
基于动态ε的社会网络差分隐私保护
2019-12-19 06:36:58刘振鹏孙静薇
郑州大学学报(理学版) 2019年4期
刘振鹏, 王 烁, 张 彬, 孙静薇
(1. 河北大学 网络空间安全与计算机学院 河北 保定 071002; 2. 河北大学 信息技术中心 河北 保定 071002; 3. 河北大学 电子信息工程学院 河北 保定 071002)
0 引言
隐私保护中的主要问题是如何对数据进行适度的保护,同时又能获得最大的数据效用性,以满足科学研究和数据共享的需求.已有的社会网络隐私保护方法分为两大类[1-2]:一种是基于聚类的匿名保护方法,用聚类算法把图划分成若干个子图,把各个子图匿名为一个超级节点,该类方法把子图内部的所有信息隐藏起来,造成的数据缺损过大,不利于数据的共享和研究;另一种是对网络结构进行改动,通过对边的添加、删除和修改操作,使发布后的图在结构上和原始图存在一些差异,这类方法数据缺损比较小,数据的效用性较高.上述两大类方法都是在攻击者对背景知识掌握受限的基础上,实现对数据的弱保护.差分隐私保护技术[3]假定攻击者已掌握所有背景知识的前提下,用数学方法进行严格定义,是一种基于数据失真的强保护模型.
在社会网络隐私保护领域中,Liu等[4]把节点的度作为攻击者的背景知识,采用贪心算法构建k-邻域匿名结构防止攻击. Cheng等[5]提出了k-同构隐私保护模型.Zou等[6]提出k-自同构的匿名方法.Wang等[7]把带权网络图的最短路径作为隐私保护的重点,设计了一种k-路径匿名保护模型,对最短路径的隐私进行保护.兰丽辉等[8]提出了一种基于差分隐私模型的随机扰动方法,设计了LWSPA(less weighted social privacy algorithm)算法,对查询结果集中的三元组进行划分,实现基于边权重的隐私保护.张伟等[9]提出一种基于层次的随机图,并且满足ε-差分隐私的社会网络数据发布算法(differential privacy-hierarchical random graph publishing,DP-HRGP),利用马尔可夫蒙特卡洛方法得到HRG结构树候选集合,对集合中的内部节点加噪,生成满足ε-差分隐私的社会网络发布图.刘晓迁等[10]对数据进行聚类划分,实现将同一簇中的个体记录匿名化隐藏,以实现聚类匿名化差分隐私.Qian等[11]提出了一种方案,即保护私有信息的统计分析(privacy preserving statistical analysis,PPSA),把同态加密和差分隐私机制结合起来对用户的敏感数据加密,保证用户的敏感信息不被发现.以上技术都是为所有数据分配一个隐私预算ε,这就导致所有数据的保护程度是相同的.
在实际应用中,一个数据集中同时存在着重要和次要的数据,使用一个隐私预算ε会导致数据的隐私保护不均衡,数据的效用性会受到一定的限制.本文的主要贡献为:
1) 针对权重社会网络中隐私保护不均衡的问题,设计了一种使用ε函数为社会网络中的边动态分配隐私预算ε的差分隐私保护方法.
2) 使用MCL和Chameleon混合聚类对社会网络中的节点和边进行划分,根据簇中边的权重信息,为每个簇分配合适的ε值.
3) 使用真实的社会网络数据进行实验,实验结果验证本文的方法有效解决了数据隐私保护不均衡的问题,并且满足用户在社会网络中的数据共享需求.
1 基本概念
1.1 MCL&Chameleon混合聚类
马尔科夫聚类算法(MCL)[12]是由Dongen提出的一种经典的网络图形聚类算法.Chameleon算法是一种层次聚类算法[13],算法为两个阶段:第一阶段为k-近邻聚类;第二阶段对聚类结果合并优化.MCL聚类的结果非常零散,大多数的簇只有一个或几个节点,不能有效地把关系近的节点和大权重的边聚到一块.采用Chameleon算法的第二阶段对MCL聚类的结果进行合并优化.下面简单介绍MCL&Chameleon混合聚类.
