
人工智能在骨质疏松症中的应用研究综述
2019-09-09 03:38尹梓名孙大运胡晓晖孔祥勇黄正行
小型微型计算机系统 2019年9期
尹梓名,孙大运,胡晓晖,孔祥勇,黄正行
1(上海理工大学 医疗器械与食品学院,上海 200093)2(上海市浦东新区浦南医院 脊柱外科,上海 200125)3(浙江大学 生物医学工程与仪器科学学院,杭州 310007) E-mail:weisskopf@hotmail.com
1 引 言
在世界卫生组织(World Health Organization,WHO)的定义中,骨质疏松症是一种以骨量减少、骨组织微结构破坏、骨骼脆性增加和易发生骨折的全身性疾病[1,2].考虑到骨质疏松性骨折和骨强度密切相关,美国国立卫生研究院(National Institutes of Health,NIH)将骨质疏松定义为一种以骨强度降低致使肌体患骨折危险性增加为特征的疾病[3].其表现为骨密度降低和骨蛋白浓度的变化.骨质疏松症会影响全身骨骼,导致骨折风险增加,且没有明显的预兆.随着年龄的增加,骨密度降低,骨折风险增加,若不及时发现和治疗,导致病情加重和死亡率增加.
常见的骨质疏松性骨折发生在髋部、脊椎、腕部等部位,且年龄是判断骨质疏松症的重要因素之一,在50岁以后,骨质疏松症的发病率显著增加[4].骨质疏松症可根据其病因分为原发性和继发性.原发性骨质疏松症多发病于绝经后妇女群体,继发性骨质疏松症是由于疾病或药物等原因所致[5],临床上以内分泌代谢疾病、结缔组织疾病、肾脏疾病、消化道疾病等为主,可能发生在任何群体身上.骨质疏松症的发病率高,前期没有明显的症状和警示信号,第一个明显症状往往是骨折.正因为这些原因,人们意识到自己患有骨质疏松时,往往已经是晚期,所以骨质疏松症又被称为“无声的流行病”,及时的预测骨质疏松症显得尤为重要.
在骨质疏松症的诊断中,X射线可以观察到骨骼的轮廓和内部结构,但其识别能力较低,只有当骨量丢失30%才能发现;从单光子骨矿物质密度(Bone Mineral Density,BMD)测定仪、双光子BMD测定仪、定量CT检查,到目前通用的双能X线BMD测试仪(Dual Energy X-ray Absorptiometry,DXA)等方法也可以测量骨量[2].DXA被认为是黄金标准,但即使在大多数发达国家,使用这种设备的机会仍然不足[6].所以,对骨质疏松的诊断还较为困难.同时,骨质疏松症的治疗成本较高,造成了重大的经济损失.根据世界范围的预测,目前髋部骨折的费用中,男性为36亿美元,女性为190亿美元,到2050年,预计男性为140亿美元,女性为730亿美元[7].
2017年7月,国务院印发的《新一代人工智能发展规划》中提到,应深化人工智能在智能医疗领域的应用,推广应用人工智能诊疗新模式、新手段,建立快速精准的智能医疗体系.随着医疗信息化的快速发展,电子病历和健康档案的实行,产生了大量的数据信息.通过人工智能技术与医疗大数据的结合,可以提升医疗卫生服务能力,解决医疗资源紧缺等问题.例如:人工智能技术通过对海量的医学文献、病例数据和诊断方案进行快速学习,可以分析出数据之间的隐含关系;通过对医学影像的智能分析,能够准确的进行特征提取,定位病灶,从而辅助医生进行预测、诊断[8].
本文旨在对人工智能在骨质疏松症中的应用进行综述,通过对相关研究所涉及的技术、方法等进行系统讨论,使读者了解人工智能相关技术在骨质疏松领域的应用现状和存在问题.本文结构如下:首先对常用医学人工智能技术进行了介绍,包括基于启发式知识的方法和常用的基于机器学习的方法;然后从骨质疏松症的危险因素分析、风险预测和识别诊断三方面,对人工智能技术在骨质疏松症中应用的相关研究做了回顾总结;最后,对其现存的局限性做了总结并对未来发展进行了展望.
2 常用医学人工智能技术简介
将人工智能技术应用在医学领域,主要有两种方式:基于启发式知识的方法和基于机器学习的方法.
2.1 基于启发式知识的方法
基于启发式知识的方法主要应用于构建医学专家系统,依赖于存储在知识库中的专家知识和 推理引擎中的推理技术,像专家一样对病情进行诊断.主要包含规则推理、框架推理和基于临床指南模型的推理等方法.
2.1.1 规则推理
规则是一种特定领域的知识表达,它封装了用于决策的逻辑流程.在基于产生式规则的系统中,每一个知识单元是一个单独的IF-THEN逻辑语句,推理引擎评估可用的数据和语句,选择下一个执行的语句.产生式规则的格式是IF-THEN语句:
IF(condition) THEN (action)
(condition)代表一条逻辑语句,如果为真,就执行(action).Condition部分也称作语句的左手边(left-hand side,LHS),Action部分被称为右手边(right-hand side,RHS).Condition 可以是一个简单的、与单个可用数据值的比较,也可以是一个复杂的布尔逻辑语句,如:IF 红斑AND 化脓AND NOT 腺病,THEN 结论“病毒性咽炎”.基于产生式规则的推理由匹配、选择和执行组成一个不断重复的环.
2.1.2 框架推理
框架是把某一特殊时间或对象的所有知识存储在一起的一种复杂的数据结构.框架通常由描述事物的各个方面的槽组成,每个槽描述对象的某一方面的特性.槽由槽名和槽值组成,同一个槽有多种类型的槽值,每种类型成为槽值的一个侧面.每个槽可以拥有若干个侧面,而每个侧面可以包含若干个值.框架如何设计取决于具体问题.一般来说,在实际应用中,使用一个框架是不够的,必须同时使用多个框架,并组成框架系统.框架是一种通用的知识表达形式,目前关于如何建立框架还没有统一的方法论,通常是根据具体问题具体分析.基于框架的系统的优点是具有良好的继承性、结构化和自然性,以及推理灵活多变.它的不足之处主要在于它不善于表达过程性知识,而临床诊断恰恰是具有创造性的思维过程,所以基于框架的系统在实际中应用的例子并不多.
2.1.3 基于临床指南模型的推理
在临床实践中,临床指南作为一系列诊断标准的集合可用于指导临床诊断.从20世纪90年代中后期一直到21世纪初,随着临床指南研究的发展,出现了许多以临床指南为建模对象的模型和方法,称为计算机可解释的指南(computer-interpretable guideline,CIG),比较著名的有Asbru[9],PROforma[10],EON[11],GLIF[12],SAGE[13]等,并涌现出一大批根据这些模型开发的专家系统,如ATHENA[14],PRODIGY[15]等.这些指南模型各有偏重,GLIF方法关注指南的标准化,PROforma关注于执行方面,Asbru关注于复杂时间计划的表达和可视化,EON关注于支持指南开发和执行的架构的开发.这种基于临床指南模型构建专家系统的方法本质上也是构建专家系统的方法.与传统专家系统相比,它只是在构建思路上稍有不同.它不将诊断视为一个单独的事件,而是将其视为一个持续的、从收集体征数据,检查检验,重新评估数据,直到足够确信度的结论并采取治疗措施的过程.它在知识的表达方式上并不用基于符号的方法,而是将其抽象成一个个的流程图.在诊断的过程中,基于CIG的专家系统提示医生收集各种信息,然后将形式化的指南知识和最新的病人临床数据进行匹配,最后提供基于特定病人的建议,影响医生的临床行为.
