
基于Inception-V3网络的双阶段数字视频篡改检测算法
2019-12-16 06:57翁韶伟彭一航叶武剑
广东工业大学学报 2019年6期
翁韶伟,彭一航,危 博,易 林,叶武剑
(1. 广东工业大学 信息工程学院,广东 广州 510006;2. 广东省智能信息重点实验室,广东 深圳 518060)
多媒体技术的快速发展使得人们可以轻易地通过Premiere、After Effects等编辑软件对数字视频进行篡改,从而导致视频的真实性、完整性遭受质疑. 篡改后的视频会导致关键语义信息的改变. 许多居心叵测的犯罪分子常常通过传播篡改视频来误导人民群众,扰乱社会秩序. 因此,数字视频取证技术研究已经成为了多媒体内容分析的一个非常重要的研究课题.
数字视频取证有主动取证和被动取证两种方式.主动取证指在视频的内容中嵌入数字水印或者数字签名信息,然后通过检测嵌入信息的完整性来判断该视频是否经过篡改. Na等[1]提出了一种基于视频空域块均值的签名方法,该算法先利用视频帧的块均值植入签名信息,然后在取证阶段采用二级匹配算法验证签名信息的完整性,若签名信息不完整,则认定该视频为篡改视频. Lee等[2]利用视频中每个图像块的梯度质心生成视频指纹信息,并与数据库中的指纹信息作比对,若无匹配信息,则判定目标视频已遭篡改. 主动取证算法对硬件设备的依赖性大且验证信息极易受到攻击,故该类算法现已很少被关注.
被动取证算法首先对视频序列中的某种统计特性进行建模,然后检测模型中是否存在异常值,以此验证目标视频的真实性. 由于篡改操作会扰乱视频帧中像素子块间的相关性,Chetty等[3-4]首先提取视频帧的图像子块的传感器噪声和量化残差特征,并把两者转化到跨通道的子空间以表征图像子块间的相关性,最后通过检测相关性的异常值来验证视频的真实性. 针对视频片段复制粘贴的篡改方式,Bestagini等[5]提出了一种基于片段相关性的取证算法. 该算法首先通过帧差法获取残差图,并依次计算视频片段与残差图的相关性,若两者相关性越强,则该片段遭受篡改的可能性越大. 针对运动目标移除后的修补操作会造成视频运动矢量异常,Li等[6]将视频帧中运动矢量的方差与预设的阈值进行对比,从而检测视频区域是否经过篡改. Bidokhti等[7]提出利用光流系数异常检测视频区域复制-粘贴的取证算法. Pandy等[8]提出一种时域、空域联合的检测算法,该算法首先在空域提取SIFT特征点,并用K-NN算法对关键点进行匹配,接着在时域提取残留噪声,计算互相关性以完成检测. 被动取证不需要依赖拍摄设备,是目前数字视频取证领域的一个研究热点,但传统的被动取证算法识别篡改类型单一,识别率低,鲁棒性差,根本无法满足实际应用的需求.
近年来,人工智能技术的飞速发展为多媒体数字取证研究带来了新的发展契机. 依靠强大的计算能力,人工智能算法能从大数据中学习并提取对象的深层特征[9],全面地表达了输入信息,从而提高了视频区域篡改的检测率. 在多媒体信息安全领域,已有学者提出基于人工智能算法的数字视频取证算法,并取得了优异的成果.
Chen等[10]认为,在数字视频取证中,应把视频帧定义为3种类型:原始视频帧、篡改视频帧和双压缩视频帧. 对视频进行篡改操作往往需要先把视频转化为视频帧序列,再对目标帧进行篡改,最后对新的视频帧序列进行二次压缩. 因此,篡改视频中应包含双压缩视频帧和篡改视频帧,而原始视频没有经过篡改操作,应仅包含原始视频帧. 据此原理,Chen等[10]认为数字视频取证的核心任务即视频帧类型的识别. 该团队利用基于隐写分析的方法提取视频帧的特征向量,并通过随机森林算法对这些特征向量进行分类. 若该视频中同时包含篡改视频帧与双压缩视频帧,则判定为篡改视频,否则判定为原始视频.对于篡改视频,算法采用共谋滑动窗口算法进一步定位篡改视频帧的所在位置,实现定位功能. 该算法在SYSU-OBJFORG数据库上取得了86%的识别准确率,同时具有一定的定位功能,但该算法仍需手动提取视频帧的特征.
