
基于信息披露文本的上市公司财务困境预测:以中文年报管理层讨论与分析为样本的研究
2019-08-19 11:51:12陈艺云
中国管理科学 2019年7期
陈艺云
(华南理工大学经济与贸易学院,广东 广州 510006)
1 引言
近年来,随着我国经济步入新常态,增长速度放缓,不少公司企业经营业绩下滑,债务偿还能力下降,信用违约事件不断增多,以信用债为例,根据Wind资讯的统计数据,2014年以前,中国债券市场未发生过实质性违约,而从2014年3月“11超日债”违约开始,当年有6只债券违约,2015年为23只,到2016年进一步增加到79只,涉及34家公司企业,违约总金额高达403亿元,信用风险对我国金融市场和宏观经济提出了严峻挑战,准确预测公司企业的财务困境对于强化信用风险管理,有效防范信用危机和债务危机具有重要的理论和现实意义。
一直以来,对于公司企业财务困境预测的研究都是以会计信息和市场信息为基础的,如Altman基于财务数据的Z评分模型[1]、Merton基于市场数据的结构模型[2]、Shumway结合两者提出的风险模型(Hazard Model)[3]等,这些方法在国内对上市公司财务困境预测的研究中都有普遍应用[4-8],不过这些研究存在着一个共同的缺陷,都是以定量数据为基础,忽视了定性的文本信息,而标准普尔在2003年的报告中就曾指出,“定性信息中包含着区分信用风险的重要信息”[9]。
从公司信息披露的角度来看,定量数据直观的反映了公司的经营和财务状况,而描述性文本信息是相应的具体说明和分析,也是与潜在股东和债权人沟通的重要机会,是对定量数据的有效补充,由此可以吸引读者的注意,促使投资者购买更多的股票或将更多资金放贷给企业,抑制出售公司股票和债权的冲动[10]。当公司财务状况开始恶化时,管理层的这种激励就会更为强烈,公司信息披露文本的措辞与风格就会随着经营和财务状况的变化而不同,这样以来,这些文本内容就可能为判断经理人与公司的违约倾向提供重要线索。Tennyson等通过对比23家破产企业和正常企业年报董事长致辞以及管理层讨论与分析部分的文本内容发现其主题会随着企业财务状况的恶化而变化[10],而Cecchini等对78家破产企业和正常企业年报管理层讨论与分析文本内容本体的分析得到了类似的结论[11]。
国内不少学者对我国上市公司年报管理层讨论与分析(Management Discussion & Analysis, MD&A)有用性的研究表明MD&A能为预测公司未来经营业绩提供增量信息[12-14],不过在研究方法上,大多采用人工阅读分析或打分的方法,采用自动文本分析的研究不多,如蒋艳辉等采用余弦相似度检验了创业板上市公司MD&A文本是否随时间和经营情况的变化进行更新和变换[15],蒋艳辉等在语句层面从可读性、业绩自利性归因、匹配信息密度、自我指涉度、前瞻性深度来衡量MD&A言语的有效性[16],而在财务困境预测或信用风险评价领域还鲜见考虑MD&A或其他信息披露文本的研究。
近年来,在公司金融领域,有不少研究通过对公司信息披露文本内容的自动分析,以正面和负面的情感表达来衡量其传递的管理层语调,并从实证角度对管理层语调的信息价值进行了检验[17-21]。基于这些研究,本文试图通过对中文年报MD&A的自动文本分析,以特定情感词典为基础来衡量管理层语调,检验管理层语调能否为财务困境预测提供增量信息,并提高预测的准确性。本文可能的研究贡献主要有:一是从财务困境预测的角度拓展了对MD&A信息价值的研究;二是在衡量管理层语调时,充分考虑情感词典、分词方法、权重设置、语调计算方法等因素的影响,有助于拓展中文文本分析在公司金融领域的应用;三是研究结果表明管理层语调是对财务数据的重要补充,而且负面语调具有更高的信息价值。
