
一种面向移动应用开发的第三方库混合推荐方法
2019-09-09 03:38赵玉琦熊燚铭
小型微型计算机系统 2019年9期
任 其,李 兵,2,王 健,赵玉琦,熊燚铭
1(武汉大学 计算机学院,武汉 430072)2(武汉大学 复杂网络研究中心,武汉 430072) E-mail:renqilvsx@163.com
1 引 言
移动应用正在日益改变着人们的日常,据统计,截至2018年11月初,App Store上拥有的移动应用数量已经超过250万个,下载量超过100万次的app数量多达32788(1)http://www.appbrain.com/stats/ free-and-paid-android-applications,2018.日益增长的用户群为移动应用的开发提出了更高的要求,快速敏捷的开发出高质量移动应用以适应日益增长的用户需求变得尤为重要.
在移动应用推荐方面,当前大多数研究工作都是从用户的角度出发,即为用户推荐合适的移动应用.在面对日益增长的移动应用时,研究者们关注的是如何将这大量的移动应用推荐给用户以满足他们的个性化需求.随之产生了大量基于海量移动应用数据的推荐算法.例如文献[1]提出了一种将兴趣-功能交互和用户结合起来进行移动应用推荐的方法,该方法在推荐过程中考虑到了用户的隐私偏好.文献[4]则通过现代资产组合理论(MPT)将移动应用的流行度,个人偏好和移动设备约束结合起来用于移动应用推荐.然而,这些方法都是从移动应用使用者的角度出发,没有考虑到开发者的需求.因此,难以实现辅助开发者进行应用开发的目标.
第三方库在移动应用开发中扮演着越来越重要的角色.首先,第三方库是用于移动应用开发的一种可重用资源,开发人员可以通过重用第三方库来实现自己需要的功能,从而可以有效的帮助开发者减低开发时间与开发成本.其次,第三方库可用来帮助完成特定的商业目标.例如,可以在应用中使用广告库完成广告的推广或者使用社交库完成用户社交的功能.根据在Google Play上的移动应用研究表明,使用最多的第三方库是Google ads,也就是广告库,其中使用广告库的移动应用超过了60%[2,3].这就更加证明第三方库在移动应用中的重要性.然而,可用的第三方库数量繁多且功能各异,这为开发者选择合适的第三方库提出了新的挑战.为此,我们构造了一个新的数据集,该数据集包含移动应用及其描述,第三方库及其描述以及移动应用与第三方库之间的调用关系.基于这些数据,我们可以完成移动应用第三方库的推荐任务.用于推荐任务的方法有很多,包括传统的基于历史信息的协同过滤算法以及基于模型的矩阵分解,这些方法在很早就被研究者证明可以在Movielens、Netflix等电影推荐中有不错的表现,研究者们进一步将不同的推荐方法进行混合以提高推荐的精度.基于构造的数据集,我们提出了一种将基于历史调用数据的推荐结果与基于描述文本的推荐结果进行贝叶斯融合的推荐方法.该方法一方面基于历史调用数据使用了基于用户的协同过滤(UBCF)方法,另一方面基于文本信息使用了TF-IDF方法.从两个不同的角度来为开发者推荐适合的第三方库.
本文的贡献包括以下两点:
1.构造了一个全新的数据集,即移动应用(app)与第三方库的数据集;
2.提出了一种混合推荐技术用于第三方库的推荐,在构造的数据集上开展实验进行验证,表明了本文所提方法的有效性.
2 相关工作
在传统的服务计算领域,软件开发者通过重用服务,能够创造出更多的服务组合来满足更多更复杂的需求并实现商业价值[5].很多研究者提出了很先进的推荐方法对服务进行推荐来实现服务组合的目标.本文所研究的问题与此相似,在移动应用的开发过程中,第三方库扮演着越来越重要的角色,第三方库的重用可以满足更多的需求.目前,已经开展了大量工作进行第三方库的相关研究,例如Pearce P等人[6]研究了Android应用程序当中的广告库,发现了有49%的应用程序中至少包含一个广告库.Shekhar S等人[7]同样研究的是Android第三方库当中的广告库,其中说明了一些恶意应用会模拟广告库的行为.有研究人员[8,9]从代码层面来识别第三方库,做法是使用机器学习来提取特征,但同样的只能识别出广告库.之后有研究人员[10]使用了基于语义的特征聚类方法,但是这样的方法同样不太准确.这些工作主要与发现和检测第三方库有关,就我们的调研所知,在第三方库的推荐方面尚没有相关研究.
