
基于RGBD的实时头部姿态估计
2019-09-09 03:27陈国军
图学学报 2019年4期
陈国军,杨 静,程 琰,尹 鹏
基于RGBD的实时头部姿态估计
陈国军,杨 静,程 琰,尹 鹏
(中国石油大学(华东)计算机与通信工程学院,山东 青岛 266580)
实时的头部姿态估计在人机交互和人脸分析应用中起着至关重要的作用,但准确的头部姿态估计方法依然具有一定的挑战性。为了提高头部姿态估计的准确性和鲁棒性,将基于几何的方法与基于学习的方法相结合进行头部姿态估计。在人脸检测和人脸对齐的基础上,提取彩色图像几何特征和深度图像的局部区域深度特征,再结合深度块的法线和曲率特征,构成特征向量组;然后使用随机森林的方法进行训练;最后,所有决策树进行投票,对得到的头部姿态高斯分布估计进行阈值过滤,进一步提高模型预测的准确度。实验结果表明,该方法与现有的头部姿态估计方法相比,具有更高的准确度及鲁棒性。
头部姿态估计;随机森林;RGBD数据;几何特征;深度特征
头部姿态估计简单的说,是通过图像推断出人的头部转动角度。准确的头部姿态估计可用于视线方向估计[1],驾驶员后视镜查看行为检测[2],预测驾驶员疲劳状态[3]或帮助残疾人控制轮椅方向等等,因此精确、快速的头部姿态估计已成为计算机视觉近年来的研究热点。从数据源角度分析,头部姿态估计的方法分为:基于二维彩色图像、基于深度图像和基于RGBD图像3种。
基于二维彩色图像的方法是最早应用到头部姿态估计的一种传统方法。LI等[4]采用基于模板匹配的方法对序列图像进行头部姿态估计,该方法简单,但准确度不高且计算量较大;郭知智等[5]使用基于几何的方法将眼角点和鼻尖作为特征点,利用自适应线性回归估计头部姿态,该方法对特殊点的依赖性较大;MA等[6]采用面部特征点的方法进行头部姿态估计,其需要手动提取面部区域,图像处理的时间较长;闵秋莎等[7]同样提出一种基于面部特征点定位的头部姿态估计方法,但该方法只能估计出头部的粗略方向。文献[8]提出面部行为分析工具OpenFace,使用面部68个特征点的相对位置估计头部姿态,其在头部转动较大的情况下特征点定位不够准确,头部姿态估计效果较差。
由于二维彩色图像受光照变化和部分遮挡的影响比较大,导致准确度低;基于深度图像的方法可以有效降低光照和遮挡的影响,提高了头部姿态的鲁棒性。文献[9]首次利用深度信息的随机回归森林方法进行头部姿态估计,且规定图像中只能有头部信息;刘袁缘等[10]引入树结构分层随机森林(random forest,RF)的方法进行头部姿态估计,提高了非约束环境下多类头部姿态估计的准确率和效率,但是结构复杂、计算量大;文献[11]提出一种基于特征点识别的计算框架,将头部姿态问题转换为空间鼻尖特征点和朝向特征点的问题,该方法对鼻子的遮挡变得极其敏感,稳定性不够。李成龙等[12]提出了一种基于卡尔曼滤波和随机回归森林的头部姿态估计方法,其使用卡尔曼滤波和随机回归森林相结合的方法进行头部姿态估计。该方法降低了深度图像的噪声影响,与单独的RF方法相比,其鲁棒性和准确性得到了提高。
由于深度图像存在噪声且解像度低,只使用深度信息进行头部姿态估计精确度较差,因此基于RGBD图像的方法受到越来越多人的关注。LI等[13]使用彩色图像检测特征点,并结合深度图像获得特征点的三维信息,使用Levenberg-Marquardt方法迭代优化姿态参数,最后使用卡尔曼滤波平滑参数。文献[14]使用基于AAM模型计算当前图像的头部姿态,然后使用估计的头部姿态值将图片转换为初始视图,最后计算初始视图和当前的图像特征点投影坐标之间的距离,用于估计头部姿态跟踪的误差值;文献[15]利用3D点云的图像集合,将当前视图转换为基于外观的集群;文献[16]提出了CLM-Z模型,在CLM的基础上增加了深度信息,进一步提高了头部姿态估计的准确度。彩色图像和深度图像相结合的方法改进了彩色图像对光照、阴影较敏感的缺点,通常具有很高的鲁棒性和准确性,但是由于一般要求使用的彩色图像分辨率较高,导致算法的计算速率低,很难保证实时性。
为了保证算法的效率,满足实时性的应用需求,本文提出一种基于RGBD的头部姿态估计方法,提取彩色图像中关键点几何位置特征、深度图像的局部深度特征以及法线和曲率特征,并使用RF的方法进行训练和预测。该方法有效地解决了复杂环境下的头部姿态估计问题,并且降低了现有方法对彩色图像高分辨率的要求,扩展了头部姿态估计的应用范围,很好的避免了不同环境下光照变化、阴影等问题。
1 图像特征提取
本文的研究目的是使用低成本传感器获得的彩色图像和低质量深度图像估计头部姿态。首先对图像进行人脸检测,提取头部位置的图像;然后进一步进行人脸对齐,定位面部特征点。为保证人脸检测算法的准确性及鲁棒性,本文采用了seetaFace进行人脸检测和对齐。
人脸检测模块基于一种经典级联结构和多层神经网络相结合的人脸检测方法[17]实现,其所采用的漏斗型级联结构(funnel-structured cascade,FuSt)专门针对多姿态人脸检测而设计,其中引入了由粗到精的设计理念,兼顾了速度和精度的平衡。
人脸对齐模块采用一种由粗到精的自编码器网络(coarse-to-fine auto-encoder networks,CFAN[18])来求解从人脸表观到人脸形状的复杂非线性映射过程。CFAN级联了多级栈式自编码器网络,其中的每一级均刻画从人脸表观到人脸形状的部分非线性映射。
为降低光照和阴影对图像的影响,采用了彩色图像的几何特征和深度图像特征相结合的方法进行头部姿态估计。几何特征和深度特征均是在人脸对齐定位特征点之后获取。
1.1 彩色图像特征提取
当头部发生转动时,由于头部与图像平面间的夹角发生改变,图像平面上关键点间的相对距离也会发生变化。所以文献[5-8]直接利用面部特征点的相对位置进行头部姿态估计。为了提高准确率,在提取面部特征点相对位置的基础上,进一步提取特征点组成三角形的面积信息,丰富了图形特征,并使用RF进行训练。
在RGB图像中定位人脸关键点以后(图1),需为5个特征点编号,1为左眼,2为右眼,3为鼻尖,4为左嘴角,5为右嘴角。按照一定顺序,计算任意2点间的距离,以及任意不共线3点组成三角形的面积(当3点共线时,标记三角形面积为0)。提取每张彩色图片特征点之间的距离和三角形的面积作为输入特征,训练模型。

