
实时视频流缩放系统设计
2019-12-06 05:45陆宝毅刘银萍刘卿卿
液晶与显示 2019年11期
严 飞,陆宝毅,刘银萍,刘卿卿,2,陈 伟
(1.南京信息工程大学 自动化学院,江苏 南京 210044;2.江苏省大气环境与装备技术协同创新中心,江苏 南京 210044;3.南京信息工程大学 大气物理学院,江苏 南京 210044)
1 引 言
数字视频具有数据量大,实时性高等特点,如果数字视频的处理仅仅依靠软件算法来实现,那么对软件和CPU的计算能力都有较高的要求,但用硬件的方式来实现的话,在处理速度以及效果上都优于前者[1]。并且在算法优化已经无法提高计算速度的前提下, 将部分单一、耗时的图像处理操作用硬件来实现可以有效地提高算法的速度[2-5]。目前处理数字图像常用的视频缩放算法分别是最邻近插值算法(Nearest interpolation),双线性内插值算法(Bilinear interpolation)以及双三次插值(Bicubic interpolation)。相较于前两种缩放算法,双三次插值算法得出比前两种插值算法更加平滑的图像信息。
随着显示器的分辨率越来越多样化,原有的一些视频格式越来越满足不了多样化的显示器分辨率,故需要采用相应的视频缩放模块将视频源的分辨率转换为对应显示器的分辨率[6]。目前的视频流缩放系统一般是基于双线性内插值算法进行设计,且进行缩放比例是固定倍率,这样的系统的缩放图像信息的缺失较大,且不能灵活地配置缩放信息[7-8]。本文设计了一种实时视频流缩放系统设计,采用了双三次插值的缩放算法,实现了视频图像的任意比例的缩放,且易于硬件实现。
2 系统组成