上述几类专家系统在各自的应用场景下取得了一定的效果,但是有相当一部分系统只是停留在评估阶段,并未在临床上获得广泛的接受.抛开系统应用设计层面的问题,最主要的原因就是专家系统中的知识相对于医疗的复杂性来说还是过于简单.医学是一个相当复杂的体系,存有大量科学无法论证的不确定性,很难进行完全的医学知识表达,并且传统推理技术还无法模拟医生诊断和治疗的决策过程.比如在临床信息缺失的情况下,临床医生可以凭借丰富的医学经验,依据不完整、不够精确的临床信息进行推理,确定临床诊断并提出治疗方案,但上述专家系统却在这方面无法与医生相比,在不确定的情况下难以进行准确的分析和推理.另外一种常见的情况是,由于疾病的复杂性和人的个体差异,很多疾病会出现非典型症状,依据启发式方法构建的专家系统很难处理这部分情况,从而判断错误.
2.2 基于机器学习的方法
常用在骨质疏松领域的机器学习方法,包括Logistics回归、决策树、随机森林,人工神经网络、支持向量机、集成学习以及最新的深度学习技术.
2.2.1 Logistics回归
Logistic回归(Logistics Regression,LR)[16]是一种机器学习技术,常用于数据挖掘、医疗诊断等领域.例如分析疾病的危险因素,并根据危险因素预测疾病发生的概率.LR是分析二进制医学数据的黄金标准方法,因为它不仅提供预测结果,而且产生附加信息,例如诊断比值比.在流行病学研究中,Logistics回归模型有两个基本用途,筛选与应变量有联系的自变量和控制混杂因素.公式(1)是简单的Logistics回归方程,其中g(x)=w0+w1x1+…+wnxn,wn是变量xn的权值.图1是简单的逻辑回归模型.
(1)
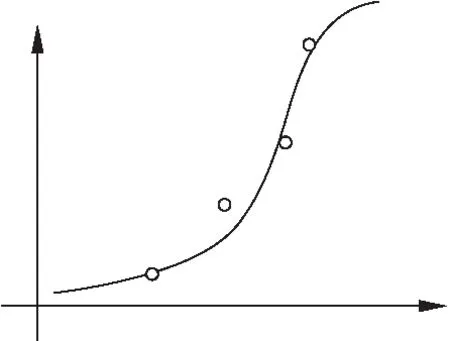
图1 逻辑回归模型Fig.1 Logistic regression model
2.2.2 决策树
决策树(Decision Tree,DT)[17]是一种归纳学习算法,其利用一组无规则、无次序的实例推理出有效的分类规则,从而对数据进行分类.决策树先通过训练集进行学习,得到一个测试函数,然后根据不同的权值建立树的分支,即叶子节点,在每个叶子节点下又建立层次节点和分支,藉此生成决策树.决策树以树状图的形式表示预测结果,比较直观.常用的决策树算法包括ID3和C4.5等.ID3算法根据信息理论,采用划分后样本集的不确定性作为衡量划分好坏的标准,在每个分叶
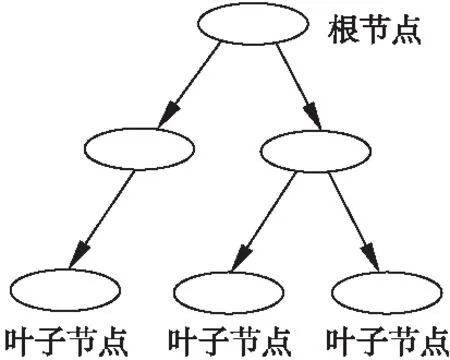
图2 决策树模型Fig.2 Decision tree model
节点选取时,选择信息增益最大的属性作为测试属性.C4.5是对ID3算法的改进和扩展,其用信息增益率来选择属性,克服了ID3在选择属性时偏向选择取值多的属性的不足,当属性值空缺时,通过使用不同的修剪技术以避免树的过拟合[18].图2是简单的决策树模型.
2.2.3 随机森林
随机森林(Random Forest,RF)[19]通过自助法重采样技术,从训练集中重复随机抽取k个分类树组成随机森林.新数据的分类结果按分类树投票多少形成的分数而定.其实质是对决策树算法的一种改进,将多个决策树合并在一起,每棵树的建立依赖于一个独立抽取的样品.随机森林中的每棵树具有相同的分布,分类误差取决于每一颗树的分类能力和他们之间的相关性.特征选择采取随机的方法去分裂每一个节点,然后比较不同情况下产生的误差.能够检测到的内在估计误差、分类能力和相关性决定选择特征的数目.单棵树的分类能力可能很小,但在随机产生大量的决策树后,一个测试样品可以通过每一棵树的分类结果经统计后选择最可能的分类[20].
2.2.4 神经网络
人工神经网络(Artificial Neural Network,ANN)是一种非线性映射方法,属于隐式数学处理方法,不需要建立数学模型,是由网络训练的数据概括出的知识,以多组权值及阀值的方式存储与各个神经元中,从而构建网络知识,利用该知识来评估或预测相关因素的结果[21].在神经网络应用于骨质疏松症的诊断中,需要建立诊断分类的神经网络模型,利用神经网络对已有的数据集进行训练,并用测试集对其进行仿真测试,再对未知的病情进行诊断分析,以得到较为准确的分类结果.
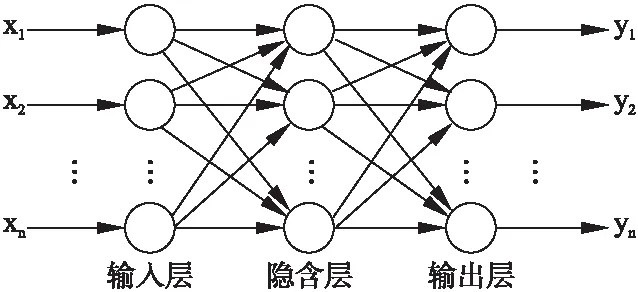
图3 人工神经网络结构Fig.3 Artificial neural network model
在人工神经网络模型的训练过程中,无需人为确定权重,可以减少诊断过程的人为因素,从而提高诊断的靠靠性,使诊断结果更有效、更客观,有助于有效的降低骨质疏松诊断的误诊率和漏诊率[22].图3是简单的人工神经网络模型.
2.2.5 支持向量机
支持向量机(Support Vector Machine,SVM)基于核函数的分类方法,联合多个参数值,在非线性空间利用支持向量机分类算法,能够实现有效的数据分类,得到非线性分类边界[23].神经网络根据经验风险最小化原则(Empirical risk minimization,ERM)来训练学习,而支持向量机则根据结构风险最小化原则(Structural Risk Minimization,SRM)提高学习的泛化能力,避免了神经网络存在的“过学习”问题[24].支持向量机在图像处理、文本分类等领域应用广泛.但是,对于输入变量较多、样本集较大的情况下,支持向量机的计算复杂性和空间复杂性会急剧增加,导致训练时间长、耗用内存资源大.通常可从两个方面来解决,一种是训练算法的改进,如SMO、CSVM等;另一种是通过简化训练数据集来降低计算复杂性[25].图4是简单的支持向量机模型示意图.
