
基于内容检索的三维模型语义标注方法研究
2019-12-25 08:15:26田枫孙宁刘贤梅
微型电脑应用 2019年12期
田枫, 孙宁, 刘贤梅
(东北石油大学 计算机与信息技术学院, 大庆 163318)
0 引言
近年来,随着计算机图形学的发展以及三维模型获取技术、图形硬件技术的提高,数字几何模型已成为继声音、数字图像和数字视频之后的第4种多媒体数据类型[1]。作为数字几何模型主要组成部分的三维模型在工业、医疗、建筑、游戏等领域的应用范围十分广泛,由于三维模型本身信息量较大的特性使得在建模过程中往往需要耗费一定的人力物力成本,如何高效的检索并重复利用三维模型成为目前的主要研究方向。因此,提高三维模型标注的准确性与高效性作为实现高效检索模型的一个重要前提逐渐成为目前的主要研究方向。
三维模型语义标注指的是通过识别三维模型内部特征等的方式给未知模型添加能描述该模型语义内容关键词的方法。如普林斯顿大学、台湾大学,国内如中科院计算所、浙江大学等都对相关领域进行了研究[2-4]。检索方式主要分为基于文本的检索和基于内容的检索[5-6]。除此之外许多学者还提出了基于语义相关性的标注方式,利用三维模型之间的语义相关性作为标注依据,将用户形状检索过程中的反馈信息作为模型语义的参考内容[7]。这种方法仅考虑了模型的语义信息,并没有考虑三维模型之间的底层特征相似度,导致标注结果并不十分理想。因此,能够更好描述三维模型底层特征的方式逐渐成为目前采用更多的一种方式。
1 基于内容检索的三维模型标注方法
三维模型标注与三维模型检索是可以相互转化相互影响的,在利用模型标注来解决模型检索的同时,我们也可以利用模型检索来解决模型标注的问题。
基于内容的三维模型标注方法是从三维数据内容出发,利用算法从模型中自动提取出能描述其外观的特征信息,并用一种紧凑的数据结构(特征描述符)来表达这种特征。利用特征描述符之间的内在联系来表达三维模型之间的特征相似性,并将具有相似性较高的三维模型及其标签作为传播目标的一种标注方法。其中,特征描述符提取及特征相似度比对是三维模型检索与标注的核心部分。
1.1 三维模型语义标注流程
在三维模型内容检索过程中,检索出的结果模型与待匹配的模型间具有一定的相关性,这种相关是具有传递性的。因此,可以在传统的三维模型语义标注方法的基础上,加入模型相关基数度量方法,通过模型间内容特征的比对及相似程度的测算,将近邻模型的已知标签传播给未知模型,最终完成三维模型的标注,如图1所示。
具体实现过程如下:
(1) 建立三维模型样本库。将三维模型、模型略缩图及其标签存入样本库。
(2) 抽取三维模型特征描述符。通过提取与保存特征描述符来进行三维模型的内容特征存取与相似度的比对。本文主要利用计算三维模型的D2分布特征及相关特征描述符来提取三维模型内容特征。
(3) 计算三维模型相似度距离。利用EMD距离计算三维模型间的特征相似度。
(4) 选取近邻模型标签进行标注。通过近邻投票算法计算三维模型相似近邻中标签出现频率,通过构建近邻中的标签子空间来实现三维模型的多标签标注。
1.2 三维模型特征提取
三维模型标注的关键在于如何提取特征描述符(Feature Descriptor),该描述符是模型内在特征的抽象描述,一般要求其与模型的旋转、平移、缩放无关。研究发现三维模型的形状分布特性是目前描述三维模型外部特征的一种较为简单高效的特征描述方式。以其为代表的主要有Osada提出的形状分布方法[8]、Suzuki提出的点密度方法以及Kazhdan提出的体素化方法等[9]。
Osada等提出的以形状分布作为特征的形状分布计算方法。分别是: 三个顶点构成的角度、顶点到中心的距离、任意两个顶点之间的距离、任意三个顶点组成三角片的面积和任意四个顶点组成四面体的体积等函数,如图2所示。
通过对A3分布、D1分布、D2分布、D3分布、D4分布做了大量的实验,分析结果证明,认为任意两个顶点之间的距离作为几何函数的效果最好[10]。同时,D2分布函数对模型的描述能力优于其它四种形状函数,尤其是对一些较为简单的三维模型,其区别能力较强且计算简单。

D3(面积)D4(体积)
图2 五种分布方式示例图
因此,本文使用D2分布统计(D2)作为三维模型的基本特征描述符,提取出表现三维模型形状特征的特征向量。简要概述D2算法流程:首先打开一个三维模型,对模型进行离散化处理后在其表面生成离散点。然后根据模型表面的三角面片数及其面积计算并随机选取离散点,然后再计算三角面中随机点对之间的距离,最后进行D2距离的统计和表征,如图3所示。