在文献[11]中,研究者提出了一种第三方库自动检测和分类的方法,可以快速精准的检测出Android 移动应用当中的第三方库.该方法基于多级聚类技术进行识别第三方库,然后通过机器学习方法对第三方库的功能进行分类.该方法用于第三方库推荐时存在的一个局限是第三方库在使用时可能会被开发者修改,这将导致聚类之后得到的第三方库可能不全,并且检测到的第三方库不是完全准确,难以支撑我们进行第三方库推荐的任务.
3 问题分析
针对第三方库推荐中面临的第三方库的检测与筛选问题,我们构造了相应的数据集.具体构造过程如下:首先,从Google Play上面提供的百万移动应用中爬取10000多个移动应用安装包,然后使用了工具ClassyShark(2)https: / /github. com/google /android-classyshark对它们进行分析.ClassyShark是Google提供的用于对apk进行反编译的一个工具,可以方便我们快速且轻巧的轻量级浏览Android apk.通过使用该工具,我们能够得到每个apk反编译之后的一系列包名.然后我们设定了一个阈值,表示为包名出现在不同apk的次数.这是为了区分出第三方库与开发者自己写的代码库,我们认为大于这个阈值即为第三方库.而对于出现的代码混淆问题,通常开发者混淆的包名和函数名都是自己为了防止被恶意篡改而对自己代码所做的一种保护措施,所以我们在筛选第三方库的过程中会自动忽略掉混淆的包名.使用这种方法得到的第三方库做实验时,我们发现一个问题,那就是阈值的选择问题,我们难以选择出最适合的阈值来最准确的筛选出第三方库.最终,我们选择了工具AppBrain(3)https: / /www. appbrain. com/stats,该工具将第三方库分为三大类:广告类、社交网络类和开发工具类,该工具上提供的app是基于Google Play,并且AppBrain上每个第三方库都有其所对应的标签及相关描述.
我们假设某一个移动应用开发者需要开发一个描述为“适用于Android手机的视频app,该app提供最热门的音乐视频和游戏,娱乐,新闻等视频,您可以订阅您喜爱的频道并与朋友分享”的移动app.对此,开发人员一开始分析功能需求确定要使用到AdMob库,AdMob是全球最大的移动广告网络之一,为移动网络上的发现,品牌推广和货币化提供解决方案.之后我们的推荐系统会产生一个用于视频移动应用开发的第三方库的候选列表Android support_lib,firebase,gcm,google_gson,android_arch,facebook,retrofit,zxing,butterknife,jsoup,protobuf.并基于这些候选列表项开发人员推荐可能要使用的第三方库以提高开发效率和质量.
针对以上的场景,我们可以将问题描述为:对于appi,i的描述文本与一些确定要使用的第三方库是已知信息.我们首先将已经要使用的第三方库作为对i的隐式反馈,基于这些隐式数据我们可以计算出与i相似的app并将这些app调用的第三方库作为候选集Ru.此外,通过i的描述文本挖掘出与其他app的语义相似度并生成候选集Rc.最后,通过贝叶斯定理将候选集Ru和Rc融合得到最终的推荐列表.
更一般地,我们将不同的app扩展为一个很大的app集合M,将M中使用到的第三方库扩展为三方库集合L.这样,我们就构建了一个M与L的隐式反馈矩阵并基于这个矩阵以及M集合中app的描述文本完成推荐目标.
