
基于改进Tiny-YOLO模型的群养生猪脸部姿态检测
2019-11-08 01:18:34燕红文刘振宇崔清亮胡志伟李艳文
农业工程学报 2019年18期
燕红文,刘振宇,崔清亮,胡志伟,李艳文
基于改进Tiny-YOLO模型的群养生猪脸部姿态检测
燕红文1,刘振宇1,崔清亮2※,胡志伟1,李艳文1
(1. 山西农业大学信息科学与工程学院,太谷 030801;2. 山西农业大学工学院,太谷 030801)
生猪脸部包含丰富的生物特征信息,对其脸部姿态的检测可为生猪的个体识别和行为分析提供依据,而在生猪群养场景下,猪舍光照、猪只黏连等复杂因素给生猪脸部姿态检测带来极大挑战。该文以真实养殖场景下的群养生猪为研究对象,以视频帧数据为数据源,提出一种基于注意力机制与Tiny-YOLO相结合的检测模型DAT-YOLO。该模型将通道注意力和空间注意力信息引入特征提取过程中,高阶特征引导低阶特征进行通道注意力信息获取,低阶特征反向指引高阶特征进行空间注意力筛选,可在不显著增加参数量的前提下提升模型特征提取能力、提高检测精度。对5栏日龄20~105 d的群养生猪共35头的视频抽取504张图片,共计3 712个脸部框,并标注水平正脸、水平侧脸、低头正脸、低头侧脸、抬头正脸和抬头侧脸6类姿态,构建训练集,另取420张图片共计2 106个脸部框作为测试集。试验表明,DAT-YOLO模型在测试集上对群养生猪的水平正脸、水平侧脸、低头正脸、低头侧脸、抬头正脸和抬头侧脸6类姿态预测的AP值分别达到85.54%、79.30%、89.61%、76.12%、79.37%和84.35%,其6类总体mAP值比Tiny-YOLO模型、仅引入通道注意力的CAT-YOLO模型以及仅引入空间注意力的SAT-YOLO模型分别提高8.39%、4.66%和2.95%。为进一步验证注意力在其余模型上的迁移性能,在同等试验条件下,以YOLOV3为基础模型分别引入两类注意力信息构建相应注意力子模型,试验表明,基于Tiny-YOLO的子模型与加入相同模块的YOLOV3子模型相比,总体mAP指标提升0.46%~1.92%。Tiny-YOLO和YOLOV3系列模型在加入注意力信息后检测性能均有不同幅度提升,表明注意力机制有利于精确、有效地对群养生猪不同类别脸部姿态进行检测,可为后续生猪个体识别和行为分析提供参考。
图像处理;模型;目标检测;Tiny-YOLO;通道注意力;空间注意力
0 引 言
随着生猪养殖规模不断扩大,养殖密度不断增加,对群养环境中的生猪个体进行自动有效识别,为其建档立卡并构建养殖可追溯系统,对实现猪场养殖的精准管理具有重要意义。生猪脸部的眼、鼻、耳等可辨识性个体信息对生猪个体识别至关重要,准确有效地生猪脸部检测可为生猪个体识别与规模化养殖决策制定提供技术支撑[1-2]。
随着深度学习技术的成熟,基于卷积神经网络CNN(convolutional neural network)的视觉分析技术在生猪姿态检测[3]、生猪图像分割[4-7]、生猪个体识别[8]等诸多领域取得较大进展,并在目标检测领域同样表现出优越性能[9-13]。CNN检测框架包括基于区域[14-15]和基于回归两大系列。其中以YOLOV1[16]、YOLOV2[17]、YOLOV3[18]和Tiny-YOLO[19]为代表的基于回归的方法能在保证检测精度的同时提升检测速度,适用于规模化生产环境中,并已被用于芒果[20]、苹果[21]、生猪个体[22]等目标的检测定位。而在生猪脸部姿态检测方面,经现有文献查证,未有学者对此领域做过相关研究。此外上述基于YOLO的系列方法认为特征图中每个区域对模型最终检测结果贡献度相同,而在群养生猪脸部姿态检测中,猪体、猪粪、猪食等噪声信息均不利于脸部位置精确提取,若可有效抑制此类信息,并对猪脸所在区域特征施以较高权重则可更好的提升检测精度。注意力机制的出现可有效解决此类问题,该机制在处理信息时只关注部分有利于任务实现的区域信息,滤除次要信息以提升模型效果,并已在图像分类[23]、图像分割[24]领域得到成熟应用,而在目标检测领域仍处于探索阶段[25],因而探讨将该机制用于猪舍场景下群养生猪脸部定位成为可能。
基于此,本文提出一种基于Tiny-YOLO模型的非接触、低成本的群养生猪脸部姿态检测新方法,该方法将通道注意力和空间注意力机制相结合以构建双重注意力子模型DAT-YOLO进行端到端训练,实现对群养生猪水平正脸、水平侧脸、低头正脸、低头侧脸、抬头正脸和抬头侧脸6类姿态高精度检测,避免猪只黏连、猪舍光照等干扰因素对检测效果的影响,以期为生猪智能养殖与管理提供技术参考。
1 试验数据
1.1 数据采集
数据采集自山西省汾阳市冀村镇东宋家庄村,为获取不同猪舍场景的生猪图像,于2019年6月1日9:00-14:00(晴,光照强烈)选取3个猪场进行视频采集,每个猪场由10~30间猪栏构成,每栏数量5~8只不等,猪栏大小约为3.5 m×2.5 m×1 m。选取5栏日龄20~105 d的群养生猪共计35头,采用佳能700D防抖镜头,移动拍摄时生猪距离镜头0.3~3 m不等,因而可用于采集不同大小猪脸区域。因实际场景下群养生猪脸部姿态具有随机性,并非均是正脸面朝镜头,故将脸部姿态细分为正脸与侧脸,同时,不同角度生猪个体脸部蕴含信息差异较大,故最终将脸部姿态细化标注为水平正脸、水平侧脸、低头正脸、低头侧脸、抬头正脸和抬头侧脸6类。标注时将耳部作为脸部与身体部位分界点,且对未出现在采集范围或眼部未出现在镜头中的脸部不做任何标注,其每类姿态详细标注原则如表1所示。

表1 生猪脸部6类姿态定义
注:夹角的正负定义为嘴部最低点与颈部连线的夹角在颈部水平方向上方为正,在颈部水平方向下方为负。
Note: The positive and negative angle is defined as positive when the angle between the lowest point of mouth and the line of neck is above the horizontal direction of neck and negative below the horizontal direction of neck.
