
基于机器视觉的茶叶品质自动检测方法研究
2019-10-28 05:24郑晓玲
通化师范学院学报 2019年10期
郑晓玲
福建泉州安溪县系“中国乌龙茶之乡”,茶产业已经成为区域经济的一个重要特色产业.茶叶品质的分类可以让不同的客户类型根据他们自己的喜好以及经济条件选择相应的茶品类,因此它在茶叶市场中有着非常重要的作用.目前在茶产业中,茶品质检测主要是由“品茶者”通过视觉、嗅觉和味觉感官来进行的,这种方法会受到“品茶者”心理(如心理状态)、生理(如年龄、性别等)因素的影响,因此,检测结果是主观的,有时会产生不可靠的结果[1].仪器分析方法检测茶叶品质[2]准确、可靠、可重复性好,但是设备昂贵,操作繁琐,设备生产时间长.因此寻找一种低成本、客观的茶叶品质自动检测方法尤为重要.
计算机视觉系统以其成本效益高、一致性好、速度快、精度高等优点,在质量检测领域有广泛应用.在茶叶的质量检测方面,GAGANDEEP S G等[3]概述各种基于计算机视觉的颜色和纹理分析算法,对茶叶的监控和分级进行介绍.ARVIND K等[4]提出一种基于直方图颜色匹配技术的基于L*a*b*颜色模型的茶饮料图像分析系统.HSIAO H Y等[5]利用机器视觉技术来定量评价茶叶的外观品质,探讨不同的光源对视觉系统检测结果的影响.马建红等[6]提出多智能体的茶叶图像等级鉴定技术,可对茶叶模糊图像等级有效鉴定.目前对茶叶品质分类的研究主要集中在对不同种类名优茶的分类,对同种茶叶的系统研究较少.因此,本文提出利用机器视觉技术自动检测同品种茶叶品质的新方法.
1 茶叶样品图像获取
茶叶样品图像的采集系统由光箱、CCD相机、LED灯构成,实验所用光源为维视数字图像技术有限公司的LED环形光源,垂直照射在待测茶叶样品上,光源距离测试样品高25 cm,茶叶样品图像由分辨率为1 300像素×1 024像素的摄像头采集,采用USB 2.0接口,终端数据处理单元为华硕计算机,处理器操作系统为Window 2010,采集的茶叶彩色图像由Matlab 2017a软件进行处理分析,采集系统如图1所示.

图1 茶叶图像采集系统
2 图像特征提取
2.1 颜色特征
颜色特征对图像来说是一种很重要的视觉特征,是人识别图像最直观的感知特征之一.HSI是由MUNSEU H A在1915年提出的一种颜色模型,该模型采用H、S和I三种基本特征量描述颜色.常见的描述颜色的RBG模型中的R、G和B分别代表图像中的红色、绿色和蓝色分量值[7],HSI与RGB颜色模型对比的优点主要在于:RGB颜色模型容易受环境光线变化的影响,HSI颜色模型基本上不受环境光线变化的影响,更与人的视觉对颜色的感知相近似[8].本文将采集到的以RGB形式表征的茶叶原始图像转换到HSI空间,计算图像H分量、S分量、I分量的平均值和方差.因样本数量较大,本文无法罗列出所有特征值,故只列出特征值的数值分布范围如表1所示.可以看出,茶叶样品良品与次品的颜色特征分布范围有一定的差异性,尤其是S分量平均值、H分量方差、I分量方差,良品与次品的特征值分布在无交集的数值区间内.
2.2 纹理特征
纹理特征在自然图像中广泛存在,其能够给人以明确的视觉效果,但由于纹理的复杂性,很难对其进行准确的描述.20世纪60年代,JULESZ等对纹理特征展开系统的研究[9].灰度共生矩阵方法是建立在估计图像的二阶组合条件概率密度函数基础上的一种纹理特征分析方法.本文根据茶叶样本图像的纹理特点,选取灰度共生矩中的能量、对比度、同质性、相关性等4个特征用以提取茶叶图像的纹理特征,然后利用Matlab 2017a分别提取每幅茶样图像能量、惯性矩、同质性和相关性的4个方向上(0°,45°,90°,135°)共计16个纹理特征参数.提取的特征值分布范围如表2所示.可以看出,茶叶样品良品与次品图像的纹理特征分布范围有一定的差异性,可将纹理特征作为自动检测茶叶品质的特征.

