
分布式系统高效升级方法研究
2019-10-21 09:21屠雪真陈小强
微型电脑应用 2019年6期
屠雪真 陈小强


摘 要: 随着移动互联网、云计算等技术的发展,分布式系统以其易扩展、高可靠、灵活性强等优点成为了应用软件系统的首选架构。然而大型分布式系统的更新升级存在着过程复杂、时间长、新旧版本共存等问题。从研究分析分布式系统更新升级的特点和关键技术点出发,结合电信大型分布式系统实践中遇到的问题,提出了一种自动化的升级和数据迁移方法,采用逻辑顺序号保证数据的一致性,采用逻辑机架实施分区升级,设计了一种接力赛机制减少升级期间的数据迁移量,解决了分布式系统升级耗时长风险大的问题。实验结果表明,与现有的升级方式相比,分区升级方法缩短升级时间50%左右,将对业务的影响时长减小到秒级,提升了升级效率,并有效降低了升级风险。
关键词: 移动互联网; 云计算; 分布式系统; 高可靠; 版本升级
中图分类号: TP393
文献标志码: A
文章编号:1007-757X(2019)06-0042-05
Abstract: With the development of technologies such as mobile Internet and cloud computing, distributed systems have become the preferred architecture for application software systems because of their advantages of easy expansion, high reliability, and flexibility. However, the update and upgrade of large-scale distributed systems have problems such as complicated process, long time, and coexistence of new and old versions. Based on the analysis of the characteristics and key technologies of distributed system upgrade, and combined with the problems encountered in the practice of large-scale distributed telecom systems, in this paper, an automated upgrade and data migration method is proposed. The method uses logical sequence numbers to ensure data consistency, uses logical racks to implement partition upgrades. And a relay race mechanism is designed to reduce the amount of data migration during the upgrade. It solves the problem that the distributed system upgrade takes a long time and has a high risk. The experimental results show that compared with the existing upgrade method, the partition upgrade method shortens the upgrade time by about 50%, reduces the impact on the service to the second level, improves the upgrade efficiency, and effectively reduces the upgrade risk.