1.2 数据预处理
将采集的视频数据进行下列操作以构建生猪脸部姿态检测数据集:
1)对采集的视频做切割视频帧处理,对获取到的1 920×1 080分辨率图像边缘添加黑色像素值操作以使其宽高比为2:1,完成后像素值变为2 048×1 024,并采用labelImg[26]作为脸部姿态标注工具,其过程如图1a~1b所示。
2)因本文检测模型输入分辨率为416×416,故对上述处理后的图片每2张进行拼接操作得到方形图片,其分辨率为2 048×2 048,对获取的图片做放缩操作,将分辨率最终转换为416×416,以减少运算量,提高模型训练速度,同时对步骤1)中所标注的脸部位置进行相应坐标变换,以获取放缩后图像对应的脸部坐标信息,其过程如图1c~1d所示。由图1可见,虽然猪的头部也位于镜头采集范围内,但其眼部并未呈现,故本文未对其进行标注。

图1 数据处理过程
经上述2步处理后,本文共得到标注图像989张,按照通用数据集划分策略[27],将其中504张作为训练集,65张作为验证集,420张作为测试集。训练集包含3 712个生猪脸部框,测试集包含2 106个猪脸框,对训练集与测试集中每类姿态标注框数量统计结果如表2所示。由表2可知,训练集与测试集上6种姿态数目不等会带来数据不均衡问题,本研究对该问题的处理见5.1讨论部分所示。
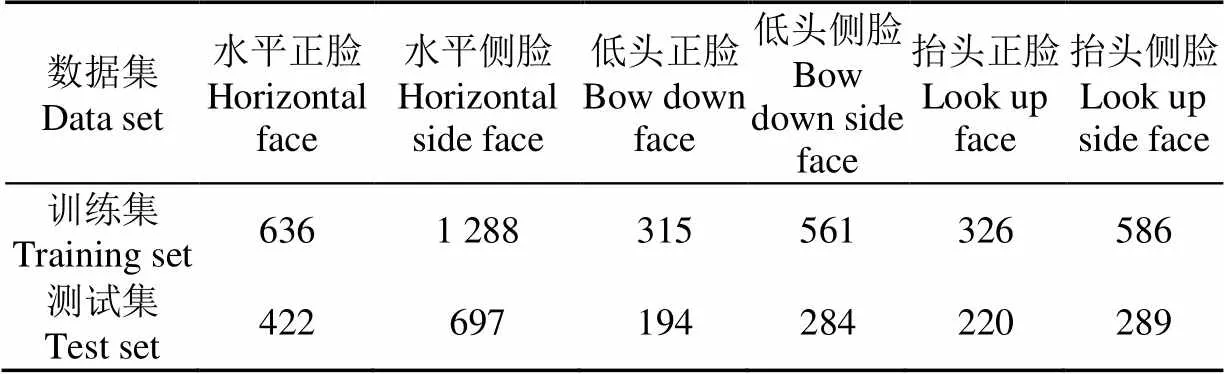
表2 训练集测试集各个姿态类别数量
2 检测模型
2.1 Tiny-YOLO模型
YOLOV1、YOLOV2和YOLOV3是Joseph等[16-18]提出的目标检测通用模型,Tiny-YOLO是轻量化YOLOV3,其融合了最新的特征金字塔网络[12](feature pyramid networks,FPN)和全卷积网络[28](fully convolutional networks,FCN)技术,模型结构更简单,检测精度更高,速度更快[29]。
Tiny-YOLO模型主要由卷积层与池化层拼接构成,其模型结构如图2所示。模型输入图像分辨率为416×416×3,经过一系列3×3和1×1卷积、池化以及上采样操作,可对输入图像进行特征提取,每步提取完成后特征图尺寸如图3中长方体底部数字所示,数字项分别表示特征图分辨率宽×分辨率高×通道数。由于不同种类目标在原始图中所占比例差异较大,Tiny-YOLO引入多尺度特征提取模块以保证对不同大小目标均具有较强的检测性能。模型最终输出2个尺度特征图,如图2中①、②所示。多尺度特征图对于同一目标可能会有多个检测结果,Tiny-YOLO引入非极大值抑制(non maximum suppression, NMS)[30]剔除冗余的检测框以使得对于每个目标均有唯一检测框,使其位置信息更准确,置信度更高。但Tiny-YOLO模型在特征提取过程中,对特征图中的每个区域均赋予相同权重值,而在生猪脸部姿态检测中,图像中的猪脸、猪蹄和猪舍等部位对猪脸区域精确定位贡献度不同,应赋予不同权重值。降低猪蹄、猪舍等噪声信息的影响,强化猪脸区域特征,可提升定位准确度。
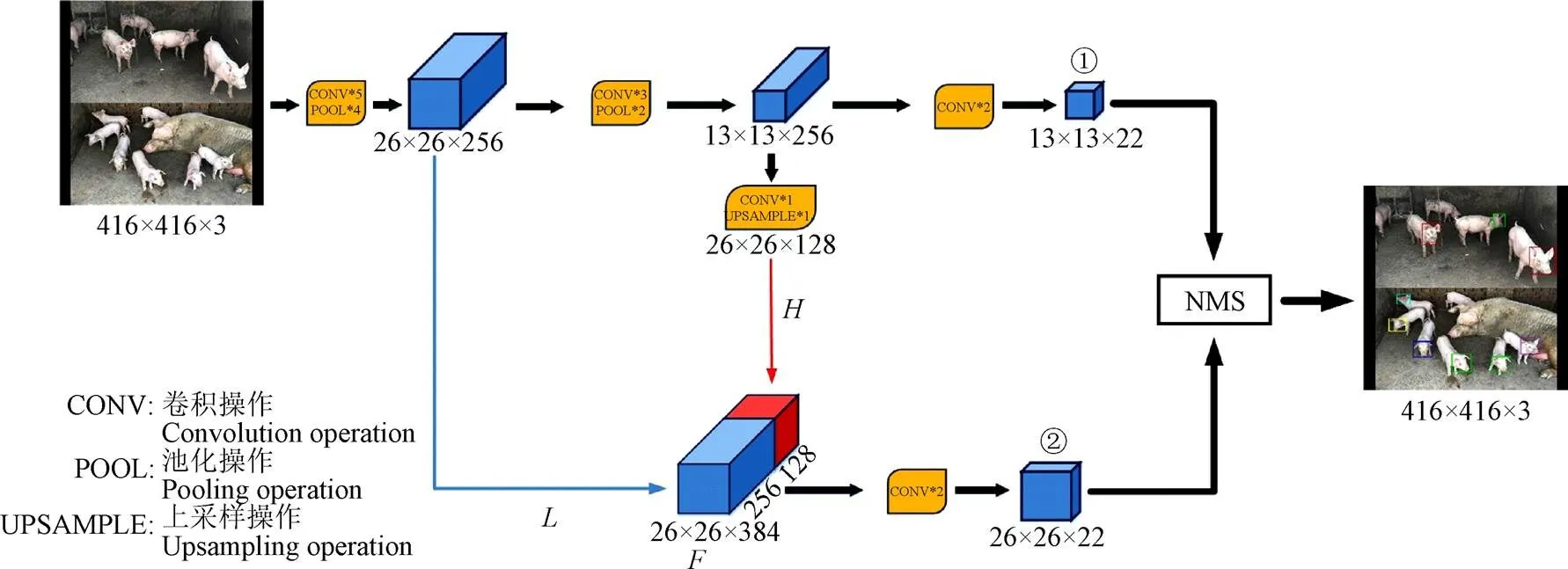
注:L表示低阶特征图,H表示高阶特征图信息,F表示高低阶融合特征图,①、②分别表示对输入图像的2种不同尺度检测结果。
2.2 对Tiny-YOLO模型的改进
2.2.1 引入通道注意力模块
因不同通道信息对检测结果贡献度不同,本文引入通道注意力(channel attention block, CAB)模块对特征图各个通道间的依赖性进行建模,可使同一特征图的不同位置具有相同的通道权重信息,使模型能选择性地强化重要信息并抑制弱相关特征,进而提高模型表征能力,可精确定位生猪脸部,其结构如图3所示。全局平均池化[31-32]常被用于汇集空间通道信息,该操作通过压缩输入特征图空间维度生成特征图像素点反馈信息以计算通道注意力,但其断然将特征图中的每一点对通道注意力信息的获取视为具有同等作用,削弱了特征强度较大区域对通道注意力信息的影响。而全局最大池化在梯度反向传播过程中仅计算响应最大地方的梯度反馈,可进一步强化敏感区域以弥补全局平均池化的短板。为此,本文CAB模块在传统通道注意力模块中加入全局最大池化操作,通过对高阶特征进行全局平均与最大池化融合得到通道权重向量以引导低阶特征图进行通道选择,实现特征响应与特征重校准效果。
其核心操作如图3中虚线框部分所示,其计算为式(1)~式(3)。
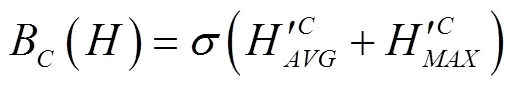
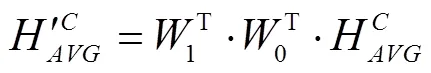
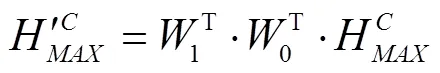
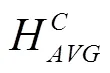
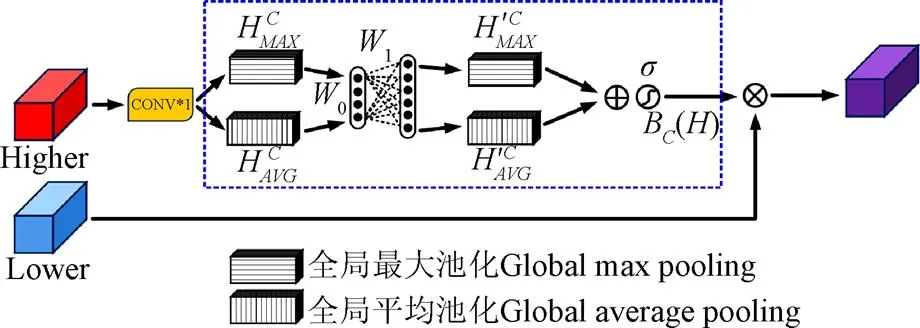
注:Higher表示高阶特征,Lower表示低阶特征。与分别表示全局平均池化与全局最大池化,与分别表示经隐藏层处理后的全局平均池化与全局最大池化值,W0与W1分别表示隐藏层参数矩阵,s表示sigmoid激活函数,BC(H)表示最终获取的通道注意力信息。
2.2.2 引入空间注意力模块
为有效编码特征图内部像素点间关系,本文引入空间注意力(spatial attention block,SAB)模块以对特征图内部元素进行建模,不同通道特征图中相同位置处具有相同的空间权重信息。不同于通道注意力对特征图中的每一通道内部的所有特征点共享相同权重,空间注意力区别对待于特征图中的每一点,将所有通道中相同位置处的值进行全局平均池化与最大池化融合操作以获取指定位置处的空间权重值,用以补充通道注意力机制无法较好获取的位置关系信息,进而用于对特征图中各个位置特征值进行筛选以突出适用于生猪脸部姿态检测的特征,其核心操作如图4中虚线框所示,其计算为式(4)。
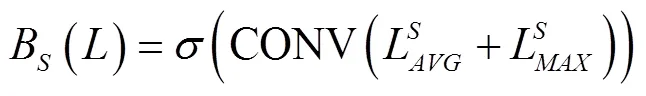
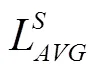

图4 空间注意力模块
Fig.4 Spatial attention block
2.2.3 融合通道与空间注意力的DAT-YOLO模型
本文提出融合CAB与SAB模块的DAT-YOLO(dual attention tiny-YOLO)模型,对Tiny-YOLO模型进行改进,用于群养环境下多角度生猪脸部姿态检测,其模型结构如图5所示。DAT-YOLO在Tiny-YOLO模型中引入通道注意力块与空间注意力块两类模块以选择性融合深浅层特征,高阶特征引导低阶特征进行通道注意力获取,低阶特征反向指引高阶特征进行空间注意力筛选,可在不显著增加计算量和参数量的前提下提升模型特征提取能力。因群养状态下生猪个体距摄像仪位置不同,故其所采集的生猪脸部面积差异较大,DAT-YOLO保留了Tiny-YOLO的多尺度特征提取模块以保证对不同大小脸部有较强的检测性能。DAT-YOLO模型核心部件如图5中最外层虚框所示,其计算为式(5)。
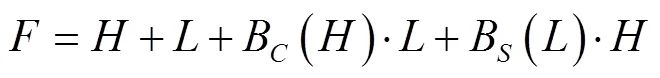
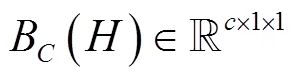
2.3 模型评价指标
本文采用目标检测领域公认的平均检测精度mAP以及精确率-召回率(precision-recall,-)曲线变化情况作为评价标准以衡量4种模型对生猪脸部姿态检测性能。-曲线反映的是不同召回率与对应召回率下最大精确率间的关系变化情况,检测精度AP指-曲线下方面积,mAP指同一模型对6种生猪脸部姿态类别的AP平均值。Precision、Recall、AP及mAP定义如式(6)~式(9)所示。

