
自由立体显示中基于深度卷积神经网络的虚拟视点生成方法
2019-12-06 05:44付傲威王琼华
液晶与显示 2019年11期
付傲威,赵 敏,罗 令,邢 妍,邓 欢,王琼华*
(1. 四川大学 电子信息学院,四川 成都 610065;2. 北京航空航天大学 仪器科学与光电工程学院, 北京 100191)
1 引 言
近年来,显示技术越来越重要,人们已经不再满足于传统的2D(Two-dimensional,二维)显示,对于3D(Three-dimensional,三维)显示的需求越来越迫切。裸眼3D显示无需借助眼镜或头盔等辅助设备即可重建出3D图像,引起了诸多研究人员的关注[1-5]。自由立体显示作为裸眼3D显示技术的一种,能够得到清晰的3D效果。自由立体显示需要获取3D图像,传统3D获取方法利用相机阵列对真实的目标场景进行拍摄,得到不同角度的视差信息,但存在成本过高以及标定、传输及存储困难的问题。当目标场景为虚拟场景时,可在3D建模软件中搭建相机阵列进行3D获取,但存在渲染时间过长和难以实现3D实时获取等问题[6-7]。利用深度图像绘制(Depth Image Based Rendering,DIBR)技术合成虚拟视点图像的方法具有成本低和绘制速度快等诸多优势,被认为是一种有效的3D获取方法[8-9]。基于DIBR的虚拟视点图像生成利用参考视点的纹理图像和深度图像,通过3D Warping变换获得特定位置的虚拟视点图像[8]。然而上述两种方法都受到深度图像精度和场景遮挡区域的影响,导致生成的虚拟视点图像存在明显的空洞和伪影,影响了自由立体图像的合成质量和自由立体显示效果。
深度卷积神经网络(Deep convolutional neural networks,DCNN)是一种新兴的图像生成和修复技术,该技术通过对样本图像的学习,可以实现图像超分辨率重建、图像去噪和图像修复[10-12]。Pathak提出基于语义的深度卷积神经网络,通过学习图像特征,生成图像缺失部分的预测图,最终实现缺失图像的修复。该方法能够修复大面积图像空洞,但纹理信息失真严重,需要大量的样本图像对网络进行训练,训练成本高、耗时长[13]。Yang提出一种多尺度卷积神经网络,通过对图像特征和纹理特征进行学习,实现了高分辨率的图像修复。该方法能够还原图像纹理,但图像部分内容修复不全,需要大量训练集[14]。
本文提出了一种基于深度卷积神经网络的虚拟视点合成方法。该方法给定一个随机初始化神经网络作为虚拟视点图像先验,经过卷积神经网络结构不断迭代对生成的虚拟视点图像进行修复,能够有效去除虚拟视点图像的空洞和伪影,得到高质量的虚拟视点图像。该方法无需大量训练集,且耗时较短。合成的多幅虚拟视点图像可交织生成自由立体图像,用于自由立体显示。实验结果表明,所提方法能够有效提升虚拟视点图像的质量,应用在自由立体显示装置上,具有良好的自由立体显示效果。