图3 D2特征提取流程图
由于三维模型主要是由许多三角面片渲染而成。因此我们的目标是在三维模型表面上的网格上生成一个随机均匀分布的点集。如果一个点在某个子区域中分布的概率与该子区域的面积成正比,则该分布是均匀分布的。因此我们可以通过计算三维模型每个面的面积来计算每个面所需随机生成的点数,如图4所示。
三角面片

点集(n=100)

点集(n=1 000)

(1)
(2)
其中X、Y、Z分别为三角形面片上的三个顶点的坐标。
形成采样点后将其平均分为两个集合形成点对,通过欧氏距离公式(3)计算点对间的距离di并统计距离分布结果,如式(3)。
(3)
通过计算点对间的距离D(di),i=0,…,n,最后按照最大距离归一化到64维的D2分布统计中形成D2分布特征向量θ(di),i=64。
1.3 三维模型相似度度量
基于特征描述符,模型之间相似程度的衡量可以转化为对其相应特征描述符的比对。本文采用EMD(Earth Mover’s Distance)来计算描述符的相似度。
EMD距离可以理解为从一种分布变换为另一种分布的最小代价,它最早被 Peleg、Warman和Rom介绍应用于计算视觉问题[10]。给定两个分布,定义一个两分布之间相似性的量化测量标准,使之最大可能地近似视觉感知上的相似性。
通过提取三维模型的D2分布特征向量θ(di)来计算三维模型之间的特征相似性,设三维模型A的特征为feaA(θi),三维模型B的特征为feaB(θi),那么我们可以计算三维模型之间的EMD距离如公式(4)。
(4)
1.4 基于近邻标签传递的三维模型语义标注
在大量三维模型数据中,如果样本三维模型之间的形状或视觉特征是相似的,那么它所包含的语义也是存在一定相关性的,因此我们可以利用三维模型底层特征的相似性来描述和传递它们之间的高层语义。
通过之前的工作我们已经获得了三维模型的D2分布特征及其相似性比对方法,借助检索三维模型的内容特征,我们可以通过内容检索对已有标签的三维模型进行模型特征及标签的获取,通过相似模型及其所含标签出现频率对其进行排序,出现频率高的标签与三维模型间的相似度较高。因此本节基于这种理论提出了一种基于内容检索的三维模型标注方法。
首先选取三维模型x的K个形状特征相似的近邻,然后提取三维模型TOP-K个近邻的n个标签,统计全部标签出现频率后对其进行排序,这样三维模型x对于标签n的相关度就可以表示为sim(x,ni),相关度求解公式可以按照式(5)来计算。通过上述方法,最终可以将出现频次较高的标签作为三维模型高相关度的标签传递给对应的未知模型如式(5)。
(5)
其中countneighborhood(ni)表示三维模型x的k近邻中具有标签ni的样本数,count(ni)为数据集中具有标签ni的模型数,p(n,x)为模型x具有标签w的概率。
通过计算出的三维模型与标签相似程度,我们就可以对未知模型进行近邻选取与标签标注,例如假设我们需对模型标注K个标签,那么我们就可以选取标签相似度在TOP-K个位置的标注词作为该模型的语义标签。
2 实验及结果
2.1 实验设置与评价准则
(1) 实验设置
实验数据集主要来自于PSB中的1 814个模型,为了测试本文所提方法对标注信息的自动标注效果,数据集分为两个部分,一部分数据通过标注员进行手工多语义标注,另一部分为待标注的测试数据集。
(2) 评价准则
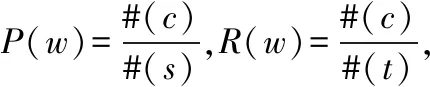
2.2 实验结果
本次实验是在VS2010上进行开发,利用Oracle数据库进行模型及特征的存储。通过单个模型标注、多个模型批量自动标注等方法进行模型标注后,再对标注准确程度进行核对。本文方法自动标注的部分结果,如图5所示。

