
基于注意力机制引导的图像描述生成
2019-12-11 11:25董虎胜徐建峰孙浩吴铭仪
现代计算机 2019年30期
董虎胜,徐建峰,孙浩,吴铭仪
(1.江苏省智能服务工程技术研究开发中心,苏州215009;2.苏州经贸职业技术学院,苏州215009)
0 引言
图像描述生成(Image Caption)[1-2]是计算机视觉中一项新兴的任务,它的目标是对给定的图像自动生成一段有意义的描述性内容。由于该任务除了计算机视觉中传统的检测、分类等工作外,还涉及到对自然语言的处理,因此非常用具有挑战性。作为对图像的高层语意理解,图像描述生成技术在图像检索、图像与视频事件分析、舆情分析等应用中具有广泛的前景,因此一经提出便获得了广泛的关注。
目前在对图像描述生成方法的研究中,基本上都采用了Encoder-Decoder的系统架构[3],借助于在其他视觉任务中取得了优秀性能的深度卷积神经网络作为Encoder来获得图像的特征表达,再使用Decoder网络根据特征表达训练解码器生成最终的文本描述序列。由于深度卷积神经网络(Deep Convolutional Neural Network,DCNN)具有优秀的特征学习能力,而长短时记忆网络(Long-Short Term Memory,LSTM)[4]具有很好的序列数据处理性能,使用CNN+LSTM的图像描述生成方法在获得的图像描述质量上要显著优于图像特征与描述语句特征匹配的方法,与使用固定文本描述模板添加关键词的方法相比,更具有灵活多样性[5]。
在对图像中的内容使用自然语言进行描述时,除了从整体把握图像之外,人们也会更加关注图中一些局部的信息,这对应于表达语句中的一些关键词语,而句子中的其他词语主要对这些关键词语进行上下文的描述。
1 图像特征的提取
当前的深度学习领域已经提出了多种模型架构,如GoogleLeNet、VGG、ResNet等,这些架构在诸如图像识别、目标检测等其他计算机视觉任务中表现出了优秀的性能。另外这些优秀的模型还提供了在ImageNet数据集上作了训练的参数,在其他任务中作适当调优即可作为优秀的特征提取器使用。因此,本文采用了在性能与网络架构上取得比较好的平衡的ResNet-101深度残差网络(Residual Net)[6]作为模型的 Encoder,模型的参数为在ImageNet上训练后的结果。
与其他的网络架构相比,深度残差网络设计了一种特殊的“短路”结构。若将输入设为x,将某一网络层设为H,那么以x作为输入后该层的输出将为H(x)。如AlexNet和VGG等一般架构的CNN网络会直接通过训练学习出H的各个参数,即直接学习H:x↦H(x)。但残差学习的是使用多个网络层学习输入与输出之间的残差之间的残差-x,即学习的是 H:x↦+x,其中 x为恒等映射(identity mapping),而即为有参网络层需要学习的输入与输出之间的残差。在DCNN模型中基本上都采用了多个“卷积-池化”层的堆叠来实现对图像进行空间嵌入,随着模型层数的加深,所获得的特征图在空间尺寸上越来越小,但是在通道数上越来越多,一方面达到对嵌入空间的降维,同时也能够捕捉原始图像不同方面的特征。总体上,随着层数的加深,学习到的特征也越来越抽象,更接近于对图像高层语义信息的提取。本文在使用ResNet-101架构时丢弃了最后两层,即全连接层与分类层,仅取最后输出的2048个通道的14×14大小的特征图(Feature Map)用作为Decoder的输入。
2 基于注意力机制的图像描述生成模型
作为图像描述自动生成模型中的Decoder,其主要任务是接收Encoder输出的特征图并逐字生成对图像的描述的句子。由于生成句子时需要按序列逐字生成,因此当前使用的Decoder模型均为循环神经网络(Recurrent Neural Network,RNN)[7]。不过尽管朴素的RNN模型具有比较强的序列处理能力,但是仅能利用前一时刻的信息,无法捕捉到较远间隔前的相关信息。与朴素RNN相比,常短时记忆网络(Long-Short Term Memory,LSTM)采用了四个特殊的门结构来实现对长时依赖关系的处理,有效地解决了序列数据中的长时记忆与短时依赖。图1给出了LSTM网络的结构。
如图1所示,LSTM实际上是一种具有重复神经网络模块(即LSTM Cell)的链式形式。在LSTM Cell中包含了遗忘门、输入门、输出门三个门结构,它们分别控制了当前的输入样本与Cell前一时刻的状态对当前状态Ct的影响,以及当前Cell状态中有多少信息被输出到LSTM的输出ht中。通过对这些处理的循环迭代,LSTM就实现了对Cell状态的序列化更新处理。训练好的LSTM网络就能够捕获序列数据中长短时依赖关系及数据内在模式。
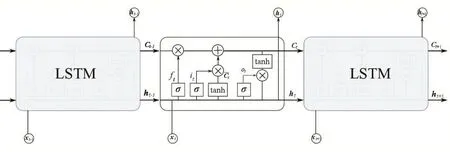
图1 LSTM网络展开结构图
LSTM中的遗忘门决定了当前Cell需要从前一个时刻的状态Ct-1中丢弃什么信息,遗忘门接收前一时刻的状态ht-1与当前输入的样本xt,并使用sigmoid函数输出一个位于(0,1)之间的数,实现对原有记忆信息进行选择性的保留和遗忘。该步骤的运算式为:

式中Wf和bf分别为权重矩阵与偏置向量,表示向量的拼接运算,为sigmoid函数。
在前一时刻的状态ht-1与当前输入的样本xt经过遗忘门后,下一步需要决定让多少新的信息被存储进Cell状态中。这一过程分为两步,首先是使用遗忘门来决定哪些信息需要被更新,即获得图1所示的it;其次是使用一个tanh层生成用于Cell状态更新的备选向量接下来,Cell新的状态将由通过遗忘门的信息与通过输入门的信息相加来获得。整个过程可以被表达为如下的算式:

式中的⋆表示对向量按元素进行相乘的运算。
LSTM Cell最终的输出是Ct过滤后信息,首先由输出门来确定Cell中哪些信息将被输出,即获得一个过滤模板Ot,然后将通过tanh激活的Ct与Ot相乘获得最终输出ht。整个过程可表达为如下的算式:
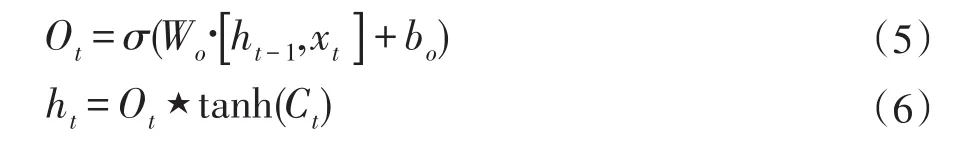
尽管直接使用LSTM作为Decoder即可实现对图像描述的生成,但是语言描述生成时采用的是按序列逐词生成的方式,这些词与图像中的内容应具有很强的图-文相关性,但是从整幅图像中提取的特征会引入不必要的噪声,增强了图像特征的语意模糊性。反之,若能够生成的词语找到图像中的对应的区域,再提取特征则可以增强图像特征的表达能力。这种在图像特征提取取对图像不同区域施加不同权重的策略即为注意力机制。图像的注意力机制应满足=1的条件,即图中的各像素点的权重αp,t的和应为1,p指代像素点位置。
本文的注意力网络接收Encoder网络生成的特征图后,首先将使用扁平化运算将其变形为N×14×14×2048维的向量,然后通过由三层全连结层、一层ReLU激活层和一层Softmax层构成的网络。Softmax层的输出即为获得的注意力权重。
获得权重后,在描述句子的生成中的每一步中,都需要使用注意力网络根据Encoder生成的特征图与LSTM前一步的状态ht-1计算每个像素的权重,然后再根据LSTM前一步生成的单词与当前加权的特征图生成下一个单词。完整的图像描述生成模型如图2所示。

图2本文基于注意力机制引导的图像描述生成模型
3 实验
为了验证本文基于注意力机制引导的图像描述生成模型的有效性,在MSCOCO(Microsoft Common Objects in Context)2014数据集上进行了实验。MSCOCO2014数据集为每张图像提供了至少5个文字描述句子,而且已经作了训练集、验证集、测试集的划分,其中分别包含113287、5000、5000张图像。本文仅在训练集上对模型进行训练,并在测试集上进行图像描述句子的生成,采用人工观测图像描述进行评价,未引入客观量化评分标准。
在实验中单词嵌入维度为512维,由于训练集中图像描述句子中单词数量长短不一,为了使输入的序列具有相同的长度,在对各个句子按单词数量降序后进行了填补。在LSTM与注意力网络中设置隐藏层与Softmax输出的维度均为512维。在训练时设置Encoder与Decoder模型的优化器均为Adam,初始学习率分别为0.0001与0.0005,并每隔20个epoch进行0.9倍的衰减。此外,实验中取批次大小为32,训练最大epoch数为120。模型使用Ubuntu环境下的PyTorch深度学习框架实现,采用NVIDIA GTX 1080显卡进行硬件加速。
图3给出本文模型在测试集上获得的图像描述生成结果,从图中可以看出训练后的模型能够生成比较流畅的文本描述,语句的结构比较完整,与图中内容也比较匹配吻合。

图3
4 结语
本文提出了基于注意力机制引导的图像描述生成算法。模型使用深度卷积神经网络作为图像特征的提取器,在获得图像的特征图后使用LSTM语言模型来生成图像描述,为了使生成的描述句子更为准确,根据LSTM的输出与特征图计算了注意力权重,使得提取的特征具有更好的表达能力。在MSCOCO数据集上的实验表明本文模型能够生成比较优秀的文本描述。
猜你喜欢
成都信息工程大学学报(2022年2期)2022-06-14
小雪花·成长指南(2022年1期)2022-04-09
北京大学学报(自然科学版)(2022年1期)2022-02-21
成都信息工程大学学报(2021年3期)2021-11-22
中学生数理化(高中版.高考理化)(2021年5期)2021-07-16
中学生数理化(高中版.高考理化)(2020年11期)2020-12-14
北京航空航天大学学报(2020年10期)2020-11-14
北京航空航天大学学报(2019年9期)2019-10-26
第二课堂(课外活动版)(2016年2期)2016-10-21
意林(2011年10期)2011-05-14