1) 使用MCL算法对网络图的邻接矩阵进行l次幂扩展和r次方膨胀操作;
2) 重复1)过程,直到算法收敛为止;
3) 把每一行的非0值所对应的列节点归为一簇,得到聚类结果V;
4) 根据簇间的相互对连度RI和相对近似度RC计算两两簇之间的相似度sim;
5) 找出最大相似度值,若超过设定的阈值将对应的两个簇合并,否则说明两个簇无法合并,放到结果簇集合中;
6) 重复4)和5)过程,直到待合并簇集合为空,得到新的聚类结果V*.
1.2 差分隐私
差分隐私保护技术假定攻击者已经掌握所有关于数据的背景知识,并在数学的基础上定义了严格的保护模型.目的是在对数据查询时,既能最大限度地提高查询的准确性,又能最大限度地减少识别数据记录的机会.差分隐私保护的基本思想是对查询结果添加服从拉普拉斯分布的噪声,使数据失真,达到隐私保护的目的.
定义1ε-差分隐私.已知数据集D和D′,给定隐私算法M,D和D′只有一条记录不相同,range(M)表示M的定义域,若M在D和D′上的任意输出结果S(S∈range(M))满足不等式Pr[M(D)∈S]≤eεPr[M(D′)∈S],则M满足ε-差分隐私.
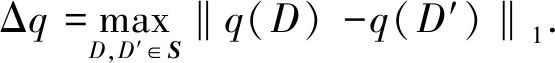
数据集D和D′只有一个元素不同.设两个社会网络数据集G1和G2所有的节点相同,只有一条边不同,即全局敏感度设为最大差异权重Δq=Wmax.
使用拉普拉斯分布[14]为数据添加噪声,
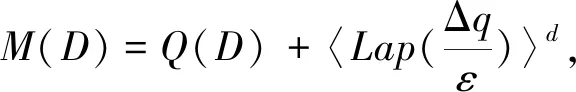
(1)
其中:〈Lap(Δq/ε)〉d是服从Δq/ε尺度参数的Laplace分布的噪声向量.Laplace机制是对于任何函数Q:D→Rd,如果算法M的输出结果满足式(1),表明M满足ε-差分隐私.
在社交网络图中,边的权重越大,表明两节点之间的关系越亲密,两节点之间的隐私越为重要,则需要更强的保护.差分隐私添加噪声的大小跟ε成反比,簇中节点间的边权重越大,应该分配的ε值就越小.由于全局的ε值不统一,本文使用组合差分隐私策略.
定义3组合差分隐私.已知数据集D={clu1,clu2,…,clucluster},D′={clu′1,clu′2,…,clu′cluster},给定隐私算法M,D和D′中都包含有cluster个簇,相对应的簇clui和clu′i只相差一条记录边,每个簇的ε值不同.range(M)表示M的定义域,若M在clui和clu′i上的任意输出结果Si(Si∈range(M))满足不等式Pr[M(clui)∈Si]≤eεiPr[M(clu′i)∈Si],则M满足组合差分隐私,
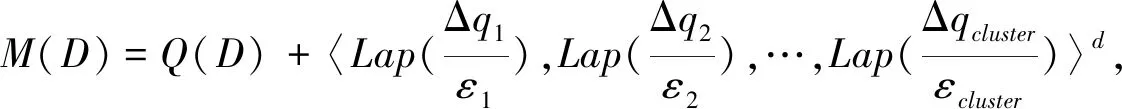
(2)
其中:εi是簇clui对应的隐私预算,Lap(Δqi/εi)(1≤i≤cluster)是为clui生成的Laplace噪声向量.
