
基于Python的非接触式人体测量数据可用性验证分析
2019-09-10 07:22尹喆尚笑梅
浙江纺织服装职业技术学院学报 2019年3期
关键词:数据分析
尹喆 尚笑梅






摘 要:以目前热门的数据分析处理编程语言Python为开发工具,综合运用numpy、pandas、matplotlib等第三方库,对用服装非接触式人体测量仪测得的颈根围、胸围、腰围原数据进行清洗,去噪,以及可视化展示,最终得到高质量可用数据;并用成对样本t检验评判非接触式人体测量和传统手测方法,结果差异性显著。
关键词:Python;数据分析;非接触人体测量;成对样本t检验
中图分类号:TS941.17 文献标识码:B 文章编号:1674-2346(2019)03-0031-06
人体测量是服装工业化设计生产基础,它是服装号型制定以及人体体型结构设计、样版制作等所需数据的来源和支撑。[1]传统意义上的量体裁衣是测量人员借助软尺工具对人体关键部位进行手工精确测量,这种手法一直延续至今。但是测量耗时长,人力物力浪费大,收集的数据量远远不能满足大批量的工业生产。近几年出现的非接触式三维人体测量技术为服装人体部位数据的获取提供了很大的便利,通过定点扫描和计算机三维建模,可在半分钟内将人体各部位尺寸测量出来,测量效率可以达到工业所需数据量的要求。然而,当测量的数据集过于庞大时,对于原始数据的筛选、处理和精准性验证成为企业一大问题。因此,合适的数据处理技术对高质量的数据采集至关重要。
1 数据分析技术简介
Python是荷兰计算机工程师Guido von Rossum在1989年发明的轻量级脚本语言。[2]它以优雅简明的编程风格和丰富的第三方库深受广大程序员的喜爱,[3]并迅速发展成为仅次于C++和Java的编程语言。
Python在数据分析的层面上,有numpy、pandas、matplotlib等强大的第三方库。numpy库能够提供向量、数组、矩阵等便于进行数据分析的数据结构;pandas构造在numpy基础之上,它包含了Series(序列)和DataFrame(数据框),提供数据结构使得Python数据处理更加灵活、迅速;matplotlib是Python中基本的繪图库,它能将数据统计信息进行可视化展示,直观的分析各变量之间关系。[4]
数据分析与挖掘技术,就是从大量的、不完全的、有噪声的、模糊的实际应用数据中提取隐含的、潜在的信息。其中数据预处理阶段就是对数据“清洗”、“去噪”,得到可用于分析研究的高质量数据的过程。[5]
2 实验背景及验证方法
2.1 背景介绍
本次数据验证分析实验基于苏州大学服装工程人体测量实验团队通过非接触式三维人体扫描仪(SizeStream)获得的人体数据。为了获得有效的、符合档差范围内的数据,我们需要对原始的数据用
Python进行预处理。原始数据集中涉及人体部位有28个左右,但由于非接触式人体扫描仪和手工测量时要求被测者的站姿不同,可能造成多个测量部位的数据差异,而围度数据受站姿的影响基本可以忽略,故此次数据分析实验只处理颈根围、胸围、腰围机测与手测数据300个。
2.2 数据可用性验证
