
边缘计算下的AI检测与识别算法综述
2019-08-30 03:31孔令军李华康
无线电通信技术 2019年5期
孔令军,王 锐,张 南,李华康
(1.南京邮电大学,江苏 南京 210003;2.北京中燕信息技术有限公司,北京 102488;3.中国航天系统科学与工程研究院,北京 100048)
0 引言
随着人工智能(Artificial Intelligence,AI)热潮的兴起,深度学习等多种算法相继被探索出来,并广泛应用在安防、交通、医疗、教育、零售、家居等领域[1]。卷积神经网络(Convolutional Neural Network,CNN),是深度学习的代表算法之一,并被广泛应用于计算机视觉、自然语言处理等领域[1]。
ImageNet[3]比赛的开展,促使图像领域卷积网络快速发展,深度学习方法远远超过传统方法的准确率,使得CNN获得了巨大的关注。随后的比赛中,CNN逐渐取代了传统的目标检测算法。为了进一步增加模型的准确率,卷积网络的模型不断被加深,导致现在的模型需要庞大的计算能力和内存才能胜任某些工作。深度学习理论的蓬勃发展,带动了商业化的需求,尤其是在智慧城市等相关领域,如人脸识别、车辆检测及车牌识别等。传统的监控系统设计方式由客户端和服务器构成:客户端负责收集图片并上传服务器,服务器负责对图片运用人工智能算法进行分析。随着客户端的增加,客户端所产生的数据量也将随之变大。这些数据若都交由云端服务器管理平台来处理,将会造成网络传输和服务器端巨大的压力。同时,设备之间的性能不相同使得实时协同工作难以保证,数据泄露风险还将增大。IDC表示到2019年,近50%物联网创建的数据将被存储、处理、分析,并在网络边缘进行操作。麦肯锡估计,到2025年,物联网应用的经济影响可能会从每年3.9万亿美元增长到11.1万亿美元。他们举例说:“在2025年,通过远程监控改善慢性病患者健康状况的价值可能高达每年1.1万亿美元。”Markets And Markets的一份新研究报告预计,边缘计算市场预计将从2017年的14.7亿美元增长到2022年的67.2亿美元,在预测期内复合年增长率超过35%。Gartner的分析报告显示,目前,大约10%的企业生成数据是在传统的集中式数据中心或云之外创建和处理的,到2022年,Gartner预测这一数字将达到50%。随着5G时代的到来和AI硬件的发展,实时、智能、安全、隐私等四大趋势催生了边缘计算与前端智能的崛起。
1 边缘计算以及卷积网络发展概况
本节将主要阐述边缘计算发展历程以及深度学习中CNN的发展历程。
1.1 边缘计算发展历程
边缘计算最早可以追溯至1998年提出的内容分发网络(Content Delivery Network,CDN),它是一种基于互联网缓存网络,通过中心平台的负载均衡、调度等将用户访问指向最近的缓存服务器上,以此降低网络阻塞。2009年提出的Cloudlet概念,高性能、资源丰富的分布式服务器为移动设备提供计算或者资源访问服务,此时边缘计算强调的云服务器功能下行至边缘服务器,以减少带宽和时延。随后,在万物互联的背景下,边缘数据迎来了爆发性增长,为了解决面向数据传输、计算和存储过程中的计算负载以及数据传输带宽等问题,研究者开始探索在生产者的边缘增加数据处理功能,即万物互联服务的功能上行,具有代表性的是计算设备端处理即移动边缘计算。
