
智能变电站二次设备多源数据建模与存储方法研究
2019-09-13 03:36肖永立宋亚奇
计算机应用与软件 2019年9期
肖永立 刘 松 见 伟 宋亚奇
1(国网北京检修分公司 北京 100069)2(北京中泰华电科技有限公司 北京 100080)3(华北电力大学控制与计算机学院 河北 保定 071000)
0 引 言
国家电网调控运行“十三五”规划明确提出了开展设备运行大数据分析的要求。变电站二次设备作为对系统监视和控制的重要设备,其自身健康状态的好坏直接关系电网的安全稳定。因此,需要对其进行状态评估,及时发现设备缺陷,减少事故损失。
相关领域学者已经开展广泛的电网设备状态评估、设备的可靠性分析、设备故障诊断和预测等方面的研究[1-3]。研究过程中使用了多种数据分析的模型,如:马尔可夫(Markov)方法[4]、Topsis模型[5]、概率模型[6]、故障树[7]、支持向量机[8]、神经网络[9]、贝叶斯网络[10]等。上述模型和方法均需要一定规模的历史数据作为训练数据,支撑数据训练过程,才能得到有效的评估和识别模型结果。目前,评估和诊断方法逐渐向着数据驱动方式和基于大数据的分析的方向发展[11-12]。
数据建模和存储是进行各类数据分析的前提和基础,直接影响到后期状态评估、故障诊断、查询分析等应用的性能、准确性和可用性。传统电网设备数据的建模和存储方法主要使用范式建模方法和企业级关系型数据库实现物理存储,主要存在的问题是支持的数据规模比较小、存储系统的扩展性较差、查询和复杂数据分析性能低下等。近年来,一些大数据的存储方法和数据处理技术被应用到电力系统中,以Hadoop为代表的大数据技术应用较多。文献[13]利用Hadoop分布式文件系统(Hadoop Distribute File System,HDFS)来存储广域向量测量系统的数据;文献[14]研究了基于HDFS的电网状态监测数据存储方法;文献[15]研究了HDFS上电网设备监测数据的存储优化方法,用以提升监测数据查询的性能;文献[16]则应用Hadoop生态系统中的Hive构建了电力设备状态信息数据仓库;文献[17]为了完成电力设备监测数据的联机分析处理(On-Line Analytical Processing,OLAP),分别讨论并给出了Hive、Impala和HBase三种存储架构和分析方案。