4 TF-IDF与UBCF的混合推荐方法
4.1 方法概述
如图1所示,本文提出了一种结合app和第三方库交互信息和文本描述信息的方法.本方法主要是由两部分组成,基于协同过滤推荐模块和基于内容的推荐模块.
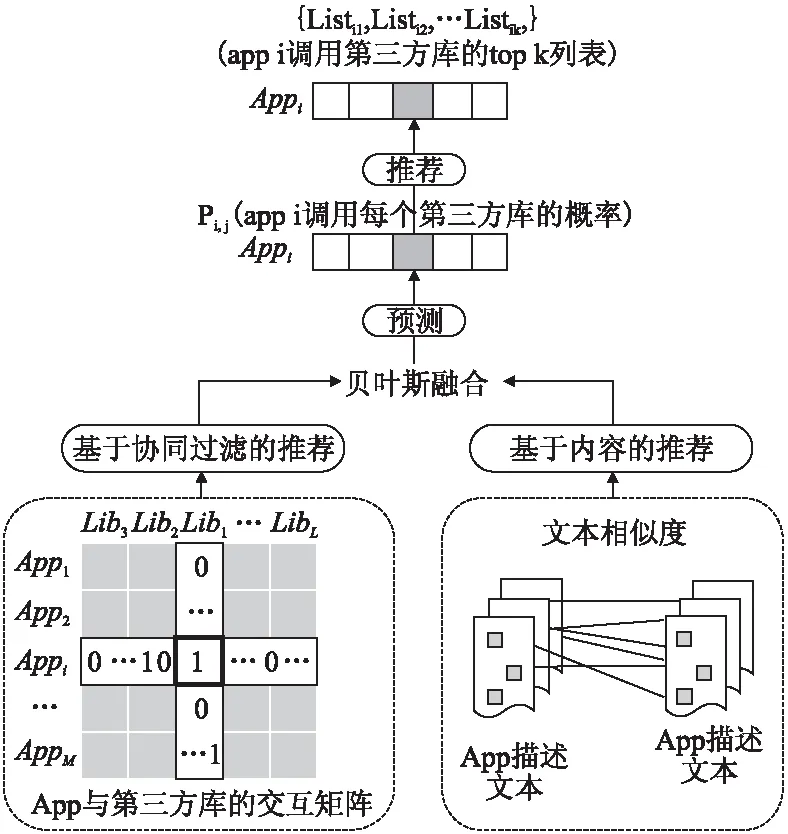
图1 App第三方库的混合推荐方法框架Fig.1 Framework of hybrid recommendation method for App third-party libraries
协同过滤的模块主要的作用是构建一个app和第三方库的调用关系矩阵,从这个矩阵中我们可以挖掘出他们两者的关系.基于内容的推荐模块主要是利用app的需求描述和第三方库的描述信息来完成,本文中我们使用了TF-IDF来计算文本相似度.首先将描述信息转化为文本特征向量,然后得到他们之间的语义关系,基于语义关系计算出app之间的相似度,然后利用相似度生成第三方库的推荐列表.最后将协同过滤的推荐结果和基于文本的推荐结果通过使用贝叶斯定理进行整合,整合之后得到最终的推荐结果.
4.2 UBCF部分
协同过滤算法是最早用于推荐系统中,也是最为经典和著名的推荐算法.该算法主要通过历史使用数据来发现目标用户的偏好,这些历史使用数据可以是显式的反馈数据,也可以是隐式反馈数据.在服务计算领域,QoS的预测是很多研究者所关心的问题,大多数基于QoS的方法是预测和排序服务质量(QoS)以推荐最佳服务[12-15]. 他们遵循经典推荐系统的思想,其中协同过滤(CF)被广泛使用来进行QoS预测.郑子彬等人在文献[16]中就QoS预测问题提出了一种协同过滤方法并取得较好的结果.本文中使用的是隐式反馈数据,即数据是二值的,0表示没有交互,1则表示有.同时,传统的协同过滤算法分为基于用户与基于物品这两种.顾名思义,前一种表示挖掘用户之间的相似性,基本思想是根据具有相似偏好的用户来为用户推荐可能喜好的物品;后一种表示寻找相似的物品,来直接为目标用户做推荐.无论是基于用户的推荐还是基于物品的推荐,都需要计算相似度,通常可以使用余弦相似度或者皮尔逊相关系数等相似度计算方法.本文中我们使用了余弦相似度来完成这个任务.本文中使用到的协同过滤图模型如图2所示.
