
卷积神经网络在古籍汉字识别中的应用实践
2019-10-21 03:34郭利敏刘悦如
图书馆论坛 2019年10期
郭利敏,葛 亮,刘悦如
0 前言
虽然OCR(Optical Character Recognition)技术在计算机视觉领域已有10多年,传统OCR技术对现代印刷体的识别很成熟,但在古籍汉字的识别上还存在挑战。由于古籍汉字属于书法字体,笔画并不像打印字体那样横平竖直,没有固定模板匹配;不同作品书写笔画粗细不同、笔画黏连;长期保存过程中还存在部分笔画模糊与缺失现象;书法字形又承载着作者独特书写风格,形态各异,给书法字识别带来了困难。
近年,随着深度学习技术在OCR 领域的应用研究,将其用于现代手写体汉字的识别已有非常多的成果。比如,IDSIA团队首次将卷积神经网络运用到手写体汉字的识别,在ICDAR-2011脱机手写体汉字识别竞赛中,其识别准确率达到92.18%[1];在ICDAR-2013联机和脱机手写体汉字识别竞赛中,采用卷积神经网络模型方法对脱机手写体汉字识别率达到了94.77%[2];最近的研究表明汉字的细微结构特征对汉字的准确识别有很大的作用[3]。
长久以来,古籍文献资源的数字化成果主要有古籍索引数据库、古籍书目数据库、古籍全文数据库等三种类型,各种数据库往往只是从古籍外部特征与主题内容的角度对古籍文献进行描述与组织,为全文文本数据库提供检索服务[4]。随着数字人文的兴起,数字人文为古籍数字化的深度开发提供了新的理论和实践方法,在使得古籍语义分析、字频统计、信息挖掘、智能标点以及古文献数字化地图建设等成为可能的同时,也对数字化古籍的加工提出了新的要求。在数字人文古籍元数据从数字化到数据化的转化加工过程中,对于古籍文本汉字的识别是最为基础也是最重要的工作之一,但由于字库的不完善、不规范和不统一等使得传统的OCR技术识别古籍困难[5],使得这项工作一直以人工为主,而工作人员又必须具备一定的专业知识素养,非常耗时费力。所以运用深度学习技术对特定样本进行学习训练,并运用迁移学习的方式对古籍汉字进行识别,可以为数字人文古籍汉字的元数据加工提供一种可行的解决方案,旨在提高古籍资源在数字人文应用研究中的效率。
1 试验方法和思路
一个卷积神经网络(CNN)通常是由一系列的卷积层和子采样层以及1 个或多个全连接层组成。其中,卷积层用以从输入图片中提取图片的特征信息,全连接层则用以将提取的特征信息进行分类。
本文通过构建卷积神经网络对特定的繁体字数据集进行特征学习,并将训练结果用于预测古籍中的汉字。整个方法可分为三个步骤(见图1)。
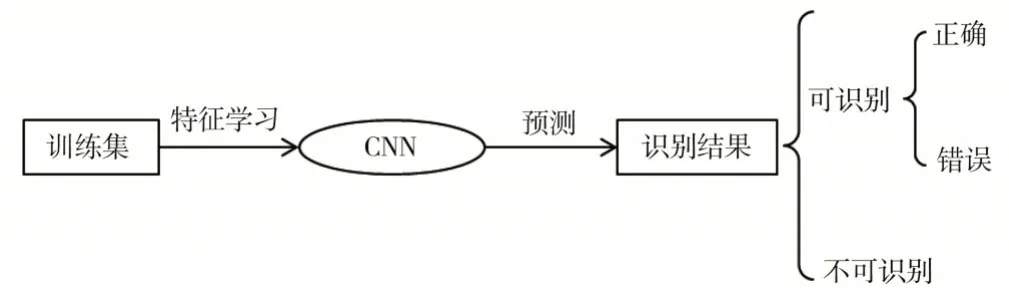
图1 基于卷积神经网络的古籍汉字识别流程
步骤一:构建训练集。运用汉字生成技术,针对古籍汉字字形寻找相似的字体,同时运用数字图像处理技术模拟真实情况下的古籍汉字图片的噪声,如笔画模糊、笔画缺失等现象构建训练集。
步骤二:网络模型的构建与训练。设计卷积神经网络模型结构,并在步骤一中构建的训练集的基础上进行学习训练。
步骤三:识别和结果分析。通过步骤二得到已训练好的深度学习网络,将从古籍图片中切割出来的古籍汉字图片(测试集)使用该网络进行识别,结果分为“可识别”和“不可识别”两类。标注为“不可识别”的,表示机器无法对其进行识别或识别准确率非常低;标注为“可识别”的,则表示机器可识别,同时会给出网络的识别结果,再对此部分结果进行正确率的分析。
基于卷积神经网络的古籍汉字识别,其本质就是通过深度学习的方式构建一个汉字图片与汉字字符的分类器,将输入的汉字图片通过卷积神经网络逐层提取图片特征,得到各个分类汉字的概率,随后选择概率最高的一个分类作为目标输出,即识别结果。为了提高精确度,通常会使用阈值作为结果筛选的依据,如公式1所示。