图1 实时视频缩放系统硬件组成Fig.1 Hardware composition of real-time video stream scaling system
实时视频流缩放系统包括两路OV5640视频输入接口、DDR3存储模块、VGA输出接口以及外围电路(电源电路、配置电路和时钟电路)模块。系统的硬件组成如图1所示,其中采用由两个OV5640摄像头模块组成的OV5642模块模拟实时的视频流的输入。
系统支持最大分辨率3 840×2 160的实时视频流的输入和最低分辨率100×100的视频数据的输出。系统主控芯片使用的型号为xc7a100tfgg488-2的一款FPGA,属于Xilinx公司ARTIX7系列。
首先,FPGA配置OV5642分别输出两个分辨率为2 592×1 944的视频,然后将输出的视频分别进入双三次插值运算模块进行缩放计算。当FPGA检测到有双三次插值运算有计算结果即有实时的有效数据时,控制DDR3外部存储将输入的视频缓存下来等待后端VGA模块读取数据进行显示,由于有两路的缩放视频流,所以设计一个PIP(Picture in picture画面叠加)模块,让缩放成不同分辨率的视频数据在一个分辨率为1 920×1 080的显示屏上进行叠加显示,由于采集的数据为RGB格式,在进行视频叠加时需要转换为YUV格式进行叠加。图像处理的流程如图2所示。
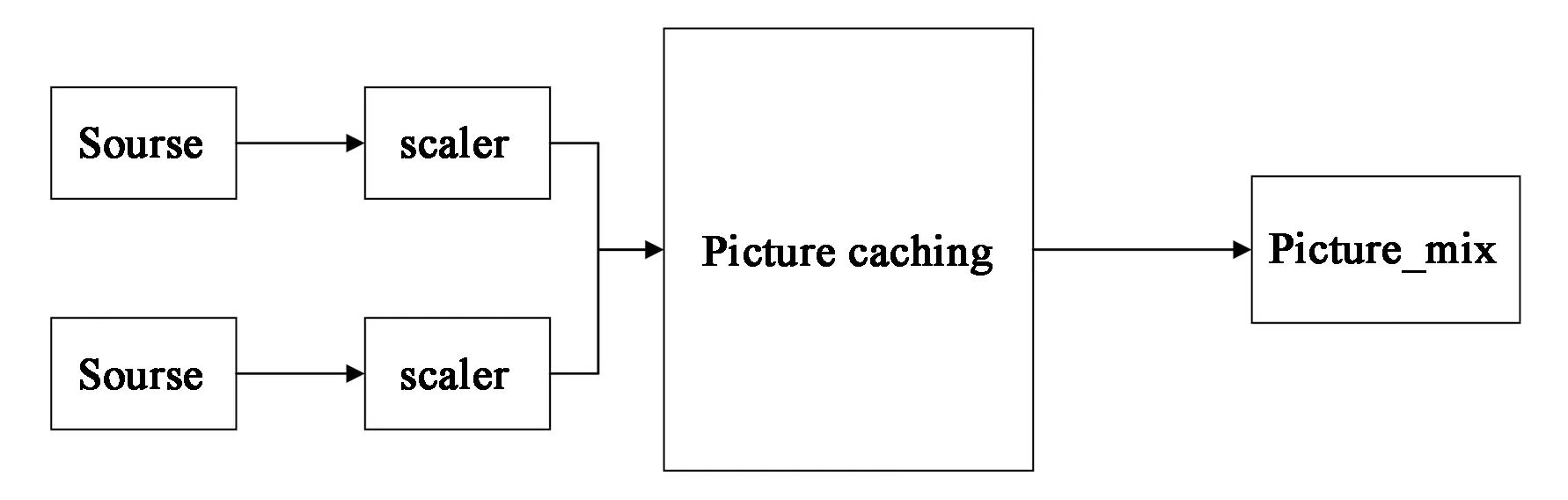
图2 本文图像处理流程Fig.2 Image processing diagram of this paper
