
网络社区划分在软件质量问题分析中的应用
2019-09-09 03:38胡学飞李增扬
小型微型计算机系统 2019年9期
胡学飞,李 兵,2,李增扬
1(武汉大学 计算机学院,武汉 430072)2(武汉大学 复杂网络研究中心,武汉 430072)3(华中师范大学 计算机学院,武汉 430079) E-mail:huxuefei@whu.edu.cn
1 引 言
计算机行业的快速发展使得软件工程受到越来越多的关注,软件系统也变得更加复杂.在如今信息化的时代,随着人们对软件的依赖程度不断增加,提出的功能点也变得多样,相应的软件系统必须不断的升级或者打补丁来满足需求,相应的对代码的质量、整个软件的架构和安全性都有更高的标准,这都大大的增加了软件系统的复杂性[1].如何对这些复杂系统进行研究,帮助其更好的发展显得愈发重要.
20世纪90年代,复杂系统成为了一门独立学科,90年代末,为了研究复杂系统,产生了复杂网络[2].复杂系统可以看作是由大量的有关联的子系统构成,我们如果把子系统视为结点,把它们之间的作用视为边,那么复杂系统就可以看成是一个复杂网络.1998年,在复杂网络的领域中,Watts和Strogatz提出了小世界网络(Small World Network,简称SWN)模型[3].1999年,Barabási和Albert又提出了无标度特征[4,5].无数学者投入到复杂网络理论的研究之中,大大促进了其发展.
复杂网络研究具有很强的跨学科特色,它可以与数理学科、生命学科和工程学科等其他学科联系起来,成为其他领域的研究方法[6].因此,复杂网络研究作为一个新兴的研究领域,受到格外的关注.同样,复杂网络理论研究给软件工程研究也打开了新思路.以复杂网络理论作为基础,将软件中的源文件看作节点,文件之间的关系看作边,软件系统则视为节点和边的集合,对软件系统结构的研究就转化为对其网络图的研究[7-9].
软件项目开发的过程中,由于软件故障或新功能需求,开发人员会对源文件不断地修改,并将这些修改提交到版本控制系统.通常,一次提交(commit)包括源文件的增加、删除和修改,这些信息被保存在版本控制系统中.软件项目源文件之间的引用调用数量可视为源文件间依赖(dependency)的强度,软件开发的提交信息中源文件被同时修改(co-change)的次数视为其被同时修改的频度.已有研究发现在Windows 7中,具有依赖关系的源文件更容易被同时修改[10,11],我们希望通过实验证实在开源软件中也存在这个规律,即依赖关系的强度和它们的同时修改的频度具有一致性.如果存在同时大量被修改的源文件不存在依赖关系,我们发现其中往往有问题,这些问题会导致整个项目质量的降低.所以,我们通过不符合一致性的源文件进一步探索其中存在的问题.
复杂网络理论研究给我们提供了很好的方法.对于一个软件系统,将文件视为点,文件之间的关系视为边,关系的强弱视为边权,复杂的软件系统就可以用加权网络来表示.我们分别根据两源文件的依赖和同时修改关系,构建依赖关系网络(dependency network)和同时修改关系网络(co-change network).使用了Girvan-Newman算法[12](GN算法)对软件的依赖关系网络和同时修改关系网络进行了社区划分.我们猜想根据两种关系划分出来的结果会表现出一致性,对于成功优秀的项目,实验结果证实了我们的猜想,而对于质量较低的项目则结果不理想,我们对有出入的地方进行分析,找出不一致源文件出现的原因,如代码的复制粘贴、混乱的引用等,给软件中问题的发现方法提供新思路.
本文的组织结构如下:第2节我们将具体的介绍实验的方法,对实验中的项目选择、数据收集和处理、实验过程等做详细的说明;第3节,给出实验结果,验证猜想并分析出现不一致的原因;第4节,对实验和未来的工作进行讨论;第5节,得出结论.
