
分布式通信对抗智能决策仿真系统
2019-08-30 03:31宋秉玺杨鸿杰杜宇峰
无线电通信技术 2019年5期
宋秉玺,肖 毅,杨鸿杰,杜宇峰
(1.中国电子科技集团公司第五十四研究所,河北 石家庄050081;2.中国人民解放军31618部队,福建 福州350003)
0 引言
自20世纪60年代人工智能被提出以来,它已应用于模式识别、语言处理和图像识别等各种领域,人工智能应用于通信对抗也已经成为国际的前沿研究方向[1]。在电子对抗方向上,美国国防高级研究计划局(DAPRA)近年来使用新一代人工智能技术重点发展自适应电子战行为学习及自适应雷达对抗等认知电子战项目[2-3],并将电子战系统的智能化水平提到前所未有的高度。2018年,美国国防部启动了联合人工智能中心(JAIC),预计投资16亿美元,探索人工智能在电子对抗领域的应用。中国船舶工业总公司的杨春华等人做了Agent理论和技术在电子战中应用的研究,主要应用于雷达对抗[4],本文将主要通过仿真手段来研究多Agent在通信对抗中的应用实现。通过建立仿真模型,来模拟通信对抗过程,进而完成智能决策算法的学习与验证,可以有效提升通信对抗能力。
1 对抗模型设计
本文主要目的是研究群体通信对抗的自动化协作决策问题,针对该问题提出模型开展仿真,找出最优方案。要构建决策对象模型,此对象模型应可以客观表征群体通信对抗作战的特点,能够进行博弈、有胜负,应用于决策技术的训练,可以展示作战过程,并且可以人机对抗演示。由此仿真模型的基本元素构想如下:
① 红蓝双方:进行博弈的2个作战方;
② 通信单元:负责进行通信的单元;
③ 干扰单元:负责进行干扰对方通信单元;
④ 干扰区域:干扰单元可以干扰到的范围;
