
分布式存储系统中容错技术综述
2019-08-30 03:31刘景伟
无线电通信技术 2019年5期
李 鑫,孙 蓉,2*,刘景伟
(1.西安电子科技大学 综合业务网理论及关键技术国家重点实验室,陕西 西安 710071;2.华侨大学 厦门市移动多媒体通信重点实验室,福建 厦门 361021)
0 引言
在当前云计算时代,全球流量快速增长,互联网、物联网、移动终端、安全监控和金融等领域的数据量呈现出“井喷式”增长态势。存储在云服务器中数据的增长速率甚至超越了摩尔法则,云存储系统成为云计算的关键组成部分之一。数据的飞速增长对存储系统的性能和扩展性提出了更苛刻的挑战。传统的存储系统采用集中式的方法存储数据,使得数据的安全性和可靠性均不能保证,不能满足大数据应用的需求。分布式存储系统以其巨大的存储潜力、高可靠性和易扩展性等优点成为大数据存储的关键系统并被推广应用到降低存储负荷、疏通网络拥塞等业务领域上,且其以高吞吐量和高可用性成为云存储中的主要系统。目前Hadoop分布式文件系统(Hadoop Distributed File System,HDFS)作为谷歌文件管理系统(GFS)[1]的开源实现已成为最主流的分布式系统,它被应用于许多大型企业,如Facebook,Yahoo,eBay,Amazon等。
为了应对海量数据的存储需求,该类存储系统的规模往往非常庞大,一般包含几千到几万个存储节点不等。早在2014年,中国互联网百度公司单个集群的节点数量就超过了10 000[2]。近两年,腾讯云的分布式调度系统VStation管理和调度单集群的节点数量可达100 000。然而数量庞大的节点集群经常会产生如电源损坏、系统维修及网络中断等故障致使节点失效频发。据一些大型分布式存储系统的统计数据表明,平均每天都会有2% 左右的节点发生故障[3]。在过去一年中,迅速发展的云计算市场不断涌出如谷歌云、亚马逊AWS、微软Azure及阿里云等主流云服务器大型宕机事件[4]。
由此可见,全球的云服务器发生故障导致数据丢失的情况时有发生。显然,能够可靠存储数据并有效修复失效数据的容错技术对分布式存储系统的重要性不言而喻。因此如何及时有效地修复失效节点,确保数据能被正常地读取和下载就显得非常重要。据统计,在一个有3 000个节点的Facebook集群中,每天通常至少会触发20次节点修复机制。具有节点修复能力的数据容错技术是通过引入冗余的方式来保证分布式存储系统的可靠性,存储系统能够容忍一定数量的失效节点,即提高了系统的数据容错能力。
为了保证用户访问数据的可靠性、维持分布式存储系统的容错性,需要及时修复失效节点。良好的容错技术要求存储系统具有低的冗余开销、低的节点修复带宽、低的编译码复杂度等特点。如何降低失效节点的修复带宽、降低磁盘I/O、降低存储系统编译码的复杂度、提高系统的存储效率成为分布式存储中研究的热门方向,因此,能够有效弥补多副本机制和MDS码不足的分布式存储编码应运而生。
1 传统的存储容错
传统最常见也是最早的存储容错是多副本机制和MDS码。通常,多副本机制引入冗余简单,但其存储负载很大,存储效率非常低,如Google文件系统和Hadoop文件系统等。传统的最大距离可分(Maximum Distance Separable,MDS)码结构可以实现分布式存储编码,比如里德-所罗门(Reed-Solomon,RS)码,以及Google Colossus,HDFS Raid,Microsoft Azure,Ocean Store等。其存储成本更低,但是其拥有更高的修复成本和访问延迟,而且没有考虑存储开销、磁盘I/O开销等,因此并不适合用于大规模分布式存储系统。
1.1 多副本机制
多副本机制是产生冗余最基本的方式。为了弥补数据失效带来的损失,确保存储系统中数据的完整性,将数据的副本存储在多个磁盘中,只要有一个副本可用,就可以容忍数据丢失。如图1所示。如果数据以最常见的3副本方式存储,那么原始数据会被复制到3个磁盘上,因此任何1个磁盘故障都可以通过剩余2个磁盘中任意1个来修复。显然,该3副本机制有效的存储空间理论上不超过总存储空间的1/3,多副本机制显著降低了存储效率。
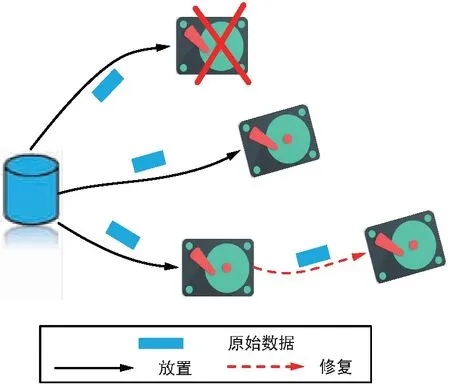
图1 3副本机制
1.2 MDS码
