
模糊指数熵组合方法的信息系统不确定性度量
2019-09-19 09:38
测控技术 2019年6期
(广东技术师范大学天河学院 计算机科学与工程学院,广东 广州 510540)
粗糙集理论是学者Pawlak[1]提出的一种有效处理不确定性数据的数学工具,它通过不可区分关系来对数据对象进行分类,并引入上近似和下近似来刻画数据的不确定性程度,由于该理论不需要数据集之外的任何先验信息,目前已广泛运用于机器学习[2]、决策分析[3]和数据挖掘[4]等领域。
粗糙集理论是度量信息系统不确定性程度的一个有力工具,而不确定性程度是信息系统分类能力的一个重要体现。Pawlak[1]采用近似精度和粗糙度来作为信息系统的不确性度量,Liang等人通过信息熵[5]和近似质量[6]来度量不确定性度,此外,还有其他很多的度量方法被提出[7-8]。
然而在目前的信息系统不确定性度量中,大多数度量方法都是比较单一的,不同的度量方法都有着一定程度的缺陷,而将多种度量方法进行各取所长地融合,将会得到更好的度量效果,Chen[9]等人通过将粗糙度与邻域熵结合提出邻域信息系统的不确性度量方式,Jiang[10]等人提出一种相对决策熵的度量方法,何松华[11]等人通过邻域近似精度和邻域粒度结合提出一种新的度量方法,并用于属性约简中。
本文在此基础上,针对各种不确定性度量的优劣,将代数角度的粗糙度度量[1]和信息论角度的模糊指数熵[12-13]结合起来,并加入依赖度[1],提出一种新的信息系统不确性度量方法——模糊指数熵组合度量,并分析了相关的性质。实验结果表明,所提出的模糊指数熵组合度量方法在各个UCI数据集上均表现出了更好的不确定性度量效果。因此所提出的度量方法更具优越性。
1 基本理论
1.1 粗糙集
定义1[1]在智能信息处理领域中,信息系统被描述成一个四元组的形式,即IS=(U,A,V),其中的U是一个非空的有限集合{x1,x2,…,xn},被称为论域,A称为全体属性集{a1,a2,…,an},V为全体属性集的值域,满足V=∪Va,其中Va为属性a∈A的值域,对象x∈U在属性a下的取值可表示为a(x)。此外,当属性集A满足A=C∪D,其中C、D分别被称为信息系统的条件属性和决策属性,此信息系统又被称为决策信息系统(DIS)。

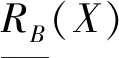
定义3[9]对于信息系统IS=(U,A,V),∀B⊆A,则X⊆U基于B的粗糙度ρB(X)定义为
根据定义3显然有0≤ρB(X)≤1,粗糙度ρB(X)反映了近似对象集X在B下的粗糙程度。
定义4[9]设决策信息系统DIS=(U,C∪D,V,f),对于∀B⊆C,则决策属性集D基于B的依赖度γB(D)定义为

1.2 模糊集
在文献[14]中,Zadeh提出模糊集的概念,把考察的对象x及反映它的模糊概念X作为一定的模糊集合,建立隶属函数μX(x),这样更加适合反映事物之间的模糊关系。模糊集X表示为
式中,μX(x)称为X的隶属度函数。
另外,为确保调查研究的真实、有效、客观、全面,本课题组成员奔赴体校,并对部分运动员、教育管理人员等就文化教育的现状、管理等问题进行了实地调研和访谈。
Pal[12]在传统信息熵的基础上提出指数熵,并将指数熵引入模糊集中,其定义如下所述。
定义5[12]设模糊集X,x关于X的隶属度函数为μX(x),那么基于X的模糊指数熵定义为
(1-μX(xi))·exp(μX(xi))-1]
在文献[13]中,Wei指出运用模糊指数熵可以作为信息系统的不确定性度量。
2 基于信息系统的模糊指数熵组合度量方法
在粗糙集理论中,粗糙度通过边界域的大小展示了近似对象在信息系统中的不确定性度[1,7-10],因此,一直被广泛运用于信息系统的不确定性度量。但是粗糙度只是通过边界域的视角来分析问题,然而在粗糙集理论中,正区域包含着许多重要的信息,也间接体现了信息系统的不确定性[8,10],因此通过粗糙度结合依赖度来作为信息系统的不确定度量是很有必要的。
文献[13]指出,模糊指数熵作为信息熵的一种推广,在信息系统的不确定性度量中具有很好的效果,因此本文通过将模糊指数熵与粗糙度和依赖度结合,提出一种新的度量方法——组合模糊指数熵,通过这种新的方法来作为信息系统的不确定性度量。



ComFEP(D)=ComFEQ(D)



证明:由性质3可以直接得到。
3 实验分析
为了验证所提出的信息系统不确定度量方法更具优越性,本实验从UCI机器学习数据库中获取了5个数据集进行实验分析,数据集的详细信息如表1所示。其中数据集1~数据集4均为符号型属性,数据集5为数值型属性。由于所提出的组合模糊指数熵的度量方法只适用于符号型属性,这里将数据集5中的数据通过等距离散化方法进行离散化。

