
汉语篇章理解研究综述*
2019-08-13 05:06王红玲周国栋
软件学报 2019年7期
孔 芳, 王红玲, 周国栋
1(苏州大学 计算机科学与技术学院 自然语言处理实验室,江苏 苏州 215006)
2(江苏省计算机信息处理技术重点实验室,江苏 苏州 215006)
1 引 言
人们理解自然语言通常是在篇章级进行的.作为自然语言处理的一个核心任务,篇章分析(discourse analysis)的主要任务就是从整体上分析出篇章结构及其构成单元之间的语义关系,并利用上下文理解篇章.根据不同的篇章分析目的,篇章单元及其关系可以表示为不同的篇章基本结构.篇章结构可以是篇章内部关系的不同结构化表达形式,主要包括修辞结构、话题结构、指代结构、功能结构、事件结构等范畴[1].从语言学角度讲,这些不同的结构表达形式从不同的角度对篇章进行描述;从计算的角度来看,它们可用线性序列、树和图等数据结构进行抽象表示.随着词法、句法分析技术的不断成熟,篇章分析已成为制约自然语言处理发展的一个瓶颈.
作为篇章分析的基本概念,篇章(discourse)又称为语篇或文本,是由一系列连续的词、短语、子句、句子或段落构成的语言整体单位[1].这里,词被认为是自然语言中有意义的最小单位,相继可以构成短语、子句和句子,句子又可以构成段落,并最终构成篇章.需要强调的是,篇章不是其构成单元的无序堆砌,只有当构建的整体单位上下连贯相互关联,所含信息整体一致,表达完整的思想和意图,才能具有明确的意义,从而称为篇章.以图 1给出的两个例子进行对比说明.在例1中,尽管每个独立子句语义正确,句法完整,但是顺次连接在一起并不能够构成一个篇章.原因在于,这些子句所表达的意义彼此没有关联,难以形成一个整体,也无法表达明确的主题.与此相比,例2中,尽管有些子句的句法成分缺失(例2所示的段落由6个基本篇章单元构成,基本篇章单元分别用(a)~(f)表示;〈〉扩起的内容表示篇章关系中缺省的连接词;[]表示对应子句在该位置缺少相关的句法成分),然而借助于句子之间的意义关联,可以构建形成一个以“李四”作为中心话题的语言整体,因而构成了一个篇章.
篇章一般围绕某个话题展开.篇章信息的一致性(篇章信息性)和篇章意图的整体性(篇章意图性)通常表现为一个话题,该话题的完整性从形式和内容两方面分别体现为篇章的两大基本特性,即篇章连贯性(coherence)和篇章衔接性(cohesion).篇章衔接性和篇章连贯性分别从内容和形式两个方面保证了篇章所要表达的意图性,即作者所要表达话题的正确性和可理解性,二者相互依赖,相互补充.
具体而言:一方面从篇章连贯性角度,话题在形式上的完整性往往体现为某种篇章基本构成单元通过递归组合,基于不同层面的逻辑关系联接,形成一种修辞上的层次化结构,即篇章修辞结构.如图2所示,B和C之间构成并列关系,B和C都是中心,BC的组合和A构成递进关系,ABC的组合和DEF的组合之间构成转折关系,DEF的组合为中心.各基本篇章单元组合后形成高一级篇章单位,进而通过再组合形成更高一级篇章单位,如此层层组合,最终可以表示成一棵篇章修辞结构树.各层篇章单位赖以组合的原因在于其间存在一些为数不多的、反复出现的修辞结构关系(如并列、递进等),这些修辞结构关系有时以连接成分作为形式标记(如例 2中的“既…又…”),有时则完全隐含(如例 2中的缺省连接词,“〈而且〉”).
上述篇章修辞结构的分析结果对篇章话题理解非常重要.例如,在自动问答系统中,通过例2中的因果关系,可以较容易地自动抽取出相关问题的答案:“领导非常器重他”的原因是“不论做啥事情,他都认真负责”.又譬如,对于自动文摘而言,根据图 2中最高层的“转折”关系,可以得出“基本篇章单元 DEF的组合”比“基本篇章单元ABC的组合”更重要;而对于次一级“因果”关系而言,“基本篇章单元 F”可能比“基本篇章单元 DE的组合”更重要;如此层层推进,最终可以得到该段篇章的核心话题,即为“基本篇章单元 F”.当然,上述推进过程的实现,主要依赖于篇章关系传递性及中心指向原则.
另一方面,从篇章衔接性角度来看,话题在内容上的完整性往往体现为思维的放射性与表达的线性之间的有机联系.这里所谓“思维的放射性”是指一个话题(或称主题)由若干子话题(或称小主题)构成,而“表达的线性”则是指各分话题的排序应符合思维的逻辑性和次序性,两者一起构成篇章话题结构.
譬如仍然以例 2作为分析对象,对于自动问答系统而言,我们能够利用图 2所示的篇章修辞结构为问答系统提供为什么“领导非常器重他”的答案(即回答“Why”问题),但是,如果需要提供“‘他’是谁?”这样的问题答案(即回答“Who”问题)时,图2所示的篇章基本结构就显得力不从心了.这时,需要我们构建如图3所示的篇章话题指称结构来解决该问题.通过其所含的指称链接关系,我们就能够回答问题“‘他’是谁?”中的“他”即指“李四”.不过,与上述篇章修辞结构类似,图3中的单一篇章指称结构也只能够解决“Who”这一类问题,对“Why”问题无能为力.
不同篇章基本结构及其关系的研究可以提供不同层面的篇章理解.显然,篇章修辞结构和篇章话题结构这两者相互依赖,相互补充.对于需要解决包含5W1H问题(Who,Why,Where,When,What,How)的篇章理解而言,迫切需要联合不同类型的篇章结构共同解决不同类型的篇章理解问题.
2 国内外相关研究
篇章理解是自然语言理解的最终目标.认知科学家和语言学家对这个问题的研究,始于20世纪70年代.其中,概念依存(concept dependency)理论[2]开启了篇章理解研究的先河,脚本(script)方法紧随其后,用于分析理解某种具体的场景“故事”.通过对内容的简化处理,类似脚本方法的技术思想已经在信息抽取(information extraction)领域得到成功应用.然而,脚本方法的缺陷在于对领域所在场景存在过度依赖,导致脚本的构建需要随时同步场景变化.这对于有些无法表示为场景的篇章而言,很难采用该类方法加以分析理解,因而进一步需要发现更为通用及开放的结构来表示篇章.为达到此目的,通过探寻篇章的基本特征来寻求解决之道不失为可行方法.
篇章的 7个基本特征[1]已被自然语言处理领域的研究者广为接受,其中,前 4个基本特征,即连贯性(coherence)、衔接性(cohesion)、信息性(informativity)及意图性(intentionality)更是有力地促进了自然语言处理研究的发展[3-9].通过分析篇章的衔接性和连贯性,可以发现篇章表层的形式表示;而通过分析篇章的信息性和意图性,则可以挖掘篇章的语义特征.同时,后两者的分析过程需要以前两者为基础关联起来综合考虑.例如,从内容表示角度,篇章的信息性注重新旧信息的变化推进,强调在符合衔接和连贯的特点下,如何合理、恰当地向读者传递新信息.相比于传递新信息的篇章信息性,篇章意图性更关注作者通过传递新信息后所产生的某种期望影响,这也反映了读者对篇章的理解程度.因此,篇章的信息性和意图性与篇章理解存在着密切的深层关系.