2 研究设计
2.1 实证方法与思路
本文将采用Shumway[3]的离散时间风险模型(Discrete-time Hazard Model,DHM)来规避配对抽样的研究设计导致的样本量受限问题,同时考虑财务困境发生概率随时间变化的情况,解决静态模型估计的有偏性问题。公司i在t+1时刻陷入财务困境的离散概率满足
(1)
其中Xi,t表示公司i在t时刻的协变量,αt表示时变的基准风险率,这样就利用所有可观测公司-年度样本,消除静态模型的选择性偏误问题。
在离散时间风险模型的基础上,本文首先对公司年报文本的量化指标——管理层语调在预测上市公司财务困境中的作用进行单变量分析,然后以传统会计信息和市场信息模型为基础,加入管理层语调,比较加入前后模型的拟合效果,再对这些模型的预测结果以及由Merton违约距离模型得到的预期违约概率的信息含量进行检验,以确定管理层语调的信息增量价值,最后采用滚动窗口方法对管理层语调的预测能力进行检验。
2.2 主要变量
2.2.1 会计信息与市场信息变量的选择
以往公司财务困境预测的相关研究中选择的财务变量与市场变量非常多,而本文侧重检验管理层语调在财务困境预测中的作用,为此根据Altman[1]、Shumway[3]、Campbell等[22](简称CHS模型)的研究选择了四个模型:一是Altman财务比率模型,包括营运资本/总资产(WCTA)、留存收益/总资产(RETA)、息税前利润/总资产(EBIT)、权益市值/债务面值(MTL)和销售收入/总资产(STA)五个变量;二是市场变量模型,包括波动率(SIGMA,股票市场日收益率的年化标准差)、超额收益率(EXCESS,年收益率与沪深300指数收益率之差)、股票价格(PRICE,年末股票价格的对数值)、相对规模(RSIZE,公司年末股票市值与沪深股市市值总和比值的对数值)和市值账面比(MB,股票年末市值/账面价值);三是Shumway模型,包括净利润/总资产(NITA)、总负债/总资产(TLTA)、波动率(SIGMA)、超额收益率(EXCESS)和相对规模(RSIZE);四是CHS模型,包括净利润/经市值调整的总资产(NIMTA)、总负债/经市值调整的总资产(TLMTA)、现金/经市值调整的总资产(CASHMTA)、波动率(SIGMA)、超额收益率(EXCESS)、股票价格(PRICE)、相对规模(RSIZE)和市值账面比(MB),其中经市值调整的总资产等于股权市值与负债账面价值之和。以上述四个模型为基础,加入文本信息量化得到的管理层语调进行重新估计,对比前后模型的拟合情况,由此来检验管理层语调能否提供增量信息。
2.2.2 基于Merton违约距离模型的预期违约概率
以Merton(1974)为代表的结构模型以未定权益分析为基础,通过计算违约距离来估计公司的预期违约概率[2],理论基础更好,但需要对公司价值及其波动性进行估计。Bharath和Shumway指出基于Merton违约距离的预期违约概率模型的价值在于其函数形式和输入变量,并非对公司价值及波动性的估计[23],因此本文采用他们的方法来计算预期违约概率:资产价值等于股权市值E与债务面值K之和,σV根据上一年股票收益率的波动率σE来计算:
(2)
根据违约距离模型,公司的预期违约概率为
(3)
其中σE根据观测的日收益率计算并进行年化处理;债务面值K,设定为短期债务加长期债务的一半来确定;股权市场价值E以股票市价与普通股股数之积来直接计算;T设置为1年。在计算预期违约概率时,对r分别选取上一年度公司股票的超额收益率和无风险利率来计算,得到两个预期违约概率pBS和pBSr。
