
旺业甸林场人工林生物量遥感反演研究
2019-10-10 06:07蒋馥根龙江平蒋治浩雷思君
中南林业科技大学学报 2019年10期
蒋馥根,孙 华,林 辉,龙江平,蒋治浩,雷思君
(1.中南林业科技大学 林业遥感信息工程研究中心,湖南 长沙 410004;2.林业遥感大数据与生态安全湖南省重点实验室,湖南 长沙 410004;3.南方森林资源经营与监测国家林业与草原局重点实验室,湖南 长沙 410004)
森林是全球生态系统的主体,是研究全球碳平衡及气候变化的重要基础[1-2]。森林生物量能直接展示森林生态系统健康状况,是森林生产者物质生产量的集中体现,是森林资源合理利用、改善生态环境的重要基础[3-4]。准确、快速测算森林生物量对提升森林资源调查效率、掌握森林生态系统质量具有重要意义[5-8]。
传统的样地调查法成本高昂、时间长、费时费力,遥感技术具有快速、实时、动态、大范围的特性,使森林生物量实现动态监测成为可能[9-11]。随着遥感技术和森林资源调查技术的发展,以遥感数据作为数据源,利用各种模型对研究区进行生物量反演已成为常用的生物量估测方法[12-14]。常用的模型一般包括经验模型和非参数模型,经验模型需要设置的参数十分简单,但是模型的模拟结果容易产生过低或过高估计。非参数模型不受总体分布的限制,可以广泛地应用于不同类型的总体,能一定程度地减小偏差、提高预测精度、了解样本序列的动态结构。作为非参数模型中新兴起的、高度灵活的一种机器学习算法,随机森林(Random forest,RF)在森林资源调查方面具有较大的优势[15]。汪康宁[16]利用GF-1 影像,结合不同窗口大小下的纹理特征信息,建立了基于随机森林的蓄积量反演模型,结果表明随机森林算法在蓄积量估测上效果良好。胡凯龙[17]在大兴安岭生态站进行样地实测调查,通过随机森林模型证明了利用LiDAR 数据进行碳储量估测是可行的。在森林生物量估测方面,Landsat 5 TM 数据结合随机森林模型在估测江山市公益林[18]和景谷县思茅松[19]生物量时表现良好,模型精度要优于其他模型,估测效果较好。
以旺业甸林场人工林为例,利用Landsat 8 OLI 遥感数据,采用随机森林回归模型、多元线性逐步回归、kNN 回归模型[20]和地理加权回归模型[21]进行生物量反演,开展模型精度比较与评价,并对研究区的生物量进行了反演。
1 材料与方法
1.1 研究区概况
旺业甸林场位于喀喇沁旗西南部,地理位置118°09′~118°30′E,41°21′~41°39′N。地形以山地为主,海拔500~1 890.9 m。属温带大陆性季风气候,冬季寒冷干燥,夏季温暖多雨,年均气温3.5 ℃~7 ℃。林场内主要为人工林,树种主要为落叶松和油松,蓄积量62 万 m3,年生长量近3 万 m3,是一个集森林经营、木材加工、苗木生产和旅游开发于一体的综合性林场。研究区位置如图1所示。

图1 研究区位置图及样地分布Fig.1 Location map and plot distribution of the study area
1.2 样地数据与遥感影像处理
