
基于注意力双层LSTM的长文本情感分类方法
2019-12-02 07:41:46
重庆电子工程职业学院学报 2019年2期
(重庆电子工程职业学院 通信工程学院,重庆401331)
0 引言
随着科学技术的迅猛发展,互联网已成为全球各地用户表达意向和观点的一个平台,产生了大量的文本。对文本进行情感分析可以挖掘用户真正的意见和建议。文本情感倾向性分析最早由Nasukawa[1]提出,用于判定句子、短语和词所表达的情感极性,例如肯定、否定和中性,更细粒度的情感倾向性分析还包括表达的情感强度。近年来,富含情感信息的文本在互联网上大量产生,情感倾向性分析以其丰富的应用背景,逐渐变成了自然语言处理(NLP)领域的研究热点之一。
传统的文本情感倾向性分析主要采用两类方法:基于情感词典的方法和基于机器学习的方法。基于情感词典的方法主要是利用情感词典中词语的情感倾向和情感强度对词语进行打分,然后对分值进行累加,根据总分判断文本的情感类别。这种方法容易受到情感词典领域性和人工规则完备性的影响。基于机器学习的方法是对特征进行选择和建模,主要是使用人工标注的数据训练机器学习模型,如SVM、KNN,其重要的影响因素是训练语料的质量,且该方法难以表达复杂的语言关系。
近年来,深度学习技术快速发展,使得计算机从无标注文本中自动学习到文本的深层表示成为可能。基于深度学习的方法利用神经网络来模拟人脑的学习过程,利用CNN、RNN和LSTM等进行文本情感分析。在NLP领域中,基于深度学习的方法在建模和效果优化等方面具有比较明显的优势。
利用自动情感倾向性分析技术挖掘海量评论文本所包含的情感倾向,能够发现大众的情感演化规律,为制定营销策略和监控社会舆情提供决策支持,具有重要的应用价值。然而,由于长文本评论的篇幅长、正负情感特征分布离散,现有方法难以根据全文信息准确判断长文本情感倾向,因此本文提出一种基于注意力双层LSTM的长文本情感倾向性分析方法。该方法首先用LSTM学习句子级情感向量表示;然后用双向LSTM对文档中所有句子的语义及句子间的语义关系进行编码,基于注意力机制根据句子的情感语义贡献度进行权值分配,加权句子级情感向量表示得到文档级情感向量表示;最终经过Softmax层得到长文本情感倾向。
1 相关工作
长文本评论情感倾向性分析方法逐渐开始使用深度学习方法,其中以RNN[2]、CNN[3]和LSTM[4]为代表的深度学习方法在情感倾向性分析领域内取得较好的结果。
基于CNN的算法虽然可以有效地进行文本分类,但文本情感倾向性分析问题并非单纯的文本分类问题。因为训练语料和预测语料均为包含作者情感的文本,故需要考虑文本上下文联系才能实现对长文本情感倾向的准确判别。因此,理想的文本情感倾向性分析算法需要考虑对长文本时序关系进行记录和学习。2014年,Kim等[3]利用CNN进行文本情感分类,利用词嵌入把文本映射成低维空间的特征矩阵,利用卷积层和下采样层提取特征,实现文本情感分类。2015年,Severyn等[5]用CNN进行推特长文本情感倾向性分析,使用非监督神经语言模型训练词嵌入,在Semeval-2015任务上取得第一名的好成绩。2017年,Segura等[6]第一次应用CNN进行西班牙语的情感倾向性分析。
RNN因包含输入信息的时序关系而在情感倾向性分析中有重要应用。2014年,Irsoy等[2]利用RNN进行了情感倾向性分析,比基于传统机器学习的文本情感分类方法的效果更好。2015年,Siwei等[7]使用RNN进行文档级情感分类,应用池化层自动判断在情感分类中重要的词语。但不可忽略的是RNN自身具有一定的缺陷,当循环轮次过多时,会产生长期依赖和梯度爆炸等问题。2016年,Zhang等[8]应用RNN进行微博的情感倾向性分析研究,输入层输入词嵌入序列,经过隐藏层数学变换得到句子向量,然后进入输出层。实验结果表明计算句子向量表示有助于句子深层结构的理解,也有助于不同领域的文本情感倾向性分析研究。
针对RNN的不足,其变体LSTM在神经网络模块的链式结构中采用记忆单元来控制信息的交互,从而避免了RNN的缺陷。基于LSTM网络的算法可以通过有选择的保存和遗忘信息来存储文本中重要的信息,从而完成文本情感倾向性分析。2015年,Tai等[9]构建了长短式记忆(LSTM)的解析树,将标准的LSTM时序链式结构演化为语法树结构,在文本情感分类上取得了较好的结果。2015年,Tang等[10]提出基于LSTM和门循环神经网络的情感分类方法LSTM-GRNN,该方法通过两步建模文档向量表示。首先使用LSTM学习句子向量表示;再次,应用双向门神经网络对句子语义及句子在文档表示中的语义关系进行编码得到文档向量表示,通过Softmax层进行情感正负倾向分类,取得了较好的结果。2016年,Xu等[4]利用缓存LSTM进行长文本情感倾向性分析,把记忆单元以不同遗忘速率分成几组,更好地保存记忆信息。
2 中文长文本情感分类方法
2.1 原理框图
本文基于注意力双层LSTM进行长文本评论情感倾向性分析。首先,利用LSTM从词嵌入学习得到句子级情感向量表示;接着,通过双向LSTM对文档中所有句子的语义及句子间的语义关系进行编码;然后,基于注意力机制对具有不同情感语义贡献度的句子进行权值分配;最后,加权句子级情感向量表示得到长文本的文档级情感向量表示,经过Softmax层分类得到长文本评论情感类别。算法原理如图1所示。
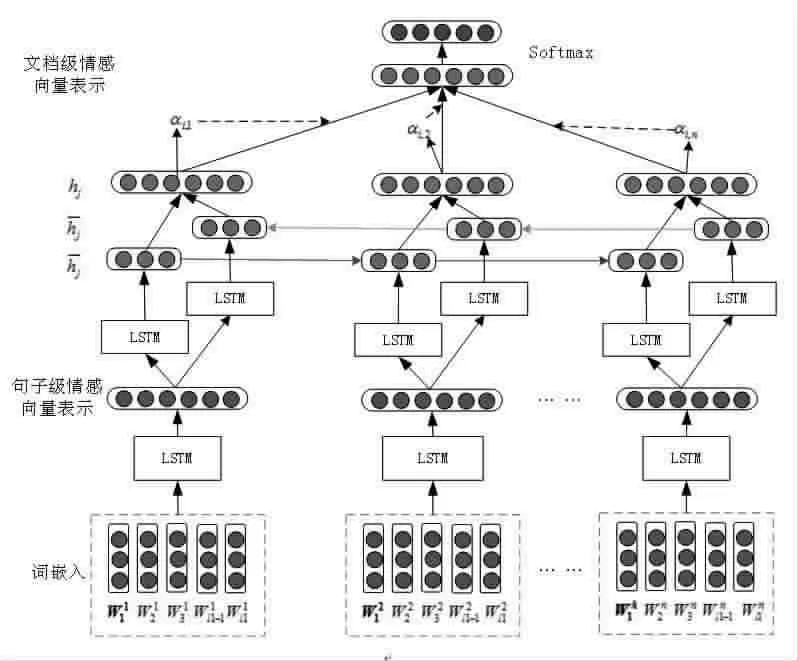
图1 基于注意力双层LSTM的长文本情感倾向性分析方法原理图
2.2 LSTM
LSTM是一种特殊的RNN类型,可以学习长期依赖信息。1997年,Hochreiter等人提出了LSTM[11],它比一般的RNN记忆能力更强,主要用于记忆长距离相关信息,它克服了循环神经网络的梯度爆炸和梯度消失的缺点,并在很多任务中取得了不错的结果。其结构如图2所示。
普通的RNN能够处理远距离相关信息,因为当前的输入包括前一时刻的输出。但是如果相关信息与当前输入位置之间的距离过远,RNN的远距离学习能力会骤降,而LSTM能帮助克服这一问题。LSTM通过一个细胞状态来ct调节整个结构,使得结构具有更强的记忆能力。
LSTM提出的记忆存储格由四部分组成:输入门、输出门、遗忘门和自循环连通结点。LSTM可以实现遗忘或记忆的功能,这是通过“门”来丢弃或者增加信息实现。输入门将新的信息选择性的记录到记忆存储格中,遗忘门能够将记忆存储格中的信息选择性地遗忘,输出门确定记忆存储格的输出值及记忆存储格是否作用于其他神经元。
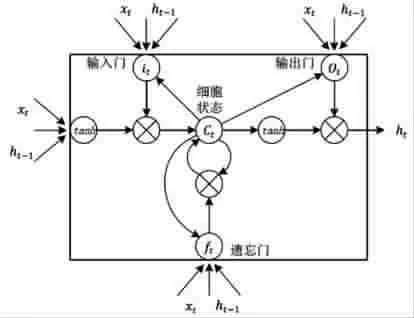
图2 长-短时记忆结构示意图
首先,LSTM要确定将被存放在细胞状态ct中的新信息,由输入门确定待更新值,然后将新候选值加入到状态中,其计算方法如式(1)所示。