注:表示经过高阶特征通道筛选后的低阶特征信息,表示经过低阶特征空间筛选后的高阶特征信息
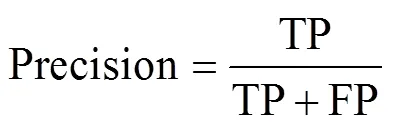

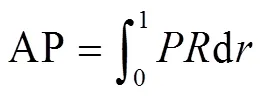
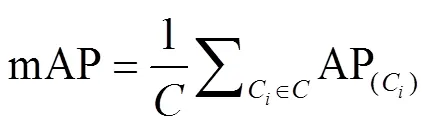
其中TP表示模型预测为正实际为正的样本数量;FP表示模型预测为正实际为负的样本数量;FN表示模型预测为负实际为正的样本数量;,分别表示精确率与召回率;表示姿态类别总数,本文取6,C表示当前第个类别,的取值范围为1~6。
3 试验平台参数
试验平台配置为Intel(R) Core(TM)i7-6700CPU@ 3.40 GHz 处理器,8 GB 运行内存,1 T 硬盘容量,12 GB GTX Titan X GPU,系统为CentOS7.4。采用keras[33]框架进行模型代码的编写。将数据集分为训练集、验证集及测试集3 个部分,其中训练集大小为 504,验证集大小为65,测试集大小为420。为避免内存溢出,采取批训练方式对Tiny-YOLO与YOLOV3两类系列8个子模型在训练集和验证集上进行试验,训练时一个批次(batch)包含16张图片,遍历1次全部训练集数据称为1次迭代,本文设置迭代次数为300。8个子模型均采用与Redmon[18]一致的loss损失函数,采用自适应矩阵估计算法(adaptive moment estimation,Adam)[34]优化模型,初始学习率设置为0.000 1,每次更新权值时使用BN(batch normalization)[35]进行正则化。为使模型能检测不同大小的生猪脸部,引入Faster R-CNN的锚框(anchor boxes)[15]思想,通过使用K-means算法对训练集锚框进行聚类,针对图5 中Tiny-YOLO系列模型①与②每种尺度分别生成2种不同大小的潜在待识别目标的锚框,最终获得4个锚点,其大小分别为(23×27)(37×58)(81×82)(135×169),其中尺度①使用后2个锚点,适合检测较大脸部对象,尺度②使用前2个锚点,适合检测较小对象,针对YOLOV3系列模型,共有9个锚点框,其大小分别为(10×13)(16×30)(33×23)(30×61)(62×45)(59×119)(116×90)(156×198)(373×326),其中前3个锚点框适合检测较小脸部对象,中间3个锚点框适合检测中等大小脸部框,后3个锚点框适合检测较大脸部对象。在计算mAP指标值时,参照PASCAL VOC2012 mAP评价指标[36]定义方式,设置当检测框与手动标注框的IOU[37]值超过0.5且检测类别相同时视为检测正确。
4 结果与分析
本文移除图5中CAB模块构建SAT-YOLO(spatial attention tiny-YOLO)子模型、移除SAB模块构建CAT-YOLO(channel attention tiny-YOLO)子模型以测试2类注意力模块在Tiny-YOLO系列模型上的有效性。同时为进一步验证注意力信息在其余模型上的迁移性能,基于YOLOV3模型分别构建CA-YOLOV3(channel attention YOLOV3)、SA-YOLOV3(spatial attention YOLOV3)与DA-YOLOV3(dual attention YOLOV3)子模型,并评估其各自性能状况。
4.1 模型的检测精度分析
表3为Tiny-YOLO模型8种子模型对生猪6种脸部姿态识别的AP以及总体mAP,不同模型间采用相同的试验训练参数,并在相同测试集上验证模型的有效性,其中每一系列模型均进行完全不引入注意力、仅引入通道注意力、仅引入空间注意力与同时引入2种注意力各4组试验,以验证注意力机制有效性。
试验结果表明:
1)基于Tiny-YOLO的子模型在水平侧脸、低头正脸、抬头侧脸姿态类别的AP值均优于基于YOLOV3的子模型,且对低头正脸类别的提升幅度最大,由表2可知,在对低头正脸类别预测的AP值方面,Tiny-YOLO系列模型相较于YOLOV3系列模型提高了2.20%~8.59%。Tiny-YOLO系列模型虽对水平正脸和低头侧脸姿态类别未能取得最佳AP值,但其值与YOLOV3系列加入相同注意力模块的子模型相比仍具有较强竞争力。Tiny-YOLO系列模型的总体mAP指标与加入相同注意力模块的YOLOV3系列模型相比提高了0.46%~1.92%,且对同时加入2类注意力模块的子模型,DA-YOLOV3模型预测mAP值达到81.92%,DAT-YOLO模型预测mAP值达到82.38%,取得了相应系列模型最优值,而对于单独引入通道或者空间注意力的mAP指标,
SA-YOLOV3预测mAP值达到78.30%,CA-YOLOV3预测mAP值达到75.80%,SA-YOLOV3预测效果优于SA-YOLOV3预测效果,SAT-YOLO模型预测mAP值达到79.43%,CAT-YOLO模型预测mAP值达到77.72%,SAT-YOLO预测效果优于CAT-YOLO预测效果,这表明注意力信息尤其是空间注意力对YOLOV3和Tiny-YOLO系列模型性能影响更大。虽然YOLOV3网络层次更深,但在本文试验数据环境中,其性能劣于Tiny-YOLO系列模型,理论上网络层次越深,其特征表征能力越强,但深层网络可能会带来梯度消失问题,导致反向传播算法无法将梯度有效传回。此外,本文群养生猪图片具有背景可控、猪只所占图片像素比例较大的特点,对场景语义丰富度较弱的图片,浅层网络往往具有更优的检测性能。基于上述试验结果,本文后续其他指标分析主要集中于性能较优的Tiny-YOLO系列模型。
2)Tiny-YOLO系列模型的DAT-YOLO子模型在多数类别上均能取得最佳AP值。与同系列模型其余3种子模型相比,DAT-YOLO模型的mAP值提高2.95%~8.39%。DAT-YOLO对抬头侧脸类别预测的AP值比其余3种子模型最优值提高6.59%,提升幅度最大。虽然DAT-YOLO对低头侧脸类别未能达到最优效果,但仅比其余3种子模型的最佳值低1.31%,说明DAT-YOLO子模型最适用于群养状态下生猪脸部姿态识别。
3)引入注意力机制在很大程度上提升了生猪脸部姿态检测准确率。在Tiny-YOLO模型中引入通道注意力或空间注意力后的子模型,SAT-YOLO比Tiny-YOLO模型的mAP提高5.44%,CAT-YOLO比Tiny-YOLO模型的mAP提高3.73%,DAT-YOLO比Tiny-YOLO模型的mAP提高8.39%,其性能均优于Tiny-YOLO模型,且DAT-YOLO子模型的效果最优,其mAP分虽较CAT-YOLO、SAT-YOLO提高4.66%和2.95%,这是因为通道注意力可对特征图的不同通道赋予不同特征,选择性增大包含生猪脸部通道的权重值,空间注意力对同一特征图不同位置特征点给予不同权重,区别对待特征图内部像素点,强化脸部特征值贡献率,两者结合可总体提升检测准确率,这表明了注意力机制对生猪脸部姿态检测的有效性。对仅引入一种注意力的子模型,SAT-YOLO提升幅度一般较高于CAT-YOLO,其mAP较CAT-YOLO子模型提高1.71%,具体到单一生猪脸部姿态类别,SAT-YOLO子模型相较于CAT-YOLO子模型对低头侧脸类别的提高值达到11.40%,提升幅度最大,说明在群养生猪脸部姿态检测中,空间注意力效果更加明显,这是因为不同于通道注意力信息,空间注意力将权重施加于特征图中的每一点,对每个特征点区别对待,自学习脸部框边界权重,可进一步提高脸部边界位置的准确率。
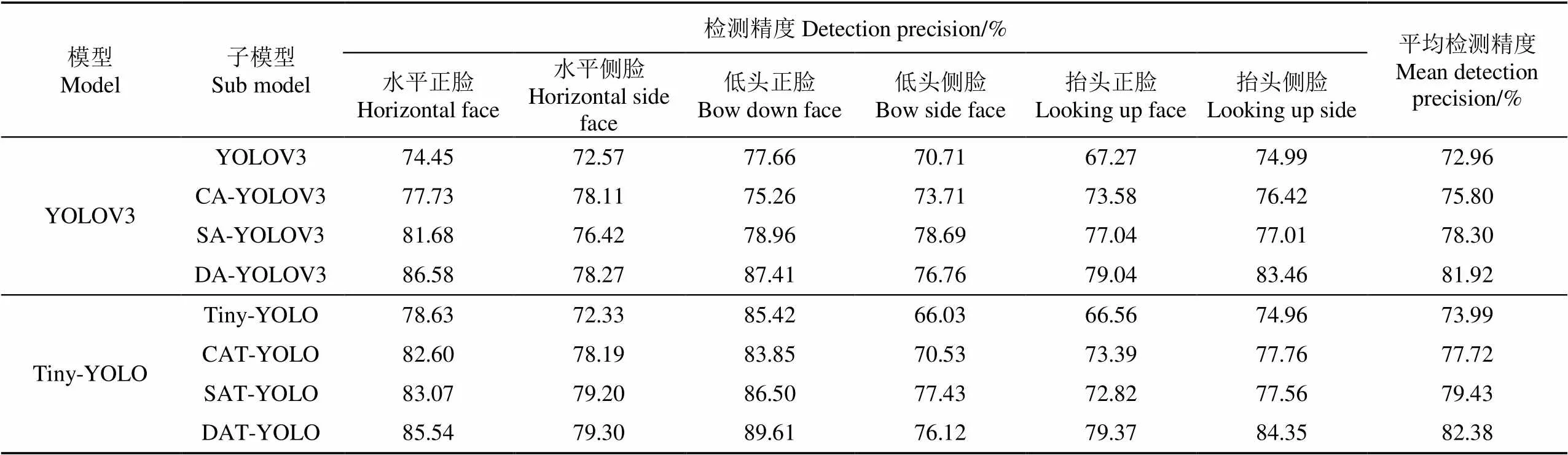
表3 测试集不同子模型对生猪脸部姿态类别的检测精度与平均检测精度
4.2 模型预测结果TP与FP数目分析