Key words: Mobile Internet; Cloud computing; Distributed system; High reliability; Version upgrade
0 引言
隨着移动互联网、社交网络、云计算等技术的快速发展,数据量呈爆炸式增长。对于日益增长的海量数据处理,许多应用面临着高并发、低时延、高可用及弹性扩展等挑战,分布式系统及相关技术被广泛地应用于各行各业的应用中。大型的分布式系统通常由几十到几百甚至几千台服务节点组成,构建和维护这种大规模分布式系统往往很复杂[1]。在系统的生命周期内,每隔一段时间,系统都需要进行升级以提升性能、修改错误或者增加新功能。如何有效地设计一种升级方案,使得大规模分布式系统能得到正确的、高效的升级和数据迁移,同时能持续对外提供服务,是实际过程中不得不面临的困难和挑战。
集中式应用系统一般由少量几台应用主机组成,其版本升级可以通过手工方式一对一地进行升级实现。而对于大规模的分布式应用系统,手工的升级方式不仅需要投入大量的人力,升级的质量和效果也很难得到保证[2]。因此,需要实现自动化升级方式,还需要确保多种版本按正确的步骤和顺序升级更新,并保证数据的一致性[3]。
1 相关工作
分布式系统是其组件分布在联网的计算机上,组件之间通过传递消息进行通信和动作协调的软件系统[4]。分布式系统的可用性指的是系统不间断提供服务的能力,公式定义如下:Availability=f(MTBF,MTTR)。
其中,MTBF(Mean time between Failures)是指系统多长时间坏一次;MTTR(Mean time to recover)是指一旦系统故障恢复服务所需要的时长。要想提高系统的可用性,要么提高MTBF,要么降低MTTR。而影响MTBF的最大的因素是软件版本升级,发布新版本则是MTBF最大的敌人[5]。一是要提高发布的版本质量,另一方面要能做好版本升级的过程控制。自动升级功能是做好版本升级过程控制不可缺少的功能[6]。
现有分布式系统的升级是各个节点串行进行的,每个节点的升级过程分成三个阶段[7]。
下线阶段:节点收到升级通知,开始迁移数据,数据迁移完成,本节点停止服务。其中最耗时的是主备副本间差异数据的迁移。
升级阶段:此阶段是离线的,主要操作是备份数据和配置文件、准备环境、替换版本等。其中备份数据最耗时。
上线阶段:节点从重启直至能对外正常提供服务都属于上线阶段。主要操作是重启进程,数据迁移,迁移完成后,开始对外正常服务。其中最耗时的是数据迁移。
由此,现有的分布式系统升级方式依然面临三个问题。一是升级时间长。大规模分布式系统节点众多,即使每个节点升级时间控制在分钟级,整个系统升级耗时累计也会达到数此小时甚至数天。二是数据迁移量大。每个节点升级完成后,重新启动会把原先属于自己的数据全量迁移回来。三是影响对外提供的服务,系统升级期间,被升级节点上承载的业务受到影响,数据迁移可能会影响系统性能,系统也存在升级失败的风险。很多商用分布式系统对升级的要求是快速精确、成功率高、过程可控,对业务影响小,甚至不能中断对外提供的服务。
近年来,有很多研究和设计来解决或改进分布式系统的这些问题和不足。
朱清华等[8]提出基于数据库日志的流式数据提取、迁移技术,通过对数据库日志进行解析,提取增量数据,并将这些数据直接发往hadoop集群,降低了数据迁移的开销。但是该研究仅限于hadoop集群中的特定数据系统,且没有经过商用的验证。
