
一个基于混沌和DNA编码的新型图像加密算法
2019-11-26 05:35:58叶瑞松
汕头大学学报(自然科学版) 2019年4期
兰 欢,叶瑞松
(汕头大学数学系,广东 汕头 515063)
0 引 言
混沌系统具有一些特性-轨道的不可预测性、非周期性、对参数和初始值的高度敏感性等与密码系统的特性-明文高度敏感性、密文呈现噪声、密钥的极端敏感性高度契合,基于混沌系统的图像加密受到了广泛关注[1].1989年,Robert Matthews 在标准Logistic 映射的基础上提出一个广义Logistic 映射,利用此映射产生伪随机数序列对文本数据进行加密,这是混沌系统首次应用于加密[2].1998年,Fridrich 将二维连续型混沌映射推广到离散型混沌映射,利用此映射对图像像素点位置进行置乱,提出了一个置乱-扩散结构的图像加密算法,这是第一次真正意义上的基于混沌的图像加密系统[3].自此,基于混沌系统的图像加密研究快速发展.Tao 等利用时空混沌系统产生密钥流,用于图像像素灰度值比特位的选择,实现了图像比特位层面的加密[4].Wang 等利用Logistic映射对颜色图像R、G、B 颜色分量进行加密,该算法在改变各分量灰度值大小及位置的同时有效的降低了分量间的相关性[5].Belazi 等提出了一个基于置换-扩散网络和混沌的加密算法,算法具体包括:基于新混沌系统的扩散、基于强S-boxes 的置换、基于Logistic 映射的扩散、分块置乱[6].超混沌系统具有更为复杂的混沌性质,应用于加密算法中可更有效地增加算法安全性.王震等采用分数阶超混沌Lorenz 系统产生的混沌序列对图像进行加密,模拟实验表明算法具有很好的安全性和应用潜力[7].Wang 等利用复数chen 系统和复数Lorenz 系统对颜色图像进行加密,加密操作包括:R、G、B 分量各自置乱,基于异或操作的扩散,混淆R、G、B 数据[8].林青等提出了一个基于超混沌系统的具有动态可变性的加密算法,利用超混沌系统产生与明文图像相关的动态可选序列,由此构建密钥流[9].
DNA 序列具备一些特性-大规模的并行性、高度的存储密度、独特的分子结构以及分子间识别机制,使其在信息加密领域拥有巨大的发展前景[10].张勋才等提出了一个基于DNA 编码和超混沌系统的图像加密算法,通过SHA-3 算法计算Hash 值将其作为超混沌吕系统的初始值,对图像进行DNA 编码及运算,利用超混沌吕系统生成的混沌序列对图像进行置乱[11].Enayatifar 等提出了一个基于DNA 编码及代数运算的图像加密算法,算法采用了同步置乱-扩散-置乱的加密结构[12].Zhang 等使用混合线性-非线性耦合映射网格的时空混沌系统、DNA 编码和运算技术对图像进行加密[13].
本文将上述混沌系统和DNA 编码这两种加密技术进行了有效地结合,通过采用复杂的加密结构:预处理-比特层面的扩散-置乱-DNA 编码及多轮双向扩散,设计出一个更为安全有效的图像加密算法.在预处理阶段,算法将灰度明文图像进行位平面分解,再将位平面合并,目的是在图像比特层面进行加密操作,增强加密效果.在第一轮扩散阶段,利用改进Logistic 映射生成的混沌序列对预处理后图像进行正向扩散和逆向扩散.在置乱阶段,通过置乱序列改变图像像素点位置.根据位平面分解逆运算将图像恢复成256 个灰度级的灰度图像.在第二轮扩散阶段,利用超混沌chen 系统产生的通过了NIST 测试的随机序列对图像进行DNA 编码及代数运算,再通过多轮双向扩散进一步提高算法的安全性.最后,安全性能分析验证算法的安全性和有效性.
论文的主要创新点如下:
(1)对标准Logistic 映射进行改进,提出一个混沌性质更好的改进Logistic 映射.
(2)同时应用改进Logistic 映射和超混沌chen 系统,增大了算法的密钥空间、增加了算法的复杂度.
(3)通过随机性测试包NIST 来提高加密过程中混沌序列的随机性,有效地提高加密算法的安全性.
(4)DNA 序列在数据加密领域拥有巨大的发展潜力,论文利用混沌系统产生规则数值,利用DNA 序列进行编码及运算,使得算法同时结合了混沌系统和DNA 序列在加密领域的优势.
论文包括如下5 个章节:
1 引言.概括了基于混沌系统和DNA 序列的图像加密研究现状,阐述了算法方案以及创新点,给出了组织结构.
2 基本理论概括.介绍了位平面分解原理,提出了改进Logistic 映射,同时分析了改进Logistic 映射及超混沌chen 系统的混沌特性,介绍了DNA 编码和代数运算规则等.
3 图像加密算法.提出了一个灰度图像加密算法,给出了算法的流程图以及具体加密过程.
4 实验结果和安全性能分析.对算法进行了仿真实验和安全性能分析,验证了算法的安全性.
5 总结.对论文进行总结.
1 基本理论概述
1.1 位平面分解
对于256 个灰度级的灰度图像,像素点灰度值a 的取值范围是从0 到255 的整数,可表示成8 位的二进制序列:
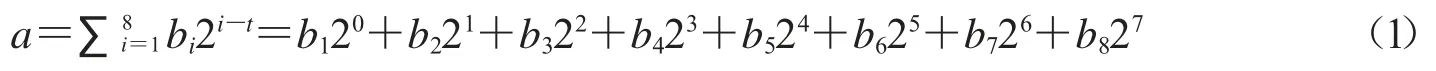
其中bi∈{0,1}(i=1,2,…,8),因此,灰度图像可被分解成8 个位平面,其中第i 个位平面由所有灰度值的第i 个比特组成.图1是灰度图像Lena,图2是Lena 的8 个位平面.可以看到,灰度图像的重要信息主要隐藏在高位的位平面中.

图1 Lena 图

图2 Lena 位平面图
本文预处理阶段将明文图像位平面按照图3合并得到一个新的图像,并在此位平面大图上实施加密操作,以达到对目标图像快速加密保护的目的.

图3 Lena 位平面合并图
1.2 混沌系统
1.2.1 Logistic 映射和改进Logistic 映射
Logistic 映射是著名的一维非线性混沌映射,定义模型如下:

其中 u 是系统控制参数,u∈(0,4],初始值 x0∈[0,1].
对Logistic 映射进行改进,改进Logistic 映射定义模型如下:
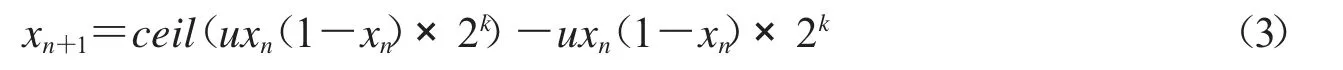
这里u>0,初始值x0∈[0,1],k 是系统参数,本文令k=13,ceil(x)是返回不小于x 的最小整数.进行混沌特性分析时不妨令u∈(0,10].
分岔图是用于识别混沌行为的特征之一,凡是产生混沌行为的系统可以观察到分叉序列.图4是Logistic 映射和改进Logistic 映射的分岔图,可以看到,Logistic 映射只在参数u∈[3.57,4]时具有很好的分叉现象,改进Logistic 映射在u∈(0,10]上均具有极好的遍历性,即改进Logistic 映射比Logistic 映射具有更大的参数空间.
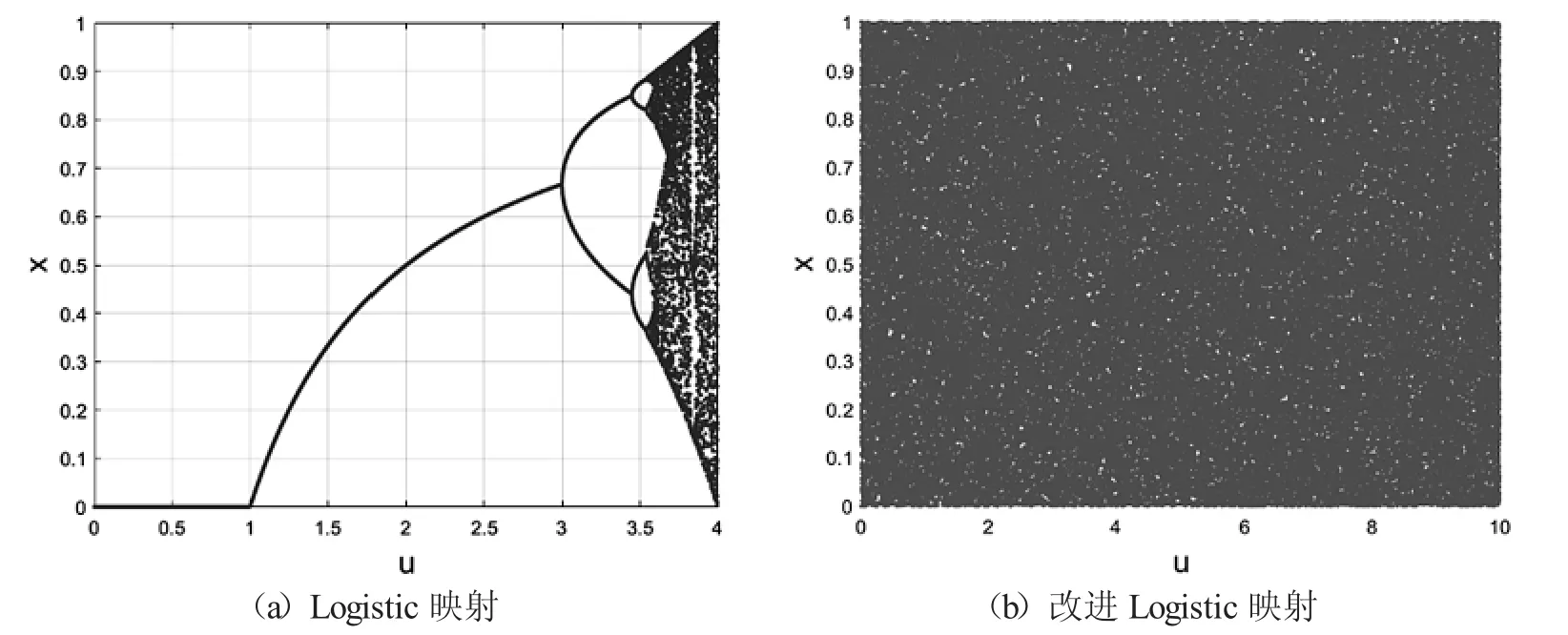
图4 分岔图
Lyapunov 指数是表示相空间相邻轨迹的平均指数发散率的数值特征,正的Lyapunov指数是混沌系统的典型特征,数值越大,混沌特性越好.一维动力系统xn+1=f(xn)的Lyapunov 指数计算公式如下:

n 维动力系统的Lyapunov 指数的计算公式如下:

图5是Logistic 映射和改进Logistic 映射的Lyapunov 指数图.图5(a)可以看到,u∈[3.57,4]时Logistic 映射的Lyapunov 指数出现正值,图5(b)可以看到,改进Logistic映射的Lyapunov 指数在u∈(0,10]时都大于0,即改进Logistic 映射具有更好的混沌行为及更稳定的混沌特性.
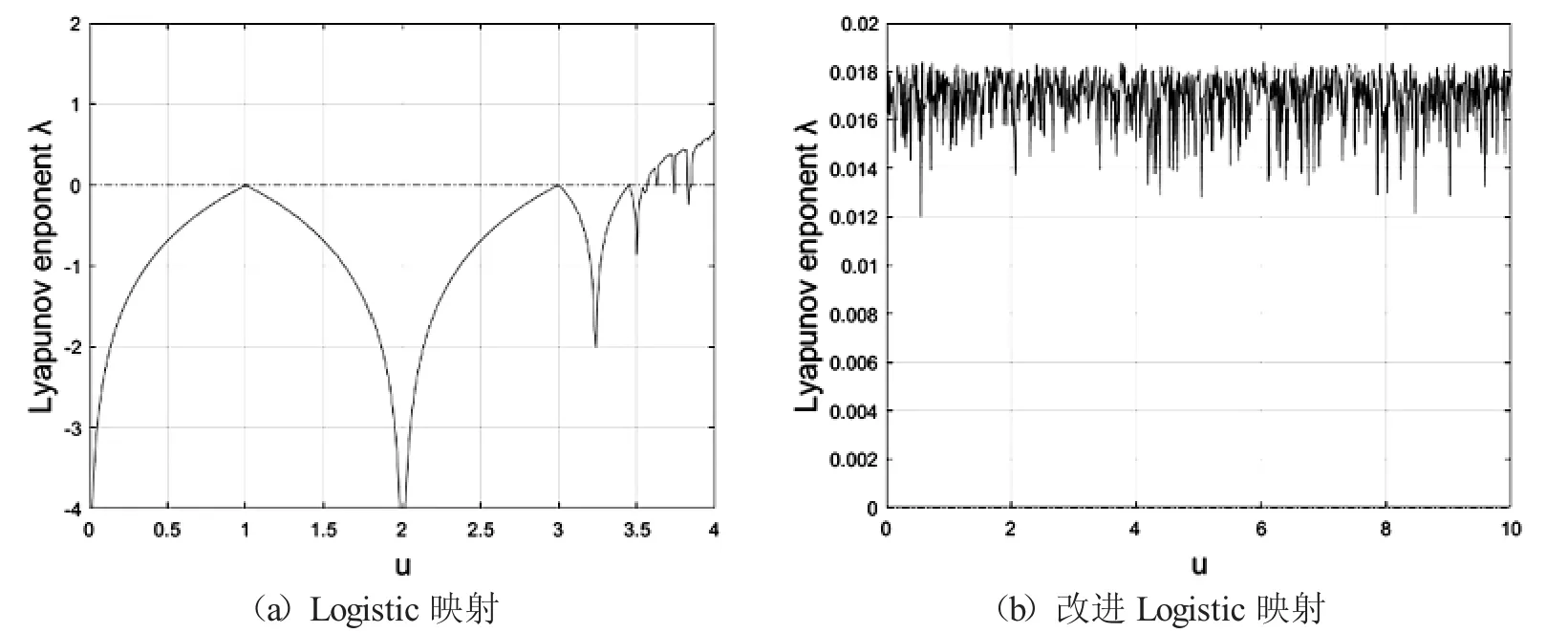
图5 Lyapunov 指数图
信息熵可以反映序列的不确定性,一般认为,信息熵越大,不确定性越强,理想值等于8.混沌序列信息熵计算公式如下:
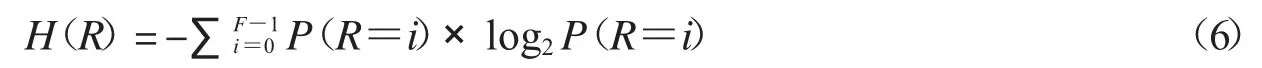
其中F 是灰度等级数,即F=256,将1 平均分成256 个区间,P(R=i)是序列中数值属于第i 个区间的概率.
图6是Logistic 映射及改进Logistic 映射的信息熵,其中蓝色表示Logistic 映射,红色表示改进Logistic 映射.可以看到,Logistic 映射的信息熵只有在u∈[3.57,4]时较为靠近理想值8,而改进Logistic 映射的信息熵在u∈(0,10]上都非常接近理想值8.相比标准Logistic 映射,改进Logistic 映射产生序列的不确定性更好,随机性更强.
自相关系数被用来检测时间序列x=(x1,x2,…,xN)前后数据之间的相关性,自相关系数越接近0,时间序列的相关性越弱,随机性越强,计算公式如下:
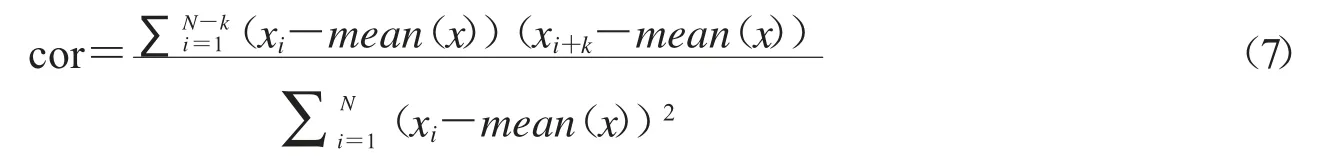
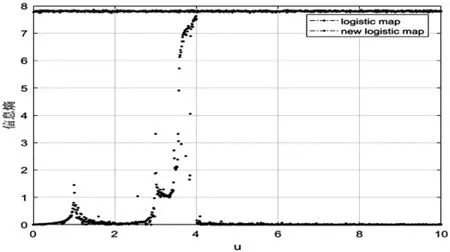
图6 信息熵
其中mean(x)是序列x 的算术平均值.图7、图8分别是不同参数u 下Logistic 映射、改进Logistic 映射生成时间序列的自相关检测图.可以看到,整体而言,改进Logistic 映射时间序列的自相关系数比Logistic 映射时间序列的自相关系数更接近0,即改进Logistic映射生成的时间序列间的自相关性更弱.
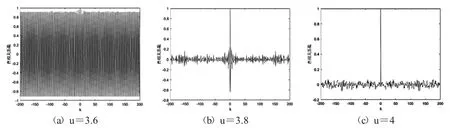
图7 Logistic 映射时间序列自相关检测图
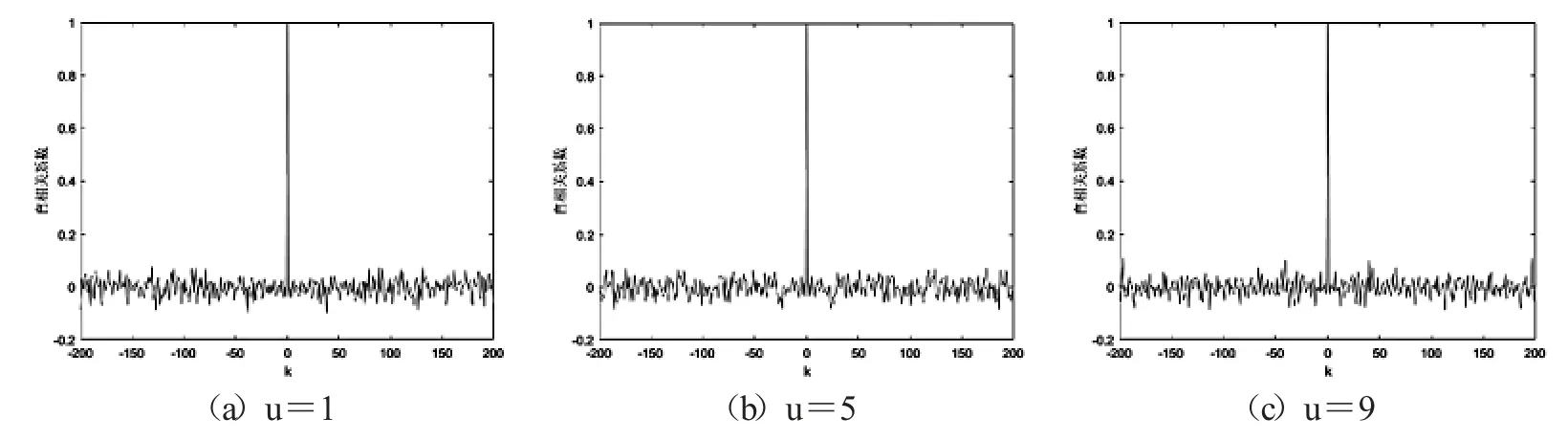
图8 改进Logistic 映射时间序列自相关检测图
根据图4-8,论文提出的改进Logistic 映射比标准Logistic 映射具有更好的混沌行为、更大的参数空间、更大的不确定性、更弱的自相关性、更好的随机性等特性.
1.2.2 超混沌chen 系统
超混沌chen 系统是一个四维连续型混沌系统,其方程为:

其中 x,y,z,w 是系统状态变量,a,b,c,d,r 是系统参数,在 a=35,b=3,c=12,d=7,r∈[0.085,0.798]时,系统表现出超混沌行为,本论文取参数a=35,b=3,c=12,d=7,r=0.6,设定初始值x0=4.45,y0=4.5,z0=5.6,w0=6.7.
图9是取步长为0.002 利用四阶龙格-库塔方法得出的超混沌chen 系统的吸引子相图,可以看出,超混沌chen 系统具有奇异吸引子,处于混沌状态.
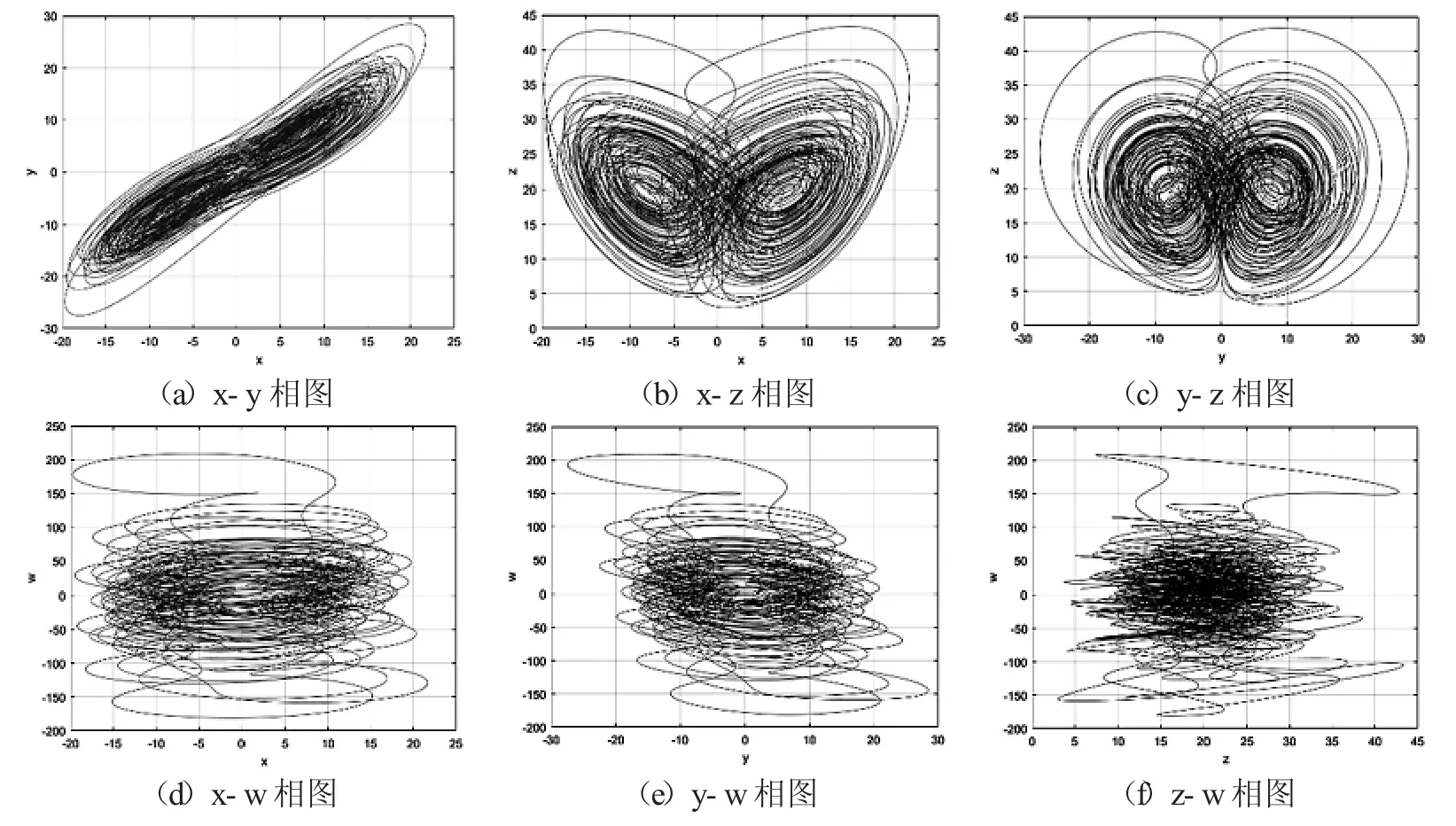
图9 超混沌chen 系统相图
图10是超混沌chen 系统生成的x,y,z,w 时间序列及其对初值的敏感性分析,其中红色曲线对应原初始值的时间序列,蓝色曲线是初始值改变1/10000 后的时间序列.可以看到,初始值的细微变化引起了红、蓝曲线的巨大差距,即超混沌chen 系统输出值的巨大变化,超混沌chen 系统对初始值具有高度敏感性.
图11是超混沌chen 系统的时间-Lyapunov 指数图,系统若只存在一个大于零的Lyapunov 指数,则系统是混沌系统,若存在两个及以上大于零的Lyapunov 指数,则是超混沌系统.超混沌chen 系统正的Lyapunov 指数个数大于1,具有很好的超混沌性质.
1.3 随机数发生器的设计和NIST测试
NIST SP800-22(National Institute of Standards and Technology Special Publication 800-22)是利用概率统计方法对比特序列的随机性进行检测的统计分析测试包,共包括15 项测试.NIST 测试结果由p 值测定,假若给定显著性水平α=0.01,所有p≥α 时,可认为在该显著性水平下该比特序列是随机的.
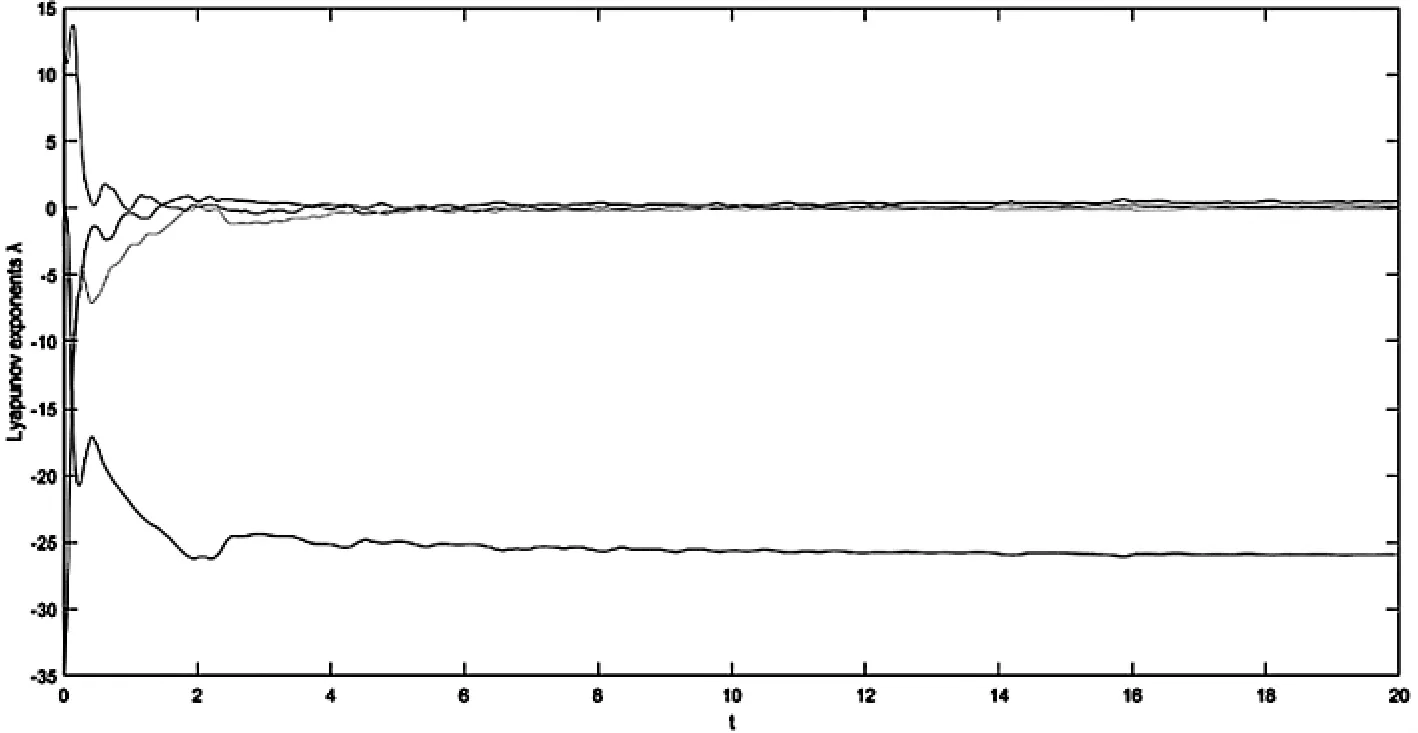
图11 超混沌chen 系统Lyapunov 指数图
1.3.1 基于改进Logistic 映射的随机数发生器
本文算法中使用了改进Logistic 映射和超混沌chen 系统,基于这两种混沌系统设计两个随机数发生器.
基于改进Logistic 映射的随机数发生器设计方案如下:

算法1.基于改进Logistic 映射的随机数发生器伪算法输入:N0、u、x0输出:X 1.输入初始值:N0、u、x0。N0 是序列舍弃项数,u 是改进Logistic 映射初始参数,x0 是初始值.2.迭代,生成时间序列g。取k=13,改进Logistic 映射(式(3))迭代生成时间序列,舍弃其前N0 项得到序列g.3.生成比特序列X。X=mod(floor(g×1013),2)(9)这里floor()是向下取整函数,mod()是取模函数.4.对X 的前1 百万项进行NIST 测试。若测试通过,则认为在初始值u、x0、k 下比特序列X 的随机性是极高的.若测试不通过,则改变参数k:k=k-1,重复步骤2-4,直到测试通过,若到k=0 仍未通过,则k=13 且改变x0:x0=x0+0.001,重复步骤2-4,直到测试通过,则认为在该u、x0、k 下比特序列X 的随机性是极高的.5.输出比特序列X.
通过模拟实验,在N0=200、u=8、x0=0.28 时,算法1 可得到随机性极高的比特序列X,即X 的前1 百万项通过了所有的NIST 测试,其测试结果如表格1、2、3 所示,其中取显著性水平α=0.01.
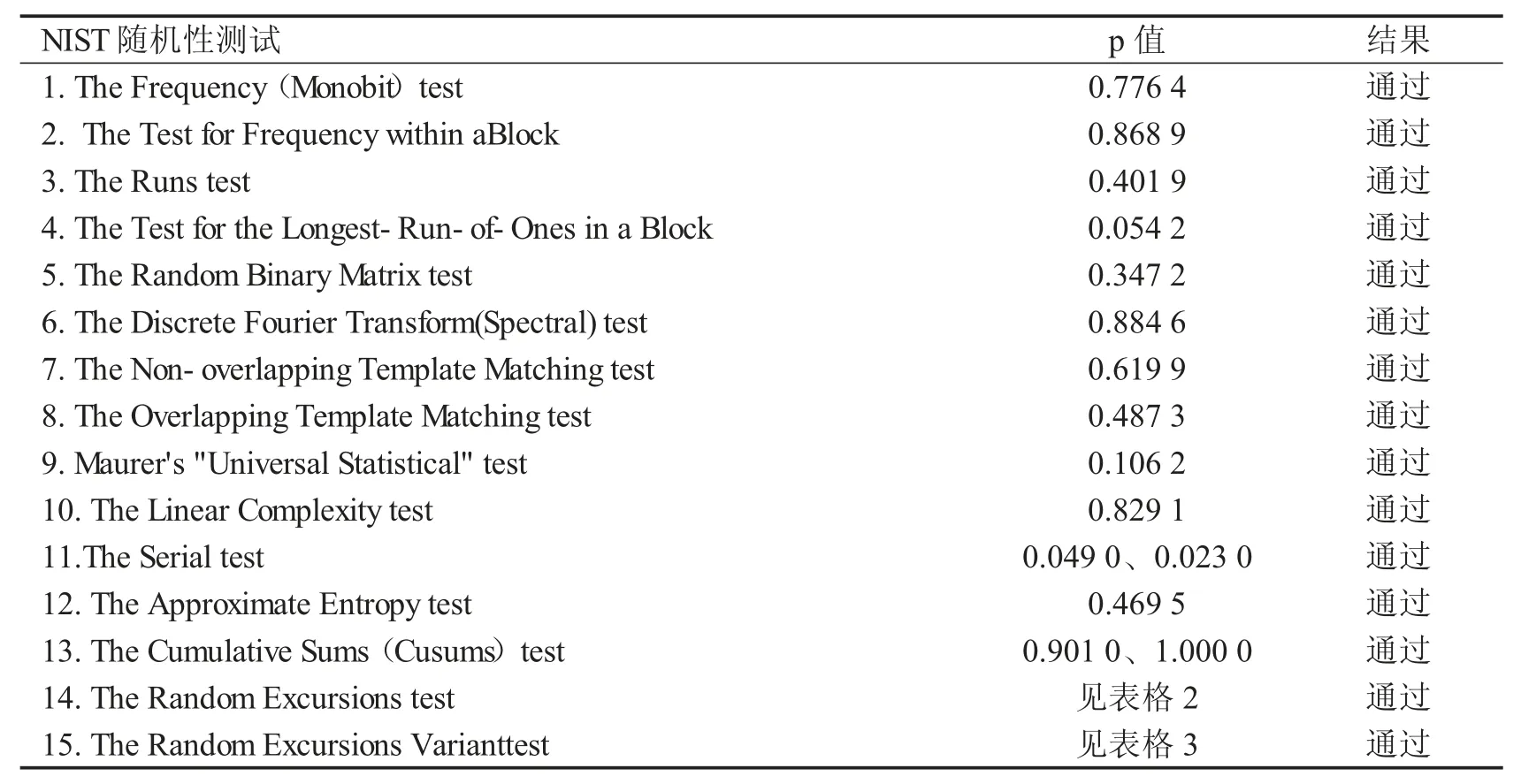
表1 比特序列X 的NIST 测试结果

