
基于FP-growth 算法的课程关联性分析*
2019-10-17 01:27喻铁朔石月凤徐明明
中国教育信息化 2019年17期
杨 彩,喻铁朔,石月凤,徐明明,侯 峰
(1.郑州轻工业大学 信息化管理中心,河南 郑州 450002;2.郑州轻工业大学 计算机与通信工程学院,河南 郑州 450002;3.郑州轻工业大学 能源与动力工程学院,河南 郑州 450002)
一、引言
随着信息技术的不断发展,高校数据不断增长,这给学校的管理带来了巨大挑战。教学工作和人才培养始终是高校的重点任务,学生成绩恰好能直观地反映教学工作的好坏,因此学生的成绩始终备受教师、管理者以及学生自身的关注。目前,高校普遍建设了成绩查询系统,通过该系统可以进行成绩查询、数据备份以及一些简单的成绩分析,但是对成绩较深入的关联分析研究却相对较少。采用数据挖掘算法可以找出课程间潜在的关联关系[1],进而可为教师上课、教务管理者开设课程以及学生自身选课提供合理依据。因此,运用数据挖掘方法对高校的数据进行探索分析成为一个亟待解决的重点问题。
目前,Apriori 算法和FP-growth 算法是关联规则挖掘分析中最常用的两种经典算法,这些算法已经广泛应用在社会的各个研究领域中,但是在高校的课程相关性分析的应用却鲜为少见。2014 年龙钧宇提出了基于压缩矩阵的Apriori 算法的高校学生成绩相关性分析研究[2],采用Apriori 算法,在产生频繁模式完全集前需要对数据库进行多次扫描,同时产生大量的候选频繁集,这就使Apriori 算法时间和空间复杂度较大,造成了大量的时间和空间浪费[3-4]。而FP-growth 算法相比于Apriori 算法,效率会更高。
基于此,本文采用FP-growth 算法[5-6]对学生的课程成绩进行挖掘算法分析,进而得到各个课程间的关联规则。通过得到的课程间的关联规则,不仅可以为学生提供学业指导,还可以为教务管理者提供教学方面的决策支持,为相关专业开设课程的前后顺序提供合理依据。
二、FP-growth 算法
