
基于多任务学习的方言语种识别
2019-12-18 07:22:56秦晨光赵子鑫
计算机研究与发展 2019年12期
秦晨光 王 海 任 杰 郑 杰 袁 璐 赵子鑫
1(西北大学信息科学与技术学院 西安 710127)2(陕西师范大学计算机学院 西安 710119)(qcgnwu@stumail.nwu.edu.cn)
联合国教科文组织统计,世界上1/3的语言面临消亡,每2周就消失1种,我国现存方言80余种,方言语种保护迫在眉睫.因此,研究方言语音,对保护、利用方言,推进方言类智能应用程序的发展,如微软小娜(Cortana)、小米小爱等,都有重要意义.随着深度学习神经网络技术在语音识别领域的广泛应用[1-3],本文从方言语种识别角度切入,解决方言研究的首要问题.
本文的主要贡献有3个方面:
1)设计基于LSTM的单任务方言语种识别模型,并通过调参优化该单任务模型的表现性能;
2)提出基于参数软共享的多语种任务方言语种识别模型和基于参数硬共享的辅助任务方言语种识别模型;
3)通过多任务学习联合训练神经网络,验证了本文提出的这2种多任务学习模型相较于单任务方言语种识别模型将方言语种识别准确率提高了5%左右.
1 相关工作
方言作为一种语音信号是语音识别、自然语言处理的一个重要分支[4],其主流研究方法从隐Markov模型到基于深度学习模型的应用.如今,深度学习神经网络在语音识别领域被广泛应用,并取得了显著的效果[3].在此基础上不断优化神经网络模型的推理结果是语音识别研究的重要目标,文献[5]对经典的深度模型进行压缩和裁剪,优化了模型在移动端的尺寸和推理时间.除此之外,改变神经网络结构、改进建模策略、调整模型训练参数等方法都能提升深度神经网络的模型效果[6].方言语种识别作为方言研究工作的首要环节,没有方言语种识别作为基础研究保障,方言翻译、方言转写、方言识别等工作就无法顺利进行[7].因此,提高方言语种识别准确率,优化方言语种识别神经网络是语音识别研究的关键环节.文献[8]运用多任务学习提高自然语言处理模型的泛化能力,并取得了一定的效果,但目前尚未在方言语种识别任务中进行应用.
语音音频是与说话人时间相关的一串音频序列,已有研究方法基于循环神经网络(recurrent neural networks,RNN),长短期记忆网络(long short-term memory network,LSTM)解决与之相关的研究问题[9].本文首先应用LSTM网络构建方言语种识别单任务模型,通过调整参数(如学习率、网络层数、神经元数目)优化模型效果.进一步,本文考虑到不同地域的方言语种存在信息相关性,而多任务学习神经网络可以充分利用多个相关任务的相关领域信息[10],具体提出了2种基于多任务学习的方言语种识别方法,分别是基于参数软共享[11]的多语种任务方言语种识别方法,以及基于参数硬共享方式[12]的方言区域任务为辅助任务的方言语种识别方法.在神经网络的后向传播过程中通过共享层共享不同任务之间的隐藏信息,通过联合训练提高模型识别方言语种的准确率.
2 单任务方言语种识别模型
神经网络模型的构建涉及数据采集、特征提取、搭建神经网络、训练模型以及推理测试模型效果.本文所用数据采用了科大讯飞AI挑战大赛提供的方言数据集.
2.1 特征处理
语音识别研究通常提取MFCC[13](mel-frequency cepstral coefficients)和Fbank[14](filter bank)特征.如图1所示,Fbank比MFCC少了一步离散余弦变换(DCT),因此具有更多的原始信息.所以本文针对方言音频,选择提取40维Fbank特征,并以此作为神经网络模型的输入.应用深度学习框架pytorch,将数据处理成[data,label](数据及其对应的标签),方便进行数据批训练.