黄礼骏等[9]提出了一种能使分布式系统在多种版本共存的环境下正确地进行升级的方案,通过zookeeper[10]生成分布式全局锁,协调节点升级过程,实现了跨数据中心的分布式环境的升级。该研究侧重于升级全过程协调,版本升级和数据迁移两个阶段是串行,每个阶段内部节点也是串行的,时间过程耗时比较长,同时也没有解决数据迁移量大的问题。
武奇等[11]提出的动态数据迁移算法,是一种启发式的数据迁移机制,将节点上访问量高的数据迁移到其他节点。该算法针对的是运行过程中数据在节点间分布不均衡的问题。本研究针对升级时节点上已有数据的迁移,针对的场景是不同的。
以上研究都局限在分布式系统部分问题的改进和提升,存在适用场景的局限。
2 分区升级方案
通过分布式系统架构和升级机制的研究分析可知,上述问题的产生,一是因为分布式系统的集群层次结构过于简单,只有集群和集群下节点两层,要解决这个问题,就应该改变现有的分布式系统集群层次结构,重新设计节点的组织方法,使得升级期间不中断对外的服务提供。二是需要迁移的数据量大,迁移时间长,迁移过程控制不精细。要解决这个问题,可以记录节点升级前的数据状态,升级完成后重启时,先加载本地数据,然后再向其它节点获取升级期间更新的数据,最后形成最新的完整数据集。
综合以上分析,本文提出了一种自动化的分区升级方案,采用逻辑机架进行并行批量升级,采用接力赛机制减少升级过程中迁移的数据量,使用逻辑顺序号LSN(Logic Sequence Number)保证分布的数据一致性,较优的解决了以上的典型问题。提升了分布式系统的升级效率。
本系统由版本发布主机和应用集群组成,如图1所示。
完整的自动升级过程分为上传应用程序和自动升级应用程序。上传程序主要用来在服务器上传即将升级的文件。客户端自动侦测版本号,当服务器端记录的版本号比本地客户端记录的版本号大时,将从服务端下载最新的程序,开始升级并保持版本同步[12]。
发布主机是核心的升级管理器,负责自动升级过程的控制和升级结果的跟踪,对应用系统版本进行管理,包含版本发布、版本回退等,并对各节点版本更新情况进行跟踪。发布过程需要保证版本发布的事务一致性,即一个版本更新包涉及的文件发布,需要保证都成功或失败时能进行回滚操作。
应用集群节点实施版本的自动升级,负责本节点版本更新以及更新结果的反馈。各节点应保留本地数据备份、当前版本文件以及要升级的目标版本文库。分布式系统都是分层次的,上层依赖于下层,所以每个节点的升级是按先下后上的层次顺序,并作为一个事务来执行的。
不同于传统分布式系统简单的层次结构,本方案设计了一种集群-机架-节点的三级架构,在集群和节点之间,增加一个逻辑机架层。集群的每个节点都归属一个逻辑机架。
确定集群逻辑机架的数量是个必须精心设计的问题,需要考虑两方面的因素:
1) 当任一逻辑机架升级时,都能正常对外服务,因此其他任一机架上必须有全部的数据;
2) 在保障分布式系统中数据的可靠性的同时,综合考虑对网络、内存、磁盘I/O的资源需求和压力,业界最常采用二副本或三副本。
因此,设计集群逻辑机架的数量等于副本数量,即一般为二或者三机架。为进一步说明集群逻辑机架的数量为什么要等于副本数量,假设集群有6个节点,有数据A,B,C,数据有2个副本,数据分布如图2所示。
图中线段连接数据的两个副本,箭头方向指示数据同步的方向。
机架分成两个,节点1,2,3属于机架1,节点4,5,6属于机架2。
数据A的主副本,在机架A的节点1上,另一个副本在机架B的节点4上。
数据B的主副本,在机架B的节点5上,另一个副本在机架A的节点2上。
数据C的主副本,在机架A的节点3上,另一个副本在机架B的节点6上。
可以看出,机架1和机架2都有全量的数据A,B,C。
集群升级时以逻辑机架为单元进行的。以图2为例说明集群的升级过程:
1) 发布主机发布指令升级机架A,机架A三个节点数据迁移到机架B上的节点。