为明确Tiny-YOLO系列模型的4种子模型对6种姿态类别的预测结果,对式(6)、式(7)中的TP、FP中间指标值采用柱状图表示。通常TP、FP值的获取,需对模型预测的结果类别框进行过滤操作,首先去除置信度低于某一值的预测框(本文置信度阈值设置为0.3),接着将筛选过后的预测框按照置信度值进行降序排列,随后计算最高置信度值预测框与真实框间的IOU值,若IOU大于设定阈值(本文IOU阈值设为0.5),则将当前预测框加入TP中,同时将对应真实框标注为已检测,后续对该真实框的其余预测框均被列入FP中,最终Tiny-YOLO系列模型4种子模型的TP与FP值如图6所示。

注:TP表示模型预测为正实际为正的样本数量;FP表示模型预测为正实际为负的样本数量。
试验结果表明:
1)对于TP数目而言,其值越高,模型越优。由图6可见加入注意力机制的3种子模型其值相差不是很大,但3种子模型预测TP指标值均高于未加入注意力信息的Tiny-YOLO模型。加入注意力信息的3种子模型对6种脸部姿态类别的TP总数目排序依次是DAT-YOLO> SAT-YOLO>CAT-YOLO,可见同时加入2种注意力对生猪脸部姿态检测的预测效果最佳。对于单一姿态类别,加入注意力的3种子模型TP值呈现出不同特点,对差异最大的低头侧脸和抬头侧脸类别,SAT-YOLO的低头侧脸TP数目比CAT-YOLO多19个,DAT-YOLO的抬头侧脸TP值比CAT-YOLO多19个。
2)对于FP数值而言,其值越低,模型效果越佳。4种子模型预测结果值排序依次为DAT-YOLO< SAT-YOLO 图7为Tiny-YOLO系列模型4种子模型对生猪6种脸部姿态识别的-曲线图。由式(6)、式(7)可知,Precision与Recall值的获取需要首先计算TP、FP以及FN的个数,每种子模型对不同种类的预测结果TP、FP值可见图6所示。对于FN数值,图像中某一类别的真实框数量是已知的,TP数量可从4.1部分求出,两者差值即为FN结果值。每个类别中-曲线下方面积即为表3中对应模型在该类别上的AP值,曲线越靠近右上角,模型效果越优。 从图7中可看出,加入注意力机制后的3种子模型-曲线均位于未加注意力信息的Tiny-YOLO模型上方,这是因为Tiny-YOLO检测模型所提取的卷积特征并未对卷积核中不同位置处特征进行区别对待,认为每个区域对检测结果贡献度相同,但实际中,待检测物体周围往往具有复杂且丰富的语境信息,对目标区域特征施以权重可使模型更好地定位至待检测特征上,说明注意力信息有利于对群养生猪脸部姿态进行检测。对于单独引入1种注意力机制的情况,SAT-YOLO子模型在除抬头正脸类别外的其余类别上其曲线均位于CAT-YOLO子模型上方,说明与通道注意力相比,空间注意力对区域检测效果更为明显。此外,4种子模型对低头正脸、抬头正脸、抬头侧脸3个姿态类别的Recall值小于0.1时,Precision值均维持在1.0附近,差异不大,但随着Recall值的减小,DAT-YOLO子模型优势逐渐明显,其对应Precision值均不逊于其余3种子模型,并在抬头正脸、抬头侧脸2个类别上优势最为明显。虽然DAT-YOLO子模型对水平正脸、水平侧脸、低头侧脸类别的表现并不突出,但其对应类别曲线状态均不弱于其余子模型,说明在同时加入2种注意力的情况下可最大限度提升模型性能,能充分融合通道注意力和空间注意力优势。 为进一步展示模型预测效果,在测试集上对Tiny-YOLO系列模型4种子模型进行预测,选取其中3幅可视化结果如图8所示。其中每行所表示子模型类别见图左侧注释所示,预测结果中预测框左上角部分显示值表示预测为当前姿态类别的置信度。 图8 部分测试集预测结果 由图8可知,对于8a对应图像,4种子模型均能正确预测出生猪脸部姿态类别及其位置,其中DAT-YOLO子模型能够取得最佳的类别置信度。对于8b对应的图像,Tiny-YOLO、SAT-YOLO和DAT-YOLO3种子模型均能对生猪脸部较小或者不明显区域做出正确预测,且DAT-YOLO预测置信度最高,且除DAT-YOLO子模型外,其余3种子模型在预测过程中均有预测错误的情形出现,表明DAT-YOLO子模型在小目标脸部姿态检测的可用性。8c对应图像,小猪较为密集黏连,4种子模型虽然均有预测错误的情况出现,但对于预测正确的情况,DAT-YOLO子模型预测结果最接近真实框。 本研究中6种脸部姿态的数量差异会产生数据不均衡问题,理论上可从数据和损失函数2种角度解决该问题[38-39]。结合文中模型的适用场景,本文采用损失函数对数据进行伪均衡化处理,采用与Redmon等[18]一致的损失函数,其形式化表示如公式(10)所示。 由表3可知,模型对不同类别姿态检测精度差异较大,该问题属于深度学习可解释性研究的最前沿领域,最新研究主要集中于对卷积核与图像特征点部位间关系的探讨[40-42]。模型的不同层次可用于提取不同特征,每层卷积核与图像的特定特征相关联,并具有一定的通用性,浅层卷积核可提取纹理、边缘等特征,深层卷积核可提取抽象特征,暂无文献研究表明提取的特定特征与最终检测精度间的定量关系,对于某些脸部姿态类别,在特征提取过程中,模型所关注区域不同,暂时无法从理论上解释模型各层卷积核学习的特征对特定脸部姿态检测类别的贡献程度。 图5中DAT-YOLO模型除注意力模块外的其余特征图数目选取均与图2中Tiny-YOLO模型均保持一致,对通道与空间注意力特征图数量的选取原则是基于经验的直观准则及约定俗成的默认设置(取2的整数次幂),目前尚无严密且令人信服的数学解释,对该部分探索性的研究集中于神经网络架构搜索(neural architecture search, NAS)[43],其可用于自动搜索最优卷积核大小及特征图数量。本研究更关注于不同注意力信息对检测效果的影响程度,故未将其列入研究范畴。 本文在Tiny-YOLO模型中引入通道注意力和空间注意力,对Tiny-YOLO模型进行了改进,建立检测模型DAT-YOLO,用于群养场景下生猪不同脸部姿态检测,主要结论如下: 1)与YOLOV3系列模型相比,Tiny-YOLO系列模型具有更强检测性能,且在加入注意力信息后,2类系列模型检测精度均有不同程度提升。 2)Tiny-YOLO系列模型中,引入注意力机制的CAT-YOLO、SAT-YOLO和DAT-YOLO 3种子模型的mAP值相较于未引入注意力机制的Tiny-YOLO模型分别提高了3.73%、5.44%和8.39%,表明注意力机制对生猪脸部姿态检测的有效性,可很大程度提升通用卷积网络的特征提取能力。 3)SAT-YOLO检测效果总体优于CAT-YOLO。其在低头侧脸类别上优势最为明显,相较于CAT-YOLO子模型,其检测精度提高6.90%。表明空间注意力信息更适用于生猪脸部姿态检测。 4)同时引入2种注意力的DAT-YOLO子模型无论在各个类别的检测精度、所有类别的平均检测精度、FP/TP指标值以及-曲线中,效果均优于CAT-YOLO和SAT-YOLO模型,表明同时引入2种注意力信息对生猪脸部姿态检测效果更佳,可为生猪脸部姿态检测提供方法和思路,为群养生猪个体识别提供有益参考。 [1] 孙龙清,李玥,邹远炳,等. 基于改进Graph Cut算法的生猪图像分割方法[J]. 农业工程学报,2017,33(16):196-202. Sun Longqing, Li Yue, Zou Yuanbing, et al. Pig image segmentation method based on improved Graph Cut algorithm[J]. Transactions of the Chinese Society of Agricultural Engineering (Transactions of the CSAE), 2017, 33(16): 196-202. (in Chinese with English abstract) [2] 邹远炳,孙龙清,李玥,等. 