其中,it表示输入门,xt表示t时刻输入值,ct-1表示t-1时刻细胞状态,ht-1表示t-1时刻输出值,σ 表示 Logistic Sigmoid 函 数,wxi、whi、wci、bi为待学习参数。
除了输入和存放新信息,还需要确定从细胞状态ct中丢弃的旧信息内容。这一功能由遗忘门完成,其计算方法如式(2)所示。
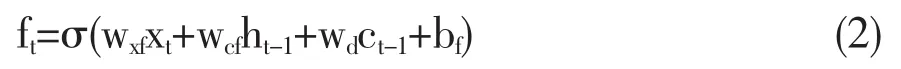
其中,ft表示遗忘门,xt表示t时刻输入值,ct-1表示t-1时刻细胞状态,ht-1表示t-1时刻输出值,σ 表示 Logistic Sigmoid 函数 ,wxf、wcf、wcf、bf为待学习参数。
接下来,更新细胞状态ct,其计算方法如式(3)所示。
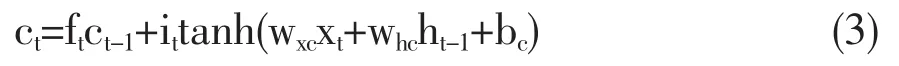
其中,ft表示遗忘门,it表示输入门,xt表示t时刻输入值,ct-1表示t-1时刻细胞状态,ht-1表示t-1 时刻输出值,wxc、whc、bc为待学习参数。
最后,LSTM需要确定细胞状态的待输出部分。这一功能由输出门完成,其计算方法如式(4)所示。
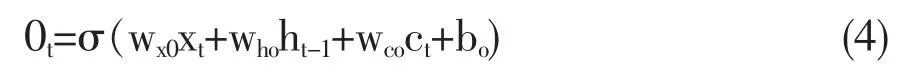
其中,Ot表示输出门,xt表示t时刻输入值,ct表示t时刻细胞状态,ht-1表示t-1时刻输出值,σ表示 Logistic Sigmoid 函数,wx0、wh0、wco、bo为待学习参数。
LSTM本质上是一种RNN,把细胞状态通过tanh层进行处理并得到一个 [-1,1]区间中的值,将其和待输出部分相乘后最终确定输出结果,其输出值的计算方法如式(5)所示。