图1 所提方法的流程图Fig.1 Principle of the proposed method
2 方法原理
本文所提的基于深度卷积神经网络的虚拟视点合成方法的流程如图1所示,该方法包括3个过程:(1)虚拟视点图像生成过程:输入参考视点纹理图像和深度图像,进行3D Warping变换,得到多幅虚拟视点图像;(2) 虚拟视点图像修复过程:利用深度卷积神经网络对生成的虚拟视点图像进行修复,得到无空洞和伪影的虚拟视点图像;(3) 自由立体图像合成过程:利用像素映射算法,将修复后的虚拟视点图像交织成自由立体图像,用于自由立体显示。
2.1 DIBR虚拟视点图像生成
DIBR虚拟视点图像生成是通过3D Warping变换生成目标视点视差图像的过程,其原理如图2所示。3D Warping变换包括两个步骤:(1)利用已知的深度信息,将参考视点纹理图像反向投影到3D空间中;(2)将3D空间点重投影到虚拟成像平面,得到对应的虚拟视点图像。
参考视点图像的反向投影和重投影过程表示为:
(x,y,z)T=RrKr-1(u,v,1)Td(u,v)+tr,
(1)
(l,m,n)T=KvRv-1{(x,y,z)T-tv},
(2)
其中,(x,y,z)表示三维空间点,(u,v, 1)T为参考视点图像平面的像素齐次坐标,Kr,Rr,tr分别表示参考视点对应摄像机的内部矩阵、旋转矩阵及平移矩阵。Kv,Rv,tv分别表示虚拟视点对应摄像机的内部矩阵、旋转矩阵及平移矩阵,d(u,v)表示(u,v)位置对应的深度值,(l,m,n)T表示虚拟视点位置,对参考视点纹理图像执行反向投影和重投影两个操作,即可生成目标位置的虚拟视点图像。
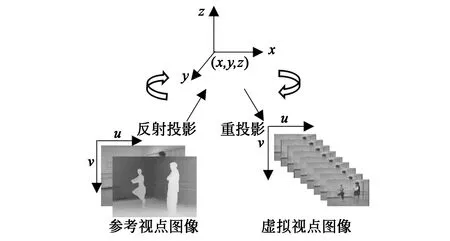
图2 基于DIBR的虚拟视点图像生成原理示意图Fig.2 Schematic diagram of the virtual viewpoint image generation based on DIBR
2.2 虚拟视点图像修复
受深度图像精度和场景遮挡区域的影响,利用DIBR技术生成的虚拟视点图像存在明显的空洞和伪影。因此,需要对虚拟视点图像进行修复,去除空洞和伪影。所提方法利用一个随机初始化的卷积神经网络作为图像先验,基于虚拟视点图像和任务依赖的观测模型,通过不断迭代使模型参数逼近最大似然,最终输出修复后的虚拟视点图像[10]。随机初始化卷积神经网络作为图像先验,通过迭代修复虚拟视点图像,无需大量的训练图像,因此大大节省了资源和时间。
所提方法从随机分布中采样虚拟视点图像数据,并基于该数据分布限制受损观测样本分布,从而对虚拟视点图像进行修复。图像修复任务可以被认为是能量最小化问题,表示为:

(3)
其中E(x;x0)是一个任务依赖的数据项,x*表示修复后的虚拟视点图像,x表示网络输出,x0为未修复的虚拟视点图像,R(x)是一个正则化项,用来抓取虚拟视点图像的通用先验。所提方法采用卷积神经网络来代替R(x),卷积神经网络的参数化表征形式为:x=fθ(z),x∈R3×H×E,z∈RC×H×W,其中z为编码张量,θ为网络参数。

(4)
其值选取如下:

(5)

图3 虚拟视点图像的修复过程示意图Fig.3 Schematic diagram of virtual viewpoint image inpainting
在随机初始化卷积神经网络的基础上,给定一个随机权重θ0,采用随机梯度下降算法训练,经过多次迭代,得到最优参数θ*,使生成的虚拟视点图像不断逼近初始的虚拟视点图像,最终获得修复后的虚拟视点图像。
采用的卷积神经网络为编解码的网络结构,编码过程包括卷积、下采样、批量标准化以及修正线性单元激活过程,对生成的虚拟视点图像特定进行学习。解码过程包括批量标准化、卷积、修正线性单元激活和上采样过程,最终输出修复后的虚拟视点图像。虚拟视点图像的修复过程如图3所示,其中di表示第i次迭代的编码过程,ui表示第i次迭代的解码过程,si表示第i次迭代的残差连接过程,将di层输出和ui层输入连接在一起,实现跳跃式传递。经过一次编解码过程,完成一次迭代,多次迭代,最终输出修复后的虚拟视点图像。
2.3 自由立体图像合成
自由立体图像由多幅修复后的虚拟视点图像的像素按照视点矢量渲染算法映射生成[7]。合成的自由立体图像的子像素按照虚拟视点图像的视点顺序连续分布,自由立体图像的像素结构如图4所示,可以看出[15],每幅虚拟视点图像像素已填充到单个柱透镜单元覆盖的全部子像素位置。