在研究区内设置25 m×25 m 标准样地90 个,其中81 个有林地,9 个非林地。样地内主要树种为落叶松和油松。对样地内所有树木进行每木检尺,记录样地坐标、海拔及环境因子等信息。
根据李海奎《中国森林植被生物量和碳储量评估》[22]中不同树种(组)生物量模型,对每个样地的生物量进行计算,样地生物量计算结果及分布如表1所示。研究采用的遥感数据为Landsat 8 OLI数据,获取时间为2017年10月12日,与样地调查时间一致。利用ENVI5.3 软件对Landsat 8 数据进行辐射定标、大气校正和镶嵌和重采样等处理。

表1 样地生物量统计结果Table1 Biomass results of 90 plots
1.3 植被指数计算及特征变量选择
研究共选取了Landsat 8 中7 个单波段反射率、两波段及三波段比值植被指数和7 个常用的植被指数,共计161 个遥感因子,植被指数计算公式如表2所示。
利用统计软件R 语言计算所有因子与生物量之间的Pearson 相关系数(Pearson correlation coefficient)矩阵。选择与生物量在0.01 显著水平上显著相关的变量开展变量筛选。为了保证变量筛选的有效性,引入方差膨胀因子(VIF)进行变量共线性分析。对共线性诊断后保留的显著变量应用逐步回归模型进行变量筛选,逐步回归的最终变量用于生物量模型反演与方法比较。
随机森林作为一种非参数集合建模方法,可以有效地构建大量的回归树用于预测。另外,随机森林能够提供变量的重要性排序,这对从众多特征变量中选取适合反演的特征变量尤其有用。利用R 语言中Random forest 函数对161 个特征变量进行重要性排序,选取重要性高的变量同时用于生物量反演模型建模,将建模结果与Pearson 相关系数特征变量选择法进行比较。

表2 植被指数计算公式Table2 Formulas of the vegetation index
1.4 随机森林模型
随机森林模型与其他常用模型相比,在学习过程、误差平衡以及变量重要性评估等方面具有优势[15]。研究选择R 语言软件中的Random forest函数,编写随机森林生物量反演程序,并导入旺业甸生物量样地数据与Landsat 8 影像进行空间模拟。采用留一交叉验证(Leave-one-out cross validation)方法对模拟结果进行精度验证,以保证尽可能多的样本进入模型,提高模型的可靠性。
1.5 生物量反演与精度检验
选择决定系数[24](R2)、均方根误差[24](RMSE)、估测精度(Estimation accuracy,EA)作为精度评价的指标。估测精度(EA)为:

2 结果与分析
2.1 变量选择
2.1.1 Pearson 相关系数法
经过相关系数矩阵计算,在0.01 水平上相关性大于0.5 的因子共56 个,相关系数最高的前5个 因 子 为SR627、SR637、SR647、SR64、SR213,分 别为:0.776、0.761、0.730、0.702 和0.657, 说 明短波红外光和近红外区间波段组合得到的植被指数与生物量的相关性显著,但同时要考虑变量之间的共线性不能过大,采用方差膨胀因子VIF 指数判断,VIF 应小于10。选择相关性较高的因子,采用多元逐步回归模型建立线性模型进行变量筛选,结合VIF 指数,得到变量为SR51、RGVI 和SR627。