该系统采用模块化的设计思路,主要包括:实时视频流采集模块,视频流处理模块以及视频叠加输出模块。其中视频流处理模块又包括图像的双三次插值缩放模块和图像缓存模块。
3 双三次插值缩放解析
3.1 数据缓存
双三次插值需要用一个4×4的模板进行计算,故需要提前准备缓存至少4行的数据[9-10],为了能够有足够的数据,且避免RAM出现不够用,造成输入和输出不实时同步的情况,本设计用了8个RAM分别缓存了8行的数据进行乒乓操作,且为了方便进行读写操作,本次设计采用了分布式RAM(Distributed memory)。如图3所示,每当缓存一行数据结束后便有一个计数器进行计数,当写到一行的最后一位且输入数据有效且该计数器的值小于8时,则换一个RAM进行缓存下一行的数据。每计算出目标图像的一行数据,需要取出源图像的4行像素数据,当已经缓存了4行及以上的视频数据时便开始进行读操作。所示每当处理到一行的最后一个像素数据时则需要进行新的一行或者多行的数据。如果目标图像的下一行对应的源图像的行数与当前计算的行数相差一行,则在计算目标图像的下一个行的输出时只要从已经缓存源图像的行数据中读取新的一行即可。但是如果目标图像的下一行对应的源图像的行数与当前计算的行数相差大于等于4行,即检测到RAM中缓存的行数不够时,将停止读操作,等待RAM中缓存的行数足够一次运算,继续进行读取和计算操作。
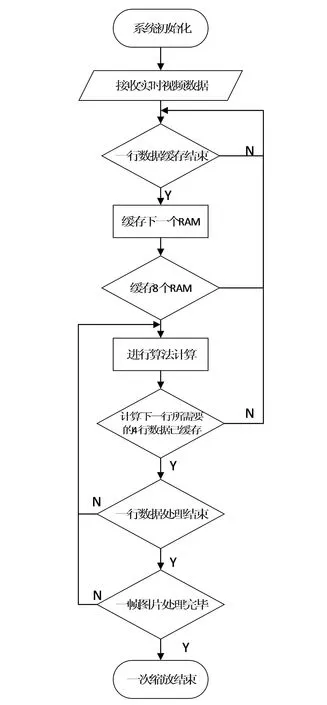
图3 实时视频缓存流程图Fig.3 Real-time video buffer flow chart
3.2 双三次插值运算
