
基于加权语义网的文本相似度计算方法研究
2019-09-10 07:22:44张弛周艳玲张贯虹
赤峰学院学报·自然科学版 2019年5期
张弛 周艳玲 张贯虹


摘要:为了更加准确地计算文本特征权重,提高文本相似度计算的精确度,文章提出了一种基于《知网(HowNet)》语义知识库的加权语义复杂网络文本相似度计算方法.该方法首先以特征词为节点,以特征词窗口共现为边,以特征词的TF-IDF值为特征词节点的初始权重,以融合共现频率和概念间语义距离计算特征词节点之间边的权重,构建加权语义文本复杂网络.然后利用综合特征指数作为加权语义网中文本的特征权重.最后基于公开数据集和KNN算法进行文本聚类实验,实验结果表明,在基于F-度量值标准上本文提出的方法要优于传统基于向量空间模型的TF-IDF方法和另一种结合复杂网络权重的方法.
关键词:复杂网络;特征词;KNN算法;文本相似度;HowNet
中图分类号:TP391.1 文献标识码:A 文章编号:1673-260X(2019)05-0019-05
随着互联网的普及和使用,互联网中文本数据的产生正在以指数级的速度增长,如何从庞大的信息库中提取有用的信息就依赖于文本挖掘技术[1],其如何能够实时、高效地挖掘出对社会生产、生活有价值的信息,已经成为文本聚类、信息检索、问答系统等诸多研究领域知识管理者和研究者所要亟待解决的问题.
文本相似度计算是文本数据挖掘中需要解决的关键问题之一.传统的文本相似度计算方法是基于统计特征的TF-IDF算法[2-4],该方法是将文本经过预处理后表示为一个向量的形式,向量中每个元素值为特征词的词频(TF)和逆文本频率(IDF)的乘积,这样就可以通过计算向量之间的差异来衡量文本之间的相似性.这种方法的优点是既可以排除文本中的低区分度词,又可以避免在文本集中分布广泛的高频词干扰文本相似度计算结果.但是这种方法同样忽略了特征词自身一般都具备丰富的语义,词与词之间的关系也不是相互孤立的,词语间的语义关系、词与词之间共同出现的频率和词的上下文结构信息等都将影响着文本相似度计算结果的准确性[5-7].
近年来,随着复杂网络科学研究的发展,在自然语言处理研究领域中也发现了小世界特性[8],为国内外学者研究文本的相似度计算提供了新的思路.文献[9-11]等基于语义知识库的方法,通过对特征词进行概念或义项的映射,计算特征词所对应的概念或义项的语义相似性、相关度和语义距离等来构建文本复杂网络,并使用复杂网络的物理结构特征进行关键词的提取研究,如节点度、介数、聚集系数等.文献[12]、文献[13]根据特征词之间的语义关系构建文本复杂网络,然后利用复杂网络社区的结构特性,使用社区挖掘算法来进行特征选择.文献[14]引入相似性和相关性对词语语义关系进行复杂网络构建,通过调节各个参数的权重进行特征项选择.虽然这些研究已经取得较好的成果,但它们都未考虑节点对全局网络的影响,忽略了在文本复杂网络中特征词的位置、共现频率、全局统计信息等因素的重要性,造成在文本网络构建中边权重计算方法不科学,结果不准确,导致最终计算结果存在较大偏差.
鉴于特征词本身具备的丰富语义特征,本文综合考虑了特征词间的语义相似性、统计TF-IDF值以及共现频率等因素,提出了一种基于《知网(How Net)》语义知识词典的文本加权语义网络构建和相似度计算方法.该方法首先对文本进行分词、去停用词操作,并依据复杂网络中的小世界特性,以特征词为节点,以特征词的TF-IDF值作为节点的初始权重,以特征词窗口共现为边,基于《知网(How Net)》语义词典将特征词映射为词典中的概念,考虑到特征词在文本中的共现系数,融合共现系数和概念间语义距离计算特征词之间边的权重,充分利用了文本的结构信息和全局统计信息.最后使用余弦相似性公式计算向量化文本之间的相似度,使用K最近邻(KNN)分类算法在标准数据集上对文本进行分类实验,对本文提出的加权语义网络方法、文献[11]提出的结合复杂网络的方法以及文献[2]提出的基于统计的向量空间方法进行实验对比,验证了本文提出的基于加权语义复杂网络的方法能够有效提高文本相似度计算结果的准确性.
