
面向数据流结构的指令内访存冲突优化研究
2019-12-18 07:23冯煜晶李文明叶笑春范东睿
计算机研究与发展 2019年12期
欧 焱 冯煜晶 李文明 叶笑春 王 达 范东睿
1(计算机体系结构国家重点实验室(中国科学院计算技术研究所)北京 100190)2(中国科学院大学计算机科学与技术学院 北京 100049)(ouyan@ict.ac.cn)
随着人工智能的飞速发展,其在社会发展中扮演着越来越重要的角色.现实生活中许多领域都需要用到人工智能,例如图像识别[1-4]、语音识别[5-7]、粒子加速分析[8-9]、DNA测序[10-11]等.这些应用均呈现出任务并发度高、数据量大等特征,要求计算系统能够高并发、强实时地处理计算请求.数据流结构作为专用计算领域的重要分支,表现出较好的性能和适用性[12-14],主要体现在3个方面:1)数据流中指令能否执行仅依赖于操作数是否准备好,不需要依赖程序计数器顺序执行[15],这种执行模式能最大限度地挖掘指令间的并行性;2)数据流结构中的执行单元内部仅有少数存储器和计算部件,没有乱序执行、分支预测等复杂控制逻辑,执行单元大部分面积都用于计算部件,使得执行单元的能耗比很高;3)数据流程序块间的数据交互直接在片上网络传递,减少共享存储的访问次数.因此,相比于传统的控制流执行模式,数据流执行模式可以取得更好的性能表现[16-17].
传统数据流结构主要分为粗粒度数据流结构和细粒度数据流结构:在粗粒度数据流结构中,如Teraflux[18],Runnemede[19]等,每个处理单元内的指令执行模式仍然为控制流执行模式,处理单元之间采用数据流执行模式;在细粒度数据流结构中,如TRIPS[20],WaveScalar[21]等,处理单元内部和处理单元之间均采用数据流执行模式.相比于细粒度数据流结构,粗粒度数据流结构更加节省片上存储资源,并能均衡数据流执行模式和控制流执行模式的特点[18-19].本文研究基于粗粒度数据流结构.
粗粒度数据流结构中,处理单元内部数据存储分为寄存器(register,REG)和随机访问存储器(random access memory,RAM).采用REG存储数据,当前时间拍的访存请求可以在当前时间拍获得数据响应;采用RAM存储数据,当前时间拍的访存请求只有在下一时间拍后才能获得数据响应.针对RAM访存数据延迟响应的问题,Stallings[22]实现了对RAM的流水访问,降低了数据平均访存延迟.由于相同存储空间的RAM占用的面积和功耗比REG少,为了减少芯片的存储资源开销,粗粒度数据流大都采用RAM作为数据的存储结构[18-19].
RAM由若干随机访问存储器块(RAM slice,RS)组成,采用RAM存储数据会存在RS的冲突访问,访存冲突主要分为2种:1)同一指令内部操作数访存冲突,如图1(a)所示;2)不同指令间操作数访存冲突,如图1(b)所示.操作数访存冲突对计算性能的影响尤为严重,指令内访存冲突越多,流水线停滞越多,使得计算部件利用率越低,导致程序的执行性能越低.本文主要针对指令内操作数访存冲突进行研究和优化.

Fig.1 Conflict types of RAM图1 RAM冲突类型示意图
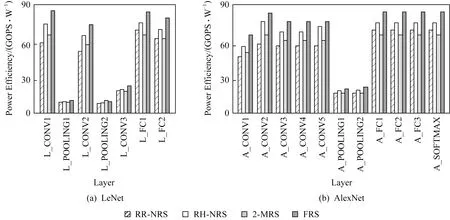
本文实现了1款粗粒度数据流加速器,并将神经网络LeNet,AlexNet移植到加速器上,如图2为各个网络层中具有指令内操作数访存冲突的指令数占比.各网络层均存在不同程度的访存冲突,网络层中数据的复用程度越高(如卷积层),具有访存冲突的指令数越多.数据流中常采用全数据冗余策略(multi-data redundancy strategy,MRS)[23-24]缓解指令内访存冲突问题,但是,全数据冗余策略大多没有对数据流结构的计算性能和硬件开销进行综合考虑.

Fig.2 Conflict instruction proportion of neutral network图2 神经网络冲突指令百分比
针对数据流指令内访存冲突问题,本文提出了灵活的数据冗余策略(flexible data redundancy strategy,FRS),能够为指令内有访存冲突的操作数申请数据冗余空间,重定向操作数访存地址至数据冗余空间中以解决访存冲突,降低了指令内操作数的访存延迟,提高了计算系统的能耗比.本文提出的架构可以用于数据中心[25]加速神经网络等应用.
本文的主要贡献有3个方面:
1)实现了一种粗粒度数据流加速器,量化分析了数据冗余策略对数据流加速器的计算性能和能耗比的影响.
2)针对指令内操作数访存冲突问题,提出了灵活的数据冗余策略.该策略由冗余数据申请机制、存储空间搜索算法和基于全局信息的回溯方法3部分组成.
3)对比了FRS与无数据冗余策略(none-data redundancy strategy,NRS)和MRS的实验结果.实验结果表明:FRS比基于Round-Robin数据映射算法和ReHash数据映射算法的无数据冗余策略能耗比分别提高了30.21%和12.37%,比2套全数据冗余策略能耗比提高了27.95%.
