
基于空间分析的气象预报文本实时生成研究
2019-09-10 07:22于敏曹学海邱国鹏
赤峰学院学报·自然科学版 2019年10期
于敏 曹学海 邱国鹏






摘 要:旨在将专业且繁杂的原始气象数据转化成通俗易懂的气象预报文本,提高气象服务的时效性、科技含量和丰富性,重点对原始气象数据进行空间计算,另外利用特征提取相关算法处理海量历史气象文本,构建气象预报文本的模板库.在此基础上实现了一套面向气象大数据的气象预报文本实时生成系统.实验结果显示,该系统生成的气象文本准确性达到71%,通顺性达到85%,合格率可达84%.较为理想的实验结果也证明了该系统的可行性与准确性,具有良好而广阔的应用前景.
关键词:自然语言处理;特征提取;空间分析;文本自动生成
中图分类号:P458 文献标识码:A 文章编号:1673-260X(2019)10-0127-04
相关数据显示,中国是受灾害影响最严重的国家之一,气象灾害的有效防御还需要气象服务能力的进一步提高;人民生活方式的不断转变和生活质量的不断提高也需要更高层次的气象服务相匹配.但是,现在我国气象服务行业仍然存在着服务能力和经济社会发展要求不相适应,产品质量不高,科技含量不足等问题.近年来,GIS(Geographic Information System地理信息系统)技术在气象的可视化、图形化领域发挥了重要作用[1],但是在具体的文本输出方面,多数气象部门仍然采用人工的方式解读大量实况数据,并依靠人工进行气象的描述和文本输出.很明显,这种人工的方式已经无法满足现代社会所需要的时效性、精细化、更新快的气象预报产品的要求.
国外于20世纪70年代初就开始了天气预报文本的计算机自动或半自动生成技术的研究,代表性的有1991年的Scribe、1993年的ICWF和1999年的Siren系统[2].从国内来看,中国气象局于2014年研究的气象落区文本自动生成技术实现了从标准化的气象数据到篇章级气象预报文本的自动生成[3].然而上述研究均存在一些不足:如只停留在原始气象数据空间处理和气象预报文本自动生成分割处理的阶段,缺乏时效性.
本文将建立面向气象预报文本生成技术的文本特征提取、模式匹配、文本规划组织的自然语言处理模型,并利用GIS相关工具对原始气象数据进行空间分析,获取具体气象信息并结合文本模型生成完整的气象预报文本,从而建立基于空间分析的气象预报文本实时生成系统模型与方法.
1 基于QGIS空间分析的气象数据模型构建
中国气象局目前所有的原始气象数据主要为14类Micaps数据,包括降水、气温、台风、雾霾等各类气象类型,分为点、线、面、栅格四种格式.Micaps数据中包含有地理方位、气象代码、距离、方向、等级等多个特征,需从这些特征中综合提取出气象空间特征[4].还需考虑不同气象要素、不同表现形式(单站点数据如观测点数据、格点数据如降水数值),对于特定类型的气象数据在空间特征提取的方法上也存在差异(如观测站点需要先进行插值处理形成空间分布场然后再表达)[4].
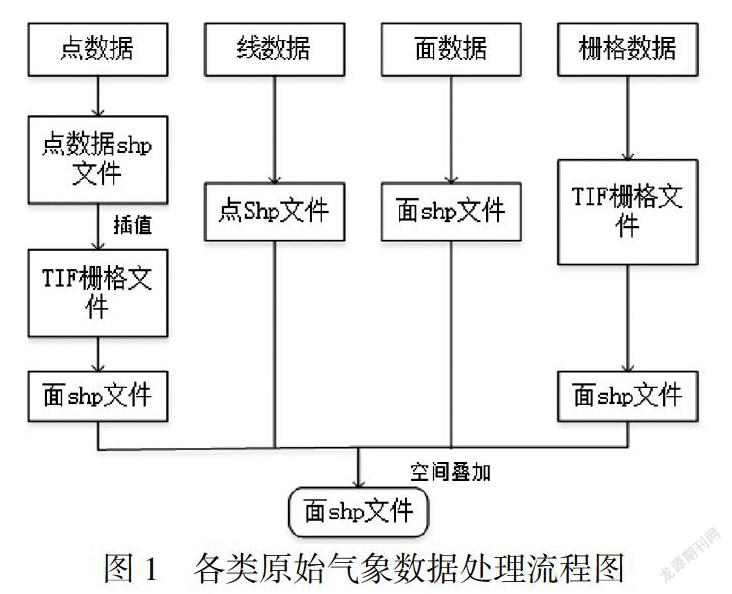
根据数据类型分别调用不同的GDAL库接口从而创建不同格式的文件[5].具体的每种原始气象数据处理流程如图1所示.