边缘计算能够解决网络拥塞、服务器计算压力大以及数据安全性等问题,然而对于卷积网络算法,受限于边缘计算硬件设备性能限制,网络模型的大小以及计算要求也必须做出相应的优化,以适应边缘计算设备使用。于是各种压缩卷积网络模型算法,如剪枝、结构化卷积核等算法被提出,用来降低模型对资源的消耗。
在谷歌学术上以“边缘计算”为关键词搜索到论文数量趋势如图1所示。2015年以前,边缘计算处于技术发展累计阶段;2015—2017年,边缘计算开始快速发展,文章数量增长了10倍之多。直到2018年,边缘计算开始稳健发展。
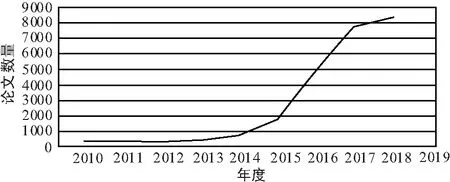
图1 谷歌学术上以“边缘计算”为关键词搜索到论文数量
1.2 深度学习下CNN发展历程
第一个神经网络是LeNet网络[1],它于1998年被提出,用于进行手写数字识别任务。它确定了卷积网络的构成,即由卷积层、池化层以及全连接层组成。由于传统算法不需要大量的计算量也能达到相同的效果或者更好的效果,使得它的出现并没引起太多关注。随着计算机硬件性能不断提高,2012年AlexNet[5]网络以绝对优势一举夺冠,自此CNN引起了广泛关注,呈现出越来越多关于CNN的研究成果。AlexNet由5个卷积层以及3个全连接层组成。其中提出的局部响应归一化层(LRN),用于对数据进行归一化,解决特征图二维平面内点之间的联系,以提升训练速度。一年后,VGG网络[6]被提出,它提供了一种新的思路,即:随着网络层的深度增加,效果也会随之增加。此后的网络设计中通过不断堆叠的卷积层,使得网络层的深度也不断增加,算法效果不断提高。VGG提出的第2年,GoogleNet[7]获得了比赛冠军,其不仅增加了深度,还通过结构化网络设计增加数据的重利用来提高效果。GoogleNet提出的如图2 inception模块所示结构,通过使用1x1,3x3,5x5卷积核以及3x3最大池化层过滤特征图获得结果,并合并结果作为提取到的特征图。为了降低计算量,使用了1x1卷积核提前过滤,获得通道维度较少的特征图,然后通过卷积核进行卷积操作, 维度减少的inception模块如图3所示。

图2 inception 模块
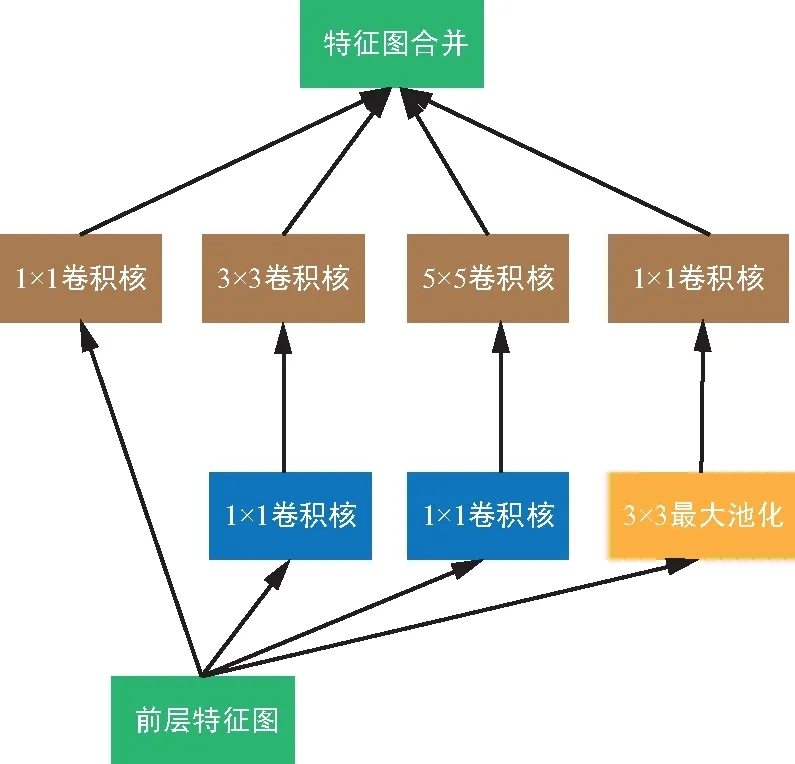
图3 维度减少的inception 模块
inception这种方式提高了参数的利用率,使得网络能够提取各种不同维度形状特征来提高识别效果。随后的网络设计也越来越深,由于每次卷积后都会通过激活函数进行激活,对数据进行筛选,这种做法能够强化卷积网络的线性表达能力。但随着卷积网路的深度增加,被过滤掉的特征也随之增加,网络也将退化,梯度也随之消失,不容易训练。为解决这个问题,ResNet[8]引入残差网络单元,如图4所示。将未被卷积的特征属性与经过卷积后的特征属性进行特征融合,并重新加以利用,使得识别效果显著增加。随着残差单元的提出,借鉴了参数重利用的网络算法不断被提出,网络性能得到一定提升,识别效果也进一步增强。一种全新的结构DenseNet[9]网络借鉴了残差单元思路,设计了一个结构简单全新的网络,性能及效果突破了Resnet的各种指标。Densenet相对于Resnet更加强调特征的复用,几乎将所有的浅层特征图作为输入进行卷积操作,极大减少了参数量,通过密集的连接缓解了梯度消失的问题。它频繁将不同深度特征通过通道合并,当前特征图融合了几乎所有前层的特征图,几乎所有层相当于直接连接输入和损失函数,这样就能够减轻梯度消失问题。