表1 茶叶外形图像的颜色特征变量值的分布范围

表2 茶叶外形图像的纹理特征变量值的分布范围
3 特征降维
主成分分析法是统计学中进行数据分析的一种有效方法,利用统计方差,去除统计变量之间的相关性,使数据得到降维和压缩,并保留全部或绝大部分的信息.
本文对提取出来的茶叶样本图像的特征进行降维处理,见图2.可以看出,前3项的贡献率累计超过90%,表明选取这三种特征可以反映不同品质茶叶的区别,实现茶叶品质的自动识别,所以样本特征矢量压缩为3个不相关的主分量.这样,降维率达到了3/22=13.6%,而信息保持率为90%.
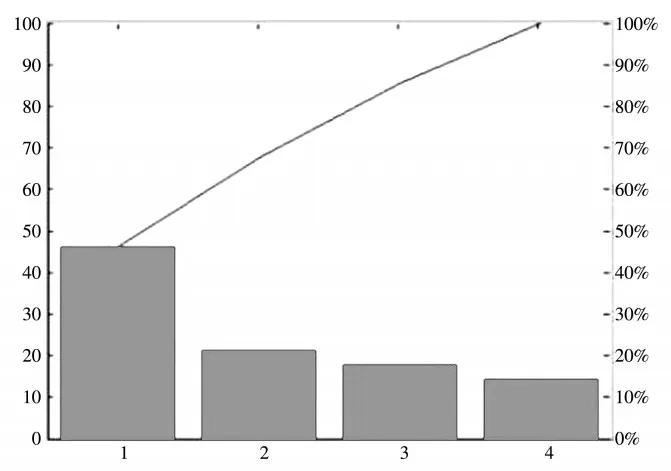
图2 试验样本特征矢量对区分整个样本的贡献率
4 人工神经网络框架的选择
对于任意、复杂和非线性的输入-输出映射,使用多层感知器的人工神经网络(ANN)分类方法的性能常常超过其他分类方法,本文考虑以下几种人工神经网络框架.
4.1 反向传播多层感知器(BPMLP)
BP-MLP模型具有输入层、输出层和一个隐藏层.输入层连接了图像特征(3个输入节点),输出层输出茶叶品质等级.在试验中观察到隐藏层的神经元个数为35的时候准确率最高,本文的研究中考虑了隐藏层的学习率为0.5,并且使用“TANSIG”作为隐藏层out put上的激活函数.“PURELIN”用作输出层的激活函数,输出层的学习速率为1,迭代次数为1 500次.
4.2 广义回归神经网络(GRNN)
GRNN是一种基于监督学习过程的前馈神经网络结构.他有四层——输入层、模式(高斯函数)层、求和层和输出层.输入层接收输入信号并将其传递给模式层进行进一步处理.模式层计算输入向量与训练向量之间的欧氏距离,并将该值传递给求和层作为激活函数(该函数为高斯函数).求和层有分子、分母两个神经元.分子神经元计算与训练样本输出相对应的加权和,分母神经元计算模式层输出的非加权和.输出层通过分子除以分母来计算输出.在我们的例子中,GRNN有3个输入节点,对应于3个图像特征.由于本文的研究是函数逼近问题,输出层只有一个节点,传播常数的值为1.0.
4.3 径向基函数网络(RBFN)
RBFN由输入层、隐藏层和输出层组成.隐藏层中被称为径向中心的隐藏节点,实现径向基函数即高斯函数,输出层则实现线性求和函数.在训练过程中,将隐藏层的权值更新到输出层并最终确定.RBFNN在径向基网络的隐藏层中不断增加神经元,通过最小化平均平方误差达到可接受的精度.对于基于RBF的人工神经网络的开发,考虑了由30个神经元组成的输入层和单神经元的输出层.
5 结果与分析
5.1 校准和测试准备数据采集
在标准的实验室条件下,使用开发的图像采集视觉系统对36个茶叶样品(18个良品,18个次品)进行实验.每个样品取不同角度的图像5次.因此,采集了180幅图像,使用图像分析程序对图像进行初步处理,然后进行特征提取.数据集的30%作为训练集,70%作为测试集.应用K-阶(在本例中为K=10)交叉验证技术来验证神经网络模型.
5.2 性能参数的选择
本研究使用以上三种类型的神经网络.因此,为了比较BPMLP、RBF和GRNN的性能,考虑MPPA(预测精度平均百分比)、MinPE(预测误差最小值)、SDPE(预测误差的标准差)、MSPE(预测误差均方差)、MaxPE(预测误差的最大值)5个性能参数.
这些性能参数是在执行10阶交叉验证后得到的结果.其中最重要的性能指示参数依次为MPPA、MSPE和MaxPE.MPPA表示神经网络模型的预测精度,MSPE表示神经网络模型的预测最优表现,MaxPE表示神经网络模型的预测精度的下限.SDPE和MSPE则能反映神经网络模型预测茶叶品质的鲁棒性.