2.4 文本分析方法与管理层语调的衡量
在分析金融文本的情感或语调时,一般有两种方法:一种是基于词典或词表的方法,即词袋方法,根据特定词典或词表对正面、负面、不确定等各类特征词的划分来对文本进行分类,对于特征词词典,可直接引入其他领域的成熟词典,如哈佛GI词典[24-25]、 Diction词典[18]、知网Hownet词典[26],这些词典的词语分类很成熟,但对金融领域词语的特殊性往往考虑不足,如税收、成本、资本、折旧等常见的负面情绪词语在会计领域并没有负面的含义,原油、癌症、矿井等负面词语仅代表着特定行业[17],因而一些学者以特定财经文本为基础构建了专门用于财经文本情感或语调分析的词表,如Henry[27]、Loughran和McDonald等[17],并得到了广泛的应用,谢德仁和林乐在对国内上市公司年度业绩说明会文本内容的分析中采用的就是他们所构建的词表[21],在中文方面,You Jiaxing等以中文财经新闻报道内容为基础构建了用以分析财经新闻媒体报道倾向的词表[28];另一种是机器学习方法,以朴素贝叶斯、支持向量机等特定算法对预先选取的训练集数据进行训练,确定文本情绪分类的规则,再应用于全部文本[29-31]。机器学习方法需要预先选择训练样本,而计算机在训练中采用的朴素贝叶斯规则或过滤原则非常多,因而其结果很难应用于对其他类似文本的分析,而词袋方法在选定词典或词表后,就可以避免研究者自身的主观性[32]。因此,本文参照谢德仁和林乐的研究,采用词袋方法来衡量管理层语调,在词典或词表的选取方面,由于分析对象为年报文本,故以LM词表为基础,并选取两个词表作为稳健性检验的词表:一是You Jiaxing等[28]基于中文财经新闻文本的词表(简称YZZ词表);二是国内中文文本情感分析时经常采用的方法,以知网Hownet、台大NTUSD情感词典和学生褒贬义词典的情感词语为基础,经过去重后所构建的情感词典(简称综合情感词典)。
在以词典或词表为基础计算文本的情感或语调值时,还需要设定情感词的权重,最常用的方法就是简单比例加权方法,假定各个情感词的权重相同,而Loughran和McDonald指出情感词权重的设定还需要考虑情感词在全部文档中的重要性[17]。本文以简单比例加权方法来计算管理层语调,并以TFIDF(Term Frequency-Inverse Document Frequency,词频-逆向文档频率)进行稳健性检验。
在分词方面,由于现有中文文本分词技术较多,谢德仁和林乐采用了结巴中文分词工具[21],本文为确保结果的稳健性,以R语言为基础,在采用结巴中文分词工具(JiebaR)的同时,以基于中科院ICTCLAS中文分词算法的Rwordseg中文分词工具进行稳健性检验。在完成中文自动分词后,进行词频统计,利用R语言的文本挖掘工具TM创建文档词语矩阵,然后再利用LM词表、YZZ词表以及综合情感词典来统计正面和负面的情感词语词频POS和NEG(分别表示该类词语数量占全部词语总数的比例)。由于财务困境是公司风险的体现,因而本文以负面词语词频NEG来衡量管理层的负面语调,同时由POS和NEG来构建管理层的净语调TONE:
(4)
由此共构建了18个管理层语调的衡量指标:JLMNEG、JLMTONE、JYNEG、JYTONE、JNEG、JTONE、RLMNEG、RLMTONE、RYNEG、RYTONE、RNEG、RTONE、JLMNEGTD、JNEGTD、JYNEGTD、JYTONETD、JLMTONETD、JTONETD,其中J和R分别代表结巴分词和Rwordseg分词工具,NEG和TONE分别表示负面语调和净语调,TD表示按TFIDF权重计算,LM和Y表示分别按LM和YZZ词表计算。
