
大数据下的电力客户动态细分方法研究
2019-12-25 08:07胡长青黄研利吴洁朱珂张利鹏
微型电脑应用 2019年12期
胡长青, 黄研利, 吴洁, 朱珂, 张利鹏
(1. 国网陕西省电力公司, 西安 710048; 2. 北京国网信通埃森哲信息技术有限公司, 北京 100032)
0 引言
电力体制改革深入推进,配售电业务纵深推进,电力市场营销管理工作己经成为电网公司的中心工作,直接影响其经济和社会效益。价值客户作为供电企业最重要的载体,满足不同客户的差异化需求,是电力企业营销工作的中心。电网公司根据当前形势,逐步开展价值客户分类管理工作[1-3],然而对理论研究与实践相对匮乏,因此在客户行为和价值分类等研究方面,仍然不够深入,造成一部分差异化营销策略维度单一、实施困难,客户管理工作并不理想。
随着电力市场日益完善,客户的需求也会随之改变,电网公司应时刻关注客户需求变化,采取及时、有效的细分对策。数据挖掘技术的不断发展,国内外出现了应用数据挖掘分析客户行为,以此实现价值客户细分的方法研究[4-6]。刘芝怡[7]等人依托基于K-means改进算法的RFAT模型,对客户进行了聚类分析,并提出差异化营销策略,充分反映了客户的当前价值和增值潜能。王荇[8]等人基于中小批发企业,设计了客户价值与客户关系质量的客户细分模型,模型使数据在不完备的情况下,仍能够实现客户的有效细分。郭崇慧[9]等人基于CRISP-DM模型提出了一种YKFM模型,该模型适用于4S店的客户细分,有助于企业在进行市场调研及制定不同分市场的营销战略时能够以尽量小的营销费用获得更大的利润。韩明华[10]将主成分分析(PCA)、BP神经网络(BPNN)算法加一结合,构建了一种基于消费者行为分析的零售业客户细分模型,基于零售业客户消费行为的实际数据,应用Matlab验证了模型的实用性。
本文将定性与定量分析相结合,基于完善的指标体系和改进的分类算法,构建动态的价值客户细分模型,根据不同客户需求和行为特点进行分群,以此提出差异化营销策略,提升供电公司市场竞争力。
1 电力价值客户细分存在问题
(1)细分维度单一。从用于对客户进行分类的技术来看,有定性和定量客户分类两种方法。但是,定性方法受限于管理者的主观因素,缺乏对客户的全面了解,对于客户的划分很粗糙,定量方法不考虑客户的静态属性,细分结果解释性往往较差。随着更丰富和更复杂数据的产生,只有采用数据挖掘手段,才能更好地贴近人类思维,使其便于理解,并使分类更科学和标准化。
(2)行为细分缺失。客户行为的细分是一切营销活动的前提,依托庞大客户行为数据的客户行为细分早已是西方发达国家炙手可热的应用范畴。因此,从电力客户行为出发细分电力客户,对于更好的认识客户,增强企业营销服务和营销管理能力都具有重要意义。
(3)细分实用性差。目前,电力客户细分结果可操作性较差,体现在两个方面。首先,客户细分脱离市场,无法满足现代电网公司营销活动的需求;其次,客户细分结果模糊不清,无法全面指导电网公司的市场营销活动。传统的电力行业细分方法已经不能满足现在电力行业客户管理和客户营销工作的需要,现在的客户价值分析法还不成熟,可操作性较差,不能反应电力客户的经济行为,实际的操作意义不大。
2 电力客户细分方法
本文的电力客户在分类前的结果都是未知的,即并不知道分到了哪一类别,所以我们需要对无标记的训练样本进行学习,揭示数据的内在性质及规律,我们将这种学习称为无监督学习。无监督学习的训练样本为{x(1),x(2),…,x(m)}形式,仅包含有特征量。基于熵值方法和主成分分析的方法,确定影响分类结果因素,并使用无监督的改进K-means算法对客户数据进行分割,最后运用K近邻算法对细分模型进行检验同时可以对指定客户进行分类。
2.1 熵值法
熵值法是指用来判断某个指标的离散程度的数学方法,作为一种客观赋权的方法,在实际中得到了较为广泛的应用,信息熵的数学表达式为式(1)。