Yao等[11]先通过帧差法获取残差图,再通过高通滤波器捕获篡改痕迹,最后使用卷积神经网络(Convolutional Neural Network, CNN)对经过高通滤波后的视频帧进行分类. 该算法无须手动提取视频帧的特征且在SYSU-OBJFORG数据库上取得了约89%的识别准确率. 然而,该算法在CNN训练过程中需要遍历数据集约12万次,付出了极大的时间代价,另外,该算法并没有实现定位功能.
针对文献[10-11]中算法存在的不足,本文提出了一种基于Inception-V3网络的二级分类取证算法.由于视频序列的帧间冗余信息会干扰算法捕捉篡改痕迹,因此本算法首先使用绝对差分算法去除帧间冗余并获取灰度差分图像. 灰度差分图像蕴含了视频帧序列中物体的运动特性,有利于算法捕捉由剪切、消除对象等篡改操作引入的痕迹. 另外,经大量实验发现,当视频帧的灰度差分图像帧序列经过一系列高通滤波、卷积等操作后,篡改视频的像素均值偏小而原始视频的像素均值偏大. 依此原理,第一级分类器将采用阈值判断方法来区分原始和篡改视频;为克服现有算法定位准确率低以及无法自动提取特征的不足之处,第二级分类器将使用Inception-V3网络来识别篡改视频帧,实现定位功能. Inception-V3网络在单层网络中同时采用了具有不同尺寸的卷积核,能够自动提取篡改视频帧的高维多尺度特征,这些特征更充分地表达了视频帧的深层特性. 另外,该结构通过加深网络深度来增强非线性拟合性能,从而提高篡改视频帧定位精度.
实验结果表明,在Inception-V3网络的训练过程中,本算法仅需遍历数据集约4万次即可找到参数最优点. 另外,相比于文献[10-11]的算法,本文算法在识别能力和定位能力上都略胜一筹.
1 基于Inception-V3的数字视频取证算法
本文提出了一种利用二级分类器识别篡改视频的技术方案. 在第一级分类器中,算法利用一系列的高通滤波器来检测视频中是否存在由篡改操作引入的伪影,然后采用共谋算法去除随机噪声,最后利用阈值判断方法来区分原始视频和篡改视频. 第二级分类器利用Inception-V3网络提取篡改视频中的视频帧特征,从而区分双压缩视频帧与篡改视频帧,实现篡改帧定位. 算法流程如图1所示.
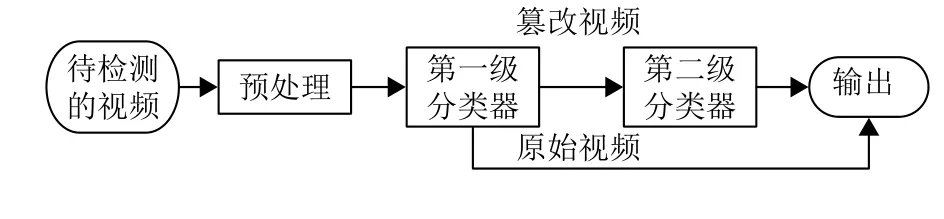
图 1 算法流程图Fig.1 The framework of proposed method
1.1 预处理
为达到掩人耳目的目的,篡改者往往会对视频序列中的某一区域进行擦除、复制和掩盖等操作,如图2所示. 因此在视频序列中,两帧之间往往存在大量的冗余信息. 这些冗余信息会增加算法复杂度,妨碍算法挖掘篡改特征. 在预处理阶段,采用绝对差分算法去除帧间冗余信息,提高算法性能.

图 2 擦除操作效果Fig.2 The result of erasing operation
绝对差分算法是一种通过对视频图像序列的连续两帧图像做差分运算以获得运动目标轮廓的方法. 当视频场景中的某个区域遭受篡改时,相邻两帧之间会出现较为明显的差异,因此两帧相减,求得图像对应像素值差的绝对值,可以进一步分析视频中物体的运动特性并去除帧间冗余.
