
基于跨域对抗学习的零样本分类
2019-12-18 07:22郑庆华罗敏楠赵洪科吕彦章
计算机研究与发展 2019年12期
刘 欢 郑庆华 罗敏楠 赵洪科 肖 阳 吕彦章
1(西安交通大学计算机科学与技术学院 西安 710049)2(天津大学管理与经济学部 天津 300072)3(综合业务网国家重点实验室(西安电子科技大学)西安 710071)(huanliucs@gmail.com)
随着深度神经网络的快速发展和面向特定任务大规模标记数据集的构建,基于监督学习的视觉数据分类研究近期取得了重大的进展[1-5].然而,在现实世界中,视觉数据的分布呈现出显著的长尾效应,大量的类别具有很少、甚至没有用于训练的样本,导致分类任务依然复杂且具有挑战性.而相比于计算机需要一定数量的样本才能完成分类模型的训练,人类却能够在不看任何样本的情况下学习新的类别,即只阅读类别的语义描述.借鉴人类的这种学习能力,一种新的范式[6],即零样本学习(zero-shot learning,ZSL)被提出用以识别未见过训练样本的新类别.
传统的零样本学习方法主要目标是建立视觉和语义特征空间之间的跨模态映射函数,包括视觉到语义的映射[7-11]、语义到视觉的映射[12-14]以及视觉和语义到公共空间的映射[15-18]等.但是,由于视觉和语义空间存在明显的模态鸿沟,在它们之间进行嵌入会造成信息损失问题;另外,由于可见类和未见类的数据分布不同,基于映射函数的方法也导致未见类的识别高度偏向于可见类.为了缓解这些问题,借助于深度生成网络[19-20],尤其是跨模态生成网络[21-24],一系列面向零样本学习的生成模型[25-30]被提出基于语义信息为未见类合成训练样本.与传统方法通过间接的映射方式处理未见类数据不同,生成模型能够利用合成的未见类假样本直接训练一个针对未见类的分类器,从而将零样本分类问题转换为经典的监督学习问题.
根据采用的生成机制不同,面向零样本学习的生成模型一般分为2类:基于生成对抗网络(gener-ative adversarial nets,GANs)的生成模型[25-28]和基于变分自编码器(variational auto-encoder,VAE)的生成模型[29-30],这2种方法的特点各不相同.生成对抗网络合成的样本相对清晰,比较逼真,但是由于训练过程不稳定,部分生成的样本会严重偏离真实的数据分布,导致模式崩塌问题,如图1(b)所示.与生成对抗网络不同,变分自编码器的训练过程相对稳定,然而由于如何评判重构样本和原始样本是否接近比较困难,导致合成的样本虽然比较均匀,却相对模糊,如图1(c)所示.