数据验证的过程遵循GB/T30548-2004三维测量仪获取的服装用人体数据验证方法。[6]具体步骤如下:
1)机测数据可靠性验证,|Amax-Amin|≤档差,即可用来实验分析;
2)手测数据可靠性验证,|Bmax-Bmin|≤档差,即可用来实验分析;
3)机测数据均值可用性验证,|Amean-Bmean|≤档差,即数据测量准确。
2.3 测量方法成对样本t检验
为了评判两种方法对同一样本测得数据的效果如何,将机测数据和手测数据进行成对样本t检验。[7]
3 数据处理分析
实验测得数据在Anaconda3的Jupyter Notebook环境中进行分析。Jupyter Notebook通过浏览器远程访问方式进行Python交互式编程,支持运行40多种编程语言,并且便于创建和共享程序文档,程序运行结果可视化效果佳。[8]
3.1 数据导入
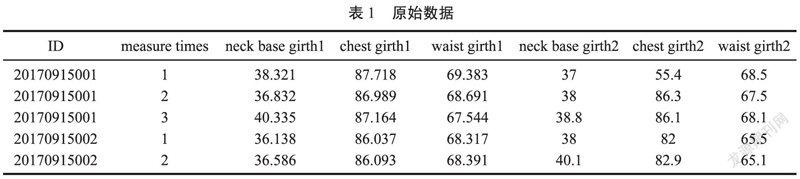
首先,导入数据分析处理三大库:nump、pandas、matplotlib。数据导入之前转为.csv文件格式,pandas的DataFrame格式并不能识别中文,故将表格中对应的属性改为英文或英文缩写形式(measure times,neck base girth,chest girth,waist girth)。在各个部位英文后面加“1”如:chest girth 1,代表机测数据;加“2”如:chest girt 2代表手测数据。用“.head()”函数展示数据表前5行,如表1所示。
3.2 原数据预处理
原始数据是300€?,共100个样本,每个样本3组数据。需先将数据进行分组操作,再对分组后每个样本求均值、极值。用“.set_index()”函数将ID和measure times组成复合索引,将每个样本3组数据归为1组,部分数据展示如表2。
3.2.1 数据可靠性验证
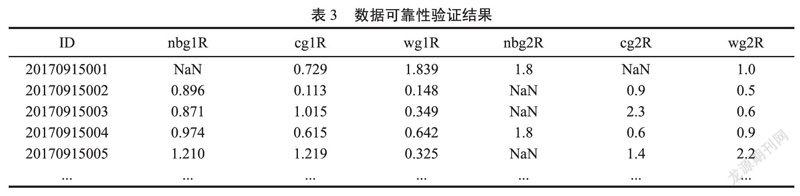
对表2中的每组数据求极差的绝对值,并将不在档差范围值赋为空值(NaN),等待剔除。核心代码如下:
#求每个样本三组数据间的极差绝对值,并修改列名
data_Range = abs(data.max(level=0) - data.min(level=0))
data_Range.columns = ['nbg1R', 'cg1R', 'wg1R', 'nbg2R', 'cg2R', 'wg2R']
#遍历数组极差绝对值,将不符合条件的值赋空值
for index, row in data_Range.iterrows():
if row['nbg1R'] > 2:
row['nbg1R'] = None
elif row['nbg2R'] > 2:
row['nbg2R'] = None
elif row['cg1R'] > 4:
row['cg1R'] = None
elif row['cg2R'] > 4:
row['cg2R'] = None
elif row['wg1R'] > 4:
row['wg1R'] = None
elif row['wg2R'] > 4:
row['wg2R'] = None
else:
continue
3.2.2 数据均值可用性验证
将分组后数据每组求均值,并赋新列名。由于每个样本数据由两种测量方法测得,如若两种方法测得的同一部位值相差过大则为视为异常值。设定将每个部位由两种方法测得的均值极差值大于5的异常点赋空值(NaN)。
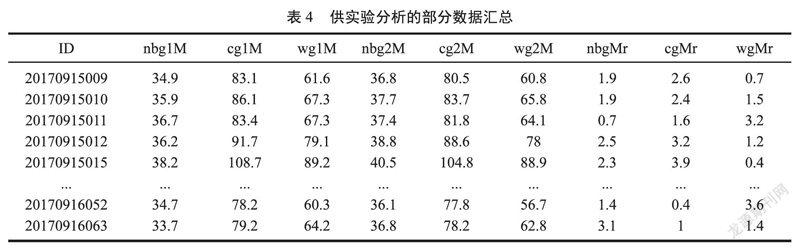
将数据集中含有空值(NaN)的列用“.dropna()”函数剔除。得到“清洁”、“干净”的数据集,合并数据均值表和极差表,最终得到可供实验分析的数据表4,数据维度变为(37€?6)。上述步骤核心代码如下:
data_mean = data.mean(level='ID')
data_mean.columns =['nbg1M', 'cg1M', 'wg1M', 'nbg2M', 'cg2M', 'wg2M']
data_mean['nbgMr'] = abs(data_mean['nbg1M'] - data_mean['nbg2M'])
data_mean['cgMr'] = abs(data_mean['cg1M'] - data_mean['cg2M'])
data_mean['wgMr'] = abs(data_mean['wg1M'] - data_mean['wg2M'])
#选出均值大于5的数值
def function(a):
if a > 5:
return np.NaN
else:
return a
data_mean['nbgMr'] = data_mean.apply(lambda x: function(x.nbgMr), axis=1)
data_mean['cgMr'] = data_mean.apply(lambda x: function(x.cgMr), axis=1)
data_mean['wgMr'] = data_mean.apply(lambda x: function(x.wgMr), axis=1)
#得可用數据集,并保留小数点后1位
new_data = pd.concat([data_mean, data_Range],axis=1)
new_data = new_data.round(1)
avavilable_data = new_data.dropna(axis=0)
3.3 多个变量之间相关性分析
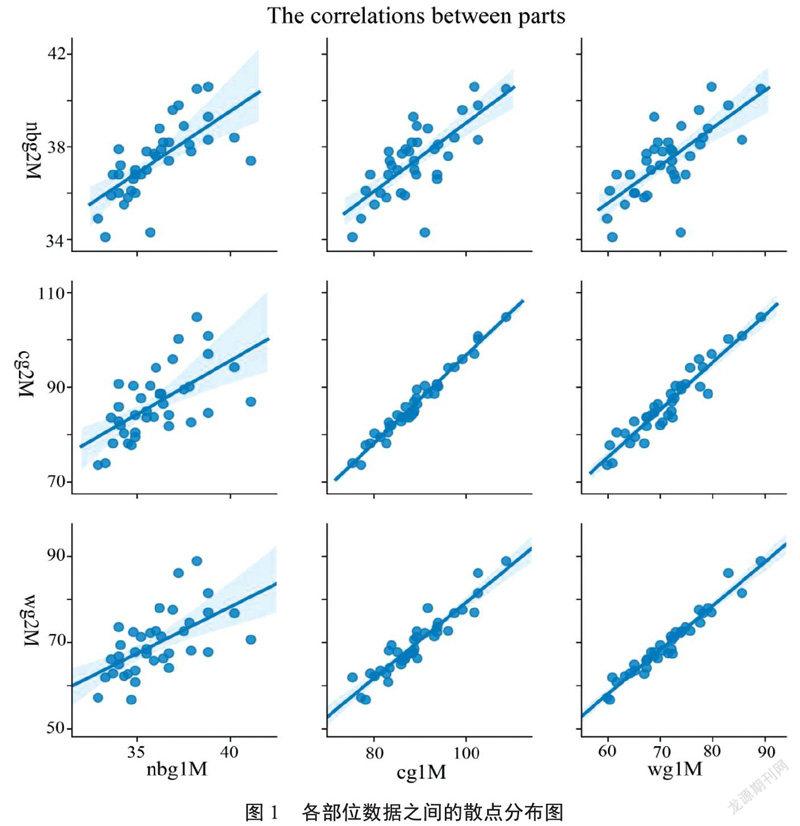
seaborn库是在matplotlib绘图库的一个延伸,对于多个变量之间关系的展示,seaborn优于matplotlib。通过seaborn库中“.pairplot()”函数,绘出3个部位机测数据和手测数据之间的散点图(图1)。
观察散点图1可发现,两种方法测得的数据,胸围和腰围的数据集中性高,与颈根围相比,这两个部位彼此之间相关性更强。颈根围与其他变量之间数据离散程度较大,这也可能与各个围度数据间的差值大小有关。从图1初步推断,用非接触式测量仪测得的人体数据与传统手工测量数据之间存在差异性。