2 研究设计
本节阐述了本文的研究目的,并根据研究目的提出研究问题,设计分析项目中源文件的依赖关系和其同时修改关系一致性的研究过程.
2.1 研究目的和研究问题
本文的研究目的是用复杂网络理论的方法,证明项目中源文件依赖关系和其同时修改关系具有一致性,并通过不符合一致性的源文件发现其中存在的问题.基于该研究目标,我们定义以下研究问题(Research Question,简称RQ):
RQ1:项目中源文件之间的依赖关系和同时修改关系是否存在一致性?
通过此研究问题,我们希望验证我们提出的两种关系存在一致性的猜想.为进一步研究奠定基础.
RQ2:出现源文件依赖关系和同时修改关系不一致现象的项目可能存在哪些问题?
通过此研究问题,我们希望从两种关系不一致的项目中发现可能存在的问题.发现一种新的项目问题的识别方法.
2.2 实验设计
为了得到研究问题的答案,我们设计本次实验分为四个阶段,分别是数据收集、数据处理、源文件划分、实验结果分析.具体流程见图1.
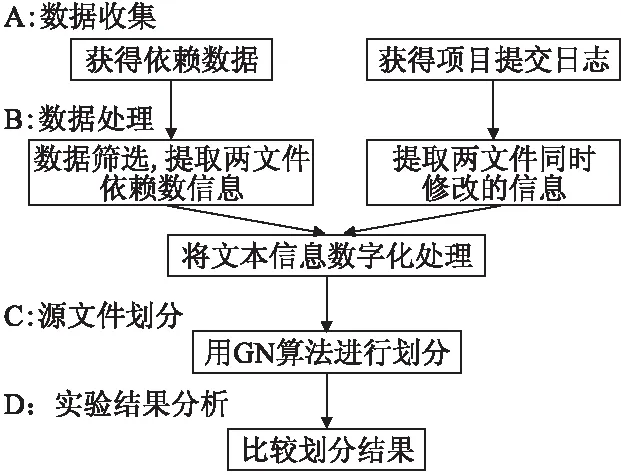
图1 实验流程图Fig.1 Experiment procedure
A:数据收集
此次实验研究对象是Java项目,仅仅分析Java源文件,忽略其他类型的源文件.近些年来网站和各种企业管理系统快速发展,Java作为开发此类项目的流行语言受到越来越多的关注,并且应用范围越来越广,再者,关于Java的分析工具比较成熟,所以我们选择了Java项目.
软件项目源文件之间的引用调用数量可视为源文件间依赖的强度,如文件A中有2处引用了文件B中的类,我们就认为文件A与文件B之间存在依赖关系,并且依赖强度为2.为了研究项目源文件的依赖关系,我们使用静态项目分析软件Understand(http://understand-china.com),它集成了代码编辑器,能将分析结果以各种形式呈现给用户.借助Understand,将项目代码导入后可以方便地获取到源文件之间依赖关系的相关数据.
为了研究项目中源文件的同时修改关系,我们在GitHub上获得项目的代码及其提交日志.通过Git版本控制系统的源客户端TortoiseGit我们可以下载项目的全部代码,并得到开发过程的提交日志.
B:数据处理
借助Understand工具,很方便能导出源文件的依赖关系.我们开发了一个工具从Understand导出的Excel文件中提取出两文件名和总依赖数.最后得到的是项目中每两个有依赖关系的源文件名称及其调用引用的数目,即源文件名A,源文件名B,调用引用数目x.
软件项目源文件之间的同时修改关系要对项目开发过程中的提交日志进行数据处理.在项目的提交日志中,每两个在同一个提交记录中增加或者修改的源文件都被认为是同时修改,其他情况,如删除或者修改版本号则不视为修改.我们计算每两个源文件在所有提交记录中同时修改的次数.得到的是每两个有同时修改关系的源文件名称及其同时修改的次数,即源文件名A,源文件名B,同时修改次数x.图2中,我们会得到如下三条记录:A.java,B.java,1;A.java,C.java,1;B.java,C.java,2.
