
自编码网络在JavaScript恶意代码检测中的应用研究*
2019-12-19 17:24龙廷艳丁红卫
计算机与生活 2019年12期
龙廷艳,万 良+,丁红卫
1.贵州大学 计算机科学与技术学院,贵阳 550025
2.贵州大学 计算机软件与理论研究所,贵阳 550025
1 引言
随着网络技术的高速发展,企业和单位提供的Web服务呈现指数级的增长,据国家信息安全漏洞库[1](China National Vulnerability Database of Information Security,CNNVD)2018年网安时情的调查,网络安全技术平台必须具备的8个特性,首要的就是覆盖电子邮件和Web 安全主流的威胁,占比为38%。而JavaScript 作为一种与后台通信的客户端脚本语言,在提高网页动态性和Web 交互方式的同时,因其不需编译就可执行给Web 安全领域带来检测的困难。恶意代码在植入和传播的过程中,利用逻辑异或运算、分割字符串和压缩字符串等混淆手段进行恶意代码的转码变形,从而躲避安全软件的检测达到自我保护的目的,这使得恶意代码的检测工作变得复杂和困难;此外,同一个恶意代码也会产生大量的同源恶意代码样本,这对恶意代码的特征提取、识别、分类和检测就显得尤为重要。
目前,恶意代码静态分析[2]方法主要有:(1)基于签名(signature-based)的方法,通过识别程序所独有的二进制字符串进行检测,该方法主要依赖已知的签名数据库[3],该方法的缺点是无法查杀新的未知程序,而且需要定期更新和维护签名库。(2)基于启发式规则(heuristic-based)的方法,是通过分析人员对已知的恶意代码提取具有启发式的规则,并通过该规则发现新的恶意代码。上述两种方法的不足都是只能在计算机被恶意代码感染后才能被检测到,而不能及时发现新的未知恶意代码[4]。(3)基于数据挖掘(data mining)的方法,该方法是一种基于统计学自动发掘数据规律的方法,通过分析海量样本的统计规律建立判别模型,从而让攻击者难以掌握避免查杀的规律。缺点是数据挖掘的算法属于有监督算法,对实时场景中丰富的样本这些算法能否胜任还有待验证[5]。(4)基于机器学习(machine learning)的方法,该方法不需要执行脚本,主要通过分析代码的结构、模糊的文本信息、语法信息来提取恶意代码特征,再利用机器学习算法进行识别和分类。如Likarish等人[6]依据JavaScript 代码中特殊函数和特殊字符出现的次数作为恶意代码的关键特征,进行统计分析,提取了65个JavaScript 特征,并建立4个分类器Naïve Bayes、AD Tree、SVM(support vector machine)和RIPPER(repeated incremental pruning to produce error reduction)来检测网页中恶意的JavaScript 代码。Wang等人[7]实现了一个JavaScript恶意软件检测并分类的工具(JavaScript malware detection and classification,JSDC)。该工具基于机器学习的方法,利用可预期的文本信息、程序结构和风险函数调用等作为特征;对于待检测的恶意软件,该工具又根据其攻击特征向量和动态执行轨迹将其分为己知的八种攻击类型。虽然机器学习的方法在恶意代码检测中得到了广泛的认可,但机器学习算法通常需要复杂的特征工程提取恶意代码中的特征,如文献[8],需要对JavaScript 源码进行分析后方可得到77个关键的特征,不仅耗费时间,而且该方法对特征选择的依赖较高,所提取特征的好坏直接影响最终的识别效果。如今出现的深度学习方法,不需要这样的特征工程,只需将数据直接传递给网络,就可立即实现良好的性能,完全消除了提取特征过程中繁重而且很有挑战性的特征工程。并且当输入是二进制数据时堆栈降噪自编码器(stacked denoising autoencoder,SDA)更适合文本的分类[9]且SDA 比其他的非监督学习方法表现都好[10]。Wang等人[11]提出由SDA和逻辑回归(logistic regression,LR)组成的深层学习框架,其中SDA被用来从JavaScript代码中提取高级特征,LR作为分类器用于区分恶意和良性的JavaScript代码。Li等人[12]使用自编码器降低数据的维度并提取恶意代码的特征,然后采用深度信念网络(deep belief networks,DBN)进行恶意代码的检测,在最后一层使用有监督的误差反向传播(error back propagation,BP)算法进行分类,实验结果表明检测准确率高于仅仅使用DBN 训练的情况,而且还降低了模型的时间复杂度。
为获取恶意代码深层本质特征信息,提高识别的精确度,本文提出了一种基于堆栈式稀疏降噪自编码网络(stacked sparse denoising autoencoder network,sSDAN)取代传统的特征提取方法。首先,采用无监督自编码器自动提取特征并降低数据维度,从高维的数据中概括出具有代表性的少量数据,用来表示数据的最本质特征。其次,在自编码器的基础上添加稀疏约束条件,从而具有更优的特征学习能力,利用降噪自编码网络(denoising autoencoder network,DAN)进行主动染噪的学习训练,可以得到有效去噪后的深度特征提取模型。最后,将恶意代码检测与sSDAN 模型结合,一方面可以提高恶意代码检测的准确性和稳定性;另一方面,sSDAN通过堆叠多个加了噪声的稀疏自编码搭建的多层神经网络架构,实现对数据各层次的特征表达,通过整体微调将特征提取和分类器有机结合,充分挖掘数据中的变化特征来优化检测性能,具有较好的目标信息表示能力、鲁棒性和泛化性。
2 检测方法
2.1 自编码网络
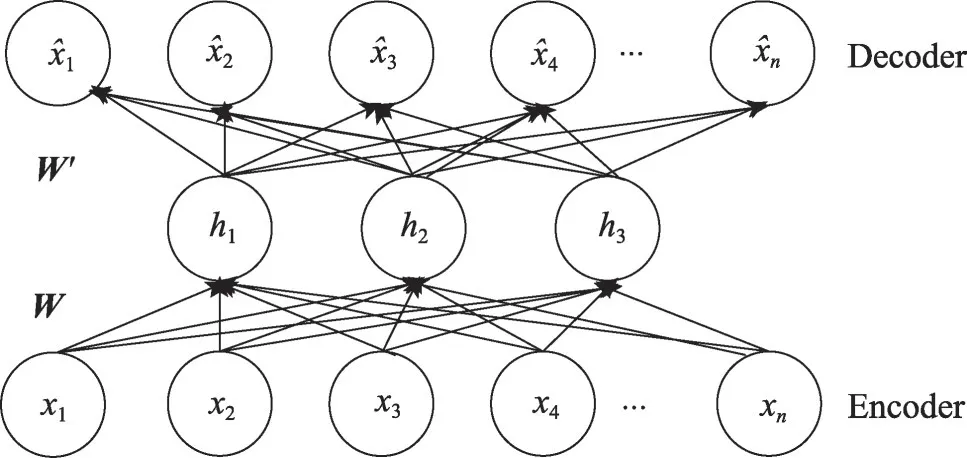
Fig.1 Structure of AE图1 自编码网络结构
自编码网络(autoencoder network,AN)是一种三层神经网络模型,图1为自动编码器的一个简单模型结构,包含了输入层、隐藏层、输出层,是一种无监督的学习算法,可以获取数据中重要信息。从输入层到隐藏层的压缩低维表达过程可以称作模型的编码阶段(encoder),从隐藏层的压缩特征映射还原出输出层的近似原始数据的过程称为解码阶段(decoder)。
设原始空间数据为Rm×n,m为原始空间中数据实例数,n为每条实例数据的维度,x(i)∈Rn(i=1,2,…,m)其每一个训练数据x(i)经过编码器操作(式(1))可得隐藏层的特征表达y(i)。