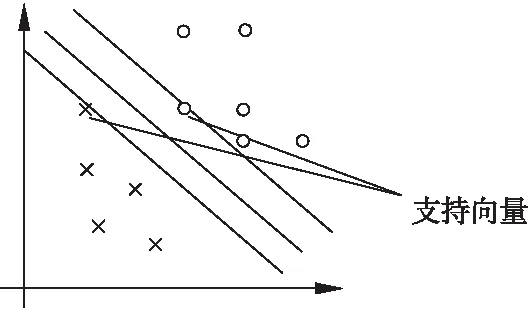
图4 支持向量机模型示意图Fig.4 Support vector machine model
2.2.6 集成学习
集成学习(Ensemble Learning,EL)是当下机器学习的热门研究方向之一.通过构建并结合多个学习器来完成学习任务,以取得比单个分类器更好的效果,有时也被称为多分类器系统(multi-classifier system)、基于委员会的学习(committee-based learning)等[26].一般来说,单一的算法在某方面存在缺陷,当处理复杂问题时,这些缺陷变得特别明显和关键,例如其数据通常具有高度复杂性、不完整性的问题.在单个算法无法满足实际诊断的需求的时候,多种不同算法的组合可以实
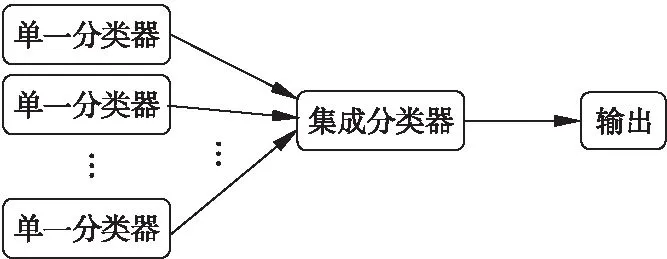
图5 集成学习模型示意图Fig.5 Ensemble learning model
现缺陷的互相弥补,保证机器学习的质量和效率,有效的降低骨质疏松预测、诊断的误诊率和漏诊率.通常通过模型的可靠性、多样性、准确性等来判断集成模型的优劣.图5是简单的集成模型示意图.
2.2.7 深度学习
深度学习(Deep Learning)是机器学习的新领域,旨在通过构建多隐含层的模型和大量的训练集数据来学习更有效的特征,从而提高分类或预测的准确性[27].与传统的浅层学习相比,深度学习具有以下特点:一是特征学习,其可以根据不同的应用自动从海量的数据中学习到所需的高级特征表示,更能表达数据的内在信息;二是深层结构,深度学习模型结构深,通常具有5层甚至更多层的隐含层节点,包含更多的非线性变换,使得拟合复杂模型的能力大大提高;三是无监督学习,模型通过数据内在的一些特征和联系将数据自动分类[28].通过在训练过程中加入无监督学习作为预训练,使得深度学习模型相比人工神经网络具有更好的分类能力.
3 人工智能在骨质疏松症中的应用
人工智能在骨质疏松中的应用,根据其在骨质疏松症中的作用目的,可以分别从骨质疏松症的危险因素分析、风险预测、识别和诊断等方面分析.
3.1 骨质疏松症的危险因素分析
研究表明,影响骨质疏松的危险因素复杂多样.例如,肥胖[29]、体重指数(BMI)[30]、脂质分布[31-34]等都有可能是影响骨质疏松症的危险因素.确定骨质疏松症的危险因素,可以制定更有效的、有针对性的预防方案,以及根据危险因素对骨质疏松进行预测或诊断.这些都有待于利用人工智能技术进行精确分析和预测.
利用人工智能技术可以有效地分析影响骨质疏松症的危险因素,为此,很多学者进行了大量的工作.2005年,Akkus Z 等基于多元二元回归,来确定骨质疏松的危险因素,并评估骨质疏松的风险变量.这项研究表明,低水平的膳食钙摄入、体育活动、教育和更年期延长是我们人群低骨密度风险的独立预测因子,适量的膳食钙摄入,结合日常体育锻炼,提高教育水平,降低产次,延长母乳喂养时间,有助于骨骼健康[35].G Huang等基于多元回归,分析危险因素与骨质疏松之间的关系.结果显示,骨质疏松的主要危险因素,男性是年龄,女性是绝经后的持续时间[36].2006年,Chiu JS等基于人工神经网络对骨质疏松症的危险因素做了研究,认为影响骨质疏松症的主要危险因素包括:人口学特征、人体测量和临床资料(性别、年龄、体重、身高、体重指数、绝经后状况、咖啡消费)[37].陈湘定等基于人工神经网络,对影响骨密度的12个因素进行分析,结果表明,性别影响因素最大,身高、体重、年龄的作用均比基因的作用强,在基因中雌激素受体α基因作用很强,而骨钙素(BGP)基因的作用最弱[38].2009年,C.Ordó?ez等基于支持向量机模型,研究影响骨质疏松症的危险因素,研究显示饮食生活习惯身高、体重、体重指数(BMI)、暴露于阳光下、钙的摄入量、蛋白质的摄入量、怀孕次数、胆固醇水平、碳水化合物的摄入量、脂肪、维生素D、钾、钠等的因素,影响绝经后妇女的骨质疏松症[39].2012年,X Ma等基于Logistics回归,分析动物性食物与骨质疏松的关系.单因素回归分析显示与骨质疏松相关的因素有年龄、出生数、肥胖、受过高等教育、高收入、蔬菜和牛肉;多因素Logistic回归分析显示,鸡蛋可增加骨质疏松症的风险,牛肉和蔬菜可降低骨质疏松症的风险[40].2013年,Anastassopoulos等采用人工神经网络和遗传算法的混合算法对骨质疏松症的危险因素进行分析.结果表明更年期、年龄、酒精摄入量是重要的危险因素[41].2015年,Quan Liu等在老年髋骨骨折的危险性预测研究中,基于人工神经网络分析其危险因素,同时证明男性模型比女性模型的危险因素少,具有更好的分类性能[42].2016年,李茂蓉等基于Logistics回归,分析绝经后非糖尿病妇女骨质疏松症影响因素,单因素Logistics回归分析显示,年龄、文化程度、产次、体质指数(BMI)、血清碱性磷酸酶(ALP)是骨质疏松的可能影响因素,多因素Logistics回归显示高龄、高ALP是中老年绝经后妇女骨质疏松发病的可能影响因素[43].表1是有关骨质疏松症的危险因素分析的相关研究总结.