如果系统编码设计的目标是在不牺牲磁盘故障容忍度的前提下最大化存储效率,那么存储系统采用MDS码来储存数据,因为它可以为相同的存储开销提供更高的可靠性。也就是说MDS码是一种能提供最优储存与可靠性权衡的纠删码。在一个分布式存储方案中,原始文件首先被分成k个数据块,接着它们编码生成n个编码块并存储在n个节点中。访问任意l(l≥k)个节点,通过纠删码的译码就可恢复出原始文件,如果l=k,该码就满足MDS性质,最多能够容忍(n-k)个节点的失效。如图2所示,原始文件被MDS码编码生成5个数据块并放置到5个磁盘中。任意某个磁盘损坏,都能通过访问其他4个幸存磁盘中的3个来修复。
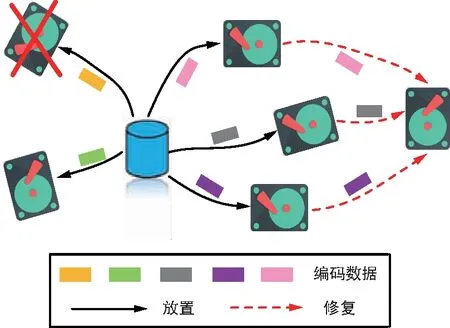
图2 (5,3)MDS码修复失效磁盘
MDS码的3个主要缺点阻碍了它在分布式存储系统中的推广。首先,为了读取或写入数据,系统需要对数据进行编译码,由于CPU限制会导致高延迟和低吞吐量。根据调研,即使Facebook存储系统的集群中用MDS码只编码一半数据,修复流量也会使集群中的网络链路接近饱和。其次,MDS码修复失效节点时必须访问多个编码块,而访问的这些编码块足以得到所有的原始数据,这样的修复代价也太大了。最后,托管在云存储中的应用程序对磁盘I/O性能很敏感,且由于大多数数据中心引入链路超额配置;因此带宽始终是数据中心内的有限资源,使得MDS码的节点修复在带宽开销和磁盘I/O开销方面都非常昂贵。
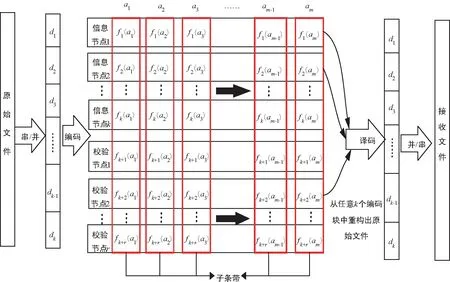
图3 采用MDS编码的分布式储存模型
2 分布式存储编码及性能比较
为了降低修复故障节点的带宽开销,有几种分布式存储编码,即再生码[6](Regenerating Codes,RGC)、局部可修复码[7](Locally Repairable Codes,LRC)和MDS阵列码等被提出来,它们都有各自的优缺点。如RGC和LRC的修复带宽较小,但由于它们在修复过程中有大量的矩阵运算,计算复杂度很高,因此构造过程非常复杂;Piggybacking编码的研究还处在起步阶段,有很多理论和实际应用还不太完善;MDS阵列码如EVENODD,B-code,X-code,RDP,STAR,Zigzag码等,它们的编译码过程基本都是构建在低阶域的简单运算之上,复杂度低。但受限于阵列码的构造过程,它们所设计的冗余节点很少,导致其容错能力有限,修复能力一般都比较弱,修复效率较低。目前,在容错技术中存储和修复性能更胜一筹的分布式存储编码主要有 3类:① 注重存储与修复开销平衡的RGC;② 面向优化磁盘I/O开销的LRC,③ 不改变系统节点分布结构的Piggybacking编码。
2.1 RGC
为了降低MDS码的节点修复带宽,Dimakis等人受网络编码的启发将编码数据的修复建模为信息流图,从而提出了再生码,其约束条件是维持容忍磁盘故障的能力[6]。基于此模型来表征存储与带宽之间的最优权衡,即给定磁盘上存储的数据量大小,可以得到修复过程中需要传输数据量的最优下界。
2.1.1 RGC原理
在信息流图中,所有的服务器可以分为源节点、存储节点和数据收集器,其中源节点表示数据对象产生的服务器。图4为RGC信息流图。
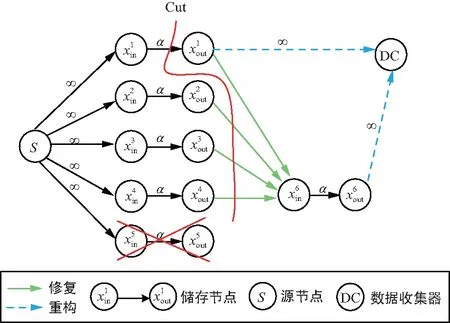
图4 RGC信息流图
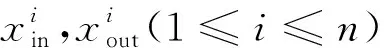
MDS码节点的数据恢复是要新生节点接收来自服务器(数据提供者)的k个数据块后,在新生节点上进行编码产生节点新数据。但再生码是在数据提供者和新节点上都能进行编码,即数据提供者(存储节点)有不止一个编码段。当需要修复节点时,提供者先发送自己编码段的线性组合,新节点将接收到的编码段再次编码重构新的节点。如图5所示,假定任意2个磁盘都足以恢复原始数据的MDS码,即k=2,每个磁盘存储一个包含2个编码段的编码块。对MDS码而言,恢复故障磁盘至少需要给新磁盘发送2个编码块(4个编码段)。但数据经提供者编码后再发送给新磁盘的数据量可减少至1.5个编码块(3个编码段),这样就能减小数据的传输量,降低25%的带宽消耗。
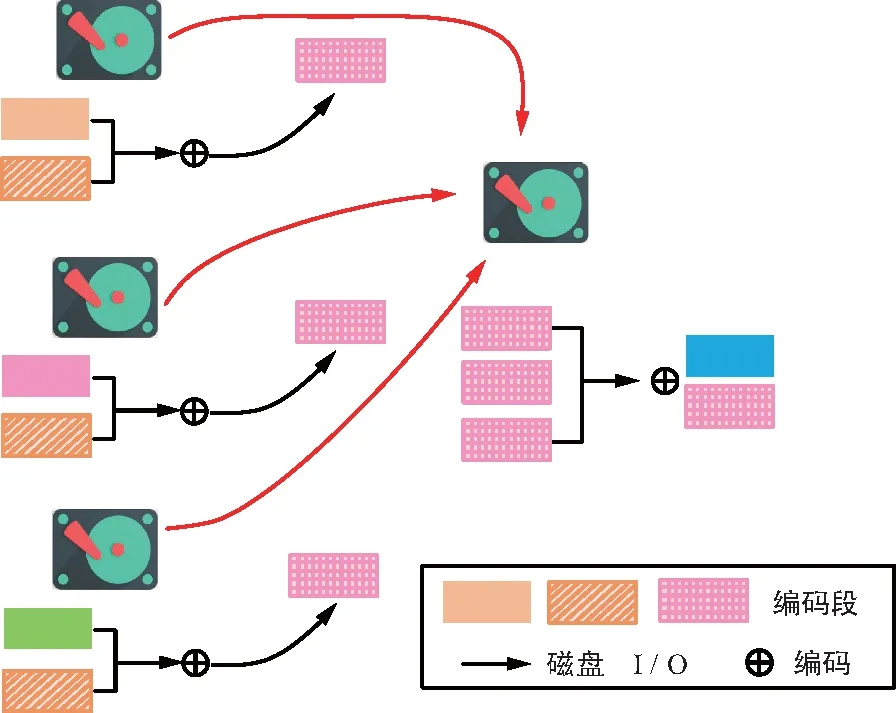
图5 RGC基本原理图
Dimakis等人利用信息流图计算最小割界得到失效节点修复带宽的下限曲线,再生码就是在存储开销α和修复带宽γ的最优曲线上。该曲线上存在最小存储和最小修复带宽这2个极值点。达到存储最小的极值点的编码称为最小存储再生码(Minimum Storage Regenerating Codes,MSR)[7],达到修复带宽最小极值点的编码称为最小带宽再生码(Minimum Bandwidth Regenerating Codes,MBR)[8]。
MSR的节点存储大小和节点修复带宽可以表示为:
MDS码的存储开销最小,而MSR码节点的储存开销就等于传统MDS码的节点大小,因此可以被当做MDS码。当d=n-1时,则上式变为:
当n趋于无穷大时,其修复带宽等于一个编码块大小,但MDS码的修复带宽为k倍的编码块大小,因此MSR码节省很大的修复带宽。
MBR的节点存储大小和节点修复开销可以表示为:
当d=n-1时,则上式变为:
从上式可以看出,MBR码的节点存储大小和修复开销一致,存储和修复带宽大小比一个编码块稍微大些,因此其修复带宽非常小。
2.1.2 RGC发展现状
分布式存储网络中一个重要的性能指标是它的安全性。RGC除了数据存储容错外,还可以应用在信息安全上。它是一种用于提供数据可靠性和可用性的分布式存储网络编码,能实现高效的节点修复和信息安全[9]。其中窃听者可能获得存储节点的数据,也可能访问在修复某些节点期间下载的数据(如果窃听者发现添加到系统中的新节点替换了失效的节点,那么它就可以访问修复期间下载的所有数据,这严重威胁了数据的安全和隐私)。在这种不利环境下,Dimakis提出了RGC的准确构造从而实现了信息保密,即在不向任何窃听者透露任何信息的情况下,可以安全存储并向合法用户提供最大的数据量,同时得到了一般分布式存储系统保密容量的上限,并证明了这个界对于带宽受限的系统来说是紧密的,这在点对点分布式存储系统中是有用的[10]。考虑用分散数据保护一个分布式存储系统的问题,研究了节点间交互在减少总带宽方面的作用[11]。当节点相互独立,交互是没有用的,并且总是存在一个最优的非交互方案。除此之外,RGC在信息安全保密方面也有研究[12]。
RGC按照故障节点的修复特点可分为功能性修复和准确性修复。功能性修复是指恢复新节点后使系统仍具有MDS性,以维持对故障节点的容忍度,一般的再生码都是功能性修复。准确性修复是指新生节点中的数据与被修复失效节点中的数据相同。因此在前期研究基础上出现了准确RGC的概念,当节点失效后能进行准确修复,这意味着系统形式的编码结构可以结合准确重构节点来实现与多副本机制一样低的访问延迟。常用的方法是干扰对齐技术,把不需要的向量对齐到相同的线性子空间以达到消除的目的[13]。
目前大多数关于RGC的研究都集中在单一节点的恢复上,但是在大型分布式存储系统中同时看到2个或更多的节点故障是很常见的。为了充分利用好修复多个故障节点的契机,一种协同修复机制应运而生,即修复节点之间可以相互共享数据。此类RGC被称为合作RGC[14],它的出现使得用更低的带宽来修复多个故障节点成为可能。
纵然RGC达到了存储与带宽开销之间的最优权衡,但因为其需要繁琐的数学参数和复杂的编码理论基础,实现过程很难。目前RGC大多在有限域GF(2q)上进行多项式运算。加法在计算机上处理较为简单,然而乘法和除法却相对复杂,更有甚者需要用到离散对数和查表才能处理。这使得RGC的编译码复杂度很高,因而很难满足分布式存储系统对计算复杂度的要求。RGC作为MDS码的改进版,拥有良好的理论基础,但是现有的绝大部分RGC编译码复杂度很高且码率低,所以迫切地提出高码率且编译码复杂度低的RGC,这具有积极的现实意义。若同时结合磁盘I/O、数据存储安全和网络结构等方面构造,能进一步推广RGC的应用范围。
2.2 LRC
与通过牺牲磁盘I/O开销来节省带宽消耗的RGC不同, LRC具有较少的磁盘访问数量。它是通过强制一个失效节点中的数据只能通过某些特定的存储节点来进行修复,从而减少需要读取和下载的数据量来降低修复带宽。虽然这种方式牺牲了对节点故障的容忍度(LRC的理论可译性:能够修复信息理论上可译的故障模式,即LRC不具有MDS性质),以牺牲少量存储开销为代价(增加了额外的局部校验块),但会显著降低磁盘I/O开销。众所周知,磁盘I/O开销越大,使用寿命就越短。因此LRC在数据容错技术中的地位不容小觑。
2.2.1 LRC的原理
常规的RGC修复故障节点时,都需要请求幸存节点将其数据的线性组合发送给新节点,即RGC仅仅针对存储与修复开销,而没能节省磁盘I/O。在修复故障节点过程中,RGC最终从幸存节点读取的数据量将远远多于写入新节点的数据量,过多的磁盘I/O操作会严重影响数据中心的总体磁盘I/O性能,使得磁盘I/O开销成为存储系统中故障节点恢复的一个主要性能瓶颈[15]。磁盘I/O开销与修复故障节点时访问的幸存节点数目(即局部修复度)成正比,因此访问的幸存节点数越少(局部修复度越小),磁盘I/O开销就越少。需要明确的是,写操作发生在新节点上,且写操作的数据量等于一个存储节点的大小。由于写操作作为重构新节点的最后一步是不可或缺的,因此在实际修复过程中更关心的是从幸存节点中读取的数据量。