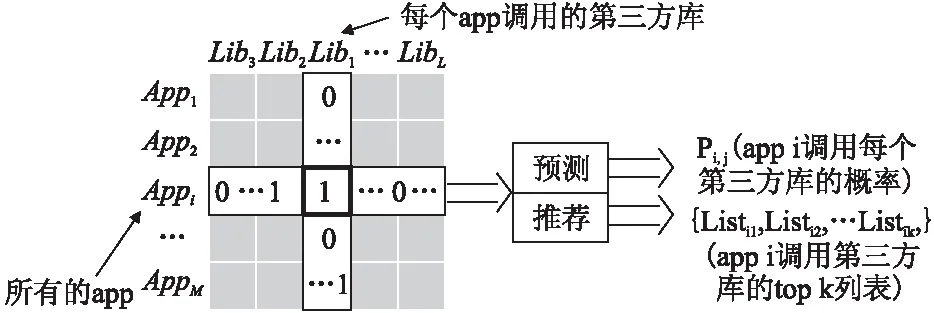
图2 协同过滤图模型Fig.2 Collaborative filtering model
如图2所示,在协同过滤中,每行表示一个app,每列表示一个三方库,矩阵中的1表示该app调用了该三方库,0表示没有.而图的右边则是对于三方库的推荐过程.从左边到右边是通过相似度的计算进行的,如下所示.
(1)
Sim(i,j)表示appi和appj之间的相似度值.得到app之间的相似度矩阵之后,我们可以计算appi对第三方库lib的相似度:
(2)
其中,Si,j表示appi和appj之间的相似度,Ij,lib表示appj是否与第三方库lib有交互,1表示是,0表示否,N则表示与appi相似的所有app集合.
4.3 TF-IDF部分
TF-IDF是一种统计方法,通常用于评估某一个词对于某个文档集合或者文档集合中某一篇文档的重要程度.TF-IDF分为TF和IDF两部分.TF是词频的意思,是指某个给定单词在指定文档中的频率,通常会将这个值归一化;IDF表示逆向文件频率,用来度量一个单词的普遍重要性的程度.IDF的值越高,说明这个单词在整个文档集合中的重要性越低.由此,TF-IDF的思想可以表示为:当某一个单词在给定的一篇文档中的TF很高,IDF值也很高的时候,就认为这个单词具有很好的区分能力,因此就保留下来这个单词.
对于移动应用市场中的app,几乎每个都有其对应的文本描述,同样的,给定一个将要开发的app的文本描述,在本文中,我们基于这些文本描述使用TF-IDF和向量空间模型来计算app之间的相似度.首先我们计算出每个app描述文本当中每个单词的TF-IDF值,在计算完单词的TF-IDF值之后,我们进行关键词的筛选,即保留重要的单词,去掉非必要的单词.然后我们使用向量空间模型将文本中的单词向量化.具体的步骤如下:
1)通过使用TF-IDF算法,将两个app各自的描述文本进行关键词筛选,即去掉那些非重要性单词
2)取出每个文本的若干个单词组成单词集合,然后计算每个app描述对该单词集合中单词的TF-IDF值
3)生成两个app描述的单词向量
4)通过计算出这两个app单词向量的余弦相似度
TF-IDF的方法描述如下:
(3)
(4)
其中,TF(tk,dj)是第k个词在第j个文章中出现的次数,nk是包含第k个词的文章数量.最后,第k个词在第j个文章中权重如下:
(5)
这里做归一化的目的是将不同文档中的向量表示归一到同一量级上.