无论西方语言或者汉语,篇章的衔接性和连贯性都是最需要关注的两个问题,是篇章的两个最基本特征[1].连贯体现篇章的整体性,是篇章中句子级的关联,采用句子间的语义连接来表示篇章的关联.而衔接是一种词汇级的关联,采用词汇(或短语)之间的语义关联来表示篇章中各语言单元之间的关联.从表达和内容两个角度,通过篇章的连贯性和衔接性的共同作用,篇章的信息性和意图性得以体现,即作者所要表达话题的正确性和可理解性得到保证.
可以看到,篇章的信息性和意图性的研究是以篇章的衔接性和连贯性研究为基础的,目前,篇章分析的研究主要集中在衔接性和连贯性的研究方面,下面分别从篇章结构分析的理论研究、资源建设、计算模型这3个方面,重点探讨篇章修辞结构(体现篇章连贯性)和话题结构(体现篇章衔接性)这两种结构,从而充分展现国内外研究现状.
2.1 理论研究
篇章结构理论主要有浅层衔接理论[10]、Hobbs模型[4,5]、修辞结构理论(rhetorical structure theory)[6,7]、宾州篇章树库理论(Penn discoursetreebank)[11,12]、意图结构理论(intentional structure theory)[8]、主述位结构理论[13]、主位推进理论(thematic progression theory)[14,15]、句群理论[16]、复句理论[17,18]、基于连接依存树的汉语篇章结构(connective-drivendependency tree)理论[19,20]、广义话题结构理论[21-23]等.
2.1.1 篇章修辞结构理论体系
涉及篇章修辞结构理论体系的理论主要包括Hobbs模型、修辞结构理论、宾州篇章树库理论、汉语句群理论、汉语复句理论、基于连接依存树的汉语篇章结构理论等.
(1) Hobbs模型
Hobbs模型[4,5]提出篇章单元和篇章单元间的连接关系是组成篇章结构的基本部分.其中,篇章单元可以是子句、句子、句群,甚至是篇章本身,而连接关系是指篇章单元间的语义关联性.Hobbs定义了 12类关系,包括:详述、并列、结果、背景和时机等.
(2) 修辞结构理论
修辞结构理论(RST)[6,7]是一种基于树状模型的修辞结构理论,早期应用于计算机文本自动生成,目前主要作为篇章结构和功能描述研究的理论基础.RST与Hobbs模型具有很大的相似性,共定义了4大类、25小类修辞关系,每个关系可连接两个或多个篇章单元.如果修辞关系连接的篇章单元间存在主次,那么中心信息单元称作“核(nucleus)”,传达支撑信息的其他单元称作“卫星(satellite)”.当修辞关系连接的单元无主次之分时,则称其为“多核”关系.与Hobbs模型相比,RST更注重句子内部的结构,篇章单元可以小到短语或语块.RST认为功能语块是最基本的篇章单元(elemental discourse unit,简称EDU),EDU间的语义关系具有开放性和可扩充性.在RST构造出来的树形结构中,叶节点、非叶节点、弧线和垂直线分别表示EDU单元、连续文本块、修辞关系和核心语块.这里的“核心”与RST中的3个基本概念之一,核心性有关.核心性是指篇章由辅助单元和核心单元构成,具有不对称性.RST的另外两个概念分别是“制约因素”和“效果”,前者表示辅助篇章单元及核心篇章单元至少有一个具有制约特性,从而表明命题存在的必要性;后者表示篇章关系的解释机制,即可以用关系达到的效果反向解释关系本身.
(3) 宾州篇章树库理论
宾州篇章树库(PDTB)[11,12]理论将源自修辞结构理论的篇章修辞关系作了改进,将其划分成 3层,其中,第 1层共4大类,第2层16类,第3层23类.相比RST,PDTB体系凸显了篇章修辞关系中连接词的作用,它以连接词为核心,根据有无显式的连接词将篇章关系区分为显式和隐式关系,并对隐式关系人工添加了可表示当前语义关系的连接词,在此基础上再标注相关的篇章单元.另外,PDTB体系中的篇章单元不再考虑短语级,将从句作为最小篇章单位,从而大幅度增加了实用性.
(4) 汉语复句理论
汉语复句理论起始于 19世纪末,普遍认为是以1898年马建忠的《马氏文通》出版为标志[24],创建了汉语复句理论.《马氏文通》是最早讨论到复句问题、首次把复句问题引入汉语语法理论领域的语法著作.然而,另外也有人认为《马氏文通》在分析句子成分时使用的是自己的一套“句读论”,固然已经分析出了许多基本复句类型,但并未明确提出“复句”的概念,是“有实无名”.真正最先提出汉语复句系统之“名”的是严复的《英文汉诂》.
复句由两个或两个以上意义相关、结构上互不作为句子成分的分句组成.分句是结构上类似单句而没有完整句调的语法单位.复句中的各个分句之间一般有停顿,书面上用逗号、分号或冒号表示;复句前后有隔离性语音停顿,书面上用句号或问号、叹号表示.语法上是指能分成两个或两个以上相当于单句的分段的句子.同一复句里的分句,说的是有关系的事.一个复句只能有一个句终语调,不同于连续几个单句[17,18].
(5) 汉语句群理论
句群也叫句组,由前后连贯共同表示一个中心意思的几个句子组成.如同分句组成复句,句子组合成为句群一样的道理[16].语法学对句群的研究最早始于黎锦熙等人[25],在我国汉语语法研究史上首次详尽地论述句群,并提出了“句群是介乎复式句和段落之间的一种语言单位”的定义.
从构成成分来看,句群是句子的组合,至少需要有两个句子组合而成的语言单位才能叫作句群.从语义联系上看,组成句群的句子之间要有紧密的逻辑关系,它们必须共同拥有一个中心思想.从组合方式来看,几个句子运用一定的方式组合在一起成为一个句群,组合方式有两种:语义组合和关联组合.
句群的分类角度有很多,例如:根据句群中句子的结构关系分类,可以将其分为“并列关系”“连贯关系”“递进关系”等 12种类别.从句群的功能角度来看,则可将其分为主题句群、过度句群和插入句群三大类.句群分类大都是借鉴句子和复句的分类方法,分类方法众多,还未形成统一的标准.
(6) 基于连接依存树的汉语篇章结构理论
苏州大学自然语言处理实验室结合 PDTB体系中连接词驱动策略和 RST体系中篇章树形表示结构的优势,同时结合汉语复句和句群理论,提出了一种基于连接依存树(connective-driven dependency tree,简称CDT)的汉语篇章结构表示体系[19,20,26].该理论对完整的篇章结构(包括篇章单位、连接词、篇章结构、篇章关系、篇章主次)进行了系统的定义和描述.在该基于连接依存树的篇章结构中,叶子节点表示基本篇章单位(elementary discourse units,简称 EDUs),内部节点为连接词(connective),由连接词连接的基本篇章单位组合称为篇章单位(discourse units,简称 DUs).各子句之间通过连接词形成更高一级的篇章单位,层次组合直至形成一棵完整的篇章结构树.连接词既可以表示篇章单位层次,也可以表示篇章单位之间的逻辑语义关系,一个连接词可以连接两个或多个篇章单位,篇章单位根据在篇章中的重要程度可分为主要篇章单位和次要篇章单位.
2.1.2 篇章话题结构理论体系
涉及篇章话题结构理论体系的主要包括浅层衔接理论[10]、主述位结构及推进模式理论[13-15]、意图结构理论[8]、话题链理论[27-32]、广义话题结构[21-23]、微观话题结构理论[33,34]等.