其中,θ=(W,b)为网络参数,W为输入层到隐藏层的权值矩阵,b为偏置向量,σ(x)为激活函数,此处选用Sigmoid 激活函数。然后隐藏层的特征表达经过解码操作(式(2)),得到重构向量z(i)。

其中,θ′=(W′,b′),W′为隐藏层到输出层间的权值矩阵,通常取W′=WT。通过无监督贪婪算法调节权值和偏置量使重构误差最小就可完成单个自编码的训练,即对模型参数优化调节实际上是最小化重构误差(式(3))。
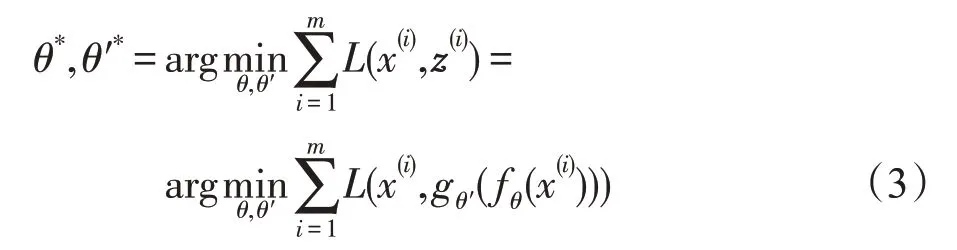
L为代价函数,文献[13]证明了交叉熵代价函数要优于平方差代价函数,因此本文采用交叉熵代价函数,其表达式为式(4)。

则整个数据集条件下的代价函数为式(5)。
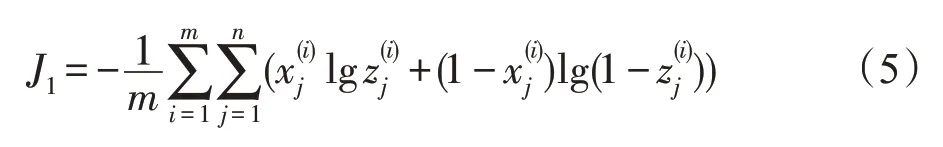
同时为了防止出现过拟合,需要添加一个L2正则化权重衰减项,λ为对应的惩罚因子,控制惩罚项从而促进权重的衰减,则改进后的代价函数为式(6)。
2.2 稀疏自编码网络
稀疏自编码网络(sparse autoencoder network,SAN)是Bengio于2007年提出,它是在自编码器基础上添加约束条件,要求大部分节点为零,少部分不为零,用尽可能少的神经元表示原始数据从而具有更优学习数据特征的能力[14]。稀疏自动编码器代价函数为式(7)。