⑤ 策略:对应作战单元的移动方式;
⑥ 行动方式:红蓝双方每次可以移动的作战单元数目,有步进方式和整体方式2种,其中步进方式表示红蓝双方每次只动一个仿真单元,整体模式则表示红蓝双方每次可动多个仿真单元;
⑦ 数量规模:仿真单元数量;
⑧ 对战策略:对战的方式,人机对战和机器对战;
⑨ 地图大小:棋盘大小,代表作战单元可移动的位置范围;
⑩ 胜负判别:多轮后累计被干扰的通信单元总数少的一方获胜。
由此设计的仿真模型基本处理流程如图1所示,可视化对抗仿真主界面如图2所示。

图1 仿真模型基本处理流程
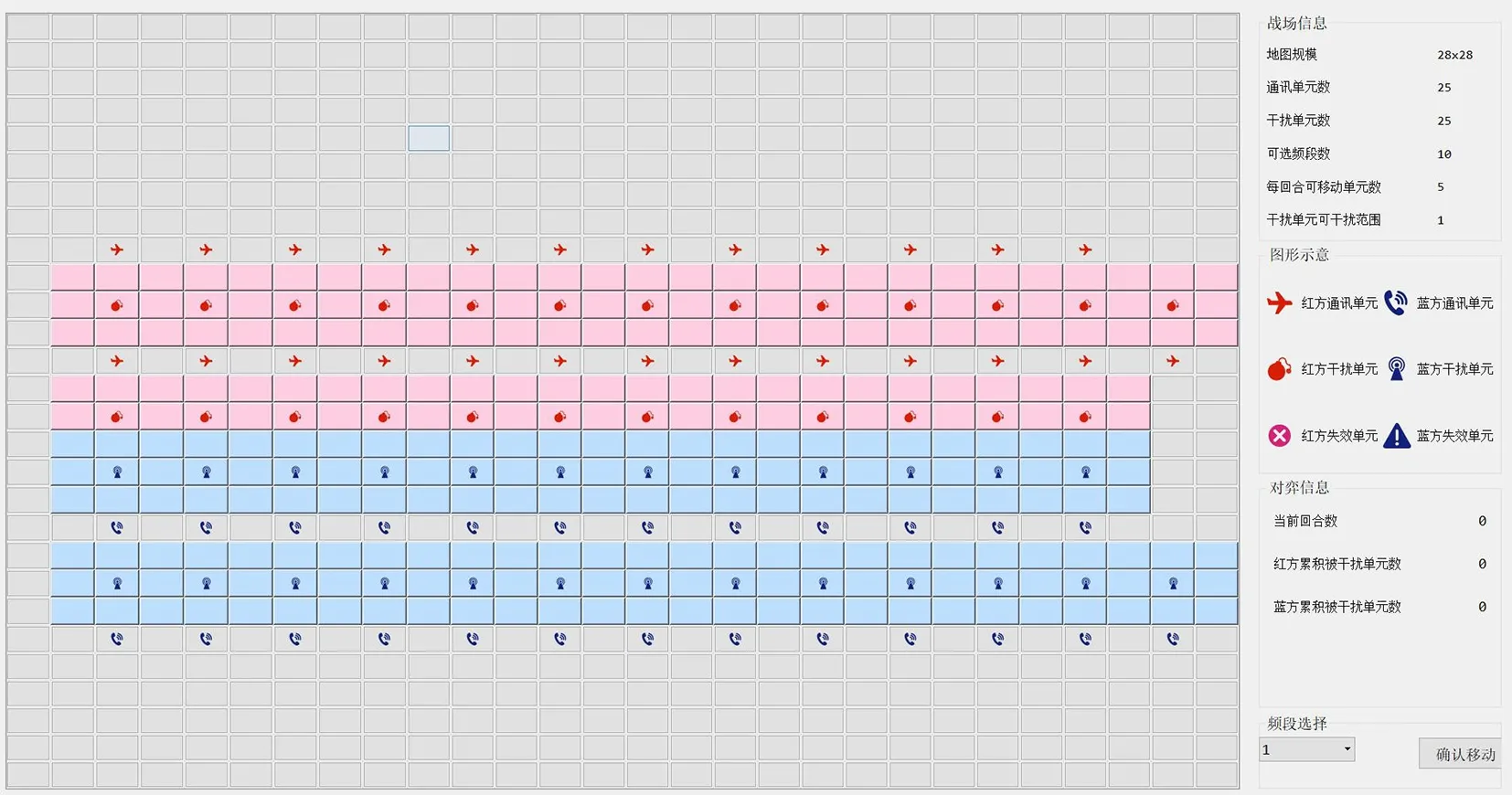
图2 可视化对抗仿真主界面
根据基本设计元素和流程设计博弈战场环境基本的配置界面主要通过在交互界面上点击下拉框选择相应的配置参数。这些参数配置信息常驻内存,在仿真的每一个回合博弈的过程中是不可重入的,在每一个回合博弈开始时是可重入的。
根据仿真配置界面数据生成通信对抗主场景,实时可视化展示当前仿真对抗的相关信息,如图2所示。页面展示的内容包含当前战场和仿真单元的位置和干扰区域等信息,显示当前回合和平均上红蓝双方的正常通信数量和干扰通信数量,显示出仿真过程。
2 智能仿真体决策关键技术
2.1 基于After-State强化学习搜索算法
2.1.1 环境定义
首先对强化学习中的环境进行定义,包括状态空间、动作空间和奖赏函数。
(1)状态表示
整个对战棋局的状态使用28*28*6的数据结构进行表示,具体每一通道所代表的含义如图3所示。
(2)动作和奖励
动作:本方所有移动单元的动作(50*5*10);
奖励:∑(本方通信单元数目+干扰对方通信单元数量)的变化值。