上述数据存储和处理方法都是针对一次设备数据开展的,对二次设备数据的建模和存储方法的研究较少。
智能变电站中二次设备的PMS(Production Management System)、OMS(Operations Management System)、监控、缺陷记录等数据来源和类型多样、经年积累下来,数据规模巨大,需要利用大数据技术进行建模、存储和分析。本文提出了一种树状结构的智能变电站二次设备数据的概念模型表示方法,相对IEC61850模型,可以有效体现二次设备的结构特征,较CIM标准中的二次系统设备建模,信息更加全面。为了实现上述概念模型的物理存储,基于大数据计算服务(MaxCompute)设计实现了多层的智能变电站二次设备数据仓库,以智能变电站中设备缺陷数据的查询分析为例,验证了所设计方法的有效性。
1 模型设计
二次设备的数据建模需要完成概念模型的设计,即从用户的角度描述数据。变电站二次设备概念模型主要对变电站站内二次设备,包括继电保护设备、自动化设备网络及计算机类设备、电源系统等的台账信息、监控信息、缺陷信息及设备结构特征信息(空间坐标、外部形状、内部结构)进行统一关联建模。
目前,针对变电站二次设备模型,已有IEC61850、IEC61970等标准对其进行规范。其中,IEC61850模型用于智能变电站中,主要对变电站二次设备逻辑功能和通信接口进行了描述,实现了设备间的信息共享和互操作性。但也存在部分不足之处,如IEC61850模型中没有体现二次设备的结构特征、硬件通信接口(如接口数量、位置、类型、接口参数等)。因此,无法根据模型统一构建智能变电站详细的通信网络结构,难以明确信息的传输路径,链路异常时难以定位异常位置。