其中,P为目标输出的概率,T为阈值,当概率大于等于阈值时才采用这个结果。然而阈值T通常是通过先验知识和实验对比选择较好阈值,依赖主观判断,这种方式准确性较低、通用性较差。
因此,在设计网络模型的时候特别增加一个“不可识别”的分类项,网络可以将不确定的识别结果作为输出项,达到动态阈值的结果,从而提高精确度。
1.1 构建训练集
充分的训练数据集是训练卷积神经网络的关键,然而真实数据样本的采集和整理需要大量的人力去把握其规模和准确性。目前针对汉字手写体的数据库有北京邮电大学发布的HCL2000 脱机手写数据库[6]、国家863中文手写评测数据[7]等,都是比较规范书写的数据。相比而言,目前能表现真实书写情况的手写单字样本数据库有中国科学院发布的CASIA-OLHWDB1.0-1.2手写单字样本数据库和CASIAHWDB1.0-1.2 文本行数据集[8],以及华南理工大学发布的涵盖单字、词组、文本行、数字、字母、符号等综合手写数据集SCUTCOUCH[9],但上述的数据集都集中在简体汉字的标准体或现代手写体上,对于书法风格的古籍汉字而言,无论是字形还是字体风格都相距甚远。
为避免在训练过程中出现“过拟合”(Over Fitting),提升CNN 模型的性能,也因为没有找到合适的数据集进行模型训练,所以采用数据生成技术来构建训练集。从不同字体中抽取字体并生成字体图片,并结合图像的平移、尺度缩放、旋转、水平或垂直拉升、椒盐噪声、高斯噪声等方法对图形进行随机变化和添加随机噪声,如图2所示。

图2 测试集中选取的有代表性的图片

图3 “度”字的部分训练样本
通过图2 对测试集的观察,发现如下特点:(1)测试集的图片格式大小不一,字形多样。(2)从“烟”字可看到,部分图片具有简体和繁体两种写法。(3)从“送”和“七”字可以看出图片的有缺失或者其他干扰噪声。依据上述特点,选取10种不同的字体文件(其中包含细明体、黑体、宋体、隶属、楷书等),每一个汉字分为简体、繁体两种,去重后共计有773 个目标汉字(部分汉字简、繁体相同),每一个汉字对于每一种字体施加随机形变和随机噪声,生成的训练样本如图3所示。
1.2 卷积神经网络的结构设计
经过尝试多种网络结构,并在准确度、收敛速度等多方面综合评估后,最终确定图4的网络结构。网络结构由7个卷积层和3个全连接层组成,其中表示卷积层的卷积核大小为卷积步长为y;表示池化层(max-pooling)的大小为步长为y;表示填充层(padding),在图像边界填充x 个像素点,“#Class”表示目标分类的个数,本文共计773个汉字(包含简繁体)以及“不可识别”分类,所以“#Class”为774个。

图4 卷积神经网络模型结构
1.3 测试样本
测试样本均来自上海图书馆主页(www.library.sh.cn)的“我的图书馆系统”登录验证码所用图片(图片均源自“盛宣怀档案”)。如图5所示,我们对每张图片进行人工标注,并做了二次审核以保证标注的正确性,其中共有660 个字1213张图片。由图2可知,由于测试集的图片形状格式不一,所以我们需要对测试集进行预处理,使其成为统一大小的灰度图片。处理结果如图6所示。通过预处理不仅把原始图片调整为统一大小,还能在一定程度上抑制原始图像的背景噪声。

图5 “我的图书馆”登录验证码界面

图6 测试集预处理前后对比
2 实验结果分析
由于计算资源有限(仅一块NVIDIA GeForce 1080 Ti显卡来做GPU 运算)。为了减少运算量,选取48*48大小的图片作为CNN 网络模型的输入,在小规模数据集上尝试构建多种网络结构,从收敛速度以及准确率两方面进行评估后,最后选定图5的结构作为本次实验的最优结构,进行大规模的训练和实际样本的测试。
目标汉字共计773个,用于生成训练样本的字体文件共计10个(包含TTF和TTC格式),共计20种字体,每个字每一种字体生成160带有随机噪声的样本。所以整体的训练样本数量约为160*10*2*773=2473600 个样本,由于部分字体并没有包含繁写体,所以最终生成的训练样本比上述值少些。
为评估实验结果,引入两个评价指标:准确率(Accuracy)和精确率(Precision)。
准确率(Racc)是:对于给定的测试数据集,正确识别的样本数(Sright)与总样本数(Stotal)之比。准确率可反应卷积神经网络对预测样本整体的识别能力。

精确率(Rprecision)是:对给定的测试数据集,正确识别的样本数(Rright)与识别出的样本数量(Rright+Rerror)之比。精确率可反应卷积神经网络的预测结果的可靠程度,在准确率较难提升的情况下,通过提升精确率使得网络的实际运用更好,系统更可靠。

对上述训练样本在图5 的模型结构于TensorFlow平台上进行20训练轮迭代后做了相应测试,结果见表1。

表1 识别结果
其中,Runknow为无法识别样本。通过公式(2)与公式(3)计算所得:

2.1 训练样本的多样性
由于训练集对模型识别的结果影响较大,特地在原有样本基础上,新增王羲之书法字体和颜体书法字体,通过字体生成技术生成单字160个不同的样本,见图7。同样进行20 轮迭代训练后,得出的测试结果如表2所示。可见,增加字体样本后未识别样本降低,整体的准确率有所提升。所以,训练样本字体的多样性有助于提升CNN网络的识别率。可以通过将古籍中的汉字切割、标注、预处理后构建训练样本,以此提高样本的多样性,进而提升识别性能。

图7 新增王羲之、颜真卿字体
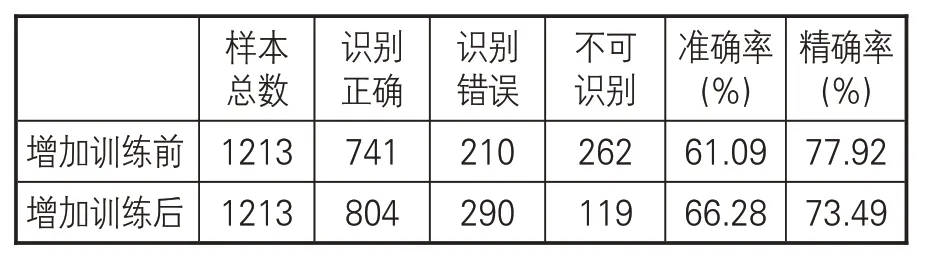
表2 增加样本前后测试准确度对比
2.2 错误结果分析

图8 预处理前后样本对比
如前文图1所示,模型对图片的结果识别分为“可识别样本”和“不可识别样本”两类,其中可识别样本包括识别正确样本和识别错误样本。在对错误样本和不可识别样本进行分析后,得到几个导致识别错误的原因。
(1)图片预处理导致的失真问题。虽然把原始图片转换成灰度图,一定程度上降低了背景噪声,但程序批量处理使部分样本在转换后失真严重,如图8所示。这种情况是由于缺少相应的训练样本使得机器将其识别为“不可识别样本”。虽然降低模型的正确率,但对精确率有一定的提升。
(2)相近字体导致的识别错误。在识别错误结果中,部分是相近字形导致的识别错误。如图9所示,将文件名第一个字符表示此图片标注的汉字,第二个为卷积神经网络识别的汉字,可见由于手写体字形的多样性和不确性使得网络将其识别成为其他相似字。如“化”字,由于连笔产生的多余信息被识别为“他”字。因此,对卷积神经网络来说,如何提升笔画细节的识别能力非常重要,也是提高准确度的关键。

图9 相近字体识别错误样例
(3)简繁体识别错误。在校验识别结果后,发现有部分繁体字被识别成为简体字,共计27个样本,占比约10%。由于在训练集中,简、繁体字被定义成为两个不同的样本,对于这样的结果目前无法解释,需要增加测试样本作进一步探究,但通过建立简繁体映射表则可解决此问题。错误样例见图10。
(4)其他错误。对其余一些识别错误的样本,很难找到具体的原因,但通过提升网络对笔画细节的识别能力,以及提升网络对不可识别汉字的判断能力,可降低这部分错误的出现率,进而提升网络识别的精确率。
3 结语

图10 简繁字体识别错误样例
古籍的元数据文本加工是数字人文研究中最重要也是工作量最大的基础工作之一,它有着工作量大、专业性强的特点,一直以来都是以人工识别为主,耗时费力。本文构建了卷积神经网络模型,通过数据生成技术生成古籍汉字图片作为训练集,并在TensorFlow 平台上训练后,用于数字化古籍汉字的识别,该方法可用于辅助古籍汉字的元数据加工工作。下一步将继续扩大训练集,并结合标注汉字图片进行模型结构和训练集合的调整,进一步提高其识别率。
对图书馆而言,由于图书馆学自身专业的定位,使得图书馆行业内计算机、数学相关的专业背景的人才相对较少,类似于传统的OCR 这种需要大量计算机和数学背景知识专业应用,对于图书馆而言,大多都依赖其他行业的应用成果。但对于卷积神经网络这类深度学习的应用,使得之前需要花费大量时间尽力进行的特征编码、算法设计等相对复杂的设计变得非常简单,在网络模型既定的情况下,通过调整训练集就可以得到一个更适合于图书馆应用场景的结果。图书馆恰好有着大量的行业数据积累,图书馆馆员也具有对这部分数据整理归纳的能力,所以深度学习相对于传统计算机算法处理而言,是一个更适合于图书馆的应用方案。
猜你喜欢
汉字汉语研究(2021年3期)2021-11-24
天一阁文丛(2020年0期)2020-11-05
布达拉(2020年3期)2020-04-13
娃娃乐园·综合智能(2020年2期)2020-03-12
科技创新与应用(2020年6期)2020-02-29
金桥(2017年5期)2017-07-05
现代电子技术(2016年23期)2017-01-12
北京理工大学学报(2016年6期)2016-11-22
小雪花·成长指南(2014年10期)2014-10-31
移动一族(2009年3期)2009-05-12