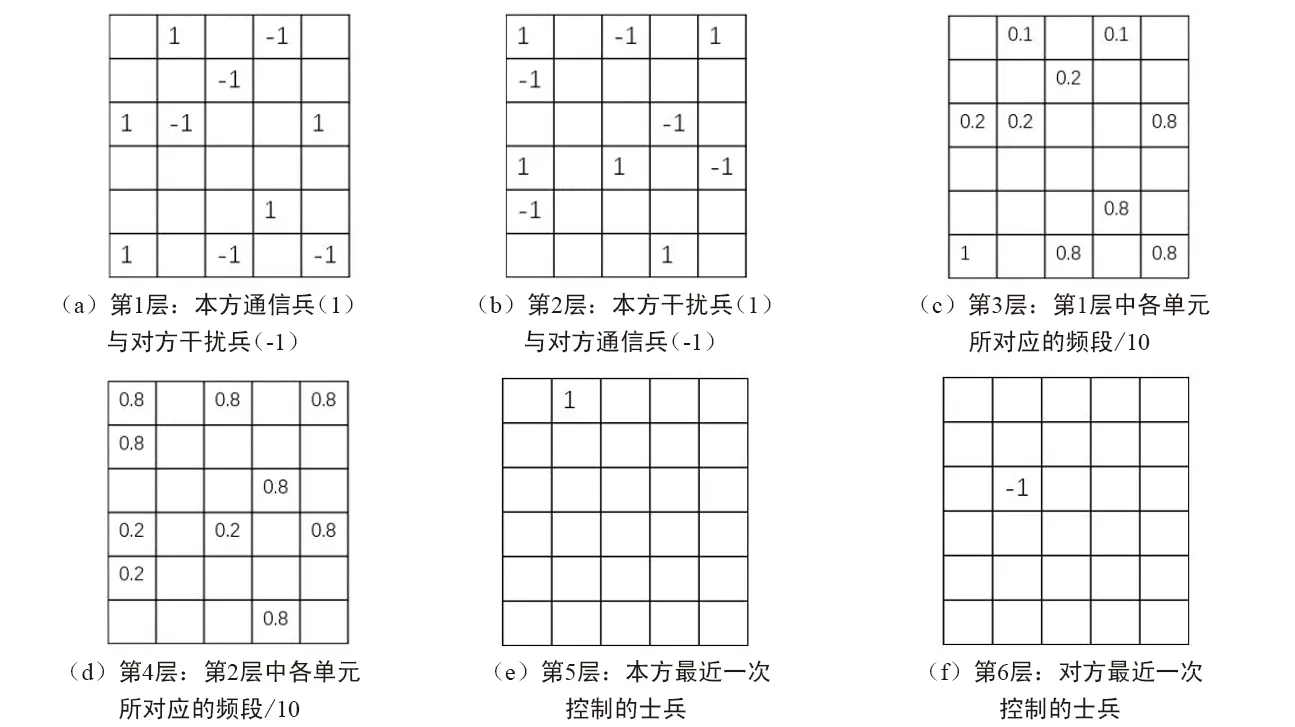
图3 棋局状态表示
2.1.2 算法介绍
① 初始化状态价值网络V(S);
② 获取当前的战场状态;
③ 通过环境模型获取所有可能的动作所到达的下一个状态;
④ 将所有可能到达的下一个状态输入至状态价值网络中,获取对应的V值;
⑤ 通过评估所有可能的V值获取当前的策略,即选择最大的V值所对应的动作;
⑥ 通过执行动作,获取Reward,更新当前的V值,更新方法为:V(S)=r+γV(S′)。
算法描述如图4所示。
网络的输入即之前定义的状态,是一个三维的张量,中间的卷积层本文定义了3层,卷积核的大小为3*3,卷积核的数量为64个,最终的全连接层的单元数为256,接最终的输出,即输入状态对应的V值。在本网络中的损失函数使用的是均方误差MSE,可以类比于回归任务。优化器用的是Adam。
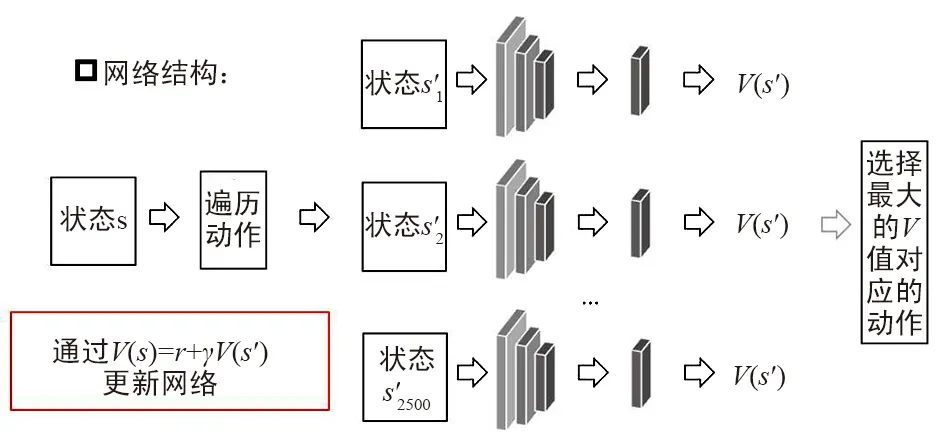
图4 基于After-State强化学习算法示意图
2.2 基于多Agent的集中式控制算法
通过对该场景进行分析认为:干扰兵必须到达地理上的可干扰区域,才能够通过控制频段实现干扰;而通信兵只有在保证较大程度地远离对方干扰兵,到达安全距离的条件下,才能最大程度保持跟队友的频段一致。因此,最核心的控制部分在于位置的控制,在该方法中将动作的控制与频段的选择进行了分离。位置的控制采用了强化学习的算法,位置确定之后频段采用基于全局的控制方法。环境定义和状态表示与基于After-State强化学习算法类此,算法的基本步骤如下:
① 初始化状态动作价值网络Q(s,a);
② 在本方所有的Agent中进行循环,依次选择;