需要指出的是,在数据中存在大量同时修改次数很少的记录,它们产生的原因主要是项目一次提交中提交了大量源文件的修改信息,其中存在没有任何关系的源文件也被同时提交.在后续的实验中进行了社区划分,经过对衡量网络中社区稳定度的模块化度量值Q[12,13]的计算,我们发现这种数据对源文件的划分的准确性产生了很大的影响,即Q值很低,这些数据也极大的影响了数据处理的速度,所以我们尝试着去除掉次数较少的数据使社区比较稳定,即Q值大于0.5.经过不断试验,对于我们研究的几个项目中,去掉次数小于3的数据能使Q值大于0.5,数据的处理速度也在可以接受的范围.我们删除了次数小于3的数据,但是这种处理也对实验结果造成一定的影响.

图2 同时修改数据处理说明附图Fig.2 co-change data processing
在源文件划分阶段,我们开发了一个程序进行数据处理,程序输入为数字格式而不是文本格式.为了让数据符合下一步划分所使用程序的输入格式,我们需要将项目中的文件进行编号,并记录下源文件名和数字编号的对应关系,然后将依赖关系数据和同时修改数据中的源文件名称都改为相应的编号.此步骤结束后,我们会得到均为数字的依赖关系数据和同时修改数据,还有两数据共用的一份源文件名与编号对应表.
C:源文件划分
社区结构是复杂网络的一个特性,整个网络是由很多社区组成的,社区中的结点联系很紧密,社区之间的联系比较少.为了比较两个网络,我们将问题转化为社区的比较,因为如果两种关系具有一致性,社区划分也会具有一致性,通过社区比较,可以发现关系不一致的地方.我们使用了GN算法对软件的依赖关系网络和同时修改关系网络进行了社区划分.
GN算法最初由Michelle Girvan和Mark Newman提出[12],是经典的社团发现算法,属于分裂的层次聚类算法,常用于研究复杂网络中的聚类特性.该算法根据网络中社团内部高内聚、社团之间低内聚的特点,逐步去除社团之间的边,取得相对内聚的社团结构.算法用边介数的概念来探测边的位置[13],某边的边介数定义为网络上所有顶点之间的最短路径通过该边的次数.由定义可知,如果一条边连接两个社团,那么这两个社团节点之间的最短路径通过该边的次数就会最多,相应的边介数最大.如果删除该边,那么两个社团就会分割开.GN算法就是基于此思想反复计算当前网络的最短路径,计算每条边的边介数,删除边介数最大的边.最后在一定条件下,算法停止,即可得到网络的社团结构,网络中社区稳定度用模块化度量值Q衡量[13].
我们将源文件视为节点,它们之间的依赖关系,同时修改关系作为两源文件的边,软件系统可以视为复杂网络,这里用依赖网络和同时修改网络来命名根据两种关系形成的复杂网络.将依赖关系数据和同时修改数据作为GN算法的输入,对两种网络进行划分.得到的是根据两种关系得到的两种网络社区划分结果.
D:实验结果分析
为了帮助分析依赖关系网络和同时修改关系网络,我们定义了两个概念:关系簇和奇异点.
1.关系簇(relation cluster)定义为:
在同一个软件系统中,一部分源文件无论在依赖关系网络中还是同时修改关系网络中都被分进同一个社区,这部分源文件被称为一个关系簇.
2.奇异点(strange node)定义为:
在依赖关系网络中或者是同时修改关系网络中,如果存在某个文件不属于当前社区中任何一个关系簇,则称这个文件为奇异点.
