
基于信任关系和项目流行度的矩阵分解推荐算法
2019-09-13 06:35李卫疆郑雅民
计算机应用与软件 2019年9期
李卫疆 郑雅民
(昆明理工大学信息工程与自动化学院 云南 昆明 650000)
0 引 言
随着互联网的飞速发展,推荐系统得到人们越来越多的关注,提供有效的用户个性化推荐是目前研究的热点问题,通过对用户历史行为的分析,预测用户偏好。近年来,结合用户社交网络的推荐算法目前已经得到广泛的应用,TidalTrust通过在信任网络中找到从用户到每个其他用户的最短路径,然后将每个用户的信任值聚合到与A直接相邻的用户进行推荐[1]。Li等基于奇异值分解的方法,根据人际关系中的六度分隔理论填充用户信任矩阵,再通过用户之间的信任度进行相关推荐[2]。用户的社交网络不仅可以有效缓解推荐中冷启动的问题,还可以通过好友推荐增加推荐的信任度。
但在社交网络中,好友关系不是基于共同兴趣产生的,用户好友的兴趣往往和用户的兴趣不一致。同时,信任网络通常是一组不相交的子图,信任无法从一个子图传播到另一个子图上,如果一个项目没有被子图中的任何用户评分,那么它就不会被推荐给子图中有可能感兴趣的用户。因此,仅仅基于用户之间的信任关系进行推荐会存在项目的覆盖问题。同时,推荐算法的覆盖率和准确率存在内在的折中,在提高推荐覆盖率的同时会降低推荐的准确率,反之亦然。
为此,我们提出了一种融合项目流行度和用户信任关系的PopTruMF算法。PopTruMF算法利用矩阵分解的传递性,将用户的信任关系与项目评分视为同一层级,在矩阵分解的过程中,项目和信任关系发生混合,使得信任传递和评分预测同时发生;同时PopTruMF算法根据项目的流行度,对用户评分项目和未评分项目分别进行加权处理,在保证了准确率的基础上,有效改善了以上方法的覆盖率。本文的主要创新点在于:
(1) 在基于信任网络的推荐算法中,提出在不相交的信任网络中进行推荐。
(2) 在基于项目的流行度的推荐算法中,提出项目流行度对用户评分项目和未评分项目有不同程度的影响。