表1 UCI数据集
为了做对比,又分别使用了目前已有的两种度量方法进行实验,分别是粗糙度度量[1]和模糊指数熵度量[13],3种不确定性度量方法在5个数据集上的实验结果如图1~图5所示。
通过图1~图5可以看出,随着选择的属性增多,3种度量方法对于数据集的不确定性度量值均逐渐减小,这意味着随着属性的增加,信息系统的不确定性度在减小,因此这3种方法对于信息系统的不确定性度量都是有效的。但是仔细观察可以发现,在图1中,数据集balance的属性从1增加到2的时候,其粗糙度度量值保持不变,这种情形体现了粗糙度度量未能有效区分系统在属性数目不同时系统分类能力的不同,类似地,其他数据集也出现相同情形。同时对于指数熵度量,在各个数据集中也出现了类似的问题。而在组合模糊指数熵度量方法中,则较少出现这样的情形,因而组合模糊指数熵能更精准地评估不确定性,从而更精确地刻画系统属性数目不同时系统分类能力的不同。因此实验结果表明,组合模糊指数熵对于信息系统的不确定性度量具有更好的评估效果,相比于其他方法更具优越性。

图1 3种方法在数据集balance实验结果

图2 3种方法在数据集car实验结果
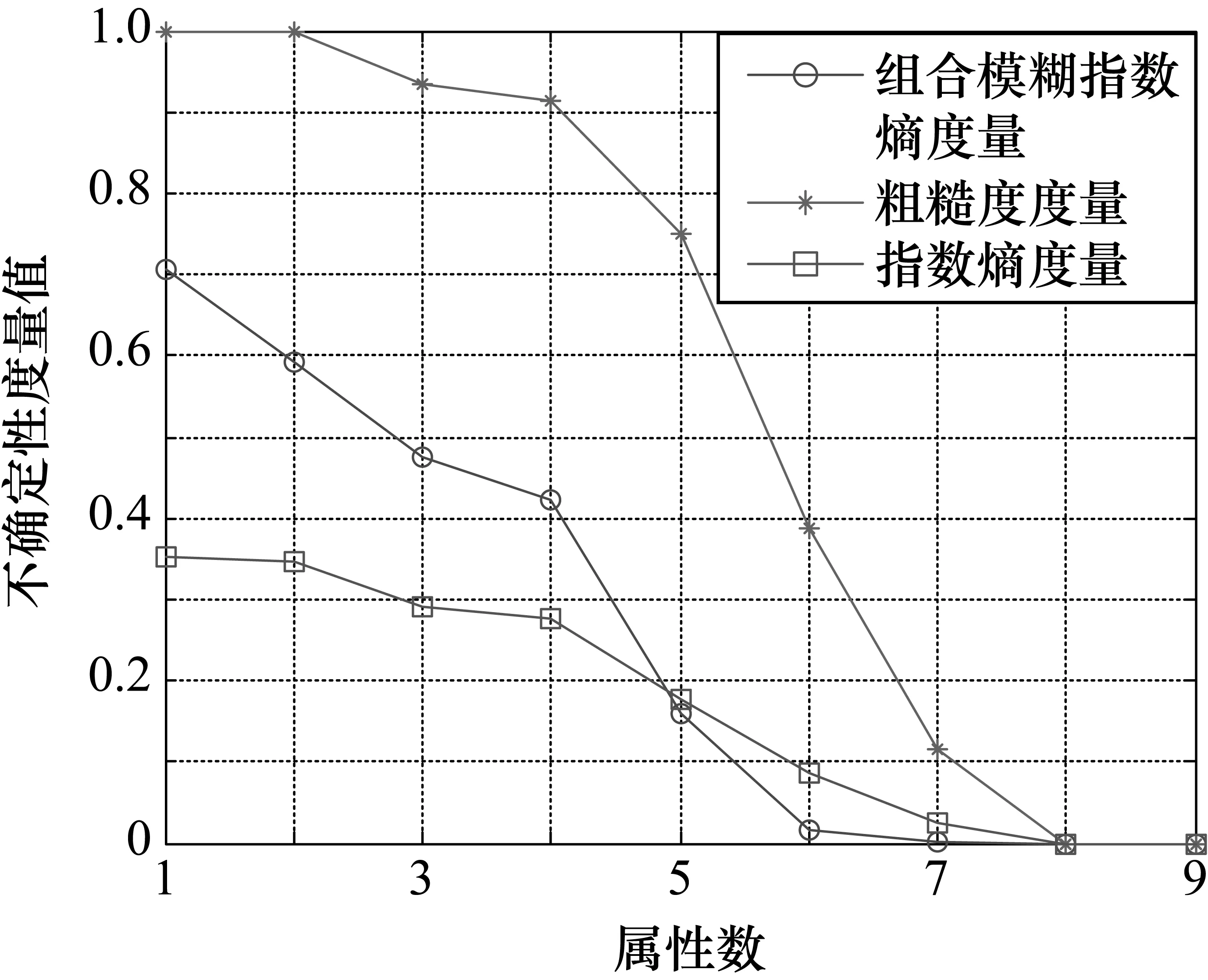
图4 3种方法在数据集tic实验结果

图5 3种方法在数据集wine实验结果
4 结束语
为了展现多种不确定性度量方法的优越性,通过融合粗糙度和模糊指数熵这两种方法,并加入依赖度提出了一种新的信息系统不确性度量方法,这种方法通过多个视角对信息系统的不确定性进行评估,发挥了各自在度量方面的优点,因而具有更好的评估效果。另外,所提出的不确性度量方法可以作为信息系统属性重要度的评估方式,因此接下来可以构建相应的特征选择方法。
猜你喜欢
成都信息工程大学学报(2022年4期)2022-11-18
法律方法(2022年2期)2022-10-20
上海文化(文化研究)(2022年3期)2022-06-28
英语文摘(2019年6期)2019-09-18
五邑大学学报(自然科学版)(2019年3期)2019-09-06
中国外汇(2019年7期)2019-07-13
模具制造(2019年4期)2019-06-24
玩具世界(2019年6期)2019-05-21
江西教育B(2019年2期)2019-04-12
制造技术与机床(2017年4期)2017-06-22