(1)
根据熵值法的原理,假设存在m个待评对象和n项评价指标,将待评对象和评价指标形成原始指标数据矩阵X=(xij)m×n,其中0≤i≤m,0≤j≤n。熵值法计算过程如下。
(1)无量纲化处理。由于不同指标的量纲和数量级的差异,因此在利用熵值法进行赋权前,需对所有指标进行无量纲化处理,本文选择极值处理法对指标数据进行无量纲化处理。
(2)计算第j项指标下第i个样本占该指标的比例:
(3)计算第j项指标的信息熵如式(2)。
(2)
(4)计算第j项指标的权重。某项指标的权重与指标的效用有关。消息效用的值取决于该指标的信息熵与1之间的差值(信息熵越大,效用越小),其直接影响权重的大小,信息效用的值越大,对评价的重要性越大,权重亦越大。第j项指标权重为式(3)。
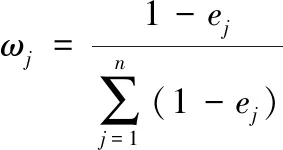
(3)
(5)最后指标的权重和对象值计算各评价对象的得分式(4)。

(4)
2.2 主成分降维算法
利用降维的思想,在失去少量信息的前提下,将多个指标转化为若干综合指标的算法。目标是在研究复杂问题时,只考虑少数几个主要成分而不会丢失太多信息,从而更容易抓住主要矛盾,揭示事物内部变量之间的规律性,同时使问题得到简化,具体过程为:
(1)选取各项指标,若度量或取值范围相同,则构建协方差阵;若不同,则构建相关矩阵;
(2)求出协方差阵或相关阵的特征根和相应标准特征向量;
(3)判断是否存在共线性,若存在共线性,可以将其暂时剔除,重新返回第(1)步;
(4)得到主成分表达式并选取主成分,确定其权重。
2.3 改进的K-means算法
K-means聚类是一种划分的而非分层的聚类方法,该算法是将数据对象划分为k个聚类,通常使用某一划分标准(称为相似度函数),以使同一簇中的对象相似,而在不同簇中的对象是相异的。本文基于K-means算法,对初始聚类中心和迭代种子的选择做了优化,使分类结果更加精准可靠。具体步骤:
(1)给定一组包含n个数据的数据集,每个数据包含m个属性,将数值进行标准化处理。并基于距离法移除孤立点。
(2)对于数据集U,令m=1。Am={xp,xq},(xp,xq)=min(distance(xi,xj)),i,j∈U。循环找到在U中与Am中每个点最近的数据对象,优先归到Am中,直到Am中的数据对象个数到达一定阈值,然后令m=m+1。循环上述过程直到形成k个对象集合。最后对k个对象集合分别进行算术平均计算,形成k初始聚类中心。
(3)应用类中与聚类种子相似度大于某一阈值的数据,组成每个类的一个子集并计算子集中的均值点,该均值点作为下一轮聚类的聚类种子。即在第k-1轮聚类获得的类,计算该类中所有数据与该类聚类中心的平均距离S,每个类的一个子集选择类中与聚类种子且相似度大于2S的数据,子集的均值点作为第k轮聚类的聚类种子。不断重复这一过程直到准则函数开始收敛为止。
2.4 K近邻算法
训练数据集为{(x(1),y(1)),(x(2),y(2)),…,(x(m),y(m))},利用样本数据对特征向量空间进行划分,并作为分类的模型,K近邻算法的工作步骤具体如下:
(1)根据给定的距离度量规则,在训练集T中找出与x最近邻的k个点,涵盖这k个点的x的邻域记作Nk(x);

3 价值客户细分模型构建
3.1 建模思路
模型构建思路如图1所示。

图1 建模思路
首先确定客户价值细分的目标及要求,应用熵权法和主成分分析法,完成价值客户评分指标体系;其次,应用指标体系,计算客户价值得分,根据价值得分曲线筛选价值客户范围。基于范围内的价值客户数据,使用经济贡献得分、发展潜力得分、信用贡献得分,应用K-means聚类算法实现客户价值细分,完成细分客户的特征解释。
3.2 数据来源及数据预处理
收集某省A市区2015年-2017年电力营销系统数据,开展模型训练。价值客户都是大客户,因此最终以非居民用户数据作为数据样本,共收集非居民用户18.94万户。基于收集到的数据,应用R软件,以用户编码为唯一标识,对客户基本信息、用电信息、缴费信息、电价信息等数据进行关联计算,剔除或填充异常样本数据。同时基于对业务的理解,将明显具有相关性的指标进行相关分析,展示了部分指标如图3,保留其中一个指标变量,避免建模时受到多重共线性的影响。最终得到有效数据为筛选出34个指标共96 274个样本。
3.3 指标体系构建
基于数据集中的34个指标,构建客户价值模型指标体系。由于没有客户价值历史类别标签,因此客户价值分析结合实际业务,应用无监督学习方法,进行指标筛选。熵权法是无监督学习中,被行业广泛应用的指标客观权重计算的典型方法,因此首先利用熵权法对指标重要性进行初步判定,包括数据指标归一化、熵值计算和权重计算。对一些明显与客户价值分析无关的指标实行剔除,最终选取用户属性、经济贡献、发展潜力、信用贡献四个维度指标初步构建客户价值指标体系如图2所示。
分析目标侧重客户的经济价值、增长情况(发展潜力)以及客户信用,因此使用R软件,利用主成分分析法将基本属性的影响权重分摊到其他3个维度指标上去,构成由经济贡献、发展潜力、信用贡献3个维度7个指标组成的价值客户评分指标体系,如图3所示。