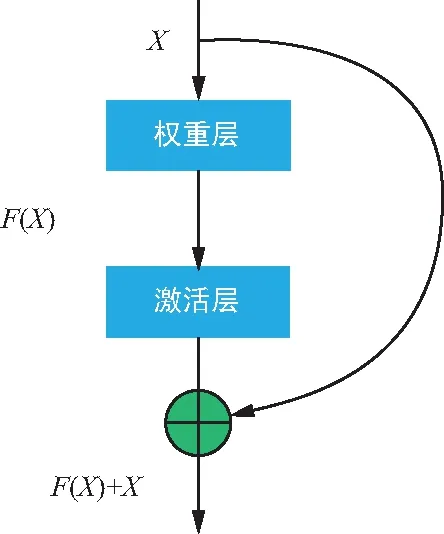
图4 残差网络单元
对上述卷积网络进行特征提取后,便可以将提取到的特征图应用到各种图像算法中,比如目标检测、目标跟踪、关键点定位、生成对抗网络等。
2 目标检测识别算法
2.1 MTCNN算法
MTCNN算法[9]既可以用于人脸检测,也可以用于其他目标检测算法中。图5 为MTCNN人脸检测算法,它首先通过图像金字塔将输入图像变为不同尺度的图片,然后送入P-Net网络获取人脸预测框预测,再将P-Net预测得到的人脸框送入R-Net及O-Net进行多次判断预测,之后再通过极大值抑制算法删减多余的预测框。训练时通过预测交叉熵损失函数训练人脸/非人脸:
(1)
人脸框回归以及关键点定位损失函数都使用L2范式:
(2)
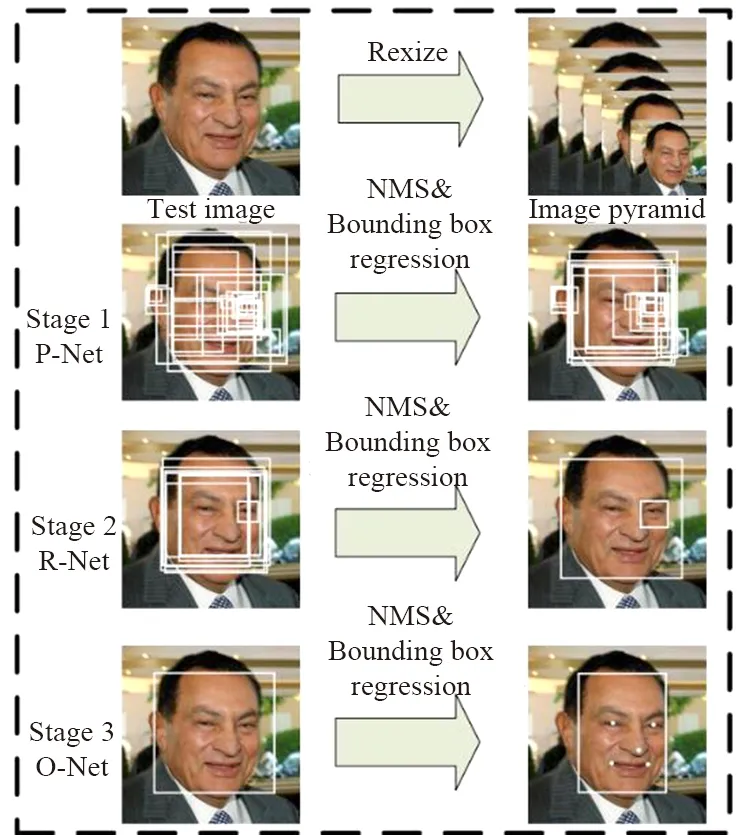
图5 MTCNN人脸检测
2.2 Faster R-CNN目标检测算法
Faster R-CNN算法[10]由目标检测算法R-CNN[11]发展而来。在ImageNet目标检测比赛中,R-CNN最先将卷积网络运用于目标识别,以压倒性优势战胜了传统目标检测算法。R-CNN具体做法是:通过提取图像ROI区域生成ROI区域组,再将区域分别送入CNN进行特征提取,并将提取到的特征送入SVM分类器判别是否属于该类别,并使用回归预测修正候选框的位置。
R-CNN经过一系列发展,演化出了性能和效果双优的Faster R-CNN目标检测算法。Faster R-CNN检测过程如图6所示[10]。
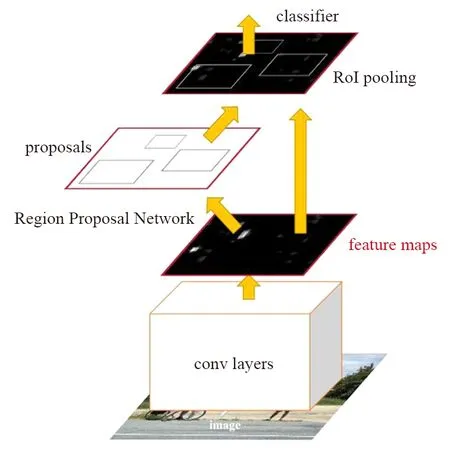
图6 Faster R-CNN检测过程
通过卷积网络进行图片的特征提取,获取图片的特征属性图,并通过Proposal层类似于区域候选网络(Region Proposal Network,RPN)获取候选anchor。Faster R-CNN anchor提取如图7[10]所示。Faster R-CNN通过特征属性图滑动窗口上的anchor获取不同形状候选框,每个候选框对应特征图上一点,然后通过分类损失函数和回归损失函数进行联合训练。
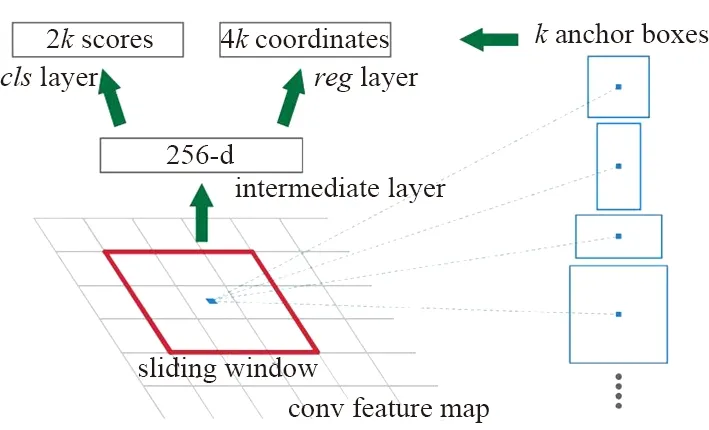
图7 Faster R-CNN anchor提取
联合训练损失函数如下:
(3)
(4)
(5)
(6)
(7)
Faster R-CNN的提出使得目标检测算法性能以及效果能够基本用于实际环境,检测的速度达到17 fps。
2.3 YOLO目标检测算法
YOLO[12]来源论文中的”You Only Look Once”,不同于R-CNN一系列网络将目标检测分为两类任务:通过RPN获取候选框完成候选框回归任务和分类任务。YOLO则是将两类任务合并成单任务进行。其基本过程为:① 将图片分为S*S个网格,对于物体中心点出现在某网格内部,则此网格负责检测该物体;② 每个网格生成B个检测框,若检测框包含物体,则认为此检测框需要预测出此物体,并且还需负责框的回归任务。训练损失函数同Faster R-CNN类似。相对于Faster R-CNN,YOLO算法性能高,但缺陷也比较明显,例如每当一个格子最多预测一个物体目标,且当出现不常见的长宽比时,YOLO网络的泛化能力就会降低。