其中,S2是隐藏层中神经元的数量,为稀疏惩罚项,即,β为稀疏惩罚项的权重,ρ∈(0,1)为指定的稀疏性参数,表示神经元的平均激活度,它与权重和偏置量有关,想让隐藏层神经元j尽量为0,可以让=ρ,然后让ρ是一个趋近于0的小数。当=ρ时,达到最小为0;当接近0或者1时,急剧增大。因此在代价函数中加入此项,并使其最小化,可以使得更靠近于ρ。
2.3 稀疏降噪自编码网络
稀疏降噪自编码网络(sparse denoising autoencoder network,SDAN)是在自编码网络的基础上,对各网络层进行稀疏项限制,同时加入按一定概率分布的噪声对输入的数据进行加噪,使稀疏自编码网络学习去除这种噪声,从而提高稀疏自编码器对数据的泛化能力,提高模型的鲁棒性[15]。Vincent等人[16]认为为了使AN具备鲁棒性的特征表达,提出降噪自编码网络(DAN)。DAN 与AN 类似,都需要编码和解码过程来重构数据,同属于无监督学习。不同的是,降噪自编码器是在原始数据x上加入一定比例的噪声变成了噪声数据x′,然后将噪声数据作为网络的输入数据,来重构原始还未加入噪声的数据,因此降噪自编码的损失函数是构造原始数据x与网络输出x′之间的一个差异性度量,然后训练恢复原始数据,使网络具有抗噪能力,最终还原出更具鲁棒性的特征,提高了基本AN对输入数据的泛化能力。稀疏降噪自编码器结构如图2所示,设训练样本x,样本空间x∈Rd,SDAN 通过一个随机映射变换进而得到一个含有噪声污染的数据D为数据集,则DAN 的编码输出为,接着通过z=解码器将y反向变化,得到原始输入数据x的重构数据z,y∈Rh,z∈Rd。通常,加噪的方法有两种:一种是添加高斯噪声;另一种是以二项分布随机处理数据,将数据以一定概率置0。稀疏降噪自编码网络代价函数为:

Fig.2 Structure of SDAN图2 稀疏降噪自编码网络结构

2.4 堆栈式稀疏降噪自编码网络
堆栈式稀疏降噪自编码网络(sSDAN)是由多个SDAN 堆叠而成。神经网络经过多层的非线性表达能够学习输入数据更深层次有效的特征,且对每个SDAN 加入一定比例的噪声ρ能够学习更强健的特征表达。在训练时,将第1个SDAN网络的隐藏层的输出作为第2个SDAN网络隐藏层的输入,并丢弃第1个SDAN网络的隐藏层到输出层的映射部分,从而构建sSDAN 网络的第2隐藏层,依次类推逐层进行训练。首先,用经过加噪处理的原始输入数据训练第1个稀疏降噪自编码器,得到输入数据的1阶特征表示然后,将该特征表示作为下一个稀疏降噪自编码器的输入,得到2阶特征表示依次类推,将第(n-1)阶特征表示作为第n个稀疏降噪自编码器的输入,得到n阶特征的表示sSDAN的学习分为无监督逐层贪婪的预训练与有监督的微调。当模型在逐层预训练过程时,训练每一层SDAN的输入数据为加入一定比例噪声ρ的数据信息,在微调过程中使用未加噪声的原始数据对整个SDAN 网络进行微调。图3呈现了预训练的过程,图4呈现反向微调的过程。其中sSDAN的数目作为模型的一个重要参数,将在下章节讨论如何确定。
模型学习的具体过程如下:
(1)无监督预训练
步骤1首先采用稀疏自编码网络先训练从输入层到h(1)层的参数,需要用原始输入数据x训练第一个SDAN,它能够学习得到原始输入的一阶特征表示将无标签的JavaScript 向量数据加入一定的比例的噪声ρ,生成样本数据作为第一个SDAN的数据,利用DAN 的重构方式,训练得到隐藏层h(1)的权重参数W1,同时计算出隐藏层h(1)的输出。训练完毕后,去除解码层,只留下从输入层到隐藏层的编码阶段。

