
Policy Gradient算法的研究与实现
2019-12-11 11:25刘俊利
现代计算机 2019年30期
刘俊利
(西南科技大学计算机科学与技术学院,绵阳 621000)
0 引言
强化学习[1]是机器学习的重要研究方向之一。不同于传统的监督学习和非监督学习,它对数据没有任何要求,只需要通过接收环境对动作的反馈并据此不断对行动方案进行改进,就能让机器逐步学会一项新的技能。按照基于值和基于策略两个方向可以对强化学习到的众多算法进行分类。基于值的(Value-Based)算法其本质上都是学习价值函数Q(state,action)[2],在具体应用时,需要先确定state(当前时刻的环境状态)和action(当前时刻的行为),然后再根据Q(state,action)选择价值最大的动作执行。基于值的算法是一种间接选择策略的做法,而基于策略的(policy-based)算法是直接对策略进行建模,不需要学习价值函数Q通过模型即可输出下一时刻的动作。Policy Gradient算法是强化学习中基于策略的经典算法之一。本文将分析Policy Gradient算法的原理及公式,然后借助Tensor-Flow[3]训练框架的算力,最终完成该算法的运行与实现。
1 Policy-based简介
value-based和policy-based是机器学习的两大类算法。value-based方法采用的策略(例如ε-greedy[4])是确定性策略,即无论什么时候,只要给定一个状态si就有唯一一个动作ai输出与之对应;而policy-based方法采用的策略是带参数θ的策略π(一个参数化函数,具体公式见式(1)),不断调整θ并利用策略评分函数J(θ)(具体公式见式(2))测量不同θ下的策略π的质量,待J(θ)函数值达到最大,此时对应的策略π即为最优策略。

policy-based方法和value-based方法的使用对比效果如图1、图2所示。其中√表示宝藏;×表示陷阱;箭头表示策略。在运用value-based方法时,由于该方法的确定性策略和迷宫的对称结构,导致当智能体处在灰色格子上时无法分辨自己处于哪个灰色格子上,所以最后学习到的策略如图1所示:当初始位置在第一个白格子上,就会陷入死循环;而运用policy-based方法时,因为学习的策略不是确定输出一个具体的动作,而是输出在这个状态下可以执行的动作的概率分布,所以即使在相同状态下,每次采取的动作也很可能是不一样的。所以最后学习到的策略如图2所示,不会造成死循环。

图1 value-based RL
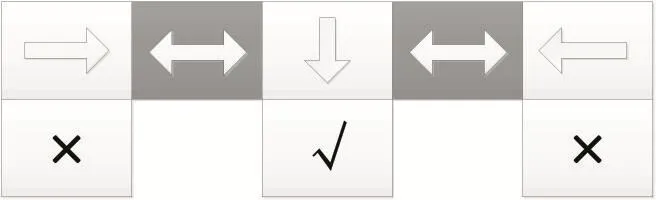
图2 policy-based RL
2 Policy Gradient算法
Policy Gradient[5]算法是强化学习的一种基于策略的算法。与其他基于价值的算法不同,该算法直接通过模型输出需要采取的动作,不需要学习价值函数Q。策略网络(Policy Network)和优化目标是Policy Gradient算法的核心。
2. 1 Policy Network 框架
Policy Gradient算法的实现过程主要是训练一个策略网络(Policy Network)。Policy Network框架具体如图3所示。该网络输入为当前状态(State),输出为各个动作的概率(State)。
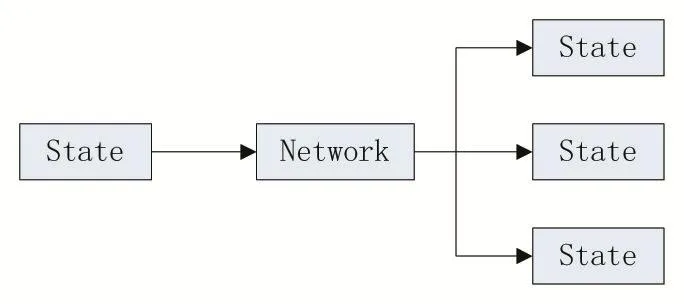
图3 Policy Network框架
2. 2 优化目标
2.2.1 目标函数
Policy Gradient算法采用的是带参数θ的策略,不断的调整参数θ可以实现策略的优化,为了评估不同参数对策略的影响,引入目标函数,目标函数的值越大,模型质量越高。一般而言,目标函数主要有三种形式:对于episode任务,优化目标是初始状态收获的期望(式3);对于连续性任务,没有明确的初始状态,优化目标是平均价值(式4);其他情况可以将每一时间步的平均奖励作为优化目标(式5)。
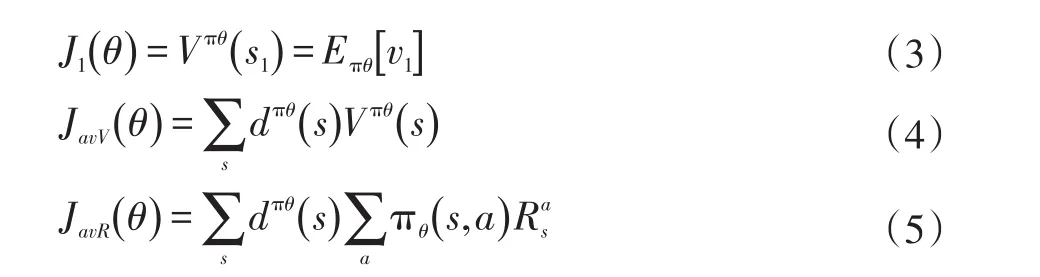
2.2.2 优化函数
在明确了目标函数以后,为了实现最优模型,需要找到一个参数θ使得目标函数能够取到最大值。对目标函数求导可以表示为式(6)。
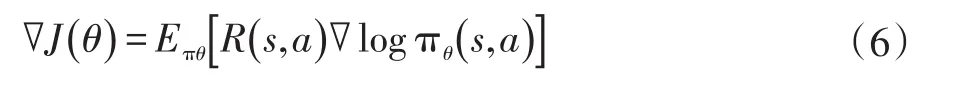
3 Python实现
3. 1 初始化
初始化的内容包括变量初始化,获得观察量以及清空gradBuffer等,具体实现如下:
running_reward=None
reward_sum=0
episode_number=1
total_episodes=10000
init=tf.global_variables_initializer()
#开始训练
with tf.Session()as sess:
rendering=False
sess.run(init)