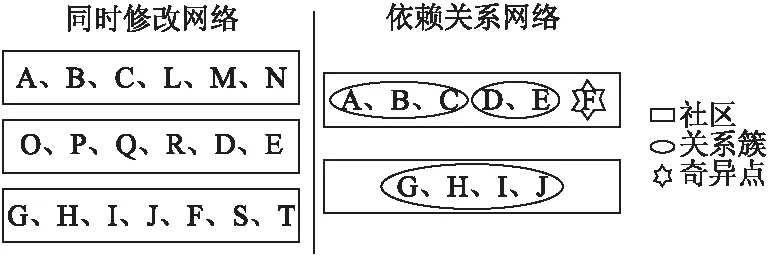
图3 关系簇和奇异点概念图Fig.3 Concept graphs of relation clusters and strange points
图3中,A、B、C三个点在两个网络中都被分在一个社区中,因此,它们组成一个关系簇,而F不属于依赖关系网络社区1中任何一个关系簇,所以F为奇异点.我们对每个社区计算它的总节点数,关系簇数和奇异点数.如果存在奇异点,它对应的源文件可能指示质量问题,我们将对奇异点出现的原因做仔细的探究.
3 实验结果
软件项目数目庞大,质量参差不齐.为了更好的研究源文件依赖关系及其同时修改关系的一致性,我们选取了评价较好,关注度高的项目Tomcat_9_0_0_M21(https://codeload.github.com/apache/tomcat/zip/TOMCAT_9_0_0_M21),截取2006年3月27日至2017年5月5日的提交信息进行研究.为了寻找项目的源文件中两种关系不一致情况下可能存在的问题,我们选取了Tomcat(https://github.com/apache/tomcat)早期版本,即2013年7月2日之前的版本,和评价次数较少,关注度较低的Restunit(https://github.com/davetron5000/restunit)项目,更新截止时间为2008年12月21日.
每一个项目供实验使用的数据首先包括项目文件名称与编号对应表,其次,根据两文件之间的依赖关系和实际关联,分别得到的依赖关系表和实际关联表,格式均为“文件编号1,文件编号2,强度”,最后是根据两种关系的划分结果数据,每一行为一个社区,社区以文件编号组成.具体数据我们提交至github(https://github.com/huxuefei/hu.git)上.
3.1 软件项目中源文件的依赖关系和其实际关联存在一致性(RQ1)
表1是tomcat根据同时修改划分的实验结果.其中,有一部分社区有相同的总节点数,关系簇数,奇异点数,因此我们把这些社区表示在同一行.例如,表1第一列的17-21表示社区编号在17至21之间的所有社区.对于项目Tomcat的实验结果,我们从表1可以看出,根据同时修改划分的每一社区中的源文件之间大部分是有依赖的,这在一方面证明了我们的猜想,大量同时修改的源文件往往是有依赖关系的.
比如划分块4,其中源文件在根据同时修改关系的划分和根据依赖关系的划分上都被划分在一个社区,这是由于有依赖的源文件一旦其中一个做出修改,调用此源文件和被此源文件调用的源文件就有很大可能需要做出修改.
我们发现实验结果中存在奇异点,它们表示源文件被大量提交而它们之间不存在依赖关系,这似乎与我们的假设有出入,仔细探究其出现原因,我们发现奇异点跟关系簇中的某些结点有很少的引用数目,但是在根据依赖关系的划分中并没有归为一个社区,从而成了奇异点.所以,单纯以引用和调用的数量来判定两源文件的依赖关系大小并不全面,但是只是在少量的源文件点中出现差错,经过排查,我们的猜想是成立的.