Fig.3 Unsupervised pre-training图3 无监督预训练
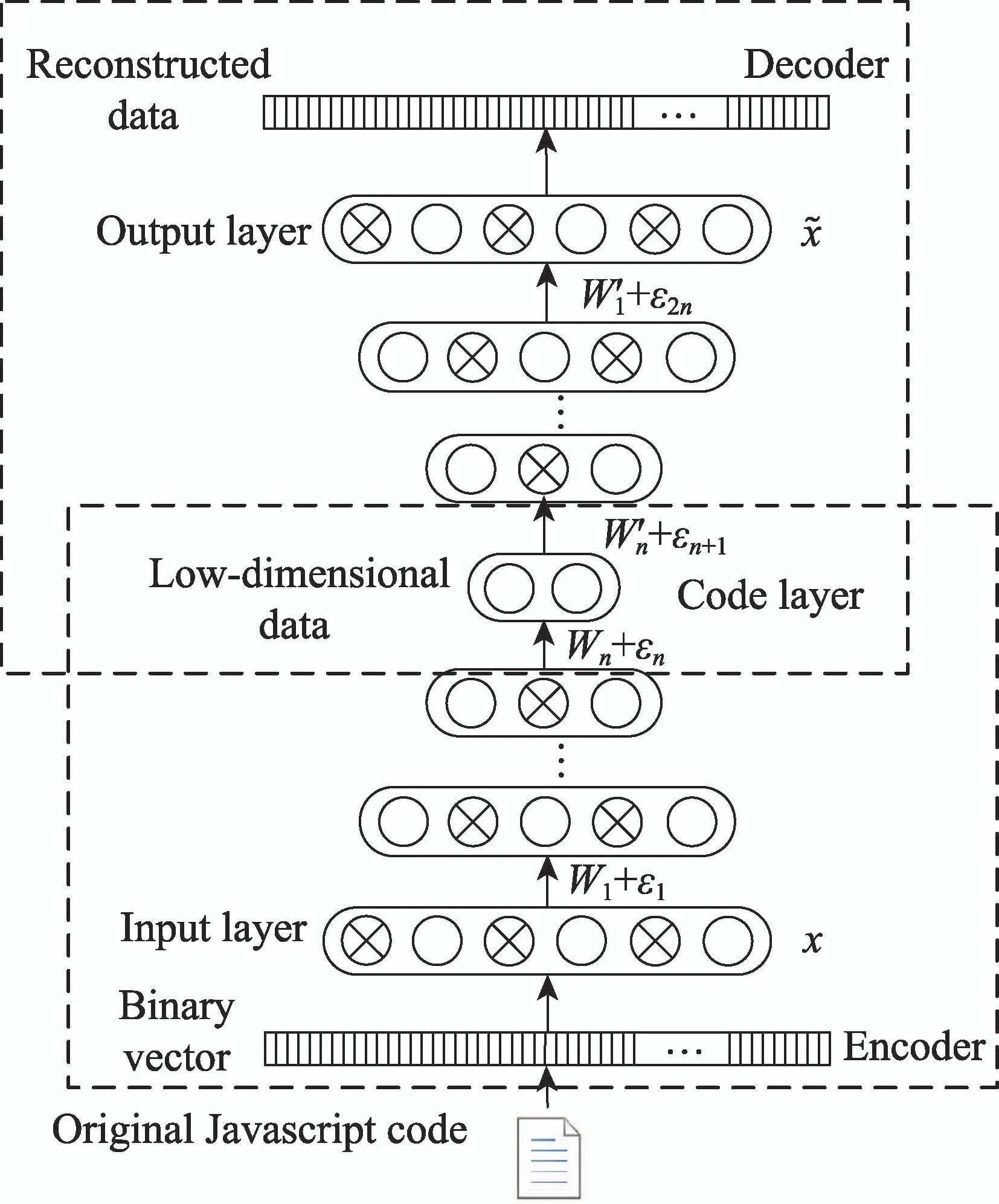
Fig.4 Supervised fine-tuning图4 有监督的微调
步骤2将步骤1的输出加入相同比例的噪声ρ,从而得到,作为第二个SDAN的输入,用相同的方式训练得到隐藏层h(2)的权重参数W2,同时计算出隐藏层h(2)的输出。训练完毕后,再去除h(2)层的解码层,如此重复,可以训练更高层的网络,这就是逐层贪婪训练的思想。
步骤3同样的方法将上一层数据加入相同比例的噪声ρ,作为第n个SDAN 的输入,训练得到隐藏层h(n)的权重参数Wn,并计算隐藏层h(n)的输出。
步骤4将步骤3隐藏层的输出作为Softmax 分类器的输入,得到分类器的参数。
步骤5将步骤1~步骤4逐层训练得到的网络参数作为网络的初始参数,完成模型预训练。
(2)有监督微调
微调是采用少量标签数据进行有监督训练,与此同时对全局网络训练中的误差进行优化,微调的作用是对整个sSDAN+Softmax 网络的权重进行调优,使模型具有更精准的特征提取和学习能力。微调算法具体过程如下:
步骤1使用标签的数据作为输入数据,对sSDAN+Softmax 进行全局训练,计算整个网络的损失函数,以及对每个参数的偏导函数。
步骤2采用误差反向传播算法并运用随机梯度下降对网络权值进行优化,过程是输入标签化的数据从前至后逐层计算输出Y值,计算输出层误差,误差反向传播,计算每层误差和梯度,将这些参数作为sSDAN+Softmax整个网络的最优参数。
3 实验
本文实验环境是CPU Intel Core i5-7300HQ 2.50 GHz、GPU GeForce CTX1050 Ti、8 GB RAM 和Windows10操作系统,使用Python3.6下Keras框架实现。
3.1 实验流程
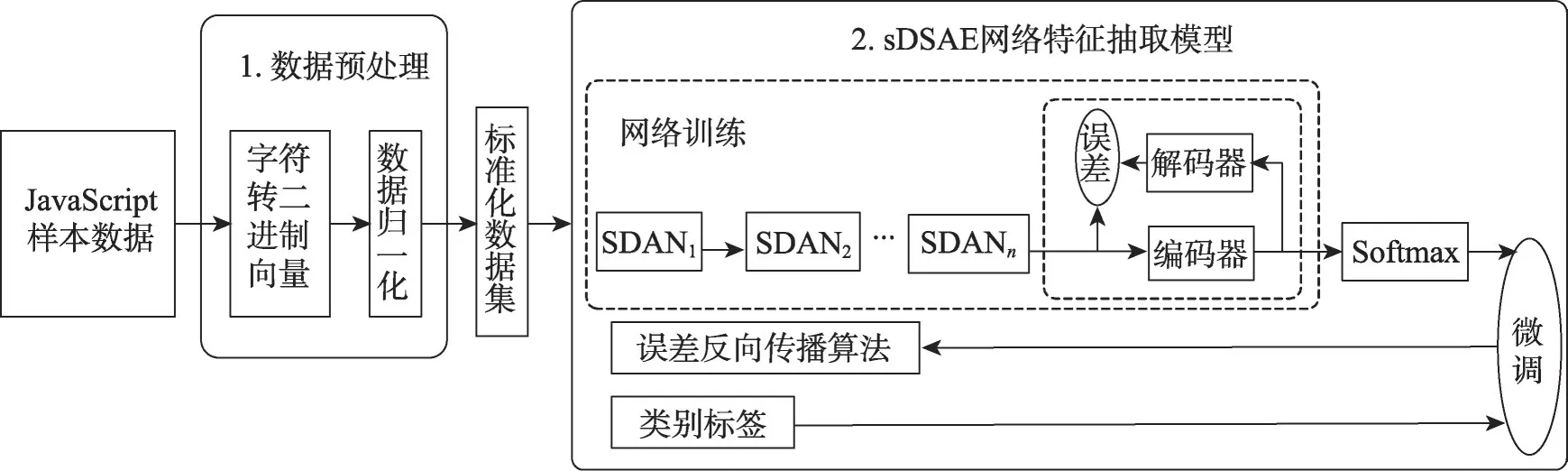
Fig.5 JavaScript malicious code detection model based on sSDAN图5 基于sSDAN的JavaScript恶意代码检测模型
为了提取更加抽象和有用的特征信息,本文提出的基于sSDAN 的JavaScript 恶意代码检测模型完整过程如图5所示。其中网络由1个输入层,4个隐藏层和1个Softmax 层组成。该检测框架首先是数据预处理阶段,将字符型JavaScript 代码转为数值型数据矢量X=(x1,x2,…,xn)T。然后将数据归一化到[0,1]区间作为输入。其次是sSDAN 网络特征抽取阶段,主要分为两步:一是预训练,采用逐层贪婪算法对每个SDAN网络初始化训练,将前一个SDAN的输出作为下一个的输入,然后在顶端加入Softmax 分类器;二是权值微调,在每个单独的SDAN 训练完成后,为保障整体权值的最优,需要进行整体权值的微调,使用误差反向传播分类算法进行全局精调。这样网络前面的隐藏层完成特征的提取,Softmax 完成最终的分类检测。
3.2 实验数据
本文的数据包括恶意的JavaScript代码样本和安全的JavaScript 代码样本。一方面来源于文献[7]开源的数据集;一方面对Alexa’s Top 排名靠前的网站爬取,得到安全的JavaScript 代码样本,从PhishTank公布的网站中使用Python Scrapy获取恶意的URL站点,并利用Google Safe Browsing API进行站点筛选,得到恶意代码样本。实验中,最终获得21 000个良性JavaScript脚本和7 068个恶意JavaScript脚本。将数据集的90%作为训练集,10%作为测试集,数据集样本大小如表1所示。