MDS码修复一个节点要求读取k个编码块。从图5可以看到,RGC中数据提供者的编码操作不能减少读的数据量,只是减少了数据的传输量,因为发送编码后的数据是需要读取节点内整个编码块(所有编码段)之后再进行编码才生成的。因此,有2种方法可以降低磁盘I/O开销。第1种,从幸存节点中选取特定的编码段,而位于同一节点中的其他编码段因为没有参与编码就不用读取;第2种,选取少量的特定节点作为数据提供者而不是任意k个节点。特别是,LRC采用的是第2种方法。假定任意3个节点都足以得到原始数据的MDS码,即k=3。修复一个故障节点,MDS码和再生码需要读取6个编码段,而图6中却只需要读取2个特定的编码段,所以能降低磁盘I/O开销。
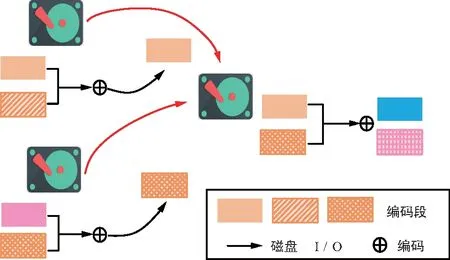
图6 访问特定编码段(或/和特定节点)来降低磁盘I/O开销
LRC之所以能通过选定特定节点来修复失效节点是因为它以额外的存储开销为代价,任意某个节点都可以通过某些特定的编码块进行修复,减少了修复过程中连接的节点数,也减少了磁盘I/O开销。虽然LRC具有较好的局部修复特性,但却无法拥有像MSR码和MBR码等那样较低的存储与修复开销。目前采用LRC编码的大型系统主要有Facebook的分布式文件系统HDFS和微软的Azure[11]。且Azure已广泛应用于微软内部的网络搜索、视频服务、音乐游戏及医疗管理等业务。LRC的实现方法主要包括分层编码(Hierarchical Codes,HC)和简单再生码(Simple Regenerating Codes,SRC)。HC是将原始文件进行编码(一般采用RS码)之后,进行二次编码得到额外的局部冗余校验块。当需要恢复一个失效节点时,通过访问该故障节点所在分组内的幸存节点和该组内编码产生的局部校验块即可,而并不需要像MDS码那样访问更多的幸存节点,因此HC可以降低故障节点的修复带宽和磁盘I/O操作。Papailiopoulos等人将可纠正多个错误的RS码与简单的异或运算结合,构造出一类LRC,即SRC[16]。该方案通过访问少量幸存节点来修复单节点故障,利用特定的放置规则降低了失效节点的修复带宽。
2.2.2 LRC 的发展现状
LRC除了有数据容错存储的应用外,国际上已经有学者开始尝试利用LRC解决分布式存储中的安全问题。2016年,Kumar等人为分布式存储设计了一种可修复喷泉码(Repairable Fountain Codes,RFC),在信息安全理论上提出了针对存储节点的窃听模型,应对通过失效节点的修复来窃取其他幸存节点数据的威胁[17]。Rawat等人通过平衡LRC的安全性和修复度,提出了安全性最佳的局部修复度结构的编码方案,可有效抵抗监听[18]。在2017年,Kadhe等人又通过内码和外码的联合设计,构造了一种广泛的安全存储码方案,同时考虑了MSR码和LRC这2种分布式存储编码。
目前,学术上针对单个节点失效LRC的研究主要集中在以下的构造方法中:
① 基于二元LDPC码的构造:2016年,Hao等人阐述了一类有着多修复组的LRC与二元LDPC码的关系,提出了用正则LDPC码去构造LRC的方法[19]。2017年,Su等人在上述工作基础上基于循环置换矩阵和仿射变换矩阵提出了2种二元LRC的构造方法,达到了距离限[20]。
② 基于联合信息可用性构造:2017年,Kim等人利用联合信息的可用性(任何可译码的纠删符号集可以从任何一组具有小基数的多个不相交符号集进行修复)提出了LRC的2个Alphabet-Dependent限[21]。
③ 基于图模型的构造:2017年,Kim等人还利用具有r个顶点和t个边的超图构造出了有着(r,t)可用性的二元LRC[22]。此前,他还提出过2个具有联合修复度的LRC的独立上限,并利用简单图模型设计出满足该独立上限的LRC,利用简单图设计出具有最佳码率和联合信息修复度的LRC[23]。
④ 基于平均修复度的构造:LRC的平均修复度,影响着修复带宽的大小、磁盘I/O的开销。Shahabinejad等人提出了一个适用于任意LRC的平均修复度的下限,并设计出3种LRC。2017年,他们通过研究信息块的最佳平均修复度,得到了一个更低的下限[24]。
⑤ 基于Matroid理论的构造:Westerb等人给出了拟阵与LRC之间的联系,通过线性的或者一般仿射来使用这些拟阵结构,可以构造新的LRC[25]。Tamo等人也通过拟阵提出了简单准确的LRC构造[26]。
⑥ 基于Rank-Metric码的构造:Silberstein等人基于最大秩距离(Maximum Rank Distance,MRD)Gabidulin码提出了LRC的构造方法[27],采用串行级联编码的结构,用MDS码作为外码,RGC或LRC作为内码,实现容错存储。