表1 有关骨质疏松症危险因素分析的相关研究总结
Table 1 Summary of related studies on risk factors of osteoporosis
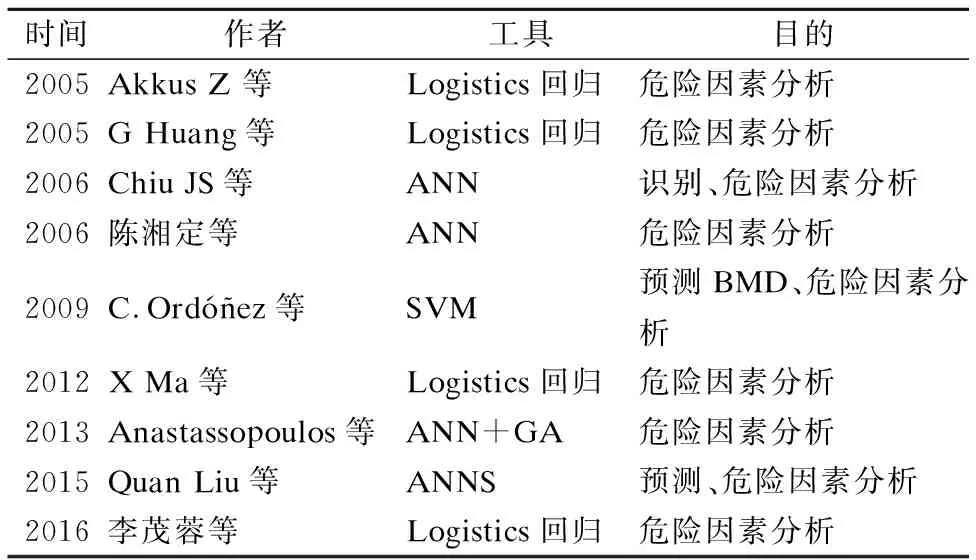
时间作者工具目的2005Akkus Z 等Logistics回归危险因素分析2005G Huang等Logistics回归危险因素分析2006Chiu JS等ANN识别、危险因素分析2006陈湘定等ANN危险因素分析2009C.Ordóñez等SVM预测BMD、危险因素分析2012X Ma等Logistics回归危险因素分析2013Anastassopoulos等ANN+GA危险因素分析2015Quan Liu等ANNS预测、危险因素分析2016李茂蓉等Logistics回归危险因素分析
注释:ANN(人工神经网络)、ANNS(集成人工神经网络)、SVM(支持向量机)、GA(遗传算法)
从以上的研究中可以看出,在对骨质疏松的危险因素进行分析的过程中,Logistics回归是最常用的机器学习算法.影响骨质疏松的最常见的危险因素包括性别、年龄、体重、教育程度、产次等临床参数.同时可以发现,在骨质疏松症的危险因素分析中,男性和女性存在差异性,对于男性来说,最重要的影响因素是年龄,而女性的绝经时间影响力较大.
3.2 骨质疏松症的风险预测
在骨质疏松症的风险预测中,我们从对骨质疏松症的预测和对骨密度的预测两方面进行研究.
3.2.1 对骨质疏松症的预测
骨质疏松症早期的症状不明显,不易被发现,严重时容易导致骨质疏松性骨折,这常常对患者的生活质量产生显著地负面影响,造成较大的经济损失,甚至威胁生命.因此骨质疏松症的早期诊断和预防是社会的重要医学问题[44].如果可以对骨质疏松症进行预测,就可以根据预测结果判断,是否需要进一步诊断,也避免了额外的花费和影像辐射危险.世界卫生组织骨折风险评估工具(FRAX)[45]和Garvan骨折风险计算器[46],都被用来评估髋骨骨折的风险.也有很多研究从人工智能方向入手,对骨质疏松症进行预测.2005年,Wang等基于人工神经网络和决策树的混合集成模型,对女性骨质疏松症进行预测.结果显示,集成模型相比单一模型具有较高的多样性,有效的提高了预测的精度.然而,由于训练后的神经网络和决策树模型之间的差异性不够高,无法显著提高集成模型的性能,需进一步提高其多样性[6].同年,2005年,Sadatsafavi等采用人工神经网络对伊朗绝经后妇女骨质疏松症进行预测.结果表明,人工神经网络模型预测性能高于传统的回归方法和目前公认的决策规则[47].2008年,Chin-Ming Hong等基于模糊神经网络,对骨质疏松症进行预测.结果显示,采用骨质疏松危险因素问卷而不是其他侵入性方法或实验室测量来预测骨质疏松症,不仅可以显著降低大规模筛查的成本,而且可以加快筛查过程[48].2010年,Mantzaris等基于概率神经网络(PNN)和学习向量量化(LVQ)神经网络来评估骨质疏松症的风险,研究结果表明,PNN的正确率为96.58%,优于LVQ的96.03%[49].2010年,G Anastassopoulos等基于概率神经网络(PNNS),评估骨质疏松症的风险[50].2012年,支英杰等基于决策树、人工神经网络、Logistic回归模型,对绝经后妇女的严重骨质疏松症预测进行研究.通过比较三者的ROC曲线,发现,神经网络和Logistics回归的拟合度较好,说明在严重骨质疏松症的预测研究中,可以考虑人工神经网络和Logistics回归[51].同年,孙凤等基于多变量Logistics回归模型,对骨质疏松症进行预测[52].2013年,Tae Keun Yoo等基于流行的机器学习模型,对骨质疏松症进行预测,并将其与四种传统的临床决策工具:骨质疏松自评工具(OST)、骨质疏松风险评估工具(ORAI)、简单计算骨质疏松风险评估(SCORE)和骨质疏松风险指数(OSIRIS)进行比较.结果显示,在将年龄、身高、体重、体重指数、绝经时间、母乳喂养时间、雌激素治疗、高脂血症、高血压、骨关节炎和糖尿病等作为变量输入的情况下,支持向量机模型优于其他模型[53].2014年,李超等基于神经网络和支持向量机的集成模型,对原发性骨质疏松症进行识别.结果显示,集成模型充分利用神经网络非线性映射、自适应、泛化能力和容错能力强,以及支持向量机分类可靠度高,推广性强的优点,其识别误差小于单一模型[54].同年,方骁然等基于支持向量机模型,通过常规的体检参数,对骨质疏松症进行预测[55].2015年,Quan Liu等基于BP神经网络,通过74个输入变量,对老年髋骨骨折的危险性进行预测.结果表明,人工神经网络在处理多输入变量的复杂医学模型方面是有效的.同时证明,男性模型比女性模型具有更好的性能,因为男性病例的复杂度低[42].同年,YC Juan等建立基于遗传算法的集成分类器,采用健康检查资料,预测骨质疏松症[56].2016年,E Tejaswini等基于人工神经网络,利用年龄、性别、身高、体重、受伤或手术史、药物史、运动和相关的医学问题,对骨质疏松症进行预测[57].2017年,TP Ho-Le等基于人工神经网络,通过年龄、骨密度、临床因素和生活方式因素,对绝经后骨质疏松症患者,患髋部骨折进行预测.研究表明,当BMD和非BMD因子结合训练的模型,预测准确度为87%,ROC曲线下面积(AUC)为0.94,该模型比单独使用BMD或非BMD因子训练的模型分类效果好[58].