设输入的视频为V,定义视频帧序列为
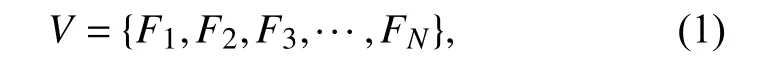
其中i∈{1,2,···,N},Fi表示第i个视频帧,N表示该视频所包含的视频帧数量. 绝对差分算法的具体操作如式(2)所示.
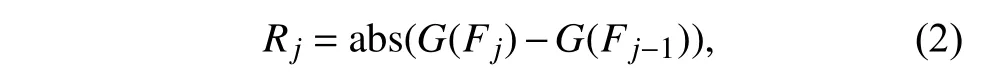
其中j∈(2,3,···,N),Rj表示第j帧的灰度差分图像帧,a bs(·)表 示取绝对值操作,G(·)把视频帧转化为灰度图像帧. 获取灰度差分图像帧的过程见图3,图3(c)中椭圆部分即为视频帧的运动信息.
事实上,对视频进行篡改操作会在篡改区域的边缘引入肉眼难以察觉的伪影. 在1.2节中,将详细地介绍第一级分类器如何在灰度差分图像中捕捉这种伪影,以区分原始视频与篡改视频.

图 3 (c)为(a)、(b)两帧相减而得的灰度差分图像帧Fig.3 (c) is produced by (a) and (b) using absolute difference algorithm
1.2 第一级分类器
在隐写分析领域中,高通滤波器常被用于消除图像内容的干扰,增强隐写信号. 近年来,已有学者验证了高通滤波器同样具有突出篡改痕迹的作用. 借助这一特性,第一级分类器将使用高通滤波器消除灰度差分图像中由图像内容造成的干扰,以捕捉篡改痕迹.当把原始帧、篡改帧、双压缩帧的灰度差分图像帧放入一系列高通滤波器后,得到的结果如图4所示.

图 4 视频帧滤波效果图Fig.4 Filtered image of frames
视频在拍摄、压缩的过程中会引入随机噪声,因此,经过高通滤波器后的灰度差分图像帧会存在噪声空洞. 由图4(a)、4(b)不难看出,原始帧的灰度差分图像帧的噪声空洞数量少、面积小,而双压缩帧的灰度差分图像帧噪声空洞数量多且面积大. 由于篡改帧中的某一区域经过篡改或修复等操作,其灰度差分图像帧往往存在大片的连通空洞,如图4(c)所示.显然,不同类型的灰度差分图像帧在经过高通滤波后,其空洞数量、大小以及分布状况均存在着明显的差异.
为了进一步突出篡改痕迹,清除篡改区域以外的黑色空洞,采用了共谋算法来消除这种随机噪声[12].设通过高通滤波器后的视频图像帧序列表示为

其中i∈{1,2,···,N},Bi表示第i个灰度差分图像帧,N表示差分图像帧的数目. 设共谋窗口大小为L=2a+1,a为Bi左右两边的帧数. 共谋操作定义为

其中ɐ是共谋运算,Ck是第k帧共谋运算后的结果. 然后,为抑制突变区域对共谋图像帧Ck统计特性的影响,将Ck通过一个3 ×3的平滑滤波器,并作二值化处理,最后得到一个新序列:
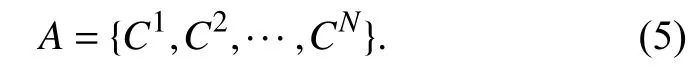
通过统计原始视频与篡改视频的图像帧序列A的 平均像素值,发现原始视频的A集的平均像素值偏大,而篡改视频的A集的平均像素值偏小. 因此,选定一个阈值T,当一个视频帧序列A集的平均像素值大于等于T时,则判定该视频为原始视频,反之则判定为篡改视频. 实验中,T值取230.
在第一级分类器,通过高通滤波器捕捉伪影,然后使用统计方法来区分原始视频与篡改视频,实现识别功能. 在1.3节中,将介绍如何使用Inception-V3网络来区分篡改视频中的双压缩视频帧与篡改视频帧,实现定位功能.