2.3 Piggybacking编码
相比于RGC和LRC,Piggybacking编码以其较低的计算复杂度、设计灵活等特点开始在数据容错技术中占有一席之地。编码设计完成后,它不改变原有系统的节点分布结构,不产生额外的存储负载、在修复失效数据时将底层码的译码替代为求解与失效数据相关的Piggyback方程。这样不仅显著降低了修复带宽,还有效降低了修复复杂度,为海量数据可靠、高效的存储提供了强有力的保障。
2.3.1 Piggybacking编码的原理
2013年Rashmi等人首次提出了Piggybacking框架的概念,且将该框架下构造的Piggybacking编码用来应对存储系统中频发的故障节点[28]。他们解释Piggybacking的含义是将MDS码作为基本码,将扩展后的MDS码中某些条带的数据符号通过精心设计好的Piggyback函数嵌入到其他条带中形成Piggyback块的一种设计。失效的数据符号可以通过求解Piggyback方程来替代传统的MDS译码来恢复,这样能有效降低修复带宽。
Piggybacking编码的框架是在一个任意的、被称为基本码的基础上操作,目前的基本码都采用MDS码。Piggybacking编码保持了基本码的很多属性,比如最小距离和操作域。Piggybacking框架有一个显著的特点就是在不改变原有存储节点的分布结构下减少了额外的存储开销,即不需要增加除MDS编码以外的校验节点,依旧能保持数据重建性。另外,Piggybacking编码满足MDS性质可以实现高码率,拥有少的子条带数和修复节点时更少的平均数据读取量和下载量等特点。另一个特别吸引人的点就是Piggybacking编码支持任意码长为n、信息位长度为k的基本码(码参数的选择取决于基本码的需要)。然而有的码如Rotated-RS码,当校验节点数r∈{2,3}和信息节点数k≤36时才存在[29];EVENODD码和RDP码也只在r=2时才可以实现。再加上Piggybacking编码设计灵活、复杂度低和易于系统实现等特点,目前已经应用于Facebook Warehouse Cluster,HDFS等系统中[30]。通常Piggybacking编码采用系统形式,因为系统形式中的信息节点承载了所有未编码的原始数据。因此用户通过直接访问信息节点就可以得到原始数据,而不用访问某些校验节点采用MDS译码来恢复原始数据,这样不仅降低了获取原始数据的复杂度,还降低了获取数据的延迟。
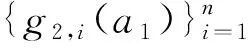

图7 Piggybacking框架
2.3.2 Piggybacking编码的发展现状
作为Piggybacking编码的鼻祖,Rashmi等人提出了3种Piggybacking设计[29]。第1种设计是基于较少的子条带数量,其中最少的子条带数只有2。这类设计修复信息节点时根据码参数不同可以节省25%~50%不等的修复带宽,且该设计也具备修复校验节点的能力。经计算表明,当整个Piggybacking框架采用的条带(例)数m越大时,修复带宽越低,修复效率越高。第2种设计是由(2r-3)列结构相同的MDS码组成,并在最后(r-1)列中增加了Piggyback方程。该设计要求校验节点数r≥3,相比第1种设计拥有更高的修复效率,平均能有效减少约50%的修复带宽。这是以牺牲子条带数量为代价:要求最少子条带数为(2r-1),且该设计不能有效修复校验节点。作者将关注度从修复带宽转移到修复度上,设计了第3种Piggybacking编码,该码可以有效修复最小修复度可达k+1的MDS码中的信息节点。
随着Piggybacking编码被提出,研究者们正试图寻找构造有效的Piggybacking框架来修复失效节点。Yuan等人提出一种广义的Piggybacking编码,并证明了当校验节点数趋于无穷大时,信息节点的修复带宽比率趋近于零,而且非常接近分布式存储编码修复带宽的理论极限(cut-set bound[31])。Kumar等人针对信息节点的修复设计了一种Piggybacking框架,然而该Piggybacking结构并没有维持MDS性质[32],且当B类校验节点数增加时,信息节点的修复带宽会减少,同时也增加了系统的存储负载。Shangguan等人提出了一种Piggybacking编码用于修复信息节点,他们根据不同Piggyback块中嵌入的信息符号数量的不同将信息节点进行划分,由此获得了较低的修复带宽[33]。Yang等人保证信息节点可修复的同时,为减少校验节点的修复带宽提出了一种Piggybacking框架[34]。