2) 数据迁移完毕,机架A的三個节点下线,更换版本并重新启动。机架A三个节点下线期间,机架B上因为存储了全部数据,能正常对外服务,因此对业务是无影响的。
3) 机架A重启成功,数据从机架B节点迁移回机架A。机架A上三个节点重启升级等操作是并行的,因此无论归属机架的节点数量是多少,重启升级时间和一个节点大致相等。
4) 数据迁移完毕,机架A升级成功并接管服务,机架B依次升级。虽然从机架的角度看,仍然是按照机架串行升级的,但是从节点来看是批量的并行升级。
假设数据是N个副本,对应N个机架,节点有M个,每个节点升级时间为T,升级时间计算和比对:
1) 以逻辑机架为单元升级时,升级时间为机架数*单个节点升级时间= N*T, 升级时间与集群内节点个数无关。
2) 节点单独升级时,整个升级时间为节点数*单个节点升级时间= M*T, 升级时间与集群内节点个数成正比。
可见,以逻辑机架为单元升级时间为2T,以节点单独升级时间为6T,节省2/3的时间。
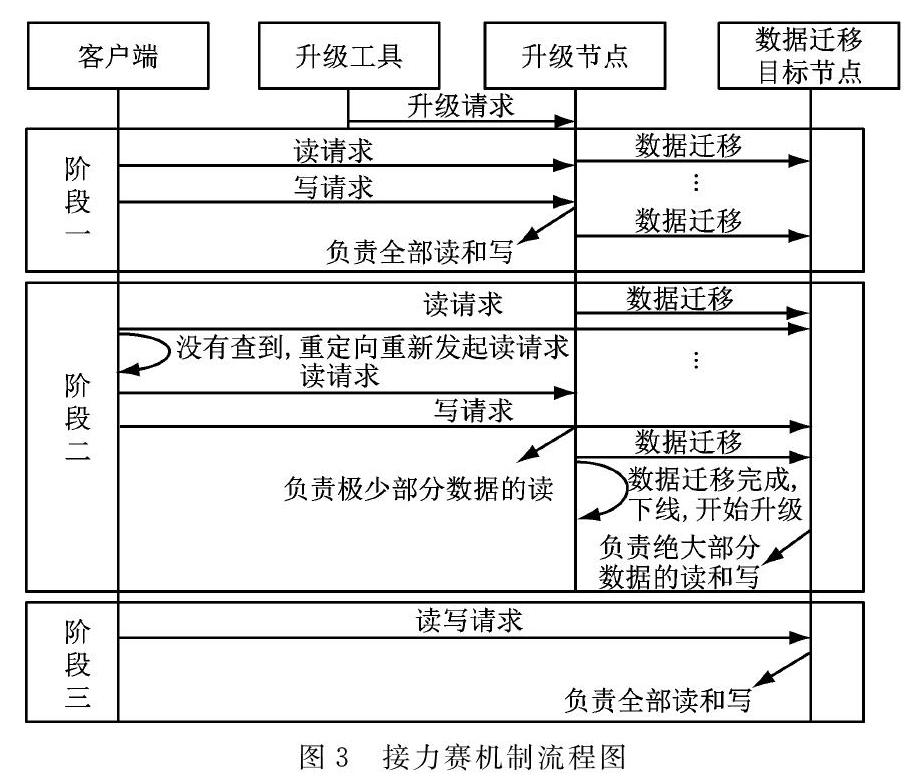
2.1 接力赛机制的升级流程
为减少升级期间对业务的影响,数据迁移时设计了一种接力赛机制。将被升级节点上的数据分成两部分进行迁移,两部分数据的大小可配置,配置原则是一部分数据为阀值大小,另一部分为其余的数据。为减少对业务影响,阀值不可配置过大。为了简化配置,只需进行阀值大小的配置,比如阀值配置为100 M。为方便叙述后面都以100 M进行描述。
整个接力赛分三个阶段,节点上承担的业务逐渐转移见下图的椭圆部分,如图3所示。
阶段一:S节点(升级节点)负责业务全部的读和写,S节点上的数据向D节点(目的节点)数据迁移,迁移期间业务只能访问S节点。数据迁移到只剩下100 M时,服务端更新路由表(数据分布节点的信息称为数据的路由表,路由表有一个版本号,当有数据从一个节点迁移到另一个节点时,版本号会变化),此时客户端感知路由表的变化并获取最新的路由表(客户端在请求消息的响应中得到路由表的最新版本,并和本地保存的版本号比较,如果不同则主动获取最新的路由表),得知S节点上绝大部分数据迁移到D节点,因此客户端后续原本向S节点写的数据重定向写到D节点,原本向S节点读的数据优先到D节点读,读不到再重定向到S节点读,至此第一阶段结束。
阶段二:S节点继续向D节点迁移第一阶段剩下的100 M数据,迁移期间D节点承担业务全部的写和绝大部分的读,如果读不到,则将客户端按照既定策略重定向到S节点,重新向S节点发起读请求,即S节点承担极少部分数据的读。
阶段三:S节点向D节点迁移完所有数据后,服务端更新路由表,此时客户端感知路由表的变化并获取最新的路由表,得知S节点上全部数据迁移到D节点,因此客户端后续原本向S节点读写的请求全部转向D节点,至此S节点就可以下线,进行升级操作。这时只有D节点承担业务全部的读写。
接力赛机制有效减小了系统升级期间对业务的影响。一是有效避免了在极端情况下,S节点一直有写业务请求,导致一直有数据要迁移,迁移过程一直结束不了的情况发生。二是对影响业务的时间可控。因为在第一阶段数据迁移时,基本对业务访问无影响。在迁移第二阶段的100 M数据时,仅当在D节点上读不到所需数据时,客户端会被重定向到S节点,再次发起读请求,这样延迟才会加大。但是第二阶段要迁移的数据量很少,所以对业务的影响极小。因为100 M数据迁移,即使在100 Mbytes网络条件下,也仅需1秒,对业务影响极小。
上面描述的是升级时的处理流程,升级结束后系统重启时也会存在数据迁移,和上述流程刚好反过来。
2.2 数据一致性保证
分布式系统为了提高可靠性,数据要保存多份,一份称为一个副本,其中一个副本称为主副本,对外可读可写,其他副本称为备副本,对外只读。当主副本不能对外服务时,备副本可以通过选举升为主副本。数据复制在可用性和性能方面給分布式系统带来了巨大好处,同时也带来了数据一致性的挑战。