1.3 第二级分类器
为提高计算性能,Google团队提出利用Inception结构来将稀疏卷积核结构聚类为较为密集的子卷积核组合[13]. 与传统的CNN网络相比,Inception-V3网络的优势主要体现在以下2个方面:(1) 特征表达能力更强. Inception结构层使用了不同尺度的卷积核. 这些卷积核具有多尺度的感受野,可以提取输入信息的多尺度特征. (2) 网络深度更深. Inception结构的主要思想是找出最优的局部稀疏结构并将其覆盖为近似的稠密组件,因此会把较大的卷积核分解成多个小卷积核的组合,这加深了网络深度,提高了网络非线性拟合性能.
单个Inception结构如图5所示,为获取不同的感受野,Inception结构中被部署了多尺寸卷积核,如1×1、3×3、5×5;其中,部分卷积核又被近似的稠密组件所代替,以加深网络深度,如3×3的卷积核被1×3、3×1的串联组合所替代. Inception结构的输出为各个卷积核输出的组合,即多尺度特征. 考虑到特征图厚度会随着卷积核尺寸、数量增大而增大,故网络在特征提取前首先使用尺寸为1×1的卷积核对特征图进行滤波以实现特征图降维.
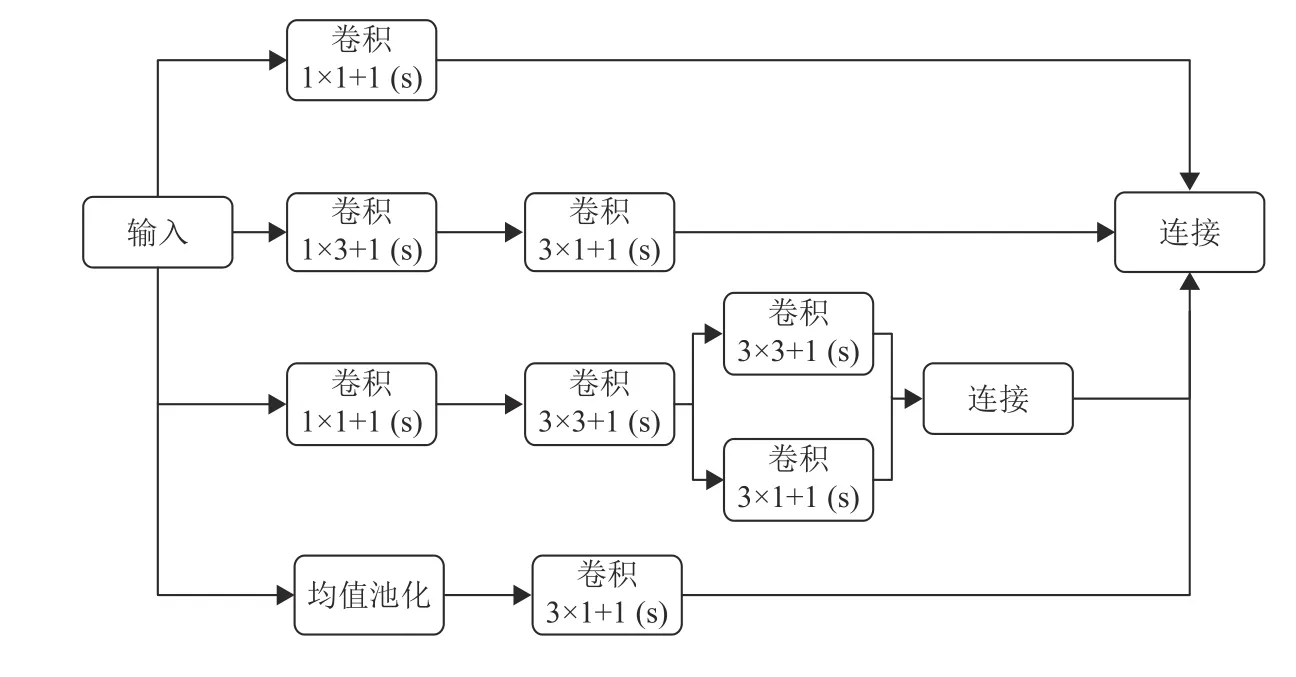
图 5 Inception结构图Fig.5 Structure of Inception
图6为本文使用的Inception-V3网络结构图,其中V1表示Inception结构层. 网络首先通过5个卷积层与2个池化层提取输入图像(Input)的低维特征,接着通过11个V1层提取Input的高维多尺度特征,最终利用softmax回归对特征进行分类. 其中,前5层卷积层的卷积核大小分别为 3×3×32、3 ×3×32、3 ×3×64、1×1×180 和3×3×192.