表2 The Random Excursions test 结果

表3 The Random Excursions Varianttest 结果
1.3.2 基于超混沌chen 系统的随机数发生器
对于基于超混沌chen 系统的随机数发生器设计方案如下:
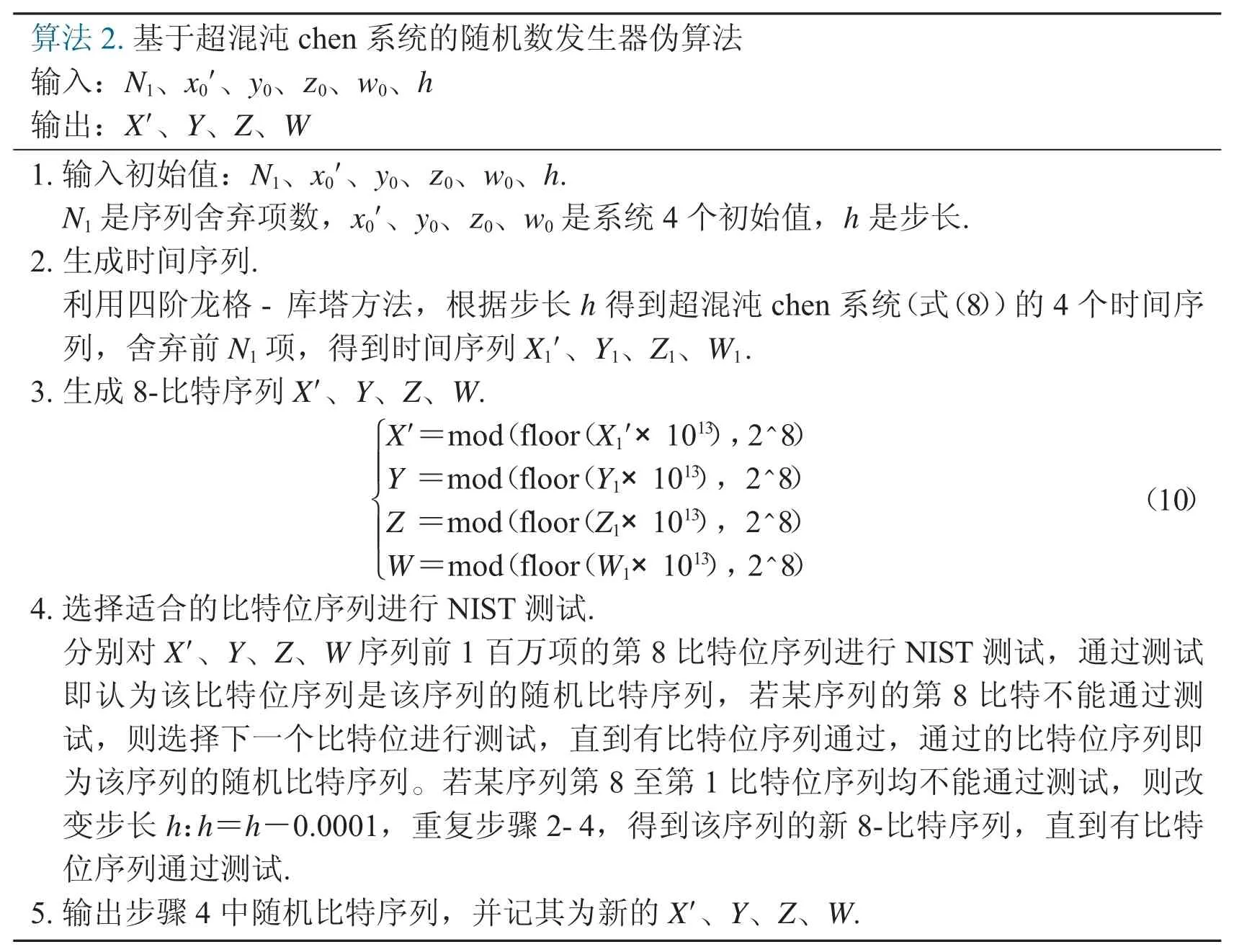
算法2.基于超混沌chen 系统的随机数发生器伪算法输入:N1、x0′、y0、z0、w0、h输出:X′、Y、Z、W 1.输入初始值:N1、x0′、y0、z0、w0、h.N1 是序列舍弃项数,x0′、y0、z0、w0 是系统 4 个初始值,h 是步长.2.生成时间序列.利用四阶龙格-库塔方法,根据步长h 得到超混沌chen 系统(式(8))的4 个时间序列,舍弃前N1 项,得到时间序列X1′、Y1、Z1、W1.3.生成8-比特序列X′、Y、Z′=mod(floor(X1′×1013),2^8)Y =mod(floor(Y1×1013),2^8)Z =mod(floor(Z1×1013),2^8)W=mod(floor(W1×1013),2^8(10))4.选择适合的比特位序列进行NIST 测试.分别对X′、Y、Z、W 序列前1 百万项的第8 比特位序列进行NIST 测试,通过测试即认为该比特位序列是该序列的随机比特序列,若某序列的第8 比特不能通过测试,则选择下一个比特位进行测试,直到有比特位序列通过,通过的比特位序列即为该序列的随机比特序列。若某序列第8 至第1 比特位序列均不能通过测试,则改变步长h:h=h-0.0001,重复步骤2-4,得到该序列的新8-比特序列,直到有比特位序列通过测试.5.输出步骤4 中随机比特序列,并记其为新的X′、Y、Z、W.
通过模拟实验,在初始值x0′=4.45,y0=4.5,z0=5.6,w0=6.7,步长h=0.002 时,通过算法2 的步骤1-3,得到原序列X′、Y、Z、W,通过算法2 的步骤4,原序列X′、Y、Z、W 分别第7、6、5、7 比特位序列的随机性极高,记为新的X′、Y、Z、W,各比特序列NIST 测试结果如表格4、5、6 所示,其中取显著性水平α=0.01.