在调度系统中,主要采用IEC61970的CIM模型,对电力系统主要的物理对象进行了抽象,包括描述具体对象的公用类、描述对象参数的属性以及类之间的关系等基本元素,提供了电力系统信息的逻辑视图。存在的不足有:CIM标准中针对二次系统设备的对象非常简单,信息不够全面。此外,变电站内模型和CIM模型并没有进行统一,变电站内的数据除了部分关键动作或异常事件,并没有上送至调度系统。
基于上述考虑,设计了智能变电站二次设备数据树状建模方法。首先对二次设备按照不同专业类型分类,分为继电保护类设备、自动化类设备、电源类设备等,并分别对不同类型设备进行建模。其次,将不同类型二次设备,按照其物理结构进行划分,并分别建模。例如,保护设备被划分为电源模块、CPU模块、通信模块、开入开出模块等。然后按照设备整体属性和各模块属性进行建模。接着,对设备整体和各子模块,分别按照台帐、运行、缺陷、结构特征、运行环境、关联设备等进行建模,其中:整体属性包括台帐、运行、缺陷、结构特征、运行环境、关联设备、软件属性;各子模块包括台帐、运行、缺陷、结构特征。二次设备数据树状建模过程如图1所示。

图1 智能变电站二次设备数据树状建模方法
在图1的模型中,整体和模块的主要内容的简要描述如表1所示。

表1 二次设备整体与模块的内容
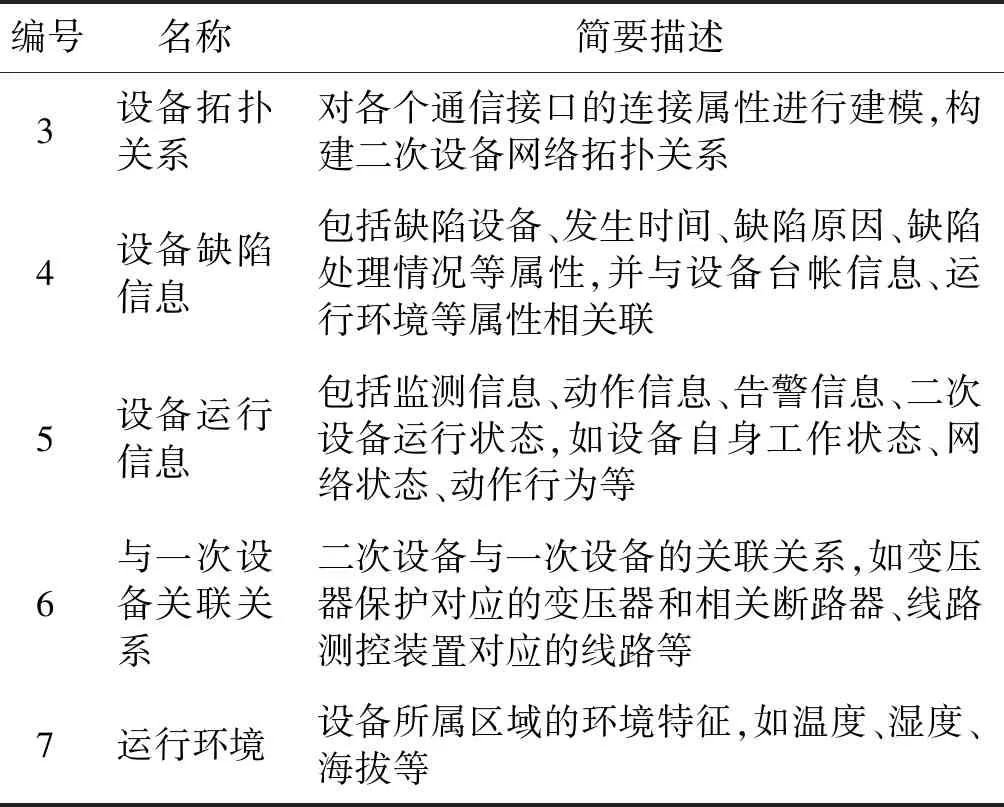
续表1
通过对变电站二次设备模型进行修改和完善,在调度侧形成二次设备完整的信息库,对辖区内变电站二次设备进行建模和数据整理,以支持二次设备监控信息、设备缺陷与设备结构的关联分析、二次设备的状态评价、故障诊断和故障趋势预警,从而提高对二次设备的管控水平。
2 从概念模型到物理存储实现
2.1 大数据计算服务
为了实现所设计的二次设备数据概念模型,本文选择MaxCompute作为物理存储平台,实现二次设备数据的物理存储。大数据计算服务MaxCompute是阿里云提供的海量数据存储和处理平台,具备海量存储、并行计算、扩展性强、免维护、低成本等诸多优势,已经在商业智能、交通数据分析、金融数据分析、工业监测数据分析等诸多领域得到应用。在功能方面,MaxCompute提供了较完整的生态系统,功能组件涵盖数据上传下载通道、SQL、用户自定义函数(User Defined Function,UDF)、扩展MapReduce、Graph等,如图2所示。