2.4 SSD目标检测算法
SSD[13]算法作为三大目标检测算法之一,拥有Faster R-CNN的高精确度以及YOLO的高性能。
SSD算法和YOLO算法架构如图8所示,同Faster R-CNN和YOLO相比,它增加了多尺度特征属性图,而且用浅层网络检测小目标、用深层网络检测大目标,同时利用Faster R-CNN的anchor思想选取不同大小形状的anchor框,增加对不同大小形状物体的鲁棒性。框回归损失函数以及分类损失函数与Faster R-CNN一样。
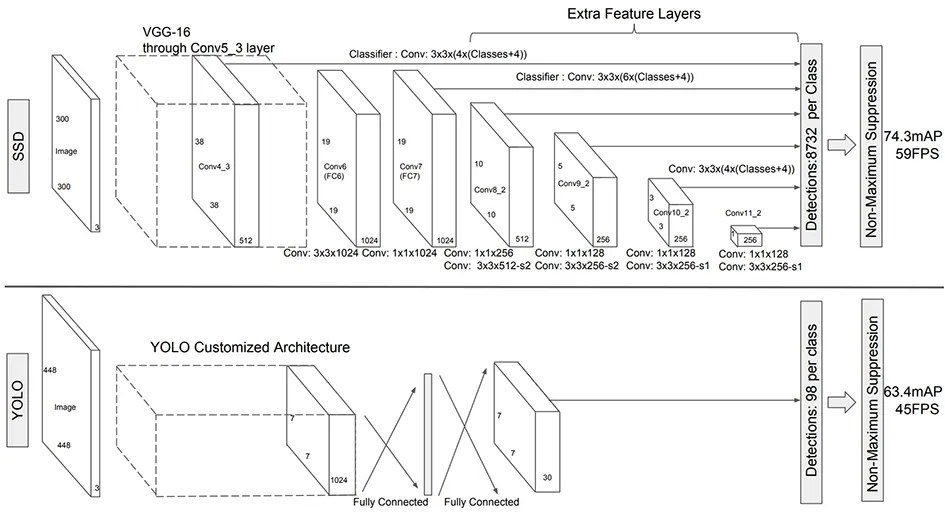
图8 SSD算法以及YOLO算法架构
2.5 其他目标检测算法
其他使用卷积网络进行目标检测的算法都是依据上述3种算法改进而来,例如以Faster R-CNN为代表的two stage和以SSD为代表的one stage方法。相比较而言,two stage有更高的精确度,one stage有更快的速度。取得阶段性进展的有R-FCN,FPN,RetinaNet[14],Mask R-CNN,YOLO v3,RefineDet[15],M2Det[16]。主要介绍其中典型的3个算法:RetinaNet,RefineDet,M2Det。
造成one stage 和two stage效果区别的因素是什么呢?主要原因便是对anchor的处理方式。Two stage对anchor进行了筛选及微调,然后送进分类与回归器中,而one stage直接将anchor送入分类器与回归器中训练,这种方式导致了anchor类别中的负样本过多,使得训练样本不均衡。为解决这个问题,RetinaNet将原来的Focal Loss替换了原来的交叉熵误差。Focal Loss的公式为:
FL(pt)=-αt(1-pt)γlg (pt),
(8)
可以看出,当某类别的数量越大,贡献的Loss平均下来越小,反之则平均贡献的Loss越大,这种做法降低了样本数量对训练损失的影响,使得量少类别对训练的贡献值提高。
RefineDet由2个内部连接模块组成,分别为:ARM(Anchor Refinement Module)和ODM(Object Detection Module)。ARM网络和Faster R-CNN中的RPN网络类似,进行预预测,ODM如SSD中的anchor处理,使其具有二者的共同优点。
M2Det使用了主干网络+MLFPN来提取图像特征,采用类似SSD的方式获取预测框以及类别,最后通过NMS得到最后的检测结果。
其中,最关键的是进行图像特征提取的结构MLFPN,其主要由3个部分组成:
① 特征融合模块FFM;
② 细化U型模块TUM;
③ 尺度特征聚合模块SFAM。
由图9 的M2Det网络可以看出,FFMPv1对主干网络提取到的浅层特征和深层特征进行融合,FFMv2通过融合不同深度特征图,最终的SFAM通过拼接聚合不同类型的属性图,最终将包含广泛信息的特征图送入类似于SSD网络中进行目标检测以及分类。