Fig.1 The feature extraction of MFCC and Fbank图1 MFCC和Fbank特征提取对比图
2.2 单任务LSTM网络模型
2.2.1 单任务方言语种识别模型
基于方言音频的时间序列特性,本文结合神经网络已有研究成果,首先搭建了1个基于LSTM模型的单任务神经网络(single-task language network,SLNet).该模型由5层神经网络构成,网络结构如图2所示:
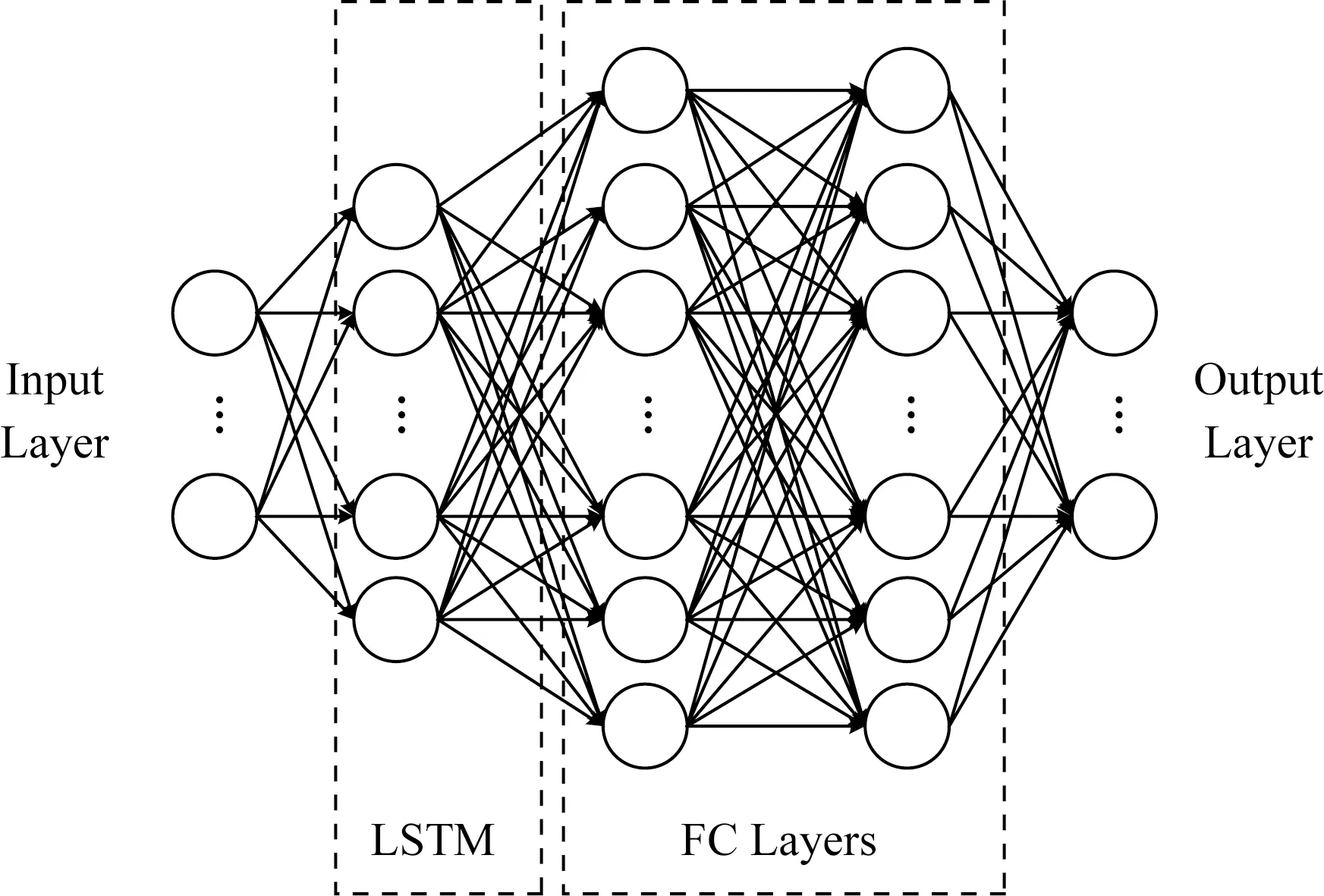
Fig.2 Single task neural network SLNet图2 单任务神经网络SLNet
SLNet具体包含:输入层、LSTM层、全连接层1、全连接层2以及输出层.搭建SLNet神经网络模型流程为:
1)对原始音频数据进行特征提取(如2.1节所示),并将数据整理为[data,label]格式,输入到单任务方言语种识别模型SLNet中.