基于分布式流式计算的生猪养殖视频监测分析系统[J]. 农业机械学报,2017,48(S):365-373. Zou Yuanbing, Sun Longqing, Li Yue, et al. Video monitoring and analysis system for pig breeding based on distributed flow Computing[J]. Transactions of the Chinese Society for Agricultural Machinery, 2017, 48(S): 365-373. (in Chinese with English abstract) [3] 薛月菊,朱勋沐,郑婵,等. 基于改进 Faster R-CNN 识别深度视频图像哺乳母猪姿态[J]. 农业工程学报,2018,34(9):189-196. Xue Yueju, Zhu Xunmu, Zheng Chan, et al. Lactating sow postures recognition from depth image of videos based on improved Faster R-CNN[J]. Transactions of the Chinese Society of Agricultural Engineering (Transactions of the CSAE), 2018, 34(9): 189-196. (in Chinese with English abstract) [4] 胡志伟,杨华,娄甜田,等. 基于全卷积网络的生猪轮廓提取[J]. 华南农业大学学报,2018,39(6):111-119. Hu Zhiwei, Yang Hua, Lou Tiantian, et al. Extraction of pig contour based on fully convolutional networks[J]. Journal of South China Agricultural University, 2018, 39(6): 111-119. (in Chinese with English abstract) [5] 杨阿庆,薛月菊,黄华盛,等. 基于全卷积网络的哺乳母猪图像分割[J]. 农业工程学报,2017,33(23):219-225. Yang Aqing, Xue Yueju, Huang Huasheng, et al. Lactating sow image segmentation based on fully convolutional networks[J]. Transactions of the Chinese Society of Agricultural Engineering (Transactions of the CSAE), 2017, 33(23): 219-225. (in Chinese with English abstract) [6] Yang Aqing, Huang Huasheng, Zheng Chan, et al. High-accuracy image segmentation for lactating sows using a fully convolutional network[J]. Biosystems Engineering, 2018, 176: 36-47. [7] Psota E, Mittek M, Pérez L, et al. Multi-pig part detection and association with a fully-convolutional network[J]. Sensors, 2019, 19(4): 852. [8] Wang Jianzong, Liu Aozhi, Xiao Jing. Video-Based Pig Recognition with Feature-Integrated Transfer Learning[C]// Biometric Recognition, 2018: 620-631. [9] Chen Zuge, Wu Kehe, Li Yuanbo, et al. SSD-MSN: An improved multi-scale object detection network based on SSD[J]. IEEE Access, 2019, 7: 80622-80632. [10] GhiasiG, Lin T Y, Le Q V. Nas-fpn: Learning scalable feature pyramid architecture for object detection[C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR). IEEE Computer Society: Piscataway, NJ. 2019: 7036-7045. [11] Law H, Deng J. Cornernet: Detecting objects as paired keypoints[C]//Proceedings of the European Conference on Computer Vision (ECCV). Cham:SpringerInternational Publishing, 2018: 734-750. [12] Lin T Y, Dollár P, Girshick R, et al. Feature pyramid networks for object detection[C]//Proceedings of the IEEE conference on computer vision and pattern recognition (CVPR). IEEE Computer Society: Piscataway, NJ. 2017: 2117-2125. [13] Liu W, Anguelov D, Erhan D, et al. Ssd: Single shot multibox detector[C]//European conference on computer vision(CVPR). IEEE Computer Society: Piscataway, NJ. 2016: 21-37. [14] Girshick R, Donahue J, Darrell T, et al. Rich feature hierarchies for accurate object detection and semantic segmentation[J]. Computer Science, 2013: 580-587. [15] Ren S, He K, Girshick R, et al. Faster R-CNN: Towards real-time object detection with region proposal networks[J]. IEEE Transactions on Pattern Analysis & Machine Intelligence, 2015, 39(6): 1137-1149. [16] Redmon J, Divvala S, Girshick R, et al. You only look once: Unified, real-time object detection[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition(CVPR). IEEE