图1 人脸检测和人脸对齐
1.2 深度图像特征提取
除了彩色图像几何特征之外,还提取了深度图像特征,即5个特征点附近的局部深度特征(图2)。为了得到更加准确的头部姿态估计,在局部深度特征的基础上,进一步将深度数据转换成点云数据,提取法线特征(图3)以及曲率特征。

图2 深度图中提取对应特征点的局部深度信息

图3 点云法向量
表面法线是几何体一个很重要的特征,可以描述面部局部区域的凹凸情况,有效区分鼻尖点、嘴角点、眼角点等特殊点,常常被用于点云渲染、重建和注册等计算机视觉应用中。将深度图像转换为点云后,表面法线的问题可以近似转化为切面的问题,进而变成最小二乘法拟合平面的问题。因此表面法线的计算问题就变为分析近邻点组成的协方差矩阵的特征矢量和特征值问题,对于每一个点P,对应的协方差矩阵,即


采用基于Voronoi区域面积的方法计算离散曲率,先生成Delaunay三角网,再利用Voronoi图计算局部块的高斯曲率和平均曲率[19]。将高斯曲率和平均曲率的公式离散化,平均曲率向量为

其中,1()={|x与x之间有一条边};为x所在的Voronoi区域的面积之和(图4(b));α和β为边xx对应的2个角度(图4(d))。当x所在的某个三角形是钝角三角形时,需对作修正[20]。高斯曲率为
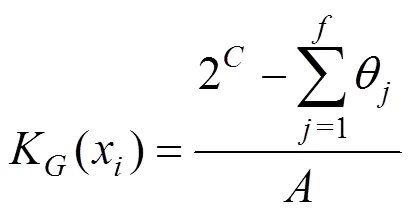
其中,为是x所在三角形的数目;角θ如图(4(e))所示。