1 相关工作
为了降低指令内操作数访存延迟,需要将指令内的操作数映射到不同的RS块中,操作数访存时可以从独立RS块中并行读取数据.
传统编译器的数据映射方法主要是对Cache的访问冲突进行优化.Agarwal等人[26]提出了一种列相关Cache以解决Cache中数据冲突访问的问题.寄存器中的数据通过物理地址Hash得到需要访问的Cache行信息,列相关Cache中通过多种Hash函数寻找最佳替换策略,能够规避单一Hash函数局限导致Cache Line行频繁替换的问题.Juan等人[27]提出了一种分割高速缓存(split cache,SC),SC中实现了一种硬件机制及简单扩展的指令集,允许编译器动态地将物理Cache分割成若干数据大小不等的逻辑Cache,编译器将有潜在冲突的数据映射到不同的逻辑Cache,从而减少Cache的冲突访问.
现有的数据映射方法不适合数据流结构,主要体现在2方面:1)存储模型不同.Cache存储模型可看作少存储项可选,每个存储项具有无限存储空间,数据流存储模型可看作多存储项可选,每个存储项为有限存储空间.2)冲突类型不同.Cache访存冲突类型为单功能部件多访存请求分时访存冲突或多功能部件多访存请求同时访存冲突,数据流访存冲突类型为单功能部件多访存请求同时访存冲突.因此,现有的数据映射方法不再适用于数据流存储模型,数据流结构中常采用数据冗余策略缓解指令内访存冲突问题.
数据冗余策略是对存储空间的数据申请冗余存储空间.程序可见的操作数标识在物理存储中存在数据冗余,当产生指令内操作数访存冲突时,冲突的访存请求可以访问数据的冗余存储空间减少访存等待.多端口随机访问存储器(multi-port RAMs,MPRAMS)可实现数据流的全数据冗余策略MRS,同时满足实时数字信号处理需求[28-30],MRS是对程序可见的所有操作数标识均申请冗余存储空间.大量的科研工作对MPRAMS结构进行了改进,以减少全数据冗余策略的硬件开销.如Endo等人[31]提出了一种支持3级流水访问分时复用的多端口存储结构;Zhu等人[32]、Mattausch等人[33]在多核系统中基于单端口随机访问存储器(single-port RAMs,SPRAMS)交叉访问实现了MPRAMS,这些研究重点优化了基本的存储结构,在增大存储密度的同时,减少了数据访问延迟,并尽可能降低存储资源占用的面积和功耗.虽然全数据冗余策略可以降低指令内操作数访存延迟,但是其会存在无效的数据冗余,增加芯片的面积和功耗的开销.
2 粒度数据流加速器
本文基于粗粒度数据流结构实现了1款数据流加速器.本节首先介绍了数据流加速器的结构和数据冗余策略,然后建模分析了全数据冗余策略对数据流加速器的计算性能和能耗比产生的影响.
2.1 粗粒度数据流加速器概述
本文实现的粗粒度数据流加速器结构如图3所示,该结构由主处理器核(host core)、片外存储(memory)、直接内存存取部件(direct memory access)和数据流加速阵列(accelerator)构成.主处理器核运行操作系统和主程序;数据流阵列执行计算密集型的程序段.数据流加速阵列主要由逻辑控制部件(micro control,MiCC),4×4的处理单元阵列(PE array)、片上存储(scratch pad memory,SPM)和片上网络(network of chip,NoC)构成.逻辑控制部件负责对加速阵列上的应用进行激活和循环控制;处理单元执行被分配到的程序块;片上网络负责传递程序执行过程中产生的控制信号和数据;片上存储负责存储应用的指令和数据,并且支持并行处理来自PE阵列和外部DMA的访存请求[34].

Fig.3 Dataflow ACC structure图3 数据流加速器结构图
处理单元内部如图3所示,包括指令存储部件(instruction slots)、数据存储部件(data RAM)、指令发射部件(fire selection)、流水执行部件(execution pipeline)和数据打包部件.指令存储部件保存处理单元执行的指令信息;数据存储部件保存指令中的计算数据;指令发射部件为单指令顺序发射;流水执行部件执行计算指令;指令打包部件将流水线执行结果打包成网络传输的数据包格式,并发送到相邻处理单元的路由装置中.
2.2 粗粒度数据流加速器的数据冗余策略
粗粒度数据流主要包含2种数据冗余策略:1)无数据冗余策略,对多路访存请求进行串行处理;2)全数据冗余策略,对多路访存请求进行并行处理.本节将对这2种数据冗余策略的优缺点进行分析.
1)无数据冗余策略NRS.如图4(a)所示,NRS的存储空间由若干RS块组成,每块RS对应程序可见的1份操作数存储空间,每块RS只有1组地址访问端口,这组端口对应数据输出端口.NRS的优点为存储资源开销小,但是在同一时刻只能够处理1个访存请求,多余的请求需要进入FIFO队列,之后再由RS统一串行处理FIFO队列中的访存请求.