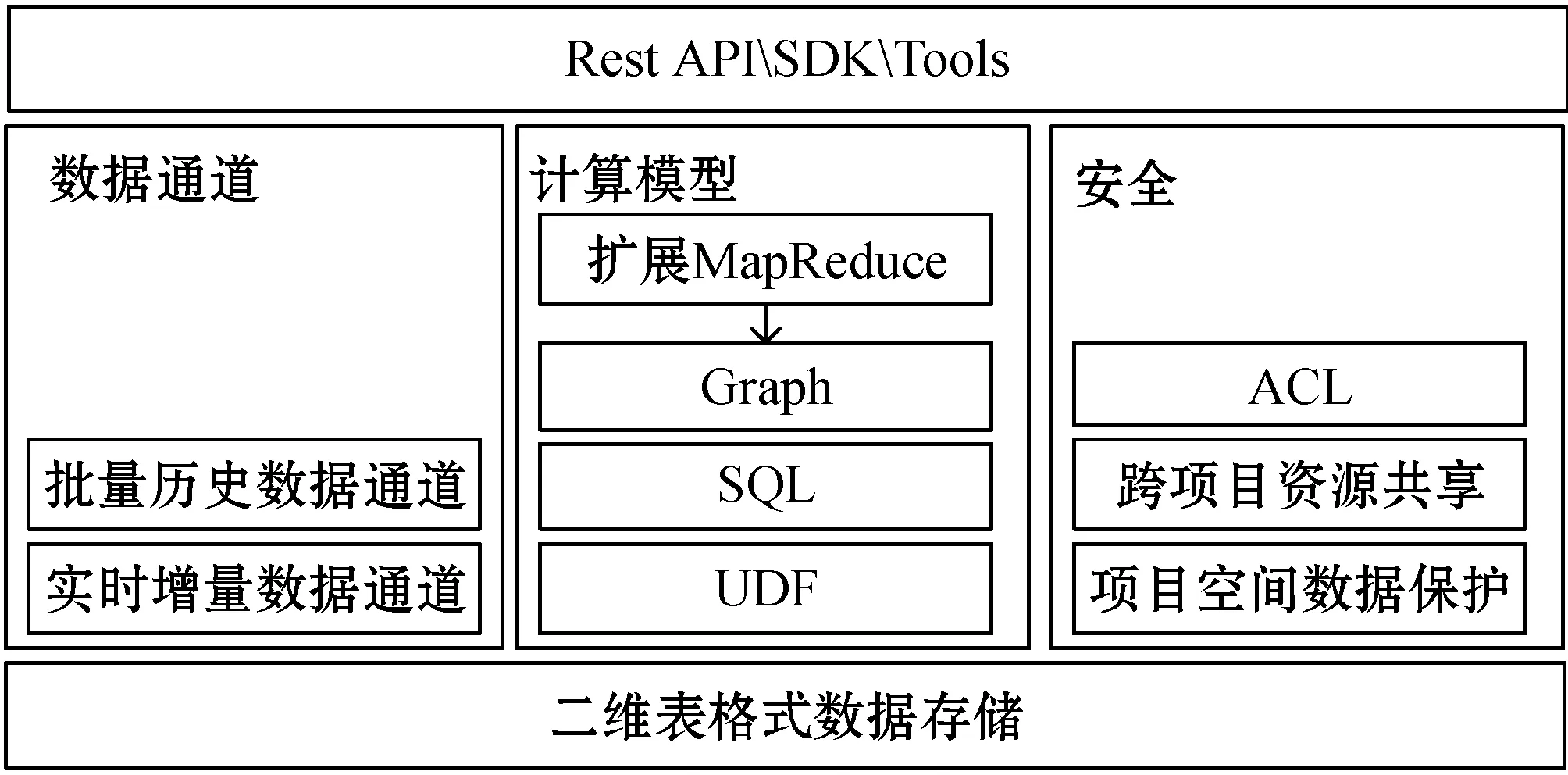
图2 MaxCompute功能组件
MaxCompute完整的生态系统和丰富的功能为智能变电站二次设备存储、数据处理和分析提供了一种新的手段。
2.2 数据仓库设计
根据所设计的智能变电站二次设备数据树状建模方法、智能变电站二次设备数据特点和二次设备数据分析需求,设计了三层存储模式的数据仓库:数据操作层(Data Operation Layer,DOL)、数据仓库层(Data Ware Layer,DWL)和数据集市层(Data Market Layer,DML)。数据仓库的整体结构如图3所示。

图3 智能变电站二次设备数据仓库3层结构
在图3中,DOL用于接收和存储来自PMS、OMS、监控、缺陷等业务系统或文档的原始数据,存储模式尽可能和数据源业务系统的存储模式保持一致,形成数据源业务系统和后续数据仓库的隔离,并为DWL提供原始的数据备份。针对DML中不同的数据分析需求,为DWL提供原始的输入数据,并应对数据分析需求的变化。另外,如果需要直接从数据源业务系统进行数据查询或者生成报表,也可以由DOL来承担,以减少对数据源系统的访问请求。
DWL是包含了所有数据分析主题的通用的数据集合。为了能够提升二次设备状态评估等数据分析应用的性能,使用星型模型进行数据建模,并按照数据分析主题进行数据的组织,每一个主题对应一个数据分析领域。为继电保护设备进行星型建模的示例如图4所示。
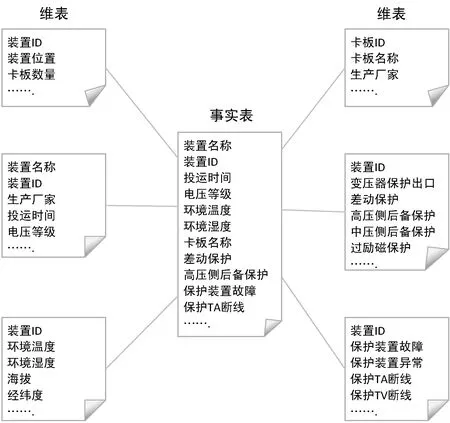
图4 数据仓库层继电保护装置数据星型数据建模
星型架构是一种非正规化的数据结构,多维数据集的每一个维度都直接与事实表相连接,不存在渐变维度,所以数据有一定的冗余。事实表可以直接支持后续的统计分析,减少或者避免了多表连接,因此分析性能较高。DWL数据来源于DOL,进入DWL的数据需要具有权威性,即后续的数据分析均需要且只允许使用DWL的数据。因此对数据质量有较高的要求,需要事先进行数据清洗,去除各类脏数据,并进行适当的类型转换、归一化和离散化处理。