双三次插值的主要计算是参加运算的16个像素的影响因子即权值的计算[11]。为了方便标注,将16个像素的位置编号为a00,a01……a33,首先我们要求出这16个像素分别与目标图像待求的像素之间的位置关系,这里设目标图像对应的源图像的位置是P(x+u,y+v),其中u和v是小数部分,则a00的地址可以表示成(1+u,1+v),a01可以表示为(u,1+v)……。
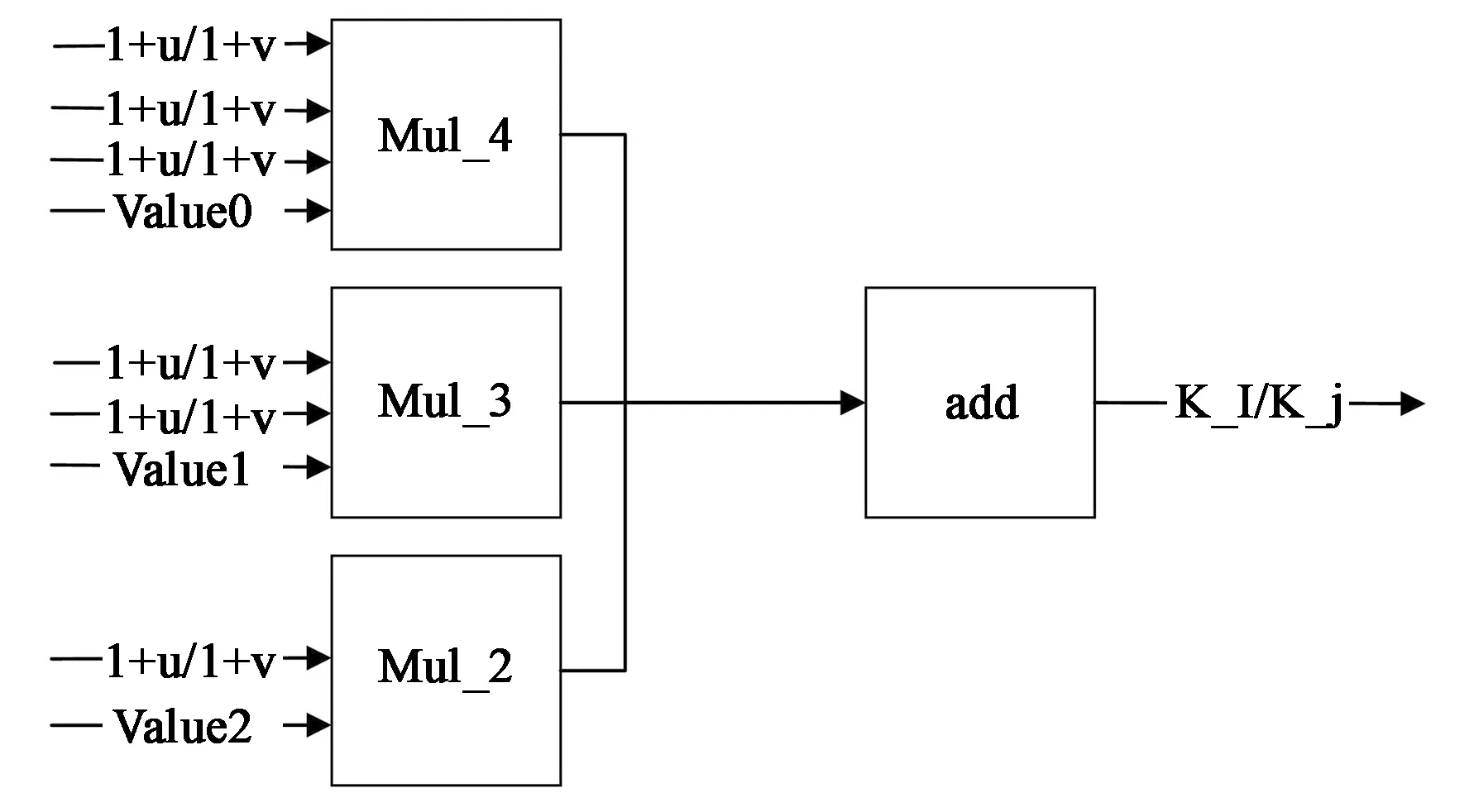
图4 a00位置行列系数处理流程Fig.4 Processing flow of a00 location row and column coefficient
如图4所示,a00的地址为(1+u,1+v)将该地址的行坐标和列坐标分辨带入插值基函数coef(aij)中则可以的得a00在行方向和列方向的对应系数。因为插值基函数coef(aij)中存在着多个单流向的乘法处理单元,本设计采用了流水线的设计方法来提升了系统的工作效率,其中value0,value1,value2代表插值基函数coef(aij)中的系数。同理,我们可以得到其他15个像素在行和列的系数。
计算完各个像素点的影响因子用每个点的像素值乘以其对应的影响因子,得到16个值相加便是目标像素点的像素值。如图5所示,在计算像素权值时a00,a03,a11,a12,a21,a22,a30,a33的权值是正数,其他的像素点的像素值是负数,所以在计算像素点值时需要先分开计算正数和负数,其中dOut_add_0和dOut_add_1是16个像素中部分正数的和,dOut_sub_0和dOut_sub_1是部分负数的和,dOut_add是所有正数的和,dOut_sub是所有负数的和,dOut_sum是加权和,利用正数部分减去负数部分或者是负数部分减去整数部分(不算符号位)。