以Micaps7数据为例,它是专门用于台风预警的站点数据,处理后得到的shp文件如图2所示,表1为添加数据之后生成的shp文件属性表(部分),包含有台风的时间、位置、速度等属性.
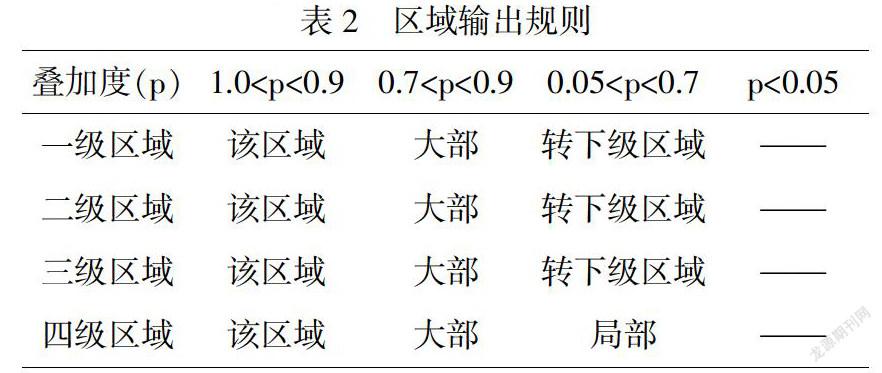
可以看到,每种天气要素发生的地理位置在原始气象数据中是以经纬度形式出现的,无法直接得到具体地名,需利用QGIS模块并结合空间叠加原理,将每个级别的气象地理区划的空间文件分别同预报的天气要素地理位置文件进行叠加,得到重合的部分,读取该重合部分所属的每级区划(如叠加部分属于江南地区、江南地区东部、江西省、江西省北部)、天气信息(如天气的类别、级别等)、重合部分面积以及此面积占整个所属地理区划面积的比例p.确定了如上信息就可以进行空间推理分析[2],规则如表2所示.
2 气象预报文本的特征提取与建模
2.1 气象预报文本的特征提取
引入中国气象局2015-2017年间各类型的历史气象文本资料共2000份,作为本模型的训练数据,利用NLPIR-ICTCLAS对气象文本数据进行信息抽取[6].主要抽取以下两部分信息:1.天气(天气类型和天气预警)和地理区域变量描述词组;2.描述天气的短句模板.这两部分信息结合就可以组成一句完整的天气描述的句子.部分结果如表3所示.
词频统计[7]结果显示,在2000份气象预报文本中,一共出现了2468个词语,有些词全年只出现了1-2次,属于分词中生僻词.对预报文本进行词频统计信息抽取的目的是得到气象文本编写的通用规律,所以在研究过程中只需要关注重点词汇就可以了,低频率的词汇可以忽略.
二元词组邻接分析[8]部分结果如表4所示,所有的二元词对总数只有17314.这种文本分析对研究预报员的文本写作习惯是非常有效的.
结合上述词频统计结果和二元词组邻接分析结果,归纳出气象预报文本必须包含的信息:模板规则和变量词汇,其中变量词汇包括气象变量和地理区域变量,两类变量通常是同时出现的,气象变量主要是指描述各类气象要素的专业气象词汇,比如“雾霾”“雷暴”“强对流”等词汇,地理变量信息是描述天气所在位置的地理区域,可以将全国分为四个等级来逐步缩小天气的描述范围,如“华北地区”“华北东部”来使天气范围更为精准.这类变量名词均是可数且有限,指代(天气、地理区域)明确的.