3.2.2 对骨密度的预测
目前骨质疏松的主要识别特征——低骨密度(BMD),主要通过双能X射线吸收法(DEXA)、定量超声(QUS)、定量计算机断层摄影(QCT)等方法进行测量.这些方法所用的仪器设备非常昂贵,难以在贫穷国家广泛推广;且存在诸如X射线之类的辐射,影响人体健康.所以如果可以对骨密度值进行预测,则可以避免不必要的花费和健康人群的辐射影响.2003年,E.I.Mohamed等基于人工神经网络,将人体测量数据(性别、年龄、体重、身高、体重指数、腰臀比和四个皮褶厚度之和)作为独立输入变量输入人工神经网络,可用于预测和估计特定部位的BMD值[59].2009年,C.Ordó?ez等基于支持向量机,研究骨密度和饮食及生活习惯的关系,并对骨密度值进行预测.同时结果表明,额外的钙摄入,适当的暴露于阳光下,体重控制,有规律的体育活动和足够的热量摄入是减少绝经后妇女骨量损失的主要因素[39].2011年,FJDC Juez等基于人工神经网络,通过营养习惯和生活方式,对骨密度进行预测.同时为了减少输入变量的数量,使用遗传算法处理原始变量,通过仅考虑重要变量的神经网络模型,预测绝经后妇女的骨密度[60].2017年,M Shioji等基于人工神经网络,通过年龄、体重、身高、绝经年龄、月经初潮年龄、绝经后持续时间、BMI、体脂百分比、脂肪质量、瘦体重、腰椎(L2-L4)或股骨BMD值,对绝经后妇女骨密度值及骨丢失率进行预测[61].
从以上相关研究可以看出,在骨质疏松症或者骨密度的预测中,一般使用临床问诊、常规体检参数等不需要花费过多金钱和过多仪器检测得来的数据,对骨密度或者骨质疏松症进行预测,从而判断受试者是否需要进一步全面的诊断,降低医疗费用和患者被辐射的风险.表2是有关骨质疏松症预测的相关研究总结.
3.3 骨质疏松症的识别与诊断
骨质疏松症的特征是骨矿物质含量的异常丢失,从而导致非创伤性骨折或骨结构变形的趋势.因此,准确估计骨密度已成为确定骨质疏松症状态和在骨质疏松症治疗中患者随访研究的最重要的诊断方法.但是许多研究表明骨密度不足以预测骨质疏松性骨折的可能性,其他因素,如骨小梁的微观结构和载荷分布对骨质疏松性骨折有显著影响.以下,我们通过研究者分析所用数据源的不同类型来对相关研究进行回顾.
3.3.1 以问题量表为数据源
在不接受医学影像检查的情况下,通过问题量表、常规体检参数等,可以对骨质疏松症进行识别.
如:2006年,Chiu JS等基于人工神经网络,通过人口学特征、人体测量和临床资料(性别、年龄、体重、身高、体重指数、绝经后状况、咖啡消费),对老年骨质疏松症进行识别[37].2011年,程若珠等基于BP神经网络,通过性别、身高、体重、临床症状问诊、胸腰椎及股骨颈骨密度,对骨质疏松症进行识别[22].2013年,Sung Kean Kim等基于支持向量机模型,通过年龄、身高、体重、体重指数、绝经时间、母乳喂养时间、雌激素治疗、高血压、高脂血症、糖尿病和骨关节炎等,对绝经后妇女骨质疏松症进行识别,并与传统的临床决策工具——骨质疏松症自我评估工具(OST)进行了对比.通过对比建立的SVM模型能更准确的区分骨质疏松症妇女和对照妇女,年龄和体重与骨质疏松的发展密切相关[62].2016年,Pedrassani等基于J48决策树模型,通过年龄段、先前骨折、先前骨折数目、先前股骨颈骨折、先前脊柱骨折、先前前臂骨折、先前t肋骨,药物使用,更年期,钙的使用,激素替代疗法,甲状腺药物的使用,子宫切除术,卵巢切除术,诊断,体重指数(BMI),体重和三度肥胖等,对骨质疏松症进行识别[63].
表2 有关骨质疏松症风险预测的相关研究总结
Table 2 Summary of related research on prediction of osteoporosis
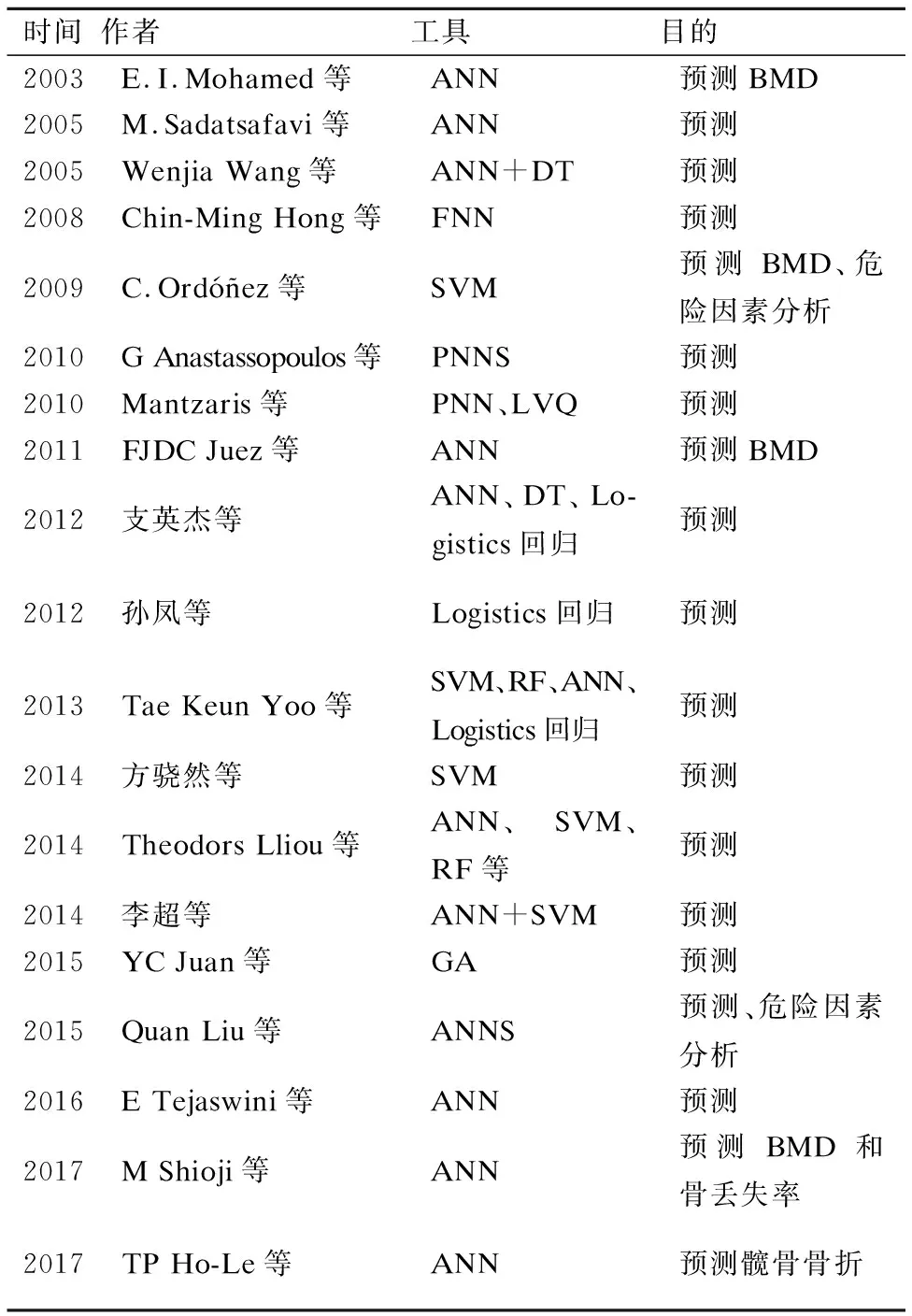
时间作者工具目的2003E.I.Mohamed等ANN预测BMD2005M.Sadatsafavi等ANN预测2005Wenjia Wang等ANN+DT预测2008Chin-Ming Hong等FNN预测2009C.Ordóñez等SVM预测BMD、危险因素分析2010G Anastassopoulos等PNNS预测2010Mantzaris等PNN、LVQ预测2011FJDC Juez等ANN预测BMD2012支英杰等ANN、DT、Lo-gistics回归预测2012孙凤等Logistics回归预测2013Tae Keun Yoo等SVM、RF、ANN、Logistics回归预测2014方骁然等SVM预测2014Theodors Lliou等ANN、SVM、RF等预测2014李超等ANN+SVM预测2015YC Juan等GA预测2015Quan Liu等ANNS预测、危险因素分析2016E Tejaswini等ANN预测2017M Shioji等ANN预测BMD和骨丢失率2017TP Ho-Le等ANN预测髋骨骨折
注释:ANN(人工神经网络)、SVM(支持向量机)、DT(决策树)、FNN(模糊神经网络)、PNNS(集成概率神经网络)、GA(遗传算法)、RF(随机森林)、LVQ(学习矢量量化)等
3.3.2 以医学影像为数据源