DML中的数据结构清晰,具有较强的针对性,直接用于支持特定的数据分析应用。DML数据需要对DWL进行数据加工,形成的结果数据存入DML。
所设计的分层结构会存在一定的数据冗余,但是可以更有效地应对数据分析需求的变化和业务系统规则的变化,分层结构也使得数据处理逻辑变得更简洁和易操作。
2.3 数据仓库各层的协作方法
所设计的数据仓库各层自底向上逐层对上层进行数据支持。以统计和发现不同环境条件下继电保护装置动作的正确率为例,介绍数据仓库中各层之间的协作方式,其协作关系如图5所示。
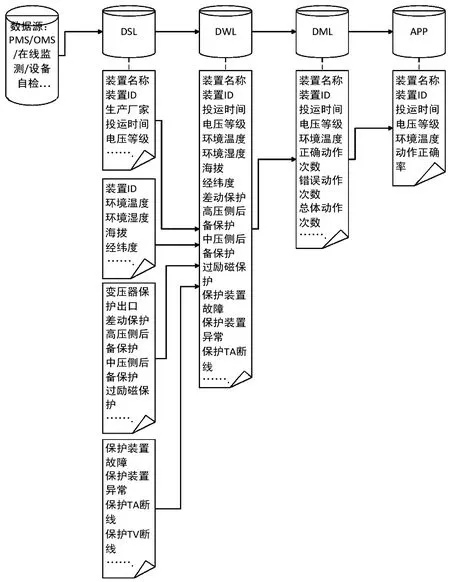
图5 统计高温情况下的继电保护装置动作正确率
在图5中,DSL接收来自PMS、OMS、在线监测、设备自检等多数据源的数据,并保持原有系统的存储模式,存储到DSL,作为整个数据仓库的基础数据。另外,如果需要对基础历史数据进行查询,可以直接在DSL中进行。DWL主要采用宽表的形式存储集成的数据。为了统计和分析环境温度、湿度等因素对继电保护设备动作正确率的影响,将来自于DSL的设备台账信息、环境信息、继电保护运行信息、告警信息集成进来,构建DWL中的表,因此表的维度较高。在使用宽表进行数据集成之前,需要对DSL中的数据进行数据清洗、适当的类型转换、归一化以及离散化等数据处理,以便得到高质量的数据,提升后续数据分析的有效性。之后,基于DWL宽表,可以统计不同周期内继电保护装置的正确动作次数、总动作次数以及相应的环境温度、湿度等,形成数据集市层DML表数据。上层的应用系统(APP)使用DML中继电保护设备动作统计次数计算动作的正确率,并进一步利用正确率和环境指标分析两者的相关性。
3 算例和实验分析
以继电保护设备状态评估为例,介绍使用MaxCompute进行数据建模、数据处理和数据分析的过程。
3.1 建表和数据同步
MaxCompute使用二维表进行数据存储。在进行数据导入之前,需要先创建表。根据2.2节设计的数据仓库,需要分别为DOL、DWL和DML创建表。根据经验,确定与继电保护设备状态评估相关的数据包括:继电保护装置整体信息、电源插件、CPU插件、通信插件和开入开出插件,共5部分信息,因此在DSL层中,分别使用SQL DDL进行表的创建,创建表的示例如表2所示。