2.2 句子模板庫的构建
经过上述对文本的变量词汇和模板规则的提取,可以建立相应的短句模板和气象变量词汇文本库[9],描述天气情况的句子主要是由这两部分组成.
为每种气象类型分别建立句子模板库,其中中括号[]内部的信息表示必填变量,如时间、地点、气象等级等;大括号{}内部信息为选填项,根据气象等级的不同选择是否出现.以下为气温预报模板示例:
“[时间],[地点]气温将{上升/下降}{度数}℃,其中{地区}{局部地区}{上升/下降}温度可达{度数}℃”
QGIS模块将处理后得到的气象变量信息保存在一张附带属性表的shp文件中,通过空间分析技术确定每一气象类型对应的具体地理区域,最后系统会从不同类别的子库中选择合适的句子进行描述.将合适的气象信息填入句子模板的过程就是一个简单的“填槽”过程[10].例如在预报气温时,可以由上述模型获得温度变化较大的地区的地理名称以及具体的温差数据,即“山东省北部、河北省大部、江南大部分地区、西北北部地区”,将其填入[地点]处地点对应的位置可得:
“20日8时,山东省北部、河北省大部、江南大部分地区、西北北部地区气温将上升4~8℃,其中,河北省大部、江南大部分地区局部地区上升温度可达10~12℃”
2.3 算法过程
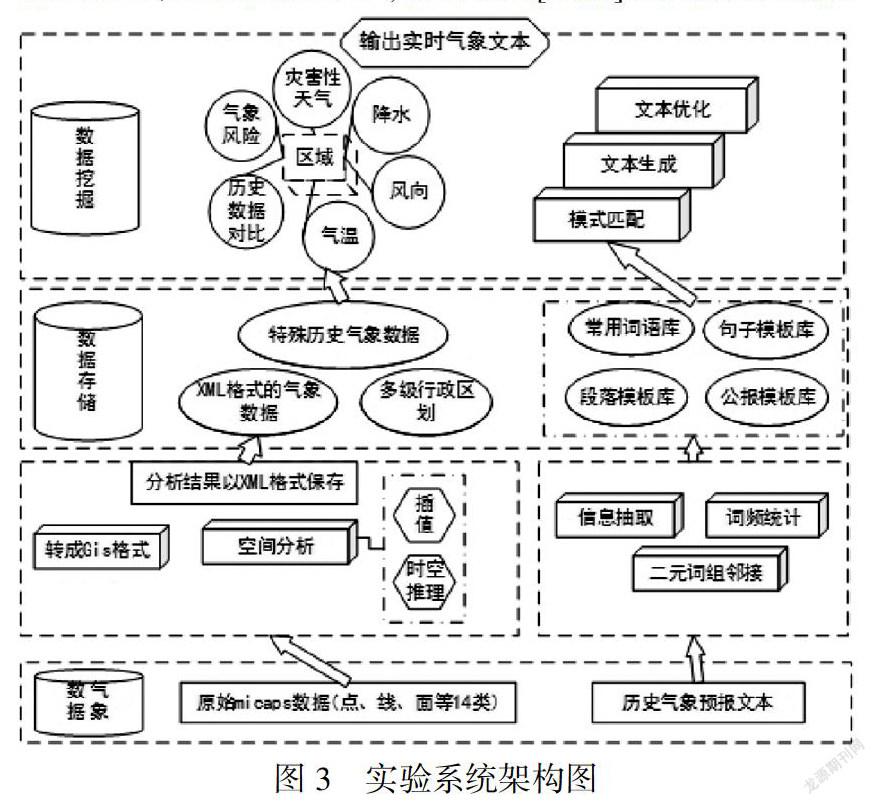
根据上述模型,对原始气象数据进行空间计算,并利用自然语言处理技术构建气象预报文本的模板库,实现一套气象预报文本实时生成系统.系统框架如图3所示.