Fig.1 Real images and two kinds of synthetic images of celebrity faces图1 名人人脸真实图片和2种合成图片
为了利用生成对抗网络和变分自编码器各自的优势,最近的研究工作提出通过共享前者的生成器和后者的解码器,将这2种生成模型整合到一个统一的框架(联合模型)中[31-34],进而学习互补信息,提高合成样本的能力.但是,由于生成器和解码器的输入分别为随机高斯噪音和原始数据的隐变量表示,经过联合模型中共享生成器/解码器合成的数据不再满足各自单一的数据分布,而是遵循复杂的多域分布,该分布包含来自生成器域的假样本(如图1(b))和来自解码器域的假样本(如图1(c)).
为了解决这个问题,提出跨域对抗生成网络(cross -domain adversarial generative network,CrossD -AGN),将传统生成对抗网络(GANs)和变分自编码器(VAE)有机地结合,基于类级语义信息为未见类合成接近真实数据分布的样本,进而实现零样本分类.首先,通过共享生成器和解码器构建联合模型,该联合模型能够同时利用生成对抗网络和变分自编码器的优势,学习互补信息;其次,针对联合模型中共享生成器/解码器合成的多域数据分布问题,提出跨域对抗学习的训练机制.通过引入2个对称的跨域判别器,分别学习判断合成样本是来自生成器域分布还是解码器域分布.这样的竞争方式促使联合模型不断优化其生成器/解码器,直到无法区分合成的样本来自哪个域分布为止,进而提高联合模型的样本生成能力.值得注意的是,本文研究的“域”与迁移学习中的“域”是不相同的。前者是“模型的域”,即对于相同语义类别,不同生成模型的合成数据分布域不同;而后者则是“数据集的域”,即对于不同语义类别,用源域中学到的知识帮助解决目标域中的任务.
本文的主要贡献有3个方面:
1)提出了一个面向零样本分类的联合生成模型,该联合模型能够将传统生成对抗网络和变分自编码器有机地结合起来,学习互补信息;
2)引入2个对称的跨域判别器,并采用对抗学习机制,通过学习判定合成样本的分布域来源,促使生成器/解码器不断优化,提高生成能力;
3)在4个真实视频数据集上进行了大量的零样本学习实验.与最先进的算法相比,提出的模型在2个评价指标上分别取得了2.7%和3.2%的提升.
1 相关工作
1.1 零样本学习
本节介绍关于零样本学习的研究工作.早期的零样本学习主要集中于在视觉空间和语义空间之间学习一个跨模态的映射函数,包括视觉到语义的映射[7-11]、语义到视觉的映射[12-14]以及视觉和语义到公共空间的映射[15-18]等.例如在视觉-语义映射方面,Frome等人[9]提出深度视觉-语义嵌入模型(DeViSE)将图像显式地映射到丰富的语义空间中,并利用文本数据学习标签之间的语义关系,以识别未见类视觉对象.而语义-视觉映射与之相反,例如在文献[13]中,将视觉空间作为嵌入空间来缓解枢纽问题(hubness problem),提高算法的效率.此外,Kodirov等人[18]提出将视觉特征和标签特征同时映射到一个属性空间中,然后利用无监督领域自适应算法来克服领域漂移问题(domain shift problem).
最近,借助于深度生成网络[19-20],一系列面向零样本学习的生成模型[25-30]被提出基于语义信息为未见类合成训练样本.相比早期的映射方法,利用合成的未见类假样本,生成类模型将零样本学习转换为传统的监督学习任务,并取得了极大的突破.根据使用的基础模型的不同,零样本学习生成模型可以分为2种:1)GANs类生成模型[25-28],利用对抗学习机制,训练生成器来合成未见类样本.例如,文献[24]提出将GANs和分类误差结合来生成具有显著区分性的视觉特征.2)VAE类生成模型[29-30],基于编码-解码机制,利用解码器从隐变量重构样本.例如Mishra等人[29]通过引入类别信息,训练VAE来学习符合标签语义的图像潜在概率分布.
最新的研究将这2种生成模型结合起来,提出了针对零样本学习的VAE-GAN联合框架[31-34],希望能够利用他们各自的优势(前者训练过程稳定,后者生成的样本清晰逼真).但是,联合模型生成的样本遵循复杂的多域分布而现有方法忽视了这个问题,所以亟需能够对多域数据分布进行建模的算法.
1.2 神经生成网络
本节叙述关于神经生成网络的研究工作.基于VAE和GANs,尤其是后者,大量有趣的应用如雨后春笋般涌现.考虑到本研究的目标是从语义信息出发合成视觉样本,我们主要回顾生成网络社区中与跨模态生成和增强训练过程稳定性相关的研究.
条件生成对抗网络(CGAN)[21]和条件变分自编码器(CVAE)[22]首先提出通过给定分类器和判别器(编码器和解码器)类标签来控制生成的样本符合特定的语义分布.基于此,后续的研究人员将离散的类别标签拓展到了属性向量和文本描述.例如为了获得包含必要细节和生动对象的视觉样本,文献[23-24,35]提出直接利用文本描述而不是类标签或者视觉属性来合成高分辨率图像.与此同时,大量研究致力于缓解原始生成对抗机制存在的梯度爆炸/消失和模式崩塌等问题.Salimans等人[36]提出了特征匹配、单侧标签平滑和虚拟批量标准化等实用技术来促进生成对抗网络在训练阶段的收敛.为了避免梯度消失问题,Arjovsky等人[37]提出使用Wasserstein距离替代原始的损失函数来衡量真假样本数据分布之间的距离,并通过简单的判别器参数裁剪实现.为了不降低判别器的能力,他们进一步改进了上述模型,提出了WGAN-GP[38],用梯度惩罚项替代参数裁剪操作.
显然,条件生成网络(CVAE,CGAN)和改进的生成对抗训练机制(WGAN-GP)为稳定地合成具有丰富语义的视觉样本提供了巨大的可能性.因此,本文在联合模型中使用类级语义信息作为条件输入,并利用Wasserstein距离和梯度惩罚项进行训练.
2 跨域对抗生成网络
本节主要介绍跨域对抗生成网络在零样本分类问题中的应用.给出了问题的定义;提出了的跨域对抗生成网络;描述了零样本分类的测试过程.本文中使用的符号和变量名如表1所示:

Table 1 Nomenclature表1 术语表
2.1 问题定义

2.2 跨域对抗生成网络
本节详细介绍跨域对抗生成网络(CrossD -AGN),如图2所示,跨域对抗生成网络包含4组部件:编码器E、生成器G(解码器Dec)、真假判别器D以及跨域判别器D1和D2.由于跨域对抗生成网络结合了生成对抗网络和变分自编码器各自的优势来合成样本,因此在所提出的模型中,来自生成对抗网络的生成器G和来自变分自编码器的解码器Dec是相同的,共享参数.
首先介绍生成器G和真假判别器D.跨域对抗生成网络中的生成器G和真假判别器D来源于传统的生成对抗网络,他们通过互相博弈进行学习.判别器D的目的是判断一个样本来自真实的数据分布还是生成器G生成的假分布,而生成器G则努力生成无法被检测为假的样本.两者相互对抗,不断优化自身参数,直到判别器D无法判断生成器G生成的样本是否真实.由于传统生成对抗网络的训练过程非常不稳定,文献[38]提出WGAN-GP模型,即利用Wasserstein距离和梯度惩罚项来缓解梯度爆炸和模式崩塌等问题,目标函数为

(1)

Fig.2 Framework of the proposed cross-domain adversarial generative network图2 跨域对抗生成网络的框架
另外,为了生成具有特定语义含义的样本,本文遵循条件生成对抗网络[21](CGAN)的做法,将语义编码同时集成到生成器G和判别器D中.因此,利用Wasserstein距离和梯度惩罚项,基于类级语义信息φt,在CrossD-AGN中,生成器G的目标是最小化损失函数:

(2)


(3)

跨域对抗生成网络中的编码器E和解码器Dec来源于传统的变分自编码器,旨在通过编码-解码的训练机制,能够从符合特定分布的隐变量生成图像等样本.具体来说,编码器E将原始数据转化为一个符合特定分布的隐变量,解码器Dec基于此隐变量重构原始输入,目标函数为

(4)
式(4)中等号右边第1项为重构误差:

(5)
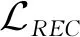

(6)
用来计算隐变量分布和标准正态分布的距离.
最后,通过引入2个对称的跨域辨别器D1和D2来将传统的生成对抗网络和变分自编码器有机地结合起来.生成对抗网络和变分自编码器都有合成样本的能力,但他们生成的特点不同.生成对抗网络合成的样本相对清晰,但是由于训练过程不稳定,部分生成的样本会严重偏离真实的数据分布,如图1(b)所示.与生成对抗网络不同,变分自编码器的训练过程相对稳定,然而由于如何评判重构样本和原始样本是否接近比较困难,导致合成的样本相对模糊,如图1(c)所示.因此,结合生成对抗网络和变分自编码器能够学习互补信息,提高生成样本的能力.但是,生成器和解码器的输入分别为随机高斯噪音zp和原始数据的隐变量表示zf,由生成器/解码器合成的数据不再满足单一的分布,而是遵循复杂的多域分布,该分布包含来自生成器域的假样本和来自解码器域的假样本.因此,为了更好地利用生成对抗网络和变分自编码器的优点来合成样本,提出跨域对抗学习的训练策略,对生成数据的域分布进行区分和建模.
将解码器域假样本xf作为真实数据,生成器域假样本xp作为合成数据,使用对抗学习的训练机制,可以得到第1个跨域对抗损失函数:

(7)
其中,pDec和pG分别为解码器域的分布和生成器域的分布.这里的第1个跨域生成器即对抗生成网络中的生成器G,目标是最小化损失函数:

(8)
第1个跨域判别器D1的目标是最小化损失函数:

(9)
相应地,将生成器域假样本xp作为真实数据,解码器域假样本xf作为生成数据,可以得到第2个跨域对抗损失函数:

(10)
这里的第2个跨域生成器即变分自编码器中的解码器Dec,目标是最小化损失函数:

(11)


(12)
总体目标函数.综上所述,跨域对抗生成网络(CrossD-AGN)的最终目标是最小化损失函数:

(13)

算法1.跨域对抗生成网络(CrossD-AGN)的训练过程.
输入:训练过程迭代次数Nsted、批大小m、每次训练迭代中判别器的更新次数ncritic、梯度惩罚系数λ、损失函数中的权重系数γ1和γ2、Adam优化器的超参α,β1和β2、初始化编码器θE、生成器(解码器)θG(θDec)、真假判别器θD、跨域判别器θD1和θD2;
① foriter=1,2,…,Nsteddo
② forj=1,2,…,ncriticdo
③ 采样一批(m个)真实数据x及其对应的语义编码φt、随机高斯噪音zp、随机数ε;
④ 合成生成器域假样本xp←G(zp,φt);
⑧ 计算编码器隐变量zf←E(x,φt);
⑨ 合成解码器域假样本xf←Dec(zf,φt);
2.3 零样本分类


(14)
最后,在测试阶段,给定一个真实的未见类样本xu和最优Softmax分类器θ*,该样本的预测标签为

(15)
鉴于所提出的框架能够基于语义编码生成语义相关的视觉样本,因此整个训练和测试过程易于扩展到其他应用,例如零样本视频检索.
3 实验与结果
本节描述了实验数据集、对比方法、实验设置、定性与定量分析以及敏感性分析.
3.1 数据集和实验设置
3.1.1 数据集及划分
使用4个公开的视频数据集进行实验,图3给出了一些例子.

Fig.3 Example videos from four datasets used in this paper图3 本文中使用的数据集视频示例
1)Olympic Sports[39].它是一个具有16种类别的体育运动数据集,其中每个种类包含50个YouTube视频.每种运动包含的动作都比较复杂,如“撑杆跳”和“三级跳”等.
2)CCV[40].它是一个包含20个种类的网络用户视频数据集,共有9 317个用户视频.类别分为事件(如“游行”)、场景(如“沙滩”)和目标对象(如“狗”)等.
3)HMDB51[41].它是一个人类日常行为视频数据集,包含51个类别,共有7 000个电影片段或Internet视频.类别可以分为5组:一般面部动作如“笑”、操作物体的面部动作如“吃”、一般身体动作如“爬”、操作物体的身体动作如“打高尔夫”以及身体互动动作如“拥抱”.
4)UCF101[42].它是一个共有101个类和13 320个YouTube视频的行为识别数据集.101个类别包括人与物交互如“刷牙”、身体动作如“攀岩”、人与人交互如“剪头发”、演奏乐器如“弹钢琴”以及运动如“滑雪”等.
本文遵循文献[43]提出的零样本视频分类数据划分方法.具体来说,对于每一个数据集,共随机生成了50个划分.在每一个划分中,用50%的类别作为可见类,剩余的50%的类作为未见类.
3.1.2 度量标准
对于零样本视频分类,在每个数据划分中,用平均top-1准确率来度量模型性能,定义:
(16)
其中,c为类别.所以,对于每个数据集,本文在实验中报告所有50个划分平均top-1准确率的均值和标准差.
对于零样本视频检索,在每个数据划分中,用平均精度均值(map)来度量模型性能,定义:
(17)