得到多元线性回归模型方程为:
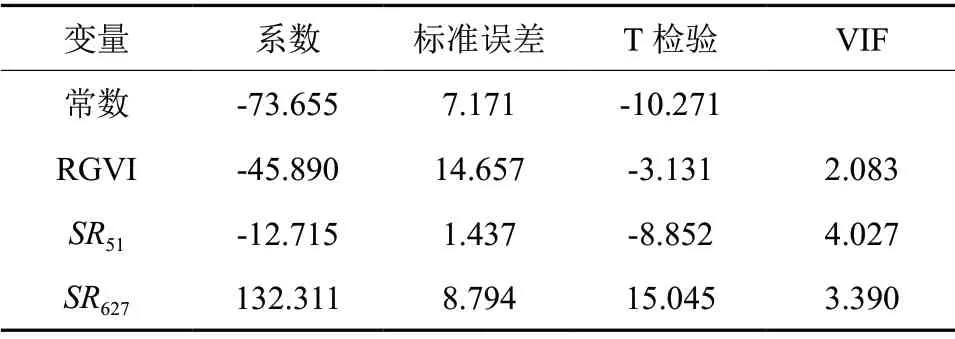
表3 多元逐步回归模型统计量Table3 Multiple linear regression model statistics
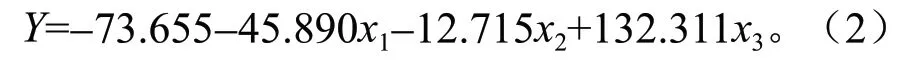
式中:x1—RGVI,x2—SR51,x3—SR627,Y—生物量。
由式(2)可以看出,生物量与RGVI 和SR51呈负相关,与SR627呈正相关。模型的决定系数R2为0.65,RMSE 为9.01,EA为72.88%。
2.1.2 随机森林法
利用统计软件R 语言中RandomForest 函数对计算的161 个特征变量进行重要性排序,重要性最高的3 个特征变量为SR637、SR627、SR647,重要性高的变量基本与Pearson 相关系数较高的变量一致。选取SR637、SR627、SR647用于生物量反演模型建模,将建模结果与Pearson 相关系数特征变量选择法进行比较。
2.2 模型结果及精度比较
利用随机森林法和Pearson 相关系数法分别进行特征变量选择,选取合适的变量,结合多元线性逐步回归、地理加权回归模型、kNN 模型和随机森林模型分别建立反演模型,并对模型进行精度评价。选择R2,RMSE 以及EA 等3 个指标进行不同模型预测结果的比较与分析,结果如表4~5 所示。

表4 不同模型预测结果(随机森林法)Table4 Prediction results based on different multiple models (Random forest method)

表5 不同模型预测结果(Pearson 相关系数法)Table5 Prediction results based on different multiple models (Pearson correlation coefficient method)
利用Pearson 相关系数法进行特征变量选择的最终模型结果精度(表5)整体优于随机森林法(表4)。两种变量选择方法各自建立的4 种模型中,随机森林模型均为效果最好,但Pearson 相关系数法建立的随机森林模型精度(R2=0.72,RMSE=8.12,EA=76.54%)显著优于随机森林法(R2=0.63,RMSE=9.31,EA=68.41%)。最终利用Pearson 相关系数法选择的特征变量进行生物量反演。
利用Pearson 相关系数法结合Landsat 8 OLI影像建立的4 种模型中(表5),随机森林模型效果最好,决定系数R2为0.72,RMSE 为8.12,EA=76.54%;线性逐步回归模型次之,R2为0.65,RMSE 为9.01,EA=72.88%;其次是kNN 回归模型,当k=3 时模型效果最好,R2为0.59,RMSE 为9.75,EA=74.89%;地理加权回归模型效果最差,R2为0.58,RMSE=13.75,EA=53.95%。随机森林模型的R2相对于地理加权回归模型提高了19.4%,RMSE下降了40.9%,EA提高了22.59%,效果明显。