图3 用户价值建模最终指标体系
3.5 价值客户确定
通过对3个维度指标的加权求和,计算出每个客户价值的总得分,同时根据得分曲线的变化斜率制定价值客户标准。如图4所示。
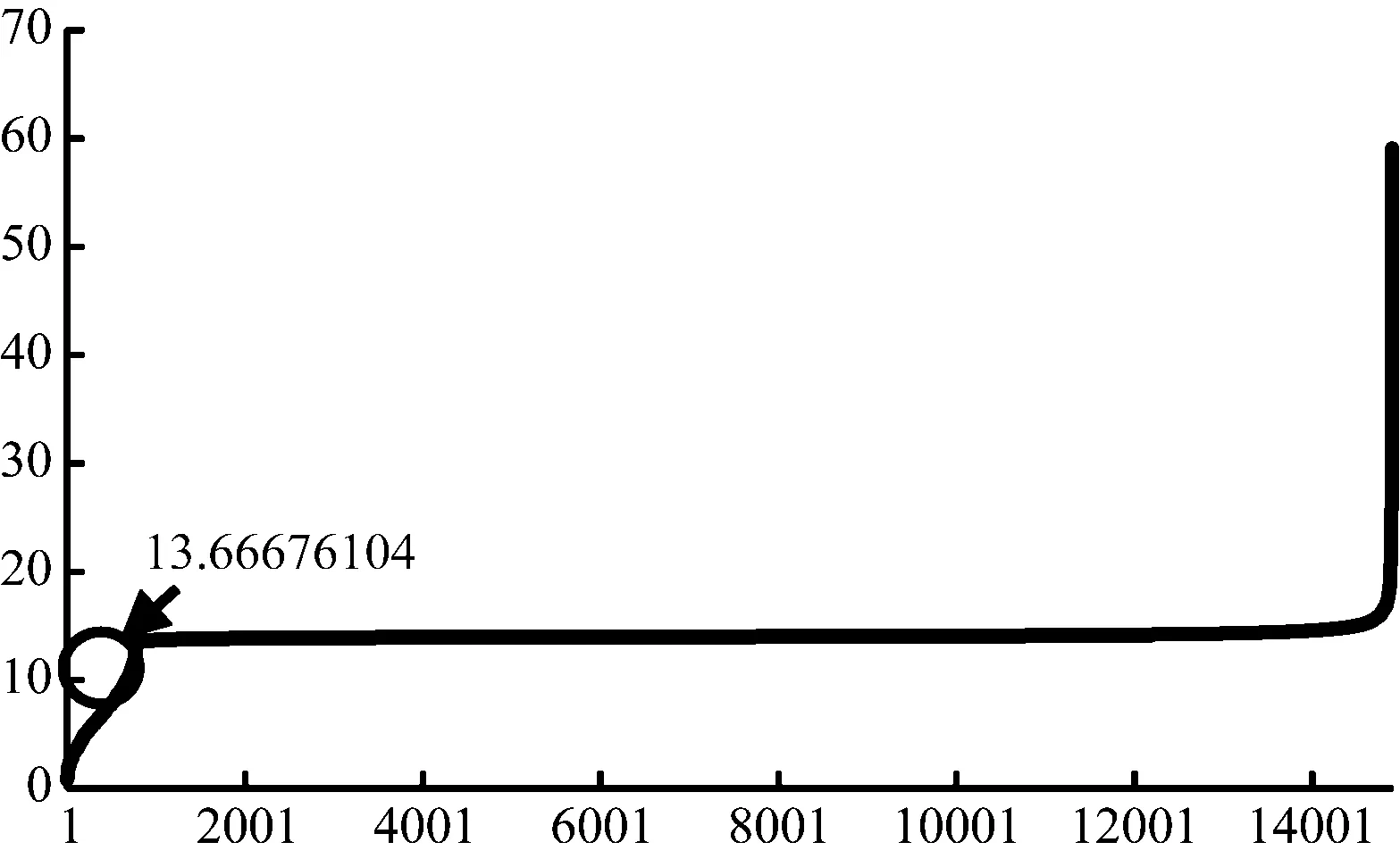
图4 价值客户得分
价值得分曲线在分数为13.666 761 04出现明显拐点,将高于这个阈值的客户作为价值客户。
同时对合同容量、用电量、电压等级、用电量年平均增长率单一数据再次进行描述性分析,如图5所示。