3 样本和数据
3.1 样本
参照国内研究的一般做法,本文将因财务状况异常而被特别处理(ST)作为上市公司陷入财务困境的标志。由于我国上市公司年度报告是在该会计年度结束之日起4个月内编制完成,因而上市公司t-1年年报公布与其在t年是否被特别处理这两个时间是同时发生的,为此本文参照石晓军等的做法[33],利用上市公司t- 2年的数据建立模型来预测其是否会在t年陷入财务困境。同时,部分市场信息变量以及预期违约概率模型的计算都需要上市公司股权的市场价值,为避免对非流通股价值的估计问题,本文选取了2006年以来,股改基本完成后的股票交易数据来衡量股权市值。结合这两个条件,本文的样本包括了2008年~2016年被特别处理的上市公司,对应的数据区间为2006年~2014年,并剔除了金融类上市公司、创业板上市公司以及跨市场在B股、H股上市的公司,在选择特别处理样本时,不考虑2008年以前已被特别处理的公司,以及被特别处理后的进一步降级或撤销特别处理的问题,此外还剔除了一年交易日不足70天的公司,最后样本中包括2024家上市公司,其中184家上市公司被特别处理,共11071个公司-年度观测样本。
3.2 分词结果
在采用JiebaR和Rwordseg两种中文分词工具对公司年报管理层讨论与分析分词后,对LM词表、YZZ词表和综合情感词典中出现频率最高的词语进行了比较,结果显示,不同分词工具在采用同一词表的差异很小,不过由于综合情感词典根据多个中文情感词典综合得到,是在其他领域应用比较成熟的中文情感词词典,但对金融领域的特殊性考虑不足,一些词语,如“负债”、“集团”、“机械”、“竞争”、“利润”等为会计或描述公司状况时的常用词语,并不能区分正面与负面的情感语调;YZZ词表以新闻报道文本为基础,一些词语在年报文本中同样不能区分正面与负面的情感语调,如“收入”、“负债”、“污染”等;而基于公司年报文本内容的LM词表尽管是由Loughran和McDonald的研究根据中文年报内容翻译得到,但相对综合情感词典和YZZ词表而言可以更好的区分正面和负面的情感语调。
3.3 数据
本文利用非参数Wilcoxon Mann-Whitney检验对全部变量是否在财务困境和正常公司两组样本之间存在显著性差异进行了检验,结果表明除市值账面比(MB)以外,其他财务和市场变量以及由不同方法得到的管理层语调变量都存在显著性差异,可以区分财务困境和正常公司。为避免极端值对实证分析的影响,参照一般做法,对财务变量、市场变量、管理层语调变量按1%的水平进行缩尾处理,对于预期违约概率pBS和pBSr则参照Hillegeist等的研究[34],将其取值限制在0.00001~0.99999之间,在进行信息含量检验时,将预期违约概率转换为逻辑分值:
BS-score=ln[pBS/(1-pBS)]
(5)
BSR-score=ln[pBSr/(1-pBSr)]
(6)
其取值范围为-11.51292~+11.51292。
4 实证结果与分析
4.1 基于离散时间风险模型的估计
4.1.1 基于单变量模型的比较分析
本文首先对语调变量是否具有预测上市公司财务困境的能力进行单变量检验,结果如表1所示。从离散时间风险模型的AUC(Area Under Curve,受试者工作特征曲线ROC下面积)、AIC(Akaike Information Criterion,最小信息准则)和Pseudo-R2来看,语调变量都具有一定的财务困境预测能力,JiebaR和Rwordseg两种分词工具的差别很小;在负面语调变量中,LM词表效果最好,在净语调变量中,YZZ词表效果最好,而综合情感词典效果在两种语调变量中都是最差的;在情感词权重设置方面,以TFIDF来设置情感词权重得到的结果比简单比例加权方法要明显更差。