2.3 残差分析
利用4 种模型预测得到的样地预测值与实测值分别进行残差计算,得到残差如图2所示。
由图2可知,多元线性逐步回归模型残差大部分都分布在X 轴下侧,随机性较差,且残差较大的样地较多,效果较差;地理加权模型存在过低估计现象,和kNN 回归模型一样残差绝对值大于20 的数量较多,说明模型拟合的效果一般;随机森林模型残差大于20 的样地较少,残差分布于X 轴两端,基本呈随机、无规律分布,效果最好。随机森林模型在4 个模型中残差分布情况最好,模型拟合度最高,误差最小,预测精度最好,是最优生物量反演模型。
2.4 生物量反演
以Landsat 8 OLI 影像为数据源,结合旺业甸林场样地实测数据,利用随机森林模型对研究区进行生物量反演,反演结果如图3所示。
研究区西北部及中部、北部地区生物量实际分布较少,这些区域为海拔较低的区域,人为活动较多,植被覆盖较少;东南部及整个南部地区植被生长情况较好,森林覆盖率高,郁闭度大,蓄积量和生物量也高。随机森林模型反演结果显示,西北部及中部、北部地区生物量分布较少,东南部与南部地区生物量分布较多,与研究区实际生物量情况分布基本一致,整个研究区反演结果效果较好,能满足反演需求。
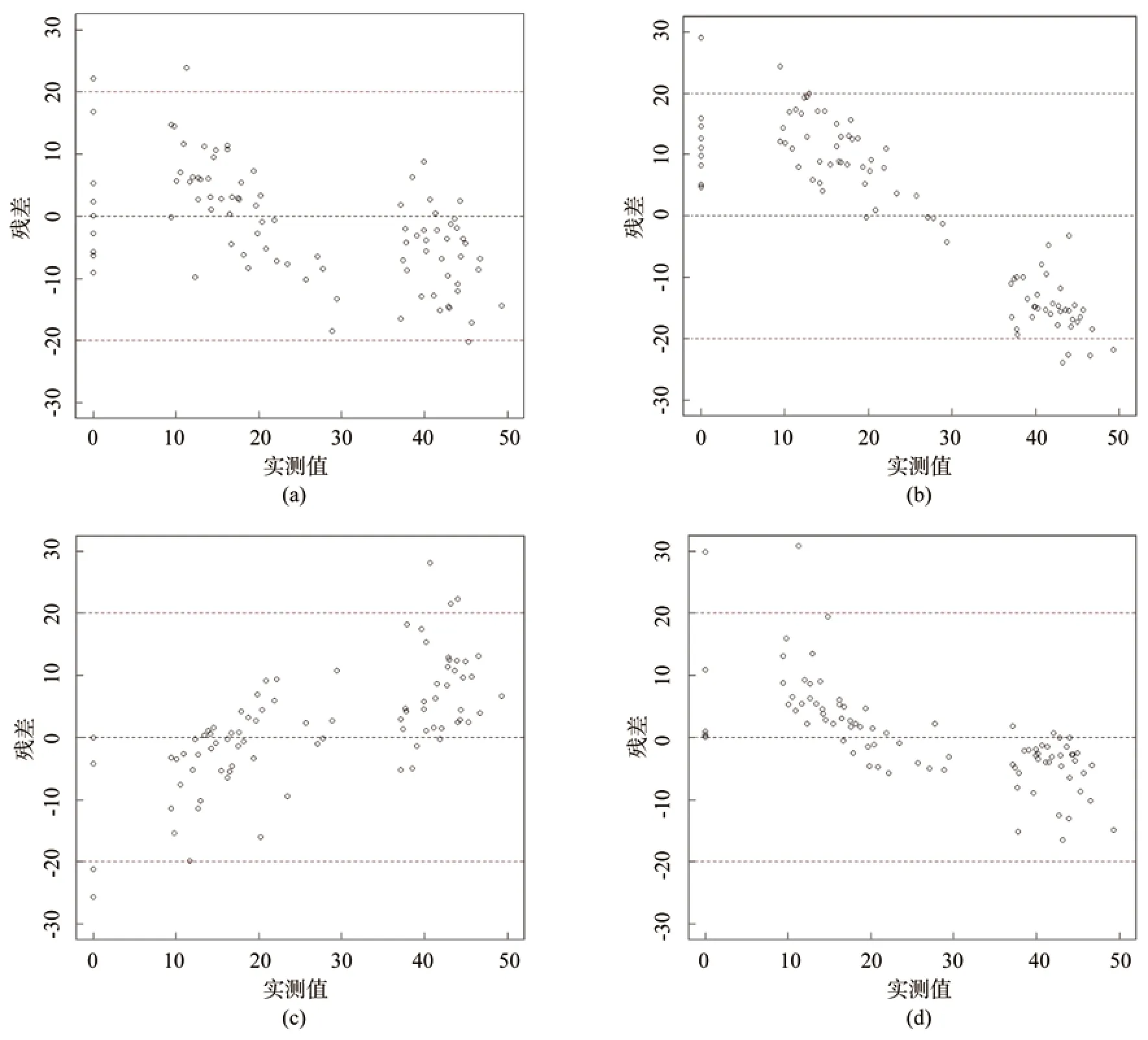
图2 4 种模型样地残差Fig.2 Plot residuals of four models

图3 研究区生物量反演图Fig.3 Biomass inversion of study area
3 结论与讨论
3.1 讨 论
1)研究使用的Landsat 8 卫星是2013年发射的陆地资源卫星,空间分辨率为30 m,与样地大小基本匹配。张雅[23]、徐婷[24]等分别以Landsat 8 影像为数据源,利用二次多项式模型和多元逐步回归模型进行生物量反演,取得了较好的结果,说明利用Landsat 8 数据进行生物量反演是可行的。
2)利用Pearson 相关系数法进行特征变量选择的最终模型结果的精度整体优于随机森林法。随机森林法能对所有特征变量进行重要性排序,但是并不能提供合适的变量组合。但Pearson 相关系数法利用多元逐步回归分析能最大的利用所有变量组合,通过不断的反复筛选,最终选出使模型拟合度较高,误差较低的变量组合。
3)在提取的161 个植被指数中,相关系数最高的前5 个因子为SR627、SR637、SR647、SR64、SR213, 分 别 达 到 了0.776、0.761、0.730、0.702和0.657。考虑变量间的共线性,得到最优变量为SR51、RGVI 和SR627。变量选用的指数利用了Landsat 8 影像的7 个波段,信息量丰富。