医学影像是医学检测中的常用手段,在骨质疏松症的诊断中,我们可以通过特定部位(髋关节、腕关节、椎体等)的医学影像,观察其纹理、结构等,来进行识别.2005年,AM Badawi等基于模糊逻辑和神经网络,对骨质疏松症进行识别.结果显示,该模型的诊断效率为97%,可以很好地识别骨质疏松症[64].2007年,Chen等基于人工神经网络,选取以下参数作为输入:三个骨密度参数(股骨颈、全身、L2L4脊柱)、三个分形参数(最小、平均、最大)和年龄,对骨质疏松患者进行判别,达到81.66%的正确分类,相比之下,传统的分类方法只能达到72%的正确分类[65].2008年,Moua Meneses等基于多层感知神经网络,应用于显微断层图像、X射线成像、骨识别中,对骨质疏松症进行识别[66].第二年,作者基于人工神经网络对图像像素进行分类,对人骨小梁结构进行定量分析.结果表明,尽管骨小梁结构复杂,但人工神经网络在图像像素的识别和定量分析以及图像的特征相容性方面是成功的[67].2010年,R.Jennane等基于遗传算法,通过髋关节显微CT图像,对骨质疏松症进行识别[68].同年,Zhi Gao等基于C4.5决策树模型,对骨小梁显微CT影像中提取的特征进行分类,以识别骨质疏松症[69].2012年,Harrar K等基于多层感知(MLP)神经网络,通过骨结构的五个特征:年龄、骨矿物质含量(BMC)、骨矿物质密度(BMD)、分形赫斯特指数(H.)和共流纹理特征(CoEn),来对骨质疏松症进行早期诊断.研究结果显示,MLP可以达到97%的正确估计,优于贝叶斯网络的86%,Logistics回归的96%[70].同年,Istanbullu,M等基于人工神经网络和支持向量机,通过计算机断层扫描图片,来识别骨质疏松症,ANN的准确率为70%,SVM的准确率为86%[71].2013年,Yan Xu等基于支持向量机和k-近邻(KNN),通过显微CT图像进行骨质疏松诊断.研究选择的图像特征,包括骨体积/总容积(BV/TV)、骨表面/骨体积(BS/BV)、骨小梁数目(Tb.N)和体积拓扑分析(VTA)的其他四个特征.结果显示SVM模型的分类效果优于KNN模型,同时除了选择的特征外,图像纹理特征也有助于骨质疏松的识别[72].同年,Sapthagirivasan等基于支持向量机模型,从髋关节的影像信息中提取骨小梁特征,以识别低骨密度的受试者[73].D.S.Li等基于支持向量机,通过体积拓扑分析从显微CT图像中获得骨密度(BMD)以及与骨小梁(TB)结构相关的四个参数,识别骨质疏松症[4].2014年,周珂等基于度量学习和支持向量机的集成模型,通过对骨质疏松纹理进行分析,来识别骨质疏松症.结果显示,基于度量的SVM模型比单独使用度量学习和SVM 的识别率高,而且分类结果稳定,在临床影像中应用可以尽快对患者进行确诊和尽早治疗[74].2015年,Tafraouti等基于支持向量机模型,对从X射线影像中提取的特征进行分类,来识别骨质疏松症[75].2016年,刘健基于支持向量机,对显微CT影响进行自动分类,诊断骨质疏松疾病[76].同年,2016年,N Kilic等基于随机子空间方法和随机森林(RSM-RF)集成模型,对骨质疏松症进行识别[77].2017年,蔡洁等将从骨小梁图像中提取出的纹理特征和形状特征相结合,用支持向量机、K-最近邻分类算法和线性判别分析方法,对骨质疏松症进行识别.结果表明,纹理参数和性状特征结合是,模型分类准确性比用一种参数的分类准确性高[78].同年,Muatapha Aouache等基于模糊决策树(FDT)模型,通过对颈椎影像识别,对骨质疏松症进行识别[79].Reshmalakshmi C等基于模糊专家系统和常规X射线图像处理技术的集成模型,通过临床影像,对骨质疏松症进行识别.结果显示,该集成模型有助于诊断骨质疏松和骨量减少[80].Yassine Nasser等提出了一种基于深度学习的骨质疏松症诊断新方法[81].
在通过医学影像骨质疏松的识别中,除了对特定部位的医学影像进行研究,也可通过牙科医学影像来判断骨质疏松.据调查,绝经后妇女进行骨质疏松症诊断的比例很低[82],但有很多机会去牙科所进行口腔护理和治疗,每年拍摄大量的牙科全景影像(日本约1200万,美国约1700万)用于诊断和治疗牙科疾病,如龋齿和牙周病,但没有用于非牙科的诊断[83],从牙科全景影像中提取的平层宽度和形状进行重新分类,对骨质疏松症进行诊断,具有较好的敏感性和特异性.2007年,Arifin等基于模糊神经网络(FNN),通过绝经后妇女的牙科全景影像,对骨质疏松症进行识别.结果表明,FNN结合皮质宽度和形状可用于牙科临床骨质疏松症患者的鉴别[84].2008年,Sooyeul Lee等基于支持向量机,使用X光影像,结合BMDS参数,区分骨质疏松骨折和非骨折组,并与仅适用BMDS的参数对比,检测骨质疏松骨折的灵敏度和特异性显著增加[67].2012年,M S Kavitha等基于支持向量机,通过牙科全景影像上关于下颌骨皮质宽度,对低骨密度的绝经后妇女进行识别[85].2013年,KM Subash等基于凝聚层级聚类(HAC)和支持向量机的集成模型,对牙齿的全景影像进行分类,对骨质疏松症进行识别[86].2014年,Suprijanto 等基于支持向量机,通过牙齿全景影像,对骨质疏松症进行识别[87].2016年,MS Kavitha等基于混合遗传算法(GSF)模糊分类器,利用牙科数字影像,对骨质疏松症进行识别,进一步将混合GSF分类器的性能与单个遗传算法(GA)和粒子群优化(PSO)模糊分类器的性能进行了比较.结果显示,使用混合GSF分类器对低骨密度和骨质疏松症的识别性较好[88].2018年,D.Devikanniga等基于蝶形优化的人工神经网络,通过数字牙科全景摄影的下颌皮质骨和小梁骨属性,结合人口统计学属性,来识别骨质疏松症和正常人[89].