(3) 本文在Epinions数据集上进行了大量的实验,实验结果表明PopTruMF算法在大幅度改善推荐覆盖率的同时,保证了推荐的准确率,能够给于用户更好的推荐结果。
1 相关工作
1.1 矩阵分解
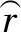
(1)
式中:w0代表缺失数据赋予的统一权重。
1.2 信任网络
美国著名的尼尔森调查表明83%的用户更愿意相信朋友对他们的推荐,因此,基于信任关系的推荐可以更好地模拟现实社会。信任网络是基于信任传递构建的有向图,通过使用用户之间的信任关系和用户的历史行为数据来预测评分,不仅可以提高推荐系统的推荐质量,还可以增加用户对系统的信任度[2,4-6]。
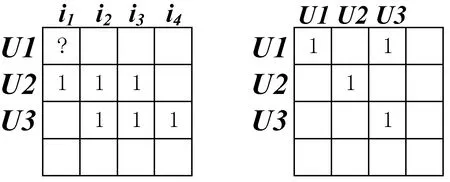
本文构建了一个简单的信任网络实例,如图1所示,其中,节点代表用户,边代表用户之间的信任关系。信任传递是信任网络的一个重要特征,用户可以通过具有直接信任关系的用户作为纽带传递给具有间接信任关系的用户。如图1所示,用户u1对项目i2、i3有历史评分,用户u2对项目i1、i2、i3、有历史评分,用户u3对项目i2、i3、i4有历史评分。因为用户u1和用户u3在相同的信任网络中,通过信任传递我们可以将用户u3偏好的项目i4推荐给用户u1。但由于左侧信任网络子图中没有用户节点对项目i4进行评分,则不能通过信任关系将项目i4推荐给用户u1。
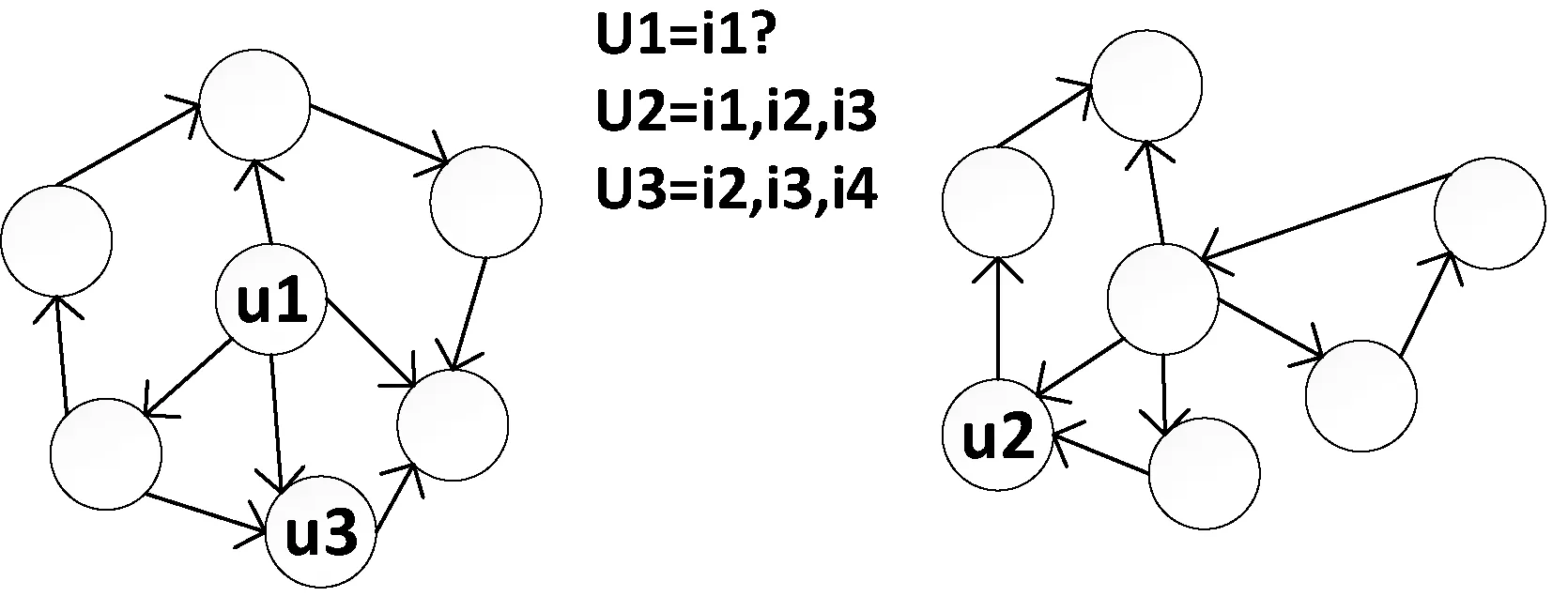
图1 不相交的用户信任网络实例
1.3 项目流行度及数据稀疏问题
类似于头条新闻、微博热榜等根据PV、UV、日均PV或分享率等数据,按某种热度排序推荐给用户,很多应用也以热门排行榜、最热卖排行榜、平均用户评分等形式展示当下流行的项目。项目被用户评分的次数越多,代表项目流行度越高;反之,则越低。作为推荐系统的新用户,或在人很难做出选择的时候,项目的历史评分确实是很有用的参考信息,且人们通常愿意接受流行项目的推荐[6-7]。基于项目流行度的推荐算法,可以深度挖掘用户偏好,给予不同用户个性化的推荐[9]。