2)依次通过pytorch封装好的LSTM层和2层全连接层.
3)通过神经网络的前向传播过程更新网络的权重.
4)利用softmax函数运算,计算样本分属每一类的概率:
(1)
其中,softmaxj表示分类到第j类的概率,k表示一共有多少类,cj,ci分别表示每个张量的值.由于softmax比较适合机器学习分类问题,因此定义此处所计算的softmax损失为该单任务语种识别模型的损失函数loss,其计算方法:
loss=-lnsoftmaxj.
(2)
5)通过神经网络迭代训练,以降低损失函数值,记录并观察迭代周期和训练轮次,直至loss收敛.
6)保存每次迭代训练的模型,比较预测标签与样本原始标签的差异,计算在训练集和验证集的语种识别正确率.
7)加载训练好的模型,对测试集进行分类预测,观察并记录该模型在测试集上的表现效果.
2.2.2 SLNet模型优化
进一步,从全连接层数维度、神经元数目、学习率等方面对SLNet模型进行优化.具体方法为
① 全连接层数.依次增加全连接层的层数由2层到8层.
② 神经元数目.隐藏层神经元由128增加到4 096.
③ 学习率.改变学习率从0.01,0.02,…,0.1.
本文采用控制变量法,在改变一类参数的时候,保持其他参数变量不变.针对改变的参数,重新训练神经网络并考量更新后的网络表现性能.具体实验结果将在4.1节展示.
3 2种多任务方言语种识别模型
多任务学习(multi-task learning,MTL)在语音识别和计算机视觉等领域取得了很大的成功,MTL通过共享多个任务之间的关联性信息来提升模型效果.本文基于多任务学习策略,分别提出了基于多语种任务的方言语种识别模型和基于方言区域任务为辅助任务[15-16]的方言语种识别模型.
3.1 多语种任务方言语种识别
不同种属的方言音频信号在音素、语音、语法、语调、词汇等方面有很大的差异但同时也存在一定程度的相似性.而这些隐含的相似信息往往与文化特征有着密切的联系,对方言语种种属分类准确率的提升提供了额外的辅助功能.因此,利用多任务学习的参数共享机制[17-18],通过神经网络模型让不同种属方言在一定程度上关注到彼此的隐含相关特性.挖掘并利用此类信息对于优化单任务网络的模型效果有很大的帮助.
本文将识别每种方言作为一个单独的任务,考虑到不同任务之间在种属、来源、音调等特性是任务相关的,进而依据多任务学习方法搭建相应的多任务学习神经网络.
根据上述思路设计了一种基于多语种任务的方言语种识别神经网络(multi-task language network,MTLNet),其模型框架如图3所示:

Fig.3 Multilingual dialect language recognition model MTLNet图3 MTLNet多语种方言语种识别模型
MTLNet包含n个子任务,将识别每种方言定义为一个单独的任务,n个任务依次定义为Task1,Task2,…,Taskn.第2节所述的最优单任务方言语种识别网络作为搭建多任务学习网络的基线网络,以此基线网络的模型结构作为每个单独子任务的模型.每个任务会有一个子任务的输出,在多任务网络MTLNet的最后将多个子任务的预测结果输入到同一个隐藏层里,通过隐层的参数软共享计算所有子任务loss平均值lossavg,根据神经网络的反馈机制更新权值参数,多次的迭代训练不断地降低网络lossavg,让网络具有更好的学习能力,能够有更好的表现性能.lossavg计算方式:
(3)
其中,LTi表示任务i的损失loss值,n表示任务总数即方言数目.
