
一种结合全局和局部特征的图像描述生成模型
2019-08-14 09:41靳华中刘潇龙胡梓珂
应用科学学报 2019年4期
靳华中, 刘潇龙, 胡梓珂
湖北工业大学计算机学院,武汉430068
随着计算机视觉和机器翻译的发展,由图像自动生成准确的文字描述成为可能.在机器翻译过程中,注意力机制能够区别对待图片中不同的局部信息,使图像自动生成越来越准确的描述文字,从而成为目前生成描述图像自然语句的研究热点.图像描述生成任务是计算机视觉和机器翻译两个领域的综合应用.首先,借助计算机视觉技术自动完成图像解译,接着根据机器翻译模型将解译的内容表达成一段自然语言.图像描述生成任务虽然面临诸多挑战,但应用前景较好.例如:在网络上利用图像描述生成文字进行基于语义的图像检索,能够弥补基于简单视觉特征的图像检索方法的不足,帮助人们找到内容更加准确且含义更加接近的图像;视频描述生成有助于视频内容加标注.此外,它还可以帮助视觉障碍者理解图像内容.目前,通常采用编码器-解码器的框架解决图像描述生成任务,是因为这种框架在许多领域中均优于其他传统方法.其中,编码器可以提取图像特征进行编码,形成更紧凑的形式;解码器可将编码的图像信息翻译成自然语言.
解决图像描述生成任务时,注意力机制能提高语义表示的准确性,因而受到了越来越多的关注.该机制预先保留编码器对输入序列的中间输出结果和图像特征对应的位置信息,接着训练一个模型便于选择性地学习输入,最后在模型输出时将输出序列与之进行关联.也就是说,输出序列中每一项的生成概率取决于在输入序列中选择了哪些项.生成图像描述文字时,注意力模型可以自动关注图像显著物体[1],能在给定已生成单词的前提下让生成下一个单词的过程与视觉感知体验对齐[2].
现有的基于注意力机制的图像描述生成模型通常基于图像局部特征提取信息,这些模型共同的缺点是忽略了图像全局特征,以致生成的句子缺少了描述图像的整体信息.为此,本文引入注意力机制并提出了一种结合图像全局特征和局部特征的图像描述生成模型,可以允许不同粒度图像特征作为模型的输入;然后搭建了图像描述生成的实验环境;最后将设计的模型在微软COCO 数据集上进行训练和测试,并对比分析了不同模型的性能.实验表明,本文提出的模型在识别目标区域与生成相应语句之间的对应关系更加贴近人类理解方式,即识别目标区域与生成语言的对齐更加合理.
1 相关工作
图像描述生成一直是计算机视觉和机器翻译领域的一个挑战性问题,描述图像不仅需要识别图像目标以及不同目标之间的关系,而且还要表示为自然语言.文献[3-7]依据预先定义的模板将检测到的视觉元素生成句子[3-7];文献[8-9]首先基于检索模型在训练集中找到类似的图像,然后检索并组成新的句子.这些方法生成的句子简单又有限,且不能描述测试图像中的特定内容.
随着机器翻译和目标检测的发展,出现了基于神经网络生成图像描述的方法[10-11].这些方法在机器翻译中通过引入编码器-解码器框架将图像直接转换为句子[12],首先根据深度卷积神经网络(convolutional neural network, CNN)将图像编码为不同目标,然后通过循环神经网络(recurrent neural network, RNN)解码后生成描述图像内容的有意义句子.文献[11]提出了多模态循环神经网络(multimodal recurrent neural network, m-RNN),创造性地将CNN和RNN 结合起来,以期解决图像标注和图像语句检索等问题.传统的CNN 和RNN 组合模型没有明确地表示高级语义概念,而是试图直接将图像特征翻译成文本信息.
针对RNN 解码方面的不足,Google 以长短期记忆(long short-term memory, LSTM)代替RNN 提出了NIC 模型.该模型采用已训练的CNN 模型提取图像特征,且只在开始时输入一次[13].预测下一个单词时,解码器试图关联图片中的不同部分.基于上述构想,文献[1]将注意力机制应用到图像描述生成中,提出了soft-attention 与hard-attention 模型.该模型可以充分关注图像局部特征,原因是注意力机制打破了传统编码器-解码器结构在编解码时依赖于内部一个固定长度向量的限制[14].