③ 根据选择出的Agent,确定该Agent的视野,进而确定其对应的状态;
④ 将该状态输入至Q网络中,获取所有动作对应的Q值;
⑤ 在环境中对该Agent执行最大Q值所对应的动作,并获取所对应的Reward;
⑥ 通过该Reward使用TD-ERROR更新Q网络;
⑦ 通过全局控制的频段选择方法对频段进行选择;
⑧ 执行下一个Agent一直到该回合结束。
算法描述如图5所示。
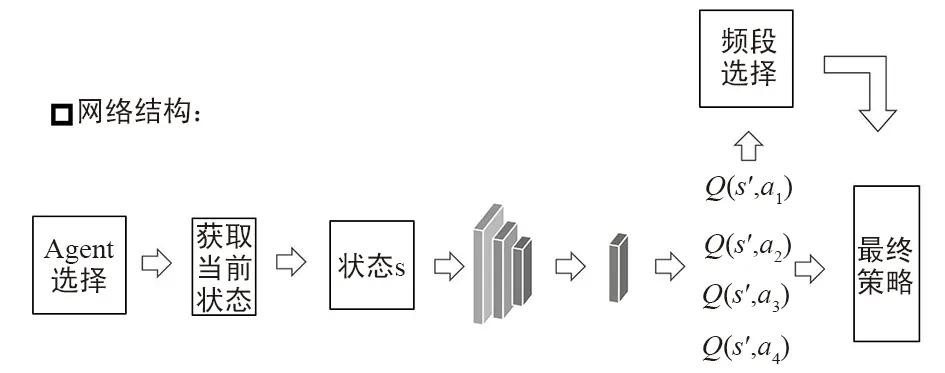
图5 基于多Agent的集中式控制图
网络的输入即之前定义的状态,是一个三维的张量,中间的卷积层本文定义了3层,卷积核的大小为3*3,卷积核的数量为64个,最终的全连接层的单元数为256,接最终的输出,即输入状态对应的所有动作的Q值。在本网络中的损失函数使用的是均方误差MSE,可以类比于回归任务。优化器用的是Adam。
2.3 基于平均场的多Agent强化学习算法
通过对基于多Agent的集中式控制算法场景进行分析,在此基础上提出再利用平均场论来理解大规模多智能体交互,极大地简化了交互模式,提高多智能体强化学习算法的能力。应用平均场论后,学习在2个智能体之间是相互促进的:单个智能体最优策略的学习是基于智能体群体的动态;同时,集体的动态也根据个体的策略进行更新。环境定义和状态表示与基于After-State强化学习算法类此,算法的基本步骤如下:
① 初始化状态动作价值网络Q(s,a);
② 在本方所有的Agent中进行循环,依次选择;
③ 根据选择出的Agent,确定该Agent的视野,进而确定其对应的状态;
④ 计算每一个Agent的所有邻居Agent的平均行为;
⑤ 将第③步和第④步计算出的结果合并;