1.4 DNA编码及异或运算
DNA 是一种由四种脱氧核苷酸-A(腺嘌呤)、T(胸腺嘧啶)、G(鸟嘌呤)、C(胞嘧啶)组成的分子结构,且遵循碱基互补配对原则,即A 和T 通过两个氢键配对,G 和C 通过三个氢键配对.在二进制系统中0 和1 配对,即0↔1,则有即00↔11,01↔10,这种高度的相似度使得碱基的排队组合可以用来进行信息的存储和计算.灰度图像像素点灰度值可用8 位二进制数来表示,采用DNA 编码可表示为4 个碱基序列.
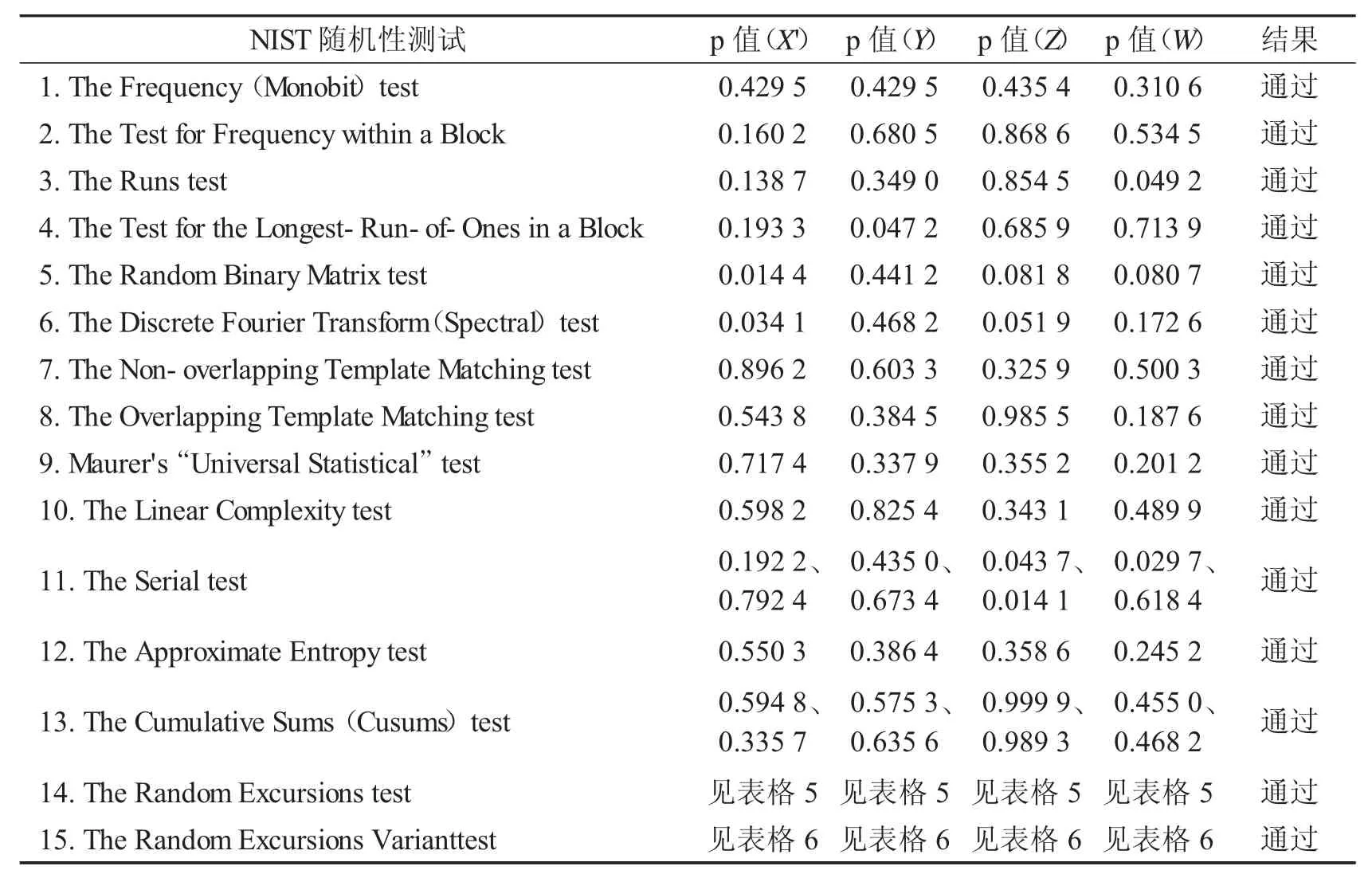
表4 比特序列的NIST 测试结果
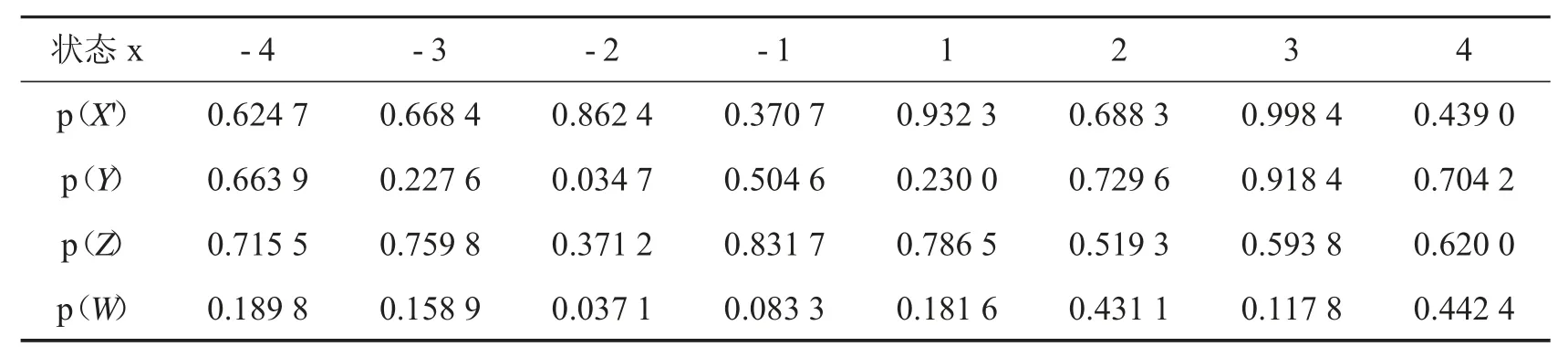
表5 The Random Excursions test 结果
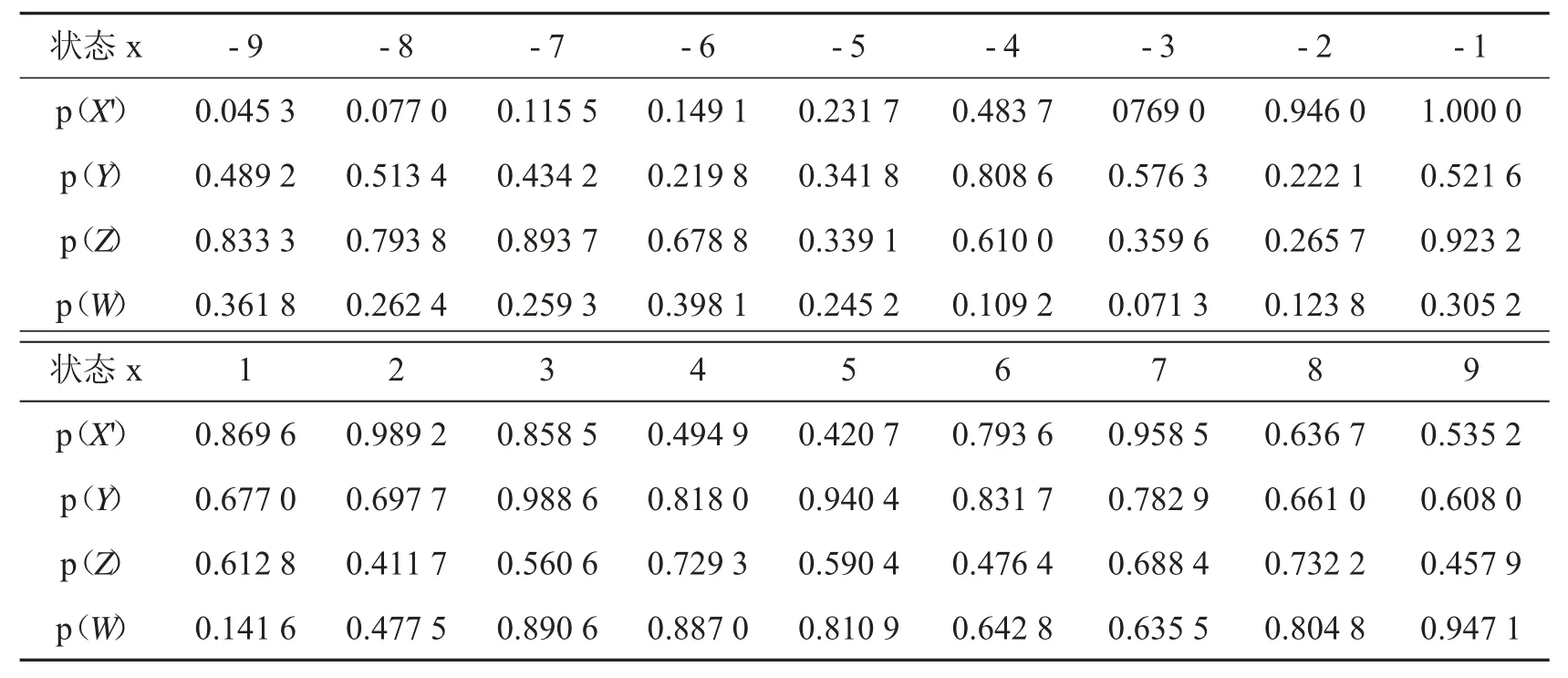
表6 The Random Excursions Varianttest 结果
表7是DNA 序列的8 种编码规则表,例如按照规则1 进行编码,则有对应关系:A↔00、C↔01、G↔10、T↔11.举一个例子,假如像素点灰度值为210,则其二进制序列为11010010,按照上述对规则1-8 进行DNA 编码,则可分别表示为TCAG、TGAC、GACT、GTCA、CAGT、CTGA、ACTG、AGTC.
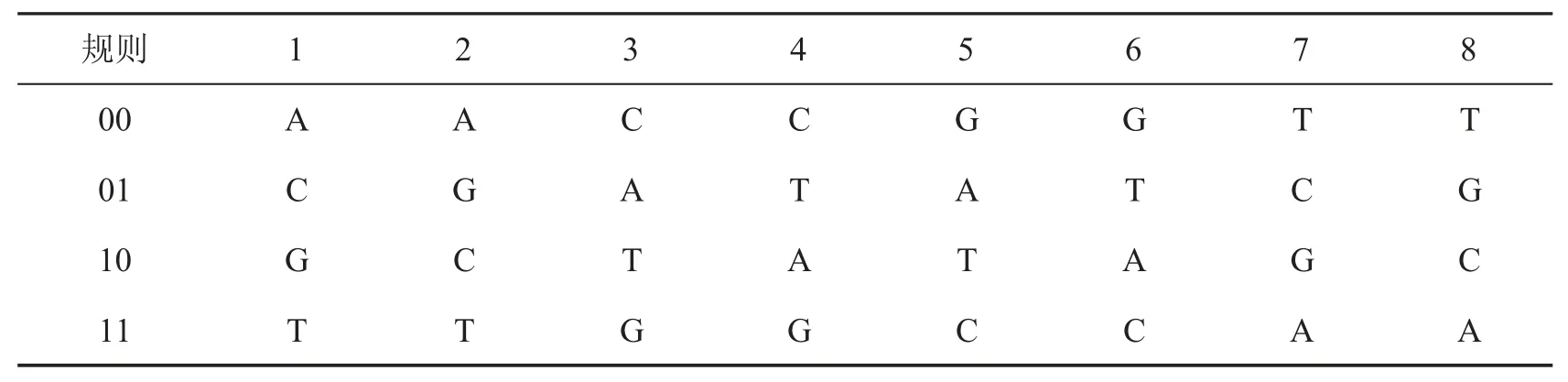
表7 DNA 序列编码表
表8是8 种规则下的DNA 序列异或运算表.举一个例子,灰度值分别为208 和25的两个像素点,其二进制分别为11010000、00011001,若按照规则1 对其进行DNA编码,则为TCAA、ACGC,再按照规则3 进行异或运算,则可表示为TCAA⊕ACGC→GCTA.