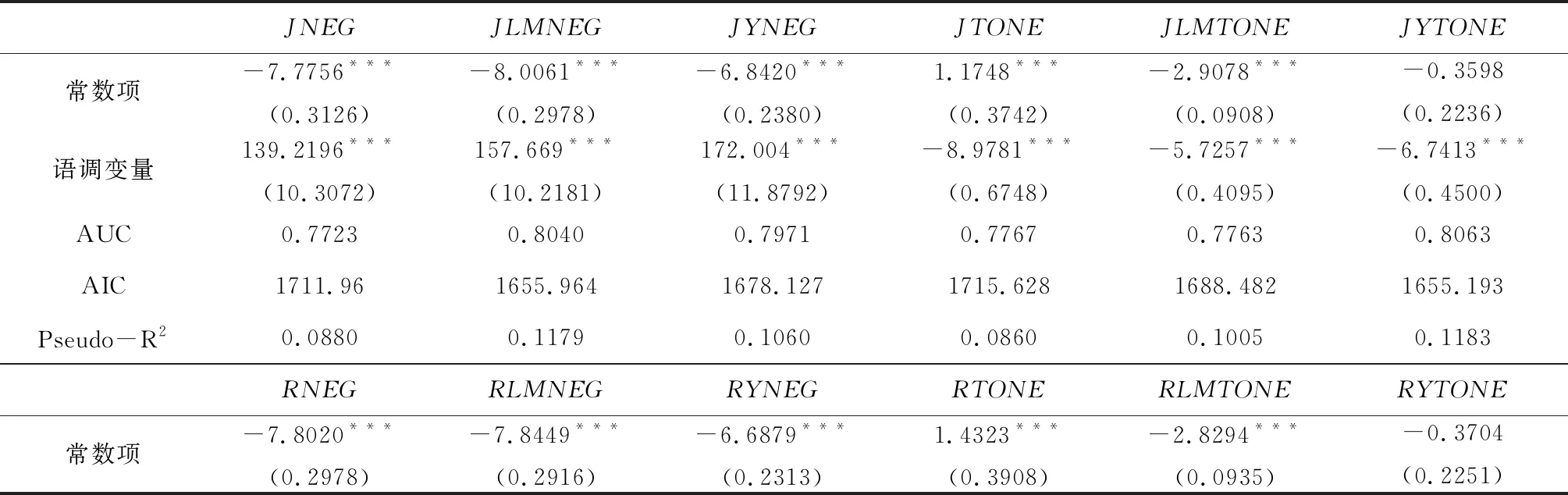
表1 语调变量对财务困境的预测能力:基于单变量的比较分析
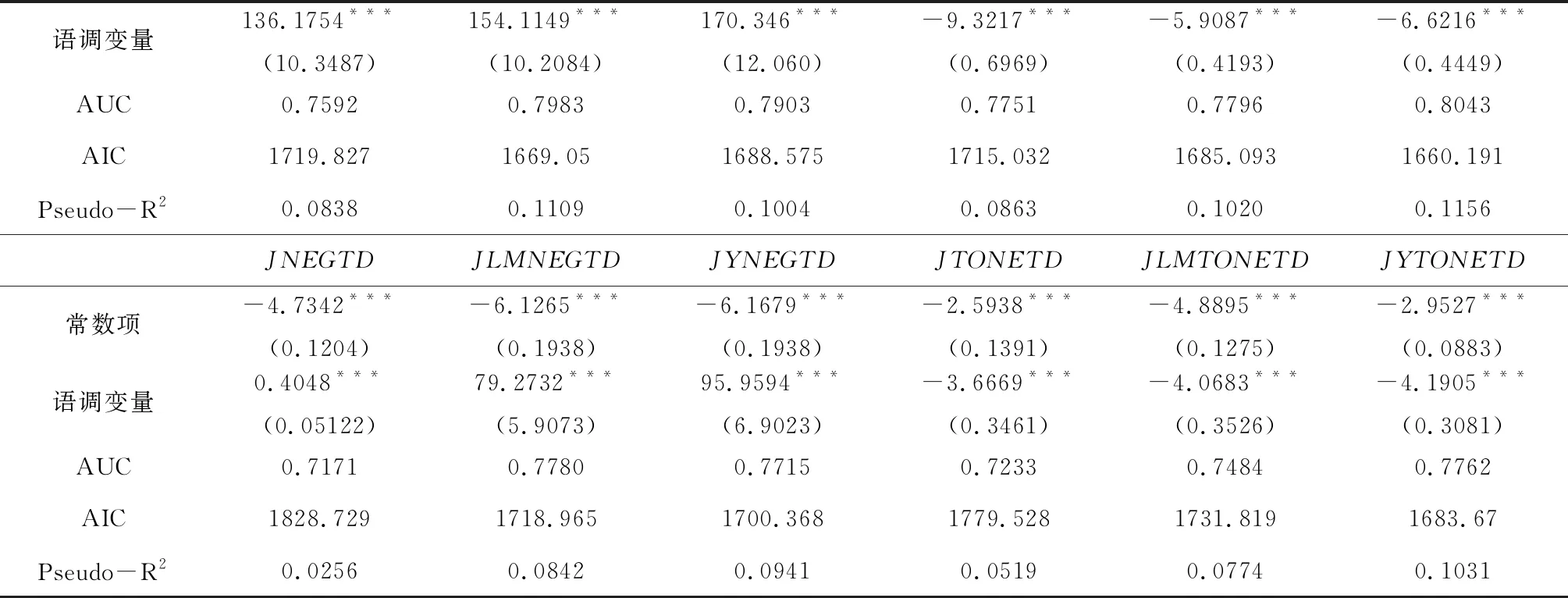
续表1 语调变量对财务困境的预测能力:基于单变量的比较分析
注:***、**、*分别表示1%、5%和10%水平下显著;括号内为标准误。
4.1.2 基于传统模型的比较分析
以传统会计信息模型(Altman财务比率模型)、市场变量模型、混合模型(Shumway模型和CHS模型)为基础,对负面语调和净语调变量加入前后模型的拟合情况进行比较,结果如表2:
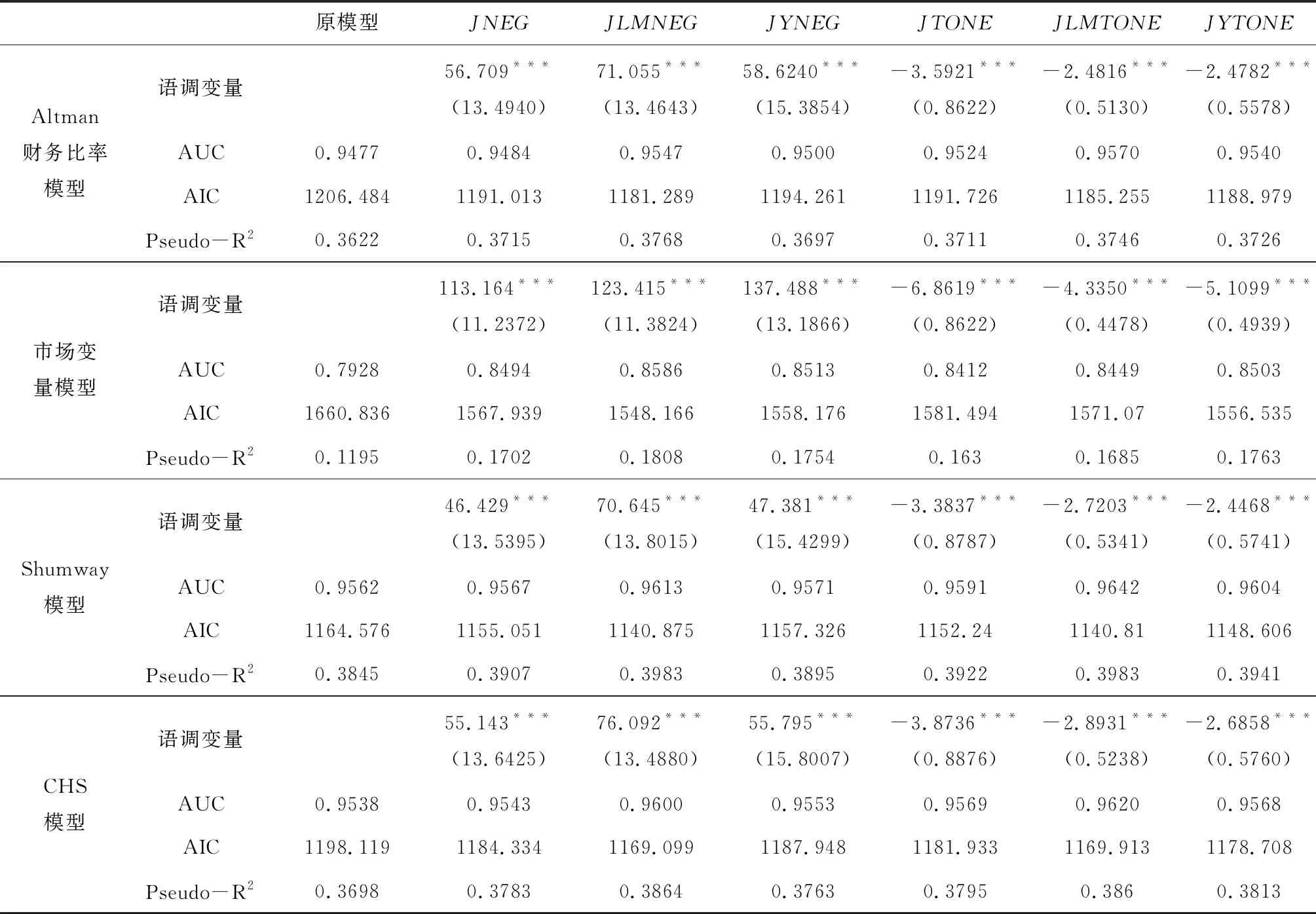
表2 基于JiebaR分词工具的离散时间风险模型的估计结果
注:***、**、*分别表示1%、5%和10%水平下显著,括号内为标准误;本文侧重分析管理层语调对财务困境预测的影响,故未给出对应财务变量和市场变量的估计结果,如有需要可向作者索取,这些变量的估计结果都符合理论预期。
首先,负面语调和净语调变量在所有模型中都显著,其中负面语调变量的系数显著为正,表明文本内容传递的管理层语调越负面,上市公司陷入财务困境的可能性就越大,而净语调变量的系数则显著为负,表明管理层的净语调越正面,上市公司陷入财务困境的可能性就越小;
其次,从模型的拟合情况来看,加入语调变量后,所有模型的AUC、AIC和Pseudo-R2都有一定的提高,其中市场变量模型最为显著,Altman模型、Shumway模型和CHS模型拟合情况的改善相对要小一些,而这三个模型中都包含了财务变量,从这个角度来看,语调变量更多的是对会计信息的补充;
再次,在语调变量中,以LM词表衡量语调时,模型的拟合程度最好,YZZ词表次之,综合情感词典相对最差,这表明根据相关金融文本构建的词表能更好的反映管理层语调,而且对于中文年报文本的分析还是应该以基于年报文本的情感词表为基础,LM词表尽管是由英文根据中文年报内容翻译得到,但效果依然要略优于YZZ词表,而直接从其他领域引入的词典,即综合情感词典在用于财经文本分析的效果要更差一些;最后,负面语调和净语调的结果非常接近,差异很小。
4.1.3 稳健性检验
本文采用以下方法进行稳健性检验:一是以Rwordseg分词工具重新计算管理层的负面语调和净语调,以确保结果不受分词工具的影响;二是在JiebaR分词工具的基础上,采用TFIDF来设定词语的权重,重新计算负面语调和净语调,以确保结果不受特征词权重设置的影响。结果与表2保持一致,只是模型的拟合情况有细微的差别,管理层语调的加入在一定程度上可以提高财务困境预测模型的拟合度,而分词工具、词语权重设置都不会影响结果的稳健性,而且基于公司年报文本的LM词表在衡量管理层语调时的效果相对更好,基于财经新闻文本的YZZ词表次之,不过差异很小,而综合情感词典明显更差。
4.2 基于信息含量检验的分析
为进一步确认管理层语调能否带来一定的信息增量,本文基于离散时间风险模型对不同财务困境预测模型、预期违约概率以及管理层语调的信息含量进行了检验。首先,由Altman模型、市场变量模型、Shumway模型和CHS模型的估计结果对各观测样本出现财务困境的逻辑分值进行预测;然后,将这些逻辑分值以及由预期违约概率pBS和pBSr得到的逻辑分值BS-score和BSR-score分别加入负面和净语调变量单变量估计得到的逻辑分值进行估计;最后结合不同模型的逻辑分值并加入语调变量单变量估计得到的逻辑分值,对其信息增量进行检验。在进行信息含量检验时,加入上一年度上市公司出现财务困境的比率RATE作为基准风险率,根据前面的分析只加入了两个基于LM词表的负面和净语调变量得到的逻辑分值JLMNEG-score和JLMTONE-score。