(a) 离散点(b) Delaunay三角网格 (c) Voronoi图(d) 平均曲率
因此每组训练图像的参数为={P=(X,L)},其中,X为一幅图像得到的图像特征,即X= (A,D,N,C),A为5个特征点组成的线段距离和任意3个点组成三角形的面积特征,D为特征点区域局部深度块的深度特征;N为近邻的法线特征;C为局部深度块的高斯曲率和平均曲率特征;L为标注真实值的标签数据。图像特征提取完成以后,使用随机回归森林进行训练和测试。
2 训练和测试
RF是一种由决策树组成的著名机器学习算法。该方法已经被应用到解决计算机视觉的很多问题,如分类、回归和概率密度估计[21]。RF中的每棵决策树均由整个数据集中选取的随机样本独立生成。
随机回归森林算法随着决策树的数量变大,泛化误差收敛于一个极限[22],同时具有快速学习等优点。此外,其还适用于处理缺失的数据问题,并容易实现并行处理,对于实时的性能提供了条件。
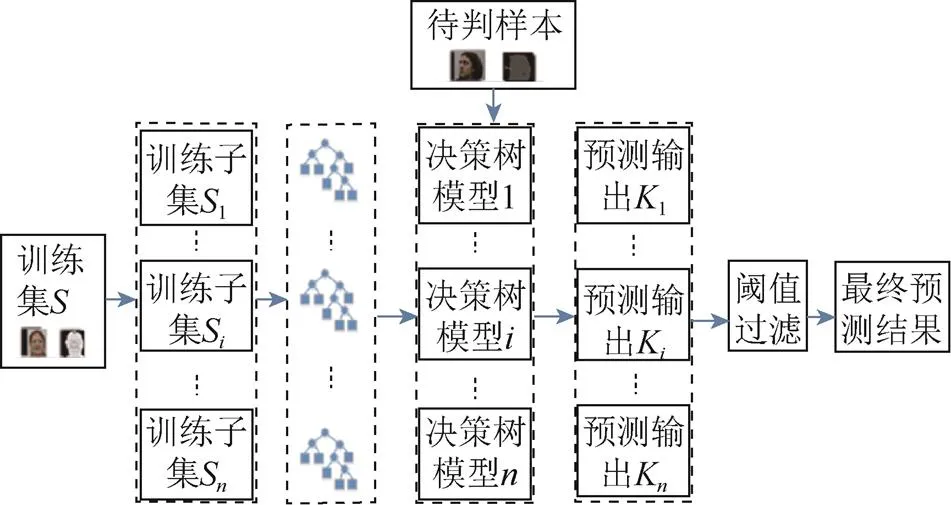
图5 使用随机回归森林进行头部姿态估计的过程
RF算法由训练和测试2个步骤组成。训练步骤主要是构建多树型分类器,包括数据归纳、树型结构的构造和参数的优化。在测试步骤中,由树生成的中间结果集成为最终的结果。为了提高准确度,将所有决策树的投票结果进行阈值过滤,从而去除掉一些异常点。
用于训练和测试的数据来自于Biwi数据集[9],其中90% (大约13 500张图片)用于训练,10% (大约1 500张图片)用于测试准确度和误差值。
2.1 Biwi数据集
Biwi Kinect head pose database含有由微软Kinect捕捉到的彩色图像和低分辨率、存在噪声的深度数据,该数据集带有真实头部转动的标签,且在头部转动角度和面部外观方面有很大的差异,如眼镜和帽子、面部表情和发型引起的部分遮挡。该数据库有超过15 K张图片,数据在距离传感器1 m远的地方采集,人脸平均大小为90×110像素。所有采集对象均需转动其头部,并试图涵盖所有可能的旋转角和俯仰角,即左右转动角度为–75°~+75°,上下点头角度为–60°~60°以及左右偏头的角度为–20°~20°。
2.2 训练过程
利用RF进行分类是将头部姿态估计问题建模为一个回归问题,并将彩色图像和深度图像提取的特征使用决策树映射到一组头部姿态的标签中。经验证,RF比文献[23]中的单个分类器显示了更好的性能,且不易出现过拟合现象。
RF从根节点递归地构建决策树的过程如下:
(1) 随机选择训练子集。在训练集中,利用不放回抽样方法选择一组训练当前树的训练子集S,并由第1节提取的图像特征和带注释的头部标签组成,参数化由1.2节的={P=(X,L)}表示。
(2) 随机选择特征集。假设总特征数为(即第1节提取的特征),则在每一轮生成决策树的过程中,由个特征中随机选取(<)个特征组成一个新的特征集,并使用新的特征集生成决策树。
(3) 选取最优特征。选择不同特征顺序,可产生不同决策树,选择信息增益率大的特征可使各子集下标签更纯净。度量分类后,提高数据集纯度的方式为计算个特征的信息增益率,并选择最优特征,信息增益率越大,表明特征分类能力越强。信息增益率的计算方法为