Table 1 Data set size表1 数据集样本大小
3.3 数据预处理
在自然语言处理中使用表示文本形式的词向量更为常见,但由于恶意JavaScript代码具有混淆特征,其中包含了大量无意义的字符串,因此恶意JavaScript代码的检测不适用于词向量形式[11]。由于JavaScript代码为字符型数据,要进行的预处理操作过程如下:
(1)数值化
依据ASCII 表将JavaScript 代码中的字符转为8位二进制数值型数据,然后以二进制文件形式保存。图6显示了JavaScript 的两个代码片段,图6(a)cklogin()函数对用户的登录进行检查,获取用户的cookie 信息并进行判断;恶意的JavaScript 代码由一些无意义的字符串组成,如图6(b)所示,通常使用Unicode、Hex、Decimal 和字符分割等手段将代码转变为人眼无法清晰可见的字符;因为空间有限,只转换了图6(a)和图6(b)的部分代码如图6(c)所示。
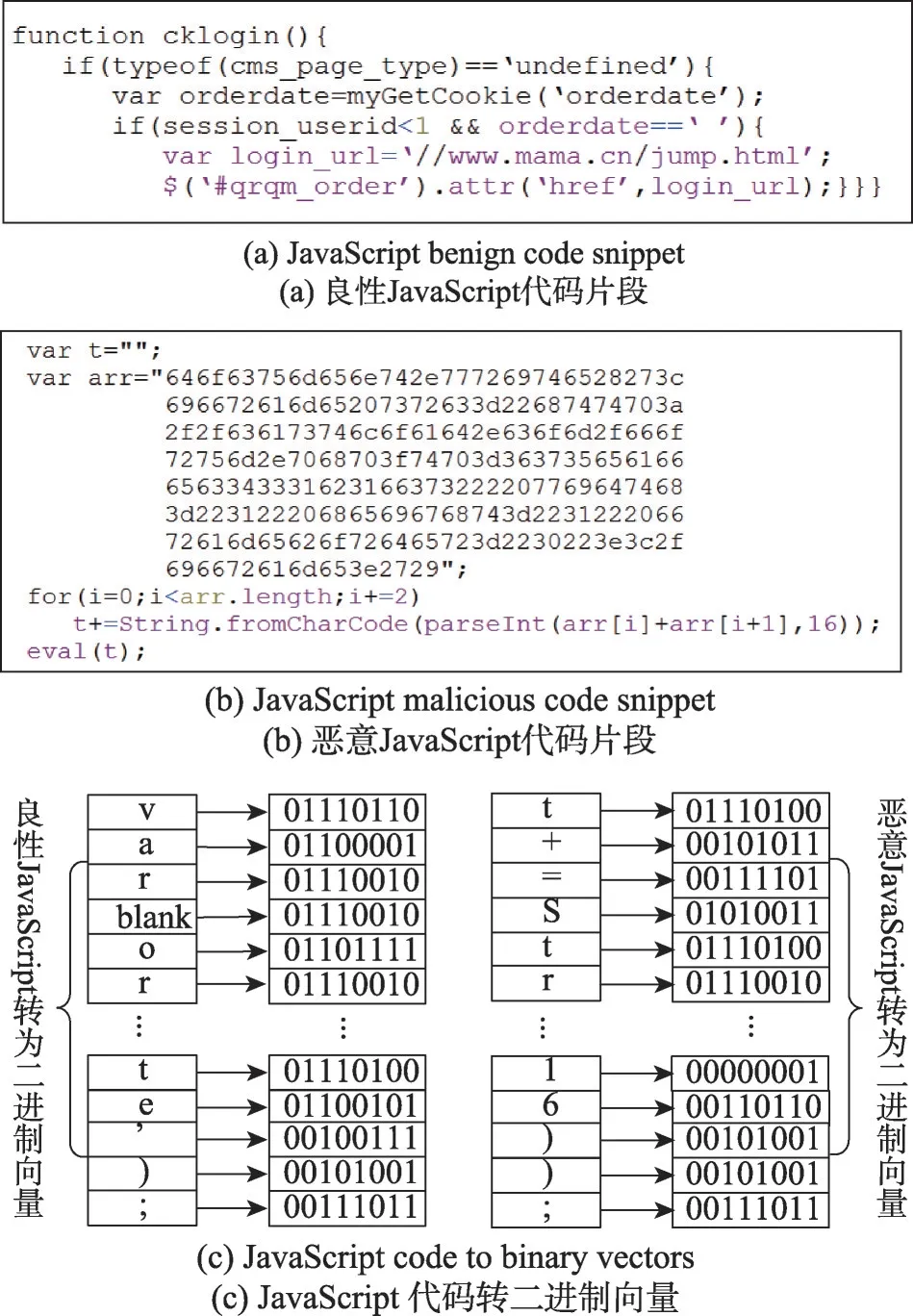
Fig.6 Data processing example图6 数据处理示例
(2)归一化
进行数值化处理之后,数据集中的数据转换为数值型数据,但数值型数据中数值差异较大,取值范围为0~255之间,数值差异较大容易引起网络收敛较慢和神经元输出饱和等问题,因此要对原始数据进行归一化处理。文中使用最大-最小归一化方法将数据集中的数据归一化到[0,1]区间之内,其公式为:

其中,x*为归一化后的数据,x为当前原始数据,xmin为当前属性中最小的数据值,xmax为当前属性中的最大数据值。
3.4 sSDAN的结构分析
在堆栈式稀疏降噪自编码学习过程中,网络参数的设置会对网络性能存在较大影响,因此,本文首先从网络层数和噪声系数大小探讨参数对网络性能的影响。
(1)网络层数
在选取过程中存在较大的主观性,没有统一的标准和要求,因此为了对比不同网络深度对整体分类性能的影响,本实验将网络层数分别设置2~6层进行对比。其中输入维度是1 000维,输出为50维,每个隐藏层节点设置为250,学习率0.01,将网络层从2变化至6,识别率如表2所示,30次误差迭代曲线图如图7所示。
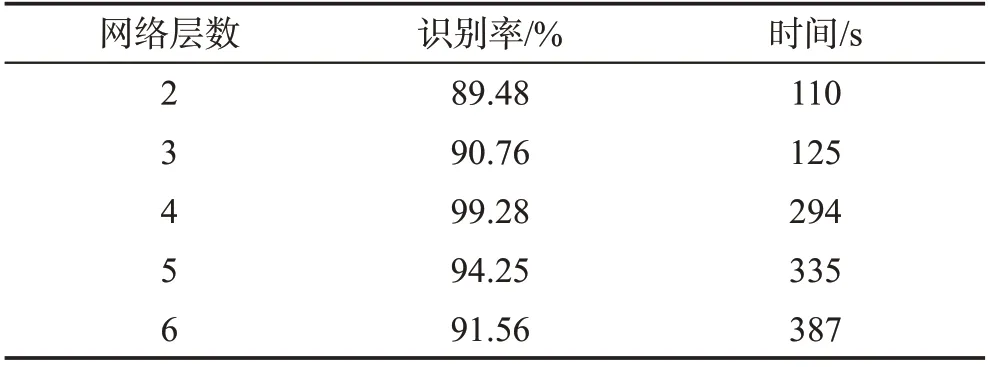
Table 2 sSDAN training of different structures表2 不同结构的sSDAN训练
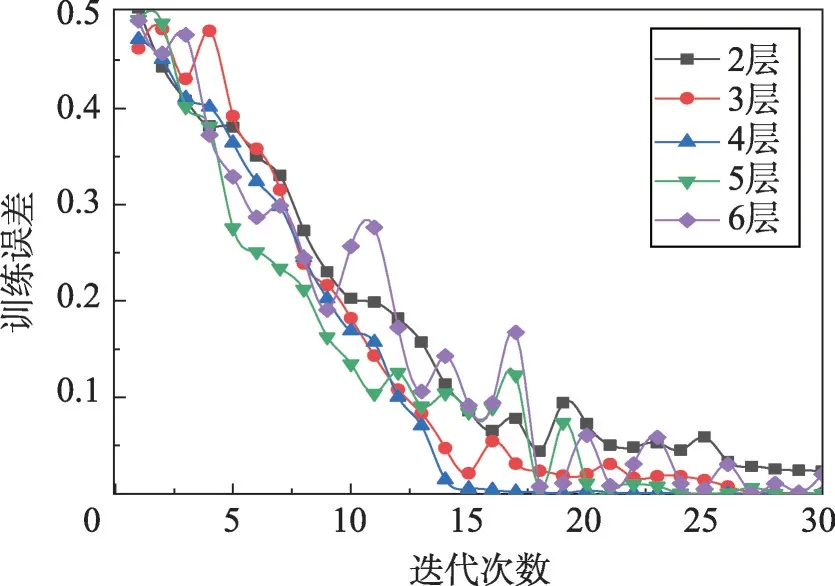
Fig.7 Local magnification of training loss function图7 局部训练损失函数放大图
从表2可以看出,当网络层数从2增加到4时,网络识别率呈现增长趋势,这是由于增加降噪编码层可以提高网络的学习性能,使得更高层次可以学习到更具有代表性的特征,当网络为4层时,识别率可达99.2%,但是当网络层数继续增大,识别率反而下降。从图7可以看出,网络层数小于4层时,网络收敛速度慢,当网络层次大于4时,网络误差震荡较大,这是因为网络过大时增加了网络的复杂度,导致网络不稳定,泛化性降低,容易出现过拟合。较浅或较深都会使误差增大。通常随着网络深度的增加,SDAN 的概括抽象能力也会增强。浅层的SDAN 网络由于网络层次较浅,导致概括抽象能力较差,容易损失较多的原始信息,从而使得训练误差较大;太过于深层的SDAN网络,随着深度的增加会导致抽取的信息过于抽象,使得原始数据的细节信息丢失,也会使训练误差增加。因而,本文选用具有4层结构的SDAN进行数据降维。
(2)噪声率
噪声率是控制降噪自编码网络中将输入随机隐藏为零的部分,即决定降噪自编码网络要通过多少节点对输入数据进行重构。如果噪声率为0.6,选择将输入数据的60%随机隐藏,用40%的节点对数据进行重构。在实际应用中隐藏输入的部分一般都要低于0.5,因此本实验中噪声系数率取最大为0.6,迭代次数100,学习率0.01。从图8可以看出,随噪声率的增加,识别率呈增长趋势。当噪声为0时,网络为传统的自编码神经网络,加入噪声后的网络性能明显优于传统自编码神经网络,当噪声系数为0.4时,可以从“被污染”的输入中学习到更鲁棒性的特征。