一般来说,选择进入模型的变量数越多,模型的拟合度就会越高,但是模型预测产生的估测误差也会随之增加。张伟[18]和孙雪莲[19]分别计算了植被指数和纹理因子作为变量进行计算,最后分别选取了9 个和5 个以上的变量进入随机森林模型参与建模,最终得到的预测精度都在70%以上,取得了较好的效果。本研究共选取SR51、RGVI 和SR627等3 个变量,选择的变量较少、变量的VIF 指数较小,且模型精度较高,反演效果较好。
3.2 结 论
以旺业甸林场样地实测数据结合Landsat 8 OLI 影像,利用多元线性逐步回归、地理加权模型、kNN 回归模型和随机森林模型对研究区进行生物量反演,结论如下:
1)利用Pearson 相关系数法进行特征变量选择要优于随机森林法。计算所有特征变量的Pearson 相关系数矩阵,通过多元线性逐步回归结合VIF 指数选取特征变量。同时利用随机森林程序对所有特征变量进行重要性排序,选取重要性较高的特征变量作为进入模型的变量。结合多元线性逐步回归、地理加权回归模型、kNN 模型和随机森林模型分别建立反演模型,发现利用Pearson 相关系数法进行特征变量选择的最终模型结果的精度整体优于随机森林法。
2)Landsat 8 OLI 影像用于生物量反演的最佳变量为SR51、RGVI 和SR627。利用Landsat 8 影像光谱信息提取植被指数,植被指数中包括单波段植被指数、两波段比值、三波段比值及7 个常用植被指数等,共161 个植被指数作为模型变量,计算所有变量与生物量之间的Pearson 相关系数。相关性系数最高的前5 个因子为SR627、SR637、SR647、SR64、SR213,分别为0.776、0.761、0.730、0.702 和0.657。结合VIF 指数,最终选取SR51、RGVI 和SR627作为模型变量。
3)随机森林模型预测效果优于其他3 个模型。在所有通过Landsat 8 OLI影像建立的4种模型中,随机森林模型模型拟合度最高,误差最小,预测精度最好。随机森林模型决定系数R2最高,为0.72,RMSE=8.12,EA=76.54%;线性逐步回归模型次 之,R2为0.65,RMSE=9.01,EA=72.88%;kNN 回 归 模 型 的R2为0.59,RMSE=9.75,EA=74.89%;地理加权回归模型最差,R2为0.58,RMSE=13.75,EA=53.95%。
4)随机森林模型生物量反演结果与研究区实际生物量情况分布一致。研究区西北部及中部、北部地区人为活动较多,植被分布稀疏,生物量分布较少;东南部及整个南部地区植被生长情况较好,生物量分布较多。整个研究区反演结果较好,能满足反演需求。
猜你喜欢
中等数学(2022年5期)2022-08-29
贵州畜牧兽医(2022年3期)2022-06-28
草业科学(2022年3期)2022-03-26
成都信息工程大学学报(2021年5期)2021-12-30
现代园艺(2021年23期)2021-12-01
空间科学学报(2021年4期)2021-08-30
农业机械学报(2021年8期)2021-08-27
新农业(2020年18期)2021-01-07
现代园艺(2020年19期)2020-10-02
中等数学(2020年2期)2020-08-24