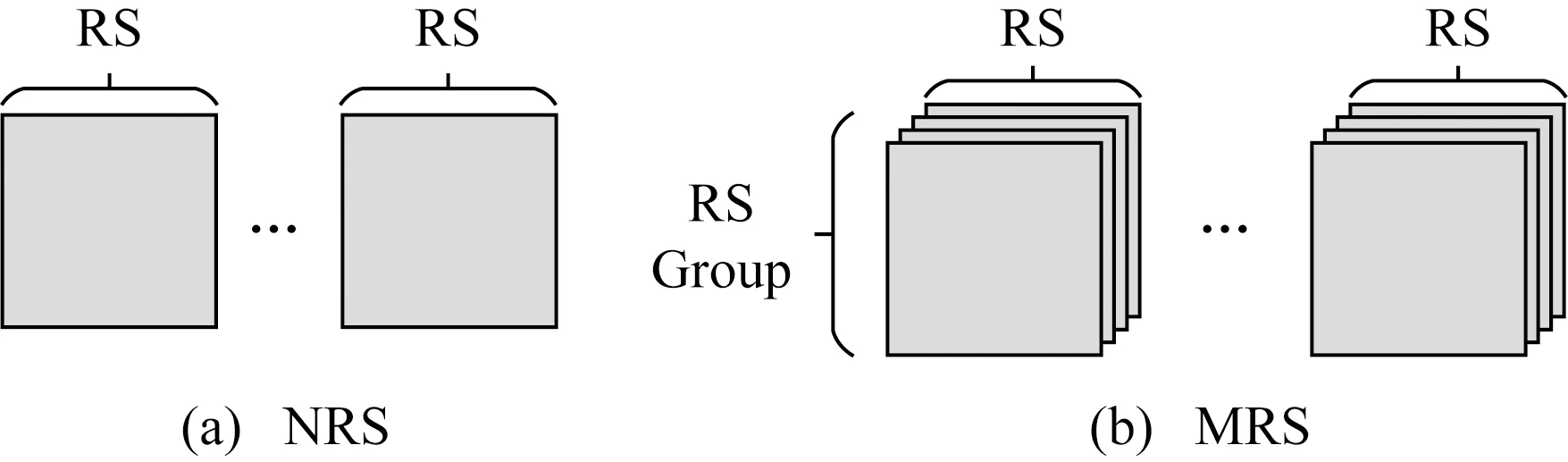
Fig.4 Data redundancy strategy图4 数据冗余策略
2)全数据冗余策略MRS.如图4(b)所示,MRS将存储空间分为若干RS组.RS组之间相互独立;每个RS组由若干大小相等的RS块组成,组内RS之间的据互为备份,当其中1块RS的数据发生改变时,由硬件电路保证组内其他的RS的数据做相同改变.N套全数据冗余策略(N-MBS)中,每个RS组由N块RS构成,每块RS对应1组地址访问端口,每组RS仅对应程序可见的1份操作数存储空间.MRS的优点为可并行处理多路访存请求,但是会增加存储资源开销,并且N套全数据冗余策略中仅有1套操作数存储空间对应用程序可见,存储资源的利用率很低.
由以上分析可得,虽然数据冗余策略能够缓解指令内访存冲突问题,提高计算性能,但是同样会增加计算系统的存储资源开销.
2.3 数据冗余策略模型分析
本节通过对全数据冗余策略进行建模,量化了全数据冗余策略对计算系统的性能和能耗比的影响.
本节理论分析做设定:1条指令能够最多含有K个操作数;程序中有Np,q(q≤p≤K)条含p个操作数的指令,且指令中存在q条操作数访存冲突.
假设RAM读取单位数据时间为twait,无访存冲突时,数据访存总时间Tassu为
Tassu=twait×N.
(1)
指令内存在访存冲突时,数据访存总时间Treal:
(2)
假设采用h套全数据冗余策略,则访存总时间Twait为

(3)
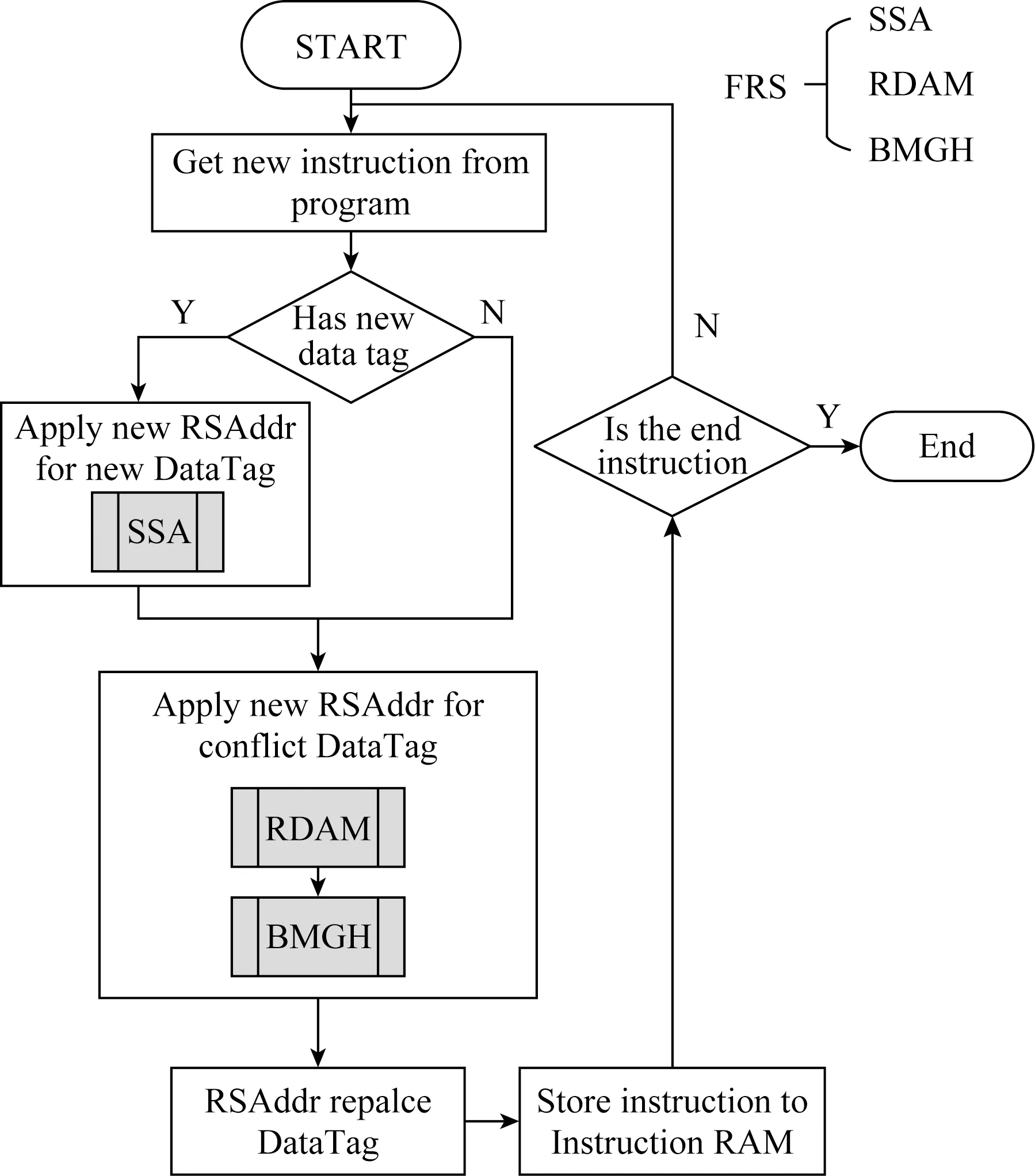
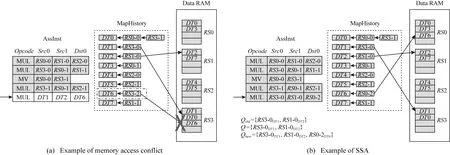
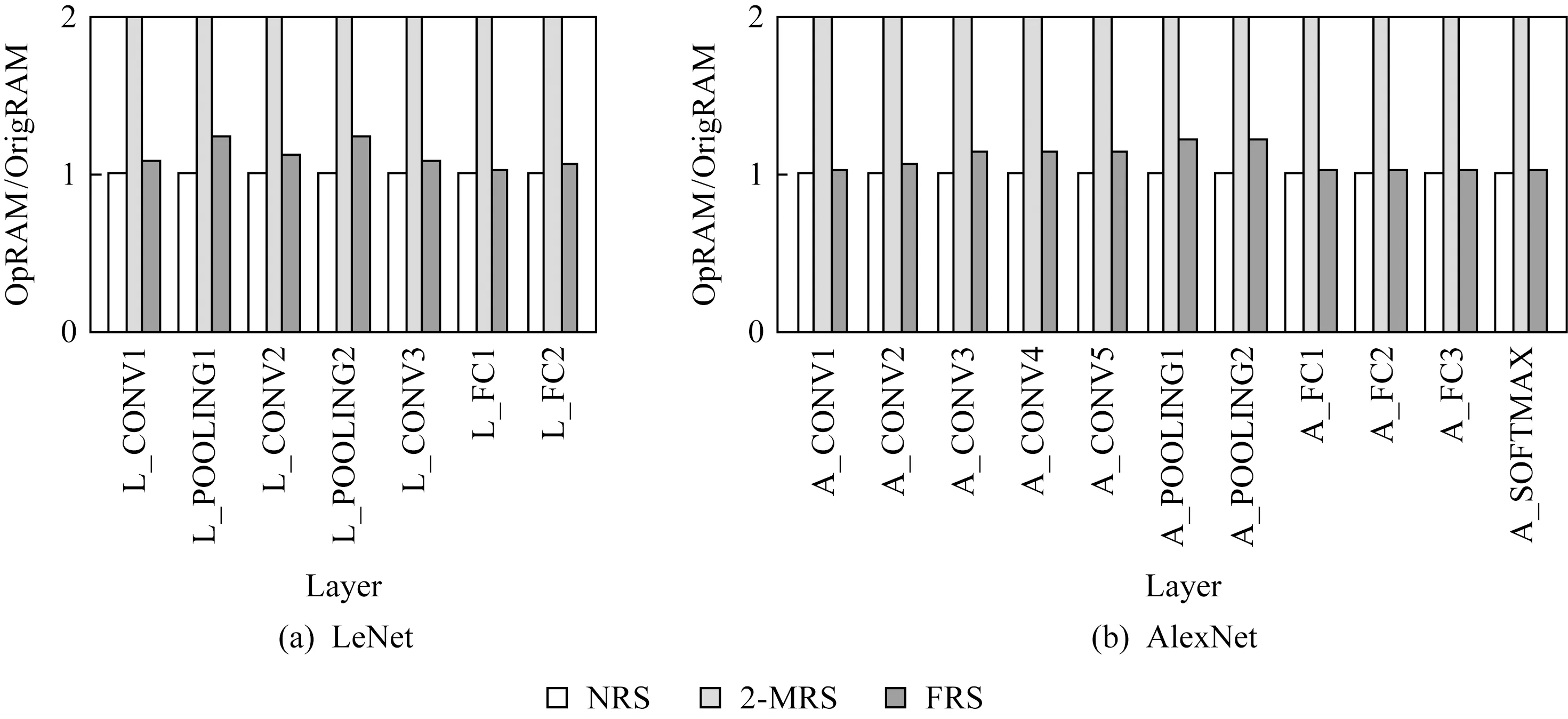
当h≥K时,数据访存总时间和理论访存总时间一致;当h 假定程序计算量为G,除了指令访存时间外,程序剩余执行时间为Telse,1份操作数存储空间的功耗开销为S,处理单元中其他硬件资源的功耗为E,则处理单元的能耗比U为 (4) 对于确定的负载和结构,G,S,E,Telse均为定值,且Twait随着h增加而降低.只有当数据冗余次数h满足条件h×S+E=Telse+Twait时,系统的能耗比达到最优. 由于全数据冗余策略中冗余次数只能取整,全数据冗余策略往往不能达到最优能耗比.此外,由于不同程序中指令类型和指令数量不同,采用固定冗余次数的全数据冗余策略无法适应程序动态场景的实时需求.因此,需要一种灵活的数据冗余策略,可以针对不同应用的访存需求,按需申请数据冗余空间. Fig.5 Compile process of dataflow program图5 数据流程序编译流程 针对指令内操作数访存冲突问题,本文基于NRS的存储结构实现了灵活的数据冗余策略(FRS),可以利用RAM中空闲的存储空间实现数据冗余,而不需要增加额外的硬件存储资源.数据流程序编译流程如图5所示,其中灰色部分为FRS增加的流程,在指令编译阶段,编译器使用RAM中的物理存储地址RSAddr替换指令中的操作数标识DataTag.FRS包括冗余数据申请机制(redundancy data application mechanism,RDAM)、存储空间搜索算法(storage search algorithm,SSA)和基于全局信息的回溯方法(backtracking method base on global histor,BMGH).当需要对1条指令进行地址替换时,采用SSA为新的操作数标识分配RS地址;采用RDAM为产生冲突的操作数标识申请数据冗余空间;采用BMGH优化全局数据冗余空间.