4.2.1 信息量检验
四个模型的预测结果A-score、M-score、S-score、CHS-score以及由预期违约概率得到的BS-score和BSR-score六个逻辑分值信息量检验的结果如表3所示,其中对每个逻辑分值的检验包括不加入语调变量的逻辑分值、加入负面语调变量的逻辑分值JLMNEG-score、加入净语调变量的逻辑分值JLMTONE-score三个模型。由表3可见:
首先,四个模型和预期违约概率得到的逻辑分值都显著为正,都包含预测上市公司财务困境的重要信息,从Log-likelihood(对数似然比)和Pseudo-R2来看,Shumway模型和CHS模型效果最好,市场变量模型及预期违约概率的效果最差;
其次,在加入负面语调和净语调的逻辑分值后,JLMNEG-score和JLMTONE-score的估计系数都显著为正,而且Log-likelihood和Pseudo-R2也都有一定程度的提高,尤其是在市场变量模型和预期违约概率模型中,可见管理层语调为预测公司财务困境提供了新的信息;
最后,在语调变量的逻辑分值中,加入负面语调逻辑分值JLMNEG-score对Log-likelihood和Pseudo-R2的提高要高于加入净语调逻辑分值JLMTONE-score的结果,从这个角度来看,负面语调所包含的信息量要高于净语调。
4.2.2 信息增量检验
以Altman财务比率模型、基于市场信息的预期违约概率模型和会计信息与市场信息相结合的Shumway模型得到的A-score、BS-score和S-score为基础来对管理层语调的信息增量进行检验,先两两结合,再加入负面语调和净语调变量的逻辑分值JLMNEG-score和JLMTONE-score,最后再将三者结合,并加入负面语调和净语调变量的逻辑分值来进行检验,结果如表4所示。
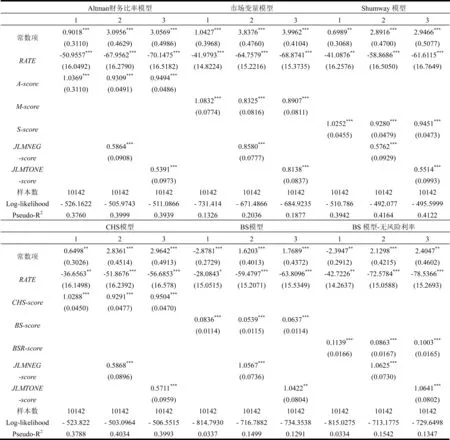
表3 信息量检验的估计结果
注:***、**、*分别表示1%、5%和10%水平下显著;括号内为标准误。
首先,在会计信息、市场信息以及两者相结合的三类模型中,基于市场信息的预期违约概率模型的效果最差,估计系数都不显著,且有多个系数为负;其次为Altman财务比率模型,而效果最好的为Shumway模型,从这个角度来看,在构建我国上市公司财务困境预测模型时,同时结合会计信息和市场信息的效果会更好。
其次,在加入负面语调和净语调变量的逻辑分值后,JLMNEG-score和JLMTONE-score的估计系数都显著为正,另一方面Log-likelihood和Pseudo-R2都有一定幅度的提高,可见管理层语调确实为预测公司财务困境提供了新的信息;而两个语调变量的对比结果与信息量检验相同,加入JLMNEG-score对Log-likelihood和Pseudo-R2的提高要高于加入净语调JLMTONE-score,即负面语调的信息增量同样要高于净语调。
4.3 基于预测能力的分析
对于财务困境模型的预测能力,一般是从样本内和样本外两个角度来进行检验。本文采用Shumway(2001)的十分位数检验方法,将财务困境模型预测的违约概率按照十分位数分成十等分,计算各十分位数中财务困境公司占总的财务困境公司数的比例。
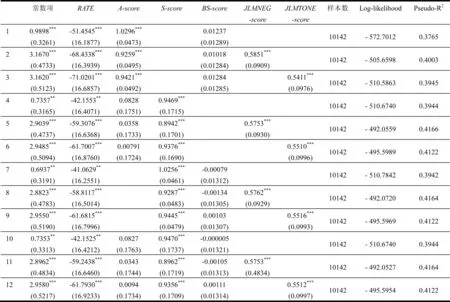