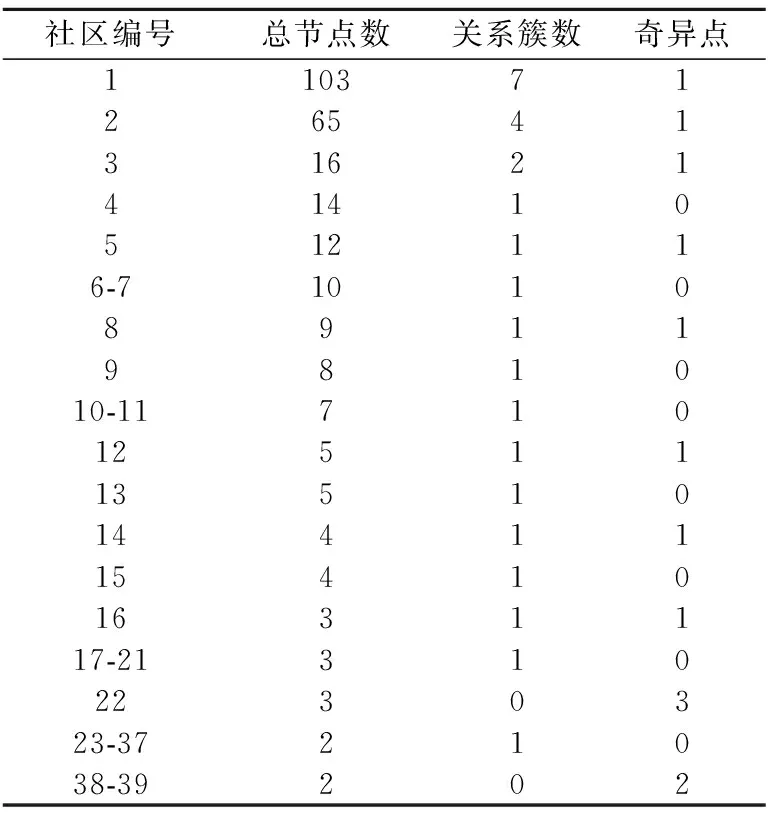
表1 Tomcat根据同时修改划分Table 1 Tomcat partition according to co-change
表2描述了tomcat根据依赖关系划分的情况,我们可以看出根据依赖关系被划分到一个社区中的源文件在同时修改关系划分中也很可能被分到同一个社区,说明具有较强依赖性的源文件在实际开发中更容易被同时修改.这在另一方面证明了我们的猜想,具有依赖关系的源文件往往会被同时修改.

表2 Tomcat根据依赖关系划分Table 2 Tomcat partition according to dependencies
同样,根据依赖关系划分的社区中也存在奇异点,它们表示源文件有较强的依赖关系而它们没有被大量提交.我们分析发现其存在也是合理的.有些源文件与其他源文件有很强的依赖关系,但其本身修改的次数就非常少,在删除同时修改次数小于3的数据的处理中,这些数据被删除,从而产生了奇异点.但这与我们的猜想并不违背.
综上,虽然两种划分中都存在奇异点,但数量很小,并且其存在有合理的解释,所以说Tomcat项目的源文件依赖和其同时修改关系有较好的一致性,在评价高,优秀的Tomcat项目中,我们的猜想得到了证实.