图5 部分自动标注效果图
为了比较本文所提方法与其他三维模型标注方法的标注效率,图2分别列出了几种标注方式下的平均标签准确率、平均标签召回率。这几种检索方式包括:欧氏距离度量方法、一个比较典型的监督分类学习方法(SVM 算法+欧氏距离)[11]以及本文所提到的方法(D2分布算法+EMD距离),如图。
由图可见,本文所提方法在少量标签信息时表现了较好的标注准确率。从上图可知,本文的方法在检索标签数量q为3的时候的标注召回率效果最好,这也体现了标签个数在3个的时候能够更加全面准确的描述三维模型的语义。除此之外本文还计算了基于内容检索三维模型的平均三维模型准确率、平均三维模型召回率,根据三维模型检索TOP-K近邻进行了准确率与召回率的统计,如图7所示。
3 总结
本文提出了一种基于内容检索的三维模型标注方法。首先,结合模型的形状分布特征匹配出形状相似的模型,计算出样本模型中的相似模型及其标签并提取出TOPK的相似模型标签,然后,通过模型与标签间的近邻投票方法计算出模型标签间的相关基数,确定样本标签中相关程度较高的标签,组成近邻标签集;最后,结合标签集确定待标注模型的标签。通过对三维模型自动语义标注的准确性实验,有效的验证本文提出方法的准确性与鲁棒性。
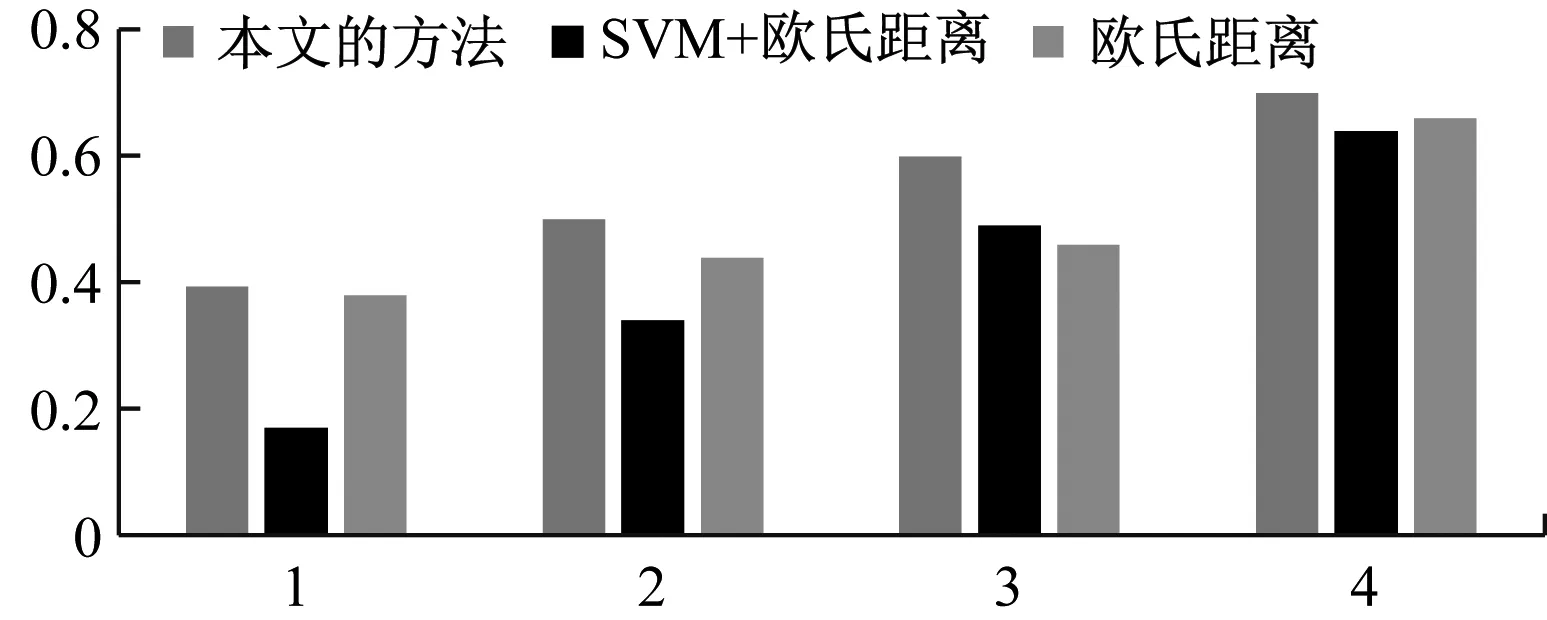
(a) 平均标签准确率(输出标签数量q区间为1-4)

(b) 平均标签召回率(输出标签数量q区间为1-4)

(c) 平均标签F1值折线图
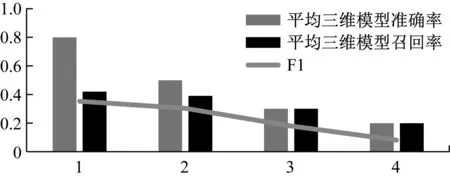
图7 平均三维模型准确率召回率及F1(输出三维模型数量q区间为1-4)
猜你喜欢
中学生天地(A版)(2022年11期)2022-11-25 07:43:16
测绘学报(2022年12期)2022-02-13 09:13:01
意林图解作文(小学版)(2019年6期)2019-07-16 08:35:46
新世纪智能(英语备考)(2018年11期)2018-12-29 10:56:52
数字通信世界(2018年1期)2018-04-18 11:05:22
测绘科学与工程(2017年5期)2017-05-07 06:30:44
小学生学习指导(低年级)(2016年10期)2016-12-01 06:10:42
专利代理(2016年1期)2016-05-17 06:14:36
中国科技信息(2010年9期)2010-11-07 08:40:44
质量与标准化(2010年5期)2010-05-03 04:15:40