表8 DNA 序列异或运算
2 图像加密算法
本文设计了基于改进Logistic 映射和超混沌chen 系统的随机数发生器,算法使用了位平面分解合并、正逆向扩散、DNA 编码及其代数运算等技术,采用复杂的加密结构,通过对图像像素点灰度值大小和位置的改变,实现对灰度图像安全、有效加密.
算法流程图如图12所示.
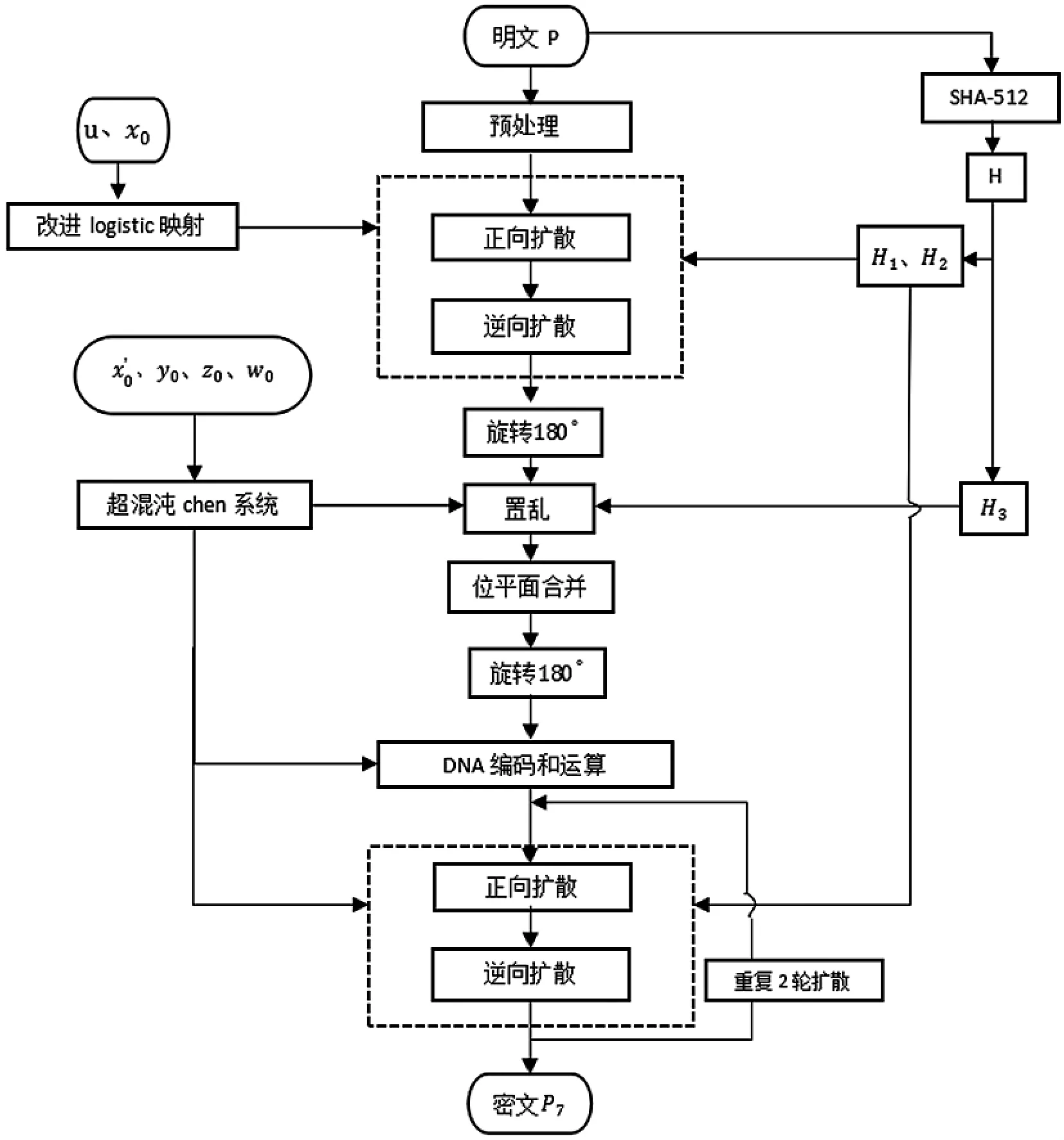
图12 加密算法流程图
具体加密步骤如下:
Step 1.初始数值输入.
读入大小为M×N 的灰度图像P,记P(i,j)为图像P 第i 行、第j 列的像素点的灰度值.输入初始密钥:改进Logistic 映射的参数u,初始值x0;超混沌chen 系统的初始值、y0、z0、w0.将明文图像P 作为SHA-512 函数的输入值,得到128 位的十六进制序列,并转化为十进制序列,记为H.
Step 2.预处理.
(1)将明文图像P 分解得到8 个位平面.
(2)记 H1为序列 H 的奇数项之和,即 H1=∑i∈[1,3,5,…,127]H(i),
记 H2为 H 的偶数项之和,即 H2=∑i∈[2,4,6,…,128]H(i),
设定随机种子:seed=sum(H1⊕H2),随机生成[0,1]的8 个数值,进行升序处理得到一个长度为8 的升序序列E1.
按照序列E1对8 个位平面进行位置置乱,实现重新排位.
(3)根据1.1 节,将位平面合并得到大图P1,图像P1的大小为2M×4N.
Step 3.正向扩散+逆向扩散.
(1)得到扩散序列X.根据1.3.1 节,给定N0=200,通过算法1 得到一个随机性极高的比特序列X,即X 的前1 百万项通过了所有的NIST 测试.取X 的前8MN 项,记为新的扩散序列X.
(2)P1将转化为一维序列.
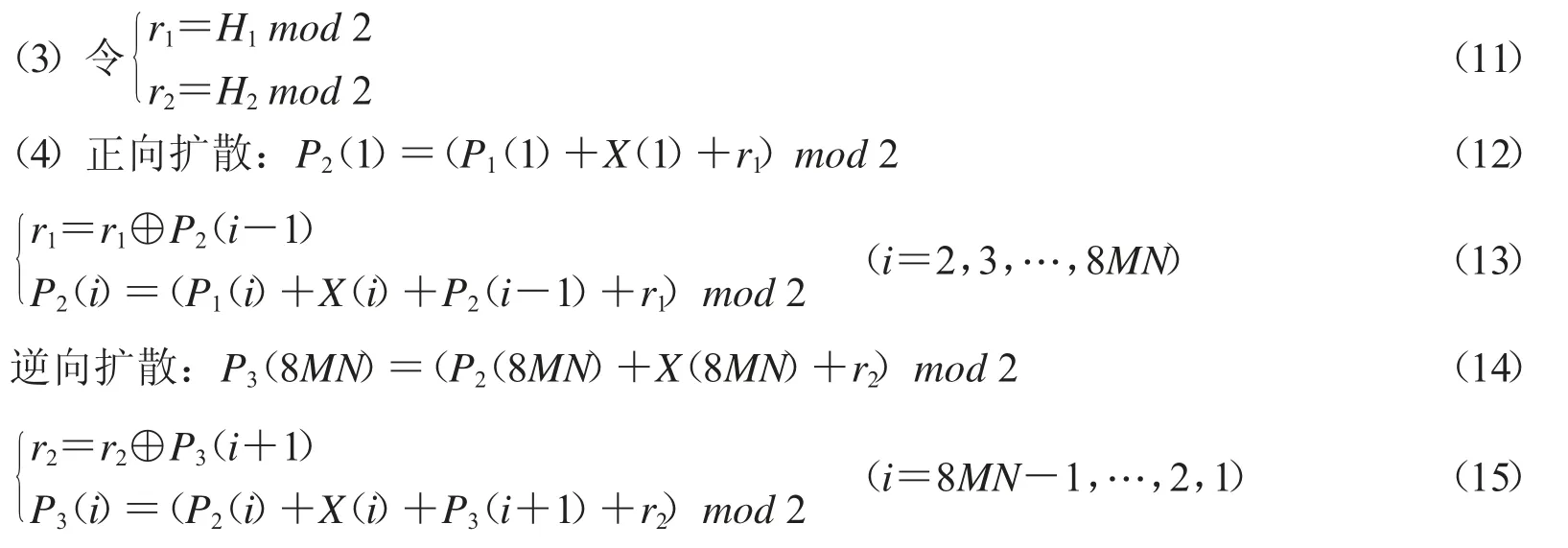
这里mod 是取模运算,⊕是异或运算.
(5)将P3转化为2M×4N 的矩阵.
Step 4.置乱.
(1)得到置乱序列E2.根据1.3.2 节,设定h=0.002,通过算法2 的步骤1-2 得到时间序列、Y1、Z1、W1,分别取其前2MN 项,按顺序合并,对其进行升序处理得到长度为8MN的升序序列E2,E2即为所求置乱序列.
(2)将图像矩阵P3旋转180°,记为新的P3.
(3)根据置乱序列E2进行置乱:
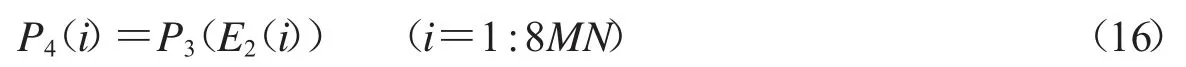
(4)将序列P4转化为2M×4N 的矩阵,按照位平面合并及位平面分解的逆操作得到大小为M×N 的新的矩阵.
(5)将新矩阵旋转180°,记为新的P4.
Step 5.DNA 编码和运算.
(1)根据1.3.2 节,设定h=0.002,通过算法2 得到4 个随机性极高的比特序列X′、Y、Z、W.
(2)分别取序列X′、Y、Z、W 的前8MN 项,不重复地依次将连续8 个比特数进行比特合并,得到4 个长度为MN 的随机序列,记为M1、M2、M3、M4.

(3)对于 P4中的第(i=1,2,…,MN)个像素点,令
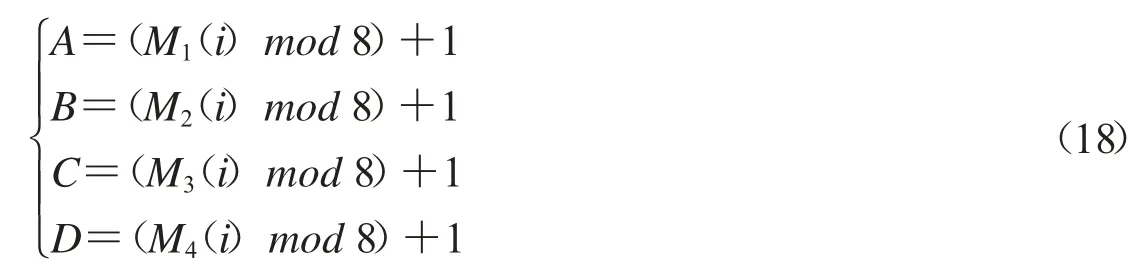
则A、B、C、D∈{1,2,…,8},根据1.4 节DNA 编码规则及其运算规则,按照规则A,将P4(i)进行DNA 编码,按照规则B,将S(i)进行编码,按照规则C,将上述两个DNA序列进行异或运算,按照规则D,将上述运算结果进行DNA 解码,得到P5(i).
Step 6.正向扩散+逆向扩散.
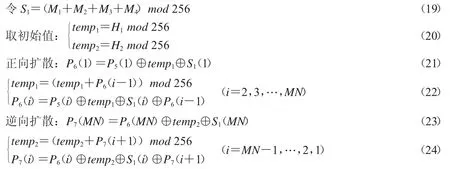
Step 7.将P7赋给P5重复Step 8、Step 9 两次,将得到的新序列转化为M×N的矩阵,记为新的P7.
Step 8.输出密文P7,输出序列H,将其作为解密算法中的密钥之一.
解密算法是上述加密算法的逆过程,这里不再详述.
3 仿真实验和安全性能分析
3.1 仿真实验
采用MATLAB R2016a 软件对算法进行仿真实验,实验设备主要硬件环境为:处理器:Intel Core i7-7500U CPU @2.70 GHz 2.90 GHz;安装内存:8GB;运行系统:Windows 10 家庭中文版.实验图像均取自文献[14]的图像数据库,包括大小为256×256的灰度图像Lena、512×512 的灰度图像Bridge、1024×1024 的灰度图像Male.实验随机选取密钥:u=8,x0=0.28,=4.45,y0=4.5,z0=5.6,w0=6.7,论文1.3 节验证了该密钥下随机序列的生成.
实验结果如图13所示,Lena 图像(a)经算法加密后得到密文图像(b),可以看到,密文图像呈现雪花形状,无明显纹理出现,不能反映出Lena 任何信息,起到了有效的隐藏和保护作用.密文图像(b)经解密得到解密图像(c),经计算,(c)与(a)中不同像素点个数为0,即算法可在正确密钥情况下经由解密算法进行无偏差地解密.相同方法分析灰度图像Bridge 和Male,不再详述.根据上述实验结果可知,本文加密算法可有效地隐藏灰度图像的重要信息,同时可实现无偏差复原.