在MTLNet中,从单任务中提取Fbank特征,输入到该任务的LSTM模型中,并输出对应的loss.方言语种与MTLNet任务的对应关系如表1所示.
将10个单任务模型的loss输入到共享隐藏层中,如图3所示的Sheared Layer.经过共享层实现参数共享,联合训练多个任务,将lossavg通过SGD优化器,反向传播更新梯度参数,不断迭代训练直至神经网络收敛.
通过分类准确率acc对模型效果进行评估,分类准确率等于分类正确的方言个数与总方言个数的比值.在单任务模型中,单任务分类准确率accs计算方法:

(4)
其中,r表示分类正确的方言条数,A表示总的方言数目.
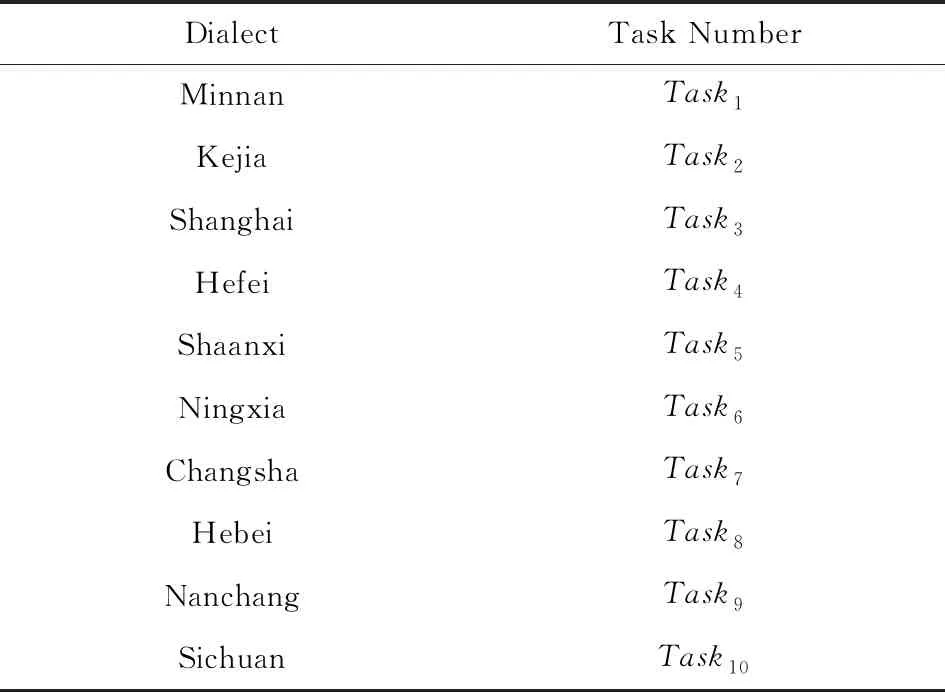
Table 1 Correspondence Between Dialect Language and Task表1 方言语种与任务的对应关系表
多任务方言识别模型中计算多任务方言分类准确率accm的方法:
(5)
其中,rti表示识别任务i类语种的正确个数,Ati表示任务i类方言音频的总个数,n表示任务个数.
3.2 区域辅助任务方言语种识别
中国方言根据地域属性可以划分为七大方言区域,分别是:官话方言、客家方言、湘方言、吴方言、粤方言、闽方言和赣方言.不同区域的方言会有各自的特点,彼此之间也会有交叉联系.例如数目较多的官话方言具有辅音韵尾比较少、语调数目较少等特点;湘方言具有元音鼻化等特点;而官话方言和湘方言在词汇方面又基本大同小异.
