
基于对抗式生成网络的电力用户意图文本生成
2019-11-12 09:08欧阳昱刘辉舟
网络安全与数据管理 2019年11期
俞 畅,欧阳昱,张 波,刘辉舟
(1.中国科学技术大学 软件学院,安徽 合肥 230031;2.国网安徽省电力公司,安徽 合肥 230061)
0 引言
电力营业厅是国家电力公司的重要组成部分,每日有大量客户在营业厅进行各类电力业务办理。目前的营业厅运营模式有着潜在的问题[1]:营业厅需要配备齐全的营业组成员,每日无歇地回应用户问答请求;同时营业厅服务人员流动大,而培养一名合格的服务人员需要进行相关的电力知识培训,从而耗费大量时间、财力。
基于以上矛盾,搭建识别用户意图的智能系统[2]可以极高地精简业务办理流程,加快业务办理速度,减少各方面人力成本。智能交互系统意图识别模块的搭建大致可以分为以下几步:收集整理在供电营业厅背景下用户问询文本语料库;搭建识别用户意图映射到供电营业厅业务的深度学习框架;训练深度学习框架下意图识别模型;验证模型的可靠性;根据电力系统业务流程和数据返回回答。
训练神经网络识别用户意图需要大量的用户问询文本。但是在现实情况中,采集电力业务问询数据是个难题。电力业务问询数据是在供电营业厅中用户对营业员进行问询时产生的,数据的本源是语音,并非是传统的网络爬虫文本采集。
为了解决这一问题,本项目成员在安徽省电网供电营业厅设置了几处录音装置,将采集到的录音通过机器翻译转换成文字,再通过人工修改并进行意图标注。数据采集过程中,项目成员遇到了几处困难:电力营业厅中杂音较多,很多用户带有口音、使用方言,机器将语音转译成文字质量不佳,需要人工大规模修正,不少录音更需要人工重新听写;最后得到的数据文本较少,在进行大规模的深度学习训练时会导致神经网络模型过拟合、泛化能力弱。由此,获得规模更大的电力业务用户意图文本数据量是当前亟待解决的任务。
基于特定领域内的文本生成,多是运用人工收集、生产和标注的方法。人工进行收集生产的弊端极为明显:人力的有限和创造力的不足会给语料生产带来巨大的麻烦,由此,进行机器生产特定领域语料有着极为重要的研究意义。
自然语言文本可看作特殊的向量组成的序列。在弱监督机器学习的前提下,由神经网络生成合成文本来拟合真实数据仍面临着很多问题。基于最大似然估计(Maximum Likelihood Estimation,MLE)算法的长短期记忆网络(Long Short-Term Memory,LSTM)[3]是文本序列生成的常用方法。但最大似然估计在推理阶段会产生偏差(exposure bias):长短期记忆网络生成序列时,需要基于之前所有已生成序列预测下一个生成词,若之前序列中的向量生成得不佳,则错误会进行传递积累,使得训练和推理间的差异越来越大。为了解决这个问题,必须要减少训练和推理之间的差异。
一种被称为Scheduled Sampling(SS)的训练策略尝试解决这一问题[4]。Scheduled Sampling以一定概率将生成的元素作为解码器输入,这样即使前面生成错误,其训练目标仍然是最大化真实目标序列的概率,模型会朝着正确的方向进行训练。因此这种方式增加了模型的容错能力。但Scheduled Sampling策略并没有从根本上解决偏差问题。主要原因在于,模型中从前一时刻输出获得后一时刻的输入涉及采样操作,而这个操作是不可微的。在强化学习中,action可以通过返回reward代替梯度回传,从而解决不可微的问题。
生成对抗网络(Generative Adversarial Networks,GAN) 是GOODFELLOW I J等[5]在2014 年提出的一种生成式模型,系统由一个生成网络与一个判别网络组成。生成网络初始化为随机采样,之后通过判别网络捕捉真实数据的潜在分布,尽可能生成相似于真实数据的分布。判别网络本质则判断输入数据是真实数据还是生成样本,起到二分器的作用。生成网络模仿真实数据生成相似的样本分布以欺骗判别网络,判别网络在迭代中不断更新以区分生成样本和真实数据。生成网络和判别网络相互博弈,直到达到那什均衡。