本节主要是对FRS中的3个步骤的核心思想进行介绍,并结合实例对其进行补充说明. 在本节中,假设处理单元需要执行的指令如图6所示,图6(b)为图6(a)编译优化后的汇编指令,MUL为指令码,DT为操作数标识. Fig.6 Instruction sequence in PE图6 PE指令序列 本文定义了数据冗余指令,通过执行数据冗余指令,将同一操作数标识的数据映射到不同的RS块中,增加操作数标识的RS地址映射选择.如图7所示,其中SRC_ADDR代表原始数据的RS地址,DST_ADDR代表冗余数据的RS地址.因为数据冗余指令是将其中1个RS块的数据拷贝至其他RS块中,故MV指令不存在访存冲突. MVSRC_ADDRDST_ADDR Fig.8 Redundancy data application mechanism图8 冗余数据申请机制 Fig.7 Data redundancy instruction图7 数据冗余指令 如图8所示,AssInst为程序的汇编指令序列,灰色部分为已经完成RS地址替换的指令,箭头指向的指令为正在执行地址映射的指令,RS0-0代表该操作数标识已经被映射到RS0的0号地址,指令执行时需要从RS0块获取数据;MapHistory保存着操作数标识-RS地址的映射关系,每个操作数标识可对应多个RS地址,代表从这些RS地址中均可获取该操作数标识的数据;Data RAM为程序可见的存储空间.本节中,数据采用Round-Roubin算法,将如图6(b)中的操作数标识依次轮询映射到Data RAM中,如图8(a)所示,在编译到第3条指令时,发现DT0和DT3均需要从RS0中访问数据,产生操作数访存冲突. RDAM对访存冲突的操作数申请数据冗余空间.在对指令进行RS地址映射时,检测操作数已映射的地址集合是否有访存冲突.如果存在没有访存冲突的地址组合,则选取这个地址组合作为该指令中操作数的映射地址.如果检测到指令中存在访存冲突,则为访存冲突的操作数申请新的RS地址,如果新RS地址可以解决访存冲突,则采用新的RS地址作为指令中该操作数的映射地址,在MapHistory中增加新的映射记录,并在冲突指令之前加入数据冗余指令标明数据冗余操作.反之,如果新地址无法解决访存冲突问题,则使用初始地址集合中的地址组合作为该指令操作数映射地址. 当检测到如图8(a)中的访存冲突时,如图8(b)所示,编译器为DT0申请了新地址RS3-1,指令中的DT0,DT3,DT5可分别映射到RS3,RS0,RS2中,不会产生访存冲突.将RS3-1作为当前指令DT0的RS映射地址,并在当前指令前加入数据冗余指令,将RS0-0中的数据复制1份到RS3-1中.最后在MapHistory中为DT0加入新的地址记录,标志该指令之后,DT0从RS0-0或RS3-1都可以获得有效数据. 在实行RDAM时,如果存在对操作数标识更新数据的操作,则更新MapHistory中该指令的映射记录,仅保留数据最新的映射记录,并释放该操作数标识除最新映射记录外其他冗余数据占用的存储空间,确保编译器在对后续指令的操作标识进行RS地址映射时使用最新的MapHistory. RDAM需要对有访存冲突的操作数申请数据冗余空间,当处理单元内部的存储资源足够多时,RDAM可利用空闲的存储空间进行数据冗余;当处理单元内部的存储资源不够时,RDAM在编译阶段将数据流加速器上的应用进行拆分,缩小数据流加速器上单次计算的应用规模,为冗余数据预留出足够存储空间. 