其中,(,)为信息增益,使用划分前几何特征和深度特征熵的值与划分后熵的差值来衡量当前特征对于样本集合划分效果的好坏,计算式为

对于待划分的数据集S,其划分前的熵()是确定的,但是划分之后数据子集的熵(|)是不确定的,(|)越小说明使用此特征划分得到的子集的不确定性越小(即纯度越高),因此需选择使得信息增益最大的特征来划分当前数据集。
待划分数据集划分前的熵()为
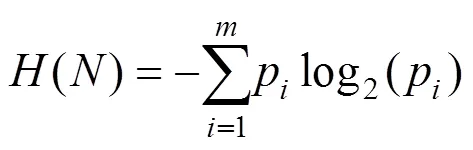
其中,为待划分的训练数据集;为子节点的数量;P为类别样本数量占所有样本的比例。
对待划分数据集,选择特征作为决策树判断节点时,在特征作用后的信息熵为(|),即
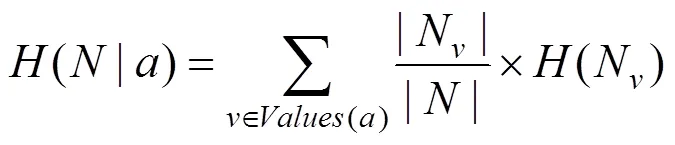
()为数据集以特征作为随机变量熵的倒数,表示分裂子节点数据量的信息增益,即

其中,为子节点的数量;n为被分到第个子节点的数据量;为父节点数据量。(,)被称为是的“固定值”,用于描述属性的纯度。如果只含有少量的取值,其纯度就比较高,否则的取值越多,纯度就越低,(,)的值也就越大,所得到的信息增益率就越低。
(4) 根据二进制测试的结果,每个分割节点将样本集分成2个子集。如果树的深度达到预定值或该节点的数据量到达一个指定的数值,则当前结点为叶子结点,不再进行递归。否则转到第(3)步。
2.3 测试方法
给定一个新的彩色图像和对应深度图像,通过人脸检测和人脸对齐获取图像特征并作为输入,使用训练生成的模型进行头部姿态角度预测。每棵树中给定样本,从根目录开始由存储在结点的二进制测试进行引导。在树的每一个非叶节点上,由存储的二进制测试对输入图像进行评估、判断,并发送至左结点或右结点,下个结点依次递归,直到叶子结点得到一个角度预测值。然后,对所有决策树结果进行整合得到最终的角度预测值。
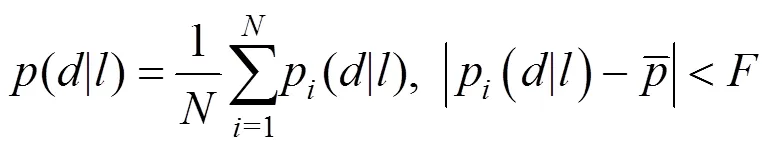
3 实验结果
为了测试非约束环境下的估计结果,本文在Biwi数据集上进行测试。首先,对3种改进方案进行了评价,并对其关键参数的影响进行检验;此外,在不同环境下,将RF估计值与真实值进行了对比;最后,在Biwi数据集上对RF的整体性能进行了验证,并与其他方法进行了比较。
所有的实验都是在Intel i7-6700 (3.4 GHz CPU)的PC平台上完成的。实验使用的参数值为:叶节点的最小样本数量为10,RF训练图像数量为13 500,测试数量为1 500。
3.1 实验参数对实验结果的影响
RF由决策树组成,因此,不同数量的决策树训练的模型准确度不同。如图6所示,在使用不同图像特征进行训练时,当决策树数量由10增加到100,头部姿态的准确率曲线均在不断提升,但50以后,误差减小的幅度变小,准确率提升也变得缓慢,该结果符合RF的规模达到一定程度时,森林可解释性减弱的特征[24]。并且,随着决策树的数量增大,RF的构建时间也会随之增加。为了平衡速度与精度,最终决策树的数量定为50,在此基础上进行其他实验。