表4 信息增量检验的估计结果
注:***、**、*分别表示1%、5%和10%水平下显著;括号内为标准误。
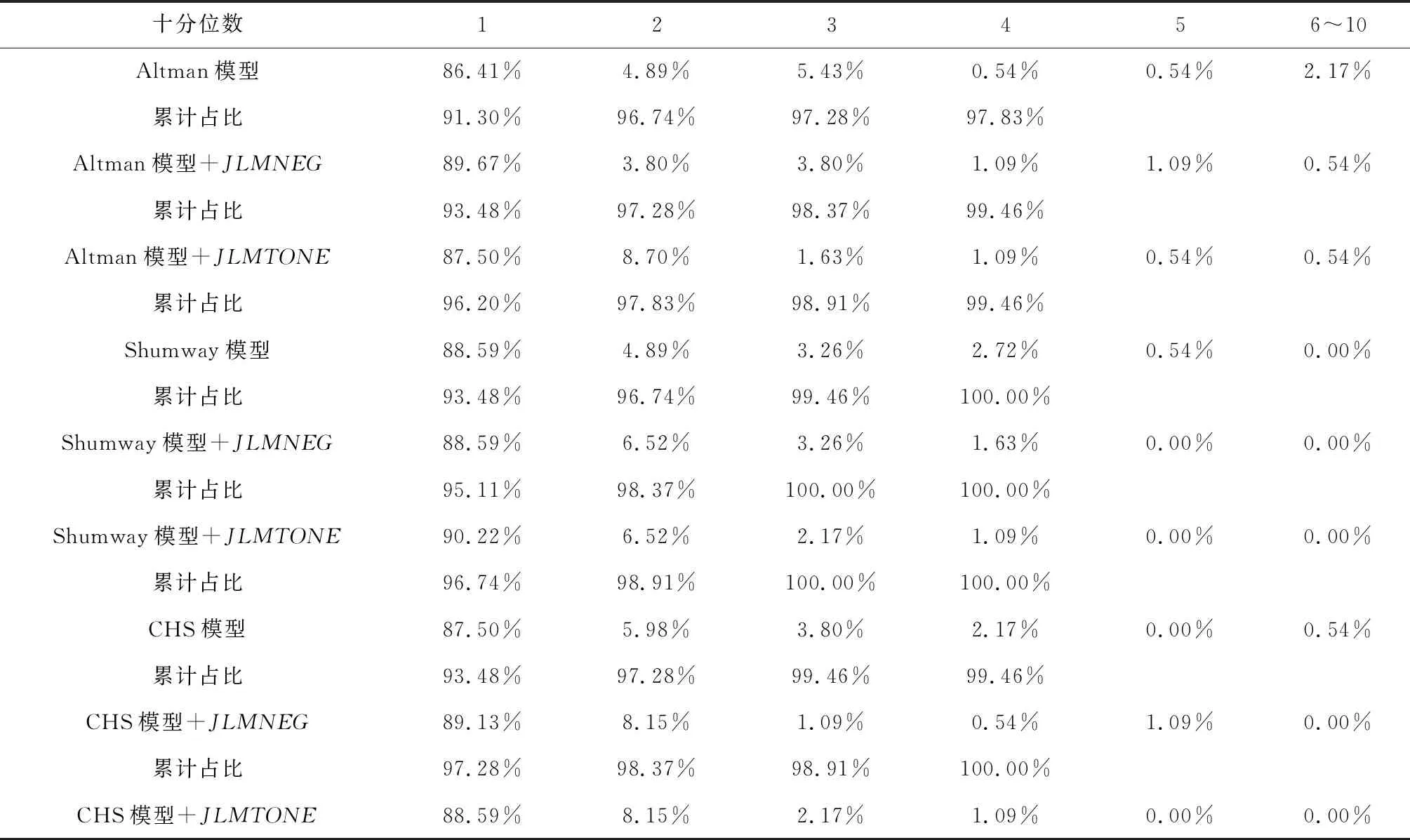
表5 样本内预测的十分位数检验
续表5 样本内预测的十分位数检验
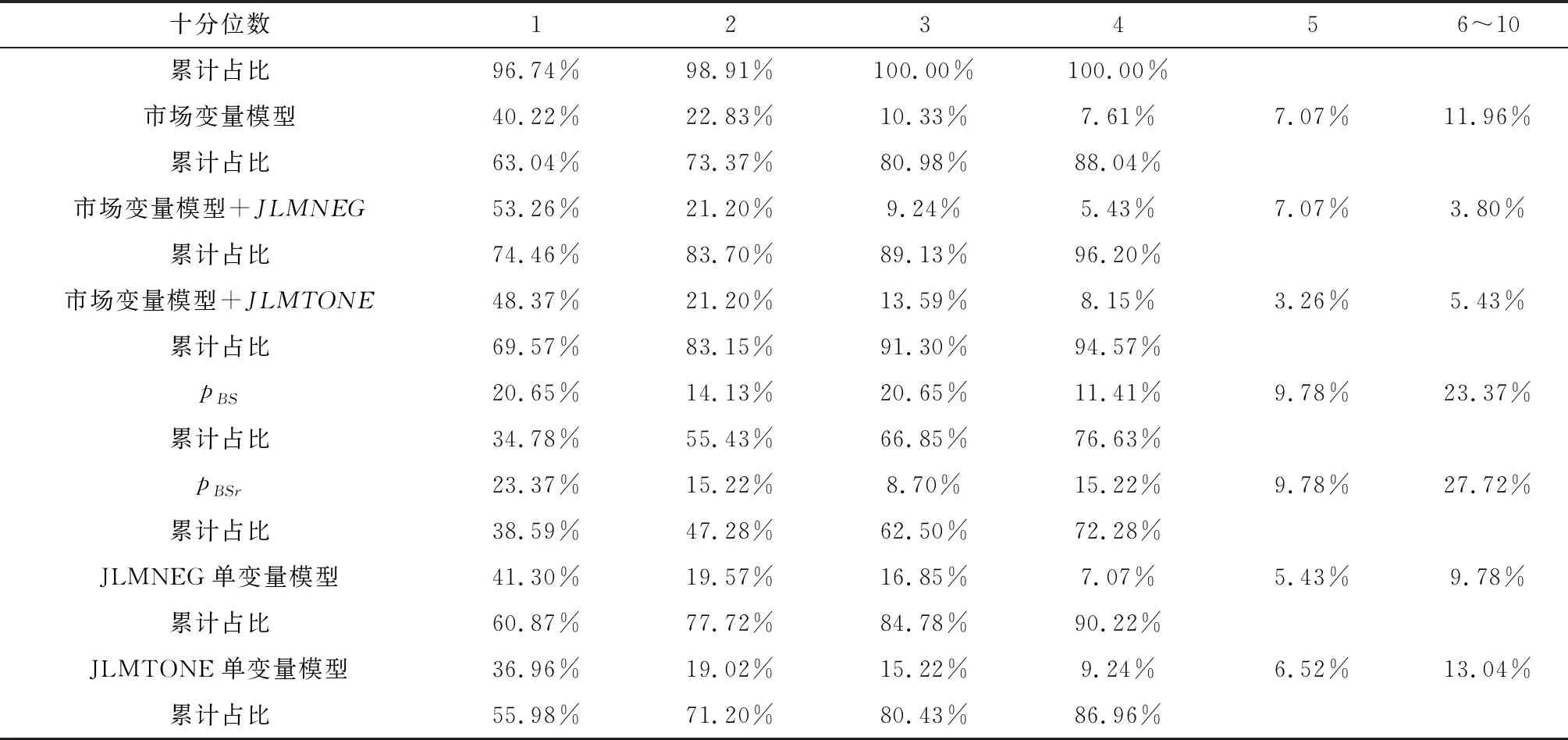
4.3.1 样本内预测
表5给出了四个模型以及加入JLMNEG和JLMTONE后预测的违约概率,作为比较,还给出了预期违约概率pBS和pBSr、以及JLMNEG和JLMTONE单变量模型预测的违约概率。
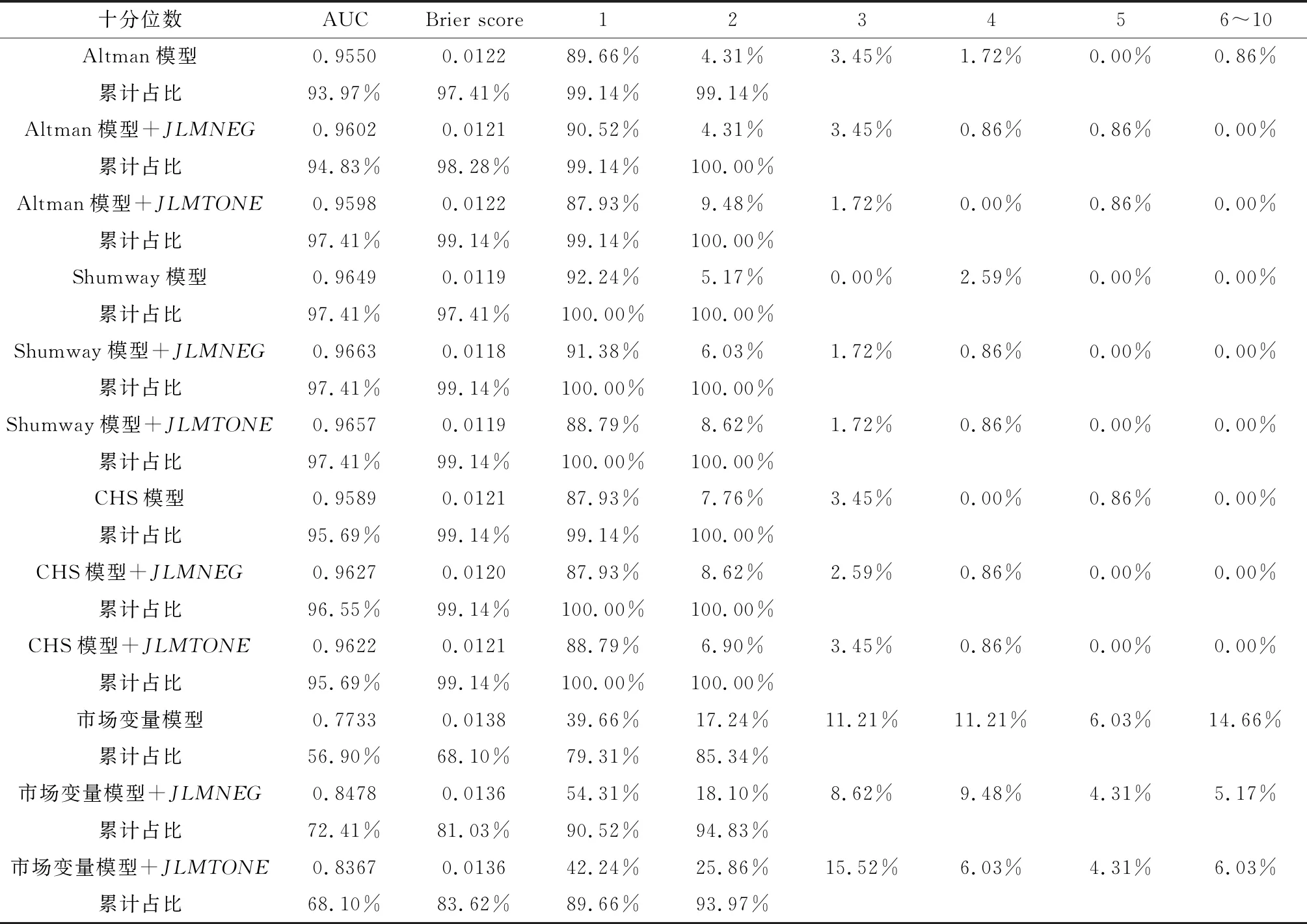
表6 样本外预测的十分位数检验
首先,市场变量模型与预期违约概率的样本内预测能力最差,结合了会计信息和市场信息的Shumway模型和CHS模型预测能力较好,这与之前模型估计以及信息量检验的结果一致;而在市场变量模型和预期违约概率模型中,后者的预测能力更差,表明在市场变量基础上按照Merton违约距离模型计算得到的预期违约概率可能因为过于概括和简化,反而遗漏了一些重要信息而导致更差的预测能力,这与国内近年的一些研究,如蔡玉兰和崔毅的结论[35]是一致的;
其次,JLMNEG和JLMTONE单变量模型预测的违约概率对上市公司财务困境的预测能力比预期违约概率pBS和pBSr还要强,表明管理层语调确实具有一定的财务困境预测能力,而其中预测能力更好的JLMNEG单变量模型预测的违约概率甚至还要强于市场变量模型;
再次,在加入语调变量后,四个模型的预测能力都有一定的提高,其中市场变量模型预测能力的提高最为明显,这与前面的分析一致;在四个模型中,除了Shumway模型外,其他三个模型在加入负面语调变量JLMNEG后,在第一个十分位数上预测能力的提高都明显高于净语调变量JLMTONE,由此可判断负面语调在提高财务困境预测能力上要好于净语调。
4.3.2 样本外预测
对于样本外预测,本文采用滚动窗口(Rolling Window)方法:首先以2008~2010年的样本来估计模型,以此预测2011年的违约概率,然后再以2008~2011年的样本重新估计模型,以此来预测2012年的违约概率,以此类推来对2011年~2016年116家上市公司被特别处理的情况进行预测,表6给出了样本外预测十分位数检验的结果,并给出预测的AUC和Brier score(布莱尔分数)。
从预测准确的公司数量来看,语调变量的加入可以显著提升市场变量模型的预测能力,但对其他三个模型的影响不太显著,在第一个十分位数组上,JLMNEG提高了Altman模型的预测能力,对CHS模型没有影响,而Shumway模型略有降低,JLMTONE提高了CHS模型的预测能力,而降低了Altman模型和Shumway模型的预测能力;进一步扩展到第二个十分位组后,可以发现不管是负面语调JLMNEG还是净语调JLMTONE大多能提高,起码不会降低模型的预测能力。
AUC和Brier score则可以清楚的反映语调变量在样本外预测中的作用。首先,负面语调和净语调两个变量的加入可以大幅提高市场变量模型的AUC,而且Altman模型、Shumway模型和CHS模型也都有一定程度的提高,其中JLMNEG带来AUC的提高更为明显;其次,负面语调变量的加入降低了所有模型的Brier score,而净语调变量的加入只对市场变量模型产生了一定的作用。由此可见,语调变量的加入确实在一定程度上提高了传统模型对财务困境的预测能力,而其中负面语调带来的信息增量价值会更大一些。
5 结语