传统对抗式生成网络在图片生成领域[6]有着广泛的应用,但是运用在自然语言领域,如文本生成,应用范围并不广泛[7-8]。对抗式生成网络有着明显的缺点:由于自然语言数据本身的离散性质,传统的GAN框架中生成器难以进行梯度回传。文献[9]以RNN(Recurrent Neural Network)作为对抗式生成网络的生成网络,以卷积神经网络(Convolutional Neural Networks,CNN)作为GAN的判别网络,使用强化学习中reward信号代替梯度回传,从而解决自然语言文本梯度无法回传问题。文献[10]对GAN的损失函数做出修改,对真实句子和生成句子的隐藏特征表示进行匹配操作,这种方法可以得到更好的收敛效果。
1 基于对抗式生成网络的电力用户意图文本生成
1.1 电力业务用户意图文本生成框架
电力营业厅智能交互系统的实现依赖于对用户意图的识别。电力用户意图文本数据量不足将导致训练模型欠拟合。为解决这一问题,本文提出基于GAN的电力用户意图文本生成框架。将人工采集到的真实用户问询语句进行数据清洗,将每个词转换成单独的word-id。使用RNN[11]构建文本序列生成网络,使用CNN[12]构建文本序列判别网络,并进行预训练:用真实数据通过MLE预训练文本序列生成网络,用真实数据作为正样本,文本序列生成网络生成的数据作为负样本,训练出二分类的文本判别网络。预训练完成后进行对抗训练,迭代训练文本序列生成网络和文本序列判别网络。对抗式生成网络以negative likelihood(NLL)作为评估方式,尝试解决极大似然估计中遇到的偏差问题。
基于对抗式生成网络的电力业务用户意图文本生成框架如图1所示,该模型由两部分组成:文本序列生成网络和文本序列判别网络。文本序列生成网络生成文本序列,之后与真实用户问询语料一并转换为词向量交由文本序列判别网络通过打分(reward)进行真假判别。文本序列生成网络只能对完整序列文本进行打分,当文本序列生成网络产生的序列不完整时,文本序列判别网络通过蒙特卡洛树搜索策略将序列补充完整。文本序列判别网络对完整序列产生打分再回传给文本序列生成网络,指导文本序列生成网络更新产生更优的文本序列。

图1 电力业务用户意图文本生成框架
1.2 文本序列生成网络Gθ
文本序列生成网络Gθ的任务是进行电力业务用户意图文本的生成,产生序列如下:Z1:T=(z1,…,zt,…,zT),zt∈T。序列中,T为电力业务用户意图文本词表。文本序列生成网络应用了强化学习的方法,每生成t个序列耗费时间t,状态s表示产生的序列(z1,…,zt-1),动作a表示从所有可能的候选词中选择下一个词zt的行为。
RNN使用词向量(word embedding)来表示序列(z1,…,zt)。通过递归调用更新函数f将ZT转换为隐藏状态(h1,…,ht)的序列,如式(1)所示:
ht=f(ht-1,zt)
(1)
softmax输出层z将隐藏状态映射到输出的词分布中,其中参数是偏置向量b和权重矩阵V,如式(2)所示:
p(ht|z1,…,zt)=softmax(b+Vzt)
(2)
1.3 文本序列判别网络Dφ
文本序列判别网络Dφ功能是判断输入的文本序列Z1:T是真实文本还是文本序列生成网络生成文本。文本序列判别网络通过调整目标函数指导文本序列生成网络进行更新,以使文本序列生成网络生产出更真实的文本。由于CNN最近在文本分类方面显示出的巨大效果,实验中选用CNN[12]作为判别器。