3 实验结果及分析
实验采用的气象数据来自中国气象局,包括气温、降雨、降雪等普通气象类型以及霾预警、台风预警、暴雨预警等各种预警类型,类别范围广且具有代表性.实验结果分为以下两种评价方式,邀请三位中国气象局专业人员进行评价:
(1)对系统生成的各气象类型预报文本分别进行人工评级,从准确性和通顺性两个角度,评价等级分为五级:很好、好、一般、不好、差,其中准确性是指文本中的气象类型、气象数值、地理变量等是否与原始气象数据所表达的一致;通顺性是指文本用词、语句是否符合气象预报的规范;统计五个等级下有多少篇对应的预报文本,规定一般及以上等级为合格,并计算合格率.
(2)对系统生成的200篇气象预报文本与对应的历史文本(由人工生成)进行相似性比对,分为:很好、好、一般、不好、差五个等级,并统计合格率.
3.1 各气象类型的预报文本实时生成实验分析
以降水预报实验结果为例,降水预报的输出结果如下:
请输入要测试的数据类型(1,3,4,7,14,lwfd):14
正在处理第十四种类型的数据...
正在处理暴雨模块...
Handel micaps14......
正在与第一级别行政区划叠加..................
0...10...20...30...40...50...60...70...80...90...100 - done.
与一级行政区划叠加后返回值(0表示正常):0
将与一级行政区划的结果图层写入磁盘shp文件的处理结果(0表示成功):0
正在与第二级别行政区划叠加..................
0...10...20...30...40...50...60...70...80...90...100 - done.
与二级行政区划叠加后返回值(0表示正常):0
将与二级行政区划的结果图层写入磁盘shp文件的处理结果(0表示成功):0
江南中部、贵州东南部等地大部地区,广东、江苏、福建西北部等地部分地區有大雨,安徽、广西、湖南、江西、浙江、广东西北部、湖北东部等地部分地区有暴雨,其中安徽南部、广西东北部、湖南南部、江西北部等地部分地区有大暴雨.
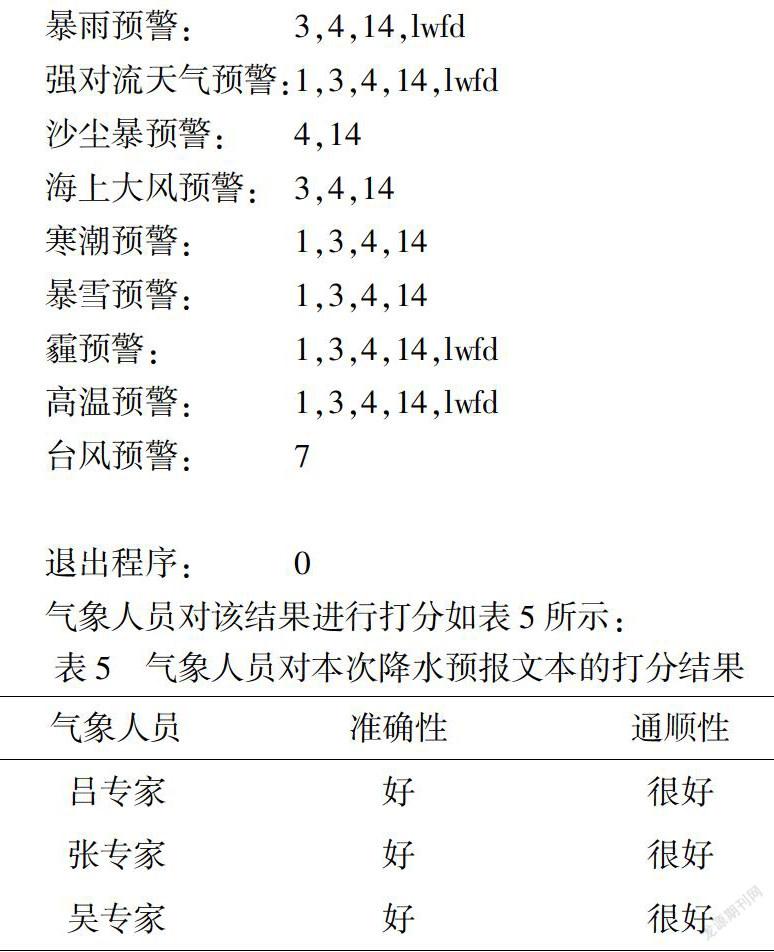
暴雨预警: 3,4,14,lwfd
强对流天气预警:1,3,4,14,lwfd
沙尘暴预警: 4,14
海上大风预警: 3,4,14
寒潮预警: 1,3,4,14
暴雪预警: 1,3,4,14
霾预警: 1,3,4,14,lwfd
高温预警: 1,3,4,14,lwfd
台风预警: 7
退出程序: 0
气象人员对该结果进行打分如表5所示:
可以看出,系统本次生成降水预报文本的准确性好,通顺性很好.