图4 自由立体图像与虚拟视点的关系示意图Fig.4 Schematic diagram of the relationship between autostereoscopic image and virtual view
3 实 验
实验采用微软亚洲研究院提供的“Ballet”图像集中一个视点的纹理图像和深度图像进行测试,虚拟视点图像生成过程如图5所示。
图5(a)和图5(b)分别为参考视点的纹理图像和深度图像,图5(c)为合成的8幅虚拟视点图像,每幅图像的分辨率为1 024×768。由细节放大图可以看出,受场景遮挡关系的影响,生成的虚拟视点图像中,人物和图像边缘存在明显的黑洞,背景区域存在大量细微的黑洞。由于视点1和8与参考视点5距离最远,其对应生成的虚拟视点图像黑洞区域最大。将生成的8幅虚拟视点图像分别输入深度卷积神经网络,对虚拟视点图像进行不断迭代,每50次迭代输出一幅对应的虚拟视点图像,迭代过程如图6所示。由图中可以看出,当迭代次数n=400次时,虚拟视点图像的空洞和伪影得到了很好的去除。

图5 参考视点和虚拟视点图像。(a)参考视点纹理图像;(b)参考视点深度图像;(c)虚拟视点图像。Fig.5 Reference view and virtual viewpoint images.(a) Reference view texture image; (b) Reference view depth image; (c) 8 virtual view images.

图6 迭代过程输出的虚拟视点图像Fig.6 Output virtual viewpoint images during iteration process

图7 未修复和修复后的虚拟视点图像。(a)未修复的虚拟视点图像;(b)修复后的虚拟视点图像。Fig.7 Unrepaired and restored virtual viewpoint images. (a) Unrepaired virtual viewpoint images; (b) Restored virtual viewpoint images.