2.3.3 Piggybacking编码的理论研究、构造与应用
Piggybacking编码的研究主要处在理论和构造阶段,因此从Piggybacking码的理论研究、构造和可能应用的这3个方向对其研究内容进行阐述,其结构如图8所示。
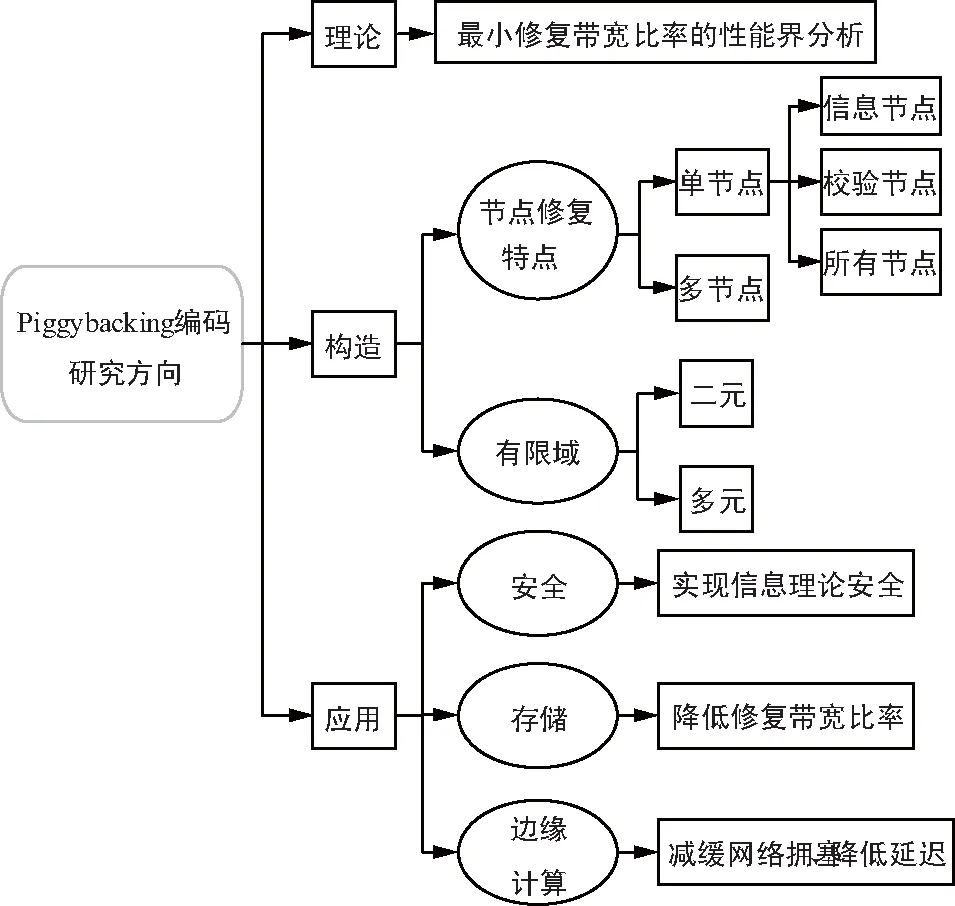
图8 Piggybacking编码的研究方向
2.3.3.1 理论研究
Piggybacking编码通常是以MDS码作为基本码,然而MDS码的弊端很多,比如:系统中MDS码的编译码操作经常会导致高延迟和低吞吐量的情况,MDS码的修复代价太高,MDS码修复度较大,对磁盘I/O性能不友好。更加遗憾的是,由于MDS码的编译码复杂度很高,会导致Piggybacking编码的编译码复杂度也不低。因此对于Piggybacking编码来说,选择复杂度低的基本码是降低自身复杂度最快、也是最有效的方法。比如可以考虑将复杂度较低的类LDPC码来作为基本码。
一种Piggybacking编码性能的好坏,不仅在于其具有较低的修复带宽比率,更希望它能有更快的收敛速度,有最小的修复带宽比率下界。因此,需要对该码的最小修复带宽比率的性能界进行分析。收敛速度越快,说明该码的最小修复带宽比率下降速度越快;最小修复带宽比率能达到的下界越低,说明该码的修复性能越好。
2.3.3.2 构造
理论上基于有限域构造,通过Piggyback块构造后产生的Piggybacking编码不改变基本码的有限域,也就是说Piggyback函数设计得到的Piggybacking编码不仅适用于二元域,也同样适用于多元域Fq(q为素数幂)。根据面向修复节点特点主要分为单节点修复和多节点修复,具体如下。
(1)单节点修复
在Piggybacking编码的构造阶段,也就是设计Piggybacking的框架,目前所有研究只是停留在单节点的修复设计上,而且大部分都是针对信息节点的修复,检验节点的非常少,而同时有效修复所有节点的Piggybacking码就更少。本小节针对这3种编码设计,分析构造它们所采取的构造思路如下:
a.信息节点的修复
一种Piggybacking编码能够修复信息节点,是因为Piggyback函数中嵌入了信息节点中的原始信息数据,然后将这些Piggyback函数嵌入到不同校验节点中的不同子条带(或条带)中。显然,当信息节点失效时,带有信息节点中失效信息数据符号的Piggyback函数存在于没有损坏的校验节点中,通过这些函数构造的逆过程即求解Piggyback方程,可得到失效数据。但当校验节点失效时,失效的校验符号没有留下任何与之相关的Piggyback函数(块),因此该Piggybacking编码就无法通过求解Piggyback方程来恢复,只能通过该Piggybacking编码基本码的MDS性质译出。但这样的修复带宽是大于通过求解Piggyback方程来恢复失效数据的修复带宽,且当基本码的编码参数增大(分布式存储系统规模的增大),通过MDS性质译出的修复带宽是远远大于通过求解Piggyback方程的。
对于不同的Piggybacking编码而言,其最小修复带宽比率(或修复效率)与修复带宽比率的收敛速度均不相同。这与该Piggybacking编码的Piggyback函数和该Piggyback块放置的位置息息相关。一般情况Piggybacking编码的修复带宽比率越低,修复效率越高,其Piggyback函数构造的复杂度就越高,方法就越巧妙。
通常可以采用整体法和分集法。整体法是将所有信息节点中的信息数据看成一个大的集合,需要构造出一种Piggyback函数,将这些数据按照此编码规则统一进行嵌入;分集法是将信息节点进行分组(理论分析,一般均分后的性能是最优的),针对每个集合需要对应构造出一种Piggyback函数,不合集合之间的函数不同,将各自集合中的信息数据采用与之对应的Piggyback函数进行嵌入。经分析,分集法的修复带宽比率的收敛速度大于整体法,因此它的修复效率更高,复杂度也较高。
b.校验节点的修复
同理,一种Piggybacking编码能够修复校验节点,是因为Piggyback函数中嵌入了校验节点中的校验符号数据,将这些Piggyback函数嵌入到不同校验节点中的不同条带(或子条带)中。与修复信息节点的Piggybacking编码相比不同的是:该Piggyback块也需加到校验节点上,而不是信息节点上。通常为了用户方便有效读取和下载数据,分布式存储系统一般是系统节点,也就是当系统中信息节点没有损坏时用户只需读取下载信息节点中自己需要的数据即可,无需进行MDS译码操作,这样可以大大降低复杂度和读取延迟。只有当信息节点或校验节点失效时,才会动用嵌在校验节点中的Piggyback块进行失效节点的修复。