本文以识别方言区域作为辅助任务,为主任务方言语种识别提供隐含信息,采用基于参数硬共享的多任务学习模式,构建基于辅助任务的多任务学习神经网络(auxiliary-task language network,ATLNet).多任务学习参数硬共享指的是多个任务具有共同的数据来源和网络输入,且多个任务之间共享隐藏层信息,整个网络联合训练所有任务的损失值.最后通过每个任务的输出结果评估ATLNet的表现效果.
根据方言所属区域,为不同方言数据打上区域标签.方言种类与方言区域对应关系如表2所示:

Table 2 Label of the Dialect Area表2 方言区域标签表
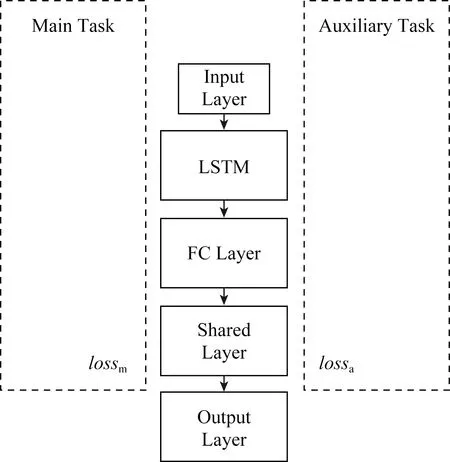
Fig.4 Auxiliary task model ATLNet图4 辅助任务模型ATLNet
主任务方言语种识别任务和辅助任务方言区域识别任务采用相同的数据来源及特征提取方法.本文设计ATLNet网络结构如图4所示:
辅助任务方言语种识别网络从上到下依次是输入层、LSTM层、全连接层、共享层和输出层,在输入层的两侧分别表示主任务和辅助任务的标签信息输入.按照模型信息流依次执行,在共享层实现参数硬共享,分别计算主任务和辅助任务的损失,分别定义主任务lossm和辅助任务lossa.然后对2个任务的loss值求和:
losssum=lossm+lossa.
(6)
通过联合losssum对网络进行反向传播和梯度更新.最后,执行训练脚本训练多任务神经网络并保存模型.
4 实验分析
本文实验硬件平台为安装有NVIDIA GTX 1060的高性能服务器,运行Ubuntu 16.04 LTS操作系统,所有深度学习模型基于pytorch0.4框架实现.
实验数据集来自科大讯飞AI开发者大赛提供的10类方言数据.数据集共包括10种方言,每种方言包含40个本地人的6 h的朗读风格语音数据.数据以采样率16 kHz、16 b量化的PCM格式存储.数据集包含训练集、验证集和测试集3个部分.训练集每种方言有5 000句语音,包含30个说话人,其中15位男性和15位女性,每个说话人200句语音;验证集和测试集中每种方言分别包含5个说话人.验证集数据根据语音段的时长分为≤3 s的短时数据和>3 s的长时数据.训练集、验证集、测试集的说话人均没有重复.
对不同数据进行标签标注:闽南话(0)、客家话(1)、上海话(2)、合肥话(3)、陕西话(4)、宁夏话(5)、河北话(6)、长沙话(7)、南昌话(8)、四川话(9).用HTK工具提取40维的Fbank特征作为神经网络的输入.(隐Markov模型工具包(HTK)是一个用于构建和操作隐Markov模型的便携式工具包.HTK主要用于语音识别研究,也被用于许多其他应用,包括语音合成、字符识别和DNA测序的研究.HTK正在全球数百个网站上使用.)