2 动态ε社会网络差分隐私保护方法
2.1 基本思想
针对社会网络发布算法中使用全局统一的ε值而导致隐私保护不均衡的问题,提出一种动态ε社会网络差分隐私保护方法.使用MCL和Chameleon混合聚类把社会网络图划分成若干个簇,根据每个簇中边的权重信息,使用ε函数f(x)来确定每个簇的ε值,对带有大权重边的簇分配较小的ε值,添加较多的Laplace噪声,提高隐私保护的程度,该方法满足ε-差分隐私模型.
2.2 ε函数f(x)
在不同的应用场景,对ε函数f(x)所需要的表达式可能会不同,在实际应用场景中f(x)也是因情况而定.本文只是使用一个例子验证动态ε的可行性.
为了给簇分配合适的ε值,在选取函数f(x)上要从多方面考虑.大权重的边需要强保护,则簇中最大权重的边作为一个因子;均值反映数据的集中趋势,需要分析簇中边权重的平均值;标准差是评价数据的离散程度,标准差越小,表明数据越均匀,数据会集中在均值附近.本文实验使用的函数f(x)实例是
2.3 算法流程
动态ε社会网络差分隐私保护方法的基本流程如下.
输入:原始社会网络图G.
输出:隐私保护后的社会网络图G*.
1) 使用1.1节介绍的MCL & Chameleon混合聚类对图G聚类,得到聚类结果V*和聚类个数newCluster,以及每个簇节点的个数m1,m2,…,mnewCluster.
2) 把V*中每个簇的节点和边的信息构成三元组(i,j,k),把所有簇间的边的三元组单独记录下来,i、j是节点编号,k代表权重,当节点之间无连接时,k设置为0.
3) 根据每个簇的三元组生成边向量X-1,X1,…,XnewCluster.其中簇的边向量表示为Xi={x1,x2,…,xmi·(mi-1)/2},i=1,2,…,newCluster.X-1是所有簇间的边组成的向量.
4) 根据每个簇的边向量Xi,使用ε函数f(x)得到ε={ε-1,ε1,ε2,…,εnewCluster},其中ε-1表示X-1向量的ε值.
5) 根据每个簇的ε值,生成满足ε-差分隐私的拉普拉斯噪声,Lap=Lap(Δqi/εi).
6) 为每个簇构造服从Laplace分布的向量组〈Lap(Δqi/εi)〉Xi,其中i=-1,1,…,newCluster.
7) 生成满足ε-差分隐私的簇向量组Si=Xi+〈Lap(Δqi/εi)〉Xi,其中i=-1,1,…,newCluster.
8) 生成满足ε-差分隐私的网络图G*={S-1,S1,S2,…,SnewCluster}.
9) 输出隐私保护后网络图G*.
2.4 算法的隐私性分析
由于每个簇使用的隐私预算ε不同,无法直接对全局的隐私性进行分析.在此通过组合差分隐私进行间接分析,当所有的簇都满足ε-差分隐私,全局也会满足ε-差分隐私.根据定义3中组合差分隐私需要满足的不等式Pr[M(clui)∈Si]≤eεiPr[M(clu′i)∈Si]来分析算法的隐私性.
设clui和clu′i只相差一条边,隐私算法为M,range(M)表示M的定义域,若M在clui和clu′i上的任意输出结果Si(Si∈range(M))满足不等式Pr[M(clui)∈Si]≤eεiPr[M(clu′i)∈Si],则本文隐私算法M满足ε-差分隐私.
证明设s∈Si,Si与Xi维度相同,由条件概率可知
其中:σ是服从Laplace分布的尺度参数,σ=Δqi/εi.由定义2可知,Δqi=Wmax.得
由Xi(clui)-Xi(clu′i)≤Wmax知
因为s∈Si,所以Pr[M(clui)∈Si]/Pr[M(clu′i)∈Si]≤eεi,算法满足组合差分隐私,即算法也满足ε-差分隐私.