郝立燕等基于TopN推荐预测提出,流行度越高的项目,体现用户兴趣的信息越少,相反,流行度越低的项目,体现用户兴趣的信息越可靠,提高了冷门项目的影响力[8]。但是用户-项目评分矩阵中评分项目一般不超过项目总数的1%,更多的是缺失的数据,因此,解决数据稀疏问题通常是提高推荐质量的关键。文献[9]将这些缺失的数据统一假定为无关用户偏好进行建模,极大地减少了建模的工作量,然而这种方法是不现实的,会降低模型的预测性。在此假设的基础上,文献[10]将缺失的数据赋予统一的权重,然后在缺失数据上设置显式先验,当新的用户或项目评分进入系统时,可以及时更新因子,给与符合最新用户偏好的推荐,但这样的假设限制了推荐算法在实际应用中的可扩展性。针对以上问题,参考现有的推荐方法,本文提出了PopTruMF模型。
2 PopTruMF模型
本文首先合并用户-项目评分矩阵和用户-用户信任关系矩阵来构建模型;然后,根据项目流行度的加权策略构建目标函数;最后,通过矩阵分解的方式同时传递信任和推荐项目。
2.1 TruMF算法
2.1.1基于项目节点传递信任
在信任网络中,由于好友关系不是基于共同兴趣产生的,用户好友的兴趣往往和用户的兴趣不一致,而不存在信任关系的用户却具有相似的用户偏好。如图2所示,用户u2和用户u3在不同的信任网络,但对项目i2、i3都有显示反馈,本文认为用户u2和用户u3具有相似的用户偏好,只不过他们不认识对方。
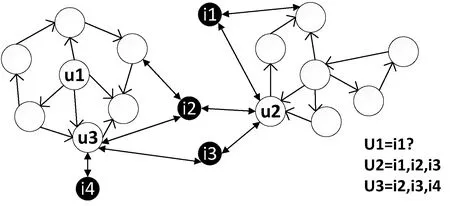
图2 相交的用户信任网络实例
本文将项目作为节点引入信任网络,相似的用户偏好作为不同信任网络子图之间的纽带,用户可以通过项目节点连接不同的信任网络子图。此时,信任网络将不再是原始的信任网络,一个用户节点具有连接用户信任关系和用户相似偏好两种不同的边。用户u2和用户u3通过相似的用户偏好建立连接,项目i1通过项目节点从用户u2传递给用户u3,再通过信任传递从用户u3最终推荐给用户u1。
2.1.2 基于矩阵分解传递信任