关联规则挖掘是从海量数据中挖掘出有用的、潜在的、数据项之间有相互联系的知识,而课程间的关联规则挖掘分析是挖掘课程之间的相互联系。典型的关联规则挖掘算法有Apriori 算法和FP-growth 算法。FP-growth 算法是韩家炜等人在2000 年提出的关联规则分析挖掘算法,FP-growth 算法相比于Apriori 算法不产生候选项集,另外FP-growth 算法比Apriori 算法效率高。FP-growth 算法目前广泛应用于各个领域中。因此本文运用FP-growth 算法挖掘课程之间的关联关系。
1.相关定义
支持度support 表示就某一项或某条规则,在它的所有历史交易数据中出现的比例或某条规则所含的全部项在所有交易历史中同时出现的比例,可表示为如公式1 所示[7]:
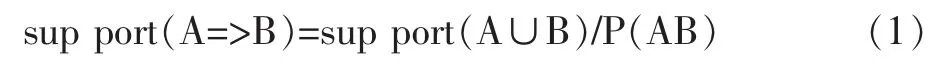
某条规则的置信度confidence 衡量的是交易中出现先导时也出现后继的比例。置信度反映了这条规则的可靠程度。关联规则A=>B 的置信度计算如公式2 所示[7]:
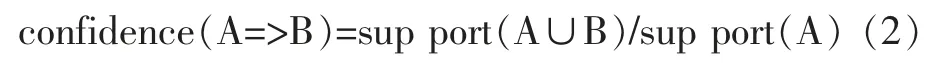
最小支持度用min-sup 表示,最小可信度用minconf 表示,这两个值可根据自身需要设定阈值。若A=>B的支持度大于给定的min-sup 阈值且A=>B 的置信度大于min-conf,那么A=>B 成立,即规则A 可以推出规则B。
2.FP-growth 算法详细过程
FP-growth 算法的主要内容可分为两大核心步骤。首先是将数据库压缩到FP-tree 树中(FP-tree 是一种特殊的前缀树,由频繁项头表和项前缀树构成),然后在FP-tree树中挖掘频繁项集。FP-growth 算法流程如图1 所示。
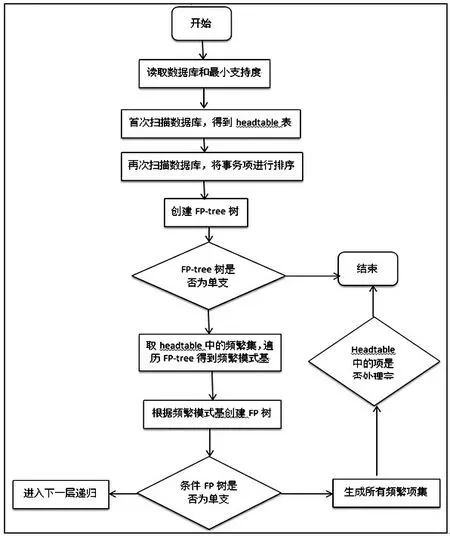
图1 FP-growth 算法流程图
FP-growth 算法的详细步骤如下所示:
第一步,构造FP-tree。扫描数据库,计算出数据库中各个项的支持度,若该项的支持度大于给定的阈值,则该项为频繁项集,并将该频繁项集按照支持度的大小顺序保存在数据库中,第二次扫描数据库,依次读取数据库并按照路径将其保存在FP-tree 中,重复此步骤直到将数据库读取完毕,即完成了FP-tree 的构造。