其中,Ot表示输出门,ct表示细胞状态,ht表示输出值。
基于以上步骤,LSTM网络可以完成对信息的选择性存储记忆功能,最终将有用信息保留并输出。因可有效解决RNN中存在的长期依赖问题,所以LSTM网络在自然语言处理中有良好的效果。
2.3 词嵌入
词嵌入又叫词向量,它将一个单词或词组映射成低维空间中的实数向量。词嵌入可以由经典的神经网络语言模型 (NNLM)[12]在训练中产生,Word2vec是一个语言建模工具,实现将词表征为实数值向量,是基于Mikolov[13]提出的神经网络概率语言模型。词嵌入输入整个文本集,利用神经网络结构,输出训练之后的每个词语对应的词向量。词嵌入上的每一维代表一个特征,此特征能表示词语的上下文信息和语法信息。词嵌入应用到自然语言处理领域中的很多研究里,例如用词嵌入计算词语的语义相似度、词性分析等等。词嵌入的低维空间表示也避免了使用词袋模型进行文本特征表示时造成的“维度灾难”问题。
Word2vec改进了神经语言模型,结合了人工神经网络和概率模型,是一个可以用来快速计算词嵌入的工具。Word2vec包含了两种训练模型,分别为CBOW模型和Skip_gram模型,两种模型都是由NNLM改进而来,其结构如图3所示。