Computer Society: Piscataway, NJ. 2016: 779-788. [17] Redmon J, Farhadi A. YOLO9000: Better, Faster, Stronger[C]// 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). IEEE Computer Society: Piscataway, NJ. 2017: 6517-6525. [18] Redmon J, Farhadi A. Yolov3: An incremental improvement[J/OL]. [2019-07-10]. USA: 2018. https://arxiv.org/abs/1804.02767 [19] Pedoeem J, Huang R. YOLO-LITE: A real-time object fetection algorithm optimized for non-GPU computers[J/OL]. [2019-07-10]. USA: 2018. https://arxiv.org/abs/1811.05588 [20] 薛月菊,黄宁,涂淑琴,等. 未成熟芒果的改进 YOLOv2识别方法[J]. 农业工程学报,2018,34(7):173-179. Xue Yueju, Huang Ning, Tu Shuqin, et al. Immature mango detection based on improved YOLOv2[J]. Transactions of the Chinese Society of Agricultural Engineering (Transactions of the CSAE), 2018, 34(7): 173-179. (in Chinese with English abstract) [21] 赵德安,吴任迪,刘晓洋,等. 基于YOLO 深度卷积神经网络的复杂背景下机器人采摘苹果定位[J]. 农业工程学报,2019,35(3):164-173. Zhao Dean, Wu Rendi, Liu Xiaoyang, et al. Apple positioning based on YOLO deep convolutional neural network for picking robot in complex background[J]. Transactions of the Chinese Society of Agricultural Engineering (Transactions of the CSAE), 2019, 35(3): 164-173. (in Chinese with English abstract) [22] Ju M, Choi Y, Seo J, et al. A kinect-based segmentation of touching-pigs for real-time monitoring[J]. Sensors, 2018, 18(6): 1746. [23] Wang Fei, Jiang Mengqing, Qian Chen, et al. Residual Attention Network for Image Classification[C]//2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). IEEE Computer Society: Piscataway, NJ. 2017: 3156-3164. [24] Yu Changqian, Wang Jingbo, Peng Chao, et al. BiSeNet: Bilateral segmentation network for real-time semantic segmentation[C]//Proceedings of the European Conference on Computer Vision (ECCV). Cham:SpringerInternational Publishing, 2018: 325-341. [25] 徐诚极,王晓峰,杨亚东. Attention-YOLO:引入注意力机制的YOLO检测算法.计算机工程与应用[J],2019,55(6):13-23. Xu Chengji, Wang Xiaofeng, Yang Yadong. Attention-YOLO: YOLO detection algorithm that introduces attention mechanism[J]. Computer Engineering and Applications, 2019, 55(6): 13-23. (in Chinese with English abstract) [26] TzuTa L. LabelImg [CP/DK]. (2017-01-09) [2019-06-20] https:// github.com/tzutalin/labelImg [27] Raykar V C, Saha A. Data Split Strategies for Evolving Predictive Models[C]//Machine Learning and Knowledge Discovery in Databases. 2015: 3-19. [28] Long Jonathan, Shelhamer Evan, Darrell Trevor. Fully convolutional networks for semantic segmentation[J]. IEEE Transactions on Pattern Analysis & Machine Intelligence, 2014, 39(4): 640-651. [29] 刘军,后士浩,张凯,等. 基于增强Tiny YOLOV3算法的车辆实时检测与跟踪[J]. 农业工程学报,2019,35(8):118-125. Liu Jun, Hou Shihao, Zhang Kai, et al. Real-time vehicle detection and tracking based on enhanced Tiny YOLOV3 algorithm[J]. Transactions of the Chinese Society of Agricultural Engineering (Transactions of the CSAE), 2019, 35(8): 118-125. (in Chinese with English abstract) [30] Neubeck A, Van Gool L. Efficient non-maximum suppression[C]//18th International Conference on Pattern Recognition (ICPR). Springer: Berlin, German. 