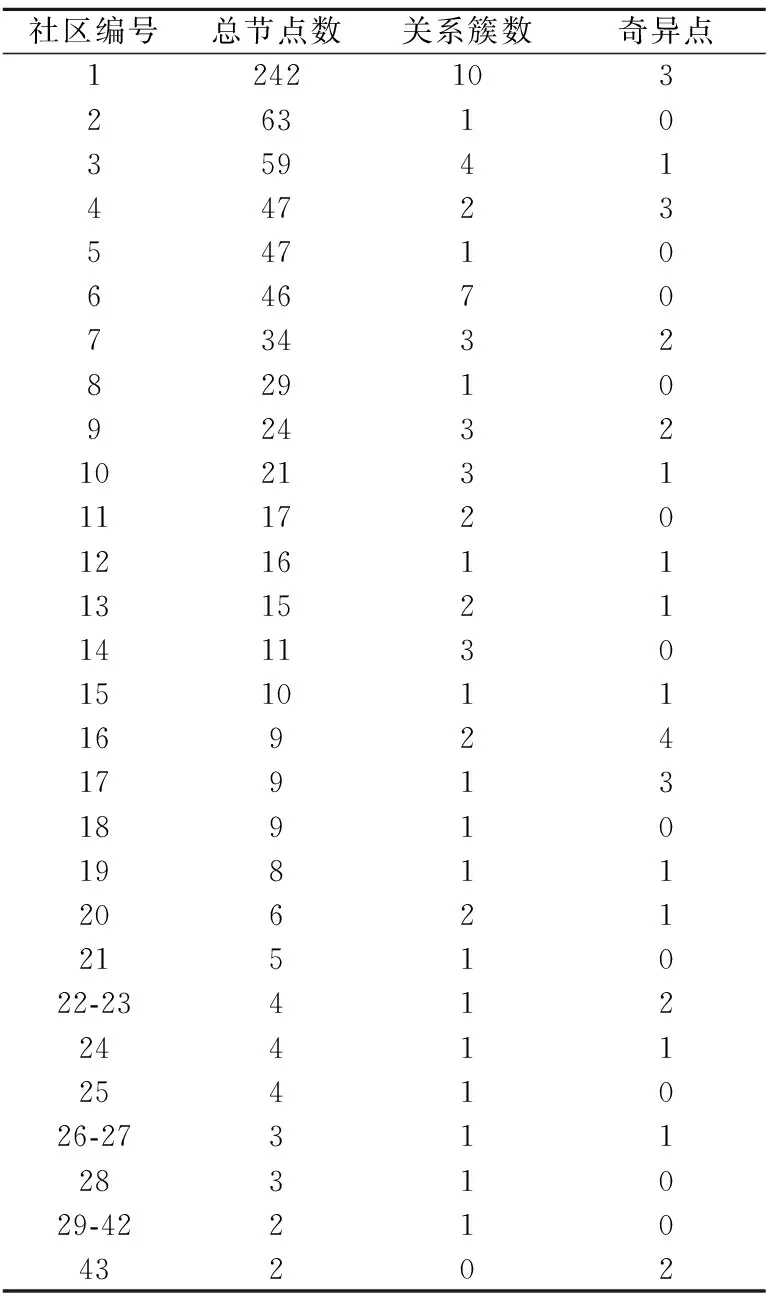
表3 Tomcat根据同时修改关系划分Table 3 Earlier versions of Tomcat partition according to co-change
3.2 出现依赖关系和实际关联不一致现象的项目可能存在的问题(RQ2)
对于评价高,星数多的优秀项目Tomcat的研究中,我们的猜想得到了证实.而对于与我们猜想不相符的项目,它们中是否存在一定的问题.为了探究出现依赖关系和同时修改关系不一致现象的项目可能存在哪些问题,我们选取了Tomcat和评价较低,关注度较低的项目Restunit(2008年12月21号之前)进行分析.
我们选择Tomcat(2013年7月2号之前)的数据是因为在此之后的一次提交中,项目进行了大量文件的增加与删除,开发者可能对项目的结构做出了调整,修复了很多问题,这将不利于我们发现问题,所以将此时间节点之前的数据进行分析更可能找出潜在质量问题.Tomcat根据同时修改关系划分的结果见表3.
我们发现,社区17中的奇异点源文件el/ImplicitObjectELResolver.java和同一社区中的所有源文件没有任何依赖,但是却大量与它们一起提交.经过分析,此源文件与同一社区中的el/BeanELResolver.java代码十分相似,大部分是重复的.这种情况不止一处,社区43中,文件authenticator/TesterDigestAuthenticatorPerformance.java和同一社区中另一文件authenticator/TestDigestAuthenticator.java之间没有依赖却同时提交,经过两文件对比分析,发现存在部分代码重复的现象.而在社区26中,我们发现三个文件valves/RemoteIpValve,filters/RemoteIpFilter 和 filters/ExpiresFilter的部分代码均是按照同一模板而写,社区22中的四个文件startup/WebRuleSet,startup/NamingRuleSet,starup/SetNextNamingRule,startup/ConnectorCreateRule也是同一个模板.可见,通过此方法分析奇异点可以发现软件中可能存在问题的地方.