3.1.3 特征提取
给定一个视频,首先从中抽取20个视频片段,每个视频片段包含16个帧.每个视频帧为3通道(RGB)的图片,大小调整为112×112,并以50%的概率进行水平翻转.因此,每个视频片段最后表示为维度为3×16×112×112的张量.紧接着,将视频片段输入3D Resnet34[44]网络来抽取该片段的视觉特征.使用的3D Resnet34网络在包含超过300 000个视频,多达400个类的Kinetics[45]数据集上进行了预训练,得到的视觉特征是网络中3D平均池化层的输出,维度为512维.最后,计算一个视频所有20个视频片段视觉特征的平均值,得到该视频的视觉特征.
给定一个类的语义信息,采用skip-gram[46]语言模型来生成语义编码.该模型在包含大约1 000亿个单词的Google新闻数据集上进行了预训练,并生成300维的编码向量.
3.1.4 实现细节
本节描述所提出神经网络的实现细节、目标函数中的权重系数以及训练过程的超参.所有的神经网络都由多层感知机(MLP)组成.具体来说,编码器E、生成器G(解码器Dec)、真假判别器D以及2个跨域判别器D1和D2都包含一个1024维的隐层.除了生成器G的输出层使用Sigmoid函数作为激活函数外,其余网络的隐层都使用LeakyReLU函数进行非线性映射.所有网络的参数都使用Xavier方法进行初始化.
为了得到最佳的实验性能,实验中经验地设置目标函数中的λ为10,γ1和γ2为0.01,随机高斯噪音的维度为300维.使用Adam优化器来训练模型,学习率为0.001,批大小为64.为每个未见类合成100个视觉特征.所有的神经网络都是基于Pytorch平台进行开发的.
3.2 对比方法
将所提出模型和9种方法进行了对比:
1)语义编码凸组合模型(ConSE)[47].ConSE通过对类标签编码进行凸组合,将图片映射到语义空间,从而实现零样本分类.
2)结构化联合编码模型(SJE)[8].SJE首先学习一个图片和类标签之间的相容函数,然后搜索产生最高相容分数的标签来对未见图片进行分类.
3)流形正则化回归模型(MR)[43].MR利用流形正则化、自训练和数据增广等技术,增强图片到语义空间的映射,从而实现零样本分类.
4)语义自编码器(SAE)[11].SAE采用编码-解码机制将视觉特征映射到类标签语义空间中,并完成语义空间到视觉特征的重构,从而能够将未见图片进行分类.
5)条件变分自编码器(CVAE)[22].CVAE利用变分自编码器基于语义编码生成视觉特征,并利用合成的未见类数据完成零样本分类.
6)条件对抗生成网络(CWGAN)[38].CWGAN采用Wassertein距离度量真假样本的距离,并且能够基于语义编码生成视觉特征,从而能够训练未见类分类器实现零样本分类.
7)细类度图像生成网络(CVAEGAN-FM)[32].CVAEGAN-FM结合VAE和GAN各自的优点,利用特征匹配技术使训练过程稳定,进而基于语义信息合成更加清晰和真实的图像.
8)零样本学习联合生成模型(CVAEGAN-PR)[33].CVAEGAN-PR在CVAEGAN-FM的基础上,引入了感知重构误差,以此增强生成模型合成视觉特征的能力.
9)任意样本学习特征生成网络(CVAEWGAN)[34].CVAEWGAN提出将VAE和WGAN进行结合,基于语义信息合成未见类的视觉特征,实现任意样本分类.
3.3 零样本学习
鉴于所提出的方法能够基于语义信息生成样本的视觉特征,因此从零样本分类和零样本检索2个方面对模型的零样本学习能力进行评价.
3.3.1 零样本视频分类
零样本视频分类的对比实验结果如表2所示.从表1中可知,相比于传统的映射方法(前4个方法),生成式模型(后6个方法)的准确率取得了显著的提高,这表明了为未见类生成视觉特征来进行零样本分类的可行性和有效性.传统方法MR的性能较高,是因为该方法属于直推式(Transductive)零样本学习方法,即在训练模型的时候,可以看到无标签的未见类数据,而其他传统方法属于归纳式(Inductive),训练阶段只能看到可见类数据.在生成式模型中,CVAE表现不佳,而基于WGAN的模型(CWGAN,CVAEWGAN,CrossDAGN)性能最好.作为效果第2好的生成模型,CVAEWGAN的准确率高于CWGAN,表明联合模型能够同时利用变分自编码器和生成对抗网络的优点来合成样本.最后,提出的模型CrossDAGN优于CVAEWGAN,验证了在零样本分类问题中,跨域对抗学习能够有机地结合2种生成模型,合成更加符合真实数据分布的样本.

