
基于Naive Bayes 的P2P 平台评论研究
2019-08-20 07:25曾政多
现代计算机 2019年20期
曾政多
(佛山科学技术学院自动化学院,佛山528000)
0 引言
P2P 金融是近几年来较为火热的一个关键词,P2P(Peer to Peer)网贷模式指的是个体和个体之间通过互联网平台来实现直接借款与贷款,它也是互联网金融(ITFIN)行业的一个子分类。我国的P2P 平台数量自2012 年开始,增长的较为迅速,迄今为止已经有数千家平台可供投资人选择。由于投资回报率过高,参与其中的投资者与日俱增。为数众多的P2P 平台鱼龙混杂,企业数量增速过快,而政府的监管却没有跟上发展的速度,从中出现了大量的问题,自2018 年6 月各大平台相继“暴雷”之后,于2018 年8 月开始,国家对互联网金融进行了整治。
即便是具有高风险,在可观的收益率下,还是有着数量庞大的投资者群体会选择P2P 平台进行投资,伴随着各类平台网站用户的持续增长,人们已经从过去的口头相传或者是通过平台的宣传广告等简单信息获取方式转变为向互联网传输自己的观点看法,从而每天可以产生很多对于各种平台的评论。这些呈指数增长的评论发生在各种相关平台如微博、贴吧、股吧论坛等各大地方,数量庞大,难以梳理。但是对于其文本是很有研究价值的。通过分析用户对不同平台不同特征的情感倾向,从而指导用户的投资行为,是很有意义的一项研究。
1 数据获取和预处理
1.1 数据获取
本文所述研究所选用的数据集是DataFoutain 中的“互联网金融平台用户评价提取”赛题中的数据集,数据中包含平台评论数据集、投资公告数据集、论坛数据集等,本研究使用了其中的评论数据集用于分析和训练。
1.2 文本去重处理
文本数据在分析之前通常要进行一些预处理,特别是在诸如此类的竞赛平台数据集中,主办方肯定会通过复制同类数据使得数据变得冗杂,那么在开始就需要对数据集使用去重处理,本文使用Python 语言中的xlrd 与xlwt 库对表格数据进行处理。如图1 所示,通过建立一个新的list 表,往里加入数据,通过遍历数据集与list 表中的进行比对,没有重复则加入list 的方法来进行去重处理,实现了数据清洗的过程。
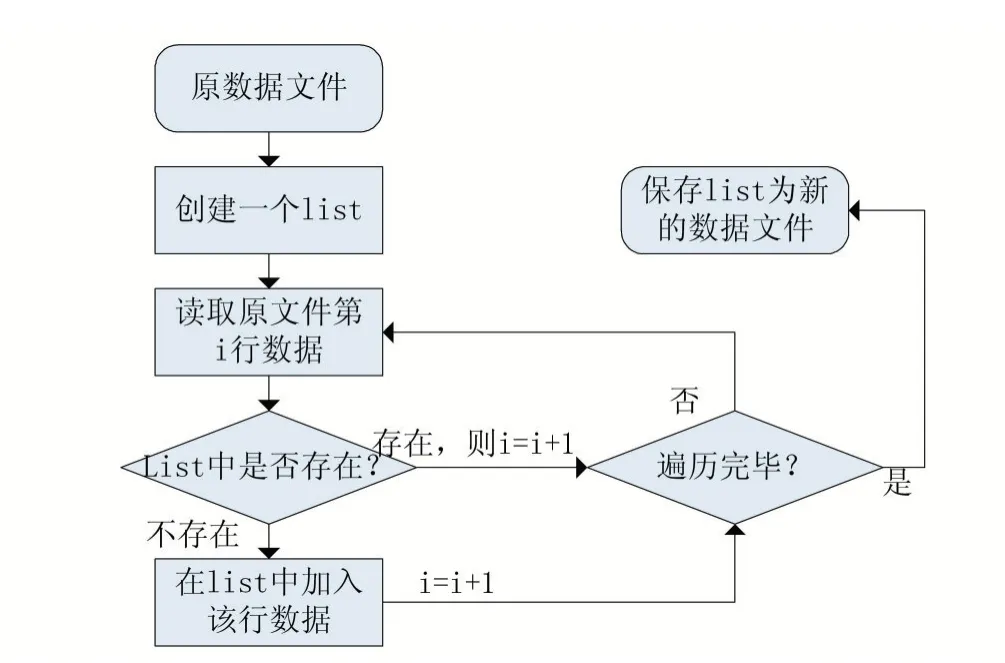
图1 数据去重流程图
1.3 文本的词频分析
TF-IDF 即“词频-逆文本频率”,它由TF(Term Frequency)和IDF(Inverse Document Frequency)两部分组成。
其中的TF 就是我们前面说到的词频(Term Frequency),文本向量化也就是做了文本中各个词的出现频率统计,并作为文本特征,后面的这个IDF,即“逆文本频率”。在英文文本中,几乎所有的文本里都会出现“to”和“and”,这类单词的词频虽然高,但是重要性却应该比词频低的“Naive”和“Investment”要低。IDF 的作用是用来反映这个词的重要性,进而修正仅仅用词频表示的词特征值。
概括来讲,IDF 指的是某个词在全部文本内出现的频率,如果某个词在较多的文本内都出现过,那么它的IDF 值是比较低的,例如上面说到的介词“to”和连词“and”。反而言之,某个词语只在很少的文本中出现过,那么它的IDF 值应高。例如一些专业的名词如“Deep Learning”。这样的词IDF 值应该高。一个极端的情况,在所有文本都出现的词,IDF 值为零。
一个词x 的IDF 的基本公式如下:
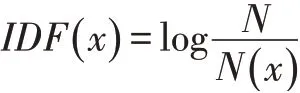
其中,N 代表语料库中文本的总数,而N(x)代表语料库中包含词x 的文本总数。
上述IDF 公式在大多数情况下适用,但是在一些特殊的情况则会出现一些小问题,例如遇到的某个词语没有出现在之前训练好的语料库中,这样计算之后会使分母为0,IDF 会失去意义。因此通常我们在IDF计算时会做一些平滑处理,使某个词语即使没有在语料库中出现,在经过计算之后也可以得到一个合适的IDF 值。平滑的方法有很多种,最常见的IDF 平滑后的公式之一为:
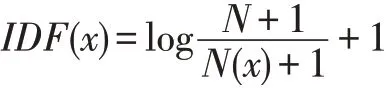
综上所述,某一个词的TF-IDF 值如下计算:
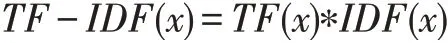
对于分词,本研究用到的是Python 里的jieba 库。jieba 分词是一个完全开源,并且有集成的Python 库,具有多种模式且使用起来较为简单。jieba 在分词的过程中可以添加自定义词库或者删除“停用词”(stopwords)。“停用词”是指那些词频很高却没有情感特征的词语,这些词的TF-IDF 值可能非常高,需要主动删除,以免引入噪声。
词云图,也就是通常所说的文字云,是对文章中出现次数比较多的“关键词”进行可视化,在词云图上,大量的低频、低质的文本信息会被过滤掉,使得浏览者只要看一眼词云图就可领会到文章主要想表达的意思。在Python 里现在有许多库可以实现词云图,本文用到的Wordcloud 是词频分析的一个热门库,在代码中可以自行设定背景和显示的字体,显示效果相比于其他的绘图工具会更加直观、具体。