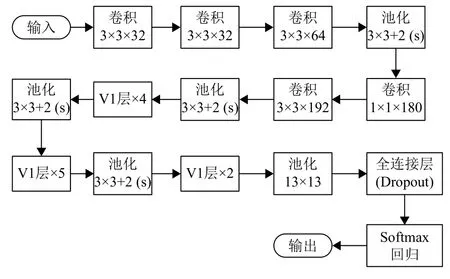
图 6 Inception-V3网络结构图Fig.6 Structure of Inception-V3 network
2 实验
本文将通过SYSU-OBJFORG数据集来验证算法的识别性能与定位性能. SYSU-OBJFORG数据集规模庞大,具有100个原始视频以及篡改视频. 其中每个视频均采用H.264/MPEG-4标准进行压缩编码,分辨率为1 280×720,帧率为25 fps,码率为3 Mbit/s,篡改方式主要为同源拼接. 在训练第二级分类器的过程中,随机选取40对视频数据作为训练集,10对视频为验证集,剩余的50对视频作为测试集. 另外,为了防止网络欠拟合,采用非对称图像分块方法对数据集实现数据增强. 最后,将与Chen[10]和Yao[11]的实验结果对比,以说明算法的优异性.
2.1 数据增强
数据量是决定模型性能的关键因素. 原则上,训练数据量越大,网络模型拟合非线性函数的能力越强,识别准确率越高. 在SYSU-OBJFORG数据库中,每段篡改视频大约有250帧,而篡改帧往往只有100帧,约占总帧数的40%. 训练样本中未篡改帧与篡改帧的分布不均衡,将会导致网络欠拟合,降低识别准确率. 为了获得相似数量的正负样本,本文采用非对称图像分块方法对数据集进行数据增强.
将每个灰度图像帧转换为相应的灰度差分图像帧后,对训练集和测试集分别进行分块处理. 对于非篡改帧,将每个非篡改帧的灰度差分图像帧划分为左、中、右3个等大的图像字块,分别为图像子块1,图像子块2,图像子块3. 在本数据库中,每个灰度差分图像帧的尺寸为1 280×720,则可划分为3个等大的720×720的图像子块;对于篡改帧,将篡改视频序列中每个灰度差分图像帧的被篡改区域用矩形块标记,点C为矩形中心点,然后将被篡改图像视频帧剪切为m个图像子块,分别为图像子块1,图像子块2,···,图像子块m,其中,每一图像子块必须包含矩形中心点C. 对非篡改帧与篡改帧的分块方式分别如图7和图8所示.