图3 CBOW模型和Skip_gram模型结构
从图3中可知,Word2vec使用的词嵌入表示方式是分布式表示,采用一个三层模型:输入层、投影层和输出层。CBOW模型是根据上下文来预测当前词语的概率。Skip-gram则是根据当前词语来预测上下文的概率。下面主要介绍CBOW模型的Hierarchical Softmax框架。
首先把每个单词映射成矩阵W对应位置上的列向量 wt,用 Context(w)=w1,w2,w3,…,wT表示上下文信息,把全文中的词嵌入通过求和或连接得到隐藏层的输入,词嵌入模型以最大化输出概率作为目标,其计算公式如(6)所示。
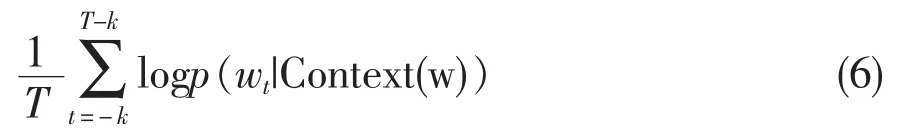
CBOW模型训练词嵌入的网络结构如图4所示。
输入层:包含context(x)中2c个词的词嵌入,m表示单个词嵌入的维度。
v(context(w)1),v(context(w)2),…,v(context(w)2c)∈Rm

图4 CBOW模型的网络结构示意图
投影层:对输入层的2c个词嵌入求和累加,作为投影层的输入,计算方法如公式(7)所示。

输出层:输出层对应一棵哈夫曼二叉树,二叉树构造过程如下:叶子节点是语料中出现过的词,叶子节点对应的权值是词频。在哈夫曼树结构中,一共N(=|D|)个叶子节点,分别对应词典D中的词,非叶子节点N-1个。
基于词嵌入的神经网络通常使用随机梯度下降方法训练,其中梯度通过误差反向传播算法获得[14]。CBOW模型的Hierarchical Softmax框架使用Softmax计算概率,如公式(8)所示。