第二步,在FP-tree 树中挖掘频繁项集。FP-tree 树构造完毕后,在FP-tree 中根据叶子结点到根结点的顺序遍历FP-tree,按照顺序为每个结点创建条件模式基(条件模式基是以所查找元素项为结尾的路径集合,表示的是所查找的元素项与树根节点之间的所有内容),再根据所创造的条件模式基创建条件模式树,再在条件模式树中挖掘频繁模式,进而挖掘出频繁项集,此时即可得到所有的频繁项集。
三、基于FP-growth 算法课程关联分析
1.数据选择
本文从某高校教务系统中选取数学与信息科学学院1001 专业下的2015 级数据信息,选取2015 级数据的2015-2016 学年第二学期必修课考试课程数据,包含的课程有程序设计技术1、大学英语读写译II、大学英语视听说II、高等代数2、数学分析2;选取2015 级数据的2016-2017 学年第一学期数据,包含的课程有概率论、马克思主义基本原理、数据分析3。
2.数据预处理
(1)数据清洗
教务系统中学生课程成绩数据包含很多字段,为了更方便地探索分析数据,首先将数据中过多的字段进行过滤,只留下挖掘中所需要的字段信息。例如,将学生的上课学时、课程性质、学院、专业等对关联分析无用的信息进行清洗,将这些列信息进行过滤即可。
(2)缺失值处理
从教务系统中抽取的数据存在空值,造成空值的原因可能包括以下几个方面:①数据抽取过程导致数据丢失;②学生本身没有考试,不存在考试成绩;③教务系统老师还没有录入学生成绩。处理缺失值常用的方法有删除法、替换法、插补法三种方法,删除法是处理缺失值最常用的方法,由于数据缺失过多,不能采用简单删除法进行缺失值处理,本文采用拉格朗日插值法处理缺失值。拉格朗日插值原理如下:
由数学知识可知,平面上已知的n 个点(无两点在一条直线上)可以找到n-1 次多项式,使此多项式曲线过这n 个点。
求已知的过n 个点的n-1 次多项式:

将这n 个点的坐标(x1,y1),(x2,y2)…(xn,yn)代入上述多项式,得:
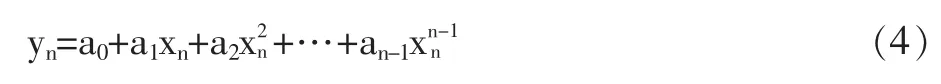
得到拉格朗日插值多项式为:
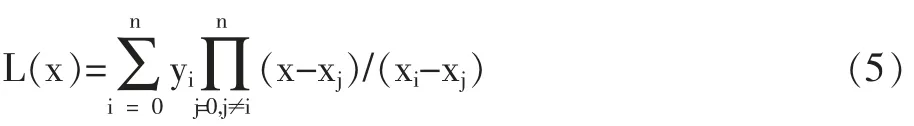
运用此种方法,将缺失值x 代入公式5,得到缺失值的近似值。文中采取拉格朗日插值方法处理缺失值。
(3)数据变换
将数据从一种形式转换为另一种适合使用的形式的这一过程称之为数据变换。本文将学生的课程成绩数据转化为二值型数据,即将成绩及格的学生成绩转化为TRUE,将成绩不及格的学生成绩转化为FALSE。