由于整个算法中浮点数的产生[12],在计算初便将参与计算的数值(二进制)左移8位,所以在最终需要对最终的结果右移8位,dOut_shift便是对算出的加权和进行右移8位的操作。由于像素的值区间在0和255之间,如果输出的像素值如果大于255便只取其七八位。

图5 目标像素点值计算仿真图Fig.5 Simulation diagram of target pixel point value computation
4 DDR缓存解析
4.1 DDR读写操作
DDR3的读写控制采用的是XILINX提供的MIG(Memory Interface Generator)IP核控制方案,MIG IP核控制方案位用户提供了两种接口总线控制模式,一种是NATIVE总线控制模式,一种是AXI4总线模式。相对与NATIVE总线控制模式,AXI4的读写控制时序比较复杂,且NATIVE控制总线也可以通过逻辑控制扩展多个读写端口,因此,本文选择NATIVE接口总线作为本次设计的控制方案[13-16]。
如图6所示,在NATIVE总线下的写操作包括写请求、写数据、写响应。在DDR准备好写入数据(app_wdf_rdy = 1)的前提下,当有写请求(app_wdf_wren = 1)时,便开始一次写DDR操作,将提前准备好的数据写入DDR中对应的地址中。同样,在NATIVE总线下的读操作包括读请求、读数据、读响应。在DDR准备好进行读操作(app_wdf_rdy ≠ 1)且不在进行读操作(app_wdf_wren = 1)的前提下,当有写请求(app_rd_data_valid = 1)时,便开始一次读DDR操作,将数据从DDR中对应的地址中读出来。