现在许多方法试图改进注意力机制,以便更好地帮助人们理解语句生成过程,使得模型学习到的对齐关系接近人类的直观认知过程.文献[15]结合空间和信道方向的注意力提出了一种新的卷积神经网络.大多数方法强制要求在每个单词生成与视觉注意相关联,然而解码器在预测诸如“the”和“of”的非视觉单词时可能并不需要来自图像的视觉信息.文献[16]提出了一种具有视觉哨兵的新型自适应注意模型,在解译文字序列的每个单词时决定是否关注图像以及关注哪个图像区域,以便提取更有意义的单词序列信息.文献[17]提出了一个自下而上和自上而下的组合注意力机制,能让每个图像区域关联相应的特征向量并确定相应的特征权重,从而计算目标对象与其他显著图像区域之间的注意力权重.在编码器-解码器的框架下,已有的注意力机制方法在解码的不同时刻可以关注不同的图像区域,进而生成更合理的词,可是在面对复杂、多目标场景时仍然存在问题[18].图像生成文字描述的过程是先建立局部图像区域之间的联系,再构建图像整体内容和信息.然而,图像全局和局部特征的粒度不同,遗憾的是现有文献只考虑了图像局部特征的情形而没有将不同粒度的特征作为输入,于是本文提出将全局特征信息加入图像描述生成模型以表达诸如图像场景之类的图像整体信息,使得目标之间的关系表述得更加合理,更加准确.
2 结合全局和局部特征的图像描述生成模型
本节介绍基于局部特征和全局特征的图像生成描述文字的模型架构,如图1 所示.
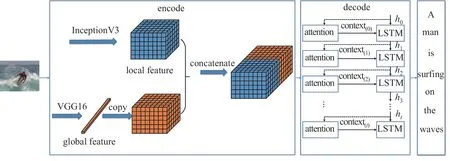
图1 结合全局和局部特征的图像描述生成模型结构Figure 1 Image caption model architecture combining global and local features
本文提出的模型与Oriol Vinyals 等类似,也采用编码器和解码器的基础框架结构[19].编码器主要负责对输入的图像进行编码,以便捕获图像中包含的对象及其相互关系,表达各自的属性和涉及的活动.在上述结构框架中,本文分别使用InceptionV3 网络和VGG16 网络提取图像的局部特征和全局特征,并将全局特征和局部特征连接起来形成编码器的结果作为解码器的输入.解码器是一种语言模型,主要负责对图像进行解码,输出词汇表中单词的概率分布.本文先将编码器提取的特征和LSTM 的状态输入注意力模型,得到一个图像目标的上下文信息;然后将上下文信息输入LSTM 网络并计算每个单词的概率分布,完成句子的翻译[20].
2.1 编码器
在编码器端,本文采用InceptionV3 网络提取图像局部特征.具体做法是保留网络中softmax 函数前的卷积层特征向量,并将原向量从8×8×512 拉伸成64×512 维.图像全局特征则由VGG16 模型负责提取,其形状为1×4 096.首先将两个特征向量输入一个包含256 个单元的全连接层,则全局特征和局部特征经过全连接后的输出为1×256 维和64×256 维的特征向量;然后将输出后的全局特征扩展为64×256 维;最后将全局特征和局部特征连接起来,形成图像特征的编码结果.
2.2 注意力机制
注意力机制保留LSTM 编码器对输入序列的中间输出结果,然后训练一个模型进行选择性的学习,最后将模型输出序列与输入序列进行关联.本文使用的注意力机制遵循了Bahdanau 的方法[21].注意力模型的输入为编码器对图片编码后的结果a(t')和LSTM 网络的前一个状态ht−1,输出为生成第t 个单词时的上下文信息context(t).注意力模型的示意图如图2所示.