数据一致性是指在对一个副本数据进行更新的时候,必须确保也能够更新其它的副本,否则不同副本之间的数据将不一致。一致性是分布式领域的一个重要的难题。
CAP定理[13]告诉我们,在一个分布式系统中,Consistency(一致性)、Availability(可用性)、Partition tolerance(分区容错性),三者不可兼得。我们无法找到一种能够满足分布式系统所有系统属性的分布式一致性解决方案。因此,如何既保证数据的一致性,同时又不影响系统运行的性能,是每一个分布式系统都需要重点考虑和权衡的。于是,有了三种一致性级别的系统,分别是强一致性、弱一致性和最终一致性。简单来说,强一致性要求更新过的数据能被后续的访问都能看到。如果能容忍后续的部分或者全部访问不到,则是弱一致性。如果经过一段时间后要求能访问到更新的数据,则是最终一致性。其中,最终一致性是业界大型分布式系统中比较主流的选择[5]。
在电信业务工程实践上的基础上,本文设计实现了一种简洁的最终一致性解决方案,保障分布式系统升级时数据的最终一致性。为了标识最新的数据副本,保证数据的一致性,我们设计了一个逻辑顺序号LSN来标识数据写或者删除的时序。它是一个长整数,每次数据有修改或更新时加一,LSN值越大,表示操作发生时间越晚。
节点正常运行时,数据每修改或更新一次,LSN就加一,LSN和数据一并同步到其它副本。当节点升级完成,重启后将本地保存的最大LSN发给备副本(此时已经切换为主副本),检查比对两个LSN,并将缺失部分同步给重启后的升级节点,保证主备数据一致。
由于系统的升级一般选择在业务空闲的时间段,且接力赛机制使得升级过程需要同步的数据比较少,因此LSN相差不大。
3 实验及应用
本实验使用中兴电信级分布式缓存系统DCACHE实施,搭建包括发布主机、客户端、服务端的集群环境。各节点配置采用通用X86服务器,配置:Intel Xeon(R) E5-2680 V2@2.80 GHz,32core;内存128 GB DDR3/1 333 MHz;intel8391GT千兆网卡*6。软件环境采用操作系统为CGSL5.04F1,内核版本3.10.0-693。
实验采用的数据量为30 G。为测试升级期间对业务的影响,启动一个客户端,保持10 000条/秒的持续的业务访问量。分别测试两个集群在2节点、4节点、6节点场景下升级耗时,业务影响时间并进行比对分析。针对分区升级的集群,因为业界最常采用二副本或三副本保障分布式系统中数据的可靠性,2个节点时采用2副本,即分成二个机架,4个节点时采用2副本,即分成二个机架,6个节点时采用3副本,就分成3个机架。业务影响时间就是从电信业务层面观察到业务有超时、查询不到数据或者得到路由不对的响应等异常情况持续的时间。
测试对比结果如图4所示。
可以看出:在升级时间方面,主要耗时在数据的备份和恢复。传统方式因为是串行过程,升级时间与节点数量成正比。对于分区升级方式,升级时间与机架数量成正比。因为归属一个机架的多个节点并行执行升级脚本,并行数据备份,所以一个机架升级时间和一个节点的升级时间大致相等。
在业务影响时间方面,在相同的网络带宽条件下,影响时间和迁移数据正相关。对传统方式来说,迁移数据量大,对业务的影响时间长。对本方案来说,影响业务的时间与与点原先承载的数据量无关,只涉及升级期间阀值的数据量和变化的增量数据,这部分数据量很小,所以对业务的影响很小。
4 总结
本文结合企业已有的需求和实际工程问题出发,介绍了一种针对分布式系统的高效升级方法。采用逻辑机架和接力赛机制,解决升级时间长、迁移数据量大、业务影响时间长等突出问题。通过和传统自动化升级方式的对比实验验证,以及商用生产环境的实际使用效果,都证明了分区升级对大规模分布式系统运维工作效率提升的有效性。本文提出的方法没有针对云化场景做全面考虑,具有一定的局限性。