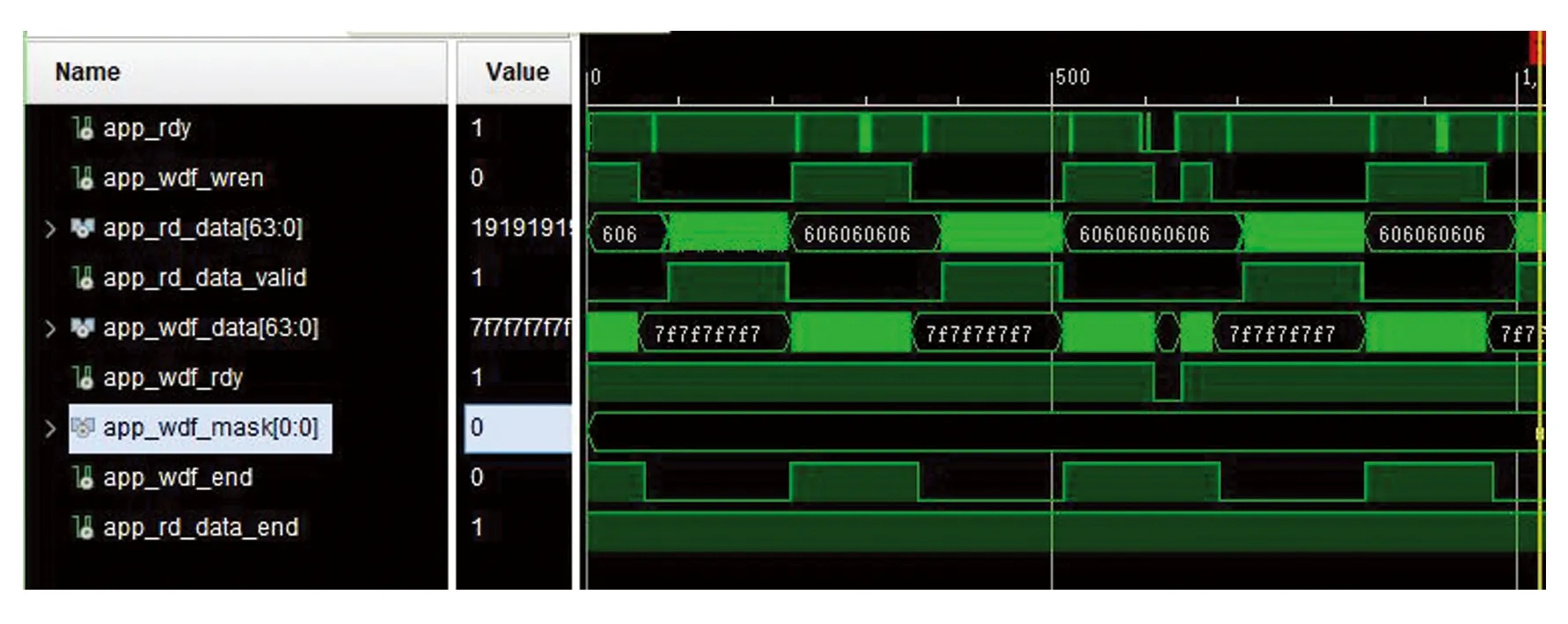
图6 Native总线下DDR读写操作Fig.6 DDR read-write operation under native bus
4.2 多端口DDR读写
由于OV5642同时输出两路的2 592×1 944的视频数据,所以需要同时将这两路视频数据存入DDR3中,并且在后端也同样需要同时将视频数据从DDR3中读出来进行缩放操作。
在程序设计时开辟了两个通道进行读写操作。如图7所示,在进行读操作时,对两个端口进行依次循环查询其状态信息,如果通道0有读请求并且该通道的突发读的长度不为0,进入通道0的读操作,否则对通道1进行查询。同样,如果通道1有读请求并且该通道突发读的长度不为0,进入通道1的读操作。
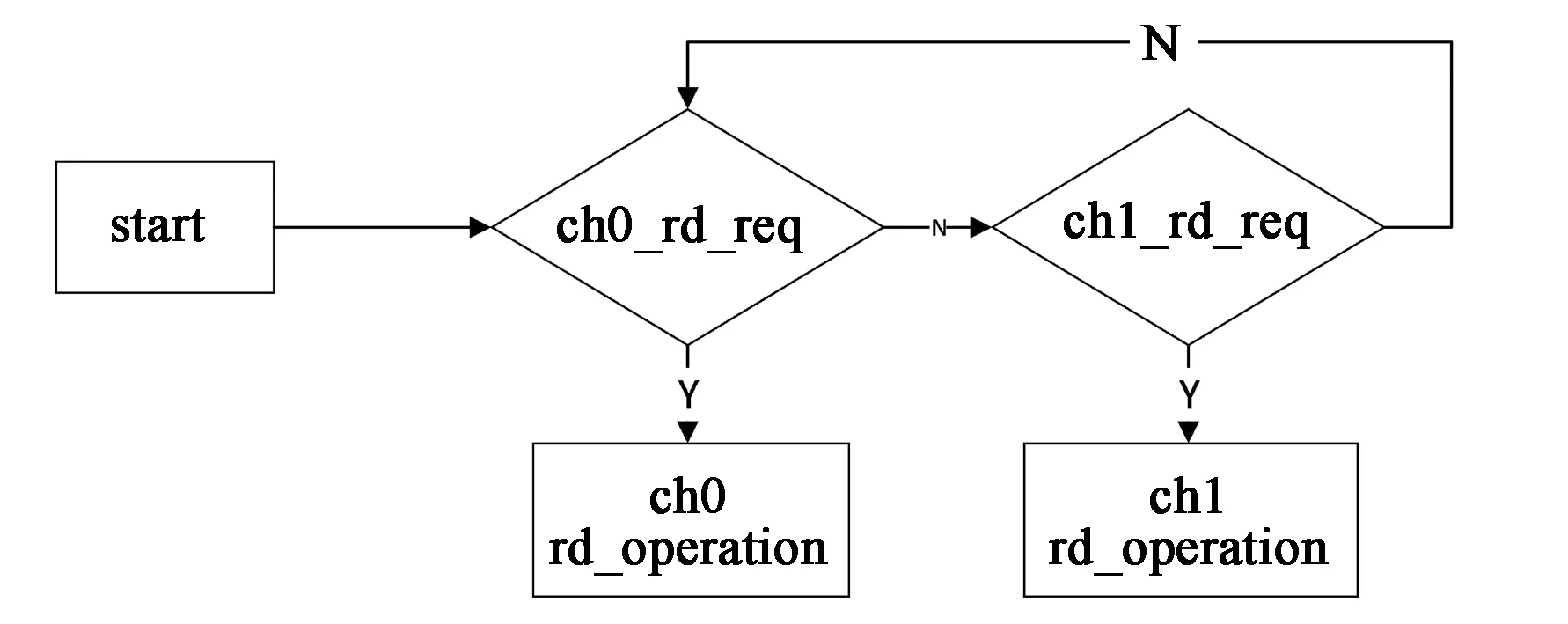
图7 读操作查询流程Fig.7 Read operation query process
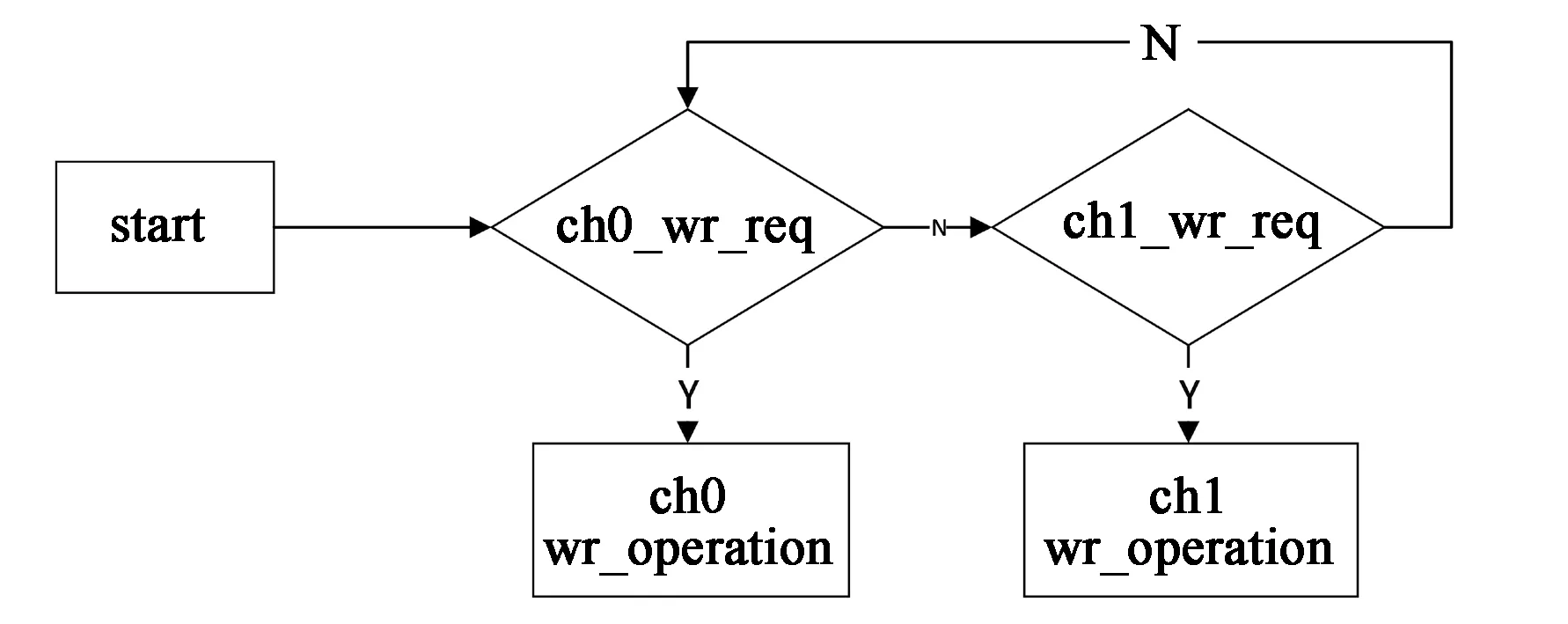
图8 读操作查询流程Fig.8 Write operation query process
如图8所示,在进行写操作时,与读操作相似,也是对每个端口进行查询其状态信息,若是通道0有写请求则进入通道0的写操作,否则对通道1进行查询。为了避免输出图像变形的情况,本设计采用乒乓操作,让DDR3的读操作和写操作分别在不同的BANK进行。
5 画面叠加输出