4.1 单任务语种识别模型性能分析
针对第2节提出的单任务语种识别模型,按照标签从小到大顺序依次加入方言语种,且每增加一类方言重新训练一次网络,并记录了每种情况下测试集的语种识别准确率,作为实验初始模型(baseline model).随后,通过增加全连接层数,提升模型准确率.如图5所示,对比了初始模型及拥有不同全连接层模型在测试集上的表现效果,实验结果显示,发现一定程度增加全连接层数对网络的优化性能是有所提高的.但层数和准确率并非正比关系,当全连接层为FC5时,效果最优达到75.03%.

Fig.5 Accuracy in increasing the numbers of FC layers图5 增加全连接层对识别准确率的影响
进一步,对全连接层为FC5的单任务方言语种识别模型进行隐层神经元参数优化.如图6所示,神经元的变化是将隐藏层的神经元数目从128开始增加至4 096.这样的增加变化对单任务语种识别模型的准确率结果影响如图6所示:
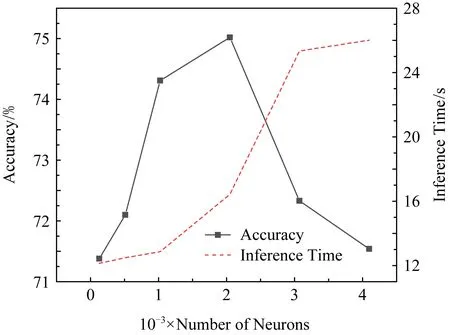
Fig.6 Accuracy in increasing the numbers of neurons图6 增加神经元数目对识别准确率的影响
由图6结果发现,一定程度上增加神经元对于方言语种识别模型的识别结果呈现一个稳步上升的态势,同时推理时间也会随之增加,说明神经元数目增加导致模型的推理变得复杂.此外,在本文中神经元数目增加到3 072时训练时间明显增长且推理时间明显变长.因此,实验发现并不能一味地增加神经元的数目,当神经元数目过大会导致网络的训练非常缓慢而且会出现内存不足(CUDA out of memory)的问题.本文最终确定合理的神经元数目为2 048.
本文对学习率(learning rate,LR)参数进行调整,从0.01逐次增加到0.1,对每次变化的新网络模型性能进行记录评估.实验结果如图7所示,记录了随着学习率的变化对语种识别准确率和模型推理时间的影响.