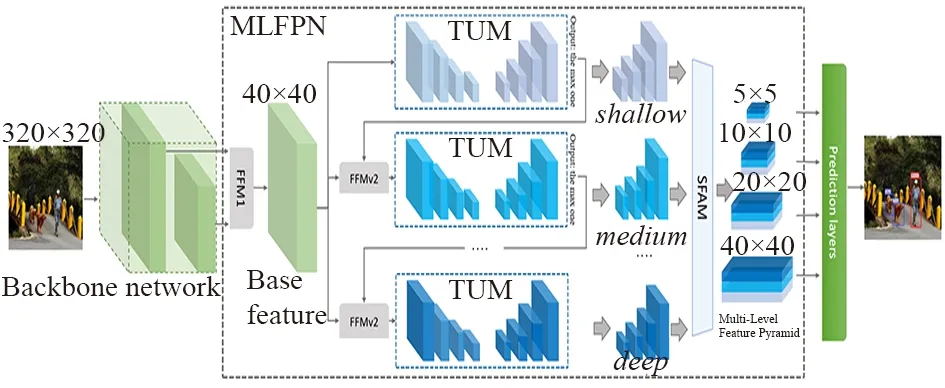
图9 M2Det网络
2.6 识别算法介绍
如图10所示,利用卷积网络进行识别可分为2个步骤:利用卷积网络进行图像特征提取,然后利用softmax进行分类。
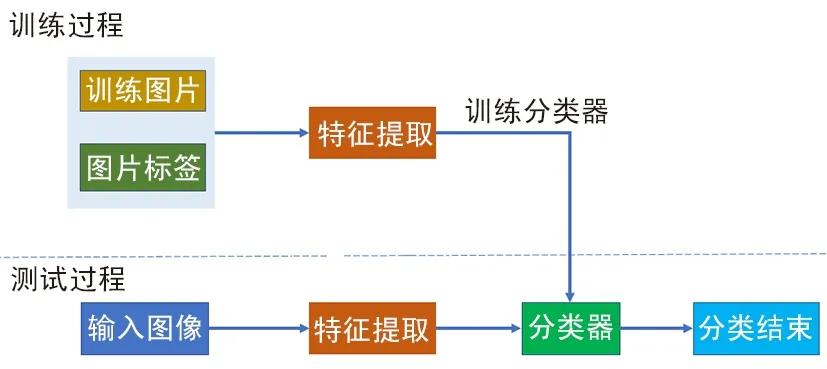
图10 识别过程
常见的识别算法主要是特定场景下的识别,例如车牌识别和人脸识别。效果比较好的开源车牌识别算法,例如Openvino框架下的LPRNet[17]通过卷积网络进行特征提取,并使用CTC LOSS损失函数训练,算法正确率能够达到95%左右。人脸识别一般通过卷积网络进行特征提取,再通过比较欧氏距离或者矩阵余弦距离进行人脸识别,有名的例如以mxnet框架写的开源的insightface。
3 算法优化
边缘计算中首先需要对卷积网络模型进行优化,以满足卷积网络运行于特定设备上具有的实时性。卷积网络模型优化主要有5种方式:① 卷积核优化;② 参数修剪和共享;③ 知识蒸馏算法;④ 低秩因子分解;⑤ 轻量级网络模型设计。
3.1 卷积核计算性能优化
卷积核优化算法中较新也较好的方式是shuffleNet[14]网络中卷积核所使用的方式。为减少计算量,最直观的方式是直接减少卷积层的计算量。常规卷积的卷积核通道数和输入特征图的通道数一致。如图11所示,MobileNets深度可分离卷积操作为最经典MobileNets[19]的核优化方式,具体做法是将卷积分为深度卷积和逐点卷积,通过基于深度可分离卷积,将典型的卷积操作图11(a)分解成深度卷积图11 (b)和逐点卷积图11 (c)。假设经典的卷积维度Dk*Dk*M,Dk为卷积核平面维度,M为输入特征属性通道数,N为输出特征维度通道数。深度可分离卷积首先通过卷积核为Dk*Dk*1对特征图平面特征方向过滤,如图11(b)所示。再通过卷积核1*1*M对特征图的通道方向进行过滤,如图11(b)所示。二者可以认为是分别对平面维度和通道维度进行降维。
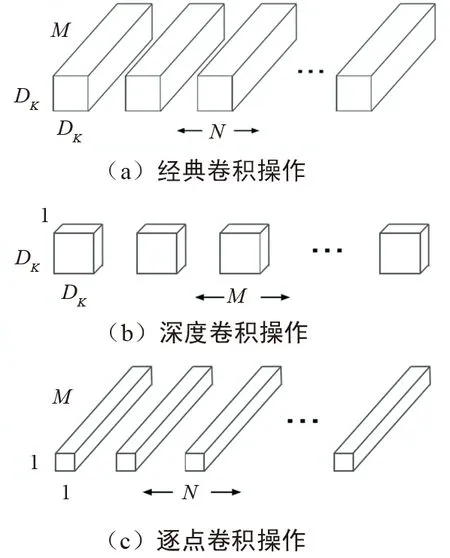
图11 移动网络深度可分离卷积操作
由于通道间信息不连通,这种方式会使通道间充满约束。为了解决这种问题,Face++团队提出了shuffleNet网络。与MobileNet一样,shuffle利用群卷积和深度可分卷积思想,优化了核卷积用以解决通道之间的约束。如图12(a)组卷积所示,Shufflenet的方法将特征图通道分组进行卷积,增强了通道内部的信息联通。然而分组卷积仅解决了特征图组内信息的流通,组外信息并不能流通,降低了信息的表达能力。当然可以将卷积后的特征图在组内部切割,然后将切割后的部分按顺序排序,如图12(b)所示。而shuffle通过通道混洗操作使得数据的通道维度上进行无序打乱,用以增加信息的表达能力,提升识别效果,如图12(c)所示。 组卷积通道混洗如图13所示,在Shufflenet经典模块图13(b)中,特征图首先通过组点卷积核操作,分组进行混洗操作,然后利用一般标准的组深度可分离卷积核进行过滤,将过滤后特征图再通过组点卷积过滤。一般而言这种方式虽然能够过滤掉没用的信息,但同时也会过滤掉有用的信息。通过与输入数据加和,以防止有用信息被过滤掉。