图6 决策树数量和平均准确率的关系
图7显示了不同图像特征对识别精度的影响。由图7可知,在几何特征的基础上,增加面部的局部深度信息,在一定程度上可减小头部姿态的平均角度误差,同时增加法线和曲率等特征也可提高了姿态角的估计精度。
表1为使用不同阈值过滤各个决策树的预测结果,即最终预测值与真实值的误差的关系,决策树数量为50,图像特征为几何特征和局部深度特征以及深度块的曲率和法线特征。

图7 决策树数量与平均角度误差的关系
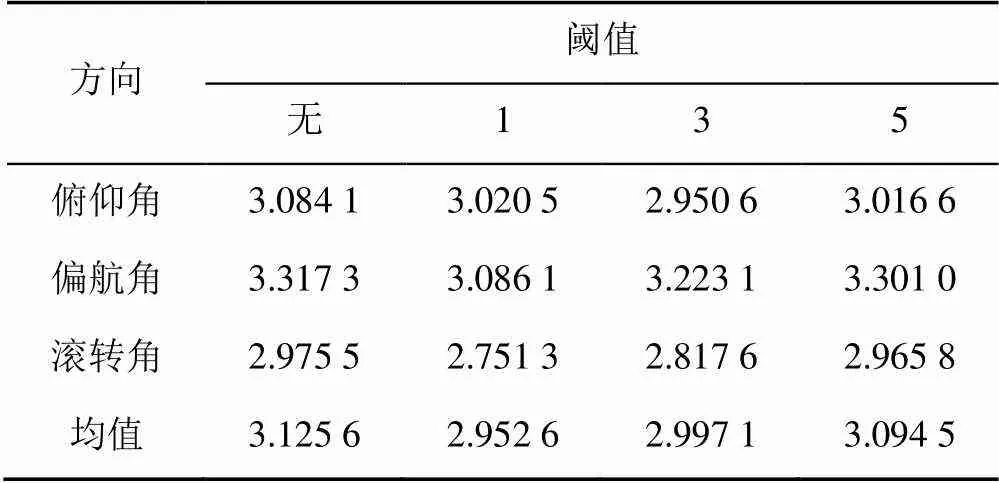
表1 阈值大小与平均误差的关系
由表1可以看出,设置阈值过滤决策树提高了RF的精确度。从理论上讲,阈值设置的越小,精确度越高,但是,当一些决策树预测结果整体偏高或偏低时,小的阈值设置对于精确度的提高并不明显,因此本文阈值选择3。
3.2 不同场景下的实验结果
为了验证方法有效性,图8和图9考虑了光照条件、相机位置、眼镜遮挡的变化对实验结果的影响。

(a) 光照条件1(b) 光照条件2 (c) 眼镜遮挡+角度1(d) 眼镜遮挡+角度2

(a) 实际应用1(b) 实际应用2
图8(a)与8(b)表示不同光照条件下的实验效果。图8(c)与8(d)表示了不同角度与遮挡情况下的实验效果。图9为实际应用中的测试实例。通过实验表明,该方法在光照、不同角度和遮挡情况下表现较好,具有一定的鲁棒性,且速度较快,可以进行实时的头部姿态估计。
图10(a)~(d)分别表示眼睛、鼻子、嘴部特征点检测不准确时,头部姿态估计值与真实值的对比。从图中可以看出,鼻尖位置偏移较其他特征点的偏移,对头部姿态估计值的影响稍大,最大差值为3°左右,因此,对于个别特征点的少量偏移具有很好的鲁棒性。

(a) 情况1(b) 情况2 (c) 情况3(d) 情况4
本文方法不单独依赖于面部某一特征点,因此,当出现遮挡或者个别特征点检测不准确时,对结果的影响小于依赖特定特征点的方法。
3.3 与其他方法准确度对比
为了更好地说明算法的精确度,图11将本文方法与其他使用加权RF进行头部姿态估计的实验结果进行对比,即线性加权法[25]和交叉加权方法[26]以及文献[27]中的动态加权法的实验结果。其显示了不同的角度阈值与实验准确率的关系。

