
规则引擎下的自动运维虚拟器件建模分析
2019-12-25 08:07:46关兆雄皇甫汉聪
微型电脑应用 2019年12期
关兆雄, 皇甫汉聪
(广东电网有限责任公司 佛山供电局, 佛山 528000)
0 引言
云计算的出现让人们对于网络的认识发生了显著的变化。人们通常习惯把数据存放在电脑当中,并主观认为能够保障数据安全。但电脑并不是完全安全的系统,在加上云计算技术的出现,让很多数据都放在了肉眼不可见的“云”中。例如我们熟知的“百度云盘”,就有效地利用了这项技术。对于虚拟化技术的管理,也需要在程序、配置上面展开优化,来解决存在的诸多问题。
1 虚拟器件的模型构建
虚拟器件实际上是安装了操作系统、业务软件等功能的软件栈,它包含了系统所需要的虚拟资源,一般以.ova为后缀的压缩包格式发布,即OVF包,它也是目前虚拟器件的业界标准,将虚拟器件定义为3种不同格式,不同的解决方案都可以用一个OVF文件来进行描述[1]。其文件构成主要包含以下几个方面。如表1所示。
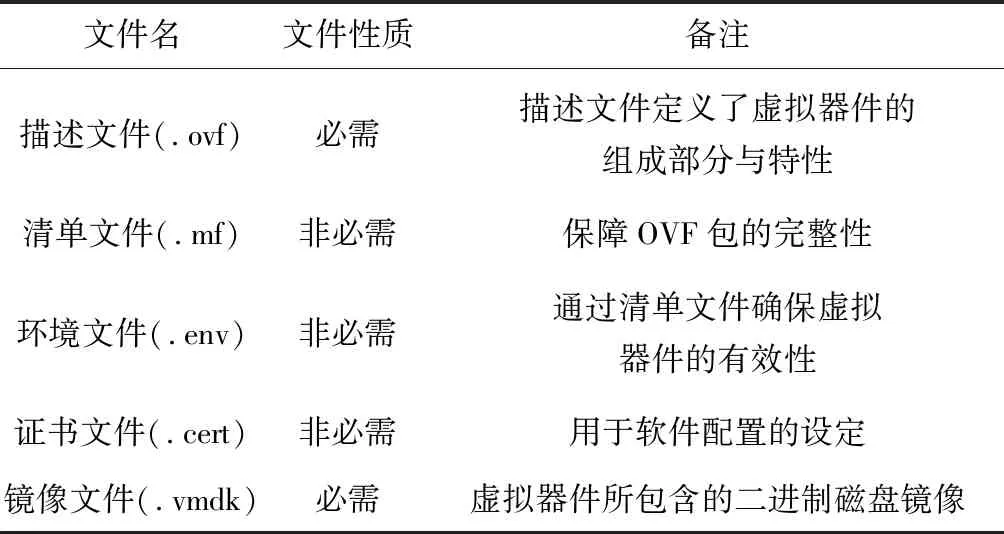
表1 OVF文件类型
2 自动运维功能要求
自动运维模块是基于引擎技术而出现的功能模块,包括不同的组件,例如图1所示。

图1 自动运维模块构成
2.1 监视器
监视器的作用是负责收集虚拟器件运行过程中存在的状态信息,并将数据结果存储至事实库当中[2]。它的信息来源主要源于两个方面,一是虚拟化平台内部的运行状态信息,主要为监视器提供接收接口;二是外部状态信息,对整个虚拟器件进行监控,获取通用信息[3]。例如CPU占用比例、内存情况、硬盘空间与硬盘读写速率等,都可以成为监视器监视的重要内容。
2.2 决策器
在自动运维模块当中,决策器是最关键的组件之一,推理设备通过对知识库与事实库的匹配,产生有效的运维序列,然后表示为虚拟器件中的对象,获取参数列表,然后决策元来根据策略信息与器件的运行状态,匹配合理的行动序列,再交给执行系统完成需要进行的运维工作[4]。一般情况下,有两种行为控制模式。首先是内部行为控制,即对操作系统与软件的运行管理,以虚拟器件的接口调用作为参照;然后是外部行为控制,即在虚拟器件的运行状态下对所占用的物力资源进行管理与快照,并对景象进行保存,防止系统损坏时无法恢复[5]。
2.3 知识库
知识库是虚拟器件自动运维的基础,也是不可或缺的组件。同时它也是虚拟器件运维方式的一种体现,由状态池、策略集组成。状态池中包含了虚拟器件的状态信息与物理机地址等,同时还包括了硬件运行环境的相关要求与软件运行环境的要求。此外,这些信息通常在读取描述文件后写入[6]。而策略集中则存储了策略信息,包括公共策略信息与私有策略信息,前者来源于公共桂策,可以适用于所有虚拟器件,进行公共行为判定;后者则是来源于封装规则集,最终可生成策略集合。
2.4 事实库
事实库可以存储虚拟器件上的所有状态数据,然后通过推理机来获取数据,并与已有的知识进行分类和比较,产生维护动作集。例如图2所示。

图2 事实库数据处理方式
事实库的数据来源如图所示,是监视器所监视的数据,并由事实库转移至推理机,推理机在获取数据后再展开分析与讨论[7]。
2.5 推理机