3.课程关联分析
本文FP-growth 算法采用的实验环境为PC 机、Window10 操作系统下,系统配置为Intel i7-7500U 的CPU、4G 内存、1T 硬盘。数据集为某大学教务系统的学生课程成绩数据。
对教务系统中抽取到的学生课程数据进行数据预处理之后,采用FP-growth 算法进行课程间的关联规则挖掘分析。在FP-growth 中,设置FP-growth 算法的最小支持度为0.9(即超过这个阈值的项集都为高频繁项集),置信度为0.8(置信度越高,可信度越高),利用FP-growth算法得到的高频繁课程项集如图2 所示。
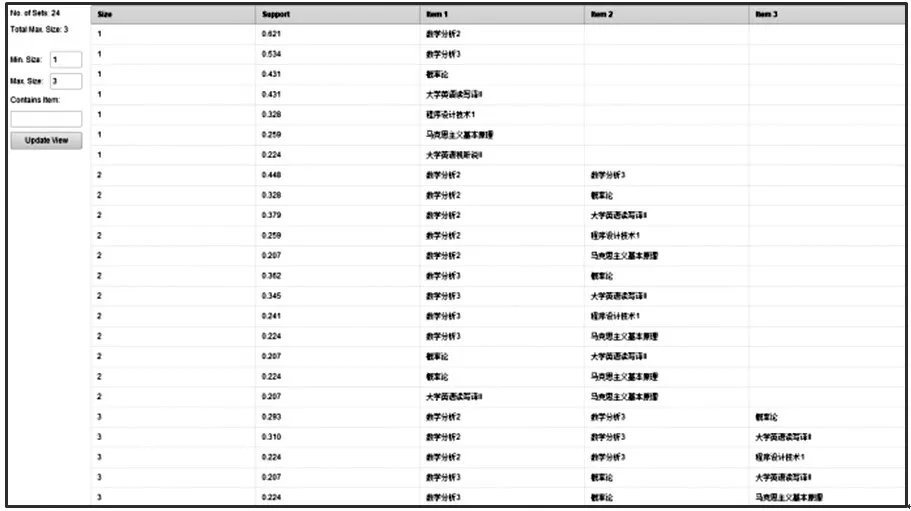
图2 高频繁项集
将图2 中的频繁项集按照由高到低的顺序进行排序,从图1 中可以得出:<数学分析2>、<数学分析3>、<概率论>等为频繁1 项集;<数学分析2,数学分析3>、<数学分析2,概率论>、<数学分析2,大学英语读写译II>等为频繁2 项集;<数学分析2,数学分析3,概率论>、<数学分析2,数学分析3,大学英语读写译II>、<数学分析2,数学分析3,程序设计1>等为频繁3 项集。
利用FP-growth 算法获取到的关联规则在结果窗口展示,如图3 所示,图3 将所有的关联规则都一一呈现出,第一至第九列分别表示为规则的先导、规则的后继、支持度、置信度、增益、提升度、确信度信息。
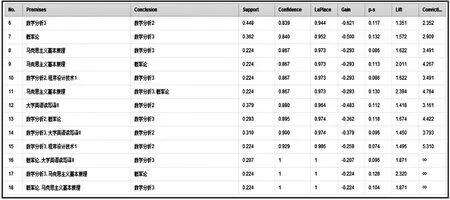
图3 最终生成的关联规则
关联规则分析的主要用途是找到课程间的关系。因此,直观地反映出课程间的联系,如表1 所示,表1 展示了课程间关联规则的文字描述。
从表1 中可以看出,课程之间的关联规则。例如,从表1 中可以得出概率论成绩好的学生,数学分析3 成绩也较好,这条规则的置信度为0.84;高等代数2 成绩差的学生,数学分析3 成绩亦差,该关联规则的置信度为0.96,置信度越高,表示可信程度越高。同理,采用FPgrowth 算法可以得到若干条关联规则,文中不再一一罗列。从得出的关联规则中,可以容易得到各门课程之间的关系。教师从课程的关联规则中,可在授课以前预测课程的整体学习情况并给予及时的干预和指导,学生也可依据课程间的关联规则,对课程学习效果做事先评估和预测,以便在今后的学习中做到有的放矢。