图11 与加权RF方法对比
表2为在相同数据集Biwi下,与文献[28]、文献[29]、文献[16]、文献[30]及文献[8]方法在不同方向的误差及平均误差。文献[16]及[28]-[29]均使用RGBD图像特征,因此更适合作为对比方法。结果显示,本文方法在数据集上展示了较优的性能。
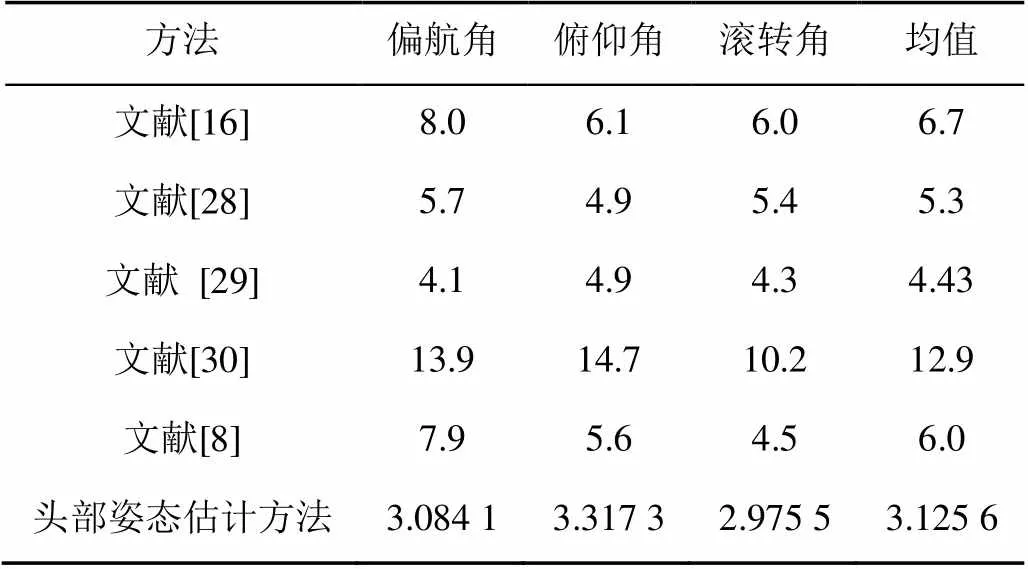
表2 各个方向的角度误差及平均误差
从图11明显看出,本文方法的准确率远远高于使用加权RF的方法。从表2可以看出,本文方法在不同角度的误差值均小于其他方法。因此,其具有更高的准确性。
当最小人脸设置为80×80时,各过程耗时见表3。总时间在30 ms左右,因此可以达到实时的性能要求。
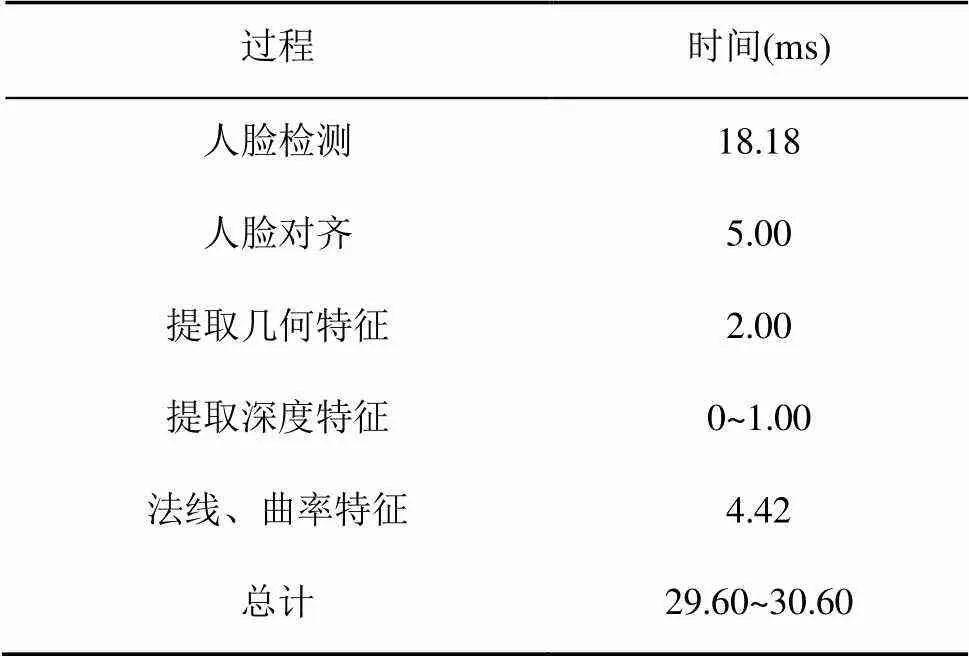
表3 头部姿态估计耗时表
4 结 论
本文提出一种基于RGBD进行实时头部姿态估计的方法,提取了彩色图像的几何特征和深度图像的深度特征以及法线和曲率特征,使用RF的方法进行训练,并在模型预测时使用阈值过滤。实验结果表明,该方法与使用整个头部的深度特征相比具有更高的准确性,并且受光照和部分遮挡的影响较小,具有更高的鲁棒性。
[1] ROSSI S, LEONE E, STAFFA M. Using random forests for the estimation of multiple users’ visual focus of attention from head pose [M]//AI*IA 2016 Advances in Artificial Intelligence. Heidelberg: Springer, 2016: 89-102.
[2] 黄波, 钟铭恩, 吴平东, 等. 基于车载视觉的驾驶员后视镜查看行为检测[J]. 图学学报, 2018, 39(3): 477-484.
[3] WONGPHANNGAM J, PUMRIN S. Fatigue warning system for driver nodding off using depth image from Kinect [C]//2016 13th International Conference on Electrical Engineering/Electronics, Computer, Telecommunications and Information Technology (ECTI-CON). New York: IEEE Press, 2016: 1-6.
[4] LI X H, CHEN H Y, CHEN Q L. A head pose detection algorithm based on template match [C]//2012 IEEE Fifth International Conference on Advanced Computational Intelligence (ICACI)). New York: IEEE Press, 2012: 673-677.
[5] 郭知智, 周前祥, 柳忠起. 基于自适应线性回归的头部姿态计算[J]. 计算机应用研究, 2016, 33(10): 3181-3184.
[6] MA B P, CHAI X J, WANG T J. A novel feature descriptor based on biologically inspired feature for head pose estimation [J]. Neurocomputing, 2013, 115: 1-10.
[7] 闵秋莎, 刘能, 陈雅婷, 等. 基于面部特征点定位的头部姿态估计[J]. 计算机工程, 2018, 44(6): 263-269.
[8] BALTRUSAITIS T, ROBINSON P, MORENCY L P. OpenFace: An open source facial behavior analysis toolkit [C]//2016 IEEE Winter Conference on Applications of Computer Vision (WACV). New York: IEEE Press, 2016: 1-10.
[9] FANELLI G, GALL J, VAN GOOL L. Real time head pose estimation with random regression forests [C]// 2011 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). New York: IEEE Press, 2011:617-624.
[10] 刘袁缘, 陈靓影, 俞侃, 等. 基于树结构分层随机森林在非约束环境下的头部姿态估计[J]. 电子与信息学报, 2015, 37(3): 543-551.
[11] 乔体洲, 戴树岭. 基于特征点识别的头部姿态计算[J]. 北京航空航天大学学报, 2014, 40(8): 1038-1043.
[12] 李成龙, 钟凡, 马昕, 等. 基于卡尔曼滤波和随机回归森林的实时头部姿态估计[J]. 计算机辅助设计与图形学学报, 2017, 29(12): 2309-2316.
[13] LI C L, ZHONG F, ZHANG Q, et al. Accurate and fast 3D head pose estimation with noisy RGBD images [J]. Multimedia Tools and Applications, 2018, 77(12): 14605-14624.