输入样本为Z=(z1,…,zt),对序列Z进行序列编码,如式(3)所示:
Γ1:T=z1⊕z2…⊕zt
(3)
式中,zt∈Rk,是k维词向量,⨁是构建矩阵E1:t的级联算子,Γ1:T∈RT×k表示词向量的链接矩阵。卷积核W∈RT×k对L个字的窗口大小应用卷积运算产生新的特征映射,如式(4)所示:
di=σ(W⊗εi:i+l-1+d)
(4)
其中,运算符⊗是点积的总和,d是偏差项,σ是非线性函数。实验使用不同数量具有不同窗口大小的内核来提取不同的电力问询用户文本序列特征。对特征映射g=max{g1,…,gT-L+1}应用最大池化操作。接着使用Sigmoid激活函数的完全连接层来判断输入序列是真实用户问询文本的概率,如式(5)所示:
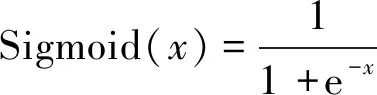
(5)
文本生成网络Gθ使用LSTM网络搭建,将参数初始化在[0,1]内,使用Dropout[13]和L2正则化来避免过拟合。为了评估文本生成网络Gθ生成文本的质量,使用LSTM神经网络对生成的电力用户问询文本进行Nll值计算,如式(6)所示:
(6)
1.4 模型预训练
生成式对抗网络的训练是生成网络与判别网络之间博弈的过程,为了以最快的方式达到那什均衡,训练开始前,将文本生成网络使用最大似然估计(MLE)方法在真实数据集上进行预训练。在预训练后,生成网络和判别网络被交替训练,随着生成网络通过一定步骤的更新训练得到进步,判别网络需要定期重新训练,以保持和生成网络的良好步调:每隔一定步骤的训练,使用生成网络生成的数据,且以最大交叉熵函数为目标函数,预训练判别网络。
具体步骤如下:首先使用真实用户问询文本初始化文本生成网络;其次,用文本生成网络生成用户问询序列,并使用预训练完成的文本序列判别网络与蒙特卡洛搜索方法,对生成的文本计算Rθ值;接着,更新文本生成网络参数;最后,在规定训练次数中使用更新的文本生成器生成文本,并使用生成文本训练文本判别网络。
1.5 模型训练方法

(7)
生成网络需要模仿真实的文本,生成序列让判别网络认定序列是真实文本。判别网络仅为完成的序列提供打分。此处使用强化学习算法[15],将判别网络的输出概率作为打分标准。如式(8)所示:

(8)
强化学习算法只为已经完成的序列进行打分,但是无法指导正在生成的序列进行参数调整。而未完成序列的下一步生成对序列质量影响极大。为了评估未完成序列,引入蒙特卡洛搜索中roll-out[16]策略对未知T-t个词进行采样。N表示由蒙特卡洛生成的第N个序列。通过采样填补未完成序列,再运用强化学习算法对填补完成的序列进行打分,进而达到指导序列生成的目的,如式(9)所示:
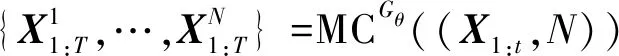
(9)
由此,进行序列评估的完整公式,参考文献[17],如式(10)所示:
(10)
生成网络在获得判别网络打分后,会更新生成网络,生成更加逼真的文本序列。序列生成网络梯度函数如式(11)所示:
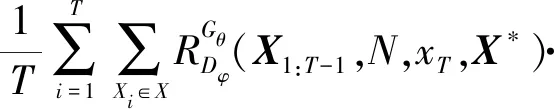
(11)
当判别网络和生成网络达到那什均衡后,为了进一步指导生成网络生成更加逼真的文本序列,判别网络需要再次运用目标函数更新判别器模型,其目标函数[17]的优化目标是最小化真值标签与预测概率之间的交叉熵,如式(12)所示:
min {lossX′∈Vdata(logD(X))-lossX′∈Gθ(log (1-D(X)))}
(12)
2 实验结果和分析
2.1 实验数据集
实验的真实数据集来自电力营业厅用户真实问询。在电力公司处获得用户录音后,通过语音转换和人工修正的方式获得最终语料。语料库共包含10 000条语料。按照智能系统可否协助办理进行业务划分,可将语料集划分为“业务一”“业务二”。“业务一”“业务二”数据集各5 000条。