冗余数据申请机制的优势在于:1)RDAM仅对程序中存在访存冲突的数据申请冗余存储空间,减少了无效的数据冗余;2)数据冗余指令执行时间与原指令中访存冲突等待时间相同,没有额外指令执行时间损耗;3)新申请的冗余数据对所有后继指令可见,RDAM对操作数标识可实现“一次冗余,多次使用”,降低了热点数据的访存延迟. 在编译器为指令中操作数标识首次分配存储空间时,若仅根据操作数标识为其分配RS地址,会造成初次RS地址分配后产生操作数访存冲突的问题.如图9(a)所示,在编译源程序第4条指令时,按照Round-Robin方法,为DT6分配物理地址RS3-2,在分配地址之后,指令中的DT1与DT6出现访存冲突.因此,在为操作数首次分配RS地址时,需要综合考虑指令中其他操作数已分配的地址集合、存储资源使用情况等信息,合理安排数据存储空间.基于此,本文提出了存储空间搜索算法(storage search algorithm,SSA). Fig.9 Storage search algorithm图9 存储空间搜索算法 如图9(b)所示,编译器编译指令时,将指令中的操作数标识分为已映射操作数标识和未映射操作数标识2类;然后对已映射的操作数标识,获取其已映射的地址集合Qold,判断Qold中是否有访存冲突,若有访存冲突,则采用RDAM为其申请数据冗余空间,得到不会产生访存冲突的地址集合Q,若Qold中无访存冲突,则Q=Qold;对于每一个未映射的操作数标识,对RS按照剩余存储空间容量从大到小依次排序,依次选取大容量RS作为该操作数标识的RS地址,将新的RS地址加入到地址集合Q,得到新的地址集合Qnew,判断Qnew是否有访存冲突,若没有访存冲突,则选取当前的RS地址为该操作数的RS地址,并增加新的MapHistory记录.若Qnew仍然存在访存冲突,则依次检查其他小容量RS的RS地址是否能消除访存冲突;若所有RS地址均无法规避访存冲突,则选择最大容量的RS地址作为该操作数映射的RS地址. 如图9(b)所示,其中RS3-0DT1代表DT1可从RS3-0中取出数据,SSA将DT6映射至RS0-2中,指令内不产生操作数访存冲突,增加DT6的MapHistory记录,并将相关的物理地址替换指令中的操作数标识. SSA根据存储资源使用情况以及指令中操作数已映射的地址集合决定新操作数标识的RS地址,减少了为新操作数标识初次分配RS地址时产生的访存冲突,提高了存储资源的利用率. 虽然RDAM和SSA仅为有访存冲突的操作数申请冗余数据空间,但是其仍然会存在着无效的数据冗余,如图8(b)所示,DT0和DT3中存在访存冲突,采用RDAM为DT0申请了新的物理地址RS3-1,虽然解决了访存冲突问题,但DT0只映射至RS3-1中也可以解决MUL1中的访存冲突,RS0-0成为了DT0的冗余数据.这个问题的原因是RDAM和SSA仅依据当前存储资源的使用情况和MapHistory实现数据冗余,无法感知历史指令的映射信息,容易陷入局部最优的映射结果.基于此,本文提出了基于全局信息的回溯方法. 如图10所示,BMGH增加了操作数标识历史映射信息表RSInstHistory,用于记录每一个RS地址已映射的指令集合.当检测到指令中存在访存冲突时,首先采用RDAM为冲突访存的操作数申请新的物理地址Rnew;对于MapHistory中DT0每一个已映射物理地址Rold,搜索RSInstHistory中Rold的记录,判断址Rnew是否能够替代Rold:如果Rnew可以完全替代Rold而不会造成之前指令的访存冲突,则释放Rold地址空间,采用Rnew作为之前指令的操作数标识映射地址;如果Rnew无法完全替代Rold,则保留2个地址,并在该访存冲突指令之前增加数据冗余指令.