[14] STRUPCZEWSKI A, CZUPRYŃSKI B, SKARBEK W, et al. Head pose tracking from RGBD sensor based on direct motion estimation [M]//Lecture Notes in Computer Science. Heidelberg: Springer, 2015: 202-212.
[15] KIM D, PARK J, KAK A C. Estimating head pose with an RGBD sensor: A comparison of appearance-based and pose-based local subspace methods [C]//2013 IEEE International Conference on Image Processing. New York: IEEE Press, 2013: 3637-3641.
[16] BALTRUŠAITIS T P, ROBINSON P, MORENCY L P. 3D constrained local model for rigid and non-rigid facial tracking [C]//2012 IEEE Conference on Computer Vision and Pattern Recognition. New York: IEEE Press, 2012: 2610-2617.
[17] WU S Z, KAN M N, HE Z L, et al. Funnel-structured cascade for multi-view face detection with alignment-awareness [J]. Neurocomputing, 2017, 221: 138-145.
[18] ZHANG J, SHAN S G, KAN M N, et al. Coarse-to-fine auto-encoder networks (CFAN) for real-time face alignment [M]//Computer Vision – ECCV 2014. Cham: Springer International Publishing, 2014: 1-16.
[19] MEYER M, DESBRUN M, SCHRÖDER P, et al. Discrete differential-geometry operators for triangulated 2-manifolds [M]//Mathematics and Visualization. Heidelberg: Springer, 2003: 35-57.
[20] LEVIN D. Mesh-independent surface interpolation [M]// Geometric Modeling for Scientific Visualization. Heidelberg: Springer, 2004: 37-49.
[21] CRIMINISI A, SHOTTON J, KONUKOGLU E. Decision forests for classification, regression, density estimation, manifold learning and semi-supervised learning [J]. Microsoft Research Technical Technical Rreport, 2011, 114(46): 224-236.
[22] BREIMAN L. Random forests [J]. Machine Learning, 2001, 45(1): 5-32.
[23] FANELLI G, DANTONE M, GALL J, et al. Random forests for real time 3D face analysis [J]. International Journal of Computer Vision, 2013, 101(3): 437-458.
[24] BREIMAN L. Random forests [J]. MachineLearning, 2001, 45(1): 5-32.
[25] OKADA R. Discriminative generalized hough transform for object dectection [C]//2009 IEEE 12th International Conference on Computer Vision. New York: IEEE Press, 2009: 2000-2005.
[26] GALL J, YAO A, RAZAVI N, et al. Hough forests for object detection, tracking, and action recognition [J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2011, 33(11): 2188-2202.
[27] SARAGIH J M, LUCEY S, COHN J F. Deformable model fitting by regularized landmark mean-shift [J]. International Journal of Computer Vision, 2011, 91(2): 200-215.