2.2 评估指标
实验参考文献[18]同时结合电力业务的实际需求对文本生成结果进行分析。
2.2.1 意图识别网络RNN的识别准确率
电力营业厅业务种类繁多,智能意图识别系统在识别用户意图后,可以协助用户进行部分业务的自助办理,进而减少营业厅人力成本和人员工作压力。智能识别系统可以协助用户自助办理的业务被归类为“业务一”。在询问完智能识别系统后,另外需要营业员人工协助办理的业务被归类为“业务二”。用搭建好的RNN意图识别网络基于真实语料进行意图分类实验并记录准确率。再用对抗式生成网络对“业务一”和“业务二”文本分别进行文本生成。挑选生成质量较好的“业务一”和“业务二”语料放入RNN训练集中重新进行神经网络训练。通过观察意图识别网络的准确率是否上升来验证对抗式生成网络生成文本的质量。
2.2.2 文本相似度评价BLEU得分
实验使用BLEU[19]打分度量真实用户问询文本和生成序列文本之间的相似度。BLEU最初用于自动判断机器翻译质量。对于评价用户问询生成文本大多数单词由一个或者两个字符组成,本文使用BLEU-3、BLEU-4和BLEU-5评价生成语料质量。
2.3 实验结果
2.3.1 意图识别准确率
将真实数据集随机打乱顺序,按照5∶2.5∶2.5比例对训练集、测试集、验证集进行划分,用事先搭建好的RNN意图识别网络进行训练。
将用户问询文本生成模型对“业务一”和“业务二”文本分别进行文本生成,各生成文本5 000条。挑选生成质量较好的“业务一”和“业务二”语料各放入RNN训练集中重新进行神经网络训练。实验结果如表1所示。

表1 数据增强前后RNN意图识别网络测试集准确率对比
实验表明,将生成文本添加入RNN意图识别网络的训练集中,测试集上的准确率由79.6%提升到82.1%。虽然存在个别生成序列不符合中文语法的现象,但大部分生成的电力问询文本在句子结构和包含内容方面能与真实的电力用户问询文本质量相似。
2.3.2 BLEU打分
实验2使用BLEU[19]打分的方式评价生成语料质量。基于电力文本语句间词语相互依赖性,采用BLEU-3、BLEU-4和BLEU-5来评估生成序列质量。将基于对抗式生成网络生成的文本和基于最大似然估计的LSTM网络生成的文本各5 000条与真实文本进行对比打分,实验结果如表2所示。

表2 文本BLEU打分
实验结果证明,用户问询文本生成模型相较于传统最大似然估计方法取得了较好的分数,生成的语句符合基本语法和用户问询场景。
3 结论
针对电力智能交互系统进行深度学习训练时文本不足的问题,提出利用对抗式生成网络进行电力问询文本生成。虽然存在个别生成序列不符合中文语法,但大部分生成的电力问询文本在句子结构和包含内容方面能与真实的电力用户问询文本质量相似。实验结果表明,将生成文本添加入RNN意图识别网络的训练集中,测试集上的准确率由79.6%提升到82.1%。BLEU打分也从侧面证明,使用对抗式生成网络生成的电力用户问询文本基本符合实际数据,相对于传统的LSTM网络生成文本方法更具优势,可以应用于电力智能交互系统的研究与开发。
猜你喜欢
法律方法(2022年2期)2022-10-20
福建基础教育研究(2022年4期)2022-05-16
厦门大学学报(自然科学版)(2021年4期)2021-06-22
法律方法(2021年3期)2021-03-16
电脑知识与技术(2019年23期)2019-11-03
科技与创新(2018年5期)2018-11-30
新城乡(2018年6期)2018-07-09
中国新通信(2017年9期)2017-05-27
外语教学理论与实践(2014年2期)2014-06-21
延河(下半月)(2014年3期)2014-02-28