(1) 浅层衔接理论
浅层衔接理论是最早研究篇章衔接关系的理论体系.浅层衔接理论[10]指出,“当篇章中的某个成分的解释依赖于篇章中另一个成分的解释时,这两个成分之间就产生了衔接关系”;衔接方式通常分为语法衔接和词汇衔接两大类,其中语法衔接手段包括指称、省略、替代和(逻辑)连接,连接又划分为增补型(additive)、转折型(contrastive)、原因型(causal)、时间型(temperal)4类,词汇衔接手段包括词汇的重复和搭配.
Grimes在深化 Halliday的浅层衔接理论时考虑了非词汇化的命题关系,给出了更详细的衔接关系类别.此外,Grimes首次提出了衔接关系的论元有主次之分,并明确指出,并列(paratactic)关系的论元同等重要,而主从(hypotactic)关系的论元有主次之分.
(2) 主述位理论
主述位理论中的主位、述位两个概念,最早来自于布拉格学派提出的功能语句观理论框架[13-15].Mathesius从功能语句观的角度提出主位、述位信息理论,用于描述句子所传递的信息结构.主位是指在既定语境中已知或至少是明显的信息,是说话人信息的出发点;述位是话语的核心,是说话人对主位的阐发.
Mathesius对主位的界定涉及3个方面的内容:句首性(sentence-initialness)、相关性(aboutness)、信息的新旧性(informational status).随后,Firbas又从“交际动力”的角度对主位作了进一步阐释:他提出主位是已知信息,所承载的交际动力低;述位是新信息,所承载的交际动力高;主位-述位的推进更替推动了篇章交际动力的动态传递.
此后,以Halliday(1994年)为代表的系统功能语言学派认为布拉格学派对主位的界定有些含混,故区分了主位研究的两个层次:句法层次上的主位-述位结构和语意层次上的信息结构.主位-述位结构是从篇章产生的角度来界定的,突出小句或话语的起点,而信息结构(已知/未知信息)是从篇章接受的角度来界定的,侧重篇章解读者对信息的处理.
从篇章功能的角度来看,每个小句和小句复合体的第 1个句法成分是主位,其余成分是述位.从系统功能语法学角度来看,主位和述位一起构成一则信息,主位是信息的起点,是小句组合的基础;述位是对主位的阐释和发展.
(3) 意图结构理论
意图结构理论由Grosz和Sidner最早提出[8],他们认为篇章是包含意图的,原因在于篇章的作者就是怀有表达自身意图的目的开始写作的.所以,篇章意图的解释应该和篇章内容一样纳入篇章结构理论的研究范畴,因而意图结构完全可以成为篇章结构理论的基础.在他们提出的篇章结构中,包括 3个方面,分别是语言结构(linguistic structure)、意图结构(intentional structure)、焦点状态(attentional state).
根据 Grosz和 Sidner对篇章结构的定义,篇章意图(discourse purpose,简称 DP)由篇章段意图(discourse segment purpose,简称 DSP)分解和表达,显示出篇章意图的层次性特点.同一个意图层,如果 DSP1有助于表达DSP2,则 DSP2占主导地位,称为支配(dominance)关系,支配关系与修辞结构理论中的“核心-卫星”结构相似,因此可以看作是主次关系在篇章意图层上的定义.
Moser和 Moore的研究表明,意图结构理论和修辞结构理论之间存在共性,如意图结构中的支配和修辞结构理论中的核相对应.
(4) 话题链理论
曹逢甫[27]最早提出了汉语话题链(topic chain)的概念,细致地分析了话题在控制小句连接方面的作用.话题链的形成主要依赖各种指代回指(anaphor)形式,即零形回指(zero anaphor,简称 ZA)、代词回指(pronoun anaphora,简称PA)和名词回指(nominal anaphor,简称NA)的选择方法.曲承熹[28]总结了前人的研究成果,提出了操作性较强的话题链定义“一组以零回指ZA形式的话题连接起来的小句”.
刘礼进[29]使用人工标注的小规模汉英篇章对比语料库,深入分析了话题链在汉英篇章的宏观语义结构描述功能上的差异情况;孙坤[30]对英汉篇章组织模式进行了对比研究;王建国[31]把话题链的描述作用从句子拓展到句群和篇章,重新定义话题链为“由同一话题引导的系列语句”,并深入分析了话题链在汉英篇章中的不同描述特点;周强[32]引入话题链描述形式,设计不同类型的话题评述关系集,构建了以话题链为主,融合关联词语和其他连贯形式的描述机制.
话题链是指由各个话题连接而成的链条.根据话题相同与否以及是否包含不同话题,话题链可分为“同题链”“异题链”和“包题链”3种基本类型.同题链是相同的话题形成的话题链;异题链是由不同的话题形成的话题链;包题链是由有包容关系的话题形成的话题链.在实际的篇章中,同题链、异题链、包题链层层相套,互相交错,交织形成话题网,共同推进篇章的发展(生成).
(5) 广义话题结构理论
宋柔等人针对汉语篇章话题结构进行了比较深入的研究,根据汉语篇章的特点,以标点句为基础,给出了广义话题结构的概念和相应的表示方法,提出了“话题的不可穿越性”和“话题句的成句性”两个广义话题结构性质;描述了汉语的话题结构和话题句特征,给出了话题句动态堆栈模型[21-23].这一研究成果是汉语篇章分析领域的一项开创性工作.但同时,广义话题理论的动态堆栈模型,强调子句语法成分的完整性,在分析层面描述粒度过细,在操作层面也面临可计算问题.
(6) 微观话题结构理论
苏州大学自然语言处理实验室在分析话题结构相关理论的基础上提出了基于主述位理论的篇章微观话题结构表示体系[33,34].该体系从篇章视角确立基本微观话题单元,将该单元表示成包含主位和述位的实体形式化表示模式,并基于主位推进理论搭建基本微观话题的上下文关联模式,再融合实体和上下文关联形成完整的汉语篇章话题结构表示体系.
2.2 资源建设
目前篇章结构的资源建设主要与上述篇章修辞结构(篇章连贯性)和篇章话题结构(篇章衔接性)理论体系相关,代表性资源包括修辞结构篇章树库(rhetorical structure theory discourse treebank,简称RST-DT)[35]、宾州篇章树库(Penn discourse treebank,简称 PDTB)[36]、ACE(automatic content extraction)评测语料[37]、ARRAU[38]、OntoNotes[39]和篇章图库(GraphBank)[40]等.
2.2.1 篇章修辞结构资源建设
目前与篇章修辞结构有关的英文资源主要包括宾州篇章树库PDTB[36]和修辞结构篇章树库RST-DT[35].
(1) PDTB:由美国宾夕法尼亚大学、意大利托里诺大学和英国爱丁堡大学联合标注,并由 LDC(linguistic data consortium)于 2006年正式发布.2008年 PDTB 2.0发布,它是目前规模最大的英文篇章语料库,共标注了40 600个关系,其中,包括18 439个显式篇章关系,16 224个隐式篇章关系,624个由非连接词表示的篇章关系,5 210个通过实体重复或共指表示的关系,还有254个相邻句子不存在所定义的关系.