Fig.8 Experimental results of different noise coefficients图8 不同噪声系数值实验结果
图9给出了稀疏参数ρ与第一层自编码网络重构误差的关系。可以看出选择0.08的稀疏参数时的自编码网络的重构误差最小,加入0.4的随机噪声使得学习到的特征更具有鲁棒性,学习率为0.001,神经元激活函数为Relu。
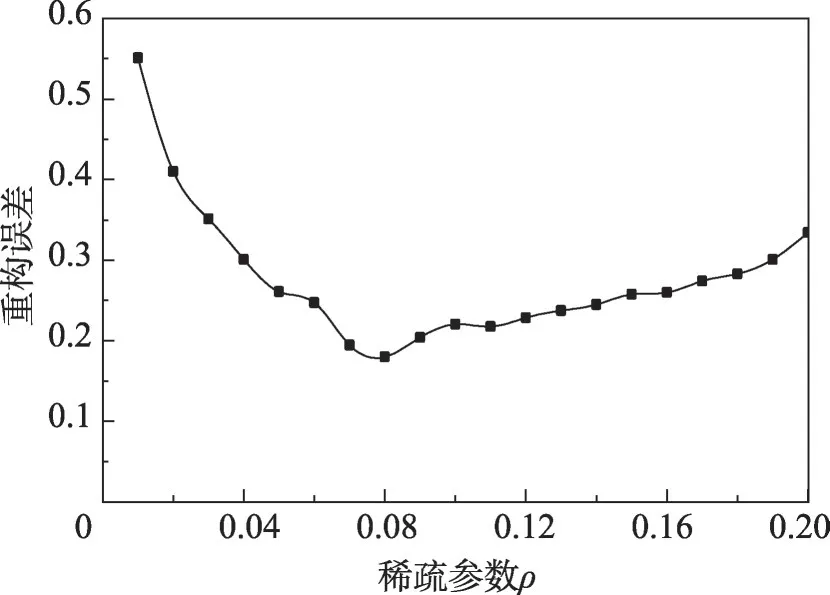
Fig.9 Reconstruction error图9 重构误差
在进行最终实验测试时,网络层数设定为4层,网络结构设置为1 000-500-250-125-50-2,首先要进行参数调优。目前对于参数调优并没有统一标准,大多数根据实验条件而定并通过对比分析参数的优劣,反复实验进行调优,最终确定的参数如表3所示。
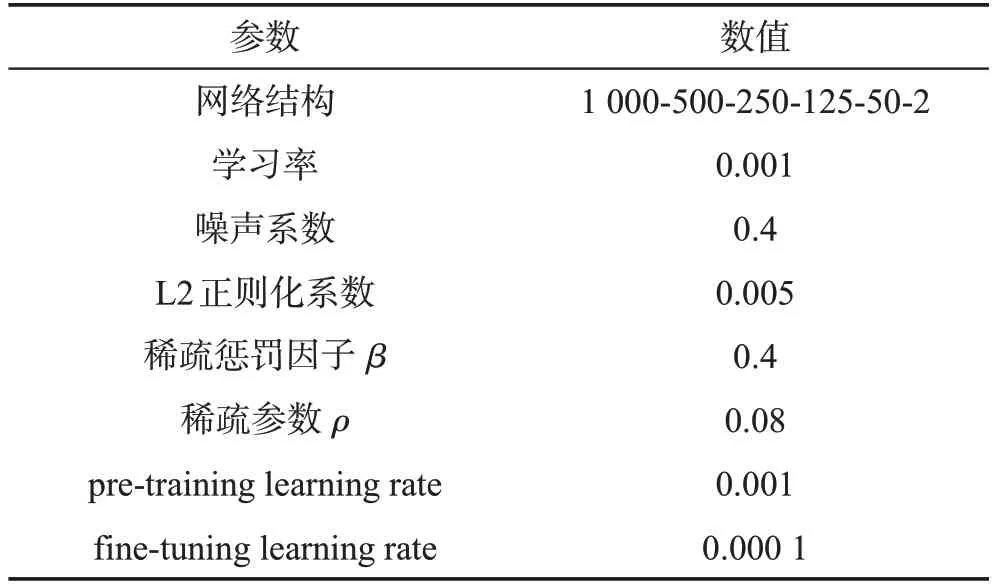
Table 3 Parameter setting of sSDAN表3 sSDAN参数设置
随后,将经过sSDAN降维后的数据作为Softmax神经网络的输入进行训练和预测。训练集和验证集的准确率和损失函数曲线分别如图10和图11所示,其中acc代表训练集的准确率,val_acc表示验证集的准确率,loss 和val_loss 分别代表训练集和验证集的损失函数曲线。从两组图像可知,检测曲线呈现稳定上升的趋势且训练准确率较高,代价函数值呈现稳定下降的趋势且训练误差较低,表明神经网络具有良好的训练效果。因此,本文选择1 000-500-250-125-50-2结构的sSDAN-softmax模型作为实验模型。