1 相关理论
1.1 复杂网络特性
复杂网络是指在结构、节点类型和连接形式等方面复杂的网络,该类网络具有明显小世界、无标度等特征[16].在复杂网络中不同的统计量能够反映不同的物理含义,对复杂网络结构拓扑的分析,能够剖析系统演化的过程和内部存在的机制,本文主要使用如下的复杂网络物理统计特征量对节点的重要性进行评估.
1.1.1 节点加权度
1.2 加权语义网
语义网是一个语义网络系统,它系统地描述了现实中词汇与词汇之间的各种语义关系.因为词汇之间一般都具有丰富的语义关系,传统上直接计算文本特征词之间的语义关系是很困难的.目前,常用两种方法对特征词进行语义关系的计算,一种是基于大规模语料库的方法[18],一种是基于世界知识的方法[19].考虑到前者需要大量的语料作为训练集,使用中经常受到语料库规模的影响;本文选择了使用基于世界知识的《知网(How Net)》语义词典进行语义复杂网络的构建,这种方法相对前者更加简单、有效.借助《知网(How Net)》语义知识词典,将特征词转化为知识词典中的概念,这样每个特征词都将对应于《知网(How Net)》知识库中的特定的概念.这样就可以使用概念之间的距离来间接度量特征詞之间的语义联系,能够区别出不同文本特征词之间的语义相似性和差异性.借鉴文献[15]在概念层面上对距离的计算,本文对概念间距离的计算也使用语义距离、语义重合度、层次关系三个因素,利用概念间语义距离作为对应特征词之间关系强弱的衡量标准.如图1所示为基于《知网(How Net)》语义词典的概念距离计算案例.
语义距离:表示为在《知网(How Net)》语义词典中两个概念之间的最短路径长度,文中用D(Si,Sj)表示两个概念Si和Sj之间的语义距离,值越小表示两个概念所对应特征词的间关系就越相近,以图1中节点S7和S4为例,D(S7,S4)=3.
语义重合度:表示为两个概念所拥有的共同父节点数量,拥有的共同父节点数量越多,说明概念间关系越相近.使用C(Si,Sj)表示概念Si和Sj之间的语义重合度.以图1中节点S7和S4、S7和S8为例,C(S4,S7)=2,C(S7,S8)=3.
層次深度:用Hi和Hj表示两个概念Si和Sj的所在语义树中的层次深度,随着两个概念间的层次深度差增加,所对应词汇之间的相似性就越小.
2 基于改进加权语义网络的文本相似度计算
2.1 文本特征词之间语义相似度计算
通常在文本复杂网络中,特征词节点之间边的权重是难以直接衡量的,特征词之间权重的精确性将直接影响到文本特征词提取的正确性.本文综合考虑词汇的共现频率权重、语义距离、语义重合度和层次深度这四个方面的因素作为语义复杂网络中边的权重.
2.5 算法流程
使用本文提出的文本复杂网络构建和特征词权重计算方法,对文本的特征词进行特征权重计算,提高文本相似度计算结果的精度,算法描述如下:
输入:带有类标签的训练文本集D1和测试文本集D2.
输出:带有类标签的测试文本集D2.
(1)对训练集D1和测试集D2分别进行分词和去停用词操作,得到初始训练集和测试集特征词集合.
(2)对训练集D1中的每篇文档使用第2.1节介绍的方法,分别计算特征词节点和边的权重,构建文本加权语义复杂网络.