管理层讨论与分析是上市公司信息披露的重要组成部分,对于分析上市公司的真实状况以及经理人对未来的预期有着非常重要的价值。本文在离散时间风险模型的基础上分析了中文年报管理层讨论与分析部分文本内容所反映的管理层语调对于上市公司财务困境预测的信息价值进行了分析,主要结论如下:
(1)管理层语调确实可以提高上市公司财务困境模型的预测能力。在传统的会计信息模型、市场信息模型以及两者相结合的混合模型中加入语调变量后,上市公司财务困境预测模型的拟合程度都有一定的提高,而且不会因分词工具、情感特征词词典以及特征词权重设置方法的选择而出现变化。信息量与信息增量检验的结果进一步确认了语调变量确实为预测财务困境提供了新的信息,而样本内和样本外的十分位数检验表明语调变量对于财务困境确实具有一定的预测能力。
(2)在各类模型中,语调变量的加入对于市场变量模型的拟合程度与预测能力有显著的提高,而对于会计信息模型以及包含了会计信息的混合模型拟合程度与预测能力的改善则相对有限,这表明信息披露报告文本内容传递的语调信息是对定量财务数据的重要补充,而且这些信息并没有在市场价格中得到充分反映。
(3)在衡量管理层语调时,负面语调的价值要高于净语调,特别是在信息量与信息增量检验以及预测的十分位数检验中效果更为明显,这表明对于中文信息披露报告的分析应该更着重于对负面语调的解释与分析。
(4)在衡量管理层语调时,以特定财经文本为基础的LM词表和YZZ词表的效果要好于没有考虑金融领域词语特殊性的综合情感词典,这表明在财经文本的挖掘分析中并不适合直接从其他领域引入成熟词典来进行分析;而基于年报文本的LM词表尽管是从英文翻译根据中文年报内容得到,但整体效果要略优于YZZ词表,这表明在分析不同来源的财经文本时,最好还是以该来源的文本为基础构建相应的情感词词表。
由此可见,在分析和预测公司企业财务困境时,可通过对其信息披露文本的挖掘和分析来获取有价值的信息,文本分析对于更好的强化信用风险管理有着重要意义。与此同时,本文基于财务困境预测的研究也可以很好的弥补以往更多从市场反应、公司披露业绩等角度来分析信息披露文本内容的信息价值的研究,有助于拓展对公司信息披露,特别是对其描述性文本内容的研究。
当然,本文的研究还存在一定的局限性:一是现有中文分词技术在切分文本时还存在一定的不足,有可能会对研究结论产生一定的影响;二是在文本内容传递的语调衡量时,不管是直接引入国内其他领域的成熟词典,还是由国外年报文本内容构建的特征词词表,也都存在一定的局限性,前者对金融领域词语的特殊性考虑不足,而后者则会对国内公司信息披露的文本内容考虑不足,因而可能最佳的解决方法还是如You Jiaxing在分析新闻媒体报道倾向时以新闻报道文本为基础去构建情感词词典一样,以国内上市公司披露的大量文本内容为基础来构建相应的特征词词典,以更好的分析上市公司信息披露的文本内容。
猜你喜欢
厦门大学学报(哲学社会科学版)(2021年5期)2021-12-21 06:32:48
英语世界(2021年13期)2021-01-12 05:47:51
劳动保护(2019年7期)2019-08-27 00:41:22
疯狂英语(双语世界)(2017年1期)2017-07-01 17:11:11
北方音乐(2017年4期)2017-05-04 03:40:10
国家图书馆学刊(2016年2期)2016-10-09 06:19:31
财经界(学术版)(2015年13期)2015-12-19 05:55:15
湖湘论坛(2015年4期)2015-12-01 09:30:02
图书馆建设(2012年3期)2012-10-23 05:16:30
意林(2012年19期)2012-05-30 07:14:22