对于Restunit,我们也计算了每个社区的总节点数,关系簇和奇异点,实验结果见表4.
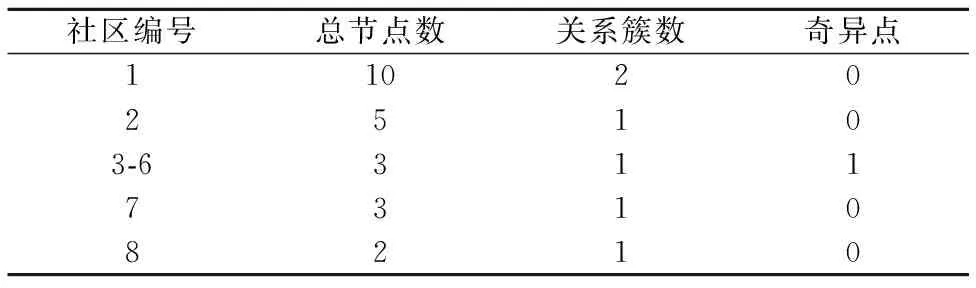
表4 Restunit根据同时修改关系划分Table 4 Restunit partition according to co-change
对奇异点进行分析我们发现影响项目质量的问题,我们将现象以图的形式展示,并做分析.图4展现了文件之间的依赖关系和它们在社区划分中的情况.记奇异点源文件restunit/SSLRequirement.java为S,记同一社区中的其他两个源文件restunit/RestTest.java为A,restunit/RestTestResult.java为B.我们发现S与A和B没有任何的依赖关系,但是存在源文件P,即restunit/RestCall.java,引用了S,而A和B都直接或者是间接的引用了P,B引用了源文件Q,即restunit/RestCallResult.java,而Q源文件引用了源文件P.有趣的是P源文件没有和任何的源文件一起提交过,反而是S频繁与A和B源文件一起提交.
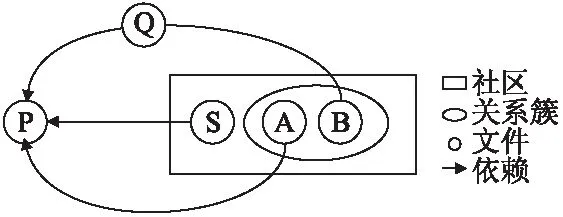
图4 质量问题1说明图Fig.4 Description of quality issue 1
如果两个文件之间有很强的关系,即在提交中大量被同时修改,但它们之间不是直接引用或者调用的话,在出现bug或者维护时需要修改文件时会十分不方便.例如程序员在做出修改时很可能不会发现另一个文件也要做出修改,因为它们之间没有直接调用.所以出现这种现象会降低软件的可维护性,也反映出设计上的失误.
类似的,我们还发现另一种情况,并将文件之间的依赖关系和它们在社区划分中的情况展示见图5.记奇异点源文件restunit/TestRestUnit.java为S,记同一社区中的其他两个源文件restunit/TestAssertions.java为A,http/RESTTreeHttp.java为B.我们发现S与A和B没有任何依赖关系,但是存在源文件P,即restunit/RestCallResponse.java,S、A、B源文件都引用了P源文件.P源文件几乎没有被修改过,而S、A、B却大量同时被修改.这种情况下,P被视为不活跃的点而在两种划分中都被去掉,一定意义上影响了根据依赖关系的划分中,S与A和B划分到同一社区.这种现象的产生可能是因为使用者对P中类错误的引用,这也加大了项目风险.