公式(8)中每个yi是对应于单个输出词的一个未正规化的log概率,计算方法如公式(9)所示。
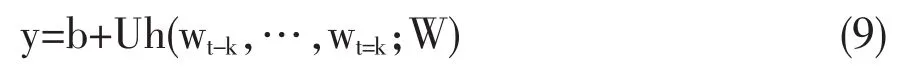
其中,U,b是分类器Softmax的参数,函数h是通过词嵌入的连接或者平均得到。
2.4 句子级情感向量表示
在词嵌入的分布式表示取得进展后,句子级、文档级分布式表示也逐渐成为深度学习研究的重点。
词嵌入包含了丰富的语义信息,在已知词嵌入的情况下,求句子级情感向量表示的最简单的方法就是直接加权词嵌入[15],但是这种方法过于简单,把词语视作独立的符号,没有考虑词语之间的语义关系。依靠词嵌入直接加权构成句子级情感向量表示丢失了真实的情感语义信息。
句子级情感向量表示的生成方式主要包括使用CNN和LSTM的生成方式。论文使用LSTM生成句子级情感向量表示,首先,把句子视为由单词按顺序构成的序列,每个单词用词嵌入表示,对应位置上有一个中间表示;然后,获得每个单词的中间表示,中间表示代表句首到该位置的语义,该单词的中间表示由当前词语的词嵌入和前一个词语的中间表示共同组成;最后,把句尾单词的中间表示视为整个句子的情感向量表示。
2.5 注意力机制
Attention机制于20世纪90年代提出,最早应用在视觉图像领域,由于谷歌mind团队在RNN模型上使用了注意力机制进行图像分类而使注意力机制受到重视[16]。他们的研究是受到人类注意力机制的启发,因为人在观察一幅图像的时候,并不是一次就把图像上的所有像素都看过,而是把注意力集中在某一特定部分,然后移动注意力。而且人会根据上一次注意力集中的图像位置学习到下一次注意力应该观察到的位置。随后,2014年Bahdanau等人[17]第一次提出在自然语言处理领域应用注意力机制,在神经机器翻译(NMT)中把一整句话映射为一个固定长度的表征向量,但是却忽略了一些重要信息,无法把一个很长的句子所包含的所有信息编码成一个向量。因此引入了注意力机制,可以使NMT关注一些重要部分同时忽略掉其他不重要部分。

图5 注意力机制原理图
注意力机制实现的原理是:对于输入的关键部分,分配较多的权重,对于其他部分则分配较少的权重。注意力机制体现了资源的的合理分配,可以排除非关键因素对输出结果的影响。图5为本文注意力机制原理图。
注意力机制通过对双向LSTM的输出进行加权求和,得到文档的向量表示。首先使用双向LSTM编码句子向量sj,编码过程如式(10)和式(11)所示。


各个句子向量的hj权重αij表示如式 (13)所示。

其中eij计算方法如式(14)所示。
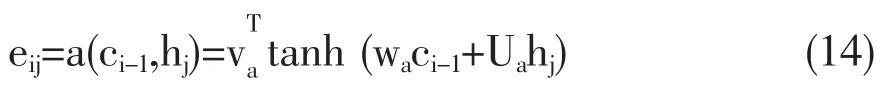
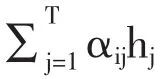

2.6 文档级情感向量表示
目前几种句子级分布式情感向量表示都局限于句子级,不能够扩展至段落级或者文档级。最简单的文档级情感向量表示是对文档中包含的所有的句子级情感向量表示线性加权得到的。Le等人[18]提出的无监督方法中最典型的文档级向量分布式表示是Mikolov等人[13]提出的Skipgram模型的扩展,该向量表示能够将变长的文本表示为定长的特征。
在文档级情感向量表示模型中,每个文档映射到文档向量空间中唯一的向量上且所有文档向量组成一个文档向量矩阵,这些文档向量包含了对应文档的主题。该文档级情感向量表示模型相较于句子级情感向量表示模型的优势在于既可以从无标注的语料中学习文档向量,又不依赖于句法分析树。本文基于注意力机制给不同的句子级情感向量表示分配不同权值,然后加权句子级情感向量表示获得文档级情感向量表示。
3 实验分析
3.1 实验目的和数据源
为验证基于注意力双层LSTM的长文本情感倾向性分析方法的效果,进行模型对比实验,与目前最优模型LSTM-GRNN[10]进行对比分析,与模型Convolutional NN(2014)[3]和Paragraph Vector[18]进行对比分析。
实验数据来自国外长文本评论,包括互联网电影资料库IMDb和酒店评论语料Yelp 2015。将训练集和测试集按4:1的比例切分。

表1 长文本情感倾向性分析实验数据(条)
其中,#s/d代表平均每个文档中的句子数,#w/d代表平均每个文档中的词语数。
3.2 实验环境和条件
实验所用软件资源如表2所示,硬件资源如表3所示。