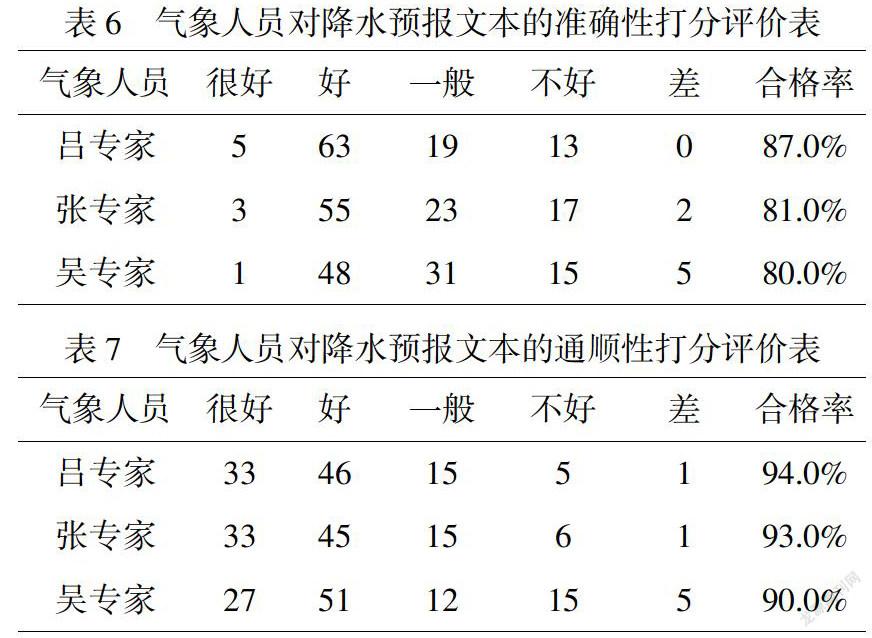
此外,随机抽取100份原始降水数据进行处理,由系统自动生成100篇降水预报文本,邀请中国气象局三位气象专业人员分别针对文本的准确性和通顺性进行评级,准确性、通顺性结果如表6、表7所示.
可以看出,对于降水数据,系统自动生成的预报文本准确性在80%以上,通顺性可达90%(均取最低值).
分别对每一种气象类型的准确性和通顺性进行打分,部分汇总结果如表8所示.
通过实验可以看出,此系统生成的气象预报文本的准确性都在71%以上,通顺性都在85%以上.
3.2 实证比对分析
目前系统支持各类天气的实况预报和灾害天气预警,为了验证其输出的准确性,随机选取2015年5月28日发布的全国降水预报原始数据做为输入,本系统输出的气象预报文本如下:
28日08时至29日08时,江南中东部、华南、新疆西部、四川省、西宁、黑龙江西北部等地有中到大雨,其中,华南地区北部和南部沿海、江西中部和东北部、浙江西部和北部、安徽南部等地的部分地区有暴雨,广东北部、广西东北部等地局地有大暴雨(100~130毫米).新疆地区、内蒙古中东部、华北北部、东北地区南部等地有4~6级风.新疆地区等地的部分地区有扬沙或浮尘.东海南部海域、台湾海峡、台湾以东有5~7级、阵风8级的西南风,南海大部海域、北部湾有5~6级、阵风7级的西南或偏南风.
当天中央气象台发布的气象预报文本如下:
28日08时至29日08时,江南中东部、华南、新疆伊犁河谷、川西高原北部、黑龙江西北部等地有中到大雨,其中,华南北部和南部沿海、江西中部和东北部、浙江西部和北部、安徽南部等地的部分地区有暴雨,广东北部、广西东北部等地局地有大暴雨(100~130毫米).新疆、内蒙古中东部、华北北部、东北地区南部等地有4~6级风.新疆南疆盆地等地的部分地区有扬沙或浮尘.东海南部海域、台湾海峡、台湾以东洋面有5~7级、阵风8级的西南风,南海大部海域、北部湾有5~6级、阵风7级的西南或偏南风.