(3)根据2.3节介绍的方法,对训练集D1中的每篇文档,使用综合特征指数CFi计算每篇文档中每个特征词的权重,选取文档权重排名靠前的m个特征词作为该文档的特征选择结果,形成训练集数据词典.
(4)根据训练集数据词典,对测试集D2中的每篇文档,使用2.1节介绍的方法,进行加权语义复杂网络构建和特征词特征综合权重计算,形成待分类的测试文档特征向量.
(5)根据步骤(4)的数据字典,对待分类文档进行特征词选择,使用公式7计算待分类文档与数据字典中的每一个文档的相似度,选取相似度值排名靠前的k篇文本作为相似文档集.
(6)根据相似文档的文本类别标记,统计这k篇相似文档中出现次数最多的类别标记为该待分类文档最终的类别标记.
(7)对测试集D2中的每个文档特征向量,循环重复步骤(5)和步骤(6),直到测试集中的每篇文档都确定一个类别标签.
3 实验验证分析
3.1 实验数据及方法
实验数据选取复旦大学提供的中文语料库中的农业、政治、经济、体育和环境五个类别,每个类别中各随机选取800篇.本文采用Java语言开发环境,使用jdk版本为1.8.0_121,分词软件使用中国科学院计算技术研究所的ICTCLAS软件[17],选取哈尔滨工业大学的中文停用词表,包含767个停用词,并使用《知网(HowNet)》计算中文特征词之间的相似度,具体实验过程如下:
本文使用三组实验进行对比,第一组采用本文提出的基于加权语义的方法,第二组实验采用文献[13]提出的综合复杂网络特性的计算方法,第三组实验采用文献[2]提出的基于向量空间模型的算法.实验中公式?茁i采用文献[9]的取值,即?茁1为0.4、?茁2为0.3、?茁3为0.3.为了验证本文所提出方法在计算结果上的准确性,本文使用KNN分类算法在标准数据集上进行文本分类实验,根据分类的结果来验证本文所提出算法的有效性.KNN分类算法中,K取值为15,特征维数取值为1200,实验时采用5折交叉验证法,取这五次的F1平均值作为最终的分类结果.
