
利用深度学习技术构建药品包装识别系统方法研究
2019-11-01 11:04施华宇刘敏超辛海莉张震江
中国医院 2019年10期
施华宇 刘敏超 辛海莉 李 闯 张震江
近几年随着硬件计算力的提高、机器学习算法技术的改进以及大数据技术的深入发展,越来越多的人工智能技术成果开始在医学影像诊断、药物研发、精准医疗等临床医疗领域有所应用。因此,为人工智能产品构建标准、可靠、高效的研发及运营平台,将成为今后医院信息化建设中的一部分工作内容[1]。本文将解放军总医院(以下简称“我院”)自主研发的基于深度学习技术的药品包装识别系统作为开发案例[2],阐述深度学习系统所需的基础环境,以及训练、推理、开发管理三类平台的相关技术与方法。
1 药品包装识别系统及其工作原理
药品包装识别系统的工作流程:窗口药师在向患者发放药品时,会在工作台上对药品进行清点,这时工作台上方的摄像头自动对药品包装图像进行采集,并对药品图像使用深度学习技术中的卷积神经网络模型(convolutional neural network,CNN)进行推理识别,识别出的药品信息会与电子处方进行核对,在发现品种或数量出现错误时,系统将对药师发出预警。此系统可辅助药师及时发现人工配剂过程中所发生的差错,避免因配剂错误所带来的医患纠纷,其工作原理见图1。
首先,药师使用药品图像采集系统对门诊药房中的各个药品进行拍摄和分类,并将药品图像作为数据集,药品信息作为标签集放入训练平台中的CNN神经网络进行反复训练,生成识别准确率高、可应用于实际业务中的神经网络模型。
其次,神经网络模型被部署到推理平台上。当推理平台接收到客户端实时拍摄到的药品图像后,会调用神经网络模型对药品图像进行推理识别,并将识别到的药品信息返回给客户端。
最后,开发管理平台则利用远程开发技术在训练和推理平台开发和调试深度学习模型代码,并对平台中服务器进行系统配置与软件安装。
2 深度学习系统的基础环境
2.1 操作系统的选择
从资源利用率、系统的稳定性与安全性考虑,推荐使用CentOS作为训练平台的操作系统[3]。CentOS使用纯命令行的方式进行交互,虽然有一定的学习成本,但却没有因图形交互界面所带来的系统资源消耗。并且CentOS作为主流Linux的服务器版本一直以稳定性闻名,可长时间运行多个任务而不出现系统崩溃。Linux系统的安全性更为出色,鲜有针对其进行攻击的病毒程序。
2.2 开发语言与开发框架的选择
Python是当前热门的面向对象的解释型程序设计语言,以其简洁、易用、高效的特点,已广泛应用于人工智能、大数据分析、网站开发等重要领域,积累了大量成熟度高、功能强大的开发资源。
Tensorflow是Google公司发布的专门针对机器学习领域的经典开发框架。通过Tensorflow强大的数据流图功能可实现各类复杂的神经网络模型。
Keras是以Tensorflow为后端,高度模块化的神经网络开发框架,通过序列化的方式帮助开发者快速搭建神经网络架构,有效简化了神经网络模型的构建过程。Keras现在已集成在2019年下半年发布的Tensorflow2.0中,以弥补Tensorflow1.X在易用性上的不足。
2.3 软件环境的安装
如服务器具备连接互联网条件,软件环境可使用Anaconda或yum进行在线安装,各种开发包及其依赖包的下载、配置及安装基本上是自动化的方式完成,可在很短的时间内快速构建深度学习所需的训练及推理平台。
如在局域网条件下,可从Python官方的第三方开发包仓库(Pypi)网站上下载离线开发包及其依赖包文件,并通过PIP命令进行安装。此方法虽然较为耗时,但仍可顺利完成构建任务。
