
混合贝叶斯个性化排序与内容的推荐算法研究
2019-12-11 11:25文晓棠吴少强
现代计算机 2019年30期
文晓棠,吴少强
(广东财经大学华商学院,广州510000)
0 引言
当今,数据量成指数级别增长,并且速度还在不断攀升。面对如此庞大的数据海洋,如何从海量数据中获取最想要的信息,这是一件很消耗时间和精力的事情。如今的搜索引擎很强大,根据输入的关键字在全球海量数据中寻找到匹配度高的内容,这在一定程度上解放了人类,但这一行为需要人们主动的发起,并且未考虑到每个人单独具备的特点。为了进一步解决这一问题,学者们提出了各具特点的推荐算法,根据每个人产生的行为记录推断其独特的兴趣并向其推送个性化信息。当下,推荐系统在部分领域比较常见,如电商平台、多媒体传播平台等。但在知识共享平台,推荐用户感兴趣的内容这一块还有待提升,因此在个性化知识推荐方面很有必要寻找解决方案。
推荐算法[1]分为以下几种:基于内容、协同过滤和混合推荐等算法。Goldberg等人[2]第一次引入协同过滤思想。Resnick等人[3]提出基于评分的协同过滤推荐算法,通过收集用户评分以获取其偏好,基于聚类算法分析用户相似性,完成推荐。Huang[4]运用Deep Structured Semantic Models(DSSM)模型构建一个基于位置感知的个性化新闻推荐模型。
上述推荐算法中,协同过滤算法是当前应用最为广泛的算法,该算法有一类为矩阵因式分解,通过FunkSVD算法或者其他改进算法等对矩阵进行分解,得到两个矩阵因子,从而用来预测用户对于未知项目的评分,但其评分是全局评分优化,不能单独对用户兴趣点排序,从而不能从大量数据中选取兴趣点较高的少量推荐项。
为了解决上述问题,本文将贝叶斯个性化排序和基于内容推荐结合,提出一种混合的推荐算法。主要贡献概括如下:
(1)基于矩阵分解的贝叶斯个性化排序算法,对三元组训练集进行训练,达到收敛,再通过计算用户个人感兴趣关键字与文章关键字匹对程度,来预测用户对该文章的感兴趣程度,两种算法充分发挥各自长处,形成混合的个性化知识推荐算法,以此来提高整体的推荐效果。
(2)在技术博文论坛,使用Kaggle上的公开数据集进行实验,取得显著推荐效果。
(3)基于混合的个性化知识推荐算法,设计个性化知识推荐模型,可使算法用于实践,具有较高实用价值。
1 相关算法
1. 1 贝叶斯个性化排序算法(BPR)
该算法是一种排序推荐算法,按照用户对物品的感兴趣程度进行排序,再选择优先级最高的物品推荐给用户。
在该算法中,训练数据集为数据对即<u,i,j>,表示的是用户u对于物品i比物品j更感兴趣。且该算法基于贝叶斯个性化排序,因此用户之间的喜好行为是相互独立的,用户对不同物品的偏好也相互独立。同时,BPR也基于矩阵分解模型,对于用户集与物品集形成的预测排序矩阵,通过优化分解得到矩阵

优化目标则为找到合适的矩阵因子V和W使得Xˉ和X最为相似。其中,V和W,通过最大后验估计优化P(V,W|>u),其中>u代表的是用户u对于物品的偏好关系。通过贝叶斯公式即可得到:

对该公式进一步分解之后,通过梯度上升法,最终使得V和W都收敛,模型即训练完成。最后使用V和W 矩阵因子求得预测值:xˉui=Vu∙Wi,并选择排序值最高的n个进行推荐。
1. 2 基于内容推荐算法(CBR)
基于内容推荐算法使用的数据包括用户兴趣关键字,及文章关键字。为了计算文章内容的关键字,需要对文章进行分词等文本预处理,之后可以计算这些词语的重要性。
本文基于TF-IDF算法[5]来评估词语在文章中的重要性,本研究中将每篇文章文本处理后的词语看作关键词的集合,即1篇文章有n关键词c1,c2,…,cn,其中1篇特定文章中词频分别是tf1,tf2,…,tfn。TF计算公式如下:

ni,j是关键词在所在文章dj中的出现次数,分母是所在文章dj中所有词语出现次数之和。
若关键词c在Dc中首篇文章出现,Dc的值越大,词语c在文章中区别于其他文章的作用就越小。如“大数据”在很多文章中出现,出现频率非常高,但它在文章中的区分度贡献小。因此,可以给文章中的关键词赋予一定的权重,如果它很少在文章中出现,通过比较可以容易找到相似文章,在文章中用于区别其他文章作用就大,其权重也就越大,反之权重越小。
本文使用IDF逆向文本频率指数计算文章中关键词的权重,计算公式如下:

|D|表示语料库中文章总数
|{j:t∈dj}|表示包含词语 ti的文章数目,若该词语不在语料库中,就会导致被除数为0,故一般情况下使用 1+|{j:t∈dj}|
假设文章数量D=1000篇,若“大数据”在所有文章中均出现,则其 idf=log(1000/1000)=0,若“人工智能”在20篇文章中出现,则其 idf=log(1000/20)=1.69897。
综上所述,使用上述TF-IDF=tfi*idif的值可以评价某个关键词在某篇首次出现的文章中的重要程度。计算某篇首次出现的文章所有组成的tf*idf和sim,可以评价文章之间的相似性。计算相似度公式如下:

依据上述公式,可以把用户感兴趣的词语形成关键词集合,然后在所有文章中计算这些关键词的tf*idf的和,从而找出相似度高的文章。
至于用户的喜好关键词集合,则由其以往的行为记录逐渐生成,同样可以使用TF-IDF算法处理用户阅读过的内容,从而形成用户喜好关键词集合。
2 混合贝叶斯个性化排序与内容的推荐算法
本文提出的混合算法主要基于上述两种算法,对技术博文进行个性化知识推荐。在该算法中,收集的用户信息包括用户对文章的评论、是否赞同、访问次数和访问时长等。对于收集到的信息会进行加权求得用户对文章的评分,形成评分矩阵S。
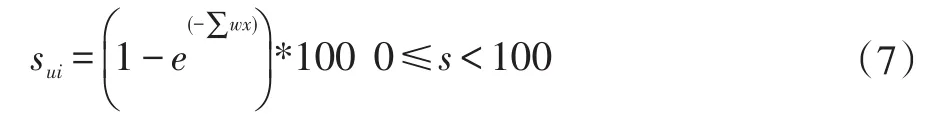
考虑相关性问题以及矩阵稀疏等问题,可使用聚集算法,形成用户集群。或者通过计算用户之间的相似度,直接取前n个邻居。相似度的计算可通过余弦相似度公式。