得到每个描述文本中每个单词的TF-IDF值之后,按照大小排序取前若干个单词组成单词向量.从而两个app之间的文本相似度可以表示为:
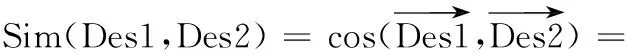
(6)
其中,Des1和Des2分别app1和app2的描述,Wi1和Wi2分别表示第i个单词在app1和app2中的权重,M表示app总数.
4.4 贝叶斯融合
通过历史调用数据,我们计算出了app与第三方库的余弦相似度,相似度的值落在0到1的范围内.我们可以将其解释为在一个app中使用到第三方库的概率,即P(libu|app).另一方面,通过app的描述文档,我们使用TF-IDF计算app之间的相似度并且利用app的相似度得到app使用第三方库的概率,概率表示为P(libc|app).因此,我们假设条件独立,就可以通过贝叶斯定理将这两个概率进行整合.整合之后,对于给定的app及其描述,我们可以将其表示为:P(lib|app)=P(libu|app)*P(libc|app).我们将问题转化为对于第三方库来说,它被新的app调用的可能性是多少,这可由后验概率P(app|lib)给出.通过使用贝叶斯定理,可以得到:
P(app|lib)∝P(libu,libc|app)*P(app)=
P(libu|app)*P(libc|app)
(7)
其中,P(app)是我们看到app的先验概率,大小为1/M,M是app的总数.这样,我们可以选出具有最大P(app|lib)的第三方库.
5 实 验
在本节中,我们将介绍为评估提出的第三方库推荐方法性能所进行的实验研究和不同方法之间的对比实验,我们的实验是基于之前所构造的现实世界的数据集.
5.1 实验设置
我们所有的实验部分都是在具有Intel(R) Xeon(R) CPU E5-1620 v3 @ 3.50GHz的处理器和64.0GB内存的Windows操作系统上进行的.
5.2 数据集
本次实验的全部数据来自于AppBrain,这也是AppBrain上的数据首次被使用于该实验目的.因此,我们选择的一些现有方法都不曾用于该数据集,这些方法会产生什么样的效果也让我们有所期待.AppBrain上包含很多的app及其调用的第三方库,由于考虑数据量的大小以及矩阵的稀疏程度,我们选择了其中的5274个app,一共包括了470个第三方库.同时我们也获取了app以及第三方库的相关描述.表1显示了数据集中一个app的信息.表2显示了该数据集的相关信息.

表1 App Gesture Call的信息Table 1 Information of App Gesture Call
数据预处理:对于文本数据,我们得到的原始文本数据包含了app的名字、类别、开发者以及描述等信息.第一步,我们选择了描述信息.然后我们对描述信息进行了分词,去掉停用词和非法字符等.剩下的词最能用来代表描述app的功能.对于历史调用数据,正如前面所提到的,我们在这方面做了很多的工作,包括自己爬取数据并设计方法去筛选第三方库.最终,我们选择使用AppBrain上的数据并且就此构造数据集.之后,针对数据集我们构造了app与第三方库的调用矩阵,该矩阵是一个0/1矩阵,其中行表示app,列表示第三方库.

表2 数据集的状态Table 2 Statistics of dataset
训练集与测试集:为了评估推荐性能,我们基于自己的数据集为每个实验构建了一个训练集和一个测试集.首先,我们随机选择70%的app作为实验的训练集,剩下的部分则作为测试集.测试集当中的app所包含的一部分第三方库用于预测,另外一部分则用于训练.每个实验进行10次实验,并将它们的平均值作为最终的结果.
5.3 评价指标
在实验中,我们采用了两种评价指标用来评估对Android app进行第三方库推荐时的性能.分别是MAP以及NDCG.
MAP是指平均均值精度,它是信息检索领域当中常见的评价指标.当测试集中app的数量为Atest时,推荐K个第三方库的MAP值定义如下:
(8)
其中,Atest表示测试集app的数量,la表示appa所调用的第三方库的数量,Ki表示出现在推荐列表中的a的第三方库的数量,I(i)表示推荐列表中位置i的第三方库是否被a所调用.