从以上的研究中可以看出,对于骨质疏松症的识别,可以通过临床问题量表、骨密度值、以及相关医学影像等进行识别.单独的骨密度值不足以对骨质疏松症进行准确识别,医学影像中提取骨骼的纹理特征、分形特征等参数,以及受试者的临床问诊、生活习惯等参数也对骨质疏松的识别有很大的帮助.所以,合理的将临床问诊、医学影像等参数相结合,运用合适的人工智能算法可以提高分类模型的性能.表3是有关人工智能在骨质疏松症识别诊断的相关研究总结.
4 讨 论
4.1 人工智能在骨质疏松应用的制约因素
1)缺乏标准的公共数据集.因为骨质疏松领域没有标准的公共数据集,所以每个研究者研究所用的数据都是自己收集的不同数据集.这些数据集具有地域、性别、人种等限制因素,使得训练模型特异性、正确性等性能受到影响.同时,这也导致由不同研究者提出的人工智能算法间不能直接进行诊断性能的比较,无法评估相互之间算法的优劣.
2)研究所用的数据集规模较小.在已有的研究中,模型所使用的训练集的规模都比较小(图6是上述所列研究中采用不同训练集容量的分布统计),可以看到0-100例数据占据了研究数目中的绝大多数,约有53%,3500-4000例数据的研究仅占4%,并且没有4000例以上的研究.以这样的数据规模生成的模型无法充分逼近疾病诊断的真实情况,存在局限性,也无法达到令临床医生满意的诊断效果.骨质疏松领域缺乏高质量的大数据集.
表3 有关骨质疏松症识别诊断的相关研究总结
Table 3 Summary of related research on identification of osteoporosis
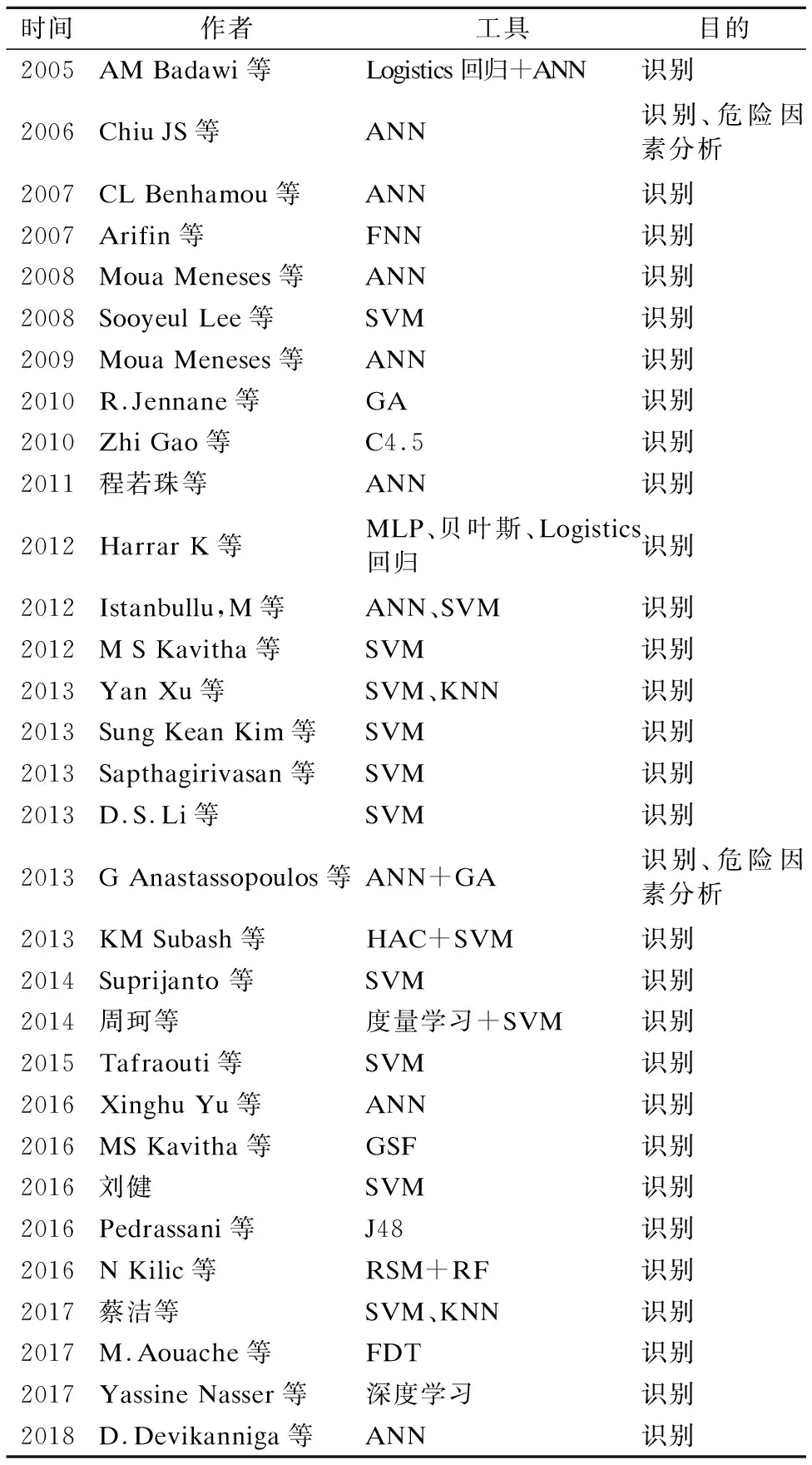
时间作者工具目的2005AM Badawi等Logistics回归+ANN识别2006Chiu JS等ANN识别、危险因素分析2007CL Benhamou等ANN识别2007Arifin等FNN识别2008Moua Meneses等ANN识别2008Sooyeul Lee等SVM识别2009Moua Meneses等ANN识别2010R.Jennane等GA识别2010Zhi Gao等C4.5识别2011程若珠等ANN识别2012Harrar K等MLP、贝叶斯、Logistics回归识别2012Istanbullu,M等ANN、SVM识别2012M S Kavitha等SVM识别2013Yan Xu等SVM、KNN识别2013Sung Kean Kim等SVM识别2013Sapthagirivasan等SVM识别2013D.S.Li等SVM识别2013G Anastassopoulos等ANN+GA识别、危险因素分析2013KM Subash等HAC+SVM识别2014Suprijanto 等SVM识别2014周珂等度量学习+SVM识别2015Tafraouti等SVM识别2016Xinghu Yu等ANN识别2016MS Kavitha等GSF识别2016刘健SVM识别2016Pedrassani等J48识别2016N Kilic等RSM+RF识别2017蔡洁等SVM、KNN识别2017M.Aouache等FDT识别2017Yassine Nasser等深度学习识别2018D.Devikanniga等ANN识别
注释:GSF(混合遗传群模糊分类器)、RSM(随机子空间)、FDT(模糊决策树)、HAC(凝聚层级聚类)、MLP(多层感知器)
3)算法模型自身的局限性.一般来说,单一的算法在某方面存在缺陷,当处理复杂问题时,这些缺陷变得特别明显和关键.在处理骨质疏松症的问题时,危险因素复杂、多样,单一的模型展现的性能受到限制,不能很好的满足骨质疏松应用需求.例如,人工神经网络作为一种非线性的映射方法,被广泛应用的同时,其也存在缺陷.比如,所取的样本的数量和质量很大程度上影响神经网络模型的学习性能、网络层数、与此同时,隐含层神经元的数量的选取也影响整个网络的学习能力和效率等[90].传统的BP算法随应用广泛,但存在易出现极值、收敛速度慢等问题.支持向量机(SVM)是一种新的机器学习技术,根据有限的样本信息在模型的复杂性(即对特定训练样本的学习精度)和学习能力(即无错误的识别任意样本的能力)之间寻求最佳折中,以获得最好的推广能力.但SVM存在核函数难求解,且需要大量存储空间来计算函数的二次规划的不足[91].所以将多种算法融合,扬长避短,形成新的算法来解决骨质疏松症领域的问题是很多研究者采用的重要方法.