表2 设备台账表创建DDL
执行数据操作层DSL建表操作,结果如图6所示。

图6 DSL层MaxCompute数据表
根据经验,从DSL数据表中进行特征选择,选出的用于继电保护设备状态评估的特征包括:(1) 运行环境:温度、湿度;(2) 无故障时间:设备实际无故障运行时间;(3) 家族性无故障时间:同型号、同批次无故障时间,基于OMS缺陷记录表,统计分析同型号、同批次设备的无故障时间;(4) 正确动作率:本身正确动作率、同型号正确动作率、同批次正确动作率(本身正确动作率=正确动作次数/总动作次数);(5) 绝缘状况:屏内接线的保护装置箱体和各插件的绝缘数据:装置发生绝缘接地情况的次数;(6) 数据采样:模拟量和开关量采样异常出现的次数;(7) 通信状况:GPS对时、与监控后台、保护信息子站的通信状况,统计通信异常出现的次数;(8) 通道运行情况:高频通道和光纤通道测试数据,统计通道异常次数。
使用上述特征构建DWL层数据宽表,如图7所示。
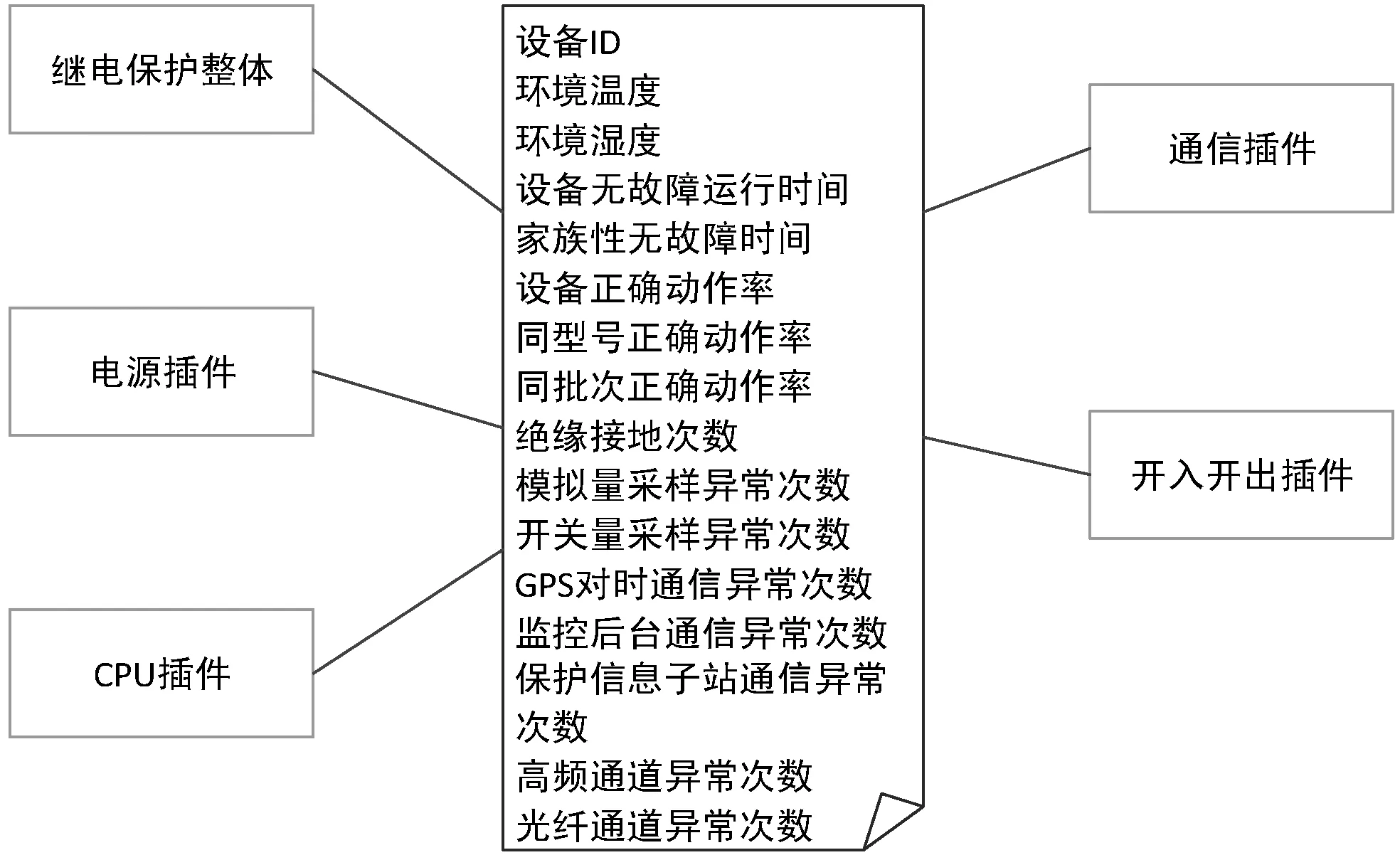
图7 DWL层MaxCompute数据表
在图7中的特征量是根据经验选取的,可以选择使用机器学习算法,如随机森林特征选择算法,利用历史数据进行进一步的特征选择,对特征量的重要性进行量化评估并排序,选出最终的特征量,用于状态评估。最终的特征量被同步到应用数据集市DML中,如图8所示。

图8 DML层MaxCompute数据表
如果不进行特征选择,则可以将DML中的表与DWL中的表保持一致即可。
3.2 数据清洗和数据加工
使用MaxCompute生态系统中的数据开发工具DataStudio完成DOL到DWL的数据清洗和数据加工过程,从数据源到DOL的数据加载也可以在DataStudio下利用数据集成工具完成。图7的DWL至DML的特征选择可以使用PAI组件完成,整体数据处理的流程如图9所示。