3.2 实验评价方法
3.3 实验结果与分析
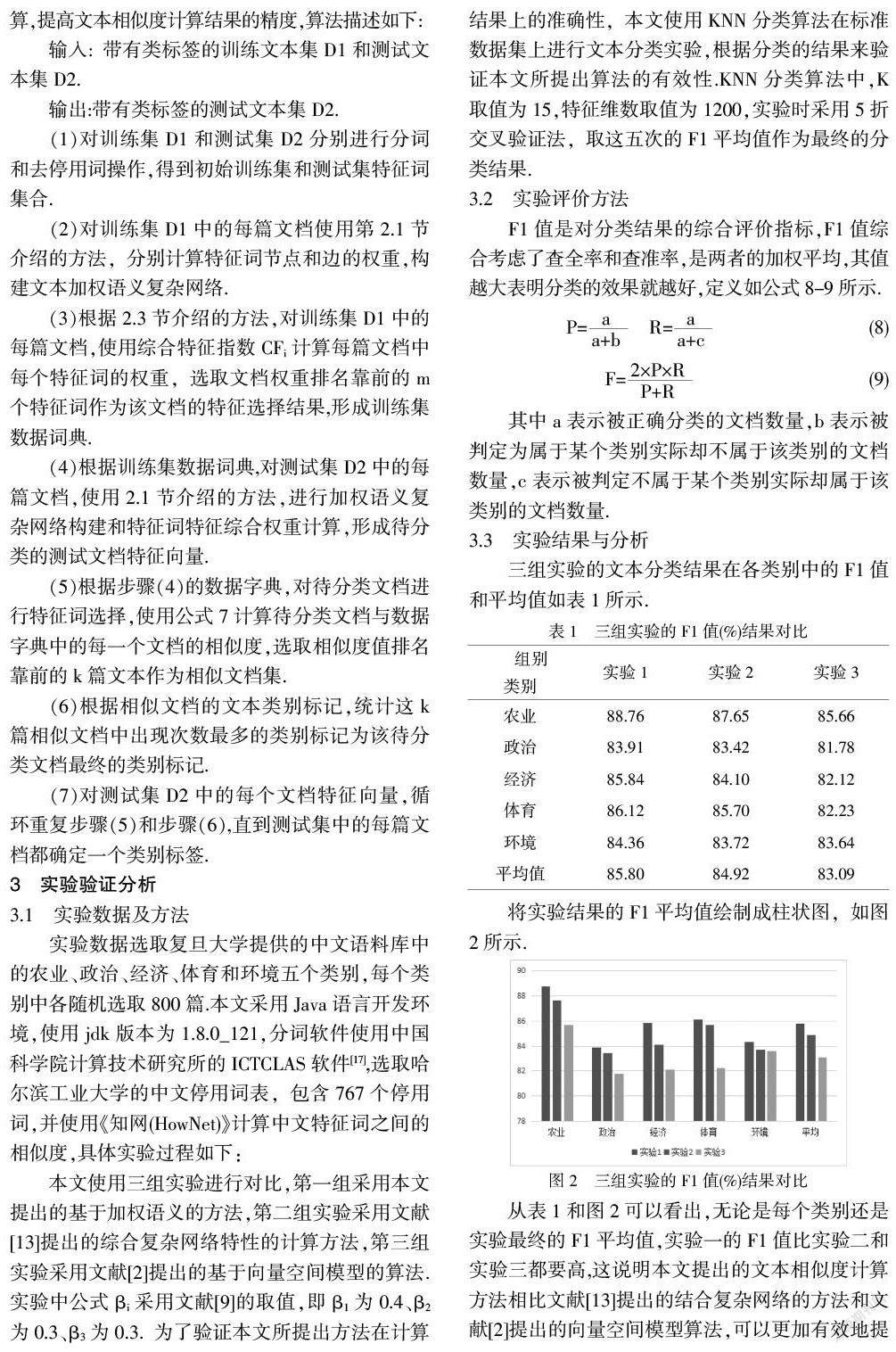
三组实验的文本分类结果在各类别中的F1值和平均值如表1所示.
将实验结果的F1平均值绘制成柱状图,如图2所示.
从表1和图2可以看出,无论是每个类别还是实验最终的F1平均值,实验一的F1值比实验二和实验三都要高,这说明本文提出的文本相似度计算方法相比文献[13]提出的结合复杂网络的方法和文献[2]提出的向量空间模型算法,可以更加有效地提高文本相似度计算结果的精确性,使最终的分类结果更加准确.实验一和实验二相比,同是使用基于复杂网络的构建和特征选择方法,但是实验二在文本复杂网络的构建中并未考虑特征词的共现因素,而且需要调节的参数较多,增加了算法的时间复杂度.实验二和实验三相比可以看出,使用结合复杂网络特征选择的实验二因为考虑了特征词之间的语义关系和统计特征,使得最终的分类效果要比单纯TF-IDF方法结果好.
4 结束语
本文提出了一种改进的加权语义复杂网络文本相似度计算方法,首先基于文本特征词的统计特征,融合特征词的共现频率和语义距离,计算文本复杂网络中特征词节点间边的权重,然后对文本的特征词综合指数进行计算,根据综合特征指数值的大小,对特征项向量进行选降维处理,使用相似度计算公式对文本进行相似度计算.最后通过对三组实验结果的对比分析,验证了本文所提出的方法能够充分利用文本网络中特征词节点间的语义信息、结构信息和统计信息,提高相似度计算结果的准确性.但是鉴于文本相似度计算的复杂性,本文的研究还有一定的局限性,例如特征词所在文本的位置、特征词与句子、句子与句子之间的关系等因素,这些还都有待于进一步的研究.
参考文献:
〔1〕崔嘉乐,姜明洋,裴志利,卢奕南. 基于深度学习的文本挖掘研究[J]. 内蒙古民族大学学报(自然科学版),2016(05):403-407.
