线检测数据流进行检测,并且检测设备状态对模型进行更新。最后,用电厂实际数据分析验证,结果表明了本文方法的有效性:(1)相比于原始特征提取方法,本文方法在保证包含原始信息的同时进一步削减了特征向量的维度;(2)模型在故障的在线检测阶段可以适应设备运行状态的变化,提高了模型的检测精度。
猜你喜欢
湖南文理学院学报(自然科学版)(2022年2期)2022-05-06
煤气与热力(2021年6期)2021-07-28
设备管理与维修(2020年14期)2020-08-12
电子制作(2019年15期)2019-08-27
制造技术与机床(2018年11期)2018-11-23
电子制作(2018年19期)2018-11-14
意林(绘英语)(2018年1期)2018-04-28
自动化学报(2017年11期)2017-04-04
现代电子技术(2015年21期)2015-11-09
城市轨道交通研究(2015年11期)2015-02-27