3 实验结果及分析
3.1 实验环境和数据
实验所使用的环境是:Intel® CoreTMi5-7300HQ CPU @2.50 GHz、8 GB内存、NVIDIA GeForce GTX 1060 with Max-Q Design,操作系统是Windows 10家庭版,编程语言是C++.
实验数据如表1所示.Lesmis是带权重社会网络图,用于验证实验数据的效用性.随机1、随机2、随机3是随机生成的数据集,用于测试算法的执行时间.

表1 实验数据Tab.1 Experimental data
3.2 实验结果
3.2.1数据效用性分析 实验测试了本文算法的不同簇的数据效用性,验证不同ε值对数据效用性的影响.实验从每个簇的隐私前后权重分布情况以及平均最短路径和平均聚类系数测试不同簇的数据效用性.对实验中的5个簇进行数据分析.平均聚类系数如图1(a)所示,平均最短路径如图1(b)所示,分析了隐私后5个簇的平均聚类系数和平均最短路径,与原始图的值进行对比,簇的隐私预算ε越小,平均聚类系数与原始值偏差越大,隐私保护程度越高,簇的数据效用性越低;簇的隐私预算ε越大,平均最短路径与原始值越接近,簇的数据效用性越高.

图1 数据的效用性Fig.1 Data utility
图2给出这5个簇的边权重在隐私前后的变化.由图2的(a)~(e)可知,ε值越小,边在隐私前后的权重相差越大,隐私保护的程度越高;ε值越大,边在隐私前后的权重相差越小,数据的效用性越高.ε值越小的簇,簇中大权重的边所占比例越高.
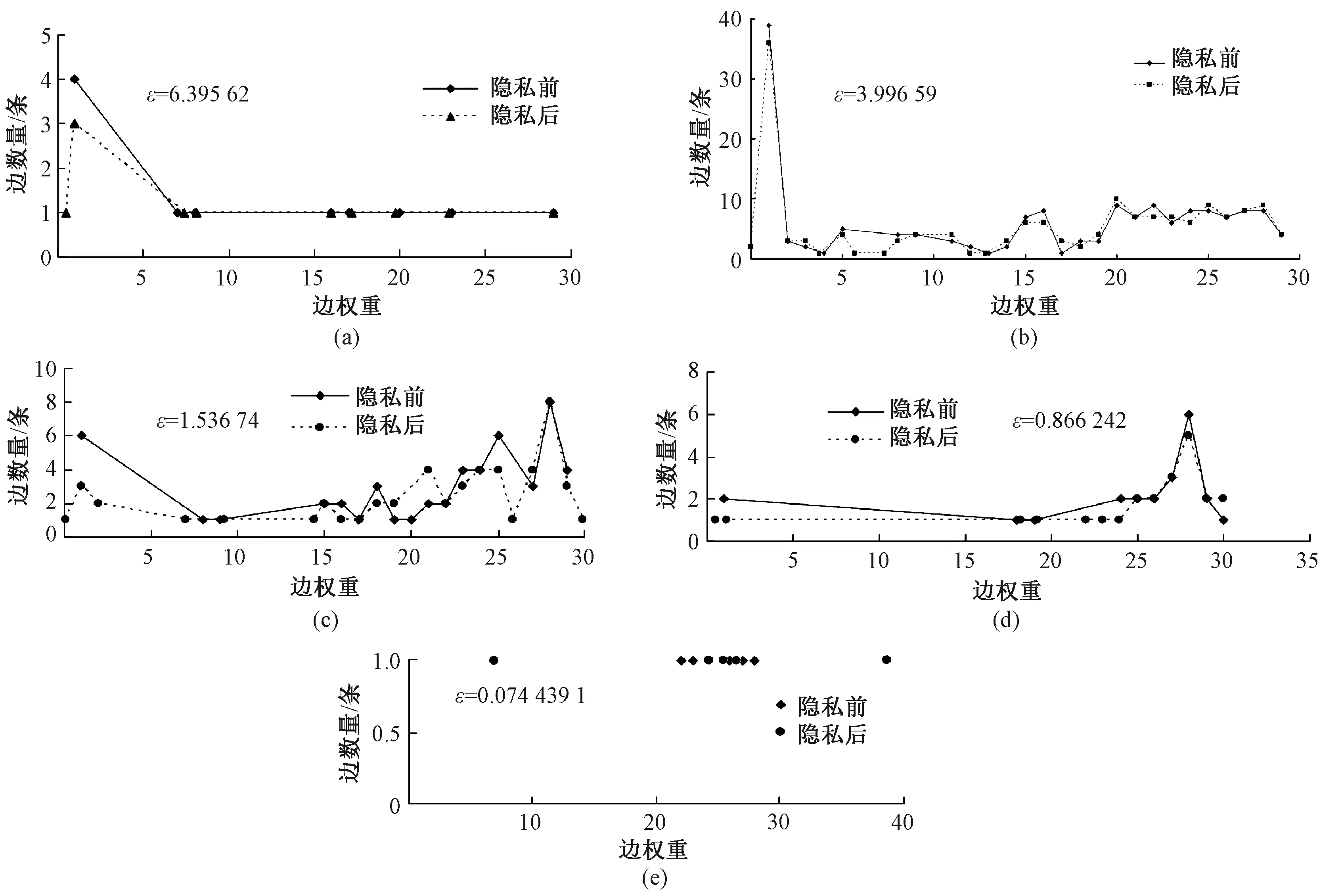
图2 隐私前后权重分布Fig.2 Weight distribution before and after privacy