当测试集中app的数量为时Atest,推荐K个第三方库的NDCG值定义如下:
(9)
其中,IDCG表示IdealDCG,是指推荐列表中的最佳排列所对应的分数.
5.4 比较方法
我们选择了几种常见的比较先进的算法作为对比.其中包括基于文本的推荐和基于历史调用数据的推荐等.
基于用户的协同过滤(UBCF):基于用户的协同过滤算法是一种广泛应用于推荐系统的经典算法.
基于物品的协同过滤(IBCF):基于物品的协同过滤算法同样是一种广泛应用于推荐系统的经典算法,所不同的是计算物品之间的相似度.
基于主题模型LDA的推荐算法(LDA):基于文本主题模型的推荐算法,通过使用LDA计算出每两个app描述文本的主题相似度,基于这些相似度生成第三方库的推荐列表.
基于用户的协同过滤与主题模型LDA的混合推荐算法(LDA+UBCF):同上,我们通过将主题模型LDA与UBCF进行整合得到混合推荐结果.


图3 NDCG@KFig.3 NDCG@K图4 MAP@KFig.4 MAP@K
图3和图4展示了我们所提出的混合推荐方法即TF-IDF+UBCF与其他的方法在NDCG@K,MAP@K这两个指标上的对比.UBCF基本上在这两项指标上都是差于其他的方法.同时,对比基于历史调用方法和基于内容的方法,我们可以得出基于文本描述的方法即LDA要表现的比基于用户的协同过滤更加优异,但却要比IBCF在两种指标上略差,其原因是我们在做第三方库的推荐时,并没有考虑到三方库在移动应用中的优先级,所以使用UBCF时可能会忽略掉优先级较高的第三方库.而IBCF则是直接通过第三方库之间的相似度关系进行推荐,因此,使用IBCF的效果要优于UBCF.此外,无论是基于历史调用数据的方法还是基于内容的方法在两种指标上都比混合方法效果差.同时我们的贝叶斯混合推荐方法也在所有方法中脱颖而出.几种指标的部分详细数值如下表所示.
表3-表4显示了各项指标的具体数值.表中加粗的数据是给定K的最好结果,†表示在0.01水平上与最佳结果的差异性具有统计显著性.从以上表格中看出,我们的混合推荐方法基本在所有指标中都是最好的结果,并且在后两个指标上与其他方法几乎都具有统计显著性的差异.更具体点,在NDCG这个指标上,当K为40时,TF-IDF+UBCF比UBCF高8.86%,比LDA+UBCF高2.76%;在MAP上,当K为40时,TF-IDF+UBCF比UBCF高7.35%,比LDA+UBCF高3.33%.
我们发现,在利用贝叶斯混合推荐方法进行基于内容的推荐时,挖掘到的相似移动应用的数量N对最终的推荐结果有着一定的影响,当设置的相似app数量较少时,会导致推荐结果不够完整,而当我们将N设置较大时则会产生一些相关性不大的推荐结果.所以,设置适当的N的大小对我们的工作来说是有必要的.为了研究N的大小对推荐结果的影响,我们将N的范围设置为20到120,步长为20.如图5和图6所示,当N从20增加到60 时,NDCG和MAP值都相应增加.