〔2〕Salton G,Wong A,Yang C.A Vector Space Model for Automatic Indexing[J]. Communications of ACM. 1975, 18(11): 613-620.
〔3〕叶雪梅,毛雪岷,夏锦春,王波.文本分类TF-IDF算法的改进研究[J].计算机工程与应用,2018(12):1-8.
〔4〕周源,刘怀兰,杜朋朋,廖岭.基于改进TF-IDF特征提取的文本分類模型研究[J].情报科学,2017, 35(05):111-118.
〔5〕夏冰,李宝安,吕学强.综合词位置和语义信息的专利文本相似度计算[J].计算机工程与设计,2018, 39(10):3087-3091.
〔6〕孙丽莉,张小刚.一种基于HowNet语义计算的综合特征词权重计算方法[J].统计与决策,2018, 34(18):82-85.
〔7〕葛斌,李芳芳,郭丝路,汤大权.基于知网的词汇语义相似度计算方法研究[J].计算机应用研究,2010, 27(09):3329-3333.
〔8〕Cancho R F I , R V Solé. The small world of human language.[J]. Proc Biol Sci, 2001, 268(1482):2261-2265.
〔9〕Zhao Hui, Liu Huailiang, Fan Yunjie. Study on the Application of Complex Network Theory in Chinese Text Feature Selection [J]. New Technology of Library and Information Service, 2012(9): 23-28.
〔10〕Liu G, Zhai Z W. Research on Keywords Extraction of Chinese Documents Based on TEXT-NET [C]. In: Proceedings of the 2011 International Conference on Electric Information and Control Engineering. 2011: 6074-6077.
〔11〕赵京胜,张丽,肖娜.基于复杂网络的中文文本关键词提取研究[J].青岛理工大学学报,2018,39(03):102-108.
〔12〕Jia X Q.Feature Selection Algorithm Based on the Community Dis covery[C].In: Proceedings of the 7th International Conference on Computational Intelligence and Security.2011:455-458.
〔13〕尹丽英,赵捧未.基于语义网络社团划分的中文文本分类研究[J].图书情报工作,2014,58(19):124-128.
〔14〕杜坤,刘怀亮,郭路杰.结合复杂网络的特征权重改进算法研究[J].现代图书情报技术,2015(11):26-32.
〔15〕廖开际,杨彬彬.基于加权语义网的文本相似度计算的研究[J].情报杂志,2012,31(07):182-186.
〔16〕汪小帆、李翔、陈关荣.复杂网络理论及其应用[M].清华大学出版社,2006.
〔17〕Wu Z B, Palmer M. Verb Semantics and Lexical Selection [C]. In: Proceedings of the 32nd Annual Meeting of the Association for Computational Linguistics. Association for Computational Linguistics, 1994: 133-138.
〔18〕Semantic Similarity Measures in MeSH Ontology and Their Application to Information Retrieval on Medline[EB/OL].[2007-12-10].http://www.intelligence.tuc.gr/publications/Hliautakis.pdf.
〔19〕张硕望,欧阳纯萍,阳小华,刘永彬,刘志明.融合《知网》和搜索引擎的词汇语义相似度计算[J].计算机应用,2017,37(04):1056-1060.
猜你喜欢
计算机系统应用(2021年9期)2021-10-11 06:47:14
计算机技术与发展(2018年8期)2018-08-21 02:08:14
中国机械工程(2017年22期)2017-12-02 01:52:34
计算机应用(2016年12期)2017-01-13 19:59:45
对外经贸(2016年11期)2017-01-12 01:12:53
无线互联科技(2016年13期)2017-01-10 02:30:36
中小企业管理与科技·上旬刊(2016年10期)2016-11-15 10:00:25
科技视界(2016年20期)2016-09-29 11:19:34
商情(2016年11期)2016-04-15 22:00:31
中文信息学报(2015年4期)2015-04-21 08:29:12