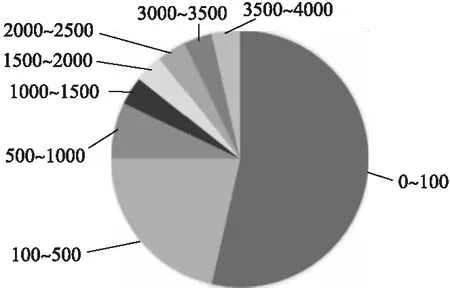
图6 采用不同训练集容量的研究分布图Fig.6 Research distribution map with different training set capacity
4)缺少时间维度的分析.目前对于骨质疏松症的预测和诊断的相关研究,仅针对单一病例某一个时间点进行判断,缺少时间维度的数据.但实际在临床中,不同时间点的症状对于预测疾病未来发展以及日后的治疗方案的确定非常重要.如果能在积累临床案例时,注意追踪某个人一段时间内的数据,那么这样的案例数目积累到一定程度,将更有利于患者的未来骨质疏松的预测.
4.2 未来发展方向
1)建立标准的公共数据库.公共数据库中的数据可供全球的骨质疏松研究者利用.公共数据库中的数据应具备种类多样、样本量大等特点,还要充分考虑多地区间人种的差异.不同的地区的不同人群可以建立常模数据和异常数据.通过对其进行模型的训练,可以更好的适应受试者多样的特点.为建立标准数据库,本文对相关研究中所用的骨质疏松症相关危险因素进行了总结,如表4所示.
2)多种算法深层次结合.在单个算法无法满足实际诊断的需求时,多种不同算法的组合可以实现算法缺陷的互相弥补,保证器学习的质量和效率,有效的降低骨质疏松症预测、诊断的误诊率和漏诊率.目前,集成模型以及多种算法融合的混合智能算法是一种研究趋势,一些学者已经开展了相关的研究工作[88].
3)深度学习技术在骨质疏松上的应用.近年来,深度学习在图像识别等领域取得了巨大的成功.在医疗领域,深度学习得到了很大的关注,例如对恶性肿瘤、肺部结节等疾病的学影像进行处理分析,来辅助医生做诊断.骨质疏松症的诊断也依赖医学影像,所以深度学习与骨质疏松影像也会得到很好地结合,从而提高其诊断的准确性.
4)多模态数据分析.骨质疏松的预测非常复杂,需要医生综合多方面的临床信息综合判断.如果研究仅以单一数据源进行分析,数据源所提供的信息往往有局限性,也不符合临床实际.所以多模态数据的综合分析是骨质疏松症人工智能未来研究的一大趋势.尤其是利用人工智能方法在临床数据、量表数据、影像数据的基础上再加入基因组学数据的分析,目前这方面的研究并不多,但已经有部分学者开始了这方面的研究[38].
表4 相关研究所用危险因素
Table 4 Risk factors used in relevant research

骨密度值图像参数临床因素1.股骨颈骨密度2.全身骨密度3.L2-L4脊柱的骨4.密度5.腰椎骨密度6.胸椎骨密度1.骨体积/总容积(BV/TV)2.骨表面/骨体积(BS/BV)3.骨小梁数目(Tb.N)4.分形参数5.纹理特征6.牙科全景照片上关于下颌骨皮质宽度1.种族2.教育3.职业4.婚姻5.月收入6.性别7.年龄8.体重9.身高10.体重指数11.腰臀比12.四个皮褶厚度之和13.绝经后状态14.母乳喂养时间15.月经初潮年龄16.雌激素使用17.咖啡摄入量18.蛋白质摄入量19.酒精摄入量20.胆固醇水平21.碳水化合物的摄入量22.脂肪摄入量23.维生素D摄入量24.钾、钠的摄入量25.钙的摄入量26.骨折历史27.抗高血压药物使用28.更年期持续时间29.糖皮质激30.甲状腺药物的使用31.高血压32.高血脂33.糖尿病34.骨关节炎35.心脏病史36.骨质疏松性肝病37.癌性白内障38.慢性呼吸道疾病39.便秘40.子宫切除术41.卵巢切除术42.骨痛43.足根痛44.腰膝酸软45.下肢拘挛46.盗汗47.少气懒言48.畏寒肢冷49.夜尿频50手足心热51.健忘52.握力53.饮食习惯54.生活习惯55.体育锻炼56.怀孕次数57.出生或流产儿童数58.腰椎T值59.股骨T值60.大家族病史62.吸烟史
5 结 论
本文主要回顾了人工智能技术在骨质疏松症中的应用.研究发现,人工智能技术在骨质疏松症的预测、识别、以及危险因素分析中,相对于传统方法,都有较好的性能.基于人工智能技术,在骨质疏松症的预测中,通过临床问卷和常规体检参数,对骨密度或者骨质疏松性骨折进行预测,有助于受试者减少疾病花费和过多的辐射暴露;在骨质疏松症的识别中,通过对问题量表或者医学影像对其进行诊断,提高了模型的分类准确性;在骨质疏松症的危险因素分析中,Logistics回归被广泛的应用.与此同时,人工智能技术在骨质疏松症中的应用,依然存在很多的局限性,如:缺乏标准的公共数据库、算法本身的局限性等.但随着人工智能技术的不断发展,如深度学习等技术的不断深入研究,其在骨质疏松症中的应用也会更加广泛.
猜你喜欢
中老年保健(2022年3期)2022-08-24
昆明医科大学学报(2022年4期)2022-05-23
装备环境工程(2022年2期)2022-03-15
保健与生活(2022年5期)2022-03-15
现代临床医学(2021年6期)2021-11-20
保健与生活(2021年17期)2021-09-17
保健医苑(2021年7期)2021-08-13
今日农业(2020年17期)2020-12-15
电子制作(2019年10期)2019-06-17
科学与财富(2016年34期)2017-03-23