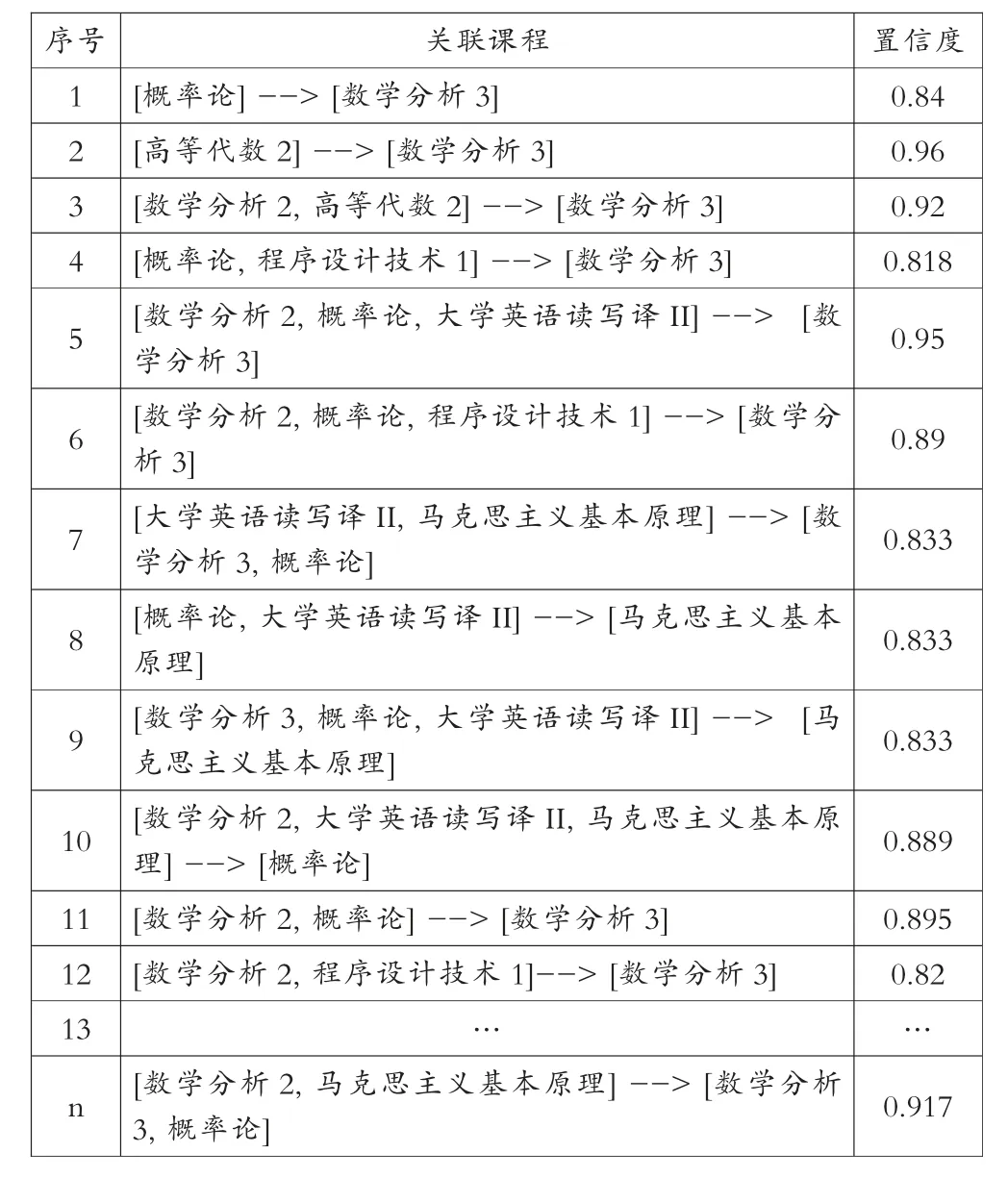
表1 课程间的关联规则
课程间的关联规则不仅可以以文字的形式进行描述,同样也可以用交互图的形式进行展示出,课程间关联规则的交互图展示如图4 所示。
此处只列出部分课程间的关联关系交互图。教学管理者可以此为参考,结合实际情况可对课程顺序进行调整并对学生进行重点培养与帮扶。例如,教学管理人员可根据找出的课程间关联规则,明确下一步的教学方向,并合理制订教学计划。同时,教学管理人员可将先导课程安排在后续课程前进行教学,这样不仅减轻了教师上课的压力,而且也可以使学生更容易接受学习知识,进而激发学生的学习热情,为学校培养人才提供有力帮助。学生结合课程间的关联结果可分析个人成绩及时预测某门课程成绩可能会较低,及时采取补救措施,加大一些课程的投入力度,以便更好地完成学业。
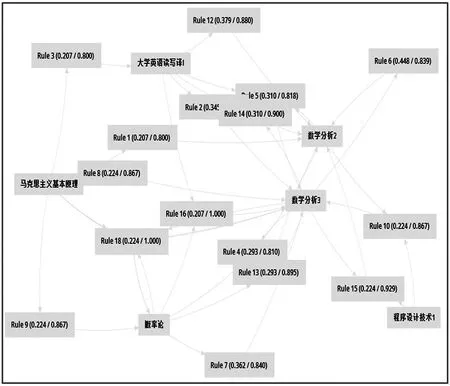
图4 关联规则的交互图展示
四、结束语
本文介绍了关联规则的基本知识,对FP-growth 算法做了详细的介绍,并以教务系统中的课程成绩等数据为基础信息,运用数据挖掘中的FP-growth 算法发现隐含在课程中的潜在、有价值的信息,从而找出课程之间的关联关系。从课程间的关联规则中,不仅可以为学生课程学习提供依据,促使学生顺利完成学业,同时,还可以使教务管理人员依据课程间的关联关系,结合实际情况对课程进行合理调整并对学生进行重点培养与帮扶,还可以为开设课程提供合理决策依据,进而提高教学质量。
猜你喜欢
计算机工程与应用(2022年15期)2022-08-09
小型微型计算机系统(2022年4期)2022-05-09
核科学与工程(2021年4期)2022-01-12
科技视界(2021年13期)2021-07-12
大学(2021年2期)2021-06-11
长江丛刊(2018年3期)2018-11-14
计算机与数字工程(2018年10期)2018-10-23
天津科技大学学报(2018年4期)2018-08-22
计算机应用(2018年5期)2018-07-25
计算机与数字工程(2017年2期)2017-03-02