为了解决信任网络脱节的问题,首先,通过用户-项目评分和用户-用户信任关系分别构建两个矩阵,如图3(a)、(b)所示。然后,通过合并这两个矩阵来构建模型,如图3(c)所示。在模型中,项目评分和用户之间的信任关系视为同一层级,通过矩阵分解的方式可以同时传递信任和推荐项目。也就是说,给定K个潜在特征向量,每个用户通过这K个特征向量对每个项目进行评分,同时,每个用户通过相同的K个特征向量来信任其他的用户。
(a) 用户-项目 (b) 用户-用户
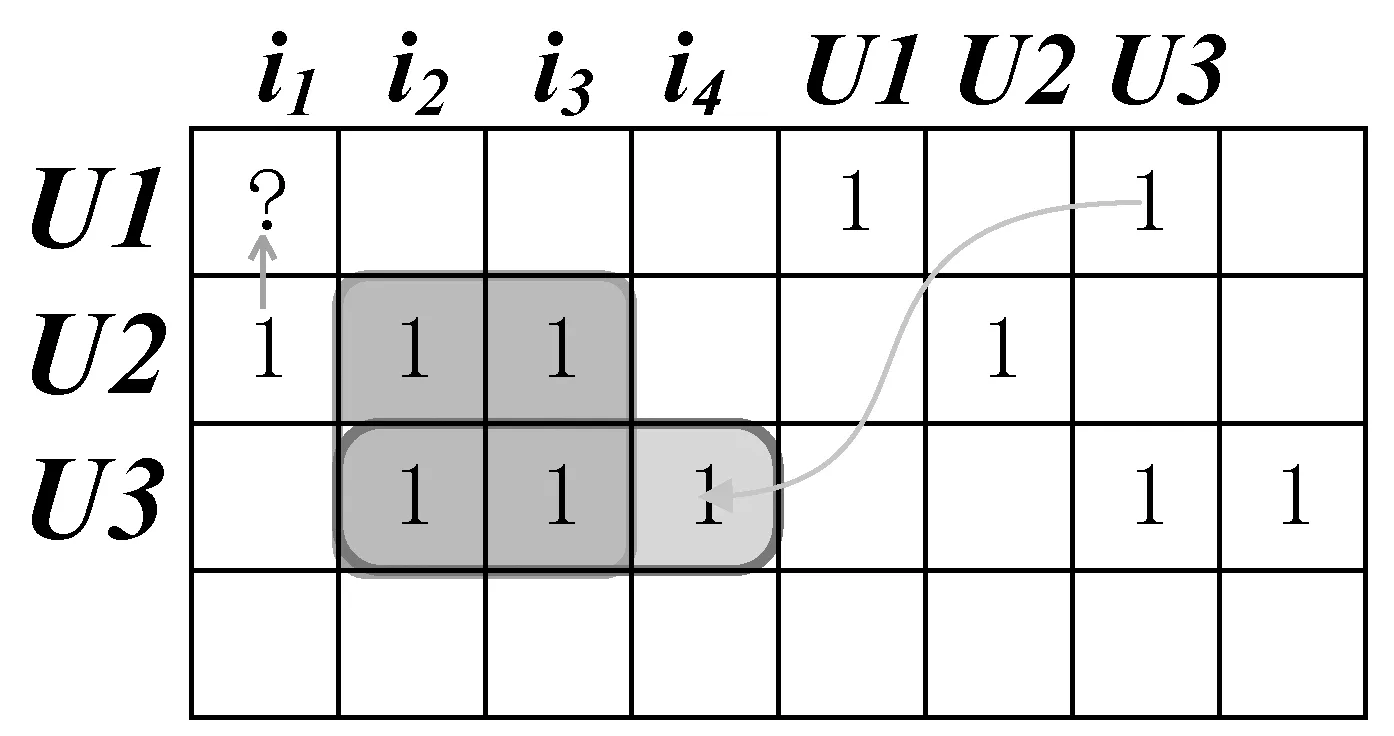
(c) 用户-项目-用户图3 合并评分矩阵和信任关系矩阵
如图3(c)所示,用户u2和用户u3之间不存在信任关系,但对项目i2和项目i3都具有显示反馈,本文认为用户u2和用户u3之间具有相同的特征向量。通过相同的特征向量,用户u2可以将感兴趣的项目i1推荐给用户u3,再通过用户之间的信任关系,最终用户u3可以将项目i1推荐给用户u1,从而解决了个性化推荐中广泛存在的信任网络脱节的问题。
2.2 项目流行度的加权策略
随着Web 2.0的发展,在所有其他因素相同的情况下,流行度较高的项目更有可能被用户认识。本文认为,项目流行度对用户评分项目和未评分项目分别有不同程度的影响。
2.2.1项目流行度对未评分项目的影响
在推荐系统中,缺失数据(未评分项目)是负反馈和未知反馈的混合物,然而区分这两种情况是众所周知的困难。文献[12]提出,在缺失数据中,流行的项目更可能是用户的负反馈而非未知的反馈,因此,在模型训练的过程中应该给予更高的权重。本文引入文献[11]中的一个权重因子:
ci=c0×item_pop(i)
(2)
(3)
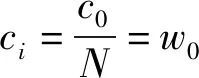
2.2.2项目流行度对评分项目的影响
随着互联网的发展,通过网络传播、媒体曝光、社区讨论等方式,流行度较高的项目,更有可能被用户认识,因此会获得更多偏离用户个人偏好的评分。对于矩阵中评分项目的数据,文献[8]认为项目的流行度越高,用户评分体现用户偏好的信息越少,相反,项目的流行度越低,用户评分体现用户偏好的信息越可靠。参考文献[8],本文提出了一个与项目流行度相关的误差权重因子:
(4)
式中:r=wuirui表示体现用户偏好的项目评分。fi最小为1,此时wui为最大值1。fi越低,wui越大,用户项目评分rui越接近用户偏好评分r;反之,wui越小,用户项目评分rui越偏离用户偏好评分r。
2.3 PopTruMF算法
根据以上分析,本文设计了一个基于项目流行度的目标函数:
(5)
首先,本文对用户项目评分根据项目流行度进行预处理,得到更接近用户偏好的评分r。式(5)中: 第一项代表用户偏好评分预测的误差,在显示评分预测中广泛使用[12];第二项代表缺失数据中负反馈对评分预测的影响[11];第三项代表一个正则项来防止目标函数的过拟合。为了获得目标函数的最小值,本文通过在pik、qku上使用梯度下降的方法训练模型:
(6)
(7)
(8)
(9)
基于项目流行度的加权策略,本文模型训练如算法1所示:
算法1Matrix Factorization
输入:合并矩阵R,潜在特征向量K,预测评分的误差权重wui,缺失数据的权重c0
输出:用户潜在特征矩阵P,项目潜在特征矩阵Q
1. Randomly initializePandQ;
2. for (u,i)∈Rdorui=puqi;
3. while Stopping criteria is not
4. //Update user、item factors
5. fori←1 to len (R)
6. foru←1 to len (R1)
7. fork←1 toK
8.wui,ci←Eq.(2,3,4);
11. fori← 1 to len (R)
12. foru← 1 to len (Ri)
14. fork← 1 toK
16. Ife<0.001
17. break;
18. ReturnP,Q·T;