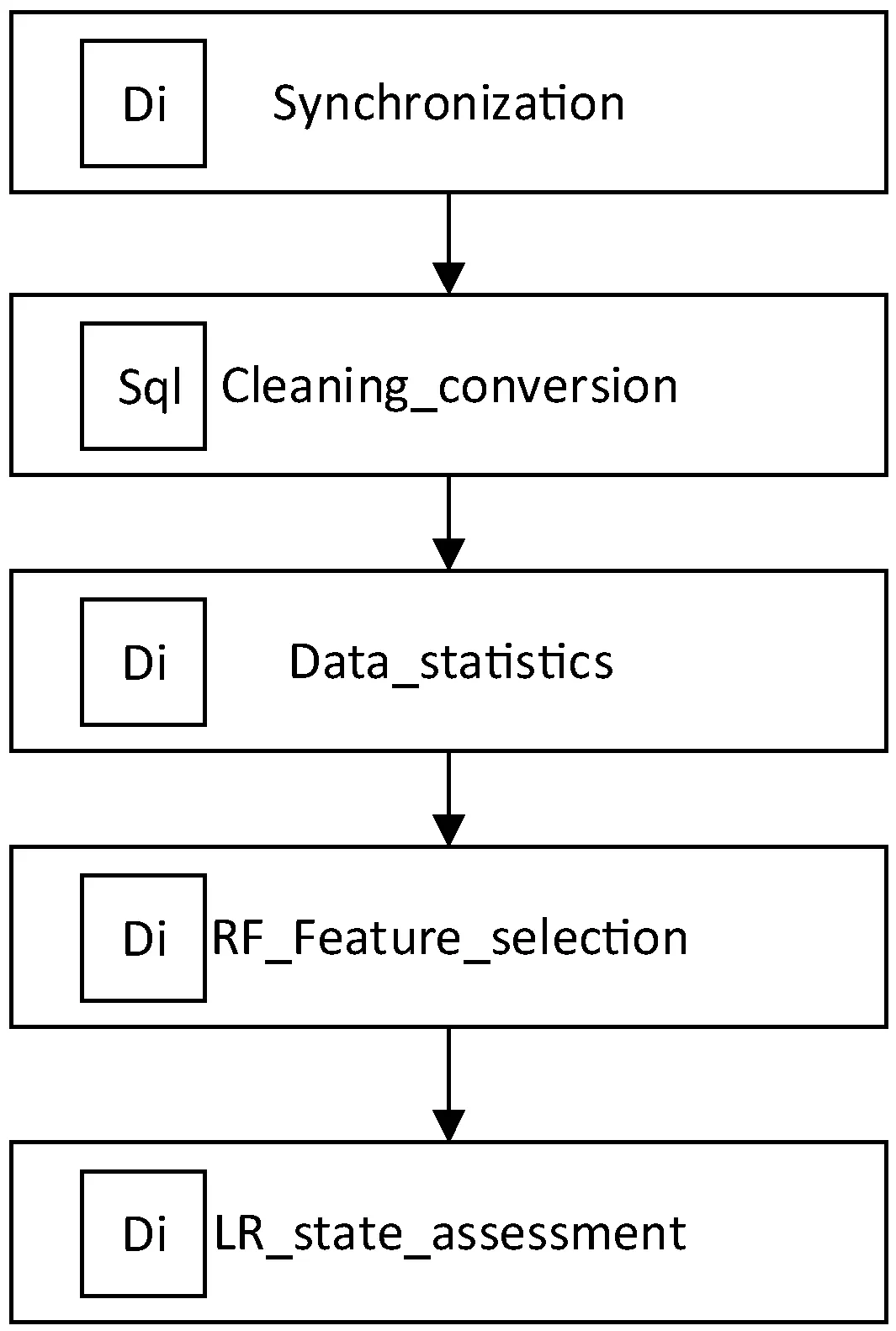
图9 DataStudio环境下继电保护设备状态评估数据处理流程
其中:Di组件为数据同步组件,负责从数据源到DSL层的数据传输;Sql组件用于数据清洗和数据的统计计算,从而形成DWL层数据;Pi组件用于特征选择,可以使用过滤式特征选择或者随机森林特征选择等方法。继电保护的状态评估使用了Pi组件中的逻辑回归算法进行训练和分类。
3.3 数据分析
数据分析的过程是在Pi组件中完成的。Pi是阿里云提供的机器学习服务。根据经验,将继电保护设备的状态评估结果设定为如下的5种状态:良好状态、正常状态、注意状态、异常状态、严重异常状态。使用逻辑回归算法进行训练和分类,数据分析的流程如图10所示。
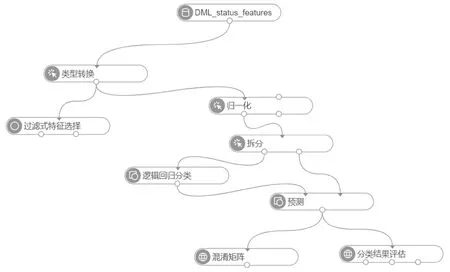
图10 Pi环境下基于逻辑回归的继电保护设备状态评估
在图10中进行了额外的过滤式特征选择,但仅是得出了当前特征重要性的量化打分和排名,并未参与后续的计算。拆分过程将历史数据按照自定义的比例,如70%训练数据和30%测试数据的比例进行了拆分,分别输出到训练模块和测试模块。最后通过混淆矩阵组件和分类结果评估组件查看模型的准确率等参数。
3.4 计算性能分析
选取来自某省电网公司2013年7月至12月的PMS、OMS、在线监测以及设备自检数据进行数据建模、存储和数据分析。实验平台使用阿里云MaxCompute、Datawork、数据集成、机器学习Pi。
使用所设计的树状模型对实验数据进行建模,并使用星型模型在MaxCompute表中进行物理存储。同时在MaxCompute中使用传统的范式模型对二次设备数据进行表示和存储。分别基于两种模式进行二次设备历史数据的查询分析,对比其执行性能。以查询分析继电保护设备的正确动作率与环境温湿度的关系为例,对比两种存储模式对查询分析的影响。分别进行了三项查询分析实验:无条件的全量设备查询Q1、根据生产厂商对不同品牌的设备进行查询Q2、根据变电站进行设备查询Q3。每组实验分别选取不同得数据规模:579 MB(数据集编号1)、1.21 GB(数据集编号2)和1.63 GB(数据集编号3),对比其执行时间,如图11所示。