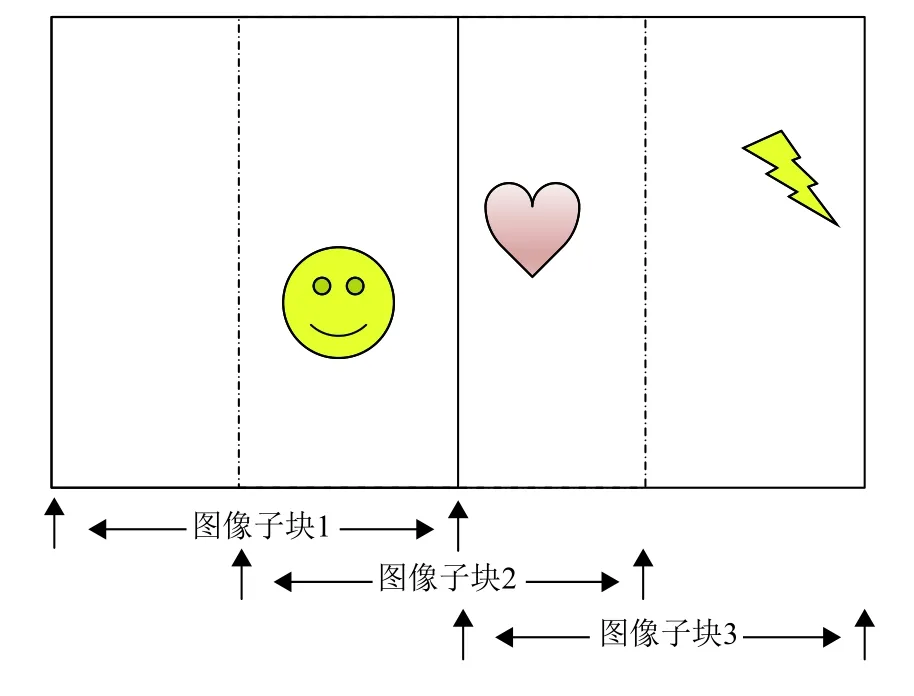
图 7 非篡改帧剪切方法Fig.7 Cutting way of unforged frame

图 8 篡改帧剪切方法Fig.8 Cutting way of forged frame
2.2 实验步骤
本文的Inception-V3网络由谷歌公司推出的tensorflow框架所搭建,训练环境为英伟达P40 GPU.采用高斯截断函数初始化变量,指数衰减法调整学习率,Adam算法优化损失函数,并设置学习率为0.01,衰减系数为0.95,衰减速度为1 000,batchsize为32. 在训练过程中,网络需要遍历训练集约4万次,即可达到参数最优点,完成训练.
在测试过程中,首先对测试视频作预处理,并输入到第一级分类器中,第一级分类器会对目标视频进行识别,并输出标签. 对于被第一级分类器标注为篡改视频的帧差序列,算法首先采用2.1小节中的分块方式对每一帧进行分块并输入到Inception-V3网络进行检测,若有一个图像子块被判定为被篡改块,则该视频图像帧被标记为被篡改视频帧,否则标记为原始视频帧.
为进一步提高Inception-V3网络模型的识别准确率,本算法将对网络的预测分类结果进行后处理,该后处理操作采用不重叠的滑动窗口来细化网络的分类判定. 滑动窗口的大小用L表示,在同一滑动窗口中标记为篡改视频帧的数量用T表示,因此L-T为同一滑动窗口中未篡改帧数,实验中,设L=10 . 在后处理过程中,如果T≥7,则把滑动窗口中的未篡改帧均标记为篡改视频帧;相反,如果T≤3,则把滑动窗口中的篡改帧均标记为未篡改帧.
2.3 实验结果
在本实验中,通过如下指标来衡量算法的优劣:
(1) 原始视频帧识别准确率:

(2) 篡改视频帧识别准确率:

(3) 双压缩视频帧识别准确率:

(4) 视频帧识别准确率:

(5) 视频识别准确率:
(6) 篡改视频帧的精度:

第一级分类器通过统计视频帧序列A集的平均像素值,再利用阈值方法来识别篡改视频. 其中,测试视频集的A集平均像素值分布如图9所示. 图9中,紫色条形为测试集中篡改视频A集的平均像素值分布,黄色条形为非篡改视频帧序列A集的平均像素值分布. 不难看出,篡改视频A集的平均像素值在180~225之间而非篡改视频A集的平均像素值在235~260之间,这说明第一级分类器可以准确地区分原始视频以及篡改视频,实验结果为图10中的VACC指标.