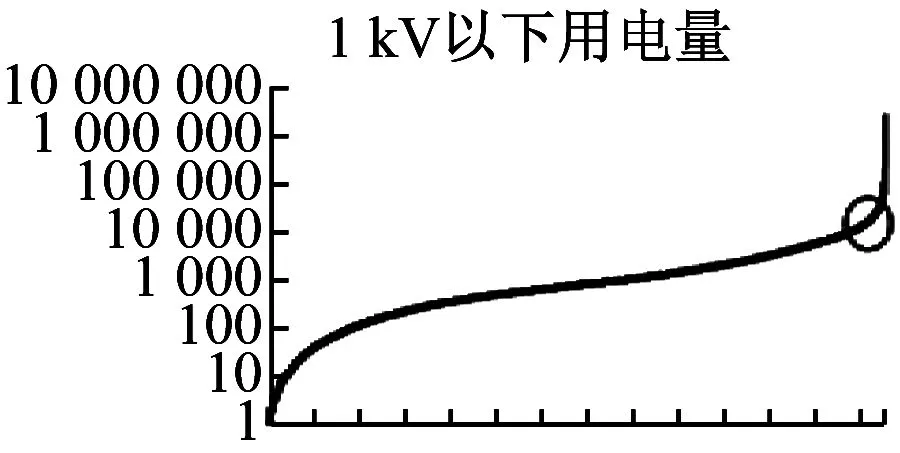
可以看出合同容量在100 KWA以后明显上升,因此合同容量边界定位100 KWA;用电量曲线与趋势线交叉点在10万度点,因此电量边界定位10万度,且该数值也与实际相符;在实际数据分析过程中,81 282(只统计用电量为正数)家供电电压在1 KV以下的用电客户,用电量在10万度以上的只有187家,占比0.2%,样本数极低,因此分析价值客客户过程中,1 KV以下客户认定为非价值客户;用电年增长率图拐点出现在-0.5,且实际计算年增长率低于-0.5的客户仅占0.11%,样本数极低,因此年增长率设定为-50%以上的客户。
综上所述,最终确定电压在10 KV以上、合同容量在100 KVA、年用电量10万度以上、增长率-50%以上、信用年违规3次以下的客户为最终的价值客户,共计12 638户。
3.6 价值客户细分
基于以上价值客户数据和三个维度指标,使用改进后K-means聚类算法对价值客户进行类型划分。得出当聚类个数为4时效果较好,在每个分类类别中各价值客户的经济贡献、发展潜力和信用得分分布如图6所示。

图6 价值客户特征
最终结合业务,将四类价值客户分为不同特征群体,如图7所示。

图7 价值客户分类
将分类结果加以应用,给定新的测试样本客户指标数值为:用电量98 984 469度,应收电费81 643 830元,综合单价为0.824 8元/度,年用电量增长率为45.2%,年应收电费增长率为44.7%,欠费次数为1次,欠费时长为1小时。
4 总结
基于数据挖掘中的分类方法得到了四类电力价值客户,共制定3项共性类策略和14项差异化营销策略。共性类策略除提出更加合理的优质服务策略外,创新的提出积分制,有偿为价值客户提供增值服务。差异化策略针对不同的群组特征,提出个性化账单、客户俱乐部、发放“贵宾卡”等服务策略,有层次、多角度的支撑公司营销工作的开展。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
今日农业(2020年19期)2020-12-14
华人时刊(2020年23期)2020-04-13
劳动保护(2019年3期)2019-05-16
现代计算机(2018年27期)2018-10-25
舰船电子对抗(2017年6期)2018-01-11
互联网天地(2016年1期)2016-05-04
专用汽车(2016年9期)2016-03-01
山东青年(2016年2期)2016-02-28
专用汽车(2015年2期)2015-03-01