[28] REKIK A, BEN-HAMADOU A, MAHDI W. 3D face pose tracking using low quality depth cameras [C]//The 8th International Conference on Computer Vision Theory and Applications, VISAPP 2013. Heidelberg: Springer, 2013: 223-228.
[29] SAEED A, AL-HAMADI A. Boosted human head pose estimation using kinect camera [C]//2015 IEEE International Conference on Image Processing (ICIP). New York: IEEE Press, 2015: 1752-1756.
[30] ASTHANA A, ZAFEIRIOU S, CHENG S Y, et al. Incremental face alignment in the wild [C]//2014 IEEE Conference on Computer Vision and Pattern Recognition. New York: IEEE Press, 2014: 1859-1866.
Real-Time Head Pose Estimation Based on RGBD
CHEN Guo-jun, YANG Jing, CHENG Yan, YIN Peng
(Computer and Communication Engineering, School of China University of Petroleum, Qingdao Shandong 266580, China)
Real-time head pose estimation plays a crucial role in the application of human-computer interaction and face analysis, but accurate head pose estimation methods still face certain challenges. In order to improve the accuracy and robustness of the head pose estimation, this paper combines the geometry-based method and the learning-based method for head pose estimate. On the basis of face detection and face alignment, the geometric feature of the color image and the local area depth feature of the depth image are extracted, combining with the normal and curvature feature of the depth block to form the feature vector group, and then the random forest method is used to do the training. Finally, all decision trees are involved in the vote, and the resulting Gaussian distribution of the head pose is filtered by thresholds to further improve the model’s accuracy. Experimental results show that the proposed method has higher accuracy and robustness than the existing head pose estimation methods.
head pose estimation; random forest; RGBD data; geometric feature; depth feature
TP 391
10.11996/JG.j.2095-302X.2019040681
A
2095-302X(2019)04-0681-08
2018-11-11;
定稿日期:2018-11-21
国家“863”计划主题项目子课题(2015AA016403);虚拟现实技术与系统国家重点实验室(北京航空航天大学)开放基金(BUAA-VR-15KF-13)
陈国军(1968-),男,江苏如东人,副教授,博士,硕士生导师。主要研究方向为图形图像处理、虚拟现实及科学可视化等。 E-mail:chengj@upc.edu.cn
猜你喜欢
世界科学技术-中医药现代化(2021年8期)2021-12-21
少儿美术·书法版(2021年9期)2021-10-20
小学生必读(低年级版)(2021年5期)2021-08-14
东北电力大学学报(2020年5期)2020-10-27
电子制作(2019年16期)2019-09-27
动漫星空(2018年9期)2018-10-26
电子制作(2018年16期)2018-09-26
物联网技术(2017年5期)2017-06-03
电子制作(2017年24期)2017-02-02
中央民族大学学报(自然科学版)(2016年4期)2016-06-27