⑥ 将第⑤步的结果输入到该状态输入至Q网络中,获取所有动作对应的Q值;
⑦ 在环境中对该Agent执行最大Q值所对应的动作,并获取所对应的Reward;
⑧ 通过该Reward使用TD-ERROR更新Q网络;
⑨ 通过全局控制的频段选择方法对频段进行选择;
⑩ 执行下一个Agent一直到该回合结束。
基于平均场的多Agent强化学习描述如图6所示。

图6 基于平均场的多Agent强化学习图
网络的输入即之前定义的状态,是一个三维的张量,中间的卷积层本文定义了3层,卷积核的大小为3*3,卷积核的数量为64个,最终的全连接层的单元数为256,接最终的输出,即输入状态对应的所有动作的Q值。在本网络中的损失函数使用的是均方误差MSE,可以类比于回归任务。优化器用的是Adam。最后在选择最大的V值对应的动作之后,本文再基于贪心策略选择频段,如果当前的Agent被干扰则更换频段,使得不被干扰;否则频段不变。
3 终端对抗学习仿真过程
在双Ti1080GPU下,用Python平台经过3小时训练后,通信子与干扰子初步具备了对抗能力。对抗的干扰子和通信子具备了追击和躲避功能,干扰兵会向前移动去干扰对方的通信兵,而通信兵则向后移动躲避对方干扰兵的干扰。干扰子在进入通信子可干扰范围后,可以自动选择和通信方一致的干扰频段进行干扰,如图7所示,红干扰单元成功干扰蓝方通信兵,使其不能通信。
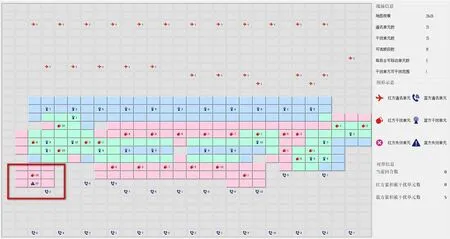
图7 红干扰单元成功干扰蓝方通信兵
当通信方被干扰后,应当自动逃离干扰子,通过训练学习后,通信子具备了此项能力,在被干扰后通信子优先选择了距离远离,并没有优先选择改变频段策略,只有无法移动后,才选择改变频段,如图8所示,蓝方被干扰通信兵陈工逃离红方干扰单元的干扰。