(2) RST-DT:由美国南加州加利福尼亚大学标注,并由LDC于2002年正式发布.RST-DT选用宾州树库的文章构建二叉修辞结构树.RST-DT对EDU进行了严格的定义,规定主语或宾语从句不属于EDU,充当主要动词的补语的从句也不属于EDU.此外,所有词汇或句法标记的起状语作用的从句属于EDU,定语从句、后置的名词修辞短语或将其他EDU分割开的从句或非谓语动词短语为内置语篇单位.RST-DT完成了85篇文章的标注,共标注了53种单核心关系和25种多核心关系,这78种关系又分成16个组别,每组都具有相同的修辞功能.标注的文章内容涉及到财政报道、商业新闻、文化点评、读者来信等多种话题.
相比英语,汉语篇章修辞结构的资源构建主要采用4种方法.
(1) 基于RST的标注
乐明[41]以RST为指导,参考汉语复句和句群理论,进行了篇章结构标注的尝试.他定义了12类47种汉语修辞关系,以句号、问号、叹号、分号、冒号、破折号、省略号及段落结束符等为标记定义汉语基本篇章单位,完成97篇财经评论文章的修辞结构标注,探索了中文篇章分析中采用 RST的可行性.陈莉萍[42]试图采用RST标注汉语篇章,其基本篇章单位以标点分割,如“目前,…”中的“目前”也会作为基本篇章单位.他们的研究都表明RST的很多篇章关系无法在汉语中找到与之对应的关系.
(2) 基于PDTB体系的标注
Zhou和Xue[43]尝试使用PDTB体系标注汉语,PDTB体系以连接词为谓词标注其论元结构,结合汉语自身的特点对PDTB体系进行了改进,并以此为参考从中文树库(Chinese Treebank,简称CTB)中选取了98篇新闻语料进行了标注.2015年,Zhou和Xue[44]进一步将该语料扩大到164篇,并最终提交LDC对外进行发布.但汉语中连接词大量缺省,PDTB体系表现出很大的不适应;又由于连接词并不能覆盖每一个篇章单位,PDTB体系通常不能构建一个完整的篇章结构,这对篇章结构分析而言显然缺少了很重要的内容.张牧宇等人[45]在英文篇章关系研究的基础上分析了中英文的差异,总结了中文篇章语义分析的特点,提出一套面向中文的层次化篇章关系体系,并进行了标注实践,目前发布了哈尔滨工业大学中文篇章关系语料(HIT-CDTB),该语料选取 LDC发布的OntoNotes 4.0中的525篇汉语文本按照PDTB体系进行了分句、复句和句群3个层次的篇章关系的标注.标注内容包括显式篇章关系的关系连接词、关系元素和关系类别信息;以及隐式关系的可插入的连接词和篇章关系类别信息.他们将篇章关系分为时序、因果、条件、比较、扩展和并列这6类,标注的关系连接词共1 472类.
(3) 采用汉语本土复句和句群理论标注
参考邢福义的汉语复句研究成果[17],华中师范大学标注了汉语复句语料库[46],目前已收有标复句 658 447句,约44 395 000字,语料来源以《人民日报》和《长江日报》为主.但汉语有标复句只占汉语复句的30%左右,这就使得该语料库的应用受到很大限制.而且该语料库仅关注复句内部关系,没有涉及句子及其以上篇章单位的结构问题,这显然不能满足篇章结构分析的需求.清华汉语树库(Tsinghua Chinese Treebank,简称TCT)[47]是从大规模的经过基本信息标注的汉语平衡语料库中提取出100万汉字规模的语料文本,经过自动断句、自动句法分析和人工校对,形成的高质量汉语句法树库语料.TCT中标出了复句内各分句之间的关系信息,复句分类采用比较常用的并列关系、连贯关系、递进关系、选择关系、因果关系、目的关系、假设关系、条件关系、转折关系分类方法.但清华汉语树库中没有标注特定复句关系所对应的复句关系词,也没有标注句子之间的关系.
(4) 基于连接依存树的篇章结构资源建设
苏州大学自然语言处理实验室结合PDTB和RST体系的优势,提出了使用连接依存树(CDT)表示汉语篇章修辞结构的方案,并基于该方案,选取宾州汉语树库6.0版(Penn Chinese TreeBank,CTB 6.0)上的500篇文章进行了篇章修辞结构的标注,构建了汉语连接词驱动的篇章语料库(CDTB)[19,20],每个段落标注为一棵连接依存树,共有效标注2 342个篇章(段落),标注信息包括基本篇章单位、连接词、篇章结构、篇章关系和主次篇章单位.
表1给出了篇章修辞结构的4种核心体系的对比情况,从中可以看出,CDT借鉴了RST、PDTB和汉语的复句、句群理论,一方面明确了EDU和篇章树结构,考虑汉语中的复句,以标点句作为EDU判别的基本依据;另一方面兼顾了连接词在篇章关系中的地位,以连接词为关系类别判断的基点,可实现关系不同分类体系的迁移.
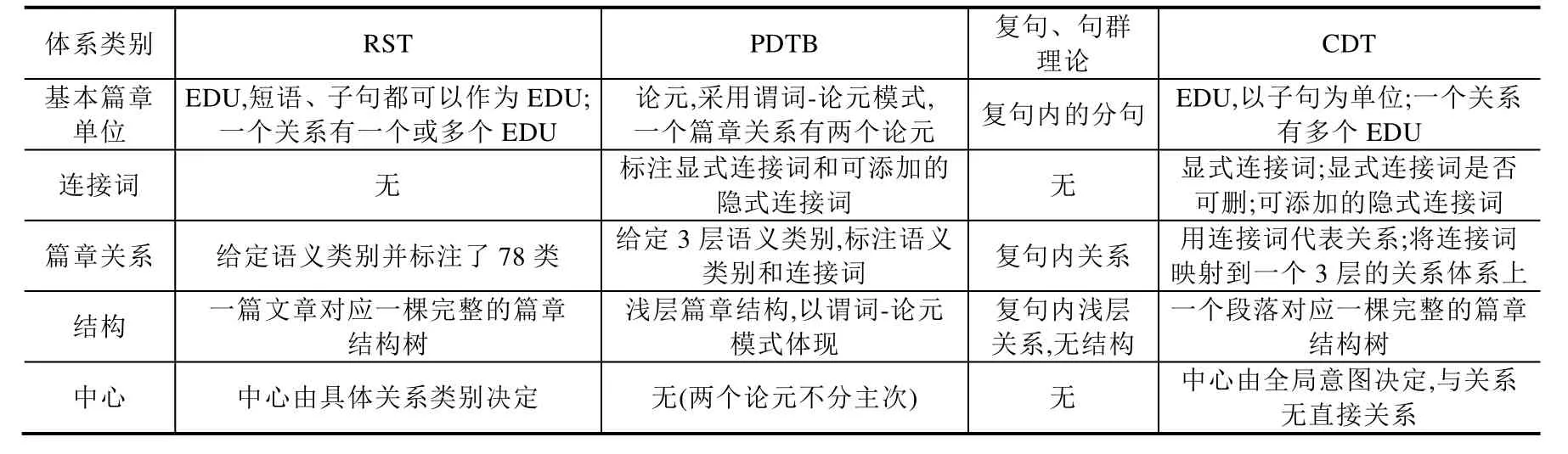
Table 1 Comparison of several important architectures of discourse rhetorical structure表1 篇章修辞结构的核心体系的对比
表2给出了3个具有一定影响力的汉语篇章修辞结构语料库的对比情况,其中,HIT-CDTB和LDC-CDTB都遵循了PDTB体系,进行了篇章关系的浅层标注,SUDA-CDTB则遵循了CDT体系,进行了篇章树结构的标注.