图2 词云图
从词云中可以看出网友们比较关注的关键词有“收益”、“平台”、“提现”、“活动”等,表明网友在金融平台的评论时,重点关注的点还是在收益和提现上,由此可见收益的高低、提现的便捷程度与速度、是否定期有举办活动是影响用户情感的关键因素。
2 数据挖掘分析
2.1 情感分析研究现状
文本的情感分析在二十世纪九十年代末由国外开始,早期的研究是基于文本数据来构建一个语义词典。在McKeown 在对连词开展研究之后,研究者们开始考虑特征词和情感词之间的关联。从Pang 等研究者开始,机器学习的研究方法开始被应用,以消极和积极两个方向维度对文本评论进行分类,取得了不错的效果。由此可见机器学习在文本情感分析的方面有着比较理想的研究前景。基于机器学习的情感分析方法需要人工标注文本,将标注到的文本作为训练集训练模型,再对目标进行情感极性判断,本研究用到的评论研究方法是属于机器学习中的有监督学习方法。
2.2 应用到的情感分析算法
目前对于单条语句的情感分析应用到的方法是通过上下文语义信息进行分析,上下文的信息将会直接影响到对于单条语句情感值判定的准确性。当前大多数基于机器学习方法的情感分析工具都需要经过训练这一阶段,对待不同的样本应当采用不同的训练集进行训练以提高模型的适应性。
本文对于情感分类的基本模型是贝叶斯模型Bayes,对于有两个类别C1和C2的分类问题来说,其特征为w1,∙∙∙∙,wn,特征之间是相互独立的,属于类别C1的贝叶斯模型的基本过程为:

表1 预测结果表格
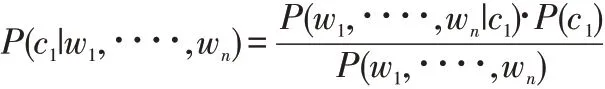
其中:
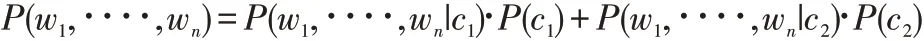
对上述公式进行简化:

其中,分母1 可以改写为:

在Python 里的SnowNLP 库的情感分析核心就是贝叶斯模型,自带了电商评论的数据训练集,因此在交易评论上效果较好,应用到金融平台上也不需要做太大的修改。SnowNLP 库是针对中文文本的自然语言处理工具,具有中文分词、词性标注、情感分析、文本分类、转换拼音、提取摘要等等功能。
本研究在SnowNLP 自带的正负预料样本的基础上,人工标注了部分评论并加入到训练集中进行了再训练,提高了预测结果的准确性。
3 实验结果分析
通过调用Python 中的pandas 库,读取了评论数据集中的每段评论并且通过SnowNLP 逐句进行了情感值分析,生成了一个处于[0,1]区间的数值作为情感预测值,研究设定当得到的情感值大于0.5 时我们将评论定位为积极评论,情感值小于0.5 则认为是消极评论。

图3“多融财富”的评论
由上述实证结果显示,使用条件筛选于2018 年7月出现问题的“多融财富”平台,发现其在2017 年10月就开始出现比较多的负面评论(低于0.5),数据集中存在的最后一条评论是2018 年3 月14 日的评论,在本研究模型上的预测结果也是比较消极的,因此可以得出该结果与本文模型比较契合,在其“暴雷”之前在评论上是有表现出将要出现问题的趋势的。
使用条件筛选“微贷网”平台的评论,出现的结果表明2018 年2 月8 日以前大多都是积极的正向结果。“微贷网”平台目前还处于正常运转的状态,通过本实验数据集的预测结果也没有出现过多的消极评论,表明该平台的对于大部分用户口碑较好,没有出现太大的问题,短时间内不会出现“暴雷”,是投资者可以作为选择的网贷平台之一。
4 结语
中文的自然语言处理技术是一项特别繁杂的工作,需要注意非常多的细节,本文提出了使用Python 语言中的jieba 库与WordCloud 库结合进行词频分析的过程,并通过SnowNLP 库分析情感极性,最后通过分析的结果来反馈到现实生活中的现象,评判一个平台的好与坏,且通过实证以及模型检验得出的对投资者的建议以及未来的一些发展趋势,为金融领域与自然语言处理学科的融合给出了初步的实验基础。
目前本研究的实验还仅仅处于初步阶段,只对评论数据进行了简单处理与分析,在今后的工作当中还可以使用不同的机器学习库进行处理,探寻如何让机器对人类情感深入细致的把握和分析才是自然语言处理工作应当做的事情。以获得更好的预测效果,同时受限于样本数量没有对单独平台进行评论分析,在今后评论数据充足的情况下可以针对单一平台进行分析同时绘制情感极性变化曲线来预测平台今后的发展情况。
对于数据集中的其他材料如新闻、股市公告等在本研究中并没有应用到,情感分析是一个相对复杂的研究,统计和展示大量数据中隐含的情感特征才是真正要探索的问题,多维度的结合分析也是今后需要研究的方向。
猜你喜欢
云南教育·小学教师(2022年4期)2022-05-17
艺术评论(2020年3期)2020-02-06
小太阳画报(2019年10期)2019-11-04
海峡姐妹(2019年9期)2019-10-08
福建基础教育研究(2019年3期)2019-05-28
中华诗词(2018年9期)2019-01-19
亚太教育(2018年5期)2018-12-01
小资CHIC!ELEGANCE(2018年20期)2018-07-06
读者·校园版(2015年7期)2015-05-14
心理学报(2014年4期)2014-02-02