图8 蓝方被干扰通信兵陈工逃离红方干扰单元的干扰
经过计算机3天的增强学习训练,各干扰节点可以简单配合对通信节点进行联合干扰。近距离干扰节点可以组成一个小组进行协作,对敌方多子进行干扰,如图9所示。
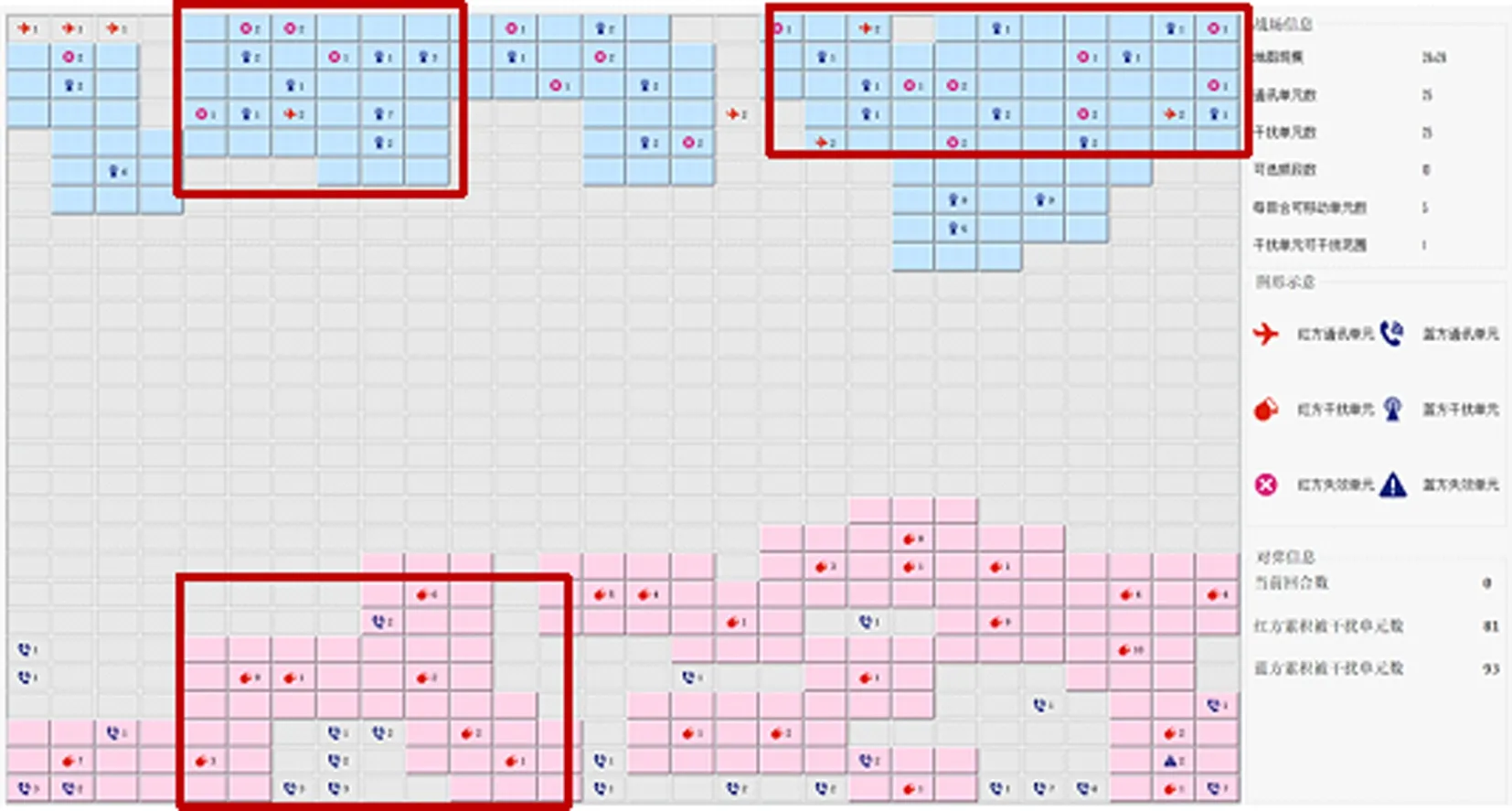
图9 近距离干扰兵作为一个小组进行合作
4 结束语
本文对分布式通信对抗作战进行了模型建立和仿真运行,设计了红蓝双方多智能体、双兵种的作战模式,分别仿真了机器自主对战和人机对战的不同模式,在此基础上利用基于平均场的强化学习算法,实现了在分布式通信对抗环境下的智能对抗系统,并对敌方系统采用随机策略、贪心策略以及人工策略的多种情况进行了仿真。事实证明,该智能对抗系统能够赢过随机策略及贪心策略,且能够在对抗人工策略时达到百分之五十的胜率。本文的方法为智能对抗系统的进一步研究提供了新的思路,可以为智能对抗系统的发展提供参考。
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02
中国传媒大学学报(自然科学版)(2021年1期)2021-06-09
地震研究(2021年1期)2021-04-13
电子制作(2019年13期)2020-01-14
航天电子对抗(2019年4期)2019-12-04
小学生作文(低年级适用)(2019年5期)2019-07-26
电子制作(2019年11期)2019-07-04
北京航空航天大学学报(2018年1期)2018-04-20
读友·少年文学(清雅版)(2018年12期)2018-04-04
CHIP新电脑(2016年3期)2016-03-10