Table 2 Comparison of Chinese corpora for discourse rhetorical structure表2 汉语篇章修辞结构语料库对比

Table 2 Comparison of Chinese corpora for discourse rhetorical structure (Continued)表2 汉语篇章修辞结构语料库对比(续)
2.2.2 篇章话题结构资源建设
篇章话题结构方面的语料库相对较少,主要包括面向话题指称结构、面向篇章意图性、汉语篇章广义话题结构和基于主述位理论的汉语微观话题语料库资源建设等.
(1) 面向话题指称结构的语料库资源建设
指称结构是一种存在于篇章中前后两个语言单位之间的特殊语义衔接关系,而确定两者的过程即称为指称消解.目前主要的语料资源有ACE评测语料[37]、ARRAU语料库[38]、OntoNotes语料库[39].
➢ ACE评测语料
ACE是美国政府支持的自然语言处理重要会议,ACE语料评测起始于2000年,自2004年开始引入中文语料.ACE评测语料基于之前的MUC评测语料,其中的指代信息采用指代链的形式标注而成,每个指代链独立编号并被记录在文件中,而相同指代关系的实体都位于同一个指代链上.MUC和 ACE评测语料为面向衔接关系的自然语言处理研究提供了重要的语料资源,但在它们通过指代形成的语料衔接关系资源中,仅仅标注了显式实体指代,而忽略了对隐式实体(或称为省略)的指代标注.
➢ ARRAU语料库
由University of Trento(意大利)和University of Essex(英国)针对较难处理的指代问题,联合建立的指代标注语料库.该语料包括对话、说明文和新闻报道,不仅标注了实体指代,也标注了抽象指代(如事件、行为指代),但并不包含汉语部分.
➢ OntoNotes语料库
由 BBN Technologies、University of Colorado(美国)、University of Pennsylvania(美国)和 University of Southern California’s Information Sciences Institute(美国)相互合作创立.OntoNotes集成了多层面的标注,包括词汇层面、句子层面和篇章层面的标注,并不为特定评测服务.OntoNotes在篇章层面主要包含实体间以及事件的共指关系.OntoNotes中既包含英语,也包含汉语,汉语部分还标注了主语位置的零指代信息.
虽然面向话题指称结构的语料库资源相对丰富,但是对于汉语中非常突出的零指代问题,资源却非常匮乏.OntoNotes语料虽然包含了少量的主语位置的零指代信息,但该语料更多关注的是句法成分的缺失,面向篇章分析的零指代标注资源极其匮乏.
(2) 篇章意图性资源建设
为克服子句间的多种篇章关系不能被树模型的篇章结构有效表达这一缺陷,Wolf和Gibson提出了通过图结构表示篇章的方法[40],并研究了篇章图库(discourse graph bank,简称DGB)的构建问题.同时,以该结构标注了135篇文章.该方法主要分为 3步:首先,根据标点符号将篇章分为基本单元(句子/子句),称为篇章段(discourse segments);然后,再根据标点符号和话题,将上述基本单元归并成组(group),每一个组都集中表达了某个话题;最后,确定基本单元、组之间的连贯关系(coherence).
(3) 汉语篇章广义话题结构资源建设
在针对广义话题结构理论的语料资源方面,宋柔课题组基于他们提出的广义话题结构的概念,以标点句为基本篇章单位,开展了汉语篇章的话题结构标注工作[21-23].目前,已标注了《围城》、《鹿鼎记》和其他语料(涉及章回小说、现代小说、百科全书、法律法规、散文、操作说明书等语体),共约 40万字.其中,《鹿鼎记》第 1回的广义话题结构标注及其说明已在网上公开发布(http://clip.blcu.edu.cn/).
(4) 基于主述位理论的汉语微观话题语料库资源建设
苏州大学自然语言处理实验室提出了基于主述位理论的篇章微观话题结构表示体系[33,34],并据此标注形成了500篇文本的微观话题结构语料库CDTC(Chinese discourse topic corpus)[48,49].该语料从CTB 6.0中选取500篇文档标注了基本篇章单元、基本篇章话题的主位(theme)和述位(rheme)、篇章微观话题结构(micro-topic scheme)、微观话题联接、微观话题链等信息,为微观话题结构的自动分析奠定了基础.
2.3 计算模型
基于不同的理论体系和相应的语料库,近年来很多有关计算模型的研究工作陆续展开,下面我们就按研究的不同角度分别展开介绍.
2.3.1 篇章修辞结构计算模型
(1) 基于RST-DT的研究
基于RST-DT的篇章结构分析主要包含两个子任务:EDU的识别和篇章连接关系的生成.其中,EDU的识别负责对文本进行切分,提取出EDU,即构造生成的修辞结构树的树叶;连接关系的生成则采用自底向上的方法生成修辞结构树中的功能节点,并为每一节点确定一个最可能的修辞关系.
关于 EDU的自动识别研究较多,结果也比较理想.其中比较有代表性的研究包括:Soricut等人[50]采用基于统计的方法进行识别,EDU识别在自动句法树上获得F1值为83.1%,在标准句法树上F1值为84.7%.Hernault等人[51]给出了一个基于序列数据标注的篇章分割模型,使用词汇和句法特征,采用 CRF进行学习,实验结果表明,作者的序列篇章分割模型F1值达到94%,接近于人工篇章分割的F1值98%.综上可知,目前RST-DT上EDU识别准确率较高,但进一步提升的空间不大.
在篇章连接关系的生成方面,结果则不理想.Soricut等人[50]利用语法和词法信息进行句子级的篇章结构分析,他们的算法称为SPADE,在篇章关系识别时采用概率模型计算各种篇章关系的概率.篇章结构分析模型采用全自动的方法,识别无标注的篇章关系F1值为70.5%,采用正确的基本篇章单位和正确句法树的结果是96.2%.但是,SPADE并不对整篇文本进行篇章关系识别.Huong等人[52]给出了一个文本自动篇章结构生成系统,该系统分为两个层次:句子级的篇章结构分析和文本级的篇章结构分析.句子级的篇章结构分析使用句法和线索词来进行基本篇章单位的识别和篇章结构的生成.对于篇章级别,为缩小篇章结构分析的搜索空间,加入了文本相邻和文本组织限制.最终在缩小搜索空间后,系统的F1值达到了 70.1%,其缺点就是计算量较大.Hernault等人[53]在RST上实现了基于SVM的篇章结构分析器HILDA.对篇章切分和关系识别使用SVM训练了分类器,采用贪婪的自底向上的方法构建篇章结构树,篇章结构树构建的时间复杂度取决于输入文本的长度.HILDA在树构建和篇章关系分析上的效果较好,结构识别F1值为72.3%,完整句法树识别F1值为47.3%.Feng[54]在HILDA的基础上进行了篇章结构树的构建和关系识别,抽取了更丰富的特征,性能比 HILDA有所提升.Joty等人[55]给出一种使用动态条件随机场进行句子级篇章分析的方法,使用人工 EDU切分结果识别 18类关系F1值为 77.1%.Surdeanu等人[56]利用感知器模型结合逻辑回归算法进行结构创建和关系预测,同时,该分析器还借助预训练的句法依存树获取句法特征.近几年来,研究人员开始注重用若干篇章中文本的分布特征来表示篇章的内部单元.Braud等人[57]使用层次神经网络模型(hierarchical bi-LSTM)构建了一个端到端的篇章分析器.Li等人[58]用基于注意力的层次型双向LSTM模型结合CKY算法构建了图篇章解析器.Braud等人[59]使用一种前馈神经网络模型构建了两种过渡型篇章分析器.Ji和Eisenstein[60]使用支持向量机结合shift-reduce转移系统构建了DPLP篇章分析器.导致篇章分析结果较低的主要原因是 RST-DT中标注的篇章结构树的数量有限,模型没有能力获取深层次的语义信息.