Table 2 acc Results (mean±standard deviation)of Zero-Shot Video Classification on Different Datasets表2 对比方法在不同数据集上零样本视频分类的acc结果(均值±标准差)
Note:The best results are highlighted in bold.
3.3.2 零样本视频检索
零样本视频检索定义为给定一个未见类的语义描述作为查询语句来检索视频,对比实验结果如表3所示.表3中平均精度均值(map)结果和表2中准确率(acc)结果呈现出类似的趋势.因此,零样本视频检索和视频分类实验结果的一致性表明所提出的跨域对抗学习方法能够为零样本学习提供令人满意的未见类样本视觉特征.
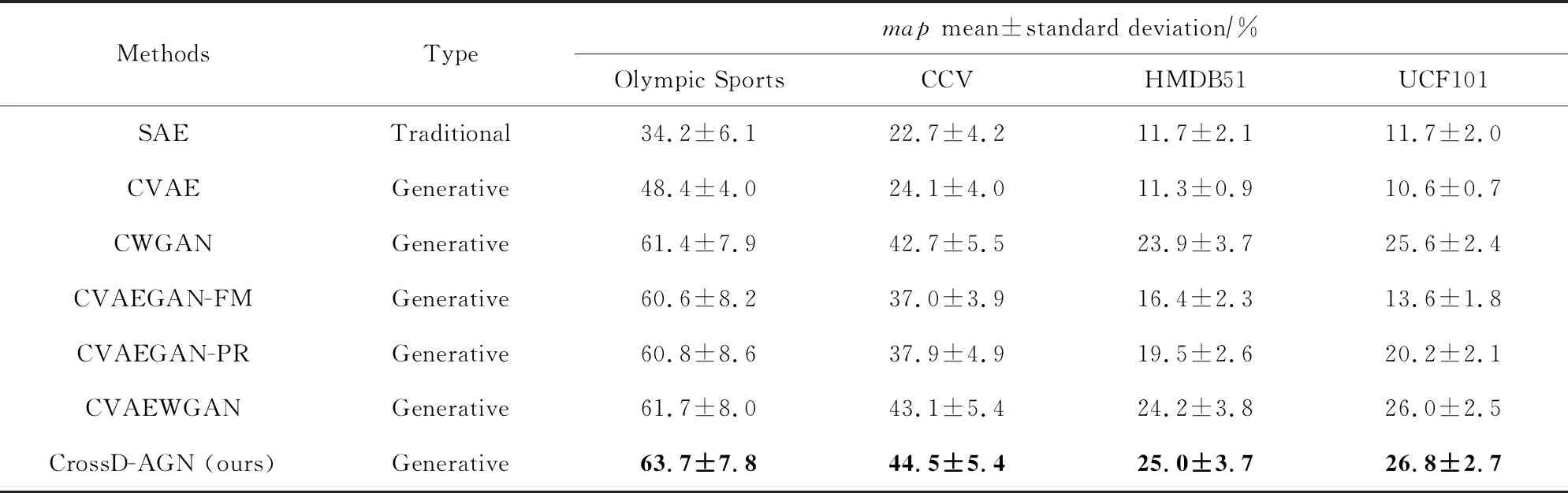
Table 3 map Results (mean±standard deviation)of Zero-Shot Video Retrieval on Different Datasets表3 对比方法在不同数据集上零样本视频检索的map结果(均值±标准差)
Note:The best results are highlighted in bold.

Fig.4 Qualitative results of zero-shot video retrieval图4 零样本视频检索的定性分析
除了上述的定量分析,还在Olympic Sports数据集上对所提出模型进行了零样本检索定性分析实验.部分实验结果如图4所示.我们注意到,除了多数正确(实线框)外,也存在一些错误(虚线框)的检索结果.这些错误大部分是由于视频的场景以及动作的相似所造成的.例如“保龄球”和“十米跳台”的检索结果中均出现了属于对方的错误视频,可能是由于类似的场景(如“室内”、“观众”等).而关于“挺举”的检索结果中,错误地出现了“抓举”的视频(第2个和第7个),这是因为这2种运动都属于举重运动,身体的动作十分相似.
3.3.3 性能差异讨论
在表2和表3中各个算法在不同数据集上性能差异较大,且按照数据集Olympic Sports>CCV>HMDB51≈UCF101的顺序降低.原因有2个:
1)Olympic Sports和CCV包含较少的类别,而类别数越少,模型越容易构建分类边界,所以算法在这2个数据集上的性能远高于类别较多的HMDB51和UCF101.另外,Olympic Sports包含800个视频,平均时长约为8 s,而CCV包含7 000个视频,平均时长约为80 s,即CCV中的视频包含了相对更多的噪音和异常点,因此在类别数差不多的情况下,各算法性能明显低于其在Olympic Sports上的表现.
2)HMDB51数据集类间边界不明显,所以在类别数更少的情况下,各算法在HMDB51上的性能却和在UCF101上差不多,甚至更低.具体地,通过计算HMDB51和UCF01数据集的2个聚类指标:Calinski-Harabasz Index(CHI)[48]和Silhouette Coefficient(SC)[49]来评估各个类别的分离程度.计算结果如表4所示,HMDB51无论是真实的数据还是合成的数据,其分布的类别分离程度都远低于UCF101.因此,即使HMDB51的类别数比UCF101少得多,各个算法在其上的性能也和在UCF101上差不多甚至更差.