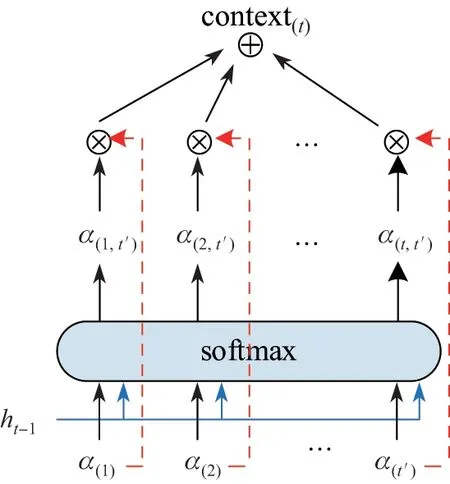
图2 注意力模型示意图Figure 2 Diagram of attention model
实现这种机制的方式如下:在时刻t 计算输入序列的每一个区域i 对应的权重a(t').在图2 中,α(t,t')表示在生成第t 个单词时上一时刻t'图像特征的权重.因满足输入序列的各个区域权重之和为1,于是有

式(1)通过softmax函数来实现,其中T 表示特征的数量,本文取T = 64.context(t)的计算由两部分组成:一个是已计算的区域a(t'),它表示第t'个特征;另一个是上一时刻t'的信息α(t,t'),其计算公式为
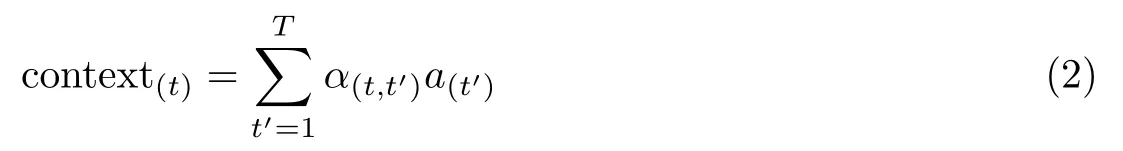
2.3 解码器
本文将LSTM 网络作为编码器.它是一种特殊的RNN 记忆网络,可以学习并处理LSTM信息,其优势在于能够建模并预测信息序列隐含的上下文依赖关系.本文利用LSTM 学习图像场景中目标区域的空间关系,通过训练集构建了一个5 000 个单词的词汇表,分析不同区域序列中隐含的上下文信息,计算词汇表中的每个单词的概率,以完成图像内容的表达.LSTM网络结构如图3 所示.
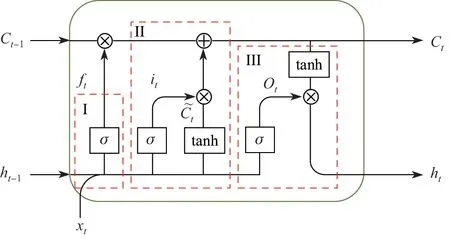
图3 LSTM结构Figure 3 LSTM structure
在图3 中,σ表示sigmoid 激活函数,σ ∈(0,1);xt表示当前时刻t新信息的输入,ht−1表示上一个时刻t-1的隐藏状态,Ct表示t时刻的细胞状态.3 个虚线矩形框I、II、III 分别表示遗忘门、输入门、输出门.LSTM 的关键在于保护和控制细胞状态,在具体学习过程中通过3 个门结构的不同状态确定下一步新信息是否舍弃或者存放在细胞状态中.每一时间步中细胞状态都会根据前一时间步的信息更新,并传递到下一个信息序列中去.虚线矩形框I 对应的数学描述为

ft根据xt和ht−1的数值来决定上一时间步中信息遗忘程度.输入门对应的数学表达式如下:
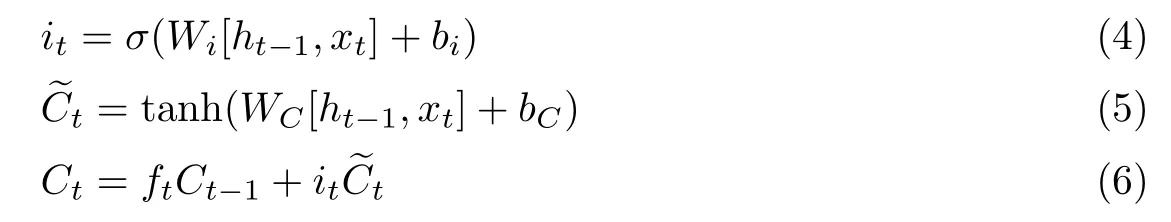
细胞状态Ct的更新由门值ft、it以及上一个时间步细胞状态Ct−1决定.由此可见,新信息输入、上文信息以及隐含状态的信息共同决定了下一步的时序信息.输出门的计算公式如下:

式中,W 和b 表示学习训练的网络参数.先将tanh 函数的输出与sigmoid 函数的输出相乘以确定隐藏状态应携带的信息,再将此隐藏状态作为当前细胞的输出,并把新的细胞状态和新的隐藏状态传递到下一个时间步长中去.
3 实验结果与分析
3.1 模型参数与数据集
为了与现有技术进行比较,本文在tensorflow 平台上搭建图像描述生成模型,通过一系列实验以多个度量指标评估模型的有效性.在编码阶段,分别采用InceptionV3 网络和VGG16模型提取图像的局部特征和全局特征.在解码阶段,采用LSTM 网络生成自然语言.在模型训练阶段,采用Adam 优化算法训练模型,学习率为0.01,batch 大小为128.本文模型在一块RTX2070 显卡上进行训练,总共耗时约为15 h.
本文以MSCOCO 作为数据源,其中训练集、验证集、测试集图片数量分别超过4万幅,每幅图像均由标注者用5 个相对直观且无偏见的句子添加注释.