图13 仿真实验结果
3.2 安全性能分析
3.2.1 密钥空间分析
算法密钥空间K={u、x0、、y0、z0、w0},其中u 的取值范围为(0,+∞),x0、、y0、z0、w0的取值范围为(0,1),如果采用精确到小数点后14 位的双精度表示,则在不考虑密钥u 的情况下,总的密钥空间已达1070,即密钥长度已达log2(1070)≈233bit,一般认为,算法的密钥长度达到128bit 则是安全的,因此即使不考虑无穷范围的密钥u,算法的密钥空间已达到安全标准,若考虑密钥u,则算法的密钥空间无穷大,足以极为有效地抵抗穷举攻击.
3.2.2 直方图分析及χ2 检验
直方图可表现出图像像素点灰度值分布的统计特性,性能良好的加密算法可使得其密文图像灰度值具有一致分布的趋势.灰度图像Lena、Bridge、Male 的明文、密文直方图结果如图14所示.可以看到,明文的直方图都分布不均匀,起伏波动大,密文的直方图则分布均匀,具有一致分布的趋势,由此可知,本文加密算法可有效地保护灰度图像抵抗统计分析攻击.
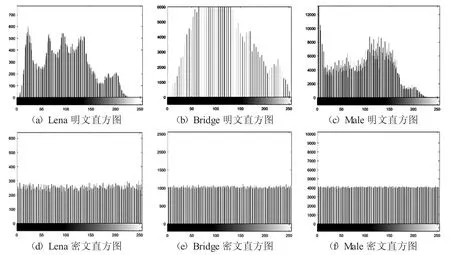
图14 直方图
χ2检验用于进一步分析明文和密文直方图的统计特性.记每个灰度值的像素点频数为fi,其理论频数为gi,(i=0,1,…,255),假设直方图服从均匀分布,则称为χ2统计量.给定显著性水平α,计算图像直方图的χ2统计量,若其中n 是灰度等级,即n=256,则可认为在该显著性水平图像像素点是近似均匀分布的.这里取显著性水平α=0.05,则
对直方图进行χ2检验,结果如表9所示,可以看到,明文图像χ2统计量都远远大于说明在显著性水平0.05 下,三个明文图像的像素点灰度值分布均与均匀分布有显著差异,而密文图像的χ2统计量都明显小于可认为这三个密文图像像素点灰度值分布都是近似均匀分布的.

表9 χ2 检验结果
3.2.3 相关性分析
自然图像相邻像素之间具有很强的相关性,使得图像易受统计分析攻击,两个像素点序列的相关性系数计算公式如下:
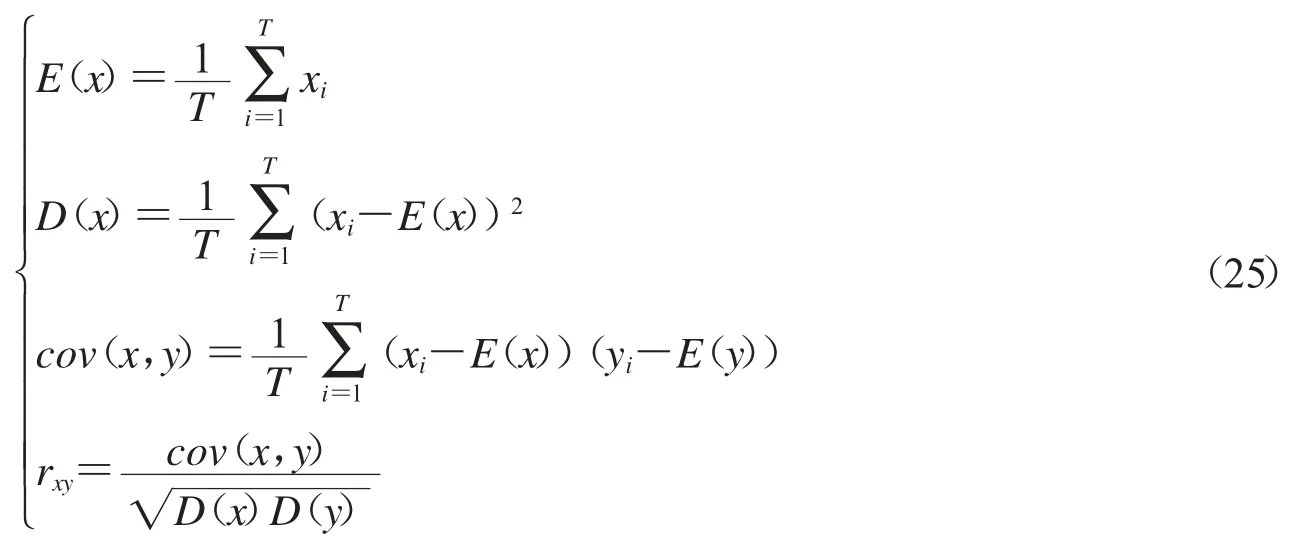
其中T 是考察的像素点对数,x,y 是相邻像素点灰度值序列,根据x,y 的不同取法,可分别计算出水平方向、垂直方向、对角方向相关性系数.
分别从不同方向随机选取T 个像素点对,这里令T=5 000,计算各明文、密文的相关性系数,某次实验结果如表10所示,三个明文图像的各个方向相关性系数都很大且接近于1,即明文图像各个方向的相邻像素相关性极强,同时,三个密文图像的相关性系数都极小且非常接近0,即密文图像各个方向的相邻像素相关性极弱.图15是Lena明文、密文像素点分布图,可以看到,明文像素点分布呈线性分布的趋势,而密文像素点分布呈无序状态,无规律可寻.本文算法可有效降低明文图像相邻像素点间相关性,可有效地抵抗统计分析攻击.
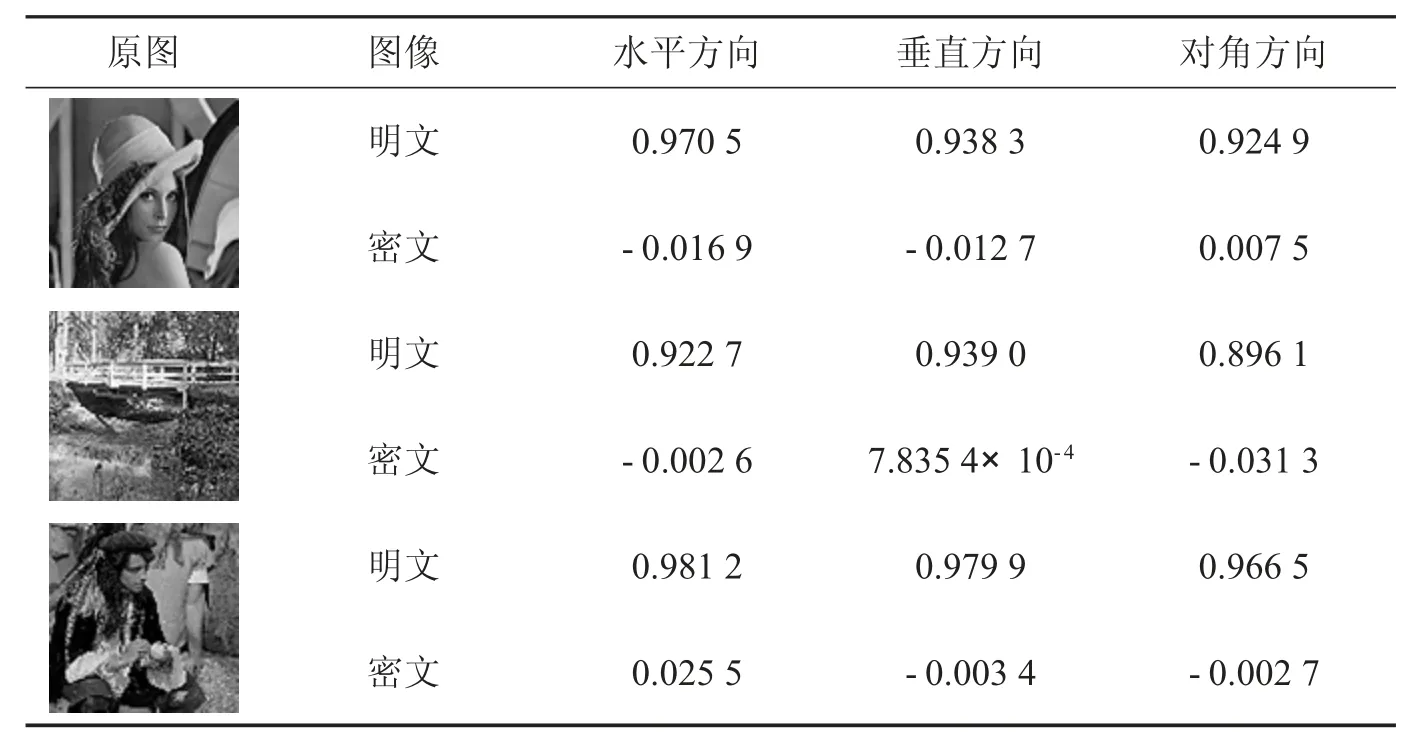
表10 相邻像素间相关性系数
明文和密文之间的相关性也能反映出加密算法的有效性,明文A 和密文B 之间的相关系数计算公式如下:
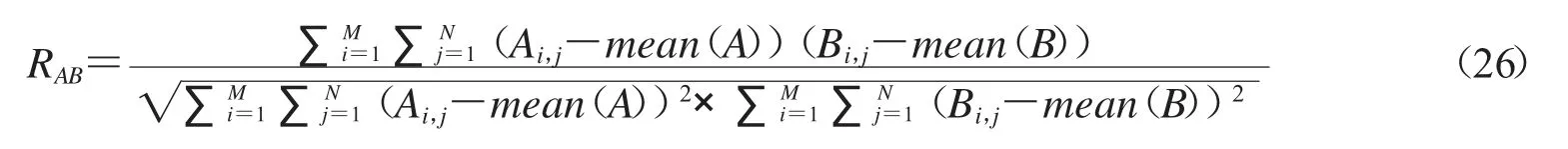
这里M、N 是图像矩阵的大小,mean(x)代表序列x 的平均值.
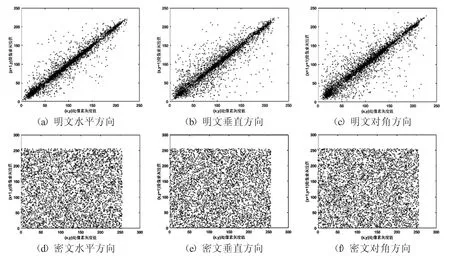
图15 Lena 像素点分布
分别计算各灰度图像明文和密文之间的相关性系数,结果如表11所示.可以看到,三个图像的明文和密文之间的相关性系数都非常接近0,即明文和密文之间的相关性极弱,进一步验证了加密算法的有效性.