3.2.2实验对比 实验使用LDRC(less divide randomize and conquer)算法[16]和LWSPA算法[8]与本文的动态ε算法在Lesmis数据集上进行比较,使用图2中的(a)~(e)5个簇与LDRC算法和LWSPA算法在ε等于0.05、0.1、1、10时对比,平均最短路径如图3(a)所示,平均聚类系数如图3(b)所示.
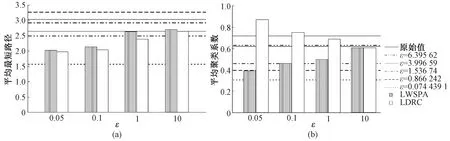
图3 实验对比结果Fig.3 Experimental comparison result
经过两种算法与本文算法中选取的5个簇在ε等于0.05、0.1、1、10时的平均聚类系数和平均最短路径对比可知,随着ε值变大,两种算法的平均聚类系数和平均最短路径越来越接近数据的原始值,数据的效用性越高;本文算法中选取的5个簇也有着相似的特性,簇的ε值越大,平均聚类系数和平均最短路径越接近数据的原始值,数据的效用性越高.但LDRC算法和LWSPA算法只能做到全局,而本文算法可以使大权重的边得到更强的保护,同时小权重的边可以提高其数据的效用性,因此本文算法与LDRC算法和LWSPA算法相比,有着明显的优越性.
3.2.3执行时间分析 实验分别测试了MCL聚类在CPU和GPU下的执行时间并计算出加速比.执行时间如图4(a)所示,加速比如图4(b)所示.
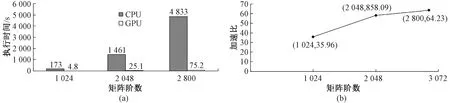
图4 MCL算法效率Fig.4 MCL algorithm efficiency
通过实验数据可以看出,随着实验数据的增加,CPU计算所需的时间急剧增加,GPU的加速比也随着数据量的增加而增加.使用GPU对MCL聚类算法加速非常有必要.
3.2.4Chameleon算法优化分析 实验验证了使用Chameleon算法第二阶段对MCL聚类优化的效果,簇的数量变化如图5(a)所示,聚到簇中的边的数量和权重的变化如图5(b)所示.