3.2 评价准则与实验结果
本文以常用的BLEU[22]、Meteor[23]、Rouge[24]评价指标评测机器翻译的准确性.BLEU的优点是它匹配信息的粒度是n-gram 而不是词,且考虑了更长的匹配信息;在本文的实验中,n 取1~4.BLEU 的缺点是不管匹配多大的n-gram,都会同等对待其重要性.Meteor 是将模型给出的译文与参考译文进行词对齐处理,通过计算词汇完全匹配、词干匹配和同义词匹配的准确率、召回率和F 值进行评测, 其初衷是避免生成很“碎”的句子,ROUGE 则是通过计算召回率来评测句子的匹配程度.
针对上述3 个评价准则,在COCO 数据集上分别评估Google NIC、soft-attention、本文模型,评估结果如表1 所示:

表1 不同模型在MSCOCO 数据集上的得分Table 1 Scores for different models on MSCOCO dataset
从评价结果来看,本文模型的各个评价指标均优于NIC 和soft-attention 模型.
本文在MSCOCO 测试集中选取了所有图像进行实验,部分实验结果如图4 所示.每幅图像下方对应的句子是本文的模型描述图像生成的句子.由实验结果可知,经本文模型翻译的句子与图像实际的内容相比,句式完整,所表示的含义准确且有意义.
3.3 结果分析
编码器的任务是描述图像所包含的对象及其相互关系,从而表达不同对象的属性、特征和所涉及的活动.从图像的局部区域来看,常常能够看到图像所包含的细节信息,比如目标及其属性等.细节信息通常描述了图像的局部特征,分布在相对不大的图像区域里.从图像的整体区域来看,往往能够发现图像的全局信息,比如目标之间的相互关系以及体现图像整体结构的场景等.这些较大尺度范围的信息反映了图像的全局特征,分布在整个图像中.本文采用InceptionV3 和VGG16 网络模型将提取的图像局部特征和全局特征连接起来形成编码器的结果,然后将其全部送入解码器进行句子的翻译.在MSCOCO 数据集上将本文方法与基于图像局部特征的soft-attention 模型进行了对比分析,其注意力权重可视化图如图4 所示.
图5 包括3 组可视化图,而每一组图下方的英文句子给出了本文模型对应原图生成的语言.左边为原图,中间图和右图分别给出了本文模型和soft-attention 模型关于句中下划线单词的注意力权重可视化结果.在图(a)中,court 在整体图像所占比例较大,属于图像的场景信息.与soft-attention 模型相比,本文模型更加关注球场场地、球网和球拍部分,以及三者之间的关联关系,其中对球场的关注度最大.Soft-attention 模型方法则更加关注图像上半部分,这部分信息包含了较少的court 信息.因此,本文模型在理解图像视觉区域目标和生成描述图像的目标语句方面都更为合理而准确.在图(b)中,bear 在图像所占比例很大,属于场景信息.当生成和描述bear时,本文模型比原模型更加关注图像中泰迪熊的头部.在图(c)中,当生成airplane 时,本文模型更加关注飞机以及场地之间的关联性.由上述分析可知:相比于只关注图像局部信息的模型,本文模型在生成图像的描述文字时关注图像的位置更加合理,能够更准确地发现图像目标之间的语义关系,也更能理解整个图像的场景信息.

图4 本文模型对图像的文字描述结果Figure 4 Results of the proposed model for image caption
4 结 语
本文针对已有图像描述生成模型存在的不足,提出了一种结合局部和全局特征的带有注意力机制的图像描述生成模型.在图像编码阶段,本文通过全局特征和局部特征相结合的方式获得了更加完整的图像信息,在这种情况下注意力机制生成的每一个单词均附带图像场景的整体信息,因此本文模型输出的结果与图像场景一致性更好.将本文提出的模型在微软COCO 数据集上进行模型训练和测试,实验结果表明:本文模型能够关注图像合理的位置,充分描述图像目标之间的活动关系,准确挖掘整个图像的场景信息,生成更准确、更完整、更有意义的句子.

图5 本文模型与soft-attention 模型的注意力权重可视化图Figure 5 Visualization of attention weight by the proposed model and soft-attention model
猜你喜欢
网络安全与数据管理(2022年1期)2022-08-29
数学物理学报(2022年4期)2022-08-22
数学物理学报(2022年2期)2022-04-26
小学生必读(低年级版)(2021年10期)2022-01-18
小学生必读(低年级版)(2021年11期)2021-03-09
小学生必读(低年级版)(2021年12期)2021-03-04
家庭影院技术(2019年8期)2019-12-04
金桥(2018年4期)2018-09-26
制造技术与机床(2017年7期)2018-01-19
西安工程大学学报(2016年6期)2017-01-15