表11 明文和密文的相关性系数
3.2.4 信息熵分析
分别计算各灰度图像明文、密文的信息熵,结果如表12所示.可以看到,明文图像信息熵都较小,与理想值8 相差较大,即明文图像信息不确定性弱,而密文图像信息熵均明显大于对应明文图像的信息熵,且非常接近理想值8,尤其是大小为是1024×1024的Male 密文图像,其信息熵可达7.999 8,说明了密文图像信息的不确定性很强.本文算法可有效的降低明文图像的信息熵,极大地增强图像信息的不确定性.文献[15]是一个基于DNA 编码的图像加密算法,与本文算法存在一定的可比较性,比较本算法和文献[15]密文信息熵,整体而言,本算法密文信息熵略大于文献[15]密文信息熵,可认为本文的加密效果约优于文献[15].

表12 信息熵
3.2.5 密钥敏感性分析
图像密码系统的敏感性分析包括密钥敏感性、明文敏感性、密文敏感性分析,旨在分析目标对象发生细微变化引起的输出图像的差别,一些指标可作为这种差别的度量方法,如NPCR(像素改变率)、UACI(平均改变强度),其计算公式如下:
其中C1,C2是进行比较的两个图像.假如两个图像均是随机图像,则两个图像任一像素点灰度值不相等的概率为即NPCR 的理论期望值是99.6094%,同理UACI 的理论期望值是33.4635%,假如一个图像给定,另一个是随机图像,则这两个图像任一像素点灰度值不相等的概率仍为UACI 的理论期望值与给定图像像素点有关,经计算若给定灰度图像Lena,另一个是随机图像,则UACI 的理论期望值为30.5588%.
密钥敏感性分析旨在分析当系统密钥发生细微变化时,同一明文图像加密得到的两个密文图像的差别或者同一密文图像解密得到的两个解密图像的差别.若两个图像差别很大,则认为该加密系统密钥敏感性强,反之,密钥敏感性弱.以图像Lena 为例,对算法的加密过程和解密过程进行密钥敏感性分析.
(1)加密过程中的密钥敏感性分析

表13 加密过程中密钥敏感性分析 (%)
(2)解密过程中的密钥敏感性分析
同上方法改变密钥值,在该密钥下解密,得到新的解密图像,计算该解密图像与原解密图像的NPCR,UACI,结果如表14所示.解密图像间的NPCR,UACI 值均与理论值非常接近,可认为密钥改变前后解密图像之间的差别极大,即算法的解密过程中也具有很强的密钥敏感性.

表14 解密过程中密钥敏感性分析 (%)
3.2.6 明文敏感性分析
明文敏感性分析旨在分析相同密钥条件下明文图像的细微改变引起的密文图像的改变程度,改变很大时,加密系统具有很强的明文敏感性,可有效抵抗差分攻击.以图像Lena 为例,随机改变Lena 一个像素点灰度值的一个比特值,加密得到新的加密图像,计算该密文与原密文的NPCR,UACI,500 次的随机实验结果如图16、表15所示.可以看到,NPCR,UACI 值都围绕其理论值上下波动,波动幅度较小,平均值非常接近其理论值.本文加密系统具有很强的明文敏感性,可有效的抵抗差分攻击,可有效的抵抗选择明文攻击和选择密文攻击.
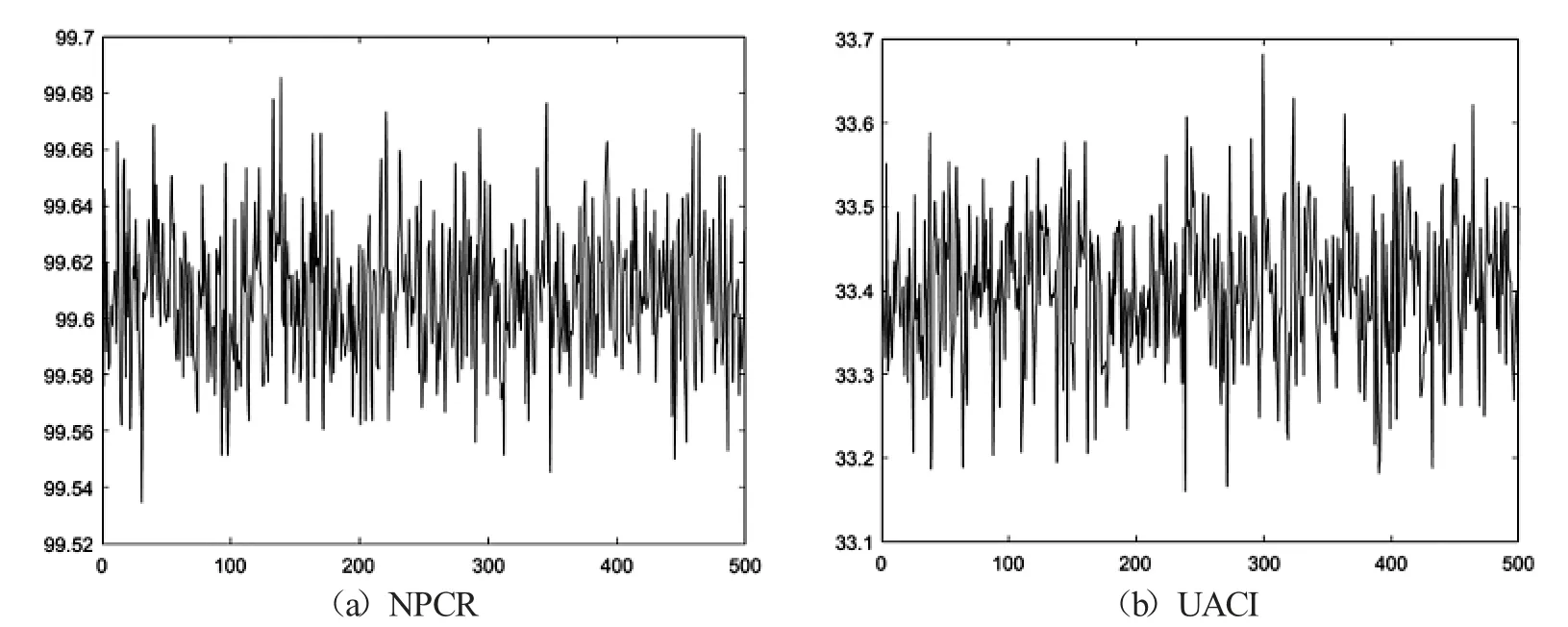
图16 明文敏感性-NPCR,UACI 曲线

表15 明文敏感性分析 (%)
3.2.7 密文敏感性分析
密文敏感性分析旨在分析当密文图像发生细微改变后,经解密系统解密后得到的解密图像与原解密图像的差别.若两个图像差别很大,则该加密系统具有较强的密文敏感性,反之,具有较弱的密文敏感性.以图像Lena 为例,随机改变其密文图像一个像素点灰度值的一个比特,并对其解密,得到新的解密图像,计算该解密图像与原解密图像的NPCR,UACI,500 次的实验结果如图17、表16所示.可以看到,NPCR,UACI值围绕理论值上下波动,波动幅度不大,平均值都非常接近其理论值,说明本文加密系统具有很强的密文敏感性.
4 总结
本文提出了一个基于混沌和DNA 序列的新型图像加密算法.论文对Logistic 映射进行了改进,提出一个混沌特性更好的改进Logistic 映射,基于改进Logistic 映射、超混沌chen 系统设计了两个随机数发生器以增加算法的随机性.算法采用预处理-比特层面扩散-置乱-DNA 编码及运算-多轮扩散的复杂加密结构,使用了位平面分解、混沌系统生成随机序列、DNA 编码及运算等技术,有效地提高了加密算法的安全性.性能分析证明了该算法具有极大的密钥空间,很好的统计特性,极强的密钥敏感性、明文敏感性,可有效的抵抗如穷举攻击、统计分析攻击、差分攻击等各项攻击,具有很好的安全性和有效性.
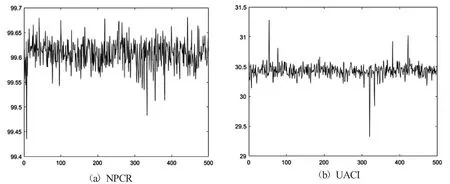
图17 密文敏感性-NPCR,UACI 曲线

表16 密文敏感性分析 (%)
猜你喜欢
电子与信息学报(2023年9期)2023-10-17 01:15:06
黑龙江大学自然科学学报(2022年1期)2022-03-29 00:57:56
计算机仿真(2021年10期)2021-11-19 08:17:42
阅读(低年级)(2019年2期)2019-04-19 09:54:46
电脑知识与技术(2018年35期)2018-02-27 13:29:44
民间故事选刊·上(2018年1期)2018-01-02 20:41:38
自动化学报(2017年11期)2017-04-04 02:52:44
小小说月刊·下半月(2016年6期)2016-05-14 15:23:24
中国资源综合利用(2016年11期)2016-01-22 02:01:25
深圳大学学报(理工版)(2015年5期)2015-02-28 16:22:05