Fig.7 Accuracy in changing the learning rate图7 调整学习率对识别准确率的影响
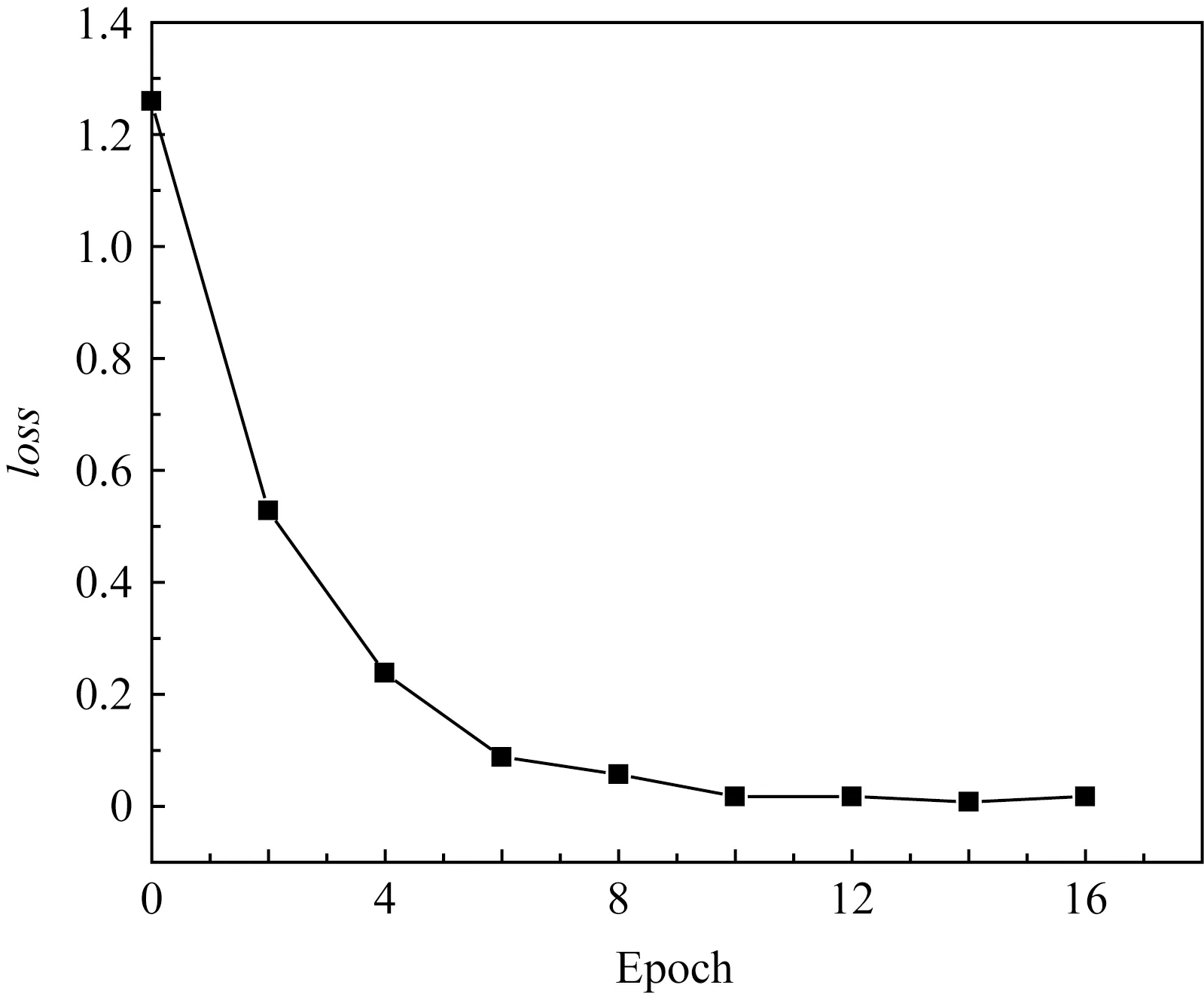
Fig.8 The loss trend with train epoch图8 迭代周期损失函数曲线
由图7可知,由于LR过低时导致的过拟合问题,以及LR过高时引起的高偏差现象,导致模型的稳定性不好.由此本文选定LR=0.05,此时准确率最高可达75.36%.
根据图7调试参数实验,最终确定单任务方言语种识别模型的网络参数为:隐层神经元2 048个、初始学习率0.05、5个全连接层.
经过初步确定参数之后,结合上述3组实验的训练过程.本文进一步通过收集该组参数配置下,网络模型的训练迭代周期及相对应的loss变化对语种识别准确率高低和推理时间长短的影响.训练迭代周期(epoch)和训练loss变化曲线如图8所示:
由图8可以看出,训练第0轮开始时损失函数loss值在1.3左右,随着迭代周期的增加loss在不断减小,且从第10次迭代开始变得平缓,表示已经开始收敛.表明10~15这个迭代周期已经比较合理,如果继续训练可能会导致模型过拟合.
进一步,在迭代周期下统计模型语种识别准确率和损失函数loss的变化,并绘制曲线如图9所示:

Fig.9 Accuracy and loss trend with train epoch图9 迭代周期损失函数和准确率曲线
通过图9发现,刚开始训练时,损失函数值很大且识别准确率很低,随着迭代周期的增加,损失函数loss降低,识别准确率增加,且二者在10~14轮这同一时期基本趋于平稳.表明模型性能已经渐渐趋于平稳,这个时期的参数指标则是我们最终确定的参数范围.