由于修复校验节点的校验块就放在校验节点上,因此该种Piggybacking编码就有了一个与修复信息节点Piggybacking编码不同的设计关键:校验节点的修复依赖与它相关的校验节点,因此必须保证每个校验节点的Piggyback块(用于修复校验节点)不能嵌入本校验节点的校验符号,假如该校验节点失效后,该节点中的校验符号连同与其唯一相关的Piggyback块一起丢失,该符号就无法通过Piggyback方程译出。为了提高Piggyback方程的可解性,即保证每个数据符号都能被正确恢复出,要求每个失效信息节点里的待嵌入数据符号不能嵌入同一个Piggyback块里(避免出现方程式的个数少于未知数个数的情况),因此这些数据符号需要尽可能地散列,当然这个条件对修复信息节点的设计也需要满足。为了设计修复带宽比率低的用于修复校验节点的Piggybacking编码,除了满足上面的设计要求,还在于Piggyback函数的巧妙设计。也可采用整体法和分集法,分析比较它们之间的修复效率。
c.所有节点的修复
经过对以上2种节点修复方法的简单描述,本节是对所有节点的修复分析方法进行阐述。该种Piggybacking编码的构造要求是需要同时满足对信息节点和校验的有效修复。用于修复信息节点和校验节点的Piggyback块都要嵌入校验节点中。因此, Piggybacking编码可分为两大类:一类是将修复信息节点的Piggyback块和修复校验节点的Piggyback块混合嵌入到校验节点中;另一类是,将这2种Piggyback块分开嵌入校验节点中。当这2种校验块出现混合嵌入同一个校验节点的同一列时,必须清楚当修复信息节点或校验节点时,用于修复另一种节点的Piggyback块是否会对正在修复节点的修复带宽产生影响,这样是否会引入额外的修复带宽(相比于单一节点修复的Piggybacking编码),以及Piggyback函数的设计复杂度增加的程度。当这2种校验块放置的子条带没有混合时,无形中又增加了Piggybacking编码框架中的校验块的嵌入子条带数,这样是否会影响该Piggybacking编码设计的参数(子条带数)要求。把握好上述2种情况,才能设计出复杂度低、同时有效修复2种节点的Piggybacking编码。
(2)多节点修复
目前所有关于Piggybacking编码的研究,针对失效节点的修复都是单节点修复。但Piggybacking编码的多节点修复可以类似RGC和LRC,且在实际的分布式存储系统中有着重要的现实意义,这对深入研究Piggybacking编码有一定的参考价值。
不同Piggybacking编码的设计框架不同,即针对其修复节点的方法不尽相同。因此,不同Piggybacking编码的多节点修复方法也不同。最重要的是,多节点的修复情况相比单节点更加复杂,包括3种情况:① 失效的全部都是信息节点;② 失效的全部都是校验节点;③ 失效的一部分是信息节点,一部分是校验节点。对于同一种Piggybacking编码,其信息节点和校验节点的修复带宽不同,因此以上3种情况的修复带宽都不相同,必须分情况讨论。最终通过概率论与数理统计的方法求得平均多节点修复带宽比率。另外,需注意的是,多节点修复的失效节点数以2起步,小于等于校验节点数r(其基本码MDS码能容忍的最大失效节点数为n-k=r)。
多节点的修复过程中会出现一种权衡,失效节点中的失效符号(需要求解未知数的个数)与Piggyback方程个数的关系。显然,Piggyback方程越多,利用线性方程能求解的未知数(失效节点中的符号数)就越多,则通过MDS译码求解剩余未知数减少,总的消耗带宽就小(最差的情况就是所有失效节点全部用MDS译码,即大小等于原始数据大小)。所以希望通过MDS译码求解的符号数应尽量少。但又不能太少,否则Piggyback方程的个数少于剩余需要求解符号数的个数时,又无法求解。因此,必须针对不同的Piggybacking编码,找到它的修复带宽的权衡,才能求得其最小的多节点修复带宽比率。
可以先对该Piggybacking编码的2个失效节点进行分析总结,找出它的权衡,再将这种方法推广到多个修复节点的推算中,难易程度循序渐进,且准确率更高。
2.3.3.3 应用
(1)存储