observation=env.reset()#observation 是环境的初始观察量(输入神经网络的值)
gradBuffer=sess.run(tvars)#gradBuffer会存储梯度,此处做一初始化
for ix,grad in enumerate(gradBuffer):
gradBuffer[ix]=grad*0
3. 2 定义策略网络
定义策略网络的过程包括定义输入层,定义损失loss然后再根据损失loss定义Adam优化器,最后再计算并保存梯度。具体实现如下:
#定义和训练、loss有关的变量
tvars=tf.trainable_variables()
input_y=tf.placeholder(tf.float32,[None,1],name="input_y")
advantages=tf.placeholder(tf.float32,name="reward_signal")
#定义loss函数
loglik=tf.log(input_y*(input_y-probability)+(1-input_y)*(input_y+probability))
loss=-tf.reduce_mean(loglik*advantages)
newGrads=tf.gradients(loss,tvars)
#优化器、梯度。
adam =tf.train.AdamOptimizer(learning_rate=learning_rate)
W1Grad=tf.placeholder(tf.float32,name="batch_grad1")
W2Grad=tf.placeholder(tf.float32,name="batch_grad2")
batchGrad=[W1Grad,W2Grad]
updateGrads=adam.apply_gradients(zip(batchGrad,tvars))
3. 3 训练
训练的过程包括:使用当前决策进行游戏交互、计算并保存每一局的梯度、将保存的梯度应用到网络并输出结果。其中计算并保存每一局的梯度在整个过程中起承上启下的作用,具体代码如下:
#一局游戏结束
if done:
episode_number+=1
# 将 xs、ys、drs从 list变成 numpy数组形式
epx=np.vstack(xs)
epy=np.vstack(ys)
epr=np.vstack(drs)
tfp=tfps
xs,hs,dlogps,drs,ys,tfps=[],[],[],[],[],[]
#对epr计算期望奖励
discounted_epr=discount_rewards(epr)
#对期望奖励做归一化
discounted_epr-=np.mean(discounted_epr)
discounted_epr//=np.std(discounted_epr)
#将梯度存到gradBuffer中
tGrad=sess.run(newGrads,feed_dict={observations:epx,input_y:epy,advantages:discounted_epr})
for ix,grad in enumerate(tGrad):
gradBuffer[ix]+=grad
4 程序运行界面效果
利用深度学习框架TensorFlow实现一个简单的Policy Gradient算法示例:一个CartPole小游戏,该游戏通过控制下面的黑色小车向左向右移动使连接在上面的杆保持垂直不倒,如果杆子过于倾斜,或者小车移出一个范围,那么游戏结束。不停地训练,直到在游戏中平均能拿到200的奖励,训练停止。在训练过程中,游戏持续时间越来越长,连接在小车上面的杆也越来越向垂直靠拢,可以明显感受到“学习”的过程。
图4运行效果
5 结语
本文首先介绍了强化学习中policy-based方法的基本概念,之后分析了Policy Gradient算法的策略网络结构和目标优化,然后利用TensorFlow搭建环境,定义并训练策略网络,最终实现Policy Gradient算法的一个简单示例:一个CartPole小游戏。运行结果良好,在不断的训练中,平均奖励稳步上升,直到达到200,整个训练结束,最终实现了Policy Gradient算法。
猜你喜欢
九江学院学报(自然科学版)(2022年2期)2022-07-02
幼儿教育·父母孩子版(2022年4期)2022-05-08
华人时刊(2020年13期)2020-09-25
VOGUE服饰与美容(2020年9期)2020-09-02
华东师范大学学报(自然科学版)(2019年3期)2019-06-24
福建基础教育研究(2019年3期)2019-05-28
西部资源(2018年1期)2018-11-01
中学生数理化·八年级数学人教版(2016年4期)2016-08-23
理科考试研究·高中(2016年9期)2016-05-14
新高考·高二数学(2015年7期)2015-10-22