推理机是自动运维模块的最重要内容,可以实现对监控数据的推理与分析,让运维动作的计算结果更加精确。本次研究中也对推理机的算法进行了分析,让数据定义成为不同的数据类型,不仅可以将一些无关数据进行筛除,让同类型的事实对象进入匹配网络当中,也可以高效地满足网络筛选数据的相关要求。
3 自动运维虚拟器件建模方案
自动运维虚拟器件建模工作可以通过虚拟化平台实现,采用B/S架构来进行,无论是一般用户还是管理员都可以直接通过浏览器进行访问和管理,并对资源进行有效整合,在资源池上建立虚拟化平台,给用户提供虚拟资源的容器[8]。在这种管理模式下资源可以得到有效的分配,虚拟化平台的稳定性也能得到显著提升,满足不同的业务需求与安全级别下多种访问模式的要求。通常情况下管理服务器与客户端物理主机之间存在着密切的联系,管理服务器主要负责系统资源的管理与规划,而物理主机则用于提供相关资源[9]。数据中心可以包含不同的资源池,满足不同的服务要求,也可以在不同的物理主机内实现动态迁移,但不跨越资源池,保障业务之间相互独立[10]。
虚拟机的管理则包括资源分配、监控、备份等各项工作,不仅可以负责虚拟机系统的启动与停止,还能进行多种类型的状态添加与移除操作。无论是在本地还是在一地,虚拟机的管理都支持不同的网络协议,也可以实现在本次操作异地设备,配置管理也能通过网络接口来实现,以创建虚拟网络的方式让虚拟机操作宿主机网络,在合理的防火墙制度下实现[11]。
3.1 运维方案的数据规划
监控数据可以采用五元组来表示,不同属性代表的是不同数据的名称与值,包括数据类型与数据来源。虚拟器件当中,感应器通过接口获取相应的数据,然后以字串形式发送个监视器,此时监视器可以判断数据来源,然后在数据上附加上一定的信息,以便于在未来生成数据实例时进行使用[12]。由于各个数据之间需要进行匹配分析,针对不同的数据类型也需要定义不同的事实数据结构。如果规则引擎进行了匹配分析,那么会被默认为“false”,即数据已经被使用。另外还可以通过一致性设计模式让内部域暴露成员属性,通过自身机制来了解事实类数据。
3.2 规则管理
规则文件的性质是一个可编辑的文本,并可以满足自动运维的业务要求,表现出虚拟器件的业务功能。通常情况下虚拟器件的厂商在开发业务软件的过程中会结合实际的运维需求来对软件进行规划,满足在不同环境下对于虚拟器件运维的需求。不同的器件会包含不同的规则文件,不同的规则文件可以视作一个运维单位。此时,规则文件的特征会结合其属性、条件与结果来判断,来明确规则执行的时机[13]。一个条件即对一个事实的添加限制,也表明可监控的数据需要满足的条件,约束是规则引擎匹配算法的单位,可以将条件内的属性进行管理与规划,并将约束的结果进行计算,当所有约束能满足规则要求时,证明条件满足。研究中还可以引入复杂事件处理,将事实进行定义,让规则的功能更加全面,例如对历史数据的分析、对规则次数的限制等[14]。
3.3 rete算法