2006, 3: 850-855. [31] Lin Min, Chen Qiang, Yan Shuicheng. Network in network[J/OL]. [2019-07-20]. USA: 2014. https://arxiv.org/ abs/1312.4400 [32] Zhou Bolei, Khosla A, Lapedriza A, et al. Learning deep features for discriminative localization[C]//In: Computer Vision and Pattern Recognition (CVPR), IEEE Computer Society: Piscataway, NJ. 2016: 2921-2929. [33] Chollet F. Keras[CP/DK]. (2015-03-28)[2019-07-05]. https://github.com/keras-team/keras/ [34] Kingma D P, Ba J. Adam: A method for stochastic optimization[J/OL]. [2019-07-20]. https://arxiv.org/ abs/1412.6980 [35] Ioffe S, Szegedy C. Batch normalization: Accelerating deep network training by reducing internal covariate shift[C]// International Conference on Machine Learning(ICML). 2015: 448-456. [36] Microsoft. PASCAL-VOC2012 [DB/OL]. (2012-02-20) [2019-08-02]. http://host.robots.ox.ac.uk/pascal/VOC/voc2012 [37] Rezatofighi H, Tsoi N, Gwak J Y, et al. Generalized intersection over union: A metric and a loss for bounding box regression[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, IEEE Computer Society: Piscataway, NJ. 2019: 658-666. [38] Lin T Y, Goyal P, Girshick R, et al. Focal loss for dense object detection[C]//Proceedings of the IEEE International Conference on Computer Vision. 2017: 2980-2988. [39] Li B, Liu Y, Wang X. Gradient harmonized single-stage detector[C]//Proceedings of the AAAI Conference on Artificial Intelligence. 2019, 33: 8577-8584. [40] Zhang Quanshi, Wu Yingnian, Zhu Songchun. Interpretable Convolutional Neural Networks[C]// The IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2018: 8827-8836. [41] Zhang Quanshi, Yang Yu, Ma Haotian, et al. Interpreting CNNs via Decision Trees[C]// The IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2019: 6261-6270. [42] Bolei Zhou, David Bau, Aude Oliva, et al. Interpreting deep visual representations via network dissection[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2019, 41(9): 2131-2145. [43] Jin H, Song Q, Hu X. Auto-keras: An efficient neural architecture search system[C]//Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, ACM, 2019: 1946-1956. Detection of facial gestures of group pigs based on improved Tiny-YOLO Yan Hongwen1, Liu Zhenyu1, Cui Qingliang2※, Hu Zhiwei1, Li Yanwen1 (1.,,030801,; 2.,,030801) The face of the pig contains rich biometric information, and the detection of the facial gestures can provide a basis for the individual identification and behavior analysis of the pig. Detection of facial posture can provide basis for individual recognition and behavioral analysis of pigs. However, under the scene of group pigs breeding, there always have many factors, such as pig house lighting and pig adhesion, which brings great challenges to the detection of pig face. In this paper, we take the group raising pigs in the real breeding scene as the research object, and the video frame data is used as the data source. Latter we propose a new detection algorithm named DAT-YOLO which based on the attention mechanism and Tiny-YOLO model, and channel attention and spatial attention information are introduced into the feature extraction process. High-order features guide low-order features for channel attention information acquisition, and low-order features in turn guide high-order features for spatial attention screening, meanwhile the model parameters don’t have significant increase, the model feature extraction ability is improved and the detection accuracy is improved. We collect 504 sheets total 3 712 face area picture for the 5 