如图10,DT0新申请的RS地址RS3-1可替换原有的RS地址RS0-0,释放RS0-0地址空间,指令中黄色块为RS3-1替换RS0-0映射的操作数标识. Fig.10 Backtracking method based on global history图10 基于全局信息的回溯方法 BMGH基于全局历史映射信息,通过判断操作数新物理地址对旧物理地址替换可能性,避免映射指令内操作数时陷入局部最优,消除了无效的数据冗余.优化了冗余数据的全局存储空间. 本文提出的指令内访存冲突优化方法包括RDAM,SSA,BMGH共3个部分.其中:RDAM为访存冲突的操作数申请数据冗余空间;SSA减少了为新操作数标识分配存储空间时产生的访存冲突;BMGH通过感知全局历史映射信息,优化操作数冗余空间. 本节主要介绍了实验平台及实验结果对比分析.实验主要从计算性能、硬件开销与能耗比等多个方面,对比了指令内访存冲突优化方法与无数据冗余策略、全数据冗余策略的实验结果.本文还基于数据流结构,实现了传统数据映射方法Round-Robin[35]和Re-Hash[25],并与本文提出的访存冲突优化方法做对比. 1)实验环境.本文使用中国科学院计算技术研究所自主研发的大规模并行模拟框架SimICT[36]作为实验平台,实现了2.1节中的数据流加速器.本文还使用硬件描述语言Verilog实现了数据流加速器,并采用TSMC的16 nm工艺和Synopsys公司的EDA工具进行功耗和面积评估.数据流加速器的结构如图3所示,表1为实验环境的各项具体参数. Table 1 Configuration of Dataflow ACC表1 数据流加速器配置 2)测试集.本实验选取LeNet,Alexet中典型神经网络层作为本文实验的测试集,并采用Eyeriss[37]的数据复用方法将神经网络层应用移植到数据流加速器上.选取的网络层包括:卷积层(CONV)、池化层(POOLING)、全连接层(FC)、SOFTMAX层,以上网络层计算时间占比达到了神经网络计算时间的95%以上.测试用例参数如表2所示,其中A代表AlexNet;L代表LeNet;H/W代表输入图像的高度和宽度;R/S代表卷积核的高度和宽度;P/Q代表输出图像的高度和宽度;C代表输入图像通道数;K代表卷积核个数;u/v代表卷积核计算步长. Table 2 Parameters of Workloads表2 测试用例参数 3)实验过程.数据流加速器的运行过程为:启动阶段,主处理器将加速器需要执行的指令和数据通过DMA拷贝到加速阵列缓存中,主处理器配置微控制器启动加速器;计算阵列完成计算任务后,由微控制器中断通知主处理器,主处理器再配置DMA将加速阵列计算结果数据拷贝回内存. 4)实验对象.本文在粗粒度数据流加速器上实现了灵活的数据冗余策略FRS,2套全数据冗余策略(2-MRS,每个数据存在2个数据冗余).并且实现了基于Round-Robin方法的无数据冗余策略RR-NRS和基于Re-Hash方法的无数据冗余策略RH-NRS. 5)性能指标.本节采用计算部件利用率评估数据流结构的计算性能.计算部件利用率越高,说明单位时间有越多的指令在处理单元中能够被发射执行,数据流结构的计算性能越高.计算部件利用率U: (5) 本节对比了FRS,RR-NRS,RH-NRS,2-MRS在执行不同神经网络层时的计算部件利用率. 如图11所示,FRS相较于RR-NRS,RH-NRS计算部件利用率平均提高了30.49%,12.61%.