Fig.10 Accuracy curve图10 准确率曲线

Fig.11 Loss function curve图11 损失函数曲线
3.5 对比实验
本文定义恶意的JavaScript 代码样本为负样本,正常的JavaScript 代码为正样本,由此得到分类器列表,详见表4。

Table 4 Evaluation index confusion matrix表4 评价指标混淆矩阵
研究中,将通过准确率和误报率来评估检测性能,对其内容分述如下。
(1)准确率(Accuracy)。被正确检测出的样本数/测试集所有样本数,公式为:

(2)误报率(false positive rate,FPR)。错误分类为恶意的JavaScript良性代码所占比例的公式为:

为了从不同角度考察本文所提方法的有效性,本文设计3组不同的实验:(1)AN、DAN 和SDAN 在不同训练数据情况下的精确度变化;(2)sSDANsoftmax、sSDAN-LR 和sSDAN-SVM 的分类效果对比;(3)sSDAN-Softmax 与传统机器学习算法效果的对比,主要是对手工特征分类和自动提取特征方法进行对比,分别从CCR(correctly classified rate)、ICR(incorrectly classified rate)、TPR(true positive rate)和FPR进行比较。
将没有添加噪声的AE 与加了噪声的DAE(denoising autoencoder)和加了稀疏限制的SDAE(sparse denoising autoencoder)对不同训练数据进行训练,结果如图12。可以看出在不同训练数据下SDAE的精确度效果都要优于AE和DAE的。

Fig.12 Accuracy comparison of AE/DAE/SDAE under different training data sizes图12 不同训练数据下AE/DAE/SDAE的精确度对比
为了验证Softmax 的分类效果,增加LR 和SVM作为分类进行对比,即将所提的sSDAN-Softmax、sSDAN-LR 和sSDAN-SVM 模型进行分析和比较。隐藏层都设置为4层,噪声和学习率参数都设置一样,每训练10次取平均值作为一次输出,实验结果如图13所示,可以看出Softmax 的分类效果要高于LR和SVM。

Fig.13 Comparison of effects of different sSDAN classifiers图13 不同sSDAN分类器效果比较
选择机器学习算法平台WEKA 中的7种机器学习分类算法对代码样本进行训练和分类。采用十折交叉验证(10-fold cross-validation)方法,将数据集分成10份,轮流将其中9份作为训练数据,1份作为测试数据,进行实验。将10次的结果数据的平均值作为实验结果,机器学习和sSDAN模型实验结果如表5所示。

Table 5 Comparison between machine learning classification algorithm and sSDAN model表5 机器学习分类算法与sSDAN模型的对比
从表5中可以看出,机器学习方法算法分类中,Naïve Bayes 的效果最差,识别准确率仅为79.939%,错误率为20.061%;效果最好的是Random Forest,识别准确率为98.784%,错误率1.216%;但所提出的sSDAN 识别准确率达到99.501%,错误率仅为0.198%。可以得知使用无监督学习的sSDAN对恶意代码的检测要优于其他传统机器学习检测模型。
4 结束语
本文针对机器学习在人工提取恶意代码特征过程中耗时且检测准确率过于依赖特征选择的问题,提出一种基于堆栈式稀疏降噪自编码网络的JavaScript恶意代码检测方法。堆栈式稀疏降噪自编码网络是一种深层神经网络结构,通过隐藏层逐层抽取有效的信息,可以很好地进行特征降维和去除冗余特征。文中提出的sSDAN-Softmax检测模型综合使用了稀疏自编码网络和降噪自编码网络,有效提高了网络的泛化能力和降维特征的鲁棒性。实验结果表明,将JavaScript 代码转为数值型矢量作为堆栈式稀疏降噪自编码网络的输入,再使用sSDAN 对高维数据进行高维至低维的非线性映射,自动提取恶意代码的抽象特征,最后对低维数据进行神经网络训练和预测,相比于传统的机器学习算法,sSDANSoftmax 对JavaScript 恶意代码的检测依然有较高的准确率,并且误报率也有所下降。因此,sSDANSoftmax 检测模型不仅提高了恶意代码检测预测准确率,且加快了检测的速度,是一种适用于当前高维、复杂多变恶意代码的方法,可以为当前的恶意代码检测研究提供一种新的思路。
猜你喜欢
网络安全与数据管理(2022年1期)2022-08-29
小学生学习指导(中年级)(2021年12期)2021-12-30
锻压装备与制造技术(2021年5期)2021-11-13
科学技术创新(2021年5期)2021-03-17
——编码器
演艺科技(2020年7期)2020-08-13
汉字汉语研究(2020年2期)2020-08-13
电子制作(2019年22期)2020-01-14
疯狂英语·新读写(2018年3期)2018-11-29
新高考·高二数学(2016年7期)2017-01-23
股市动态分析(2016年17期)2016-10-20