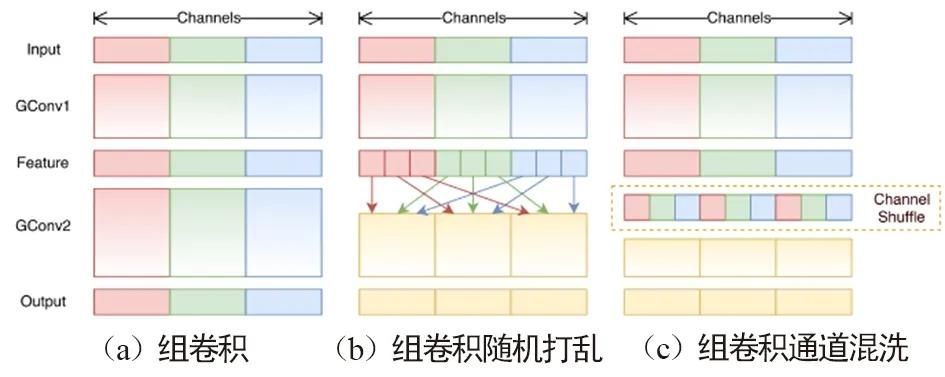
图12 shuffle通道维度上的组卷积操作
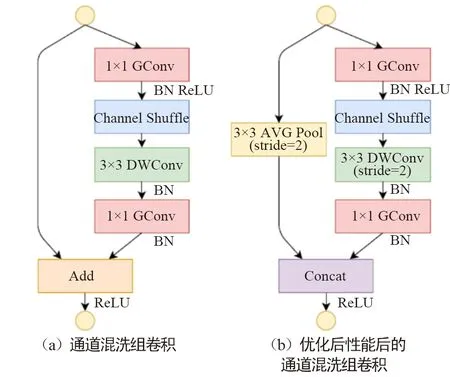
图13 混洗模块
为减少计算量,通过将组深度可分离卷积的滑动间隔stride由1修改成图13(b)中的2,再利用平均赤化层下采样输入特征属性,最终通过将得到的特征图进行通道级联,取代图13(a)混洗模块的特征图求和。虽然通道级联增加了通道的维度,但由于下采样减少了平面维度,导致计算成本并未增加很多。通过实验发现,此方式能够显著降低网络所需的计算性能,而网络的效果并没有显著降低。第二代ShuffleNet v2[20]网络指出了以往架构过于注重FLOPs的不足,提出了2个基本原则和4项准则指导网络架构设计,无论在速度还是精确度上,都超过以往通过压缩卷积核计算要求的算法。
3.2 剪枝和参数共享
参数共享在卷积网络上用于降低计算量和减少参数,最开始的剪枝应用便是dropout,它通过随机剪枝防止过拟合并加速训练,当然也可以用来降低参数量。
早期的剪枝方式通过权重的重要性剪枝方法进行分结构化剪枝[21],删除不重要的权重参数重新进行训练,直到达到满意的模型大小,并且模型效果没发生显著改变。随后提出的基于偏差权重衰减的最优脑损伤和最优脑手术方法,是通过减少损失函数的海森矩阵来减少连接数量。研究表明剪枝方式的精确度比重要性剪枝方式好。然而此方式的剪枝并不能应用于实际卷积网络层上,因为此类方法导致剪枝后的权值矩阵是无规则稀疏的,其仅仅将剪枝后的权重设置成0,输入和0相乘消耗计算量,因此实际加速效果较低。只有剪掉的枝叶从搭建的网络中消失,才算完成剪枝。通过结构化剪枝可以使剪枝后的模型运行于实际场景中。与非结构化剪枝不同的是,结构化剪枝设置了一系列的剪枝约束条件。根据细粒度的程度,结构化剪枝可以分为向量机剪枝、核级剪枝、组级剪枝和通道级剪枝4种类型。结构化剪枝能够直接降低模型的计算FLOPS。
3.3 知识蒸馏
正如Hinto提出来的一个例子[22],幼小的昆虫擅长从环境中汲取能量,而成年后则擅长迁徙繁殖等方面。与这个例子相同的是,在训练阶段,神经网络能够从大量数据中训练模型网络;使用阶段,则能够应用于更加严格的包括计算资源及计算速度的限制。一般首先在大数据集上训练一个复杂网络模型,一旦网络模型训练完成,便可以通过“蒸馏”方式,从大型模型中将所需要的应用模型提取出来。知识蒸馏中,软目标是通过复杂模型预测得到的概率分布,硬目标则是真实样本的概率。参考复杂模型的结构、深度等信息重新设计一个小模型,再将小模型的预测值分别与软目标和硬目标做交叉熵的损失,并将两部分损失进行联合训练。软目标与硬目标的综合训练损失所占的比重不断地由9:1通过迭代训练慢慢变成1:0。对于卷积网络,一般通过类别的shot-hot码进行训练,相当于使用硬目标进行训练。总而言之,将复杂模型预测得到的数据作为小模型的样本标签,对网络加以训练,以增加网络的泛化能力。
3.4 权值张量低秩分解
卷积网络核的参数权重W可以看作一个四维张量,他们分别对应卷积核的长、宽、通道数以及输出通道数。通过合并某些维度,四维张量能够转变成更小维度的张量。基于权值张量低秩分解方法,其实质是找到与张量W近似、但计算量更小的张量。现阶段已经有很多低秩分解算法被提出,例如优必选悉尼AI研究院入选CVPR的基于低秩稀疏分解的深度压缩模型。