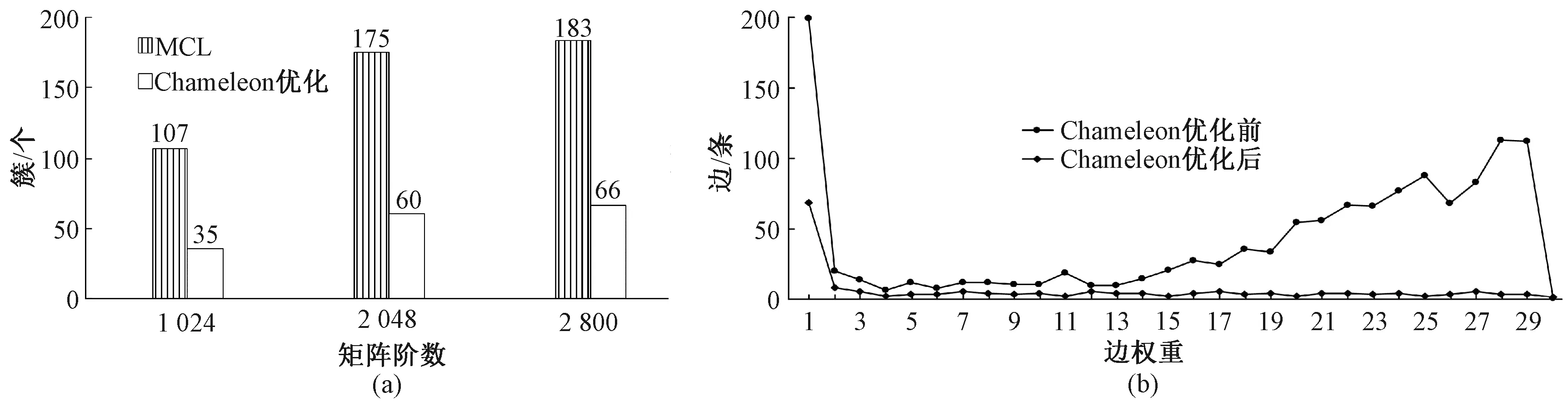
图5 聚类优化前后对比Fig.5 Comparison before and after cluster optimization
由图5可以看出,在优化前,簇的数量很多,并且聚到簇中的边很少,大权重的边更少.簇的个数过多且非常零散,会导致实验的效果比较差.通过Chameleon算法的第二阶段优化,簇的个数减少很多,聚到簇中的边比优化前的数量提高近10倍,并且更多大权重的边聚到簇中,使动态ε隐私保护方法可以达到预期的效果.
4 结论
针对社会网络差分隐私保护对数据保护不均衡问题,在ε-差分隐私模型的基础上,提出一种动态ε-差分隐私保护方法.使用MCL和Chameleon混合聚类把网络划分成若干个簇,根据每个簇中边的权重信息,使用ε函数f(x)为每个簇分配合适的隐私预算,簇添加服从拉普拉斯分布的噪声,有效解决了数据隐私保护的不均衡问题.使用GPU对MCL算法加速,提高了运行效率,满足当前大数据时代对运算速度的要求.
猜你喜欢
新世纪智能(数学备考)(2021年5期)2021-07-28 06:19:46
少儿美术(2019年7期)2019-12-14 08:06:22
活力(2019年21期)2019-04-01 12:17:00
中国塑料(2016年9期)2016-06-13 03:18:48
中国新通信(2015年21期)2015-05-30 04:41:37
信息安全研究(2015年3期)2015-02-28 20:17:57
现代农业(2015年5期)2015-02-28 18:40:44
现代农业(2015年5期)2015-02-28 18:40:42
太空探索(2014年1期)2014-07-10 13:41:50
中学教学参考·理科版(2014年2期)2014-03-10 19:34:21