3.4 成对样本t检验结果
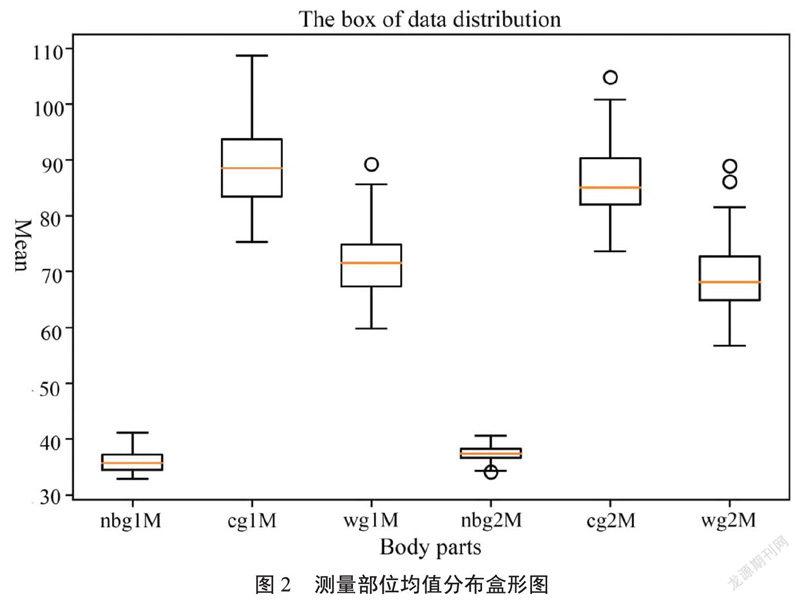
盒形图2给出了单个变量数据之间的分布。从盒中可以看出,颈根围整体数据间离散程度小,受体型影响相对较小;胸围和腰围数据离散程度大,这可能与样本处在不同身高档差范围有关。并且,图中3个部位对应机测、手测最大值和最小值及中位数的分布都有明显差异。
为了定量的验证这种直观结论,从scipy库中引入统计分析函数stats,做成对样本t检验,判断非接触式测量和传统手工测量方法的差异性。核心代码如下:
from scipy import stats
#颈根围
stats.ttest_rel(new_nbg_mean['nbg1M'],new_nbg_mean['nbg2M'])
#胸围
stats.ttest_rel(new_cg_mean['cg1M'],new_cg_mean['cg2M'])
#腰围
stats.ttest_rel(new_wg_mean['wg1M'],new_wg_mean['wg2M'])
t检验(双侧)结果如表5。
由表5中成对样本t检验结果得出:颈根围、胸围、臀围的P/2(单侧)值均小于0.05,故拒绝原假设H0,即认为这3个部位用非接触式测量仪和传统手工方法测得的数据均值差异性显著。
综上,本文从应用的视角出发诠释了Python在数据分析与挖掘领域的内涵。通过处理服装行业人体测量数据,实现了大数据时代背景下服装用非接触式人体数据可用性的分析。然而,当面对庞大数据量时,对有“噪”的脏数据的预处理远不止这些。可对缺失值数据填充、修改、异常值剔除;可对数据做探索性数据分析,可对数据进行更多的可视化展示等。本文的例子只是大数据应用的冰山一角,数据分析与挖掘的热度正在上升。作为数据分析者,须理解和熟悉数据挖掘原理与技术,综合利用编程语言技能,利于自己工作,服务于行业。
参考文献
[1]陈益松,夏明. 光学三角测量法及其在人体测量中的应用[J].纺织学报,2012,33(12):95-101.
[2]李俊华.基于Python的数据分析[J].电子技术与软件工程,2018(17):167.
[3]王海涛,齐达.基于Python下的数据采集和分析在融媒体中的作用[J].电声技术,2018,42(06):63-64+67.
[4]阮敬. Python数据分析基础[M].北京:中国统计出版社,2017.
[5]吕晓玲,谢邦昌.数据挖掘方法与应用[M].北京:中国人民大学出版社,2008.
[6]GB/T 30548-2014.服装用人体数据验证方法用三维测量仪获取的数据[S].北京:中国标准出版社,2014.
[7]汪洁.t-检验成对二样本分析法在船舶定线制中的应用[J].中国水运(下半月),2010,10(06):8,37.
[8]薛煜阳.Jupyter Notebook在Python教学中的应用探索[J].信息技术与信息化,2018(07):168-169.
猜你喜欢
中国市场(2016年36期)2016-10-19
商场现代化(2016年22期)2016-10-18
科技视界(2016年22期)2016-10-18