3.5 轻量级网络模型设计
在卷积网络模型中,合并网络层不改变网络输出是重要模型的优化方式。例如,BatchNorm层(简称BN层)在深度学习中归一化网络模型加速训练,放置于卷积层或全连接层之后。测试时,通过将BN层合并到卷积层或全连接层中以减少计算量。
假设BN层输入数据为X,则BN层处理数据获得输出为:
(9)
卷积操作的权重为w,偏置为b,假设卷积网络输入为X,卷积网络的输出为Yconv,则卷积网络操作为:
Yconv=WX+b。
(10)
由式(9)和式(10)可知,通过卷积、池化操作后结果为:
(11)
因此卷积层更新后的权重W*以及偏置b*可以得出:
(12)
(13)
4 边缘计算硬件发展历程
对于边缘计算,成本及性能是重要的考量因素。一直以来,并行计算两大厂商之一的英伟达非常重视并行计算在数学上的应用,不但开发出了CUDA库用于并行计算,还开发出了CUDNN库等各种矩阵运算库用以优化运算性能,仅需要学会简单的C++便能方便地调用显卡加速运算。各种深度学习框架如Caffe,Tensorflow等对nvidia的cuda支持,使其移植到嵌入式设备的成本极低,这些因素都使得英伟达旗下显卡占有重要的市场Nvidia硬件对比如表1所示,给出了嵌入式产品端的主要参数。理论上核心越多,并行计算能力越强,从表1中可以看出,Tx1的并行计算能力是Nano的2倍,而使用新架构Pascal的Tx2性能是Tx1的2倍,另一款产品Jetson Xavier则能够提供超过Jetson Tx2的20倍以上性能,但昂贵的价格使不能被大规模部署。
表1 Nvidia硬件对比
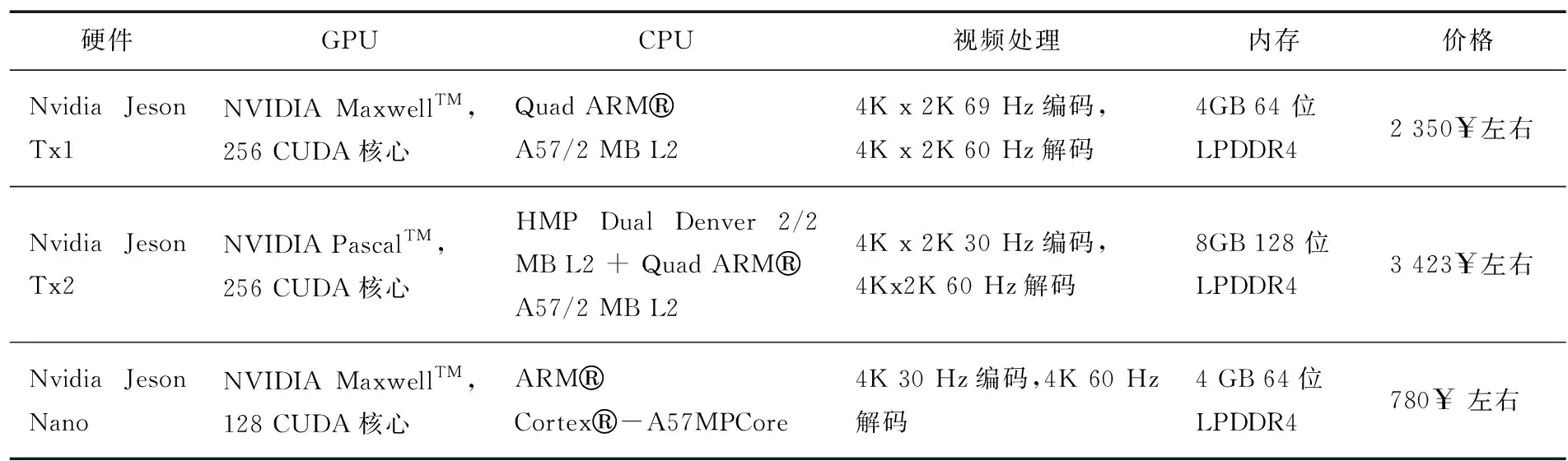
硬件GPUCPU视频处理内存价格Nvidia Jeson Tx1NVIDIA MaxwellTM,256 CUDA核心Quad ARMA57/2 MB L24K x 2K 69 Hz编码,4K x 2K 60 Hz解码4GB 64 位LPDDR42 350$左右Nvidia Jeson Tx2NVIDIA PascalTM,256 CUDA核心HMP Dual Denver 2/2 MB L2 + Quad ARMA57/2 MB L24K x 2K 30 Hz编码,4Kx2K 60 Hz解码8GB 128 位LPDDR43 423$左右Nvidia Jeson NanoNVIDIA MaxwellTM,128 CUDA核心ARMCortex-A57MPCore4K 30 Hz编码,4K 60 Hz解码4 GB 64位LPDDR4780$ 左右
英特尔也于2016年收购了一家硅谷公司Movdius,该公司主要为各种消费设备设计神经网络加速芯片,其开发产品中的神经网络计算棒使用的是Movidius芯片,可以通过openvino调用Movidius芯片进行加速计算,但其安装包目前为止支持树莓派的armv7架构以及x86架构。在收购另一家公司Nervana后,英特尔将很快推出专为人工智能打造的系列处理器—英特尔神经网络处理器(以前称为“Lake Crest”)。