目前在规则引擎技术之下,rete算法是目前的“业内标准”,一些引擎接口标准也是以rete为基础而制定的。这种算法包含两个部分,即运行执行部分与规则部分。规则部分即形成一个识别网络进行匹配,然后让事实数据通过匹配传播进行过滤,让符合条件的事实得到保留。研究过程中也将事实数据进行了检查,将不符合要求的数据进行过滤,让网络中需要的数据类型进入网络当中[15]。目前rete网络有多种节点类型,而事实库中一旦有新的事实对象插入,那么匹配后的状态也会得以保存,这样一来等下一个事实对象插入时,只需要对新的事实对象进行管理和检查,减少了大量的重复计算。此外,rete算法还可以共享不同规则网络中的共同部分,即节点相同时,不同规则的网络可以共享相同规则的节点,减少内存中的节点数量,提升系统的匹配性能。但这种方式也需要注意一点,即事实对象变化频率较快时,采用rete算法的工作效率并不突出。
3.4 运维流程管理
运维流程管理方案如图3所示。
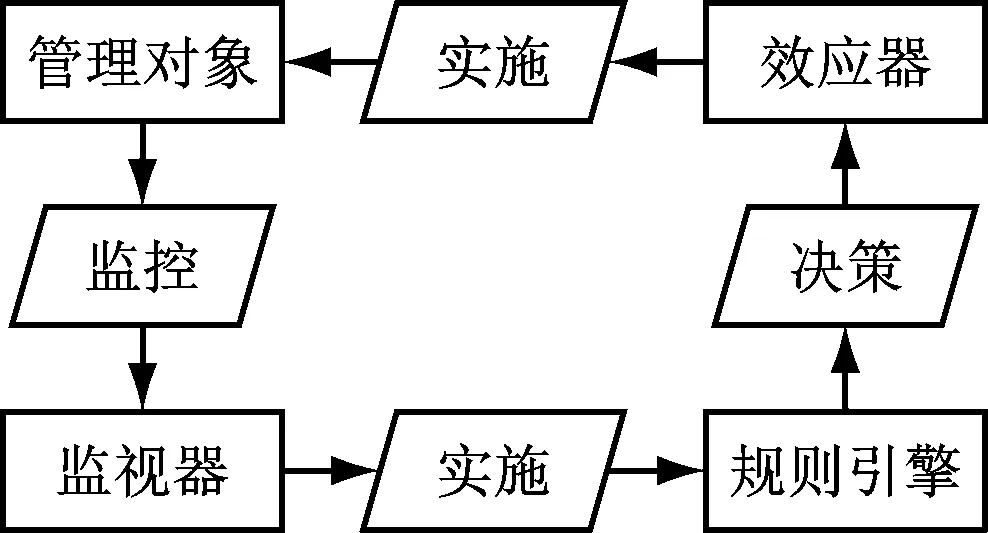
图3 自动运维
虚拟器件自动运维管理可以对运维对象进行有效监控,然后在获取状态数据后进行反馈。如图所示,虚拟器件的状态属性可以通过监视器来进行管理,可以根据器件状态池的参数来获取运行状态时的数据,并将其作为规则引擎的事实数据存入事实库当中,此时规则引擎可以对知识库进行查询匹配,将相关的信息发送给效应器与决策器,结合参数数据来执行相关的工作,引起操作对象运行状态的变化,再让新的状态进入事实库进行处理分析,实现“循环”,并最终实现虚拟器件的自动运维[16]。
3.5 规则解析
规则引擎采用的是代码形式的规则文件,便于相关运维人员进行管理和修改。但考虑到实际的工作需求,如何对规则进行解析,并在编辑界面中进行管理,成为了主要的研究内容。通常情况下不同的规则可以添加不同的条件,条件与条件之间也可以建立联系,编辑器在运行过程中可以赌气描述文件,并将选项进行展示,如果用户需要这些文件,便可以对这些文件进行编辑与保存,例如在创建新虚拟器件时,就可以根据器件运维要求进行编辑。
4 总结
作为云计算技术的核心组成部分,如何提升虚拟化平台的工作效率,推动虚拟化产品的开发与规划,对云计算技术的普及具有显著的现实意义。传统虚拟化技术的效率问题也让虚拟器件技术随之产生,具有显著的优势。本文针对虚拟器件的模型,对系统和管理平台进行了针对性分析,在虚拟化平台中融入规则引擎技术,对各个层次的不同对象进行了自动运维管控,减少了系统问题的产生。在未来的工作中,还需要对测试环境进行完善,力图在一些更复杂的环境下展开测试,为企业的数据管理等工作提供技术支持,并实现出业务软件外所有运维对象的有效管控,提升操作系统的质量。
猜你喜欢
电子制作(2019年10期)2019-06-17 11:45:10
测控技术(2018年9期)2018-11-25 07:44:42
电子制作(2018年14期)2018-08-21 01:38:20
电子测试(2017年11期)2017-12-15 08:57:56
小猕猴智力画刊(2016年10期)2016-05-30 19:02:15
信息化视听(2016年7期)2016-05-14 06:38:19
北京信息科技大学学报(自然科学版)(2016年6期)2016-02-27 06:31:54
网络安全和信息化(2015年8期)2015-12-03 01:03:34
电子工业专用设备(2015年4期)2015-05-26 09:10:31
中国舰船研究(2015年2期)2015-02-10 06:45:50