(2) 基于PDTB的研究
宾州篇章语料库(PDTB)的构建,以及CoNLL 2015和2016年Shared Task的举办,显著推动了篇章结构分析的研究,在篇章计算方面受到了极大的关注.
基于PDTB的篇章分析包含论元的抽取、篇章关系的识别和端到端系统的构建这3个方面,下面分别加以介绍.
➢ 论元的抽取
代表性的工作包括:Dines等人[61]针对Subordinate类型的连接词提出了一种tree subtraction算法来自动完成句内论元的抽取,但该方法使用了一套具有很强针对性的规则,对其他类别的连接词并不完全适用.Lin等人[62]借鉴 Dinesh的 tree subtraction算法,借助机器学习方法首先识别覆盖论元的最小子树,再利用 tree subtraction算法在子树中抽取论元.但覆盖论元的最小子树也会包含非论元的部分,造成后续的抽取不能完全正确.他们的实验结果也证实了这一点:完全精确匹配的标准下,Arg1和Arg2同时正确的性能仅为40%,而在部分匹配的标准下,这一性能可达到 80%以上.Wellner等人[63]提出一种机器学习的方法来确定连接词对应论元Arg1和 Arg2的 head,但是 PDTB语料中并没有标注论元的 head信息,因而评测上缺乏一致的标准.Ghosh等人[64,65]基于条件随机场模型将论元抽取看成序列标注问题,给出了一个论元识别方案,但他们使用了一些来自PDTB的标准信息,例如语义类别、Arg2信息等,给出的结果也只考虑了标准句法树,未对自动句法分析结果进行评测.Kong等人[66]借鉴SRL中的句法树裁剪策略给出了一个论元构成子树的提取方案,并借助ILP进行全局最优,大大提升了完全精确匹配下论元识别的性能.
➢ 篇章关系识别
Pitler等人[67]指出,在PDTB篇章语料库中隐式篇章关系与显式篇章关系大约各占一半.由于显式篇章关系中连接词(connective)的存在且歧义较少(大约只有 2%),因此比较容易识别.这使得隐式篇章关系研究成为篇章结构关系分析成败的关键.识别隐式篇章关系的研究可以归纳为 3类:基于伪隐式篇章关系语料的研究,基于纯隐式篇章关系语料的研究和基于伪隐式和纯隐式的篇章关系混合语料研究.基于伪隐式关系的研究的代表性工作包括:Marcu和 Echihabi[68]首次提出使用无监督的方法识别隐式篇章关系.他们使用一系列文本模式从网络上自动获取语料资源,同时去除篇章连接词构成一个伪隐式篇章关系语料.他们的实验结果表明,使用词对(word-pairs)特征为识别隐式篇章关系提供了帮助.Saito等人[69]扩展了他们的工作,从文本域中提取短语模式特征,实验结果表明,同样有助于提高隐式篇章分析的性能.尽管如此,我们认为伪隐式篇章关系并不能从真正意义上代表纯隐式篇章关系,因为它们在表示关系上存在着很多的不同,比如隐式关系的存在表明上下文的联系足够强而不需要使用篇章连接词来衔接.
随着PDTB 2.0的发布,该语料显式地区分了隐式篇章关系和显式篇章关系,并且仅针对段落内相邻句子间的隐式篇章关系进行标注.至此,很多工作开始侧重研究纯隐式篇章关系识别.这方面具有代表性的工作包括:Pitler等人[67]首次提出使用不同的语言学特征,比如动词、极性和上下文环境等,识别隐式篇章关系.Lin等人[70]受Pitler等人的启发,首次提出使用两类句法特征,即成分句法推导规则和依存句法推导规则,来识别PDTB中第2层隐式篇章关系.Park和 Cardie[71]使用了贪婪的特征选择算法确定了识别隐式篇章关系的最优特征子集.他们的实验在第1层4大类关系上取得了最好的F1值.近年来,一些研究表明,样本不平衡问题成为了提高隐式篇章分析性能的重大阻碍.有人提出使用伪隐式和纯隐式关系混合的篇章关系来进行分析.相关工作包括:Zhou等人[72]使用语言模型来计算困惑度以判断相邻句子间插入连接词的合理性.Biran和 McKeown[73]使用聚集词对尝试解决特征稀疏问题,但他们的实验结果表明性能提升很小.为了解决隐式关系标注样本缺少的问题,Lan等人[74]提出使用多任务学习的方法引入伪隐式篇章关系来辅助隐式篇章关系的识别.Zhou等人[75]提出一种基于信息检索的无监督方法识别隐式篇章关系,他们利用 Web上的资源提取大量的伪隐式关系辅助识别隐式篇章关系.
近几年,越来越多的研究人员开始寻求用神经网络的方法来完成隐式篇章关系识别的任务.同时,为了缓解有标数据缺少带来的问题,很多传统算法和神经网络算法都借助没有标注的数据,辅助完成隐式篇章关系识别.Lan等人[76]提出了一种基于多任务注意力机制的神经网络来解决隐式篇章关系的表示和识别问题,并取得了当前最好的性能.
➢ 端到端的篇章结构分析
Lin[77]研究如何在PDTB上进行篇章结构分析,对于难度较大的隐式篇章关系识别,采用上下文、词对、句法特征、依存树特征进行识别.整个系统包括连接词识别、论元识别、显式关系分类、隐式关系分类、属性标注,这是第一个端到端的PDTB分析工作.此后,随着CoNLL 2015和2016年Shared Task以端到端的篇章逻辑语义分析为任务,大量工作随之展开,主要可以分成3类:一是跟随Lin等人的工作,进一步完善各个模块;二是借助ILP、Structured Perceptron等全局优化策略对系统进行全局优化;三是引入神经网络、深度学习框架对平台中影响性能的论元识别和隐式关系识别进行改进.
(3) 汉语篇章修辞结构分析
由于语料缺乏,这部分研究受到了制约.代表性的工作包括:张牧宇等人[78]在哈尔滨工业大学中文篇章关系语料(HIT-CDTB)上进行显式篇章句间关系和隐式篇章句间关系识别,并给出初步的实验结果,但其所标语料参考英语 PDTB体系,不能进行完全的篇章结构分析,只能进行部分篇章分析.CoNLL 2016的 Shared Task中以Zhou和Xue[44]标注的、LDC发布的CDTB V0.5为语料,引入了汉语浅层篇章修辞结构分析的任务,使得汉语浅层篇章修辞结构分析得到了一定的关注,但大部分工作都采取用英文一致的体系进行.涂眉等人[79]在TCT上进行了基于最大熵的汉语篇章结构自动分析方法,实验结果表明,篇章语义单元自动切分的F1值能达到89.1%,当篇章语义结构树高度不超过6层时,篇章语义关系标注的F1值为63%.Kong等人[80]基于苏州大学的CDTB语料采用流水线的方式构建的端到端的中文篇章解析器,该平台包括子句识别、连接词识别与分类、隐式篇章关系识别、篇章单位主次识别等部件,最终输出构建完成的篇章结构树.在CDTB上的结构性能的F1值达到了46.7%,但若再综合进篇章树中的每个关系的具体属性,整个分析器的F1性能只有20.0%.Jia等人[81]利用转移系统和深度学习的方法,给出了一个完整的从平文本到树形结构的篇章结构自动解析框架,在英文RST和苏州大学的 CDTB语料上都取得了较好的性能.孙成等人[82]给出了一个完整的基于转移系统的篇章结构树的生成框架,并参考RST上相关评价体系给出了完整的汉语篇章结构树的评价体系.