Table 4 The Degree of Separation Evaluation of Classes表4 类别的分离程度评估 %
3.4 组件分析
为了进一步验证论文提出的跨域判别器D1和D2的作用,对3个由变分自编码器和生成对抗网络组成的联合模型(CVAEGAN-FM,CVAEGAN-PR,CVAEWGAN)进行组件分析实验,即比较添加跨域判别器前后的模型性能.简单起见,本文只在Olympic Sports和CCV数据集的前8个数据划分上进行了实验,实验结果如表5所示.显然,所有的联合模型在添加跨域判别器之后,利用跨域对抗学习的训练机制,不管是分类的准确率还是检索的平均精度均值都获得了显著的提升.该实验结果表明,所提出的跨域判别器不仅有助于为零样本学习合成高质量的样本,而且具有较好的泛化能力,能够推广到不同的联合模型.

Table 5 Components Analysis of the Proposed Cross Domain Discriminators表5 跨域判别器的组件分析
Note:The best results are highlighted in bold.
3.5 敏感性分析
为了研究2个跨域判别器的关系和最优的样本合成数目,进行了2组敏感性分析实验.首先,我们在数据集Olympic Sports和CCV的前8个划分上进行了跨域判别器权重系数(γ1和γ2)敏感性实验,结果如图5所示.实验结果表明:(γ1,γ2)=(0.01,0.01)是2个跨域判别器的最佳平衡点,即它们是对称的,对样本的合成起到相同的作用.其次,我们在相同的数据集上进行了视觉特征合成数量的敏感性实验,结果如图6所示.显然,当合成的数量为100时,所提出的模型可以达到最优的性能;而随着数量增大直到100以上时,准确率和平均精度均值反而开始下降.这一现象表明,合成更多假样本的同时也会引入更多的噪声数据.因此,应该控制合成视觉特征的数量,以便在有用知识和随之而来的噪声信息之间进行权衡.