这是因为虽然RAM的存储空间足够大,但是可选择的RS块有限,而程序中存在大量的操作数标识,传统数据映射方法很难将大量的操作数标识独立映射到不同的RS块中,无法完全解决指令内的访存冲突问题,导致RR-NRS,RH-NRS的性能较FRS有性能下降.FRS在不同的网络层中较RR-NRS的计算部件利用率提升程度不一样.在池化层中,FRS的计算部件利用率比RR-NRS平均提高了20.62%,其原因在于池化层的数据复用程度很低,程序中有访存冲突的指令少,因此FRS相比于RR-NRS对计算部件利用率优化效果有限,而在卷积层中,FRS的计算部件利用率比RR-NRS的平均提高了43.1%,这是因为卷积层中数据的复用程度高,程序中有访存冲突的指令多,导致FRS的计算部件利用率较RR-NRS有较大的提升. Fig.11 Computing resource utilization comparison on RR-NRS,RH-NRS,2-MRS,FRS图11 RR-NRS,RH-NRS,2-MRS与本文提出的FRS计算部件利用率对比 如图11所示,FRS相较于2-MRS计算部件利用率平均降低了6.03%,这是因为2-MRS是由硬件机制实现数据冗余,加速器执行的指令数与原始程序的指令数相同,而FRS是在编译阶段通过添加数据冗余指令实现数据冗余操作,加速器除了执行原始程序的指令外,还需要执行增加的数据冗余指令,增加了程序的执行时间,导致了FRS较2-MRS有部分程度的性能下降.FRS虽然相较于2-MRS增加了数据冗余指令,但是仅有少量的性能损失.这是因为FRS具有“一次冗余,多次使用”的特性,使得因申请操作数空间而增加的数据冗余指令在总指令的占比很低,因此FRS和2-MRS的计算部件利用率相近. 如图12展示了FRS,NRS,2-MRS各网络层的操作数占用空间和原始程序的操作数占用空间的比值,其中OpRAM为实验对象操作数占用的存储空间,OrigRAM为原始程序操作数占用的存储空间.可以看出,NRS操作数占用的空间和原始程序的相同,这是因为NRS仅使用原始数据进行计算,因此没有额外的存储空间开销,而2-MRS操作数占用的空间为原始程序的200%,这是因为2-MRS为每一个操作数均申请了1个冗余数据空间.如图12所示,FRS操作数占用空间较NRS提高了11.1%,较2-MRS降低了44.46%.这是因为FRS仅对存在访问冲突的操作数标识申请数据冗余空间,且每一个数据冗余空间对全局程序可见. Fig.12 Storage requirement comparison on NRS,2-MRS,FRS图12 NRS,2-MRS与本文提出的FRS存储空间需求对比 如图13和图14展示了FRS,NRS,2-MRS所需的存储结构的面积功耗对比结果.其中FRS所需的面积与NRS的相同,功耗比NRS的平均增加了0.06%,这是FRS采用为编译优化的方法,不需要额外的存储资源开销,所以FRS与NRS的面积相同,而FRS比NRS增加的数据备份指令会增加访问RAM的动态功耗,但是由于FRS仅对访存冲突的数据进行冗余,且冗余数据对所有指令可见,所以FRS相比于NRS增加的功耗非常少.FRS相比于2-MRS的面积平均降低了48.83%,相比于2-MRS的功耗平均降低了48.90%,这是因为2-MRS对所有的存储空间都进行冗余,每个操作数标识需要2个物理地址进行存储,因此相同存储空间的2-MRS较FRS面积功耗开销多. Fig.13 Area comparison on NRS,2-MRS,FRS图13 NRS,2-MRS与本文提出的FRS面积对比 Fig.14 Power comparison on NRS,2-MRS,FRS图14 NRS,2-MRS与本文提出的FRS功耗对比 本节对数据流加速器中整体功耗进行评估,并结合4.2节中计算性能测试结果,计算得到FRS,RR-NRS,RH-NRS,2-MRS的能耗比.