AI视觉套件角蜂鸟是基于英特尔神经网络的Movidiu芯片开发的,它多提供一个摄像头。研扬科技开发的UP系列单板,可以看作是一个能够运行x86架构桌面平台的嵌入式产品,它只有信用卡大小,能够支持神经网络计算棒以及研扬和英特尔联合推出的AI Core作为并行加速计算扩展,虽然UP单板有x86平台的高性能优点,但其价格也比较昂贵。
谷歌作为深度学习领域一个重要的公司,不仅维护深度学习开源框架(Tensorow),还推出了硬件加速平台 Edge TPU,其设计目标就是简单流畅运行TensorFlow Lite。处理器使用的 Cortex-A53/Cortex M4F,GPU为GC7000Lite,内置了Google Edge TPU加速Tensorow运算。另一款专为树莓派设计的AIY Edge TPU Accelerator 则仅需利用USB-C/USB-B与Linux系统连接,即可加速tensorflow-lite运算。此外,华为的HiKey 970,可提供强大AI算力,支持硬件加速,性能强劲。寒武纪的Cambricon-1A,Cambricon-1H8,Cambricon-1H16系列可广泛应用于计算机视觉、语音识别及自然语言处理等智能处理关键领域。
其他推出的比较小众的产品,例如LightspeeurTM光矛系列是全球首款可同时支持图像和视频、语音与自然语言处理的智能神经网络专用处理器芯片方案,相比边缘计算硬件市场上其他解决方案,能够高出几个数量级。例如其产品LaceliTM人工智能计算棒可以在1 W功率下提供超过9.3万亿次/s的浮点运算性能,而Movidius每瓦功率范围运算能力则是0.1万亿次。恩智浦BlueBox是一款开发平台,可为开发自动驾驶汽车的工程师提供必要性能、功能安全和可靠性平台,并且配备雷达、激光探测与检测(LIDAR)等自动驾驶必须的模块。中星微的“星光智能一号”是中国首款嵌入式神经网络处理器(NPU)芯片。Deepwave公司推出的AIR-T(Artificial Intelligence Radio Transceiver)具有嵌入式高性能计算功能。深鉴科技于2018年上市的“听涛系列列SoC”,只需1.1 W功耗,却能达到4.1TOPs峰值性能。性价比是小众平台产品的最佳优势。
5 结束语
Faster R-CNN,SSD,YOLO等目标检测算法优缺点分明,通过研究其原理,发现设计网络模型及损失函数是提升AI性能和效果的重要方式。然而,高昂的计算代价会阻碍AI算法在边缘计算硬件上的部署,因此模型优化精简和移植将是AI商业化的必经之路。随着硅芯片的发展使得AI算法部署成为可能,边缘计算将解决人工智能的最后一公里,构建万物感知、万物互联、万物智能的崭新世界。
猜你喜欢
保健医苑(2022年5期)2022-06-10
北京航空航天大学学报(2021年9期)2021-11-02
成都信息工程大学学报(2021年6期)2021-02-12
计算机应用(2020年5期)2020-06-07
电子制作(2019年13期)2020-01-14
电子制作(2019年11期)2019-07-04
北京航空航天大学学报(2018年1期)2018-04-20
天津诗人(2017年2期)2017-03-16
通信产业报(2016年44期)2017-03-13
雕塑(1999年2期)1999-06-28