从2015-2017年的气象预报文本数据库中,随机抽取200篇天气预报(这些文本是预报员手工写的)以及其相对应的原始气象数据(矩阵格式),同时用该系统调用这200份原始气象数据进行分析,生成相应的天气预报文本.
气象专业人员的打分原则是系统生成的文本能否准确并简练的描述当日气象信息.专家打分的结果经过统计,如表9所示,证明了系统自动生成的气象预报文本易读、可用性较高.
由表9可知,最后三人打分的合格率分別为89.0%、85.5%和84.0%,由此可见,系统预报的结果能够比较好地描述气象信息,基于空间分析的方法也有足够的可行性.
4 结束语
本文利用自然语言处理技术分析海量历史气象文本,抽取其中的语法、用词规律,针对每一种天气类型建立对应的预报文本模板;另外利用QGIS技术对原始气象数据进行解析,提取空间信息,并建立了一套完备的空间推理规律,最后通过模式匹配、文本生成并优化来生成实时的气象预报文本.目前,已证实了系统的准确性、实时性和实用性.但是,中国气象局发布的气象预报种类繁多,也就是说,本文所研究的系统仅仅是一个开始,在气象领域的文本自动生成技术还有很多可发展空间,届时会需要更多的空间推理方法作为支撑,这也是后续的研究方向.
参考文献:
〔1〕赵汝冰,肖如林,万华伟,等.锡林郭勒盟草地变化监测及驱动力分析[J].中国环境科学,2017,37(12):4734-4743.
〔2〕刘彬.气象GIS空间数据集成组织与系统原型设计[D].南京:南京信息工程大学,2017.
〔3〕吴焕萍,吕终亮,张华平,等.气象落区文本自动生成研究[J].计算机工程与应用,2014(13):247-266.
〔4〕李涛,冯仲科,孙素芬,等.基于Hadoop的气象大数据分析GIS平台设计与试验[J].农业机械学报,2019,50(1):180-188.
〔5〕DUFFY D Q, SCHANSE J L, THOMPSON J H, et al. Preliminary evaluation of MapReduce for high-performance climate data analysis [EB/OL]. [2016-04-08]. https://ntrs.nasa.gov/archive/nasa/casi.ntrs.nasa.gov/2012009187.pdf.
〔6〕Huang Hongzhao,Larry H,Ji Heng. Leveraging deep neural networks and knowledge graphs for entity disambiguation [DB/OL].Ithaca:ArXiv,[2015-04-28]. Https://arxiv.org/pdf/1504.07678v1.pdf.
〔7〕Berg-KirkpatrickT, Gillick D, Klein D. Jointly learning to extract and compress[C]. Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies-Volume 1. Association for Computational Linguistics, 2011:481-490.
〔8〕Galanis D, Androutsopoulos I. An extractive supervised two-stage method for sentence compression[C]. Human Language Technologies: The 2010 Annual Conference of the North American Chapter of the Association for Computational Linguistics. Association for Computational Linguistics, 2010: 885-893.
〔9〕张红斌,殷依,姬东鸿,等.基于词序列拼积木模型的图像句子标注研究[J].北京理工大学学报,2017,37(11):1144-1149.
〔10〕李东阳.基于模板匹配的交通领域标准信息抽取技术[D].西安:长安大学,2019.
猜你喜欢
导航定位学报(2022年5期)2022-10-13
电机与控制学报(2018年9期)2018-05-14
计算机应用(2016年10期)2017-05-12
软件(2016年7期)2017-02-07
计算机应用(2016年12期)2017-01-13
现代商贸工业(2016年21期)2016-12-26
电脑知识与技术(2016年10期)2016-06-16
电脑知识与技术(2016年5期)2016-04-14
科技视界(2016年5期)2016-02-22
珠江水运(2015年15期)2016-02-21