对比实验结果并进行理论分析. 计算机体系结构常用能耗比评估芯片的硬件效率,芯片的能耗比越高,说明单位功耗达到的性能越高,芯片的硬件效率越高.芯片能耗比V: (6) 如图15所示为FRS,RR-NRS,RH-NRS,2-MRS的能耗比的对比结果,其中FRS的能耗比分别比RR-NRS,RH-NRS,2-MRS平均提高了30.21%,12.37%,27.95%.在处理单元内部,操作数存储空间的能耗占比达到了34.67%.虽然全数据冗余策略能够提高程序的执行性能,但是却大幅度提高了计算系统的功耗,造成计算系统的能耗比下降,在数据复用度低的网络层中(如POOLING和FC),其带来的性能提升甚至不能弥补增加的功耗.FRS的能耗比提升主要源于2个方面:一方面是因为FRS实现了数据冗余方法,缩短了指令内操作数访存延迟,提高了计算部件利用率;另一方面是FRS基于NRS的存储结构,在指令编译阶段预留出数据冗余空间,不需要额外的存储支持,降低了存储资源的硬件开销. Fig.15 Power efficiency comparison for RR-NRS,RH-NRS,2-MRS,FRS图15 RR-NRS,RH-NRS,2-MRS与本文提出的FRS能耗比对 本文研究了粗粒度数据流架构中处理单元内部存储结构的特点,分析了指令操作数访存冲突对于程序计算性能和能耗比的影响.基于无数据冗余策略的存储结构提出并实现了指令内访存冲突优化方法.该方法能够感知指令内部操作数访存冲突,为访存冲突操作数动态申请数据冗余空间,重定向操作数访存地址至数据冗余空间解决访存冲突.本文还在冗余数据申请机制基础上,提出了存储空间搜索算法和基于全局信息的回溯方法,通过感知物理存储的使用情况和全局操作数历史映射信息,优化了全局数据冗余空间,提高了数据流结构的能耗比. 实验结果表明:采用本文提出的指令冲突优化方法,能耗比相对于Round-Robin,ReHash的无数据冗余策略分别提高了30.21%,12.37%,相比于2套全数据冗余策略能耗比提高了27.95%. 本文的后续研究将是针对数据流中的访存冲突进一步优化,结合存储受限和多流水线等复杂情况,进一步提高数据流加速器的能耗比.
3 指令内访存冲突优化方法

3.1 冗余数据申请机制



3.2 存储空间搜索算法
3.3 基于全局信息的回溯方法

4 实验评估
4.1 实验平台



4.2 程序执行性能

4.3 硬件开销
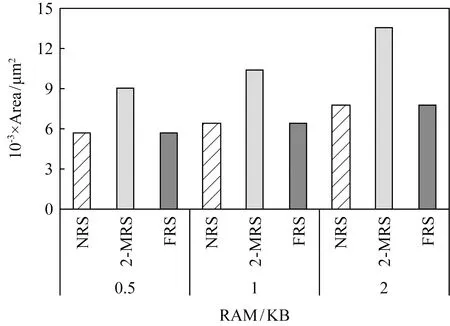

4.4 能耗比分析

5 总 结
猜你喜欢
现代装饰(2022年5期)2022-10-13
航空学报(2022年7期)2022-09-05
小哥白尼(趣味科学)(2022年5期)2022-08-15
智能计算机与应用(2021年6期)2021-12-17
少先队活动(2021年6期)2021-07-22
汽车维修与保养(2020年10期)2021-01-22
综艺报(2020年21期)2020-11-30
汽车维修与保养(2020年11期)2020-06-09
计算机技术与发展(2020年5期)2020-05-22
电脑爱好者(2019年17期)2019-10-30