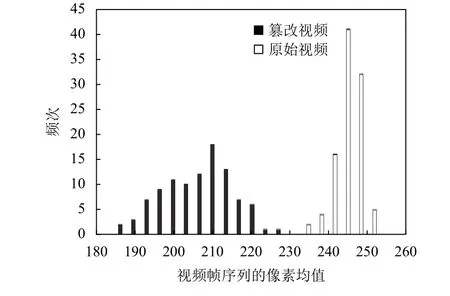
图 9 测试集的A 集 平均像素分布图Fig.9 Average value of all the pixels of test set
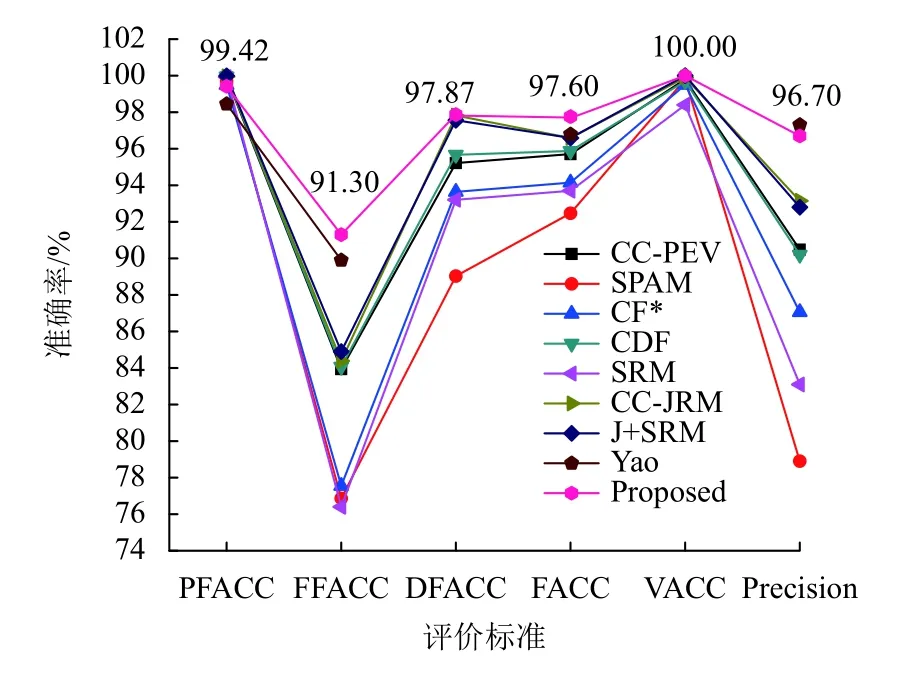
图 10 第二级分类器实验结果图Fig.10 Experiment result of the second stage classifier
第二级分类器通过Inception-V3网络识别篡改视频中的篡改视频帧. Chen等[10]对比了7种不同的特征提取算法的实验结果,这7种特征提取算法均基于隐写分析,分别为CC-PEV、SPAM、CF*、CDF、SRM、CC-JRM、J+SRM. 将与Yao[11]和Chen[10]的实验结果作对比,以突出本算法的优异性,实验结果如图10所示.
相比于Yao[11]的算法,本算法在Inception-V3网络的训练过程中仅需要遍历训练数据集约4万步,极大降低了训练成本. 另外,相比于传统算法,本算法具有自动提取特征的能力,可以识别多种类型的篡改方式. 从图10可知,本算法在 PFACC上与Chen[10]、Yao[11]的算法相比基本持平,而在 FFACC、D FACC、FACC、V ACC等指标上均优于Chen[10]、Yao[11]的实验结果,这说明本算法在识别篡改视频与定位篡改视频帧的能力更胜一筹.
3 结论
本文提出了一种基于Inception-V3的数字视频取证算法,主要贡献如下:(1) 算法巧妙地应用了二级分类结构,把统计方法与深度学习算法进行有机结合,可以高效准确地区分原始视频与篡改视频,并实现篡改帧定位;(2) 把篡改视频的问题转化为帧类别识别问题,并首次在多媒体取证领域中应用Inception-V3网络;(3) 相对于传统的数字视频取证算法,该算法能自动提取特征,且有识别多种篡改方式的能力.
实验结果表明,相比于文献[10-11]的算法,本算法的识别准确率更高,定位能力更强. 该算法的缺陷在于缺乏帧内定位的能力,无法追踪帧内的篡改区域,这也是下一步重点研究的课题.
猜你喜欢
数学杂志(2022年5期)2022-12-02
智能计算机与应用(2022年10期)2022-11-05
新世纪智能(数学备考)(2021年5期)2021-07-28
现代计算机(2021年36期)2021-03-14
自动化学报(2019年11期)2019-12-12
计算机应用(2018年12期)2019-01-07
计算机应用(2017年4期)2017-06-27
光学精密工程(2016年4期)2016-11-07
光学精密工程(2016年3期)2016-11-07
信息安全研究(2015年3期)2015-02-28