Piggybacking编码作为分布式存储编码中的新生力量,诞生于大数据、云计算时代。目前它的主要应用是存储业务,并已经应用到了Facebook Warehouse Cluster,HDFS等系统中。
(2)安全
Piggybacking编码与同属于分布式存储编码的RGC和LRC一样,都具有维护信息理论安全的潜力。因此,可以使Piggybacking编码既能成为一种执行高效、复杂度低的节点修复,同时还能实现信息数据的安全性。
考虑一个理论上能应对在存储节点的窃听模型,并通过损坏节点的修复得到其他节点的数据。其中的窃听者可能获得存储节点的数据,也可能访问在修复某些节点期间下载的数据,通过设计安全可靠的Piggyback函数,既能对失效节点进行有效修复,还能使窃听者获得的数据无法解密译出,从而确保信息的保密能力。在不向任何窃听者透露任何信息的情况下,可以安全存储并向合法用户提供最大的数据量。最后通过证明窃听者和原始数据之间的互信息为0,即窃听失败,证明Piggybacking编码的安全模型可行。可以对信息理论安全和Piggyback函数设计的复杂度进行权衡分析,提出理论安全和具有最低Piggyback函数设计的复杂度二者结合的Piggybacking编码方案可抵抗窃听。另外,除了在Piggyback函数的设计(编码)上考虑,还可以结合信息安全方面的知识建立安全模型。
(3)边缘计算
如果在分布式存储系统中完全依赖云中心去修复失效节点,不仅会占用大量的网络带宽,还会导致整个系统的性能瓶颈变为网络带宽的瓶颈,因为云中心的处理速度要远超网络中数据的传输速度。若节点的修复计算能搬移到边缘节点,且只向云中心提交处理后的结果,不仅能降低不必要的带宽消耗,还能减少修复延迟,从而进一步提高系统性能。另外,就地处理数据,可以大大降低数据在网络传输中被窃取的风险,有效进行隐私保护,保障数据安全。
协同边缘如图9所示,它连接了多个在物理位置或网络结构中分散的边缘节点。边缘节点作为一个将终端用户和云中心连接具有数据处理能力的小型数据中心,也是逻辑概念的一部分[35]。实线箭头代表云服务器中心给边缘节点下发任务,虚线箭头表示多个终端用户将自己产生的数据交给具有计算能力的边缘节点进行处理。在网络边缘处,节点不仅可以从云中心请求服务和内容,还可以在本地执行计算卸载、数据存储、缓存和处理以及物联网管理等任务。基于这些能力,需要对边缘节点进行良好设计,保证存储系统中数据的可靠、安全和隐私[36]。综上所述,这些分布式边缘节点为终端用户提供了合作和共享数据的机会。因此,边缘计算具有极大潜力,可以通过与Piggybacking编码结合来安全高效地解决分布式存储系统中失效节点的修复难题。
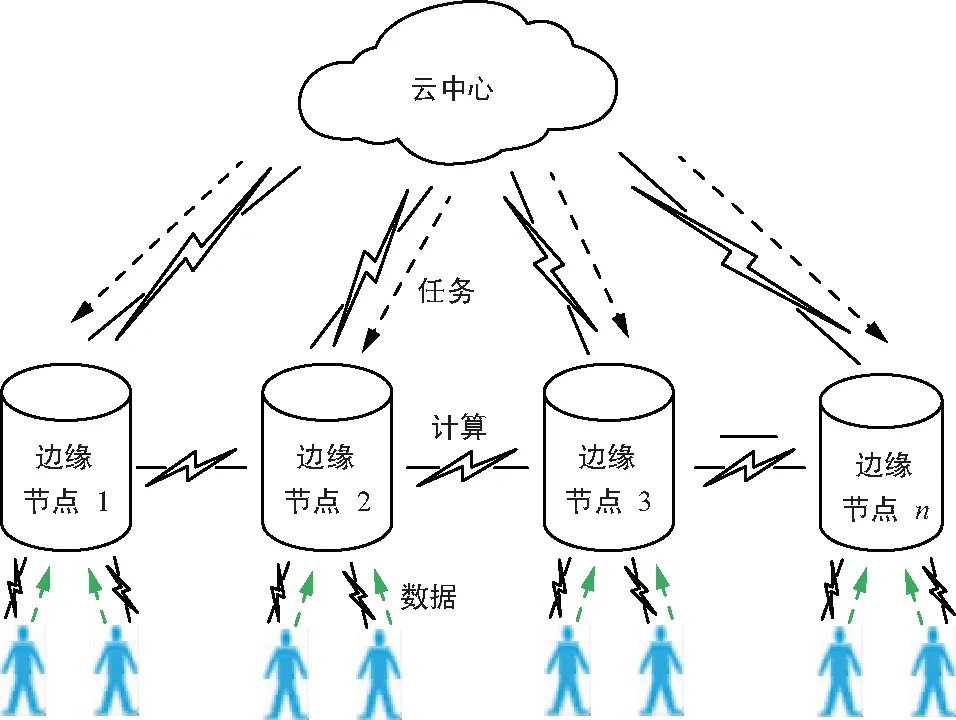
图9 分布式存储中协同边缘计算范式的结构
2.4 性能比较
表1针对文中5种存储容错方式的性能进行了简单粗略比较(注:从这几种容错存储的基本原理来考虑,并没有针对具体的容错参数或码参数)。其中“★”的数量表示性能的相对大小程度,即4颗星表示最高,3颗星表示较高,2颗星表示较低,1颗星表示最低。例如多副本机制的修复带宽开销最低,用1颗星表示;其存储开销最大,用4颗星表示。
表1 几种存储容错方式的性能比较

存储容错修复带宽销存储开销修复度计算复杂度容错能力多副本机制★★★★★★★★★★★MDS码★★★★★★★★★★★★★★RGC★★★★★★★★★★★★★★LRC★★★★★★★★★★★★★Piggybacking编码★★★★★★★★★★★
3 结束语
本文简单介绍了目前分布式存储系统中常见的容错技术,主要分为4部分:① 传统的容错技术即最早的多副本机制和MDS码;② 基于网络编码的再生码;③ 着眼于降低磁盘I/O的局部可修复码;④ 不改变存储结构的Piggybacking编码。传统的容错技术与分布式存储编码的容错相比,其基本性能劣势比较明显,慢慢会被取代。不同的分布式存储编码都有自己优缺点,具体选择哪种容错方式要根据分布式存储系统的需求来决定。
猜你喜欢
九江学院学报(自然科学版)(2022年2期)2022-07-02
中学生学习报(2022年15期)2022-04-17
机电工程技术(2021年3期)2021-09-10
电脑爱好者(2020年18期)2020-09-26
网络安全和信息化(2019年10期)2019-11-26
电脑爱好者(2019年2期)2019-10-30
发明与创新·大科技(2019年12期)2019-03-17
传播与制作(2018年9期)2018-11-15
电脑知识与技术(2017年14期)2017-07-10
山东工业技术(2016年10期)2016-09-06