画面叠加是将已经缩放完成的视频在一个1 920×1 080的画布上显示。通常一帧图像分为有效区域和消隐区域[17],其中我们在显示屏上看见的区域即有效区域。由于图像是逐行扫描的,所以在到达需要显示图像的区域时从DDR中读出相应的数据显示。
如图9所示,在第一幅图片的显示有效区域时,产生读信号从DDR的对应位置中取出数据进行显示,同样在第二幅图显示有效区域时,产生读信号从DDR中读出数据进行显示。
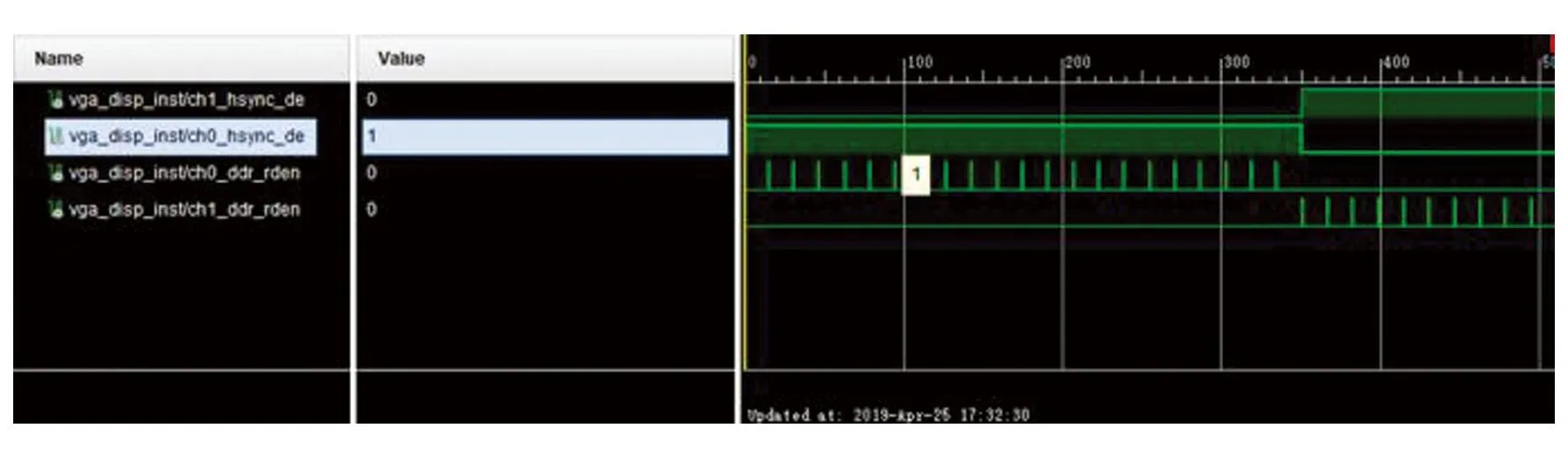
图9 画面叠加原理仿真Fig.9 Simulation of picture superposition principle
6 实验结果
本设计的目的是为了满足一些不是常规分辨率的显示器,所以在上板测试时设置是将2 592×1 944分辨率的视频图像分别缩放至731×731和1 920×1 080。如图10所示,显示屏幕的背景是1 920×1 080分辨率的视频图像,前端窗口显示的是731×731分辨率的视频图像。满足任意比例的缩放效果。
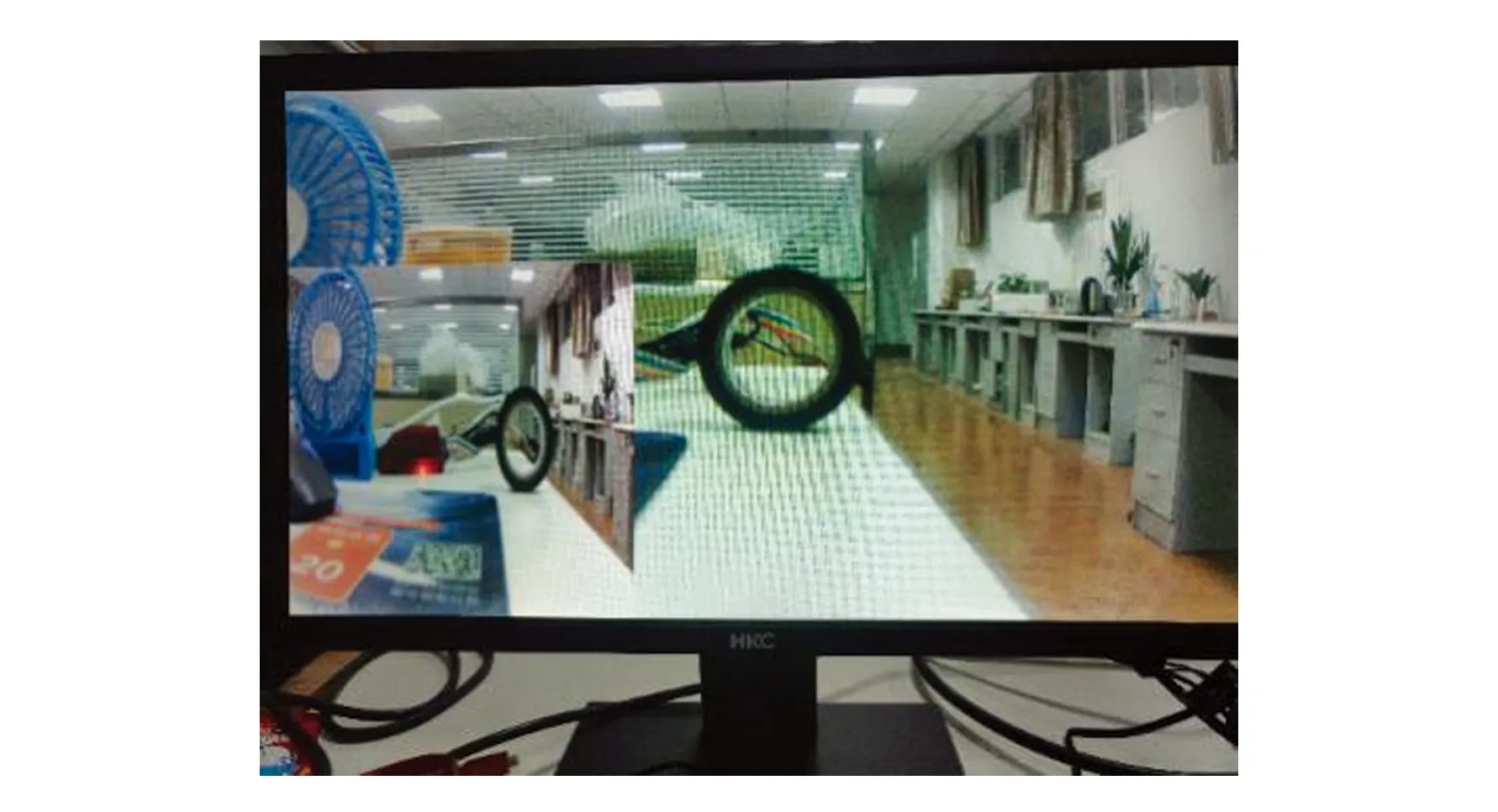
图10 双三次插值算法在FPGA上实现效果图Fig.10 Implementation of bicubic interpolation algorithms on FPGA
实验结果表明,基于FPGA的双三次插值图像缩放系统能够支持3 840×2 160的图像进行任意比例的缩放。实际板上验证时视频流从ov5642输入,经过缩放、缓存、同步以及拼接等多个处理过程,最终通过VGA接口输出至支持1080P的显示器上。