2.4 神经网格模型与运行环境
药品包装识别系统现阶段使用LeNet模型对药品图像进行特征提取及分类识别。其他CNN模型还包括MobileNet、Inception、ResNet、VGG等,这些CNN开源神经网格模型代码都是由各个著名的开源组织维护与发布。此外,运行CNN神经网络模型还需要服务器具备一定的浮点运算力,最好是在配置GPU的环境下进行训练与推理。若在只有CPU的环境,虽可正常执行训练及推理功能,但需要很长的运行时间。

图1 药品包装识别系统工作原理
3 训练平台
3.1 模型超参优化
超参是指在神经网络模型中直接影响训练准确度的重要参数,包括学习率、激活函数、损失函数、优化函数、训练次数、正则化函数、每批次训练的样本数等。超参的优化与调整也被称为调参,是提高模型识别准确度的重要手段。
调参是深度学习系统开发过程中最为繁琐耗时的工作,开发人员需要反复调整参数并训练模型,直到训练后的模型准确率达到要求的标准。因此产生了许多调参优化方法,包括表格搜索法、随机参数法、贝叶斯优化法等,可以帮助开发人员在节省训练时间的同时找到合适的参数配置。
3.2 早停法与保存最优模型
早停法是指当每次训练完成后,如发现准确率已持续下降了一定次数的情况,系统将自动停止训练过程。因为在训练神经网络模型过程中过多的训练次数并不能提高模型识别的准确率,在实际情况中当模型训练到一定次数后,基本会进入过拟合状态,准确率一般会出现持续下降的情况(图2),所以使用早停法可以避免无效的训练过程。
同样因为过拟合的原因,最后一次训练出的模型未必是最优状态下的模型。因此,当每次训练完成后在程序中判断此次训练的验证准确率是否是历次训练中最高的,如果是则将当前模型中的结构及权重值输出为神经网络模型文件并保存到硬盘上。
3.3 训练过程可视化
为更好地观察训练的运行状况,可在训练程序中加入TensorBoard可视化工具。TensorBoard可根据每次训练所产生的数据生成日志,通过解析日志数据生成可视化的Web页面,帮助开发人员实时观察训练状态、计算图结构、变量直方图等重要运行数据。
4 推理平台
推理平台根据其部署模式分为以推理服务器为中心的Web服务模式,以及在终端使用嵌入式设备的边缘计算模式。
4.1 Web服务模式
Web服务模式是现阶段药品包装识别系统所使用的部署模式,主要流程如下:首先将训练好的神经网络模型文件部署到推理服务器上,再通过Python语言使用Flask网络应用框架编写RESTFul网络服务接口。当业务终端需要推理服务时,将药品图像数据打包成标准的Http协议报文,并通过RESTFul网络服务接口上传至推理服务器,推理服务器调用神经网络模型对药品图像进行推理预测,最后将推理到的药品信息数据以JSON格式返回业务终端。
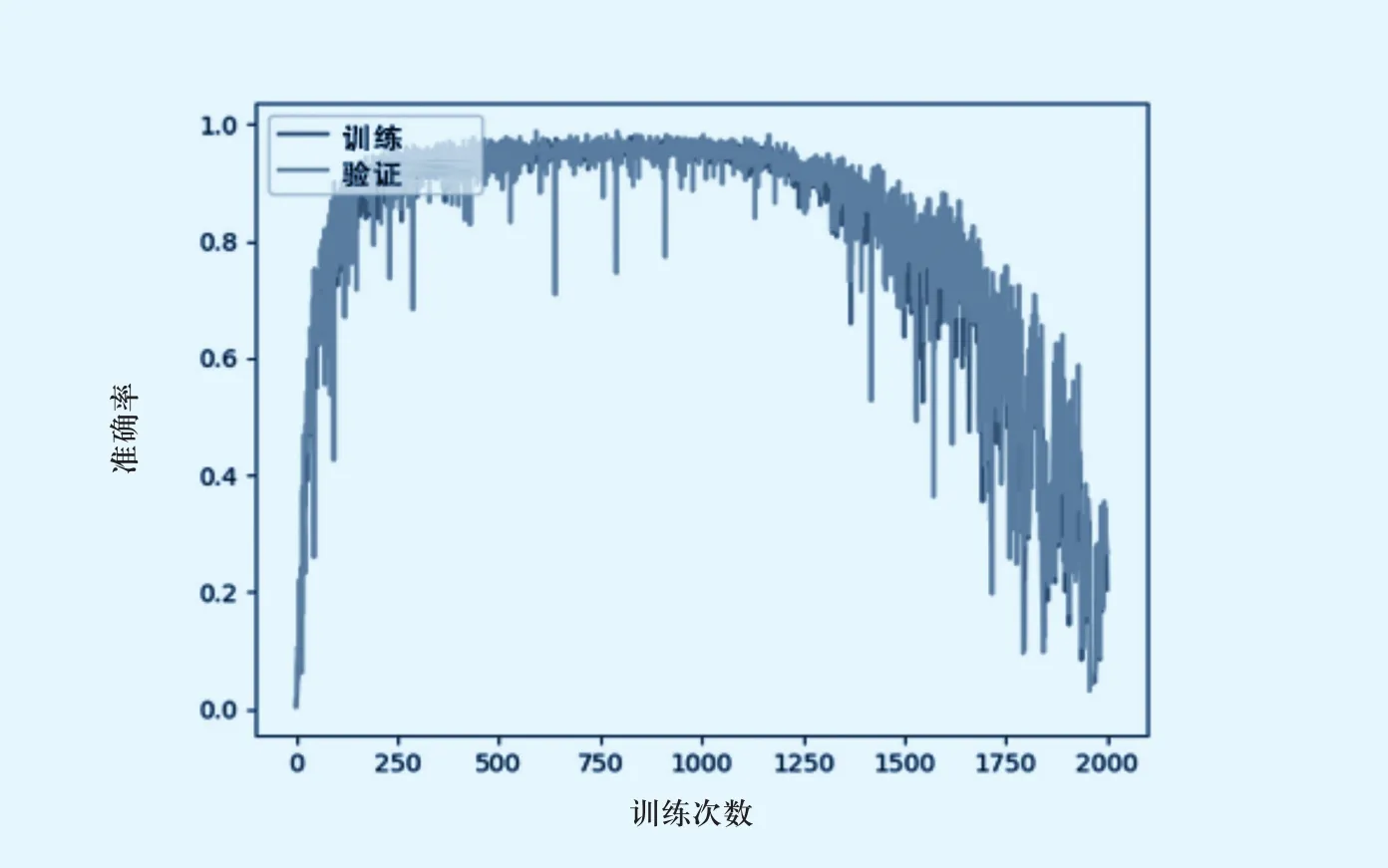
图2 训练神经网络模型时生成的准确率趋势图
Web服务模式以推理服务器为中心,将深度学习的推理过程转换为网络的服务接口,其他业务系统都可通过调用RESTFul接口的方式调用推理过程。此模式技术成熟、部署简单快捷、具备可复用性,是现今主流的部署模式。但此模式对推理服务器要求性能很高,尤其使用Inception、VGG这类层级很高的模型或出现高并发请求时,会出现大量的系统消耗,如服务器不具备相应的运算资源,将会导致系统响应时间被拖延至几秒甚至几十秒,严重影响用户体验。
4.2 边缘计算模式