近年来,来自谷歌的Kubernetes社区风头强劲,已在业界大量科技公司规模商用并致力于成为领先者[13],基于Docker[14]的自动化运维技术已成为一种必然趋势。众多的使用分布式架构的公司,也开始对原有系统进行容器或升级,传统分布式架构如何进行容器化升级是我们下一步的工作方向。
参考文献
[1] 曹雨薇,张毅.分布式系统运维交付解决方案研究与应用[J].电脑与电信, 2017(10):44-47.
[2] 黄炜耀,分布式应用系统更新及实现方式[J].中国新通信,2016(21):98.
[3] Aumani Sameer, Barbara Liskov, Liuba Shrira. Modular software upgrades for distributed systems[C]// ECOOP 2006-Object-Oriented Programming. Belin Heidelberg: Springer 2006: 452-476.
[4] Coulouris G, Jean Dollimore, Tim Kindberg, et al. Distributed Systems:Conceptes and Design(5th Edition) [M].Boston:Addison-Wesley, 2011.
[5] 高可用架构社区著. 高可用架构[M]. 北京:电子工业出版社,2017.
[6] 毛承国,张卫华,张进铎,等.大规模集群运维自动化的探索与实践[J].信息安全与技术, 2014(2):60-61.
[7] 燕振斌.分布式环境下程序部署与监控系统中的任务调度模型研究[D]. 北京:北京工业大学,2013.
[8] 朱清华.数据迁移云服务的设计与实现[D].杭州:浙江大学,2017.
[9] 黄礼骏.分布式系统的升级和数据迁移问题研究[D]. 北京:北京大学, 2015.
[10] Apache ZooKeeper[DB/OL]. https://en.wikipedia.org/wiki/Apache_ZooKeeper,2018-12-16.
[11] 武奇,劉钢,郭建伟,等. 基于启发式算法的数据迁移机制[J].吉林建筑大学学报, 2016,33(5):77-80.
[12] 冒佳明,滕爱国,唐巍. 基于SaltStack的电力信息系统版本自动化升级工具[J].电力信息与通信技术,2017(4):54-59.
[13] Eric Brewer. CAP twelve years later: How the “rules” have changed[J]. IEEE Explore, 2012,45(2):23-29.
[14] 龚正,吴治辉,叶伙荣,等.Kubernetes 权威指南[M]. 北京:电子工业出版社, 2016.
[15] Docker Containerization Unlocks the Potential for Dev and Ops[EB/OL].https://www.docker.com/why-docker, 2018-12-26.
(收稿日期: 2019.01.16)
猜你喜欢
人间(2016年28期)2016-11-10
软件导刊(2016年9期)2016-11-07
软件导刊(2016年9期)2016-11-07
时代金融(2016年23期)2016-10-31
电脑知识与技术(2016年21期)2016-10-18
电脑知识与技术(2016年21期)2016-10-18
电脑知识与技术(2016年21期)2016-10-18
新闻世界(2016年10期)2016-10-11
考试周刊(2016年76期)2016-10-09
大学教育(2016年9期)2016-10-09
