
外星语字母词根查找模型的建立
2019-08-15 03:40季传灵江西理工大学
数码世界 2019年8期
季传灵 江西理工大学
1 引言
在所给定的大量外星语的样本文本,该文本语言只由20 个字母组成,无法知道该语言的具体含义。假设在所有的分段文本中,部分序列都会出现,以英文构词作为依据,很可能这些重复出现的片段是具有具体含义。在记录的过程中,就会发生一些错误,在只考虑替换错误的情况下,要设计合理的数学模型,实现对符合要求的字母片段的查找,以较快的速度找到较多的片段。针对本题中的问题,将每段长度在5000-8000 字母的30 段文本中,找到长度在15-21 字母片段,并且该片段在每段文本中都有出现。
2 模型假设
(1)假定记录文本错误中只有替换错误,且不会出现超过4 个字母的错误
(2)假设所要查找的字母片段,在所有的文本中,每次都会出现
3 问题分析
先要获得只由20 个字母构成的30 段5000-8000 个字母的文本,将文本进行分词处理,再让每个文本进行匹配,在错误允许的范围内每个文本所都出现的片段就是我们要查找的。将所建立的数学模型和编写的算法,对文本进行处理。在得到较好的效果后,对算法进行优化,提高算法的效率,对30 段文本以外的样本进行处理,要达到较快的速度得到较多的片段的效果。
4 模型的建立与求解
4.1 Simhash1 算法的介绍与不足
基于Sim Hash 指纹的近似文本检测是主流的检测方法之一,能将一个文档,最后转换成一个64 位的字节,称之为特征字,可根据文档间的特征字的距离是不超过n,就可以判断两个文档是否相似。通过查阅大量的文献资料,该算法有以下几点不足:
1.Simhash 的hash 值变化敏感,任一字母的微小变动即引起hash 值的巨大变化
2.指纹位数单一, 故导致其会丢失一定量的信息
3.Simhash 算法适用于在文本相似度较高的情况下,但当文档数据量较多时则效果较差
4.2 基于编辑距离模糊匹配2和KMP非线性跳转移位的综合算法
4.2.1 算法建立
步骤一:取第一段文本,将所有的数据映射为一个数组的数据结构,以6 个单词为间距对文本进行平移连续切词,每隔一个字母移动一次,得到一个切词a[i](0 <= i <= 5000),所以能得到5000 左右的片段;同理将第二段的文本也按此法进行切词得到b[j](0 <= j <= 5000)。
用伪代码描述如下:
a[i]={"第一段火星文"};
for(i=0; i++; i<=5005)
{
片段i:A[i]={a[i]~a[i+5]};
}
步骤二:将步骤一中的切词与余下29 段文本分别进行编辑距离的模糊匹配;此模糊匹配分为两步:(1)非线性跳转移位;(2)利用编辑距离算法进行模糊匹配;
4.3 编辑距离算法的定义及步骤
编辑距离算法是根据二个字符串的差异程度的检测,检测方式是计算将一个字符串变成另一个字符串的最少操作次数。
编辑距离算法步骤:
a.先将第一个文本段的第一个字母片段a[0]与第二段所得的第一个切词b[0]进行模糊匹配,计算其匹配度。

b.将a[0]与b[i]相匹配,且匹配度符合容错率3k ≤2,则将a[0]与余下的28 段的字母片段相比较;若a[0]与b 段中的字母片段匹配时,匹配度不符合其容错率,则将a[0]片段丢弃;

c.当a[0]与剩余的字母片段相匹配时,都满足匹配度符合容错率k ≤2,a[0]就是我们所要找的片段;若a[0]与其中一段不匹配时,则停止匹配。将a 段的a[1]与余下的片段相匹配,重复步骤b;

d.在执行完上述步骤之后,直到找到a[i]与其余的文本中的字母片段模糊匹配的匹配度符合容错率k<=2,则a[i]就是我们要找的片段。
5 模型的改进
针对前文提出的用KMP 来实现的非线性跳转移位算法的不足之处,主要体现在其时间复杂度较大。如果某个字符匹配成功,模式串首字符的位置保持不动,仅仅是i++、j++;如果匹配失配,i 不变,模式串会跳过匹配过的next [j]4个字符。整个算法最坏的情况是,当模式串首字符位于i - j 的位置时才匹配成功,算法结束。
BM 算法5 是由Bob Boyer 和JStrother Moore 提出的,其基本思路是:首先设计一个数组bm Bc[],如bm Bc[‘K’](表示坏字符‘k’在所给的模式串中的最右边所出现的位置与模式串末尾之间的长度),当匹配时遇到坏字符,所给的模式串要移动 shift(坏字符) = bm Bc[T[i]]-(m-1-i) 的距离,(T[i]是指在i 位置上的坏字符,(m-1-i)是指坏字符的位置与模式串末尾之间的长度),当坏字符位置与在模式串出现坏字符位置的距离为负时,模式串向后移动一位,重新开始匹配,因为有好后缀规则,移动时的距离选择较大的。如图 2 所示:
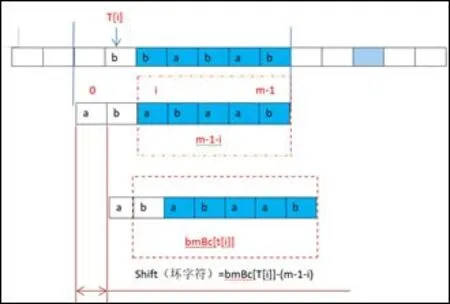
图 2 bm 流程图
改进方案为:在该题中,考虑本题每个片段可能有4 个字母替换错误的情况,我们可以先对要匹配的片段最后四位进行依次匹配,如果这四个后缀字母都不匹配,则放弃继续匹配。此时再用BM 算法,即将最后一个后缀字母判为“坏字符”,然后将模块字符直接移到坏字符后面一格,余下的所有片段按该步骤循环进行。
6 结束语
该模型是从第一段文本段取15-20 的字母片段,如果在余下的每一文本段里找到了一个符合题意的字母片段,放弃继续匹配,但这样最后得到的词根不知道其在30 段文本中出现的频率次数,所以数据利用价值不高,不太利于专家对外星语的研究。若将每一个字母片段赋予其权重,权重即是最后得到的词根在30 段文本出现的频率,使所得到的外星词根按重要程度进行排列。
猜你喜欢
现代英语(2022年16期)2022-11-20
英语世界(2022年9期)2022-10-18
汉字汉语研究(2020年2期)2020-08-13
现代装饰(2020年6期)2020-06-22
小学生学习指导(低年级)(2019年12期)2019-12-04
电子制作(2019年19期)2019-11-23
电脑爱好者(2019年8期)2019-10-30
学苑创造·B版(2017年3期)2017-05-03
校园英语·中旬(2016年6期)2016-05-14
科技视界(2015年24期)2015-08-15