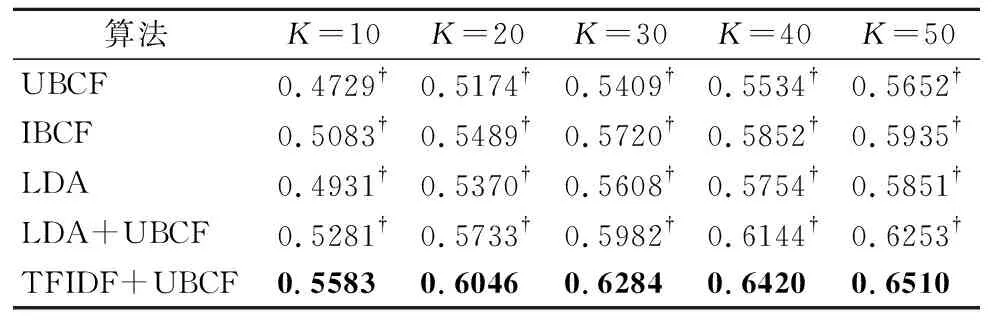
表3 5种方法的详细NDCG值Table 3 Detailed NDCG values for the five methods
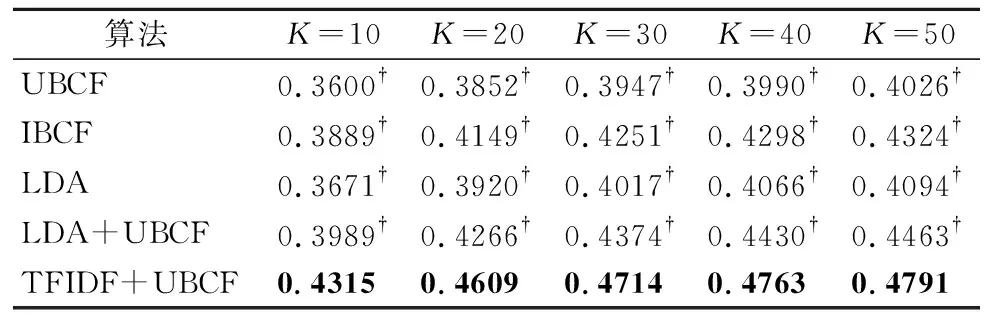
表4 5种方法的详细MAP值Table 4 Detailed MAP values for the five methods
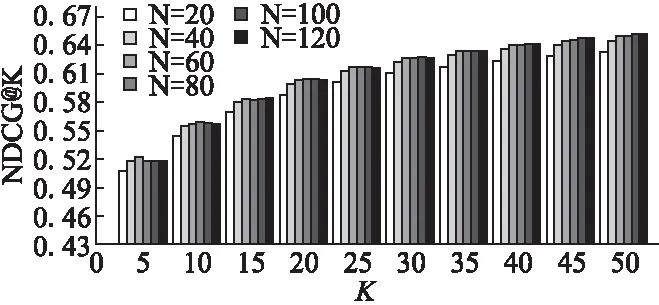
图5 NDCG@KFig.5 NDCG@K

图6 MAP@KFig.6 MAP@K
但是当N从60增加到120时,两种度量指标都几乎没什么变化或者说在某个值附近浮动,这是因为排名越靠后的移动应用有着越小的影响因子,当这个排名值达到某个临界点时,后面的推荐结果几乎不影响整体的推荐性能.由此可以得出,在我们的贝叶斯混合推荐系统中,当推荐的移动应用数量N不大于60时,推荐性能会随着N的增加而增强;然而当N继续增加时,推荐系统基本趋于稳定.
6 结论与未来工作
本文针对为移动应用推荐三方库这一应用场景,构建了相应的数据集.并在此基础上提出了一种新的混合推荐方法,即使用贝叶斯理论集成了历史调用和文本内容信息.所提模型中集成的文本内容可以在一定程度上缓解推荐系统中经典的冷启动问题.在真实数据集上开展的实验,表明了本文所提方法的有效性.
下一步,我们将在推荐模型中进一步利用数据集中的app以及第三方库的标签与类别等信息,并将这些信息与当前隐反馈数据加以整合,另外,将使用神经网络进一步挖掘app与第三方库的潜在关系.
猜你喜欢
北京航空航天大学学报(2022年6期)2022-07-02
新班主任(2022年4期)2022-04-27
商品与质量(2019年34期)2019-11-29
汽车观察(2019年2期)2019-03-15
计算机系统应用(2019年3期)2019-03-11
民生周刊(2017年19期)2017-10-25
经济(2016年29期)2016-12-27
CHIP新电脑(2016年3期)2016-03-10
中国信息化·学术版(2013年1期)2013-05-28
智能计算机与应用(2007年4期)2007-08-25