图8 本文所提方法与传统方法修复的虚拟视点图像PSNR对比图Fig.8 Comparison of PSNR of virtual viewpoint images inpainting by the proposed method and traditional method
8幅未修复和修复后的虚拟视点图像如图7所示。图7(a)为利用3D Warping变换直接生成的虚拟视点图像,图7(b)为经过深度卷积神经网络修复后的虚拟视点图像。由图7(a)和7(b)的细节放大图对比可以看出,修复后的1和8视点图像的空洞区域得到了很好的修复,同时背景区域中小的空洞也得到了填充。
为验证所提方法的有效性,将修复后的虚拟视点图像与传统像素填充方法修复后的虚拟视点图像进行了对比。不同虚拟视点个数下,两种方法的PSNR(峰值信噪比)值对比结果如图8所示。本文所提方法中,修复后的虚拟视点图像的PSNR均值为25.6,而传统像素填充方法修复后的虚拟视点图像的PSNR均值为22.5之间。由实验结果可知,所提方法对虚拟视点图像的修复效果优于传统方法。
实验采用视点矢量渲染算法,将修复后的8幅虚拟视点图像合成为分辨率3 840×2 160的自由立体图像,并在斜率为0.181 8的8视点自由立体显示器上进行显示,不同视角的再现3D图像如图9所示。可以看出,随着视角从左向右进行移动,芭蕾舞者手部与墙上贴图之间的距离逐渐增大。实验结果表明,所提方法生成的虚拟视点图像应用在自由立体显示器上,具有较好的3D显示效果。
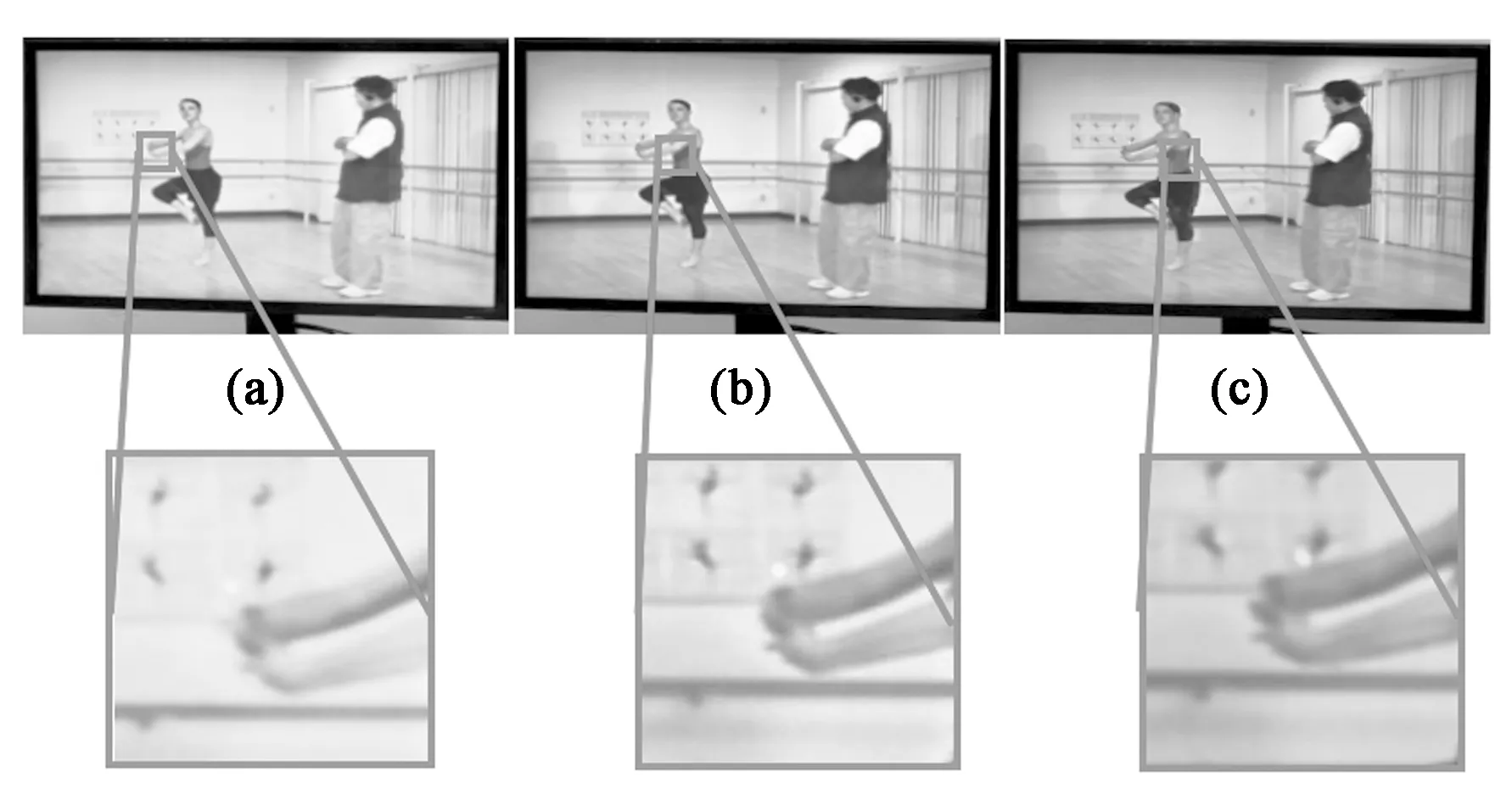
图9 不同视角的再现3D图像。(a)左视角;(b)正视角;(c)右视角。Fig.9 Reconstructed 3D images with different views.(a) Left view; (b) Positive view; (c) Right view.
4 结 论
本文提出了一种基于深度卷积神经网络的虚拟视点生成方法。该方法采用深度卷积神经网络对虚拟视点图像的空洞和伪影进行修复,并将修复后的虚拟视点图像通过视点矢量渲染算法合成自由立体图像,应用在自由立体显示器上,实现了较好的3D显示效果。实验结果表明,所提方法生成的虚拟视点图像质量相比传统方法有明显提升。
猜你喜欢
上海金属(2021年2期)2021-04-07
软件(2020年3期)2020-04-20
摄影之友(影像视觉)(2018年12期)2019-01-28
Coco薇(2017年8期)2017-08-03
故事作文·高年级(2017年2期)2017-03-01
环境(2016年7期)2016-05-14
Coco薇(2015年5期)2016-03-29
新闻传播(2015年20期)2015-07-18
新闻前哨(2015年2期)2015-03-11
中国水利(2015年5期)2015-02-28