2.3.2 篇章话题结构计算模型
受限于理论体系的可计算性和相应语料资源的匮乏,目前有关篇章话题结构的计算模型研究主要集中在指代结构的研究,而指代结构的研究又分别从实体指代、事件指代和零指代3方面展开.
(1) 实体指代消解研究
作为信息抽取的核心组成部分之一,指代消解一直都是自然语言处理领域的一个研究热点.早期指代消解方法均采用启发式规则方法,从 20世纪 90年代开始,随着各类指代消解标注语料的不断发布以及一些有影响力的自然语言处理会议和公开评测的召开,例如 MUC(Message Understanding Conf.)[83,84]、ACE(automatic content extraction)[37]、CoNLL shared task[85,86]等,指代消解的研究重点也转向了数据驱动的指代消解方法研究.目前主流的方法有:
· 基于规则的方法:2010年,Raghunathan等人[87]提出了一个基于多重过滤框架的共指消解模型.这个框架是由 7个消解模块组成,这些模块按照精度从高到低进行排列,每一层的输入以上一层输出的实体聚类体为基础.该框架通过共享属性传递全局信息保证了强属性信息的功能要优于弱属性,也使得过滤模型做出共指判断时能使用所有的属性信息.2011年,Lee等人[88]基于Raghunathan的思想进行了扩展,通过添加过滤器,增加候选先行语的抽取和确定以及全局优化,使得系统在CoNLL-2011 Shared Task测评中获得最高的准确率.
· 基于统计的方法:1999年,Cardie等人[89]提出通过聚类方法进行名词短语的同指消解,其基本思想是收集篇章中的基本名词短语,根据短语的特征对名词短语聚类,判断两个名词是否属于同一个类.
· 基于分类的方法:1995年,McCarthy[90]把判断先行语的问题转换成分类问题,通过分类器判断指代语与每个先行词候选之间是否存在指代关系.这一思想为日后指代消解的研究开辟了一条全新的道路.Soon等人[91]则给出了详尽且完整的实现步骤,并开发出实用的系统.在此基础上,许多研究者进行了不同程度的扩充和改进,主要包含3类:(1) 抽取强而有力的平面特征以及篇章中结构化信息支持学习模型.例如,2012年,孔芳等人[92]提出基于树核函数的中英文消解方法;(2) 单一模型向多重模型融合逐渐演变,并以此增强分类器效果.例如,2012年,Xu等人[93]提出融合基于规则与基于分类的方法用于指代消解;(3) 优化共指链的形成.2012年,Belder等人[94]提出一种新的方法优化二元分类后共指链链接问题,把共指链接问题看成是一个线性规划问题,并提出用列生成的方法获取最优解以此达到准确消解的目的.
· 深度学习方法:深度学习是通过模拟人脑神经元和突触处理感知信号的过程,构建含多个隐层的机器学习模型.其主要优势在于能自动地学习数据中比浅层特征更加抽象的高层特征表示.Wiseman[95]提出利用循环神经网络来学习潜在的、全局的实体聚类的特征表示,利用贪婪搜索算法实现实体-实体表达模型.Clark[96]使用增强学习方法结合神经网络对实体表达排序模型进行直接优化,并提出了两种优化算法:增强策略梯度算法和奖励重调最大化算法,后者实现了更好的性能.Lee[97]利用循环神经网络对实体表达的上下文信息进行编码,结合单词的分布式表达,利用注意力机制形成 mention的有效表示,然后最大化得分函数来训练神经网络,在CoNLL 2012任务上取得了最好的结果.
上述研究主要针对英文.相比英文指代消解,目前汉语指代消解的研究要少很多,主要属于跟进型研究.代表工作包括:王厚峰等人[98-100]分别从领域和语义等知识出发,提取规则进行了指代消解的研究;李国臣等人[101]将英文平台的类似做法移植到中文指代消解中,采用决策树方法对中文人称代词的消解进行了研究.周俊生等人[102]提出了一种基于图划分的无监督的汉语指代消解算法,其性能与监督的汉语指代消解性能相当;杨勇等人[103]给出了一个基于机器学习的指代消解平台,并对指代消解中各类距离特征对指代消解性能的影响进行了深入的探索;王海东等人[104]探索了语义角色对指代消解性能的影响,他们的研究表明,语义角色信息的引入能够显著提高指代消解的性能;李渝勤等人[105]针对基于机器学习的中文共指消解中不同类别名词短语特征向量的使用差异,提出一种基于特征分选策略的方法,提高了共指消解的性能.张牧宇等人[106]提出一种利用中心语信息的新方法.该方法首先引进一种基于简单平面特征的实例匹配算法用于共指消解.在此基础上,又引入了先行语与照应语的中心语字符串作为新特征,并提出一种竞争模式,将中心语约束融合进实例匹配算法,提升了消解效果.Song等人[107]提出一种基于马尔可夫逻辑网的共指消解模型.
(2) 零指代研究
除上述名词短语的指代消解外,零指代现象在中文中频繁出现,近年来,中文零指代成为研究热点.代表性的工作有:Zhao等人[108]给出一个完整的基于机器学习的中文零指代消解方案,并提出一套有效的适用于中文零指代任务的特征集合.但是他们的工作主要关注零指代的消解子任务,对零指代项的识别仅给出一个保证高召回率的规则方法.他们的实验结果也表明,过低的零指代项识别准确率会严重影响后续消解的性能.Kong等人[109]给出一个中文零指代消解的完整框架,将中文零指代消解清晰地划分成零元素识别、零待消解项识别和零元素消解 3个子任务,并采用基于树核函数的方法分别给出每一个子任务适用的结构化特征集.但是,他们仅关注平台的统一性,只给出了标准句法树上平台的性能,未给出完全自动状况下方法有效性的验证.Chen等人[110]首次给出完整的端到端的全自动状况下的中文零指代消解平台,并提出一组更有效的句法和上下文特征.Chen等人[111]给出一个无监督方法的生成式模型,并借助它进行中文零指代消解.基于这一工作,Chen等人[112]进一步在生成式模型中基于概率将零待消解项识别和消解任务进行联合学习,取得了一定性能的提升.Chen等人[113]又进一步在该平台中引入深度学习方法,取得了更好的性能.Sheng等人[114]在传统零指代消解平台中考虑了篇章修辞结构信息,从篇章修辞树结构中提取各类篇章级的信息来帮助中文零指代,并通过一系列实验验证了修辞结构信息的引入能够提升中文零指代的性能.Kong和 Zhou[115]参考普通名词短语消解平台的研究进展,提出了一种全新的链到链的中文零指代消解方案,其基本思想是将普通名词短语的指代消解结果看作对中文零元素的先行词候选的一种过滤,并以指代链为单位进行中文零指代消解,实验取得了目前最好的性能.Yin等人[116]提出了一个借助深度记忆网络将零元素的上下文信息向量化,从而自动学习相关的语义信息来帮助零指代.Zhang等人[117]给出了一种深度神经网络方法,通过对零元素的上下文和可能的先行词候选及其上下文进行高效的向量化表征来提升零指代的性能.Liu等人[118]为了解决零指代标注语料不足这一问题提出了一种自动生成大规模伪训练语料的方法,使用这些伪语料,借助神经网络方法提升汉语零指代消解的性能.进一步地,Yin等人[119]在神经网络平台中引入强化学习策略,进一步提升了汉语零指代消解的性能.