预测评分由模型训练得到的用户特征向量pu和项目特征向量qi的内积产生。在预测评分构成的新矩阵中,由于信任矩阵部分通常被认为是算法的次要结果,本文对此先进行过滤,再生成最终的推荐列表。本文推荐算法的基本框架如图4所示,主要输入是用户-项目评分矩阵、用户-用户信任矩阵和项目的流行权重。该算法的主要步骤是合并矩阵、引入项目流行度的加权策略、模型训练、预测评分、过滤信任矩阵、生成推荐列表。
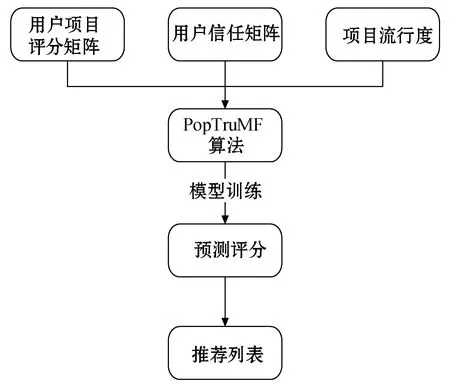
图4 PopTruMF模型基本框架
3 实验结果与分析
3.1 实验设置
数据集 本文采用公开的Epinions数据集,其中包括40 163个用户对139 738个项目的664 824条评分,评分数值在1~5之间,用户之间的信任信息包括487 181条,数据的稀疏度为0.011 845 84%。由于原始数据集的高稀疏性,使得推荐算法在模型训练的过程中存在一定的难度。例如,一半以上的用户只有一个评论。对此,本文按照文献[13]的方法先进行数据过滤,使得本实验中数据的稀疏度为99.89%。
(1) 度量方法 我们采用均方根误差(RMSE)、准确率(precison)、覆盖率(coverage)、F值四个性能指标评估推荐算法的推荐质量。
(10)
(11)
式中:I表示所有物品的集合,coverage表示推荐列表中的物品占总物品数的比例。其中,RMSE的值越小,代表推荐效果越好。由于实际评分和预测评分之间最大差值是5-1=4,本文算法的最差精度为:
(12)
为了更好地评估算法的推荐质量,本文引入F值指标,将准确率和覆盖率结合在一个数字度量中。其中,F值越大,代表推荐算法的总体效果越好。
(13)
(2) 对比方法 将本文算法与下面的算法进行比较,评估各算法的性能。
SocialMF算法[4]基于矩阵分解的方法,结合用户之间的信任关系,学习用户和项目的潜在特征向量,提出每个用户的特征向量依赖于社交网络中他直接邻居特征向量的加权平均。
SocialSVD算法[2]基于奇异值分解的方法,根据人际关系中的六度分隔理论计算用户之间信任度,填充用户信任矩阵,提高了预测的准确率。
TrustWalker算法[5]结合用户之间的信任关系,在信任网络上随机游走以预测项目评分。如果在特定的深度阈值内未找到该项目,则基于相似的项目预测项目评分。