Fig.5 acc and map with respect to different γ1 and γ2图5 不同γ1和γ2对应的准确率和平均精度均值

Fig.6 acc and map with respect to different numbers of synthesized features图6 不同数量合成特征对应的准确率和平均精度均值
3.6 t-SNE可视化
使用t-SNE[50]方法对Olympic Sports和CCV数据集中未见类的真实特征和3个生成模型合成的特征进行可视化,结果如图7所示.与CWGAN和CVAEWGAN相比,CrossD -AGN能够合成更接近真实数据分布的样本.在图7(a)中,CrossD -AGN合成的特征和真实的特征分布一样,都具有明显的类间边界;在图7(b)中,某些由CrossD -AGN合成的类的特征彼此非常接近甚至略有混淆,而真实的特征分布中也存在一定的重叠.
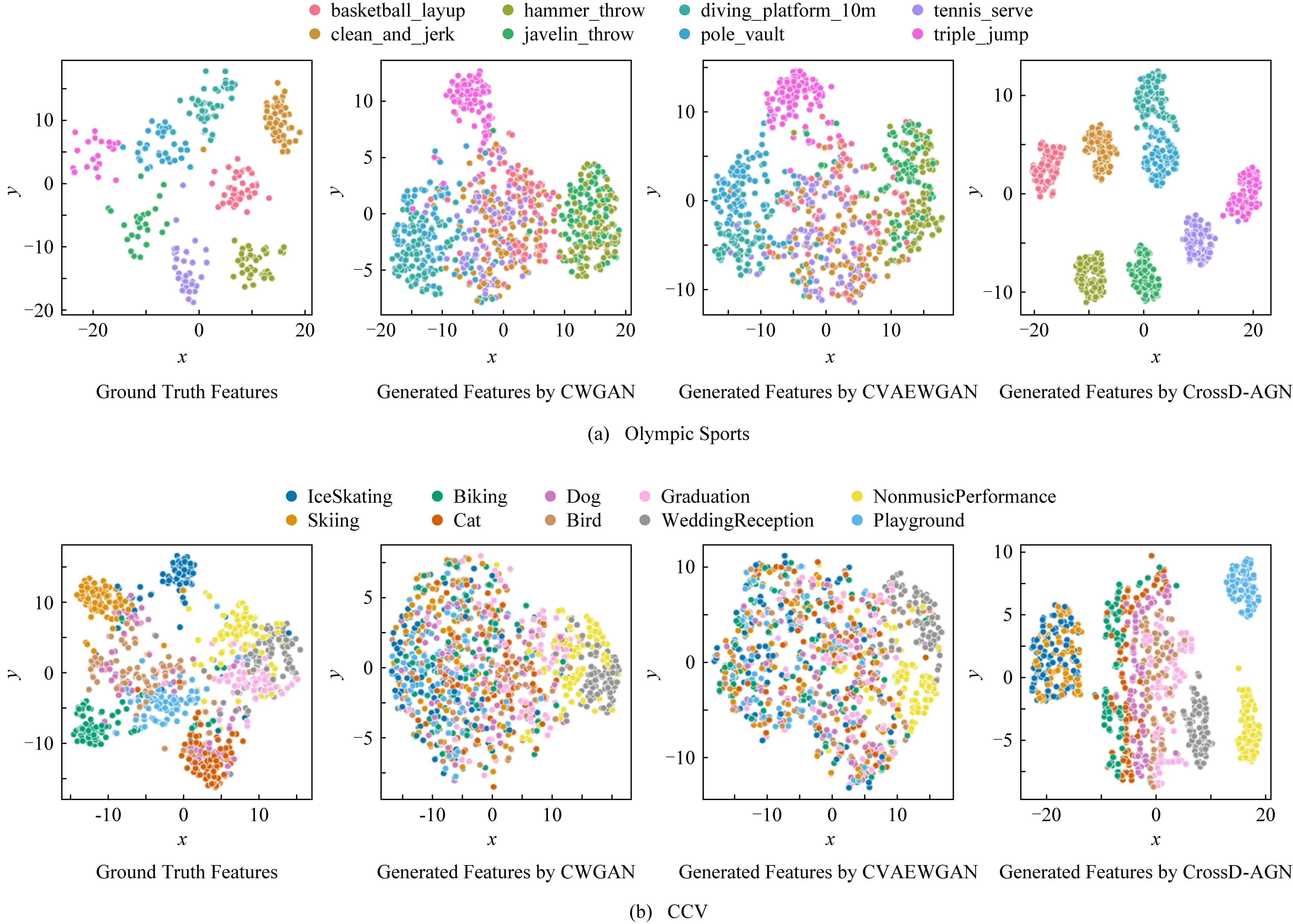
Fig.7 t-SNE visualization of real and three synthesized features for unseen classes图7 未见类的真实特征以及3种合成特征的t-SNE可视化
4 总 结
本文提出了一种基于跨域对抗生成网络的零样本分类方法.通过引入2个跨域判别器,利用对抗学习机制,不断学习判定联合模型合成样本的域分布来源,进而优化联合模型的生成器/解码器,最终提高样本生成的能力.与目前最新的CVAEWGAN模型相比,所提出的CrossD -AGN在指标acc和map上分别取得了2.7%和3.2%的平均提升,表明了所提出模型的有效性和优越性.此外,3种传统联合模型的性能在添加跨域判别器之后在2个指标上分别增加了4.0%和4.2%,也表明了跨域对抗学习思想的灵活性,易于推广.但是,目前的方法只考虑了类别信息来合成样本,而对于零样本分类问题来说,这样做仍不足以产生较高的类间辨别性.因此,未来的工作将尝试引入分类相关的损失信息来进一步提高零样本学习的性能.
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
网络安全与数据管理(2022年1期)2022-08-29
读报参考(2022年1期)2022-04-25
小学生必读(低年级版)(2021年10期)2022-01-18
锻压装备与制造技术(2021年5期)2021-11-13
科学家(2021年24期)2021-04-25
科学技术创新(2021年5期)2021-03-17
小学生必读(低年级版)(2021年11期)2021-03-09
小学生必读(低年级版)(2021年12期)2021-03-04
——编码器
演艺科技(2020年7期)2020-08-13