同理,收集损失函数值和训练时间结果,并将其曲线绘制在同一坐标系,结果如图10所示:

Fig.10 Training time and loss trend with train epoch图10 迭代周期损失函数和训练时间曲线
综合图8~10曲线显示,本文发现损失函数降低到0.15左右网络开始收敛且损失函数值保持在稳定状态,故当通过迭代训练将网络损失降低至0.15附近停止训练,此时的迭代周期为12~14之间.对比损失函数loss和识别准确率以及训练时间的关系,发现损失函数越小准确率越高,但是在一定程度二者会同时趋于稳定.又因为随着不断迭代损失函数值才能降低,因此训练时间在持续增加.综合考虑训练时间、损失函数和准确率三者的变化,当loss曲线逐渐收敛趋势平稳之后2~3个迭代周期是最佳停止时间,同时满足了模型对性能和时间的要求.
4.2 多任务语种识别模型性能分析
4.2.1 多语种任务模型性能分析
针对3.1节所述内容,现将单个语种的识别任务作为多语种识别的子任务,并联合训练多任务神经网络.每次添加一个新的子任务(任务维度由2线性增加到10),并重新训练改进后的神经网络.如图11所示,将多语种任务方言语种识别模型同单任务方言语种识别模型进行对比.

Fig.11 Inference accuracy between single &multi-task图11 单任务模型和多任务模型识别准确率对比
由图11可知,单任务网络数据维度的增加和多任务网络任务维度的增加都会提高模型识别准确率.对于单任务模型,准确率的提高源于输入数据维度增加使训练的样本更充足;对于基于语种任务的多任务学习模型,不同语种之间通过参数软共享的方式学习隐含信息,从而提高了模型的表现性能.与此同时,基于语种的多任务语种识别模型比同等维度的单任务方言语种识别模型有更好的识别效果,平均性能提高约5%.
4.2.2 区域辅助任务方言语种识别性能分析
根据3.2节所述方法,对方言数据增加方言区域标签,由此每条方言数据会同时拥有语种标签和方言区域标签,预测每个任务的标签与每个任务的真实标签的误差就是每个任务的loss.通过多任务学习参数硬共享联合训练这2个主辅任务,在方言测试集得到如表3的实验结果:

Table 3 The Accuracy of Auxiliary Task Model表3 辅助任务模型准确率结果 %
由表3结合图11可以看出,主辅任务联合的多任务学习模型比主任务方言语种识别任务和辅助任务方言区域识别任务二者各自的单任务模型的识别准确率都有提高.并且方言语种识别作为主要任务,其准确率较单任务方言语种识别模型和基于多语种任务的方言语种识别模型都有提高,且效果更好,识别准确率达80.2%.
5 结束语
针对中国方言的多样性、复杂性、相似性,本文首先应用了LSTM神经网络搭建方言语种识别基线系统,并通过调参优化该单任务方言语种识别模型.进一步提出2种基于多任务学习方法的改进模型,分别是基于多语种任务的方言语种识别模型和基于方言区域识别任务为辅助任务的方言语种识别模型.本文经过一系列实验发现,多任务模型在方言语种识别问题上比单任务模型识别准确率更高,平均提高5%.且基于辅助任务的方法比基于多语种任务方法在此问题上效果更好.这2种方法的有效利用将有助于推进方言识别研究.
猜你喜欢
东方少年(2022年28期)2022-11-23 07:09:46
今日农业(2021年15期)2021-11-26 03:30:27
时代邮刊(2021年8期)2021-07-21 07:52:44
新世纪智能(高一语文)(2019年11期)2020-01-13 06:10:38
新世纪智能(高一语文)(2019年11期)2020-01-13 06:10:38
中国生物医学工程学报(2019年6期)2019-07-16 07:52:40
疯狂英语(双语世界)(2017年3期)2018-01-19 01:40:05
自动化学报(2016年3期)2016-08-23 12:02:56
电测与仪表(2016年5期)2016-04-22 01:13:46
计算机工程(2014年6期)2014-02-28 01:26:17