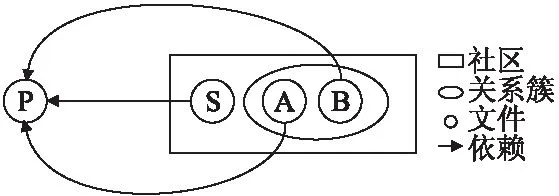
图5 质量问题2说明图Fig.5 Description of quality issue 2
综上,我们可以说出现依赖关系和同时修改关系不一致现象的项目可能存在问题.最典型的问题是代码的复制粘贴现象,这种单纯的复制粘贴降低了代码的重用性,进而降低了软件的可维护性,是影响软件项目质量的重要原因.而实验结果中提到的另外两种引用造成的不一致,从项目本身出发,其中也存在一些设计上的不合理.所以我们可以从项目中源文件的依赖关系和其同时修改关系是否具有一致性来发现软件项目中存在的问题.
4 讨 论
实验运用复杂网络研究中的社团检测方法对软件工程中项目源文件依赖关系与同时修改关系的一致性进行了探究.实验结果符合已知的规律,从中我们发现两种关系不一致的软件项目中可能存在问题,经过仔细对代码分析,找出了其中的原因,最典型的有代码的复制粘贴和混乱的引用关系.
实验方法上具有一定的局限性.对于依赖关系大小的衡量上,我们单纯的用源文件之间引用调用的数量来判断,从实验结果来看,这是不全面的,有些源文件引用调用数量很少,但是这少量的依赖却是非常的重要,以至于它们大量同时被修改,即同时修改关系十分的紧密.对于根据同时修改关系对源文件进行划分中,为了排除干扰,缩小数据规模,对数据做出一定的删减,这种删减是合理而有效的,但是这种处理也不可避免的在实验结果上造成了小部分的错误,比如有些源文件与其他源文件有很强的依赖关系,但其本身修改的次数就非常少,在数据缩减中我们忽略了它与其他源文件的联系,从结果上看就无法证明具有依赖关系的源文件更容易被同时修改的观点.但在我们实验中由于这种原因造成的奇异点数量占总结点数量不足3%,所以不影响整体的判断.
实验项目的选择上,我们倾向于选择中小型规模的项目,对于较大规模的项目因为条件所限没有进行尝试,有一定的局限性.
5 结 论
我们对项目中源文件的依赖关系与其在提交信息中同时修改关系的一致性进行了分析,得出以下结论:
在质量较高的软件项目中,源文件的依赖关系与同时修改关系有非常强的一致性.有依赖的源文件更容易被同时修改,同时大量修改的源文件之间往往存在依赖.
如果存在没有依赖关系而被同时大量提交的源文件,软件项目中很可能存在一定的问题,比如代码的复制粘贴现象,或者混乱的引用情况.
未来的研究中,我们可以尝试更多不同规模的项目,看是否与我们的猜想相符.在项目中源文件的依赖关系和其同时修改关系具有一致性的前提下,我们可以探究更多造成不一致的原因,分析它们是否降低了软件项目的质量.进而,我们可以用这种方法侦测软件项目架构上的问题.为了分析实验结果,我们提出了关系簇的概念,显然关系簇数目越小,两种关系更具有一致性,这种简单指标一定程度上可以用作软件项目质量的评定,但还需要更多的实验来证明.
猜你喜欢
辽宁教育(2022年19期)2022-11-18
汽车实用技术(2022年9期)2022-05-20
英语文摘(2021年10期)2021-11-22
幼儿园(2021年6期)2021-07-28
疯狂英语·新悦读(2021年1期)2021-01-27
当代陕西(2019年16期)2019-09-25
摄影之友(影像视觉)(2019年3期)2019-03-30
大众摄影(2017年2期)2017-01-20
大众摄影(2016年4期)2016-05-25
燕山大学学报(2015年4期)2015-12-25