表3 10阶交叉验证预测茶叶品质分级平均准确率(%)
5.3 茶叶品质检测的神经网络模型比较
使用180张茶叶样品的图像对所提出的茶叶品质自动检测技术进行测试.利用10阶交叉验证技术对整个数据集进行了三种模型的验证.表3分别用BPMLP、RBFN和GRNN预测茶叶品质等级,给出了10阶交叉验证后的结果.
5.4 定预测模型的性能分析
神经网络模型(BPMLP、RBFN和GRNN)预测茶叶品质等级的性能总结如表4所示.以看出,三种模型都能获得较高的识别率,预测精度平均百分比MPPA的数值都能在90%左右.另一方面,BP-MLP和GRNN的预测误差最大值(MaxPE)分别为17.06%和12.99%,低于RBNF的9.12%,表示RBNF的预测精度下限高于GRNN和BP-ML.BP-MLP和GRNN标准差分别为2.23和2.08,方差分别为4.95和4.34,RBNF的标准差为1.33,方差为1.76,均低于其他两种模型,表示RBNF的检测稳定性高于其他两者.因此,对于茶叶品质的自动检测可以清楚地观察到RBFN的性能优于BP-MLP和GRNN,故选用RBFN作为检测系统的神经网络模型.

表4 三种神经网络模型预测茶叶品质等级的性能总结
6 结语
本文提出一种利用低成本工业相机和光照条件建立的计算机视觉系统来自动检测茶叶品质.10倍交叉验证结果显示三种神经网络模型都能得到90%左右的识别准确率,RBFN算法性能要优于其他神经网络算法,而且性能更好,预测精度的下限较高.机器视觉技术可以用来自动检测茶叶的品质,能够得到准确、稳定的茶叶品质分级结果,实际应用价值较高.目前茶叶分类只有2类,对茶叶品质检测率尚未达到100%,未来可以通过优化神经网络模型和增加特征参数等来提高检测准确率,并对茶叶的等级分级进行细化.
猜你喜欢
茶叶通讯(2022年2期)2022-11-15
哈尔滨轴承(2020年2期)2020-11-06
创造(2020年5期)2020-09-10
软件(2020年3期)2020-04-20
电子制作(2019年10期)2019-06-17
摄影之友(影像视觉)(2018年12期)2019-01-28
电子制作(2018年19期)2018-11-14
电子制作(2018年9期)2018-08-04
快乐语文(2018年36期)2018-03-12
Coco薇(2017年8期)2017-08-03