验证系统所采用的硬件平台是xc7a100tfgg488-1,如表1所示,其消耗的LUT(Look Up Table, 查找表)资源占FPGA总资源的69.9%,由于本设计的行缓存所消耗的片上资源LUTRAM,所以LUTRAM资源的占用为76.16%,在DDR读写部分用到了时钟域的转换,采用的是消耗BRAM资源的FIFO,BRAM资源的占用为26.3%,用来缩放计算的DSP资源占用为60.42%。

表1 FPGA资源利用情况
7 结 论
提出了一种实时视频流缩放系统的硬件结构设计,基于双三次插值图像算法,采用流水线的设计思路对算法的浮点运算进行优化,采用乒乓操作的思想避免了视频流输入与输出不同步的情况,减少了计算延时,易于FPGA的实现,在提高系统的运算速度的同时减少了对硬件资源的消耗,并在VIVADO环境中对该设计进行测试验证,实现了任意比例缩放。经实际验证,该实时视频流缩放系统设计支持最高3 840×2 160分辨率的视频输入,最低支持缩放至100×100分辨率输出,能够满足需要特殊分辨率的显示屏的需求。
猜你喜欢
无线互联科技(2022年11期)2022-08-18
数字通信世界(2020年11期)2020-12-04
数学物理学报(2019年3期)2019-07-23
西南石油大学学报(自然科学版)(2019年1期)2019-01-28
家庭影院技术(2018年9期)2018-11-02
新生代(2018年16期)2018-10-21
制造技术与机床(2017年7期)2018-01-19
北京航空航天大学学报(2017年2期)2017-11-24
物流科技(2017年5期)2017-07-06
自动化学报(2017年5期)2017-05-14