3.2 实验结果及分析
本文采用上述的Epinions数据集,依次对SocialMF算法、SocialSVD算法、TrustWalker算法和本文提出的合并矩阵TruMF算法以及完整的PopTruMF算法做对比实验。在实验中,我们设置潜在特征向量K=25、β=0.01,且所有方法都是用python实现的,以便公平比较所有方法。实验结果如表1所示。
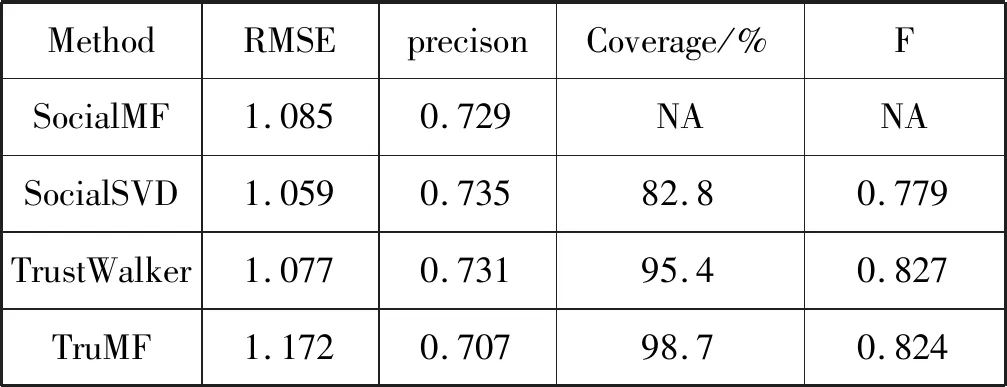
表1 TruMF算法与各算法实验结果
如表1所示,本文提出的TruMF算法的F值最大,推荐效果最好。在现有的推荐算法中,TrustWalker算法是推荐结果覆盖范围最广的方法之一,高达95.4%,而本文的TruMF算法相比TrustWalker算法项目覆盖率略有提高,约98.7%。TruMF算法的覆盖率同样也高于其他两种算法,因为SocialMF算法和SocialSVD算法都是基于信任网络中的信任传递进行推荐,因此存在信任网络脱节的问题。但在准确率方面,TruMF算法分别低于SocialMF算法、SocialSVD算法和TrustWalker算法。
本文结合项目流行度加权策略,在TruMF算法的基础上作出进一步优化,提出PopTruMF算法。其中c0代表缺失数据的总权重,∂控制项目流行度对以上权重的影响。首先,本文将缺失数据赋予的统一权重,即∂=0。如图5所示,当c0取128左右时,RMSE最小,达到预测准确性的峰值,而当c0变小或设置的太大时,RMSE的值显著升高,这说明在TruMF算法中适当考虑缺失数据的必要性。
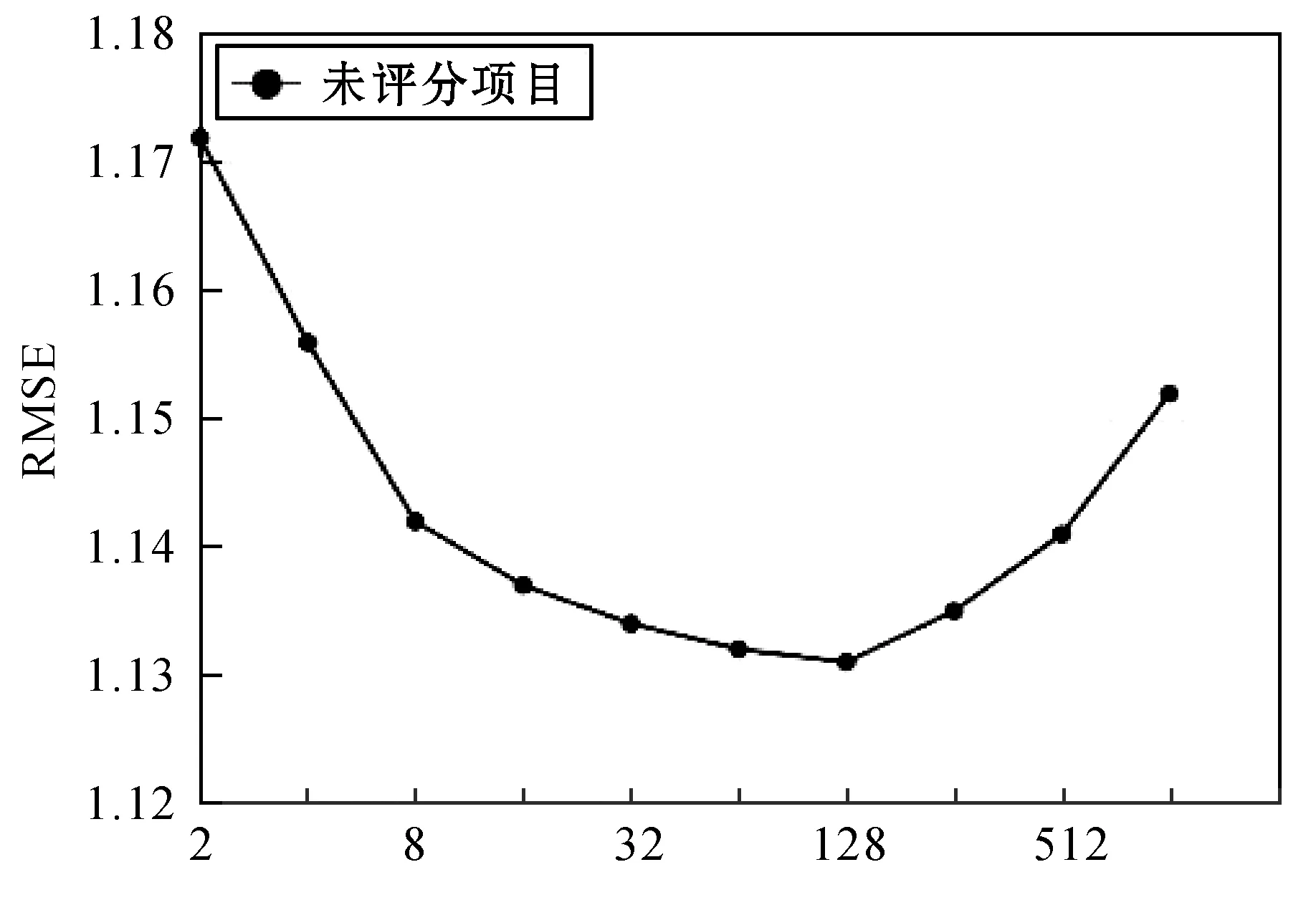
图5 c0(∂=0)
然后,我们将c0设置为128,来观察项目流行度对推荐效果的影响。如图6所示,随着α的增加,RMSE的值会再次减小,到达一个最优值后又会大幅度升高,这说明在TruMF算法中适当考虑项目流行度的有效性。本文设置c0=128、∂=0.4,同时引入项目流行度的误差权重因子wui,适度增加∂,会达到更好的预测效果。如图6所示,根据项目流行度对用户评分项目和未评分项目分别进行加权处理,可以更有效提高推荐算法的准确率。