(3) 事件指代消解研究
受限于标注语料及任务的复杂度,相比实体指代消解而言,事件指代消解的相关研究刚刚起步,大多参考实体指代消解的解决思路.主要的代表性工作有:2006年,Ahn[120]通过构建事件对,计算事件对之间的相似度来判断事件的同指关系.随着机器学习方法的推进,事件指代消解任务的研究转向通过人工构建事件的特征来计算事件之间的“距离”,进而判断同指关系.Chen等人[121]利用最大熵模型建立事件指代消解系统,并在各项评测指标下评估了系统的性能.Bejan和Harabagiu[122]运用无监督的非参贝叶斯模型将词汇特征和WordNet中的语义相似度引入事件指代消解任务中.2015年,Araki等人[123]首次提出一种联合学习模型,即将事件抽取任务和事件指代消解任务同时研究.随后Lu和Ng[124]也构建了一个基于一元二元以及三元特征融合的联合学习模型.近年来,神经网络在自然语言处理的各个领域都取得不错的研究成果,Nguyen[125]通过非连续卷积模型在 KBP[126]语料上完成事件指代消解任务的研究.同年,Krause等人[127]也搭建了卷积神经网络模型,并在ACE和ACE++语料进行了相关任务研究.在中文事件指代消解方面,受限于语料,目前只有少量工作,代表性工作包括:Lu和 Ng[124]构建的平台不仅汇报了英文事件指代消解的性能,也汇报了 KBP中文语料上的性能;滕佳月等人[128,129]基于ACE中文语料进行了中文事件指代消解的研究,并提出了基于全局优化进行性能改善的策略.
除指代外,针对篇章意图性的计算模型的研究很少,代表性工作是Pustejovsky等人[130]在GraphBank上的相关工作,他们对 GraphBank进行了分析,认为篇章连接词和两个句子间的跨度距离是高效识别显式和隐式篇章关系的关键因素.
2.4 存在的问题和研究趋势
从上述国内外研究现状的分析中我们可以看到,相比英语,汉语的篇章研究刚刚起步,汉语篇章阅读理解研究鲜有见诸文献.目前汉语篇章理解还存在如下一些主要问题.
(1) 适用于汉语篇章阅读理解的篇章结构理论体系很不完善.有必要借鉴英语的相关篇章理论,并结合汉语特点和复句、句群、广义话题结构等本土理论,逐步建立汉语篇章结构理论体系.
(2) 适用于汉语篇章阅读理解的篇章结构大规模标注资源非常缺乏.虽然有一些研究者,或基于英语篇章理论体系,或基于汉语的复句、句群和广义话题结构等理论,对汉语篇章结构资源库展开了研究,但相关研究比较分散,大多属于探索性工作,有待进一步深入、系统地进行研究.
(3) 适用于汉语篇章阅读理解的篇章结构分析关键技术十分匮乏.由于适用于汉语篇章结构分析的理论体系尚未有效建立,相关标注资源缺乏,因此很难大规模有效地进行关键技术研究.
(4) 篇章理解需要涉及不同视角、不同层次的篇章结构分析结果,各种结构间也存在明显的互补关系,构建统一体系(包括理论体系和资源)进行多视角、多层次的联合分析研究,有待进一步深入.
2.5 机器阅读理解的相关研究
虽然适用于汉语篇章阅读理解的篇章结构分析研究处于起步阶段,机器阅读理解的相关研究却吸引了众多研究者.目前,机器阅读理解方面已经开展了一些工作,具体包括:Hermann等人[131]借助爬虫技术从CNN和每日邮报新闻网页爬取数据,构建了一个完形填空类型(cloze-style)的阅读理解数据库CNN and Daily Mail.2016年,斯坦福大学通过亚马逊众包平台建立了一个新的阅读理解数据集 SQuAD[132],它包含 536篇维基百科文章,100 000多个问题,而且每篇文章都是经过人工阅读,提出问题并给出答案片段.微软公司选取了100 000多名用户通过Bing搜索引擎提出的问题,每一个问题都会对应大约10篇相关的从网页抽取的文章,相关人员会根据10篇文章给出问题的答案,以此构建了MS MARCO[133]语料库.随着这些语料的正式发布,各种机器学习方法、深度神经网络方法和 attention机制都不断被提出并被应用到这一任务中[134-142].此外,Cui等人[143]发布了第一个中文cloze-style阅读理解语料People Daily News数据集和Children’s Fairy Tale(CFT)数据集.从2017年至今,“讯飞杯”中文机器阅读理解评测已经成功举办两届,从第1届以填空型阅读理解问题为主,到第2届关注基于篇章片段抽取的阅读理解,评测会议发布了人工标注的中文填空型和篇章片段抽取型阅读理解的数据集[144],很多的相关研究也在这些数据集上有所展开.但本质上,这些工作只是把篇章看作一个词符号序列,缺乏真正意义上的篇章理解.当然,从另一层面而言,这些研究也大大推动了人们对篇章理解的关注和重视.例如,NSFC最近几年就批准了多个汉语篇章理解方向的重点项目和人工智能应急重点项目,包括哈尔滨工业大学刘挺主持的篇章级中文语义分析理论与方法,中国科学院自动化研究所宗成庆主持的汉语多层次语篇分析理论方法研究与应用,苏州大学张民主持的面向多层次篇章语义的机器翻译理论、方法与实现,北京理工大学黄河燕主持的中文语义深度计算与阅读理解,以及苏州大学周国栋主持的话题驱动的汉语篇章机器阅读理解等.
3 总 结
综上所述,在自然语言处理领域,与词法分析、句法分析等研究相比,篇章结构分析研究相对滞后.特别是适用于汉语篇章阅读理解的篇章结构分析研究还处于起步阶段,尚未形成一套有效的理论体系,相应语料库资源建设薄弱,关键技术研究严重滞后.相应地,机器阅读理解的相关研究也刚刚起步,目前主要是基于检索技术的相关片段抽取,缺乏真正意义上的篇章理解.众所周知,与英语等西方语言相比,汉语无论是篇章结构和信息意图表达方式,还是事件描述方式和话题表述方式等方面都有较大的差异.这就迫切需要进一步完善适用于汉语篇章阅读理解的篇章结构理论体系,建立一定规模的适用于汉语篇章阅读理解的汉语篇章结构资源库,并在此基础上建立汉语篇章结构分析的计算模型,实现高性能的汉语篇章结构分析和篇章深度理解平台,为自然语言理解和篇章级应用提供基础支撑.
猜你喜欢
科学咨询(2022年19期)2022-11-24
成都理工大学学报·社会科学版(2022年1期)2022-05-26
华北电力大学学报(社会科学版)(2021年2期)2021-07-21
考试与评价·八年级版(2020年1期)2020-10-26
阅读与作文(英语初中版)(2019年10期)2019-11-27
新生代(2019年3期)2019-10-19
高中生学习·高三版(2016年12期)2016-12-26
东西南北(2016年19期)2016-11-01
儿童时代·快乐苗苗(2009年5期)2009-06-04
安徽理工大学学报·自然科学版(2008年1期)2008-06-25