groups of 20 days to 3 and a half months of group health pig video extraction, the number of pigs is 35. In order to obtain the model input data set, we perform a two-step pre-processing operation of filling pixel values and scaling for the captured video. The model outputs are divided into six classes, which are horizontal face, horizontal side-face, bow face, bow side-face, rise face and rise side-face.The results show that for the test set, the detection precision(AP)reaches 85.54%, 79.3%, 89.61%, 76.12%, 79.37%, 84.35% of the horizontal face, horizontal side-face, bow face, bow side-face, rise face and rise side-face respectively, and the mean detection precision(mAP) is 8.39%, 4.66% and 2.95% higher than that of the general Tiny-YOLO model, the CAT-YOLO model only refers to channel attention and the SAT-YOLO model only introduces spatial attention respectively. In order to further verify the migration performance of attention on the remaining models, under the same experimental conditions, two attentional information were introduced to construct the corresponding attention sub-models based on the YOLOV3-based model. The experiment shows that compared to the YOLOV3 submodel, the sub-model based on Tiny-YOLO increase by 0.46% to 1.92% in the mAP. The Tiny-YOLO and YOLOV3 series models have different performance improvements after adding attention information, indicating that the attention mechanism is beneficial to the accurate and effective group gestures detection of different groups of pigs. In this study, the data is pseudo-equalized from the perspective of loss function to avoid the data imbalance caused by the number of poses of different facial categories, and actively explore the reasons for the difference in the accuracy of different facial gesture detection. The study can provide reference for the subsequent individual identification and behavior analysis of pigs. image processing; models; object detection; Tiny-YOLO; channel attention; spatial attention 燕红文,刘振宇,崔清亮,胡志伟,李艳文. 基于改进Tiny-YOLO模型的群养生猪脸部姿态检测[J]. 农业工程学报,2019,35(18):169-179.doi:10.11975/j.issn.1002-6819.2019.18.021 http://www.tcsae.org Yan Hongwen, Liu Zhenyu, Cui Qingliang, Hu Zhiwei, Li Yanwen. Detection of facial gestures of group pigs based on improved Tiny-YOLO[J]. Transactions of the Chinese Society of Agricultural Engineering (Transactions of the CSAE), 2019, 35(18): 169-179. (in Chinese with English abstract) doi:10.11975/j.issn.1002-6819.2019.18.021 http://www.tcsae.org 2019-08-16 2019-08-28 国家高技术研究发展计划(863计划)资助项目(2013AA102306);国家自然基金面上项目资助(31772651);山西省重点研发计划专项(农业)(201803D221028-7) 燕红文,博士生,主要研究方向为农产品加工新技术及装备、计算机视觉技术。Email: yhwhxh@126.com 崔清亮,教授,博导,主要从事旱作农业机械化关键技术与装备的研究。Email: qlcui@126.com 10.11975/j.issn.1002-6819.2019.18.021 TP391 A 1002-6819(2019)-18-0169-114.3 模型精确率-召回率曲线分析
4.4 模型预测结果分析

5 讨 论
5.1 数据不均衡问题处理
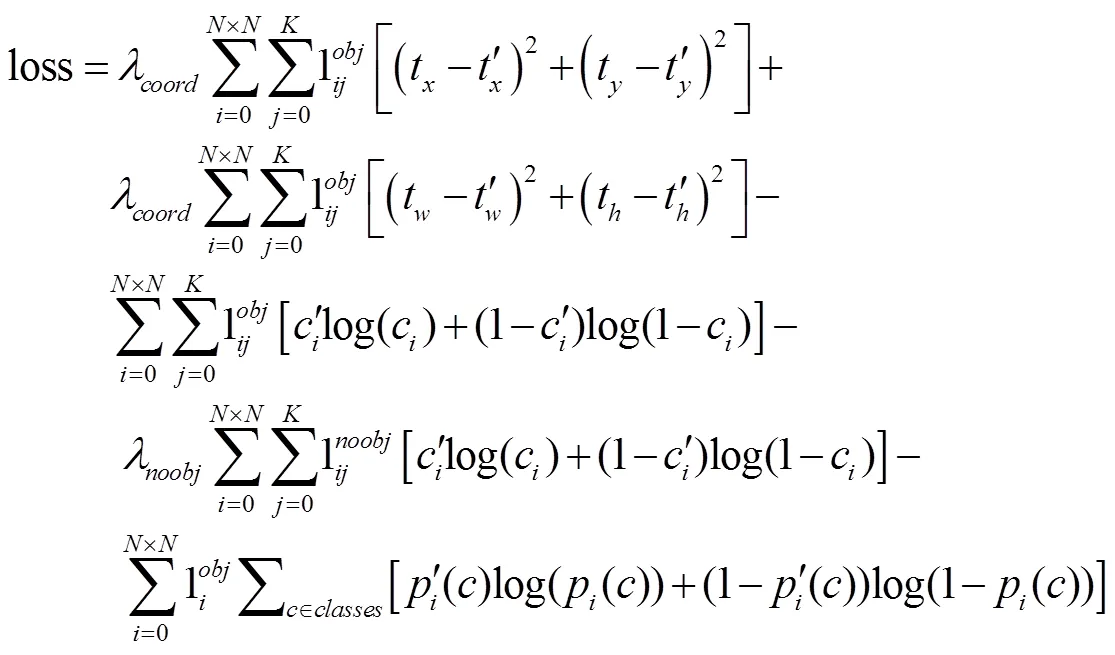
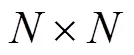
5.2 不同姿态检测精度差异研究
5.3 注意力特征图数量取值原则
6 结 论
猜你喜欢
学生天地(2020年3期)2020-08-25 09:04:16
汽车观察(2018年9期)2018-10-23 05:46:40
中国自行车(2018年8期)2018-09-26 06:53:44
新校长(2016年8期)2016-01-10 06:43:59
商事法论集(2014年1期)2014-06-27 01:20:42
中国中医药现代远程教育(2014年16期)2014-03-01 04:28:46
世界科学(2014年4期)2014-02-28 14:58:24
医学美学美容(2013年5期)2013-04-29 00:44:03
食品科学(2013年8期)2013-03-11 18:21:31
长江大学学报(自科版)(2013年33期)2013-03-11 15:08:24