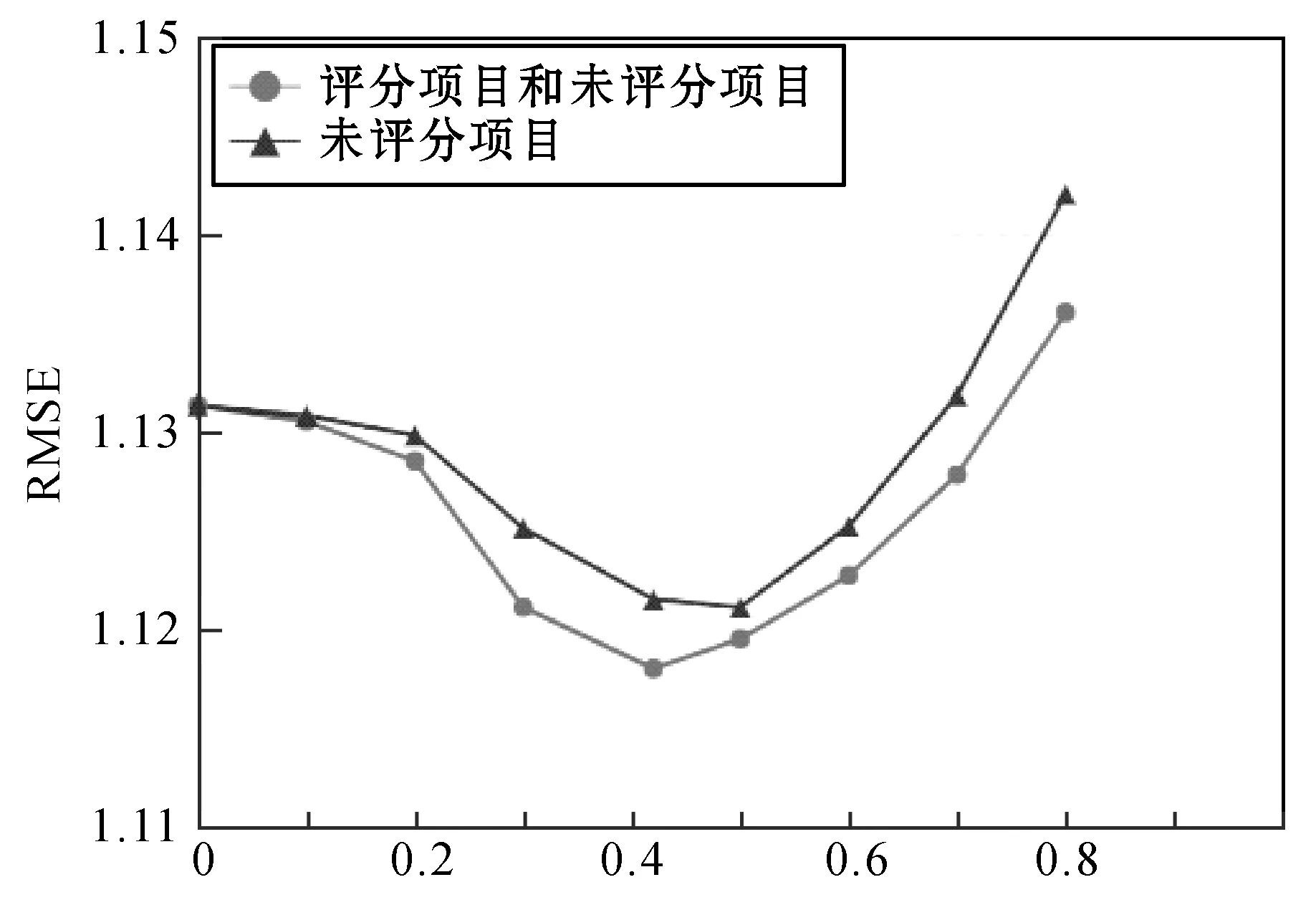
图6 ∂(c0=128)
PopTruMF算法与各算法的实验结果如表2所示。可以看出,PopTruMF算法的F值在TruMF算法的基础上得到进一步的改善,准确率和覆盖率得到了更好的折中。与前几种方法相比,PopTruMF算法虽然损失了5%的RMSE,但在推荐中覆盖项目的范围最广,能够给于用户更好的推荐效果。
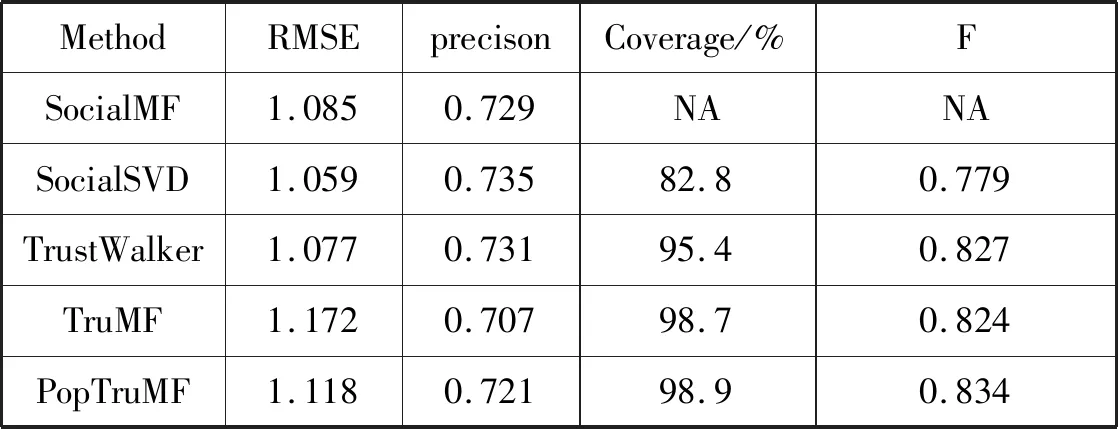
表2 PopTruMF算法与各算法实验结果
4 结 语
针对现有推荐算法在推荐中项目覆盖范围有限的问题(如用户信任网络不相容、项目评分矩阵的高稀疏性、用户个性化推荐存在偏差等),本文提出了一种基于合并用户信任关系和项目流行度的PopTruMF算法,并讨论了如何通过信任关系将项目推荐给不同信任网络的用户,以及在推荐算法中考虑缺失数据和项目流行度的有效性。通过在Epinions上的实验表明,PopTruMF算法在大幅度改善推荐覆盖率的同时,保证了推荐的准确率,能够给于用户更好的推荐效果。
在下一步的研究中,我们将进一步探索项目和用户基于多个潜在特征对个性化推荐的影响,以及通过给与用户实时的推荐,进一步提升模型性能。
猜你喜欢
保定学院学报(2022年2期)2022-04-07
中学生理科应试(2021年11期)2021-12-09
数学学习与研究(2018年15期)2018-11-12
读与写·教育教学版(2017年10期)2017-11-10
桃之夭夭B(2017年2期)2017-02-24
南都周刊(2015年4期)2015-09-10
南都周刊(2015年3期)2015-09-10
南都周刊(2015年1期)2015-09-10
高中生·青春励志(2014年11期)2014-11-25
中学数学研究(2008年11期)2008-01-05