使用本算法设计的个性化知识推荐模型如图1所示。

图1混合贝叶斯个性化排序与内容的个性化知识推荐模型图
本混合推荐算法的核心过程如下:
S1:获取最近一段时间内用户所产生的行为记录,包括评论、是否赞同、访问次数和访问时长等。
S2:通过评分函数计算用户对文章的评分,并最终形成评分矩阵,行表示用户,列表示文章,并通过该矩阵抽取得到<u,i,j>三元组训练集。
S3:贝叶斯个性化排行对训练集进行训练,最终达到收敛,并通过模型对未交互过的文章进行预测,得到感兴趣的文章排序列表。
S4:使用基于内容推荐算法对推荐结果进行部分纠正,计算用户感兴趣关键字与推荐文章的关键字的匹配分值,如果相似度高则对推荐结果进行增强,否则对其进行削弱,得到最后的推荐结果。
其中,对于新注册用户,由于没有过去所产生的行为记录,无法得知其兴趣爱好并对其推荐,则可使用热点推荐以及全局基线方法为其进行推荐。同时,应用系统同时会定期对用户关键字进行削弱,并更新文章关键字。
3 实验结果与分析
3. 1 数据集
使用Kaggle公开数据集中的数据,主要是用户与文章交互的记录。统计包括文章2987篇,用户1895名。记录形式如图2所示。
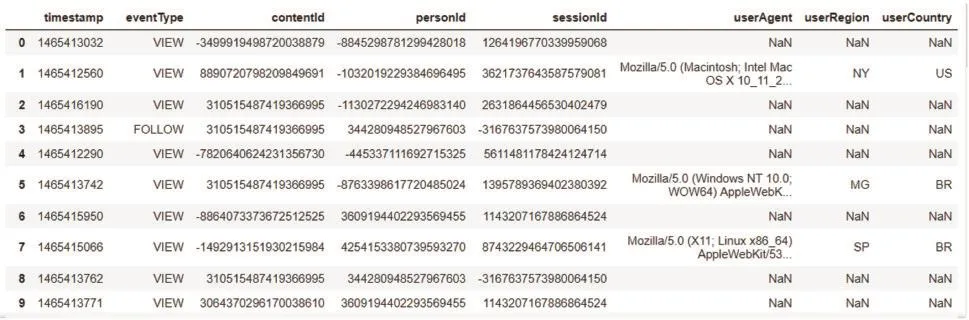
图2数据集记录形式
行为记录的数量时间分布图如图3,可将某个日期之前的数据作为训练数据集,后续数据作为验证数据集。
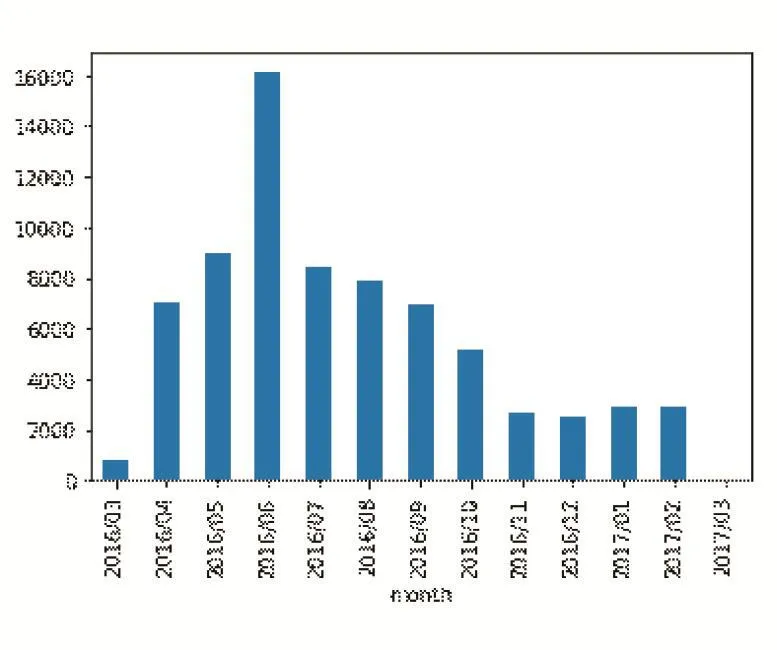
图3行为记录数量时间分布图
其中,行为包括:查看、喜欢、收藏、评论、订阅作者。各种类型行为统计数如表1。
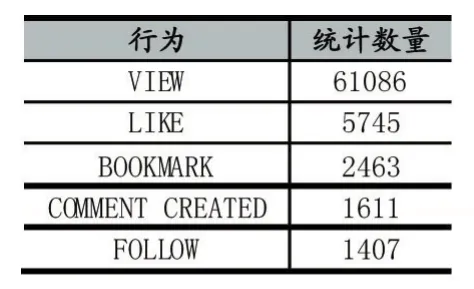
表1用户行为-统计数量表
3. 2 实验结果
首次通过余弦相似度求得邻居后,分别将邻居对某篇文章的评分乘以相似度值,后求和,得出对文章的预测评分。但效果不佳。
将数据转换为评分矩阵,并进行归一化处理。将模型通过训练后,部分预测排序值与真实数据评分的对比如图4-图5。

图4初始推荐predict值
从实验结果可以看出,贝叶斯个性化排序推荐算法推荐效果比较明显,均方误差也达到了较小的程度。但实验未能完全实践上使用基于内容推荐算法对推荐结果优化,理论上若完全实现混合算法,推荐效果要远优于实验结果,这是笔者需要进行的下一步工作。

图5贝叶斯个性化排序算法predict值

图6均方误差
3. 3 总结
使用混合推荐算法,在一般规模的数据上,表现出较好的推荐效果。不过还有很多可以改进的地方。当数据规模达到一定程度时,便需要将推荐系统部署在集群计算平台,以此来加快模型的训练等。并且在超大数据规模上,深度学习构建的模型可能占据更大的优势。通过深度学习构建神经网络对技术博文进行推荐还有待研究,并且对用户的评论也可进行相应的情感分析来辅助推荐。
猜你喜欢
名家名作(2021年4期)2021-05-12
科普童话·学霸日记(2020年1期)2020-05-08
小天使·一年级语数英综合(2019年2期)2019-01-10
智富时代(2018年11期)2018-01-15
智富时代(2018年11期)2018-01-15
科教导刊·电子版(2017年32期)2018-01-09
读与写·教育教学版(2017年10期)2017-11-10
数学学习与研究(2017年10期)2017-06-22
南都周刊(2015年4期)2015-09-10
南都周刊(2015年3期)2015-09-10