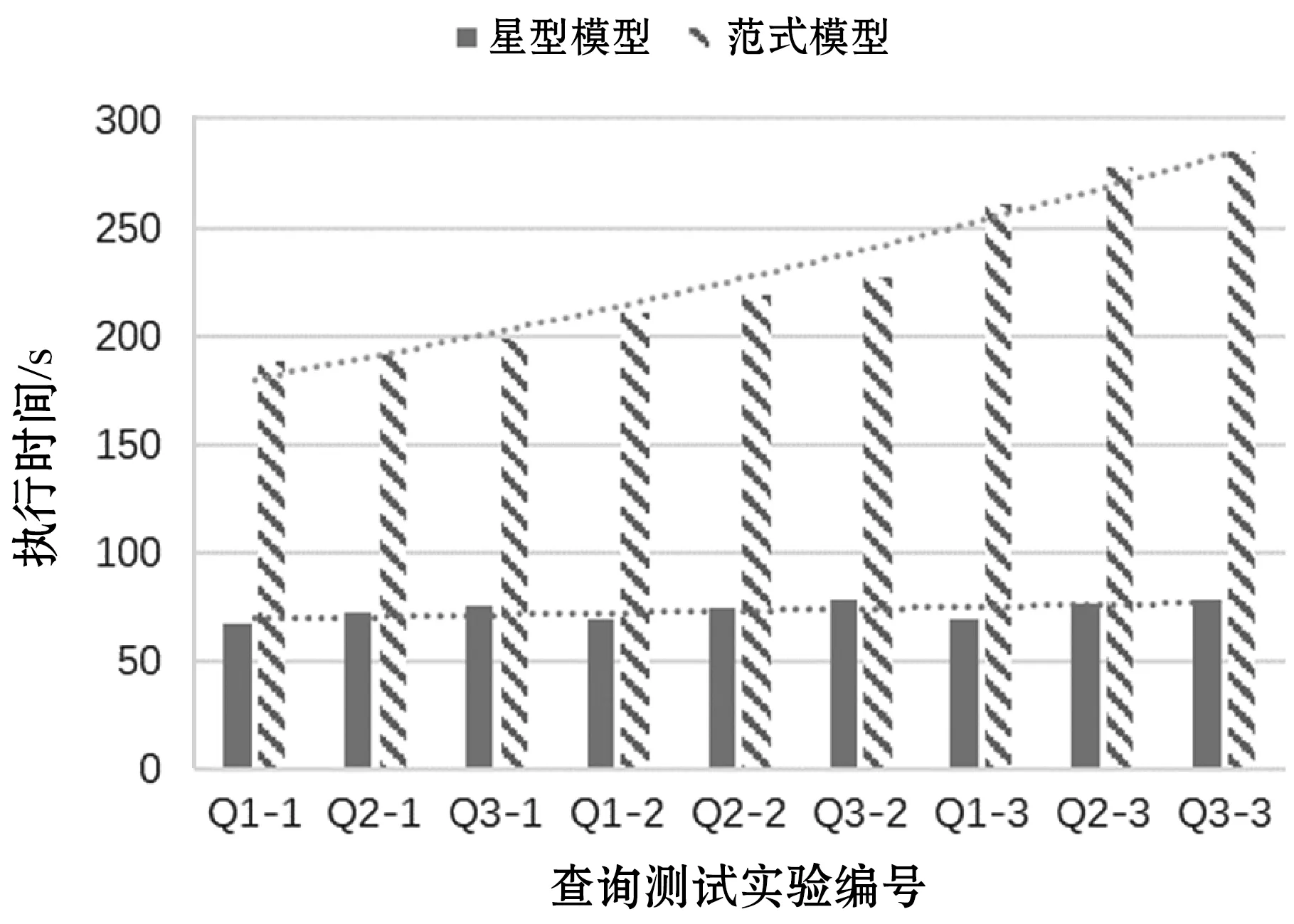
图11 历史数据查询分析执行时间对比
在图11中,QX-Y表示对数据集Y执行QX查询。采用范式建模方式,执行时间约为星型建模方式的3倍左右,不同规模不同查询方式下,9次实验的平均执行时间比例为3.12。从图11中各次实验的执行时间变化趋势可以看出,两种存储模式下的执行性能在数据规模增长的情况下执行性能比较平稳,这与MaxCompute的平台特性相关。MaxCompute下执行数据分析任务时,分配的计算资源会随着数据规模的增长而增长,因此执行时间总体比较平稳。尤其在星型存储模式下,执行时间随着数据规模的增长几乎没有增长,表明了所设计的存储方法能够有效应对智能变电站二次设备数据的存储和数据分析。
4 结 语
本文研究了智能变电站二次设备数据的特点、建模方法和物理存储方法,提出一种智能变电站二次设备数据树状建模方法。并基于阿里云的大数据平台MaxCompute设计实现了3层结构的二次设备数据仓库,给出了数据操作层、数据仓库层和数据集市层之间的交互方法。以继电保护设备状态评估为例说明了数据建模、存储和数据分析的过程。以继电保护设备数据的统计查询分析为例,在不同数据规模下,对比了所设计的星型存储模式和传统的范式模式下的查询执行时间,验证了所设计的建模和存储方法的有效性。
猜你喜欢
商品与质量(2021年43期)2022-01-18
商品与质量(2021年43期)2022-01-18
电子乐园·下旬刊(2021年3期)2021-02-08
科技与创新(2017年21期)2017-11-30
现代电子技术(2016年23期)2017-01-12
科学与财富(2016年18期)2016-12-22
电脑知识与技术(2016年25期)2016-11-16
国外科技新书评介(2016年8期)2016-11-16
电脑知识与技术(2016年15期)2016-07-04
电脑知识与技术(2016年14期)2016-06-30