表2 实验所用软件资源

表3 实验所用硬件资源
3.3 评价方法
论文采用正确率(Accuracy)评价长文本评论情感倾向性分析的结果,正确率计算方法如式(16)所示。
其中,TP是将正类评论文本预测为正类的数目,FN是将正类评论文本预测为负类的数目,FP是将负类评论文本预测为正类的数目,TN是将负类评论文本预测为负类的数目。
3.4 实验过程和参数
LSTM-GRNN是Tang等提出的基于LSTM和双向门循环神经网络的长文本情感倾向性分析方法,该方法首先使用LSTM学习句子向量表示;其次,应用双向门神经网络对句子语义及句子间的语义关系进行编码得到文档向量表示;最后经过softmax层进行情感分类。
Convolutional NN是Kim等利用CNN进行文本情感分类的方法,其利用词嵌入把文本映射成低维空间的特征矩阵,利用卷积层和下采样层提取特征,实现文本情感分类。
Paragraph Vector是Le and Mikolov提出的段落向量模型,其由一个无监督学习算法构成的,将变长的文本学习到固定长度的向量表征。该向量表征可用来预测上下文中的周围的词。
Attention-BiLSTM是论文提出的基于注意力双层LSTM的长文本评论情感倾向性分析方法。为了验证该算法的效果,设置词嵌入词汇表数为400 000,词嵌入维度为100,设置每篇文档最大句子数为18,单句最大词汇数100。模型参数:损失函数为'categorical_crossentropy',优化方法为'rmsprop',批梯度数量为 50,激活函数为'softmax',LSTM层输出尺寸为200。
3.5 实验结果和结论

表4 长文本情感倾向性分析对比实验
实验结果表明本方法Attention-BiLSTM优于LSTM-GRNN。Attention-BiLSTM在Yelp 2015语料上的情感分类正确率为70%,比目前最优方法LSTM-GRNN提升了2.4%,在IMDb语料上的正确率为47.5%,提升了2.2%。Attention-BiLSTM方法分类效果更好,该方法利用LSTM学习句子级情感向量表示,使用双向LSTM对句子的语义及句子间的语义关系进行编码,基于注意力机制根据句子的语义贡献度进行权值分配,进一步提高了情感分类正确率。而目前最优方法LSTM-GRNN不能根据句子的情感语义贡献度对不同句子进行权值分配,情感分类效果比Attention-BiLSTM差。Attention-BiLSTM在长文本评论情感倾向性分析上具有更好的效果。
4 小结
针对长文本评论篇幅长,正负情感特征离散分布且每个句子的情感语义贡献度不同的问题,提出了一种基于注意力双层LSTM的长文本评论情感倾向性分析方法。该方法通过双向LSTM对文档中所有句子的语义及句子间的语义关系进行编码,基于注意力机制对不同句子级情感向量表示分配不同权值,加权获得长文本文档级情感向量表示,经过Softmax层进行情感分类。在Yelp 2015和IMDb上进行实验,结果表明,情感分类正确率相比目前最优方法LSTM-GRNN分别提升了2.4%和2.2%。Attention-BiLSTM情感倾向性分析方法表现更好,可以根据句子的情感语义贡献度分配不同权重,进一步提升了情感分类正确率。将来的研究可在以下三方面进行:(1)文本特征的提取;(2)衡量评论的情感强度;(3)进一步提升深度神经网络的准确率。
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09 18:39:41
有色金属(矿山部分)(2021年4期)2021-08-30 06:10:42
中国新闻周刊(2021年26期)2021-07-27 04:02:12
传媒评论(2017年3期)2017-06-13 09:18:10
信息安全研究(2016年4期)2016-12-01 06:06:54
第二课堂(课外活动版)(2016年2期)2016-10-21 16:58:54
新闻研究导刊(2015年17期)2015-12-25 12:36:42
Asian Pacific Journal of Reproduction(2015年1期)2015-12-22 12:09:35
语言与翻译(2015年4期)2015-07-18 11:07:43
中央民族大学学报(自然科学版)(2014年3期)2014-06-09 08:54:32