边缘计算技术的主要目的是去中心化,将处理过程从服务器端交由本地终端的边缘计算层来处理。而在深度学习系统中的边缘计算层的功能是由专门集成高速运算器的嵌入式设备来完成[4]。此类嵌入式设备现阶段典型的有Intel神经网格计算棒,以及Google公司的TPU开发板。
Intel神经网格计算棒是通过USB接口连接到终端计算机上,使用OpenVINO技术在客户端就可加速神经网络模型的推理操作。
Google公司的TPU开发板实际上是集成了CPU、GPU、TPU 3种高速运算器,专门为处理深度学习业务设计的微型嵌入式Linux计算机。TPU开发板可通过USB接口直接调用摄像头采集图片,再调用经Tensorflow lite转化过的神经网络模型对图片推理,最后将推理结果以有线的USB OTG(On-The-Go)模式,或无线的Wifi模式传送到客户端。
以上两种边缘计算方式,设备成本较GPU服务器要低廉很多,其中最贵的TPU开发板也不过1000余元,而且是按需配置,有多少终端就配置几个设备即可,可有效节省设备成本。但边缘计算技术推出的时间尚短,Intel神经网格计算棒于2018年上市,而TPU开发板更是在2019年3月才正式发售,性能及可靠性方面还有待验证。但边缘计算技术以成本小、配置灵活、响应快、无需网络连接的优势,有着非常高的实用价值,具备非常好的发展前景。
5 开发管理平台
药品包装识别系统使用PyCharm作为开发管理平台。PyCharm是由JetBrains公司研发的Python语言开发工具,使用PyCharm的远程开发功能并不需要在开发端安装Python环境,直接使用Deployment(部署)功能即可通过SFTP协议将本地的Python开发项目同步到服务器上。同时自动下载服务器已安装的Python开发包信息,在开发端生成本地的代码导航,方便开发人员进行编码工作,提高开发效率。使用PyCharm也可在开发端远程调试服务器上的Python代码,服务器产生的调试信息会自动反馈到开发端,效果与在开发端进行本地调试基本一致。PyCharm除开发功能外,也支持标准的SSH会话功能,帮助开发人员通过SSH协议连接到服务器进行系统配置与软件的安装。
6 结语
现在对药品包装识别系统的研发已进入完善阶段,训练平台已对500种药品进行了图像采集与模型训练,训练时验证准确度已达到96.4%。但要将此系统实际应用到业务中,还需要实现对门诊药房1600多种药品的识别能力,这需要对现有神经网络模型进行更深层次的改造。推理平台方面Web服务模式现已部署完成,边缘计算模式中的TPU开发板也已调通,等改造CNN模型工作完成后就可进行对比实验,决定最终的部署模式。
训练、推理、开发管理这三类平台的应用并不仅局限在此项目中,对其他CNN网络或长短期记忆网络等深度学习系统的研发都有一定的借鉴价值[5]。
猜你喜欢
中国合理用药探索(2022年1期)2022-11-26
世界最新医学信息文摘(2021年12期)2021-06-09
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
农业科技与信息(2021年2期)2021-03-27
健康体检与管理(2021年10期)2021-01-03
网络安全和信息化(2020年9期)2020-12-31
网络安全和信息化(2020年7期)2020-08-07
网络安全和信息化(2019年8期)2019-08-28
小学生优秀作文(低年级)(2